 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Enhancing Event Sequence Modeling with Contrastive Relational Inference
Sep 06, 2023
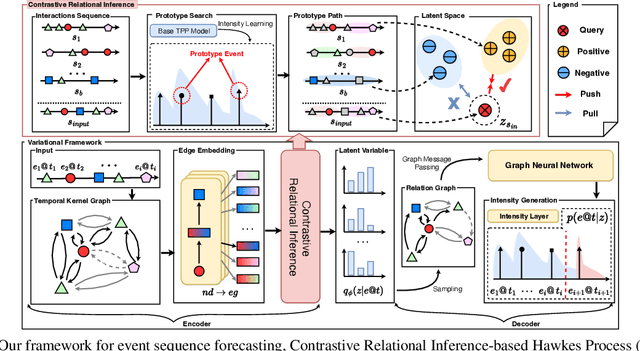
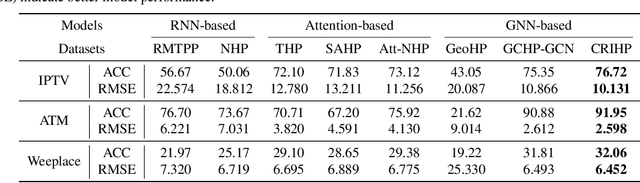
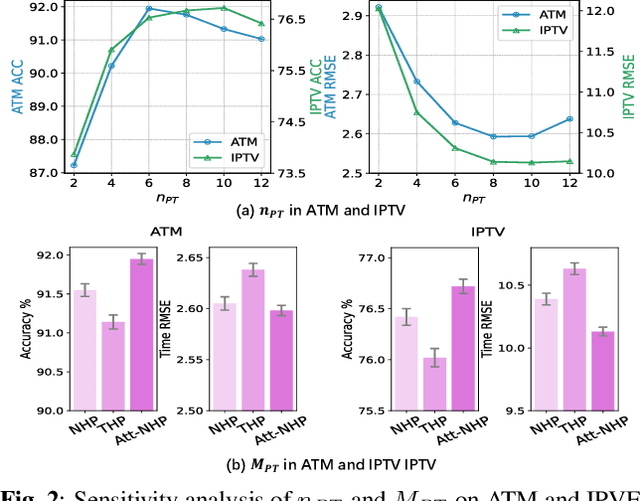
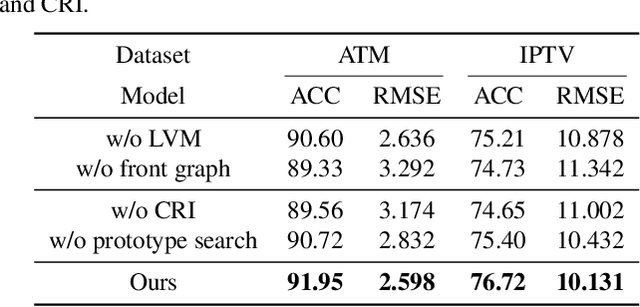
Neural temporal point processes(TPPs) have shown promise for modeling continuous-time event sequences. However, capturing the interactions between events is challenging yet critical for performing inference tasks like forecasting on event sequence data. Existing TPP models have focused on parameterizing the conditional distribution of future events but struggle to model event interactions. In this paper, we propose a novel approach that leverages Neural Relational Inference (NRI) to learn a relation graph that infers interactions while simultaneously learning the dynamics patterns from observational data. Our approach, the Contrastive Relational Inference-based Hawkes Process (CRIHP), reasons about event interactions under a variational inference framework. It utilizes intensity-based learning to search for prototype paths to contrast relationship constraints. Extensive experiments on three real-world datasets demonstrate the effectiveness of our model in capturing event interactions for event sequence modeling tasks.
