 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
LEGO: Learning and Graph-Optimized Modular Tracker for Online Multi-Object Tracking with Point Clouds
Aug 19, 2023
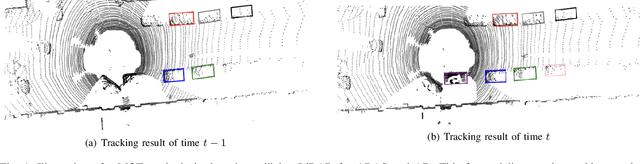
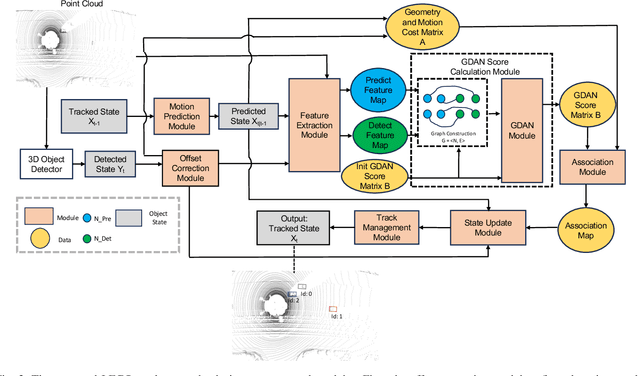
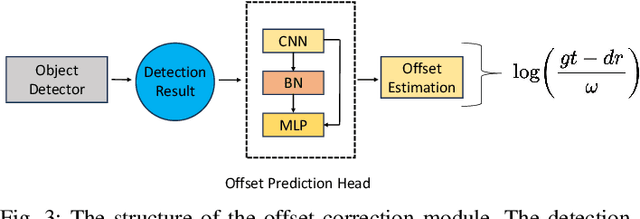
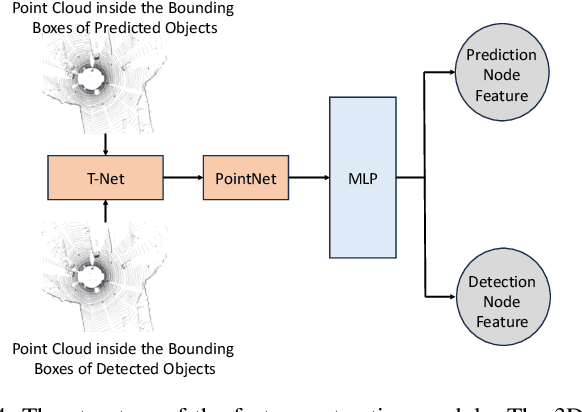
Online multi-object tracking (MOT) plays a pivotal role in autonomous systems. The state-of-the-art approaches usually employ a tracking-by-detection method, and data association plays a critical role. This paper proposes a learning and graph-optimized (LEGO) modular tracker to improve data association performance in the existing literature. The proposed LEGO tracker integrates graph optimization and self-attention mechanisms, which efficiently formulate the association score map, facilitating the accurate and efficient matching of objects across time frames. To further enhance the state update process, the Kalman filter is added to ensure consistent tracking by incorporating temporal coherence in the object states. Our proposed method utilizing LiDAR alone has shown exceptional performance compared to other online tracking approaches, including LiDAR-based and LiDAR-camera fusion-based methods. LEGO ranked 1st at the time of submitting results to KITTI object tracking evaluation ranking board and remains 2nd at the time of submitting this paper, among all online trackers in the KITTI MOT benchmark for cars1
