 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
An Asynchronous Linear Filter Architecture for Hybrid Event-Frame Cameras
Sep 03, 2023
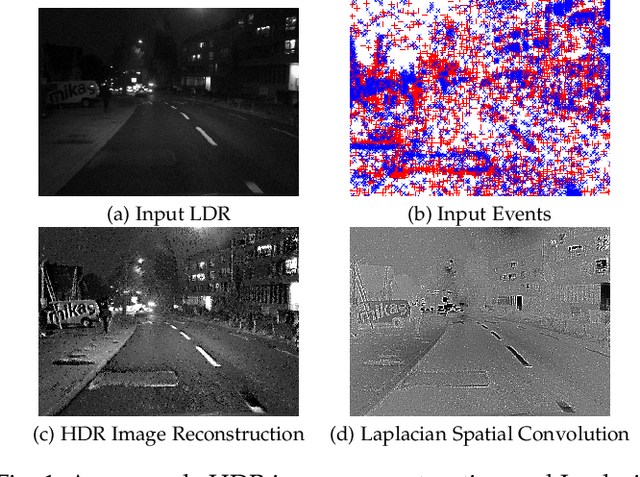
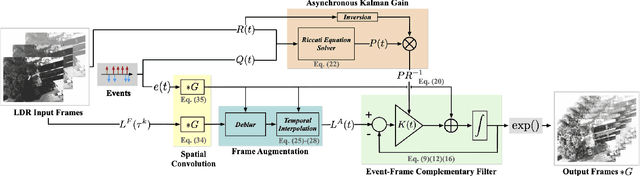

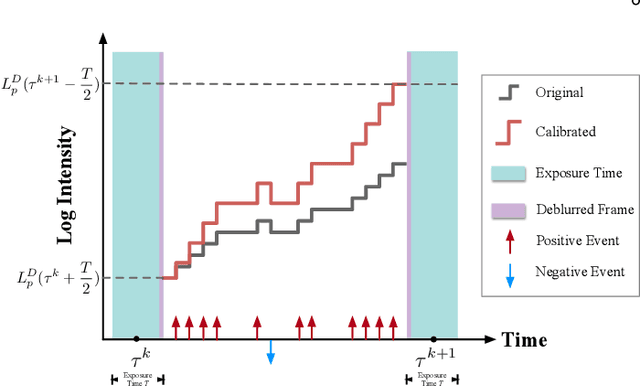
Event cameras are ideally suited to capture High Dynamic Range (HDR) visual information without blur but provide poor imaging capability for static or slowly varying scenes. Conversely, conventional image sensors measure absolute intensity of slowly changing scenes effectively but do poorly on HDR or quickly changing scenes. In this paper, we present an asynchronous linear filter architecture, fusing event and frame camera data, for HDR video reconstruction and spatial convolution that exploits the advantages of both sensor modalities. The key idea is the introduction of a state that directly encodes the integrated or convolved image information and that is updated asynchronously as each event or each frame arrives from the camera. The state can be read-off as-often-as and whenever required to feed into subsequent vision modules for real-time robotic systems. Our experimental results are evaluated on both publicly available datasets with challenging lighting conditions and fast motions, along with a new dataset with HDR reference that we provide. The proposed AKF pipeline outperforms other state-of-the-art methods in both absolute intensity error (69.4% reduction) and image similarity indexes (average 35.5% improvement). We also demonstrate the integration of image convolution with linear spatial kernels Gaussian, Sobel, and Laplacian as an application of our architecture.