Autoencoders for Real-Time SUEP Detection
Jun 23, 2023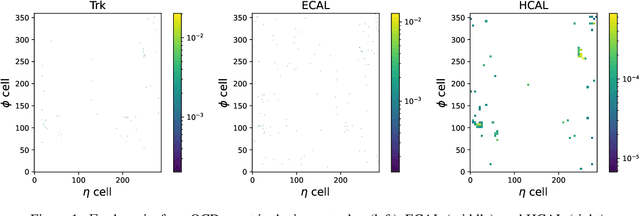
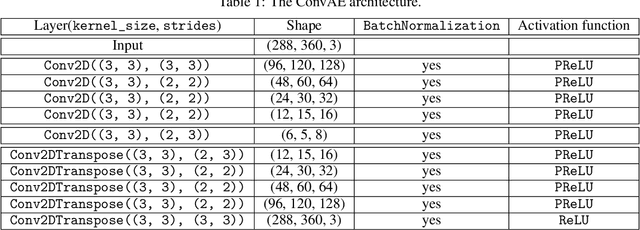
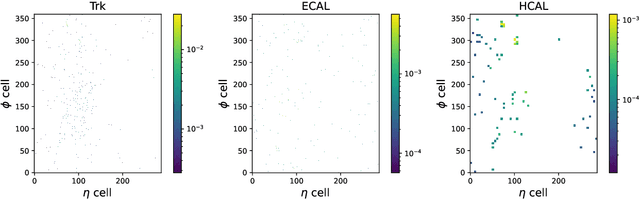
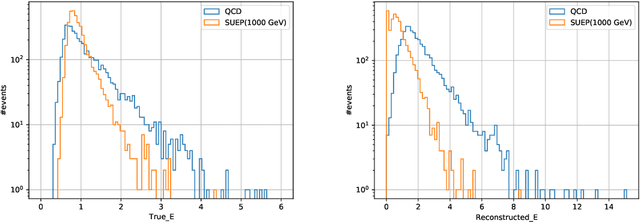
Confining dark sectors with pseudo-conformal dynamics can produce Soft Unclustered Energy Patterns, or SUEPs, at the Large Hadron Collider: the production of dark quarks in proton-proton collisions leading to a dark shower and the high-multiplicity production of dark hadrons. The final experimental signature is spherically-symmetric energy deposits by an anomalously large number of soft Standard Model particles with a transverse energy of a few hundred MeV. The dominant background for the SUEP search, if it gets produced via gluon-gluon fusion, is multi-jet QCD events. We have developed a deep learning-based Anomaly Detection technique to reject QCD jets and identify any anomalous signature, including SUEP, in real-time in the High-Level Trigger system of the Compact Muon Solenoid experiment at the Large Hadron Collider. A deep convolutional neural autoencoder network has been trained using QCD events by taking transverse energy deposits in the inner tracker, electromagnetic calorimeter, and hadron calorimeter sub-detectors as 3-channel image data. To tackle the biggest challenge of the task, due to the sparse nature of the data: only ~0.5% of the total ~300 k image pixels have non-zero values, a non-standard loss function, the inverse of the so-called Dice Loss, has been exploited. The trained autoencoder with learned spatial features of QCD jets can detect 40% of the SUEP events, with a QCD event mistagging rate as low as 2%. The model inference time has been measured using the Intel CoreTM i5-9600KF processor and found to be ~20 ms, which perfectly satisfies the High-Level Trigger system's latency of O(100) ms. Given the virtue of the unsupervised learning of the autoencoders, the trained model can be applied to any new physics model that predicts an experimental signature anomalous to QCD jets.
AI4Food-NutritionFW: A Novel Framework for the Automatic Synthesis and Analysis of Eating Behaviours
Sep 12, 2023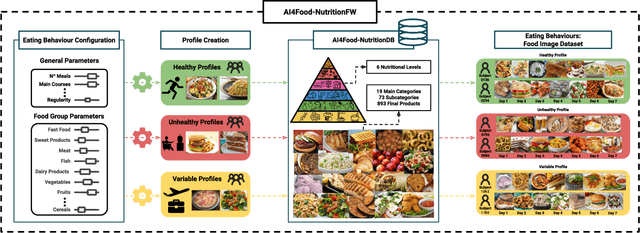
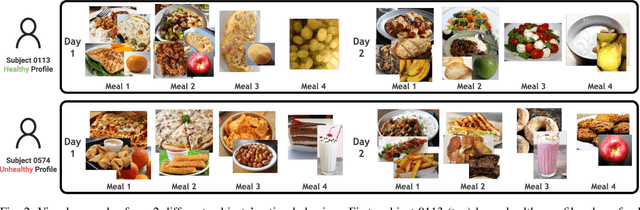