Motion Perceiver: Real-Time Occupancy Forecasting for Embedded Systems
Jun 15, 2023
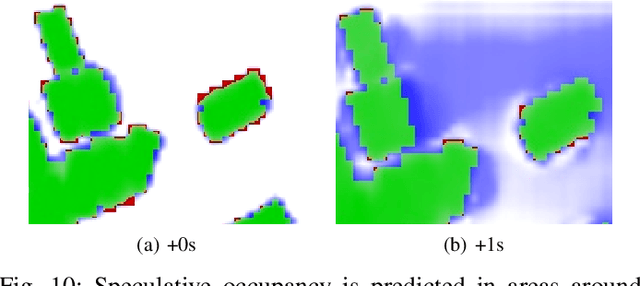
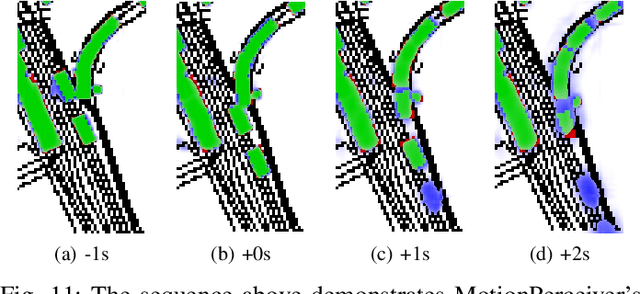
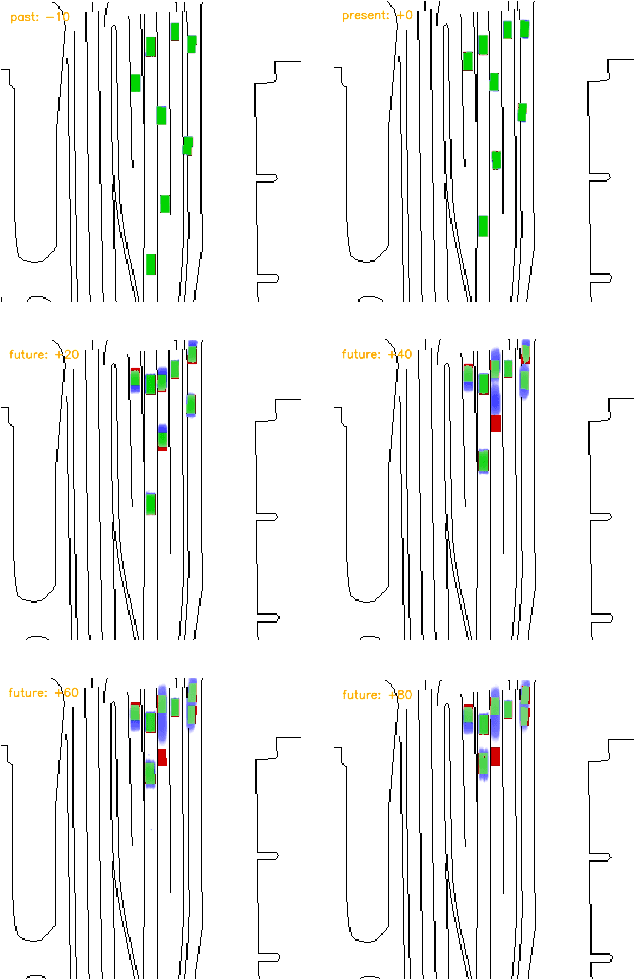
This work introduces a flexible architecture for real-time occupancy forecasting. In contrast to existing, more computationally expensive architectures, the proposed model exploits recursive latent state estimation, using learned transformer-based prediction and update modules. This allows for highly efficient real-time inference on an embedded system (profiled on an Nvidia Xavier AGX), and the inclusion of a broad set of information from a diverse set of sensors. The architecture is able to process sparse and occluded observations of agent positions and scene context as this is made available, and does not require motion tracklet inputs. \networkName{} accomplishes this by encoding the scene into a latent state that evolves in time with self-attention and is updated with contextual information such as traffic signals, road topology or agent detections using cross-attention. Occupancy predictions are made by sparsely querying positions of interest as opposed to generating a fixed size raster image, which allows for variable resolution occupancy prediction or local querying by downstream trajectory optimisation algorithms, saving computational effort.
