 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
SATAY: A Streaming Architecture Toolflow for Accelerating YOLO Models on FPGA Devices
Sep 04, 2023
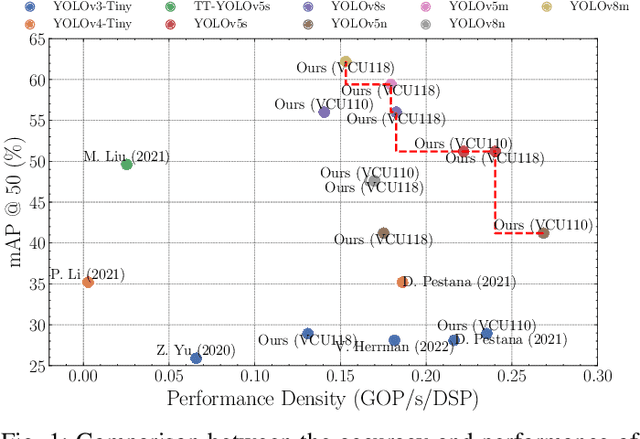
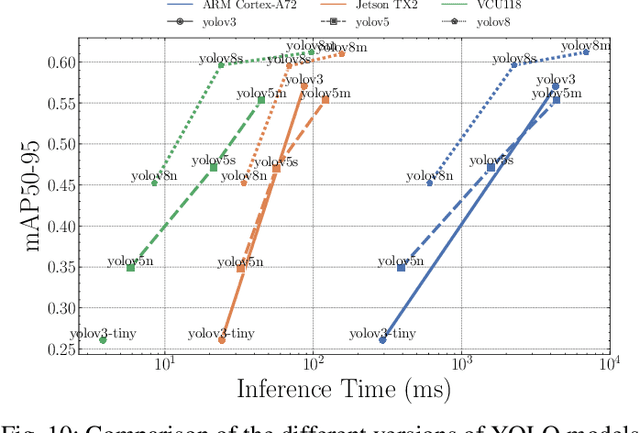
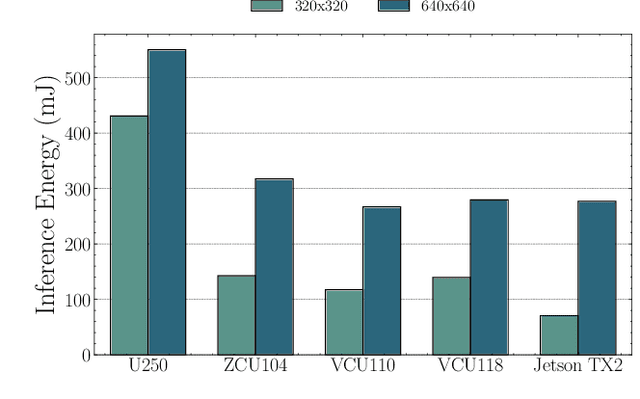
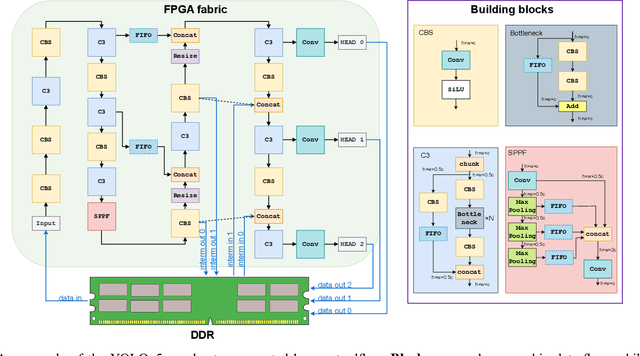
AI has led to significant advancements in computer vision and image processing tasks, enabling a wide range of applications in real-life scenarios, from autonomous vehicles to medical imaging. Many of those applications require efficient object detection algorithms and complementary real-time, low latency hardware to perform inference of these algorithms. The YOLO family of models is considered the most efficient for object detection, having only a single model pass. Despite this, the complexity and size of YOLO models can be too computationally demanding for current edge-based platforms. To address this, we present SATAY: a Streaming Architecture Toolflow for Accelerating YOLO. This work tackles the challenges of deploying stateof-the-art object detection models onto FPGA devices for ultralow latency applications, enabling real-time, edge-based object detection. We employ a streaming architecture design for our YOLO accelerators, implementing the complete model on-chip in a deeply pipelined fashion. These accelerators are generated using an automated toolflow, and can target a range of suitable FPGA devices. We introduce novel hardware components to support the operations of YOLO models in a dataflow manner, and off-chip memory buffering to address the limited on-chip memory resources. Our toolflow is able to generate accelerator designs which demonstrate competitive performance and energy characteristics to GPU devices, and which outperform current state-of-the-art FPGA accelerators.