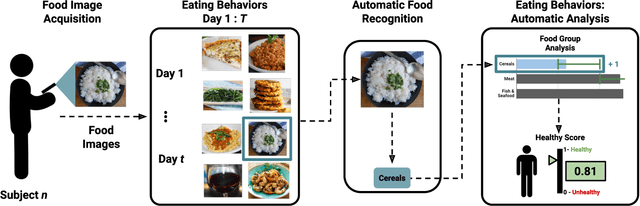
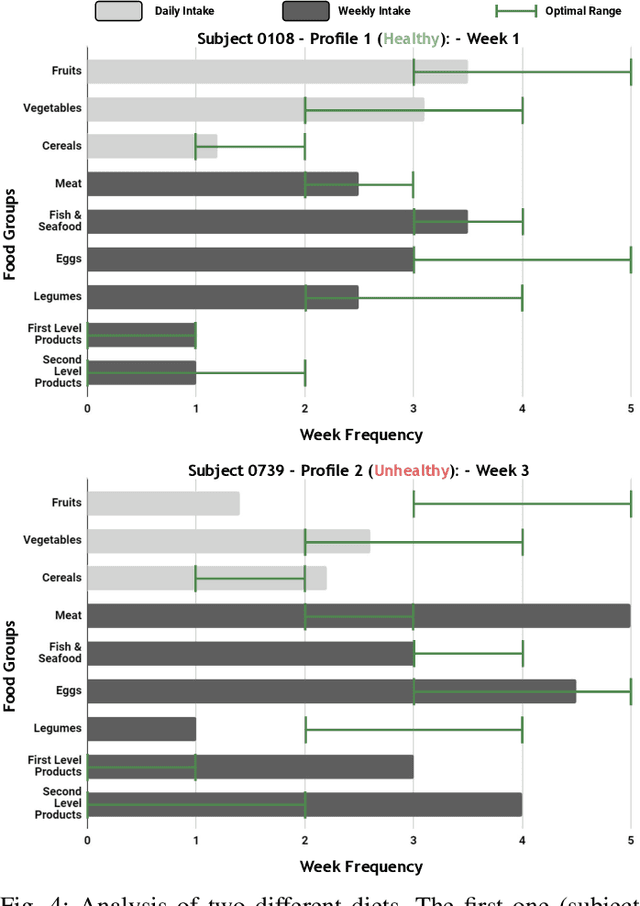
Nowadays millions of images are shared on social media and web platforms. In particular, many of them are food images taken from a smartphone over time, providing information related to the individual's diet. On the other hand, eating behaviours are directly related to some of the most prevalent diseases in the world. Exploiting recent advances in image processing and Artificial Intelligence (AI), this scenario represents an excellent opportunity to: i) create new methods that analyse the individuals' health from what they eat, and ii) develop personalised recommendations to improve nutrition and diet under specific circumstances (e.g., obesity or COVID). Having tunable tools for creating food image datasets that facilitate research in both lines is very much needed. This paper proposes AI4Food-NutritionFW, a framework for the creation of food image datasets according to configurable eating behaviours. AI4Food-NutritionFW simulates a user-friendly and widespread scenario where images are taken using a smartphone. In addition to the framework, we also provide and describe a unique food image dataset that includes 4,800 different weekly eating behaviours from 15 different profiles and 1,200 subjects. Specifically, we consider profiles that comply with actual lifestyles from healthy eating behaviours (according to established knowledge), variable profiles (e.g., eating out, holidays), to unhealthy ones (e.g., excess of fast food or sweets). Finally, we automatically evaluate a healthy index of the subject's eating behaviours using multidimensional metrics based on guidelines for healthy diets proposed by international organisations, achieving promising results (99.53% and 99.60% accuracy and sensitivity, respectively). We also release to the research community a software implementation of our proposed AI4Food-NutritionFW and the mentioned food image dataset created with it.
When UAVs Meet ISAC: Real-Time Trajectory Design for Secure Communications
Jun 25, 2023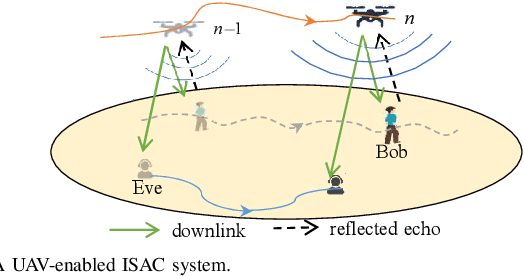
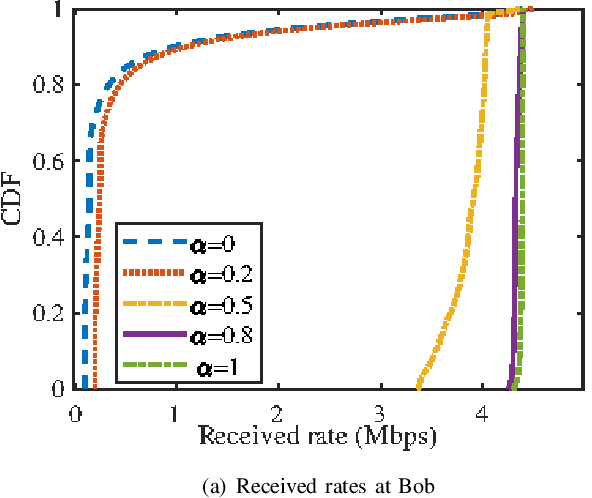
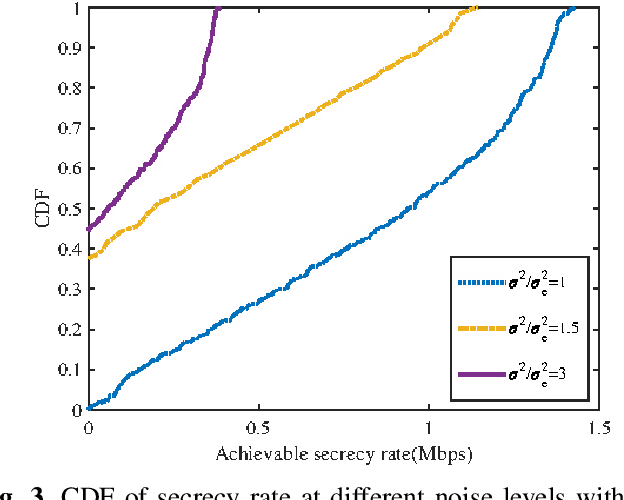