Machine Learning for Real-Time Anomaly Detection in Optical Networks
Jun 19, 2023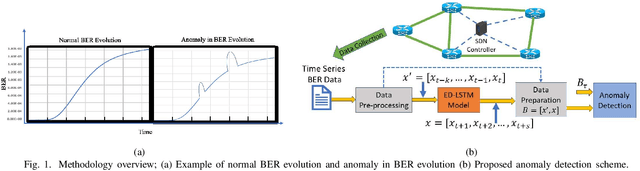
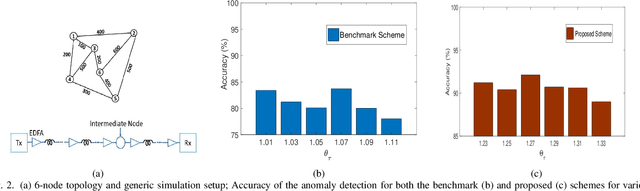
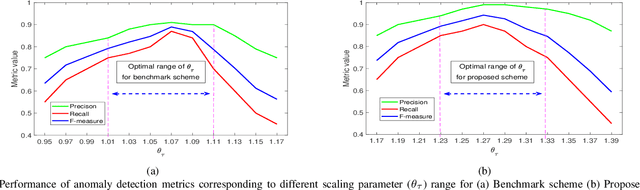
This work proposes a real-time anomaly detection scheme that leverages the multi-step ahead prediction capabilities of encoder-decoder (ED) deep learning models with recurrent units. Specifically, an encoder-decoder is used to model soft-failure evolution over a long future horizon (i.e., for several days ahead) by analyzing past quality-of-transmission (QoT) observations. This information is subsequently used for real-time anomaly detection (e.g., of attack incidents), as the knowledge of how the QoT is expected to evolve allows capturing unexpected network behavior. Specifically, for anomaly detection, a statistical hypothesis testing scheme is used, alleviating the limitations of supervised (SL) and unsupervised learning (UL) schemes, usually applied for this purpose. Indicatively, the proposed scheme eliminates the need for labeled anomalies, required when SL is applied, and the need for on-line analyzing entire datasets to identify abnormal instances (i.e., UL). Overall, it is shown that by utilizing QoT evolution information, the proposed approach can effectively detect abnormal deviations in real-time. Importantly, it is shown that the information concerning soft-failure evolution (i.e., QoT predictions) is essential to accurately detect anomalies.
Stabilizing RNN Gradients through Pre-training
Aug 23, 2023Numerous theories of learning suggest to prevent the gradient variance from exponential growth with depth or time, to stabilize and improve training. Typically, these analyses are conducted on feed-forward fully-connected neural networks or single-layer recurrent neural networks, given their mathematical tractability. In contrast, this study demonstrates that pre-training the network to local stability can be effective whenever the architectures are too complex for an analytical initialization. Furthermore, we extend known stability theories to encompass a broader family of deep recurrent networks, requiring minimal assumptions on data and parameter distribution, a theory that we refer to as the Local Stability Condition (LSC). Our investigation reveals that the classical Glorot, He, and Orthogonal initialization schemes satisfy the LSC when applied to feed-forward fully-connected neural networks. However, analysing deep recurrent networks, we identify a new additive source of exponential explosion that emerges from counting gradient paths in a rectangular grid in depth and time. We propose a new approach to mitigate this issue, that consists on giving a weight of a half to the time and depth contributions to the gradient, instead of the classical weight of one. Our empirical results confirm that pre-training both feed-forward and recurrent networks to fulfill the LSC often results in improved final performance across models. This study contributes to the field by providing a means to stabilize networks of any complexity. Our approach can be implemented as an additional step before pre-training on large augmented datasets, and as an alternative to finding stable initializations analytically.