T-SaS: Toward Shift-aware Dynamic Adaptation for Streaming Data
Sep 05, 2023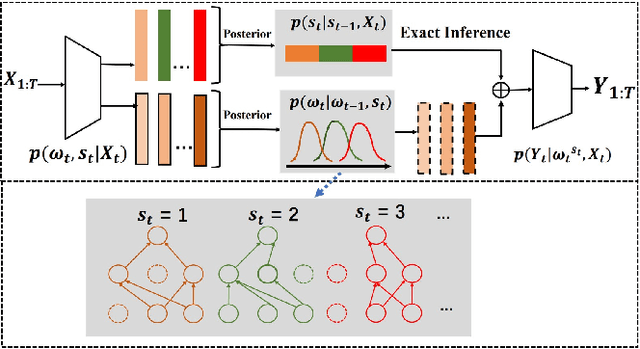
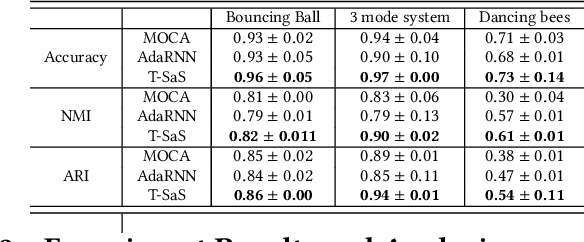

In many real-world scenarios, distribution shifts exist in the streaming data across time steps. Many complex sequential data can be effectively divided into distinct regimes that exhibit persistent dynamics. Discovering the shifted behaviors and the evolving patterns underlying the streaming data are important to understand the dynamic system. Existing methods typically train one robust model to work for the evolving data of distinct distributions or sequentially adapt the model utilizing explicitly given regime boundaries. However, there are two challenges: (1) shifts in data streams could happen drastically and abruptly without precursors. Boundaries of distribution shifts are usually unavailable, and (2) training a shared model for all domains could fail to capture varying patterns. This paper aims to solve the problem of sequential data modeling in the presence of sudden distribution shifts that occur without any precursors. Specifically, we design a Bayesian framework, dubbed as T-SaS, with a discrete distribution-modeling variable to capture abrupt shifts of data. Then, we design a model that enable adaptation with dynamic network selection conditioned on that discrete variable. The proposed method learns specific model parameters for each distribution by learning which neurons should be activated in the full network. A dynamic masking strategy is adopted here to support inter-distribution transfer through the overlapping of a set of sparse networks. Extensive experiments show that our proposed method is superior in both accurately detecting shift boundaries to get segments of varying distributions and effectively adapting to downstream forecast or classification tasks.
Decomposed Guided Dynamic Filters for Efficient RGB-Guided Depth Completion
Sep 05, 2023RGB-guided depth completion aims at predicting dense depth maps from sparse depth measurements and corresponding RGB images, where how to effectively and efficiently exploit the multi-modal information is a key issue. Guided dynamic filters, which generate spatially-variant depth-wise separable convolutional filters from RGB features to guide depth features, have been proven to be effective in this task. However, the dynamically generated filters require massive model parameters, computational costs and memory footprints when the number of feature channels is large. In this paper, we propose to decompose the guided dynamic filters into a spatially-shared component multiplied by content-adaptive adaptors at each spatial location. Based on the proposed idea, we introduce two decomposition schemes A and B, which decompose the filters by splitting the filter structure and using spatial-wise attention, respectively. The decomposed filters not only maintain the favorable properties of guided dynamic filters as being content-dependent and spatially-variant, but also reduce model parameters and hardware costs, as the learned adaptors are decoupled with the number of feature channels. Extensive experimental results demonstrate that the methods using our schemes outperform state-of-the-art methods on the KITTI dataset, and rank 1st and 2nd on the KITTI benchmark at the time of submission. Meanwhile, they also achieve comparable performance on the NYUv2 dataset. In addition, our proposed methods are general and could be employed as plug-and-play feature fusion blocks in other multi-modal fusion tasks such as RGB-D salient object detection.