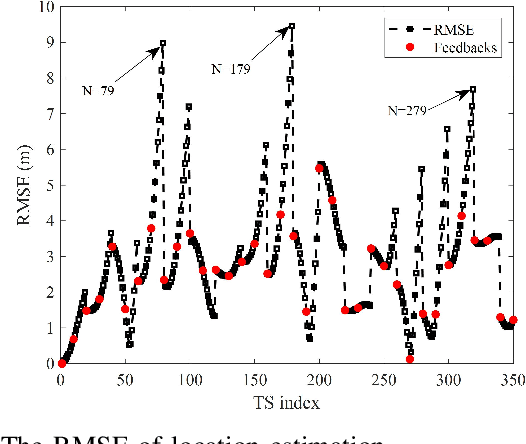
The real-time unmanned aerial vehicle (UAV) trajectory design of secure integrated sensing and communication (ISAC) is optimized. In particular, the UAV serves both as a downlink transmitter and a radar receiver. The legitimate user (Bob) roams on ground through a series of unknown locations, while the eavesdropper moves following a fixed known trajectory. To maximize the real-time secrecy rate, we propose an extended Kalman filtering (EKF)-based method for tracking and predicting Bob's location at the UAV based on the delay measurements extracted from the sensing echoes. We then formulate a non-convex real-time trajectory design problem and develop an efficient iterative algorithm for finding a near optimal solution. Our numerical results demonstrate that the proposed algorithm is capable of accurately tracking Bob and strikes a compelling legitimate vs. leakage rate trade-off.
Combining predictive distributions of electricity prices: Does minimizing the CRPS lead to optimal decisions in day-ahead bidding?
Aug 29, 2023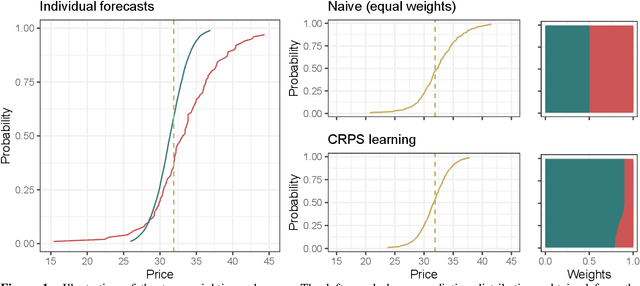
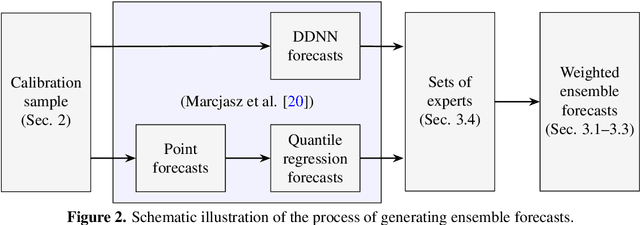
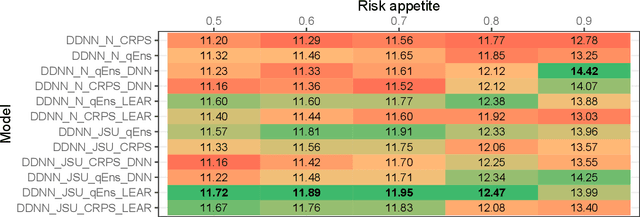
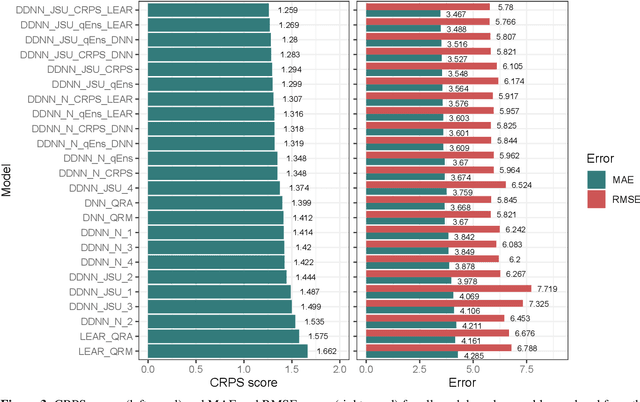
Probabilistic price forecasting has recently gained attention in power trading because decisions based on such predictions can yield significantly higher profits than those made with point forecasts alone. At the same time, methods are being developed to combine predictive distributions, since no model is perfect and averaging generally improves forecasting performance. In this article we address the question of whether using CRPS learning, a novel weighting technique minimizing the continuous ranked probability score (CRPS), leads to optimal decisions in day-ahead bidding. To this end, we conduct an empirical study using hourly day-ahead electricity prices from the German EPEX market. We find that increasing the diversity of an ensemble can have a positive impact on accuracy. At the same time, the higher computational cost of using CRPS learning compared to an equal-weighted aggregation of distributions is not offset by higher profits, despite significantly more accurate predictions.