Real Robot Challenge 2022: Learning Dexterous Manipulation from Offline Data in the Real World
Sep 04, 2023
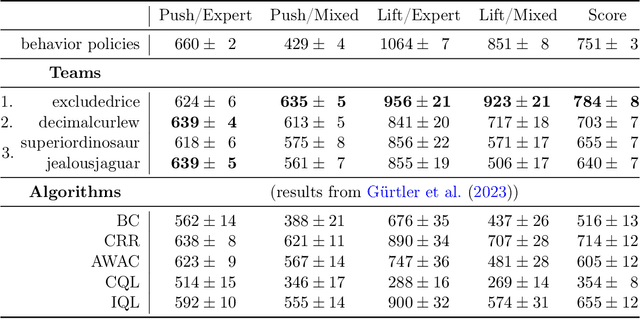
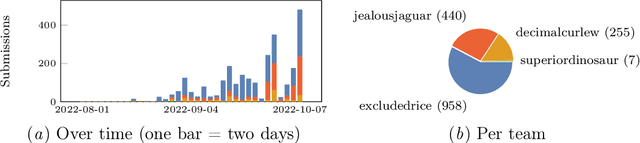
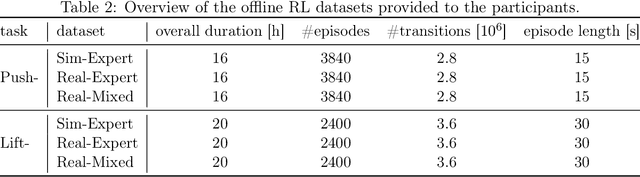
Experimentation on real robots is demanding in terms of time and costs. For this reason, a large part of the reinforcement learning (RL) community uses simulators to develop and benchmark algorithms. However, insights gained in simulation do not necessarily translate to real robots, in particular for tasks involving complex interactions with the environment. The Real Robot Challenge 2022 therefore served as a bridge between the RL and robotics communities by allowing participants to experiment remotely with a real robot - as easily as in simulation. In the last years, offline reinforcement learning has matured into a promising paradigm for learning from pre-collected datasets, alleviating the reliance on expensive online interactions. We therefore asked the participants to learn two dexterous manipulation tasks involving pushing, grasping, and in-hand orientation from provided real-robot datasets. An extensive software documentation and an initial stage based on a simulation of the real set-up made the competition particularly accessible. By giving each team plenty of access budget to evaluate their offline-learned policies on a cluster of seven identical real TriFinger platforms, we organized an exciting competition for machine learners and roboticists alike. In this work we state the rules of the competition, present the methods used by the winning teams and compare their results with a benchmark of state-of-the-art offline RL algorithms on the challenge datasets.
Prompting or Fine-tuning? A Comparative Study of Large Language Models for Taxonomy Construction
Sep 04, 2023Taxonomies represent hierarchical relations between entities, frequently applied in various software modeling and natural language processing (NLP) activities. They are typically subject to a set of structural constraints restricting their content. However, manual taxonomy construction can be time-consuming, incomplete, and costly to maintain. Recent studies of large language models (LLMs) have demonstrated that appropriate user inputs (called prompting) can effectively guide LLMs, such as GPT-3, in diverse NLP tasks without explicit (re-)training. However, existing approaches for automated taxonomy construction typically involve fine-tuning a language model by adjusting model parameters. In this paper, we present a general framework for taxonomy construction that takes into account structural constraints. We subsequently conduct a systematic comparison between the prompting and fine-tuning approaches performed on a hypernym taxonomy and a novel computer science taxonomy dataset. Our result reveals the following: (1) Even without explicit training on the dataset, the prompting approach outperforms fine-tuning-based approaches. Moreover, the performance gap between prompting and fine-tuning widens when the training dataset is small. However, (2) taxonomies generated by the fine-tuning approach can be easily post-processed to satisfy all the constraints, whereas handling violations of the taxonomies produced by the prompting approach can be challenging. These evaluation findings provide guidance on selecting the appropriate method for taxonomy construction and highlight potential enhancements for both approaches.