Adapting Classifiers To Changing Class Priors During Deployment
Sep 04, 2023Conventional classifiers are trained and evaluated using balanced data sets in which all classes are equally present. Classifiers are now trained on large data sets such as ImageNet, and are now able to classify hundreds (if not thousands) of different classes. On one hand, it is desirable to train such general-purpose classifier on a very large number of classes so that it performs well regardless of the settings in which it is deployed. On the other hand, it is unlikely that all classes known to the classifier will occur in every deployment scenario, or that they will occur with the same prior probability. In reality, only a relatively small subset of the known classes may be present in a particular setting or environment. For example, a classifier will encounter mostly animals if its deployed in a zoo or for monitoring wildlife, aircraft and service vehicles at an airport, or various types of automobiles and commercial vehicles if it is used for monitoring traffic. Furthermore, the exact class priors are generally unknown and can vary over time. In this paper, we explore different methods for estimating the class priors based on the output of the classifier itself. We then show that incorporating the estimated class priors in the overall decision scheme enables the classifier to increase its run-time accuracy in the context of its deployment scenario.
STUPD: A Synthetic Dataset for Spatial and Temporal Relation Reasoning
Sep 13, 2023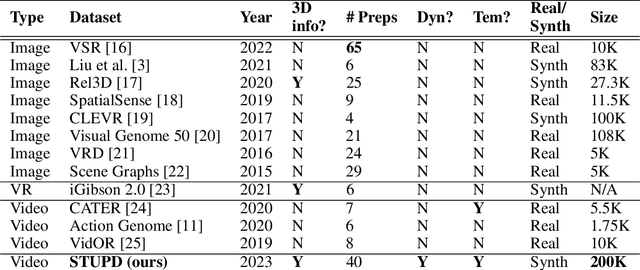

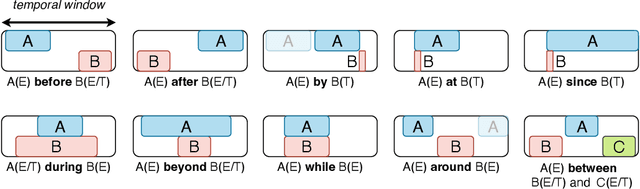
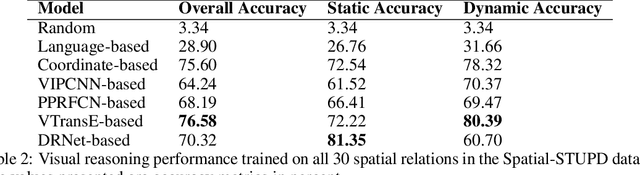
Understanding relations between objects is crucial for understanding the semantics of a visual scene. It is also an essential step in order to bridge visual and language models. However, current state-of-the-art computer vision models still lack the ability to perform spatial reasoning well. Existing datasets mostly cover a relatively small number of spatial relations, all of which are static relations that do not intrinsically involve motion. In this paper, we propose the Spatial and Temporal Understanding of Prepositions Dataset (STUPD) -- a large-scale video dataset for understanding static and dynamic spatial relationships derived from prepositions of the English language. The dataset contains 150K visual depictions (videos and images), consisting of 30 distinct spatial prepositional senses, in the form of object interaction simulations generated synthetically using Unity3D. In addition to spatial relations, we also propose 50K visual depictions across 10 temporal relations, consisting of videos depicting event/time-point interactions. To our knowledge, no dataset exists that represents temporal relations through visual settings. In this dataset, we also provide 3D information about object interactions such as frame-wise coordinates, and descriptions of the objects used. The goal of this synthetic dataset is to help models perform better in visual relationship detection in real-world settings. We demonstrate an increase in the performance of various models over 2 real-world datasets (ImageNet-VidVRD and Spatial Senses) when pretrained on the STUPD dataset, in comparison to other pretraining datasets.