MDTD: A Multi Domain Trojan Detector for Deep Neural Networks
Sep 03, 2023

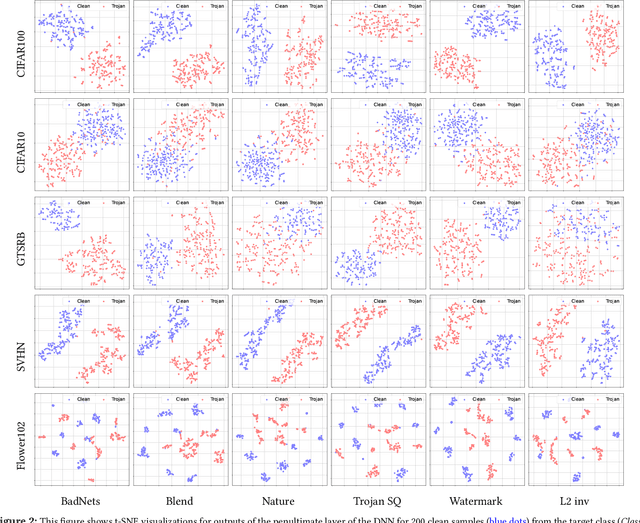

Machine learning models that use deep neural networks (DNNs) are vulnerable to backdoor attacks. An adversary carrying out a backdoor attack embeds a predefined perturbation called a trigger into a small subset of input samples and trains the DNN such that the presence of the trigger in the input results in an adversary-desired output class. Such adversarial retraining however needs to ensure that outputs for inputs without the trigger remain unaffected and provide high classification accuracy on clean samples. In this paper, we propose MDTD, a Multi-Domain Trojan Detector for DNNs, which detects inputs containing a Trojan trigger at testing time. MDTD does not require knowledge of trigger-embedding strategy of the attacker and can be applied to a pre-trained DNN model with image, audio, or graph-based inputs. MDTD leverages an insight that input samples containing a Trojan trigger are located relatively farther away from a decision boundary than clean samples. MDTD estimates the distance to a decision boundary using adversarial learning methods and uses this distance to infer whether a test-time input sample is Trojaned or not. We evaluate MDTD against state-of-the-art Trojan detection methods across five widely used image-based datasets: CIFAR100, CIFAR10, GTSRB, SVHN, and Flowers102; four graph-based datasets: AIDS, WinMal, Toxicant, and COLLAB; and the SpeechCommand audio dataset. MDTD effectively identifies samples that contain different types of Trojan triggers. We evaluate MDTD against adaptive attacks where an adversary trains a robust DNN to increase (decrease) distance of benign (Trojan) inputs from a decision boundary.