Accuracy and Consistency of Space-based Vegetation Height Maps for Forest Dynamics in Alpine Terrain
Sep 04, 2023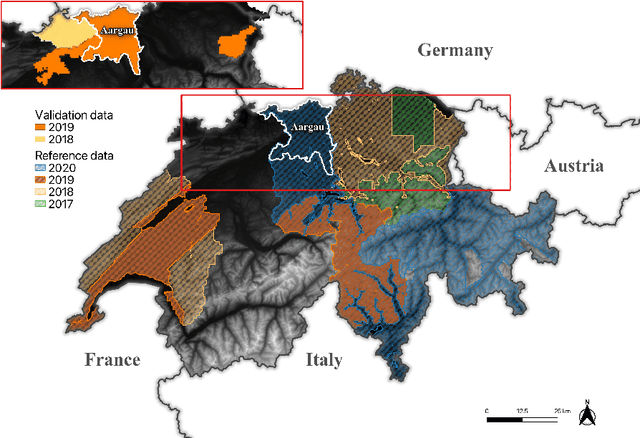
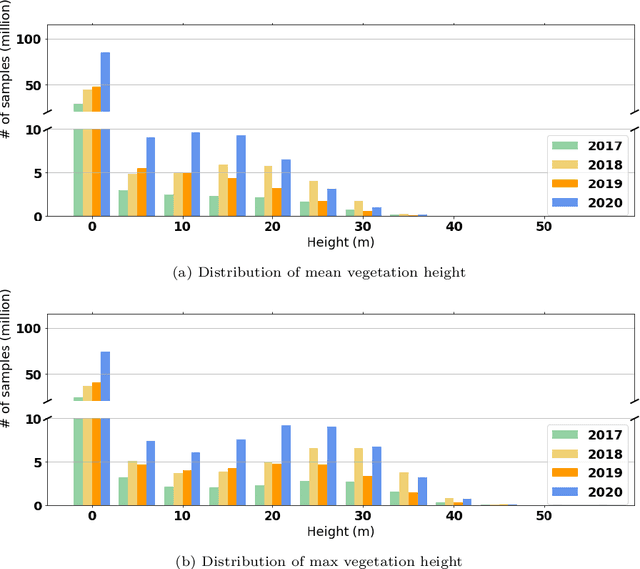

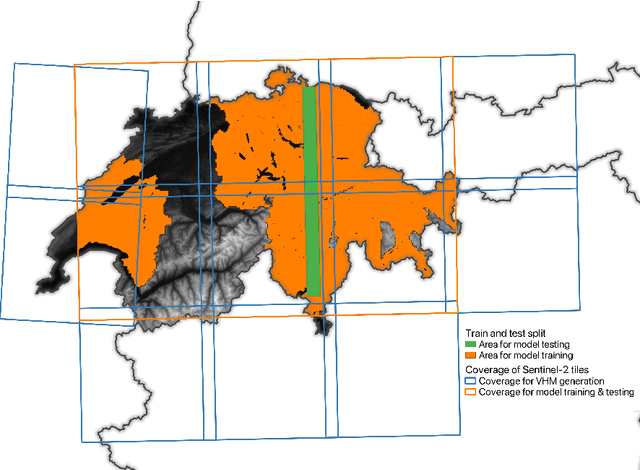
Monitoring and understanding forest dynamics is essential for environmental conservation and management. This is why the Swiss National Forest Inventory (NFI) provides countrywide vegetation height maps at a spatial resolution of 0.5 m. Its long update time of 6 years, however, limits the temporal analysis of forest dynamics. This can be improved by using spaceborne remote sensing and deep learning to generate large-scale vegetation height maps in a cost-effective way. In this paper, we present an in-depth analysis of these methods for operational application in Switzerland. We generate annual, countrywide vegetation height maps at a 10-meter ground sampling distance for the years 2017 to 2020 based on Sentinel-2 satellite imagery. In comparison to previous works, we conduct a large-scale and detailed stratified analysis against a precise Airborne Laser Scanning reference dataset. This stratified analysis reveals a close relationship between the model accuracy and the topology, especially slope and aspect. We assess the potential of deep learning-derived height maps for change detection and find that these maps can indicate changes as small as 250 $m^2$. Larger-scale changes caused by a winter storm are detected with an F1-score of 0.77. Our results demonstrate that vegetation height maps computed from satellite imagery with deep learning are a valuable, complementary, cost-effective source of evidence to increase the temporal resolution for national forest assessments.