Mutation-based Fault Localization of Deep Neural Networks
Sep 10, 2023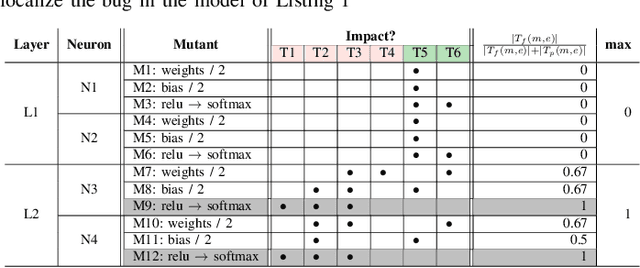
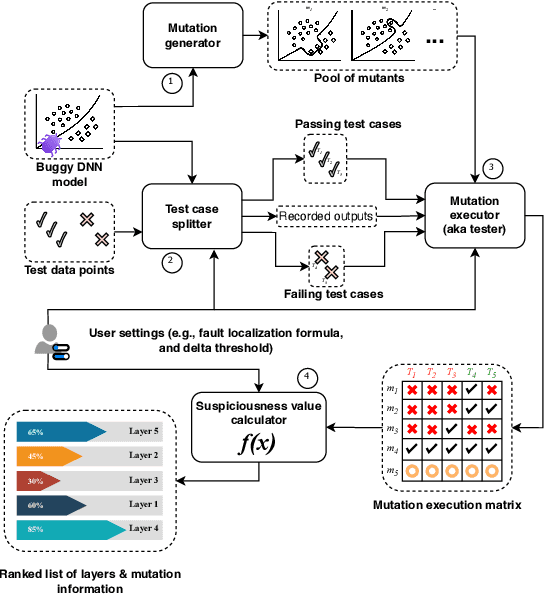
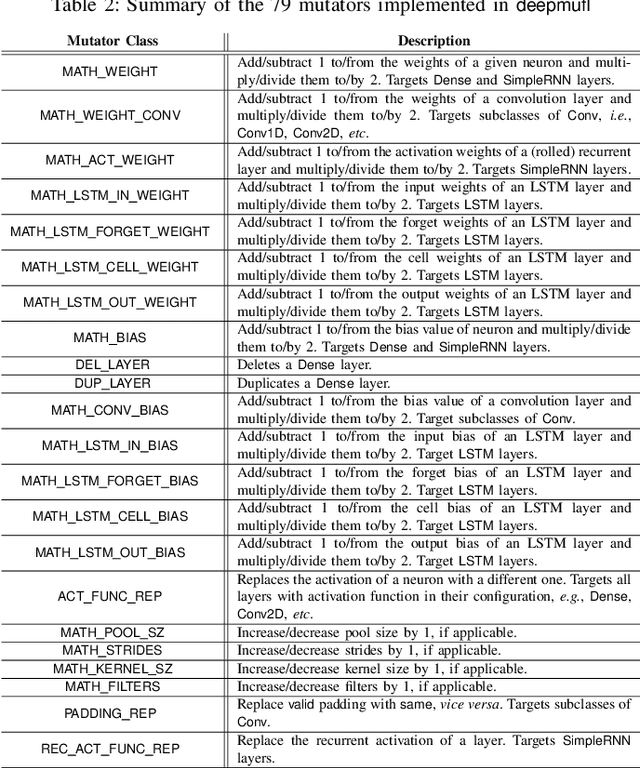
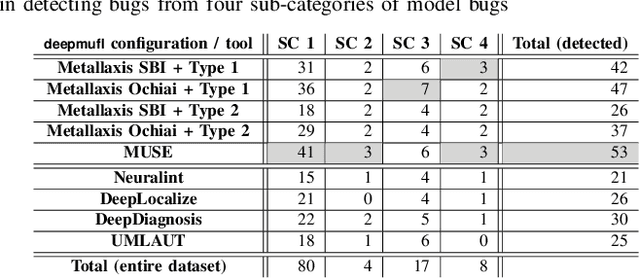
Deep neural networks (DNNs) are susceptible to bugs, just like other types of software systems. A significant uptick in using DNN, and its applications in wide-ranging areas, including safety-critical systems, warrant extensive research on software engineering tools for improving the reliability of DNN-based systems. One such tool that has gained significant attention in the recent years is DNN fault localization. This paper revisits mutation-based fault localization in the context of DNN models and proposes a novel technique, named deepmufl, applicable to a wide range of DNN models. We have implemented deepmufl and have evaluated its effectiveness using 109 bugs obtained from StackOverflow. Our results show that deepmufl detects 53/109 of the bugs by ranking the buggy layer in top-1 position, outperforming state-of-the-art static and dynamic DNN fault localization systems that are also designed to target the class of bugs supported by deepmufl. Moreover, we observed that we can halve the fault localization time for a pre-trained model using mutation selection, yet losing only 7.55% of the bugs localized in top-1 position.
The online learning architecture with edge computing for high-level control for assisting patients