Compositional nonlinear audio signal processing with Volterra series
Aug 23, 2023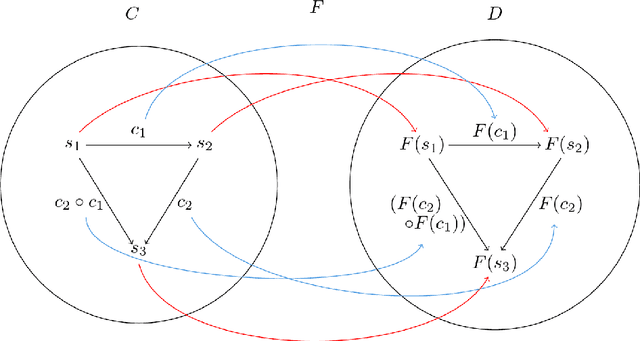
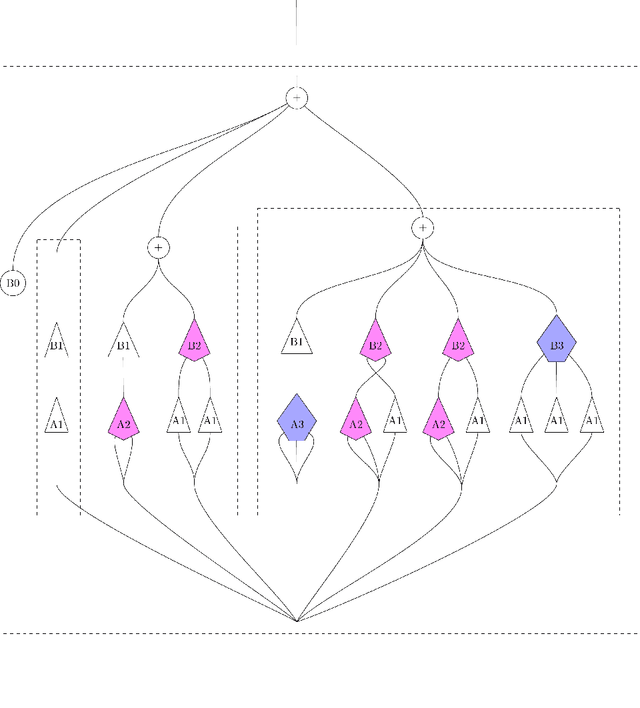
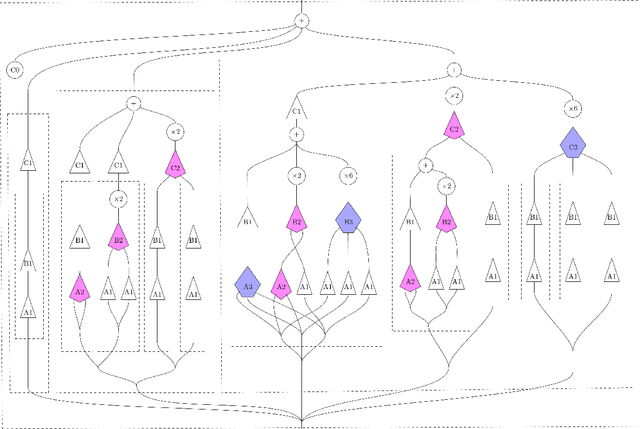
We develop a compositional theory of nonlinear audio signal processing based on a categorification of the Volterra series. We begin by considering what it would mean for the Volterra series to be functorial with respect to a base category whose objects are temperate distributions and whose morphisms are certain linear transformations. This leads to formulae describing how the outcomes of nonlinear transformations are affected if their input signals are first linearly processed. We then consider how nonlinear audio systems change, and introduce as a model thereof a notion of morphism of Volterra series, which we exhibit as a kind of lens map. We show how morphisms can be parameterized and used to generate indexed families of Volterra series, which are well-suited to model nonstationary or time-varying nonlinear phenomena. We then describe how Volterra series and their morphisms organize into a category, which we call Volt. We exhibit the operations of sum, product, and series composition of Volterra series as monoidal products on Volt and identify, for each in turn, its corresponding universal property. We show, in particular, that the series composition of Volterra series is associative. We then bridge between our framework and a subject at the heart of audio signal processing: time-frequency analysis. Specifically, we show that an equivalence between a certain class of second-order Volterra series and the bilinear time-frequency distributions (TFDs) can be extended to one between certain higher-order Volterra series and the so-called polynomial TFDs. We end with prospects for future work, including the incorporation of nonlinear system identification techniques and the extension of our theory to the settings of compositional graph and topological audio signal processing.