SSVOD: Semi-Supervised Video Object Detection with Sparse Annotations
Sep 04, 2023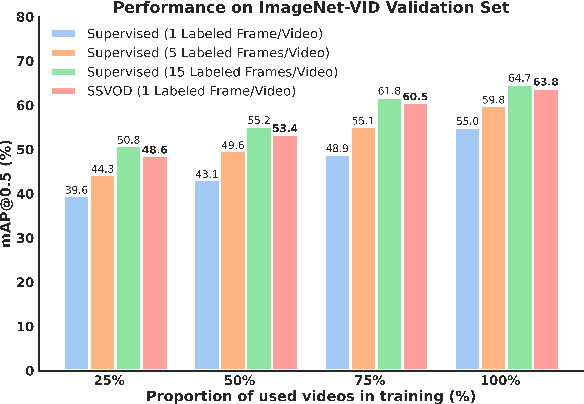
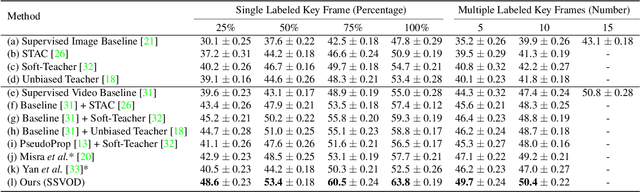
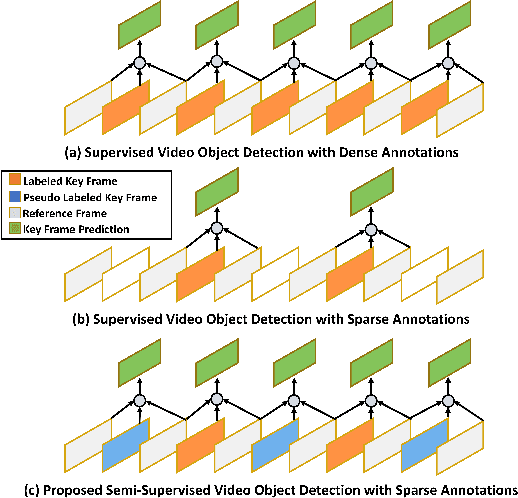
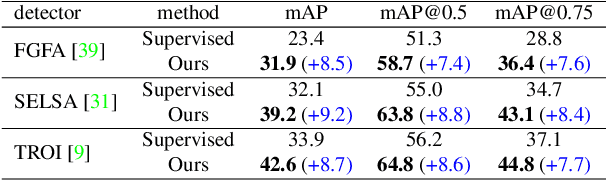
Despite significant progress in semi-supervised learning for image object detection, several key issues are yet to be addressed for video object detection: (1) Achieving good performance for supervised video object detection greatly depends on the availability of annotated frames. (2) Despite having large inter-frame correlations in a video, collecting annotations for a large number of frames per video is expensive, time-consuming, and often redundant. (3) Existing semi-supervised techniques on static images can hardly exploit the temporal motion dynamics inherently present in videos. In this paper, we introduce SSVOD, an end-to-end semi-supervised video object detection framework that exploits motion dynamics of videos to utilize large-scale unlabeled frames with sparse annotations. To selectively assemble robust pseudo-labels across groups of frames, we introduce \textit{flow-warped predictions} from nearby frames for temporal-consistency estimation. In particular, we introduce cross-IoU and cross-divergence based selection methods over a set of estimated predictions to include robust pseudo-labels for bounding boxes and class labels, respectively. To strike a balance between confirmation bias and uncertainty noise in pseudo-labels, we propose confidence threshold based combination of hard and soft pseudo-labels. Our method achieves significant performance improvements over existing methods on ImageNet-VID, Epic-KITCHENS, and YouTube-VIS datasets. Code and pre-trained models will be released.