Sep 10, 2023
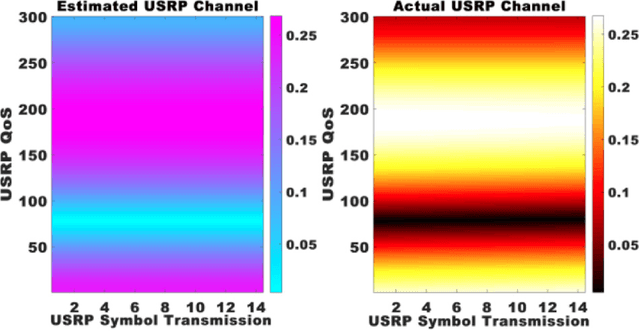
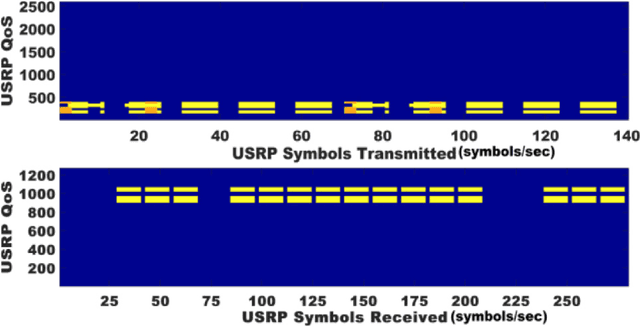
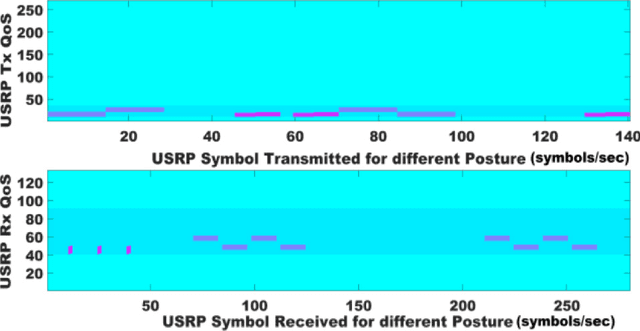
The prevalence of mobility impairments due to conditions such as spinal cord injuries, strokes, and degenerative diseases is on the rise globally. Lower-limb exoskeletons have been increasingly recognized as a viable solution for enhancing mobility and rehabilitation for individuals with such impairments. However, existing exoskeleton control systems often suffer from limitations such as latency, lack of adaptability, and computational inefficiency. To address these challenges, this paper introduces a novel online adversarial learning architecture integrated with edge computing for high-level lower-limb exoskeleton control. In the proposed architecture, sensor data from the user is processed in real-time through edge computing nodes, which then interact with an online adversarial learning model. This model adapts to the user's specific needs and controls the exoskeleton with minimal latency. Experimental evaluations demonstrate significant improvements in control accuracy and adaptability, as well as enhanced quality-of-service (QoS) metrics. These findings indicate that the integration of online adversarial learning with edge computing offers a robust and efficient approach for the next generation of lower-limb exoskeleton control systems.