Medical needle tip tracking based on Optical Imaging and AI
Aug 28, 2023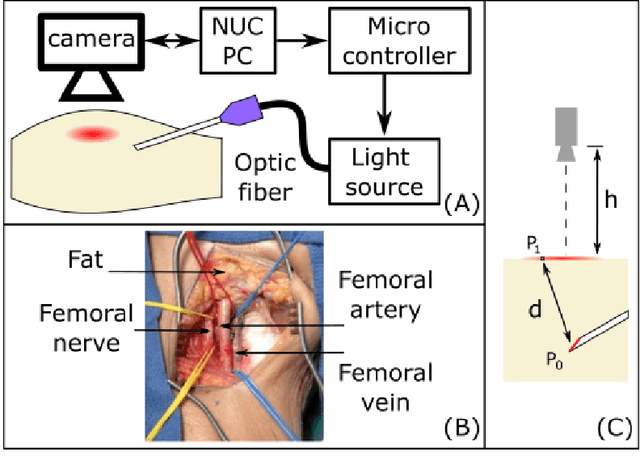
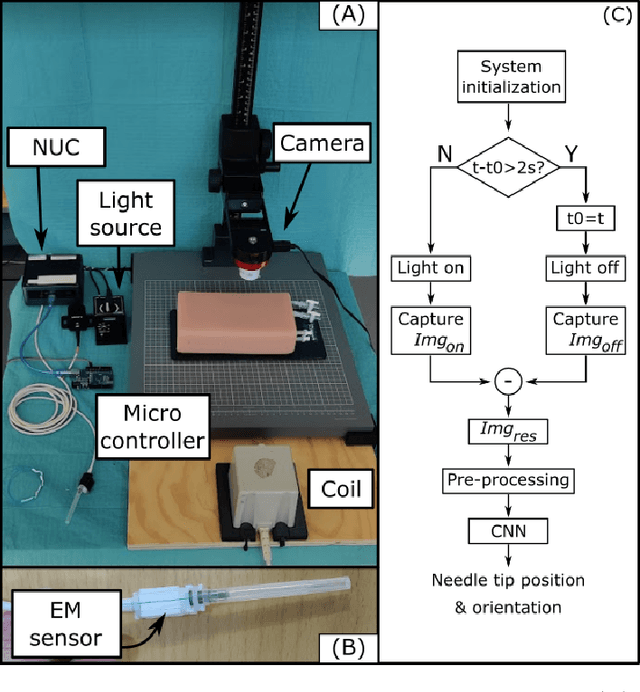
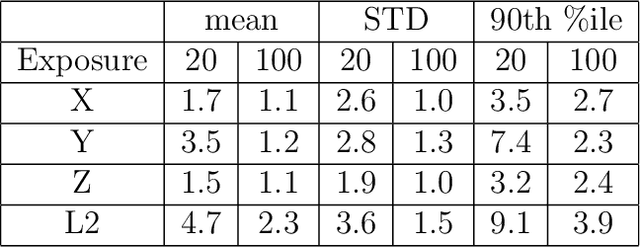
Deep needle insertion to a target often poses a huge challenge, requiring a combination of specialized skills, assistive technology, and extensive training. One of the frequently encountered medical scenarios demanding such expertise includes the needle insertion into a femoral vessel in the groin. After the access to the femoral vessel, various medical procedures, such as cardiac catheterization and extracorporeal membrane oxygenation (ECMO) can be performed. However, even with the aid of Ultrasound imaging, achieving successful insertion can necessitate multiple attempts due to the complexities of anatomy and tissue deformation. To address this challenge, this paper presents an innovative technology for needle tip real-time tracking, aiming for enhanced needle insertion guidance. Specifically, our approach revolves around the creation of scattering imaging using an optical fiber-equipped needle, and uses Convolutional Neural Network (CNN) based algorithms to enable real-time estimation of the needle tip's position and orientation during insertion procedures. The efficacy of the proposed technology was rigorously evaluated through three experiments. The first two experiments involved rubber and bacon phantoms to simulate groin anatomy. The positional errors averaging 2.3+1.5mm and 2.0+1.2mm, and the orientation errors averaging 0.2+0.11rad and 0.16+0.1rad. Furthermore, the system's capabilities were validated through experiments conducted on fresh porcine phantom mimicking more complex anatomical structures, yielding positional accuracy results of 3.2+3.1mm and orientational accuracy of 0.19+0.1rad. Given the average femoral arterial radius of 4 to 5mm, the proposed system is demonstrated with a great potential for precise needle guidance in femoral artery insertion procedures. In addition, the findings highlight the broader potential applications of the system in the medical field.