DCdetector: Dual Attention Contrastive Representation Learning for Time Series Anomaly Detection
Jun 17, 2023
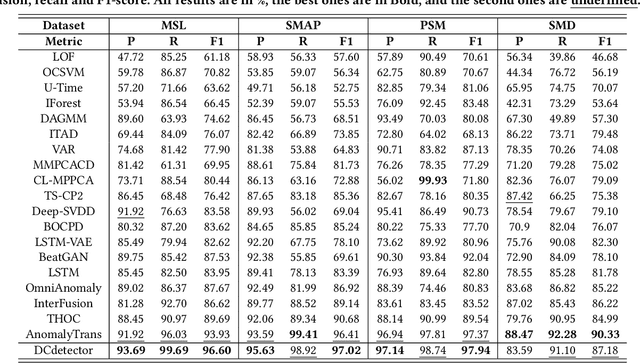
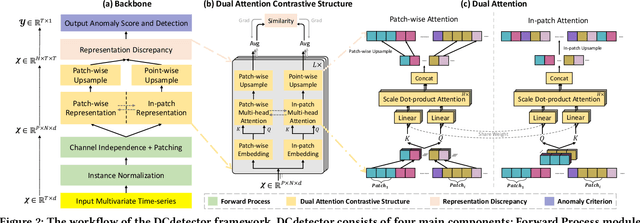
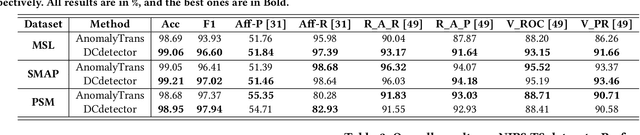
Time series anomaly detection is critical for a wide range of applications. It aims to identify deviant samples from the normal sample distribution in time series. The most fundamental challenge for this task is to learn a representation map that enables effective discrimination of anomalies. Reconstruction-based methods still dominate, but the representation learning with anomalies might hurt the performance with its large abnormal loss. On the other hand, contrastive learning aims to find a representation that can clearly distinguish any instance from the others, which can bring a more natural and promising representation for time series anomaly detection. In this paper, we propose DCdetector, a multi-scale dual attention contrastive representation learning model. DCdetector utilizes a novel dual attention asymmetric design to create the permutated environment and pure contrastive loss to guide the learning process, thus learning a permutation invariant representation with superior discrimination abilities. Extensive experiments show that DCdetector achieves state-of-the-art results on multiple time series anomaly detection benchmark datasets. Code is publicly available at https://github.com/DAMO-DI-ML/KDD2023-DCdetector.
ICU Mortality Prediction Using Long Short-Term Memory Networks
Aug 18, 2023Extensive bedside monitoring in Intensive Care Units (ICUs) has resulted in complex temporal data regarding patient physiology, which presents an upscale context for clinical data analysis. In the other hand, identifying the time-series patterns within these data may provide a high aptitude to predict clinical events. Hence, we investigate, during this work, the implementation of an automatic data-driven system, which analyzes large amounts of multivariate temporal data derived from Electronic Health Records (EHRs), and extracts high-level information so as to predict in-hospital mortality and Length of Stay (LOS) early. Practically, we investigate the applicability of LSTM network by reducing the time-frame to 6-hour so as to enhance clinical tasks. The experimental results highlight the efficiency of LSTM model with rigorous multivariate time-series measurements for building real-world prediction engines.