Autoencoders for Real-Time SUEP Detection
Jun 26, 2023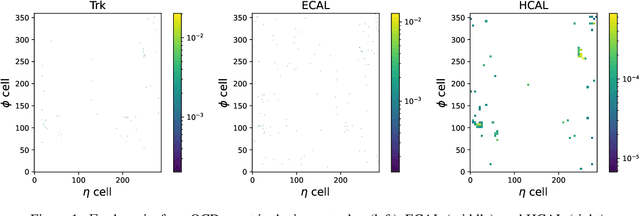
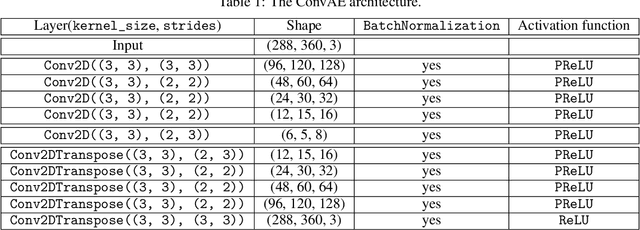
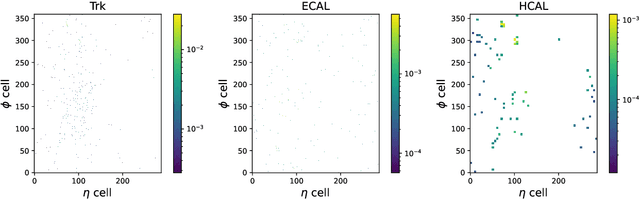
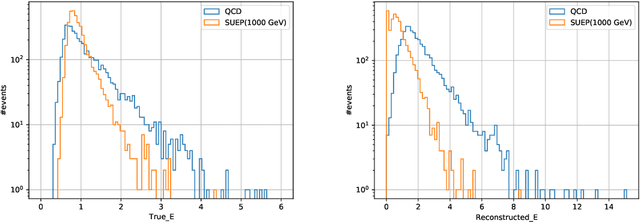
Confining dark sectors with pseudo-conformal dynamics can produce Soft Unclustered Energy Patterns, or SUEPs, at the Large Hadron Collider: the production of dark quarks in proton-proton collisions leading to a dark shower and the high-multiplicity production of dark hadrons. The final experimental signature is spherically-symmetric energy deposits by an anomalously large number of soft Standard Model particles with a transverse energy of a few hundred MeV. The dominant background for the SUEP search, if it gets produced via gluon-gluon fusion, is multi-jet QCD events. We have developed a deep learning-based Anomaly Detection technique to reject QCD jets and identify any anomalous signature, including SUEP, in real-time in the High-Level Trigger system of the Compact Muon Solenoid experiment at the Large Hadron Collider. A deep convolutional neural autoencoder network has been trained using QCD events by taking transverse energy deposits in the inner tracker, electromagnetic calorimeter, and hadron calorimeter sub-detectors as 3-channel image data. To tackle the biggest challenge of the task, due to the sparse nature of the data: only ~0.5% of the total ~300 k image pixels have non-zero values, a non-standard loss function, the inverse of the so-called Dice Loss, has been exploited. The trained autoencoder with learned spatial features of QCD jets can detect 40% of the SUEP events, with a QCD event mistagging rate as low as 2%. The model inference time has been measured using the Intel CoreTM i5-9600KF processor and found to be ~20 ms, which perfectly satisfies the High-Level Trigger system's latency of O(100) ms. Given the virtue of the unsupervised learning of the autoencoders, the trained model can be applied to any new physics model that predicts an experimental signature anomalous to QCD jets.