SciRE-Solver: Efficient Sampling of Diffusion Probabilistic Models by Score-integrand Solver with Recursive Derivative Estimation
Aug 15, 2023
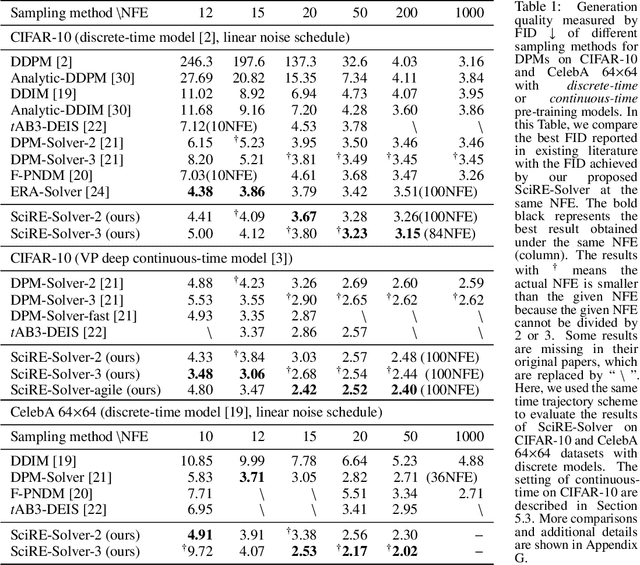
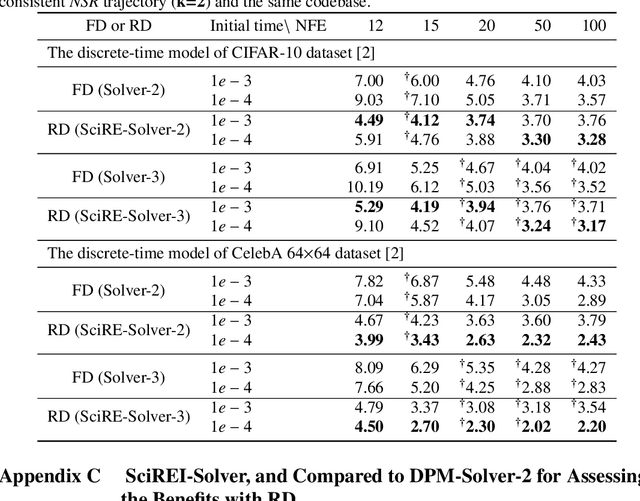
Diffusion probabilistic models (DPMs) are a powerful class of generative models known for their ability to generate high-fidelity image samples. A major challenge in the implementation of DPMs is the slow sampling process. In this work, we bring a high-efficiency sampler for DPMs. Specifically, we propose a score-based exact solution paradigm for the diffusion ODEs corresponding to the sampling process of DPMs, which introduces a new perspective on developing numerical algorithms for solving diffusion ODEs. To achieve an efficient sampler, we propose a recursive derivative estimation (RDE) method to reduce the estimation error. With our proposed solution paradigm and RDE method, we propose the score-integrand solver with the convergence order guarantee as efficient solver (SciRE-Solver) for solving diffusion ODEs. The SciRE-Solver attains state-of-the-art (SOTA) sampling performance with a limited number of score function evaluations (NFE) on both discrete-time and continuous-time DPMs in comparison to existing training-free sampling algorithms. Such as, we achieve $3.48$ FID with $12$ NFE and $2.42$ FID with $20$ NFE for continuous-time DPMs on CIFAR10, respectively. Different from other samplers, SciRE-Solver has the promising potential to surpass the FIDs achieved in the original papers of some pre-trained models with just fewer NFEs. For example, we reach SOTA value of $2.40$ FID with $100$ NFE for continuous-time DPM and of $3.15$ FID with $84$ NFE for discrete-time DPM on CIFAR-10, as well as of $2.17$ ($2.02$) FID with $18$ ($50$) NFE for discrete-time DPM on CelebA 64$\times$64.