Comparative Analysis of Deep Learning Architectures for Breast Cancer Diagnosis Using the BreaKHis Dataset
Sep 10, 2023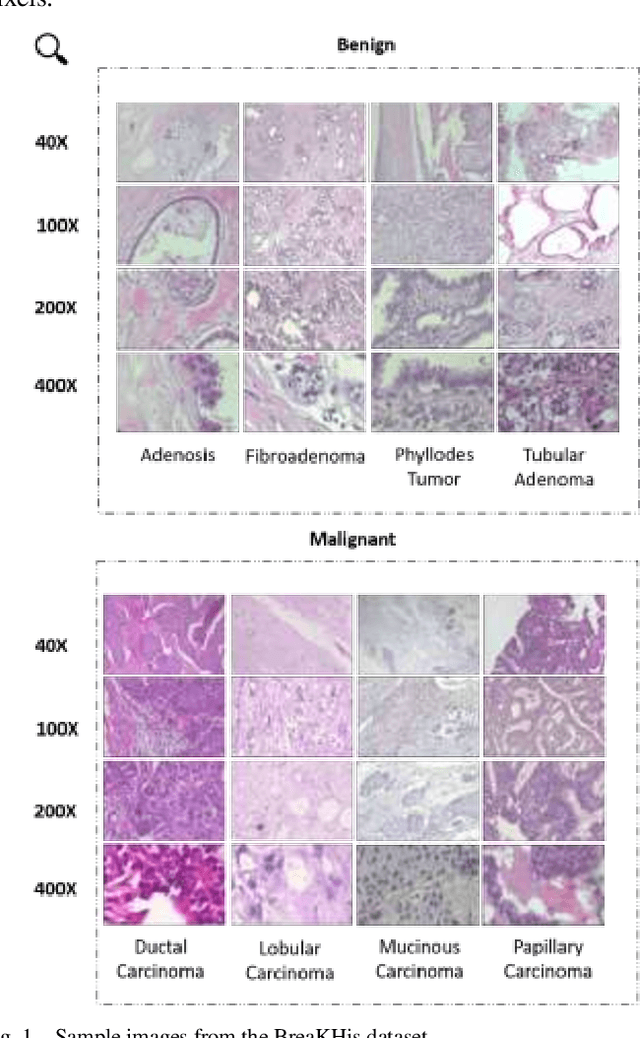

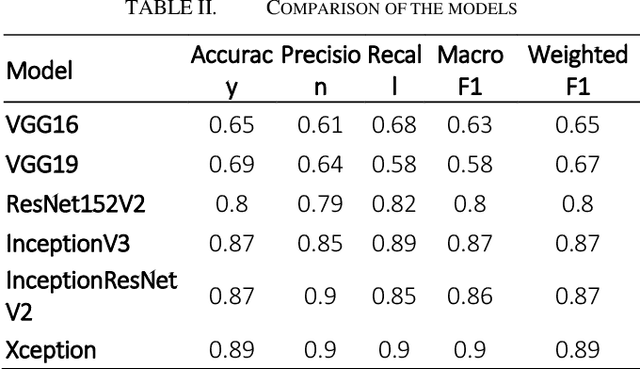
Cancer is an extremely difficult and dangerous health problem because it manifests in so many different ways and affects so many different organs and tissues. The primary goal of this research was to evaluate deep learning models' ability to correctly identify breast cancer cases using the BreakHis dataset. The BreakHis dataset covers a wide range of breast cancer subtypes through its huge collection of histopathological pictures. In this study, we use and compare the performance of five well-known deep learning models for cancer classification: VGG, ResNet, Xception, Inception, and InceptionResNet. The results placed the Xception model at the top, with an F1 score of 0.9 and an accuracy of 89%. At the same time, the Inception and InceptionResNet models both hit accuracy of 87% . However, the F1 score for the Inception model was 87, while that for the InceptionResNet model was 86. These results demonstrate the importance of deep learning methods in making correct breast cancer diagnoses. This highlights the potential to provide improved diagnostic services to patients. The findings of this study not only improve current methods of cancer diagnosis, but also make significant contributions to the creation of new and improved cancer treatment strategies. In a nutshell, the results of this study represent a major advancement in the direction of achieving these vital healthcare goals.
SdCT-GAN: Reconstructing CT from Biplanar X-Rays with Self-driven Generative Adversarial Networks
Sep 10, 2023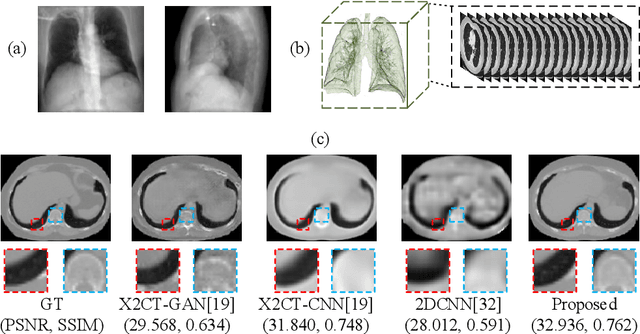
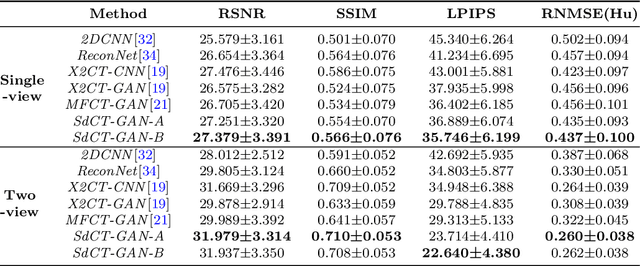
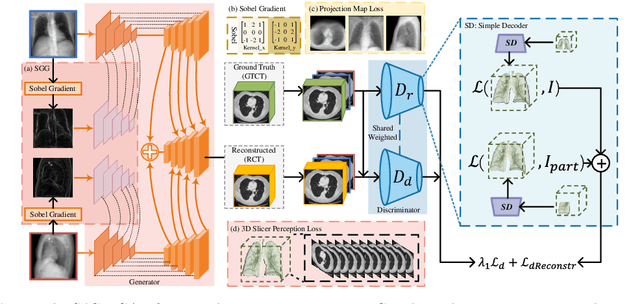

Computed Tomography (CT) is a medical imaging modality that can generate more informative 3D images than 2D X-rays. However, this advantage comes at the expense of more radiation exposure, higher costs, and longer acquisition time. Hence, the reconstruction of 3D CT images using a limited number of 2D X-rays has gained significant importance as an economical alternative. Nevertheless, existing methods primarily prioritize minimizing pixel/voxel-level intensity discrepancies, often neglecting the preservation of textural details in the synthesized images. This oversight