Toward Reproducing Network Research Results Using Large Language Models
Sep 09, 2023
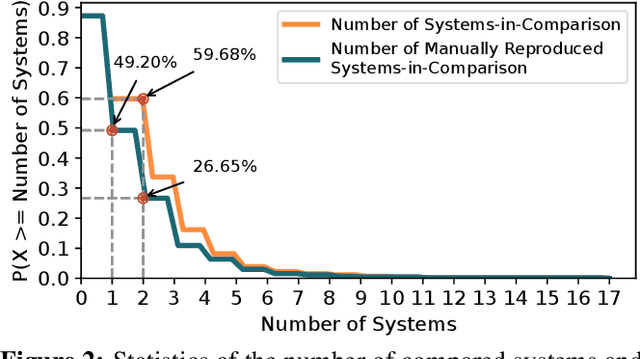

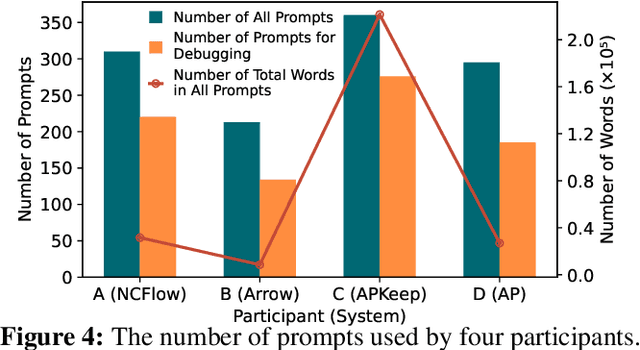
Reproducing research results in the networking community is important for both academia and industry. The current best practice typically resorts to three approaches: (1) looking for publicly available prototypes; (2) contacting the authors to get a private prototype; and (3) manually implementing a prototype following the description of the publication. However, most published network research does not have public prototypes and private prototypes are hard to get. As such, most reproducing efforts are spent on manual implementation based on the publications, which is both time and labor consuming and error-prone. In this paper, we boldly propose reproducing network research results using the emerging large language models (LLMs). In particular, we first prove its feasibility with a small-scale experiment, in which four students with essential networking knowledge each reproduces a different networking system published in prominent conferences and journals by prompt engineering ChatGPT. We report the experiment's observations and lessons and discuss future open research questions of this proposal. This work raises no ethical issue.
AmbientFlow: Invertible generative models from incomplete, noisy measurements
Sep 09, 2023
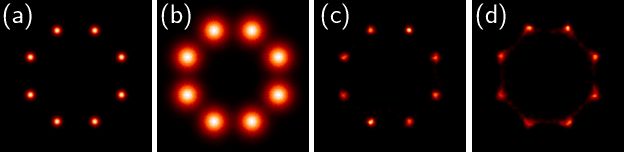


Generative models have gained popularity for their potential applications in imaging science, such as image reconstruction, posterior sampling and data sharing. Flow-based generative models are particularly attractive due to their ability to tractably provide exact density estimates along with fast, inexpensive and diverse samples. Training such models, however, requires a large, high quality dataset of objects. In applications such as computed imaging, it is often difficult to acquire such data due to requirements such as long acquisition time or high radiation dose, while acquiring noisy or partially observed measurements of these objects is more feasible. In this work, we propose AmbientFlow, a framework for learning flow-based generative models directly from noisy and incomplete data. Using variational Bayesian methods, a novel framework for establishing flow-based generative models from noisy, incomplete data is proposed. Extensive numerical studies demonstrate the effectiveness of AmbientFlow in correctly learning the object distribution. The utility of AmbientFlow in a downstream inference task of image reconstruction is demonstrated.