Fast Feedforward Networks
Aug 28, 2023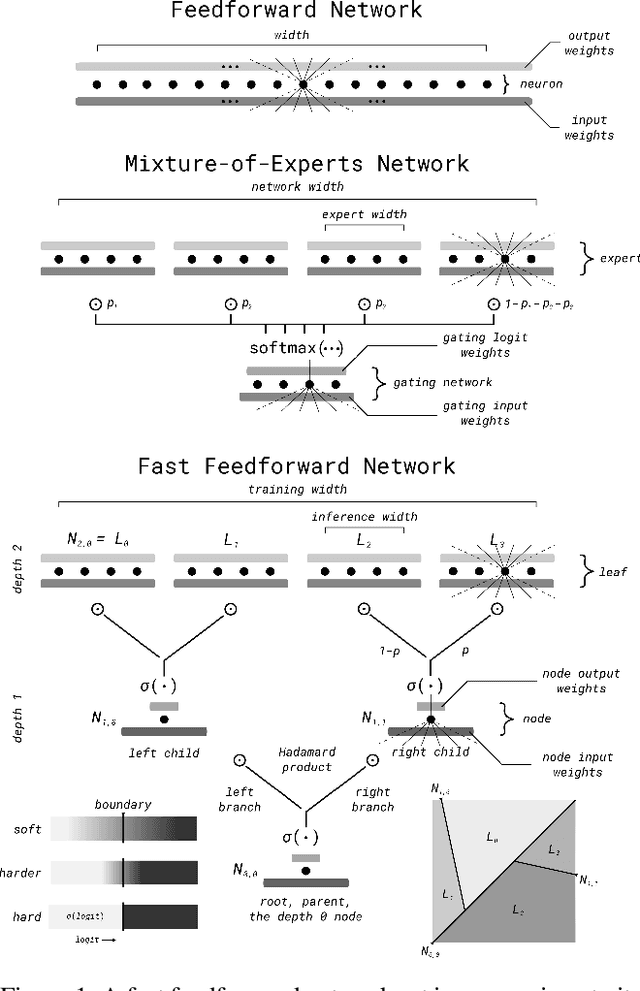
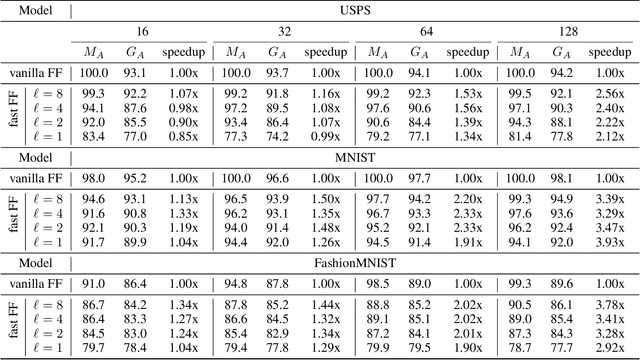
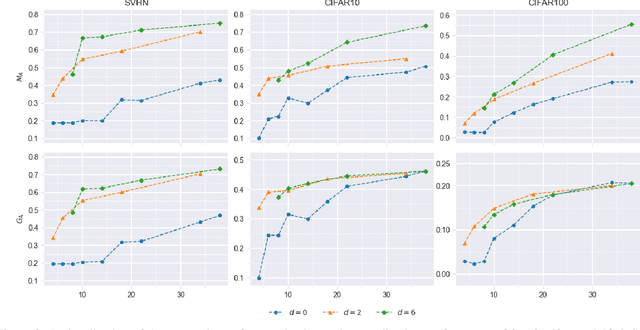
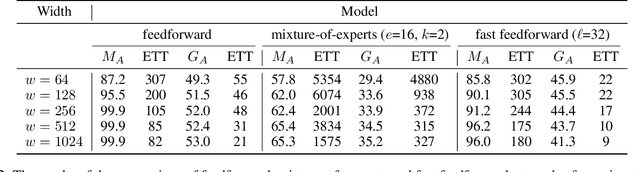
We break the linear link between the layer size and its inference cost by introducing the fast feedforward (FFF) architecture, a logarithmic-time alternative to feedforward networks. We show that FFFs give comparable performance to feedforward networks at an exponential fraction of their inference cost, are quicker to deliver performance compared to mixture-of-expert networks, and can readily take the place of either in transformers. Pushing FFFs to the absolute limit, we train a vision transformer to perform single-neuron inferences at the cost of only 5.8% performance decrease against the full-width variant. Our implementation is available as a Python package; just use "pip install fastfeedforward".