directly impacts the quality of the reconstructed images and thus affects the clinical diagnosis. To address the deficits, this paper presents a new self-driven generative adversarial network model (SdCT-GAN), which is motivated to pay more attention to image details by introducing a novel auto-encoder structure in the discriminator. In addition, a Sobel Gradient Guider (SGG) idea is applied throughout the model, where the edge information from the 2D X-ray image at the input can be integrated. Moreover, LPIPS (Learned Perceptual Image Patch Similarity) evaluation metric is adopted that can quantitatively evaluate the fine contours and textures of reconstructed images better than the existing ones. Finally, the qualitative and quantitative results of the empirical studies justify the power of the proposed model compared to mainstream state-of-the-art baselines.
Less is More -- Towards parsimonious multi-task models using structured sparsity
Aug 31, 2023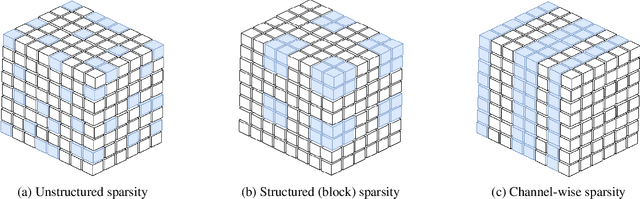
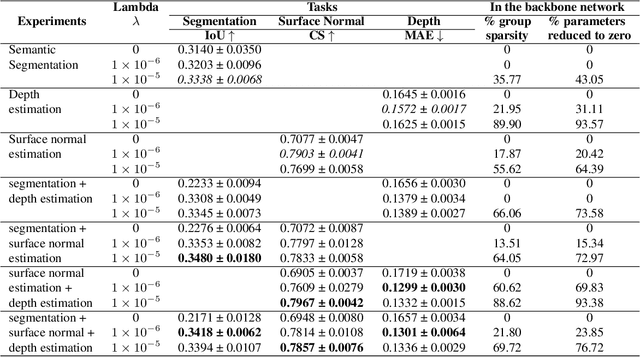
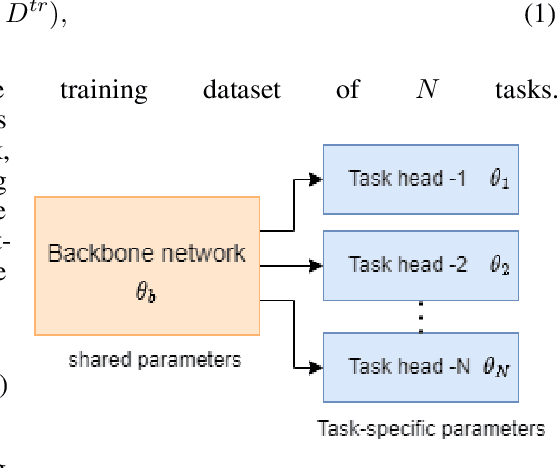

Model sparsification in deep learning promotes simpler, more interpretable models with fewer parameters. This not only reduces the model's memory footprint and computational needs but also shortens inference time. This work focuses on creating sparse models optimized for multiple tasks with fewer parameters. These parsimonious models also possess the potential to match or outperform dense models in terms of performance. In this work, we introduce channel-wise l1/l2 group sparsity in the shared convolutional layers parameters (or weights) of the multi-task learning model. This approach facilitates the removal of extraneous groups i.e., channels (due to l1 regularization) and also imposes a penalty on the weights, further enhancing the learning efficiency for all tasks (due to l2 regularization). We analyzed the results of group sparsity in both single-task and multi-task settings on two widely-used Multi-Task Learning (MTL) datasets: NYU-v2 and CelebAMask-HQ. On both datasets, which consist of three different computer vision tasks each, multi-task models with approximately 70% sparsity outperform their dense equivalents. We also investigate how changing the degree of sparsification influences the model's performance, the overall sparsity percentage, the patterns of sparsity, and the inference time.