Stochastic Gradient Descent outperforms Gradient Descent in recovering a high-dimensional signal in a glassy energy landscape
Sep 09, 2023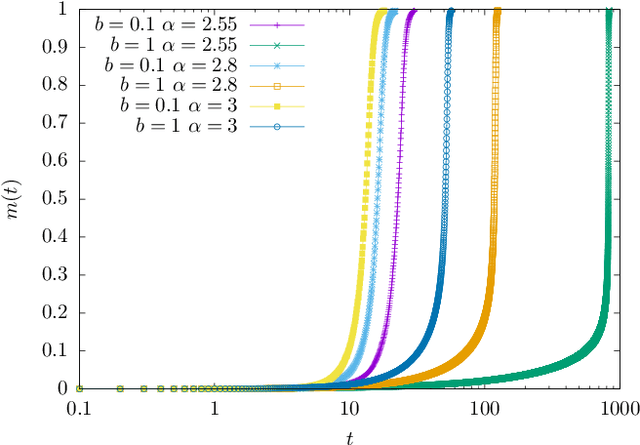
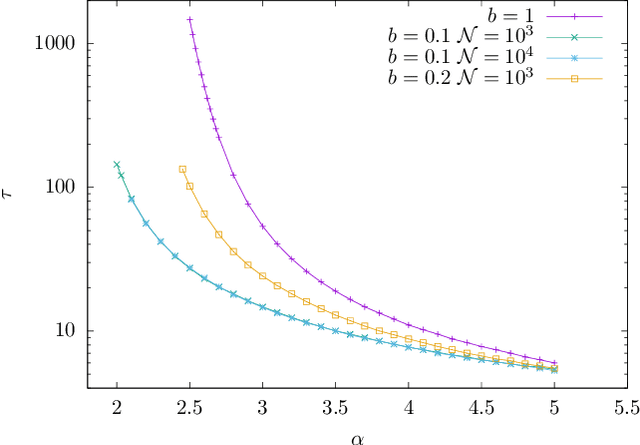
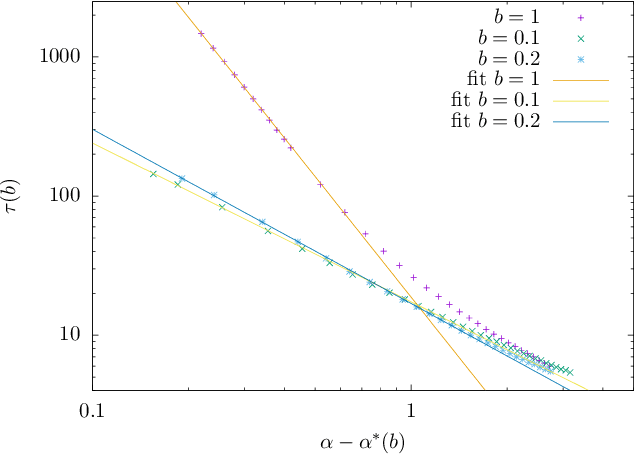
Stochastic Gradient Descent (SGD) is an out-of-equilibrium algorithm used extensively to train artificial neural networks. However very little is known on to what extent SGD is crucial for to the success of this technology and, in particular, how much it is effective in optimizing high-dimensional non-convex cost functions as compared to other optimization algorithms such as Gradient Descent (GD). In this work we leverage dynamical mean field theory to analyze exactly its performances in the high-dimensional limit. We consider the problem of recovering a hidden high-dimensional non-linearly encrypted signal, a prototype high-dimensional non-convex hard optimization problem. We compare the performances of SGD to GD and we show that SGD largely outperforms GD. In particular, a power law fit of the relaxation time of these algorithms shows that the recovery threshold for SGD with small batch size is smaller than the corresponding one of GD.
Score-PA: Score-based 3D Part Assembly
Sep 08, 2023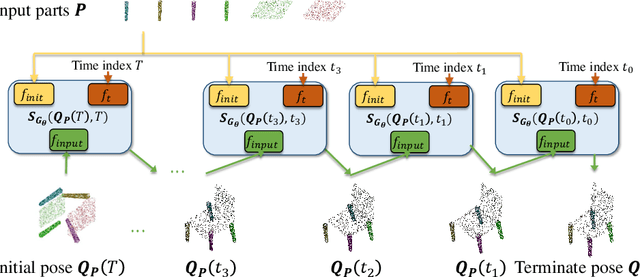