TFBEST: Dual-Aspect Transformer with Learnable Positional Encoding for Failure Prediction
Sep 06, 2023
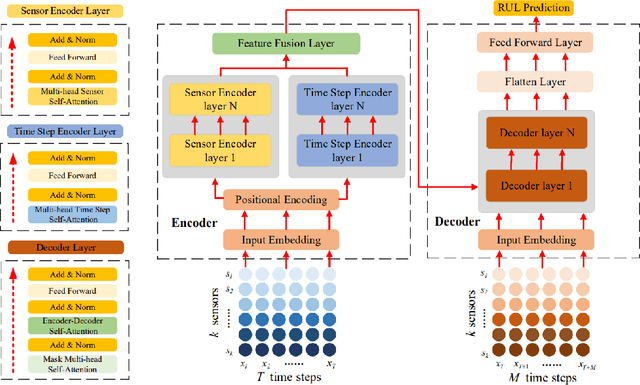
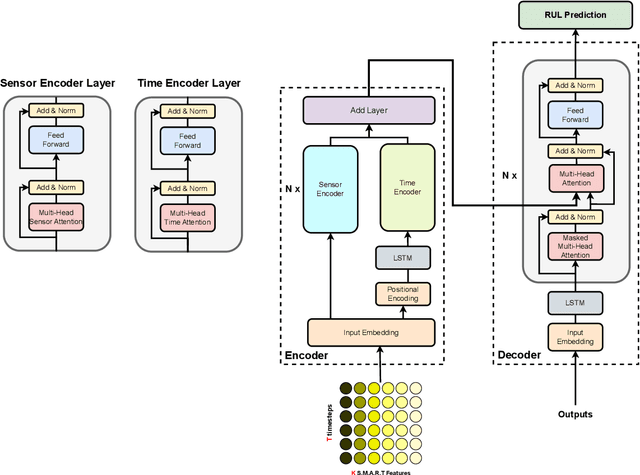
Hard Disk Drive (HDD) failures in datacenters are costly - from catastrophic data loss to a question of goodwill, stakeholders want to avoid it like the plague. An important tool in proactively monitoring against HDD failure is timely estimation of the Remaining Useful Life (RUL). To this end, the Self-Monitoring, Analysis and Reporting Technology employed within HDDs (S.M.A.R.T.) provide critical logs for long-term maintenance of the security and dependability of these essential data storage devices. Data-driven predictive models in the past have used these S.M.A.R.T. logs and CNN/RNN based architectures heavily. However, they have suffered significantly in providing a confidence interval around the predicted RUL values as well as in processing very long sequences of logs. In addition, some of these approaches, such as those based on LSTMs, are inherently slow to train and have tedious feature engineering overheads. To overcome these challenges, in this work we propose a novel transformer architecture - a Temporal-fusion Bi-encoder Self-attention Transformer (TFBEST) for predicting failures in hard-drives. It is an encoder-decoder based deep learning technique that enhances the context gained from understanding health statistics sequences and predicts a sequence of the number of days remaining before a disk potentially fails. In this paper, we also provide a novel confidence margin statistic that can help manufacturers replace a hard-drive within a time frame. Experiments on Seagate HDD data show that our method significantly outperforms the state-of-the-art RUL prediction methods during testing over the exhaustive 10-year data from Backblaze (2013-present). Although validated on HDD failure prediction, the TFBEST architecture is well-suited for other prognostics applications and may be adapted for allied regression problems.
Mitigating Motion Blur for Robust 3D Baseball Player Pose Modeling for Pitch Analysis
Sep 02, 2023

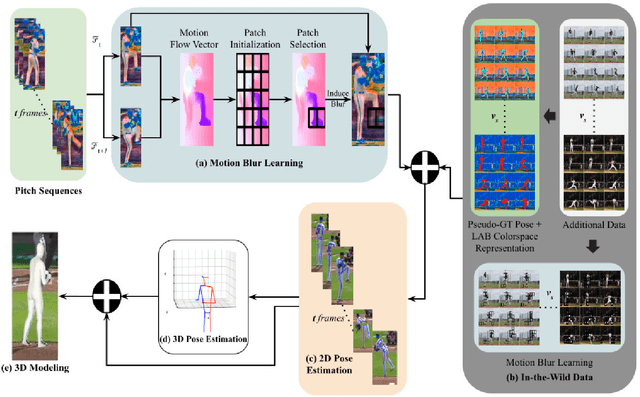

Using videos to analyze pitchers in baseball can play a vital role in strategizing and injury prevention. Computer vision-based pose analysis offers a time-efficient and cost-effective approach. However, the use of accessible broadcast videos, with a 30fps framerate, often results in partial body motion blur during fast actions, limiting the performance of existing pose keypoint estimation models. Previous works have primarily relied on fixed backgrounds, assuming minimal motion differences between frames, or utilized multiview data to address this problem. To this end, we propose a synthetic data augmentation pipeline to enhance the model's capability to deal with the pitcher's blurry actions. In addition, we leverage in-the-wild videos to make our model robust under different real-world conditions and camera positions. By carefully optimizing the augmentation parameters, we observed a notable reduction in the loss by 54.2% and 36.2% on the test dataset for 2D and 3D pose estimation respectively. By applying our approach to existing state-of-the-art pose estimators, we demonstrate an average improvement of 29.2%. The findings highlight the effectiveness of our method in mitigating the challenges posed by motion blur, thereby enhancing the overall quality of pose estimation.