Towards Fast and Accurate Image-Text Retrieval with Self-Supervised Fine-Grained Alignment
Aug 27, 2023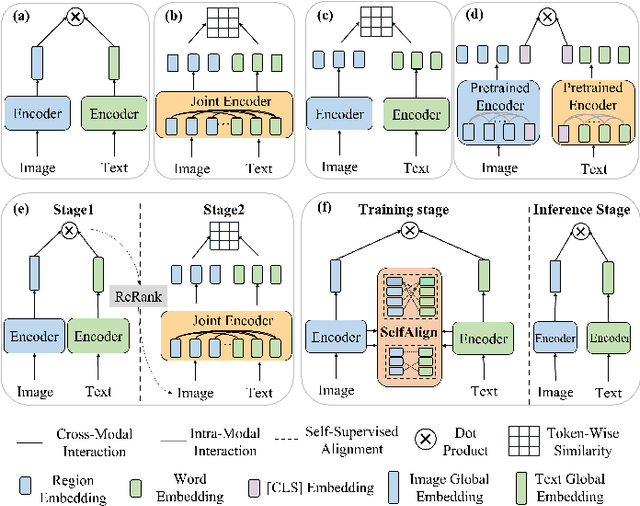
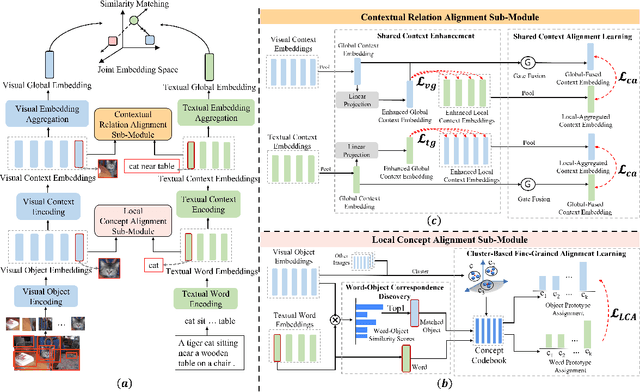
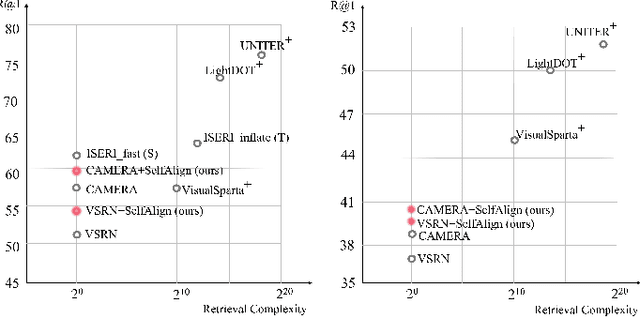
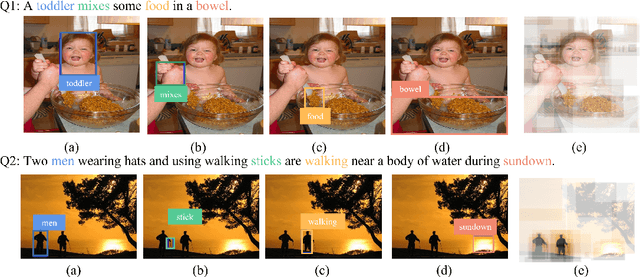
Image-text retrieval requires the system to bridge the heterogenous gap between vision and language for accurate retrieval while keeping the network lightweight-enough for efficient retrieval. Existing trade-off solutions mainly study from the view of incorporating cross-modal interactions with the independent-embedding framework or leveraging stronger pretrained encoders, which still demand time-consuming similarity measurement or heavyweight model structure in the retrieval stage. In this work, we propose an image-text alignment module SelfAlign on top of the independent-embedding framework, which improves the retrieval accuracy while maintains the retrieval efficiency without extra supervision. SelfAlign contains two collaborative sub-modules that force image-text alignment at both concept level and context level by self-supervised contrastive learning. It does not require cross-modal embedding interactions during training while maintaining independent image and text encoders during retrieval. With comparable time cost, SelfAlign consistently boosts the accuracy of state-of-the-art non-pretraining independent-embedding models respectively by 9.1%, 4.2% and 6.6% in terms of R@sum score on Flickr30K, MSCOCO 1K and MS-COCO 5K datasets. The retrieval accuracy also outperforms most existing interactive-embedding models with orders of magnitude decrease in retrieval time. The source code is available at: https://github.com/Zjamie813/SelfAlign.
* Accepted in IEEE Transactions on Multimedia (TMM)