A Multilayer Perceptron-based Fast Sunlight Assessment for the Conceptual Design of Residential Neighborhoods under Chinese Policy
Aug 15, 2023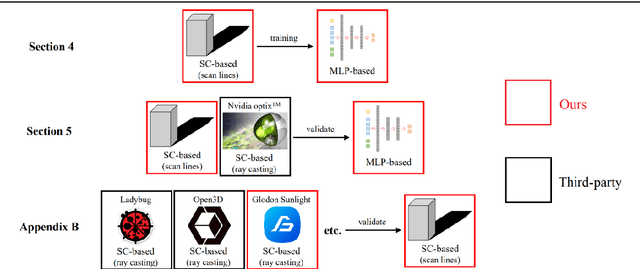
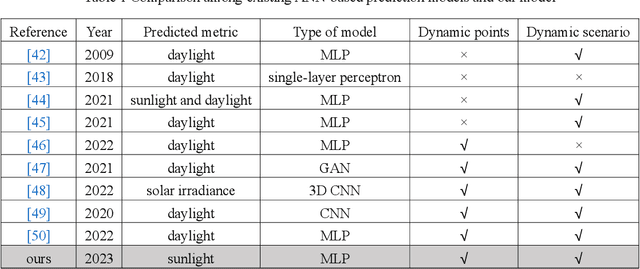
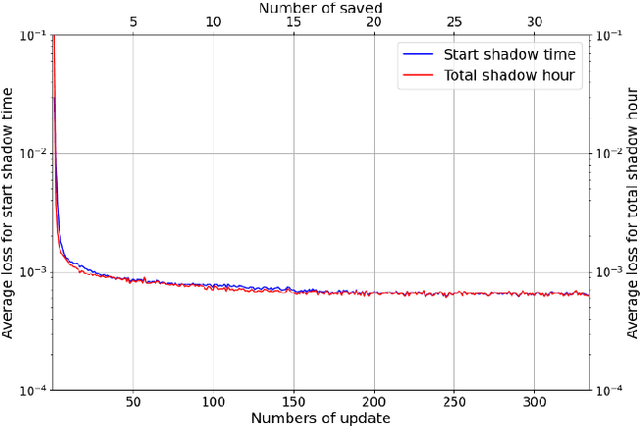

In Chinese building codes, it is required that residential buildings receive a minimum number of hours of natural, direct sunlight on a specified winter day, which represents the worst sunlight condition in a year. This requirement is a prerequisite for obtaining a building permit during the conceptual design of a residential project. Thus, officially sanctioned software is usually used to assess the sunlight performance of buildings. These software programs predict sunlight hours based on repeated shading calculations, which is time-consuming. This paper proposed a multilayer perceptron-based method, a one-stage prediction approach, which outputs a shading time interval caused by the inputted cuboid-form building. The sunlight hours of a site can be obtained by calculating the union of the sunlight time intervals (complement of shading time interval) of all the buildings. Three numerical experiments, i.e., horizontal level and slope analysis, and simulation-based optimization are carried out; the results show that the method reduces the computation time to 1/84~1/50 with 96.5%~98% accuracies. A residential neighborhood layout planning plug-in for Rhino 7/Grasshopper is also developed based on the proposed model. This paper indicates that deep learning techniques can be adopted to accelerate sunlight hour simulations at the conceptual design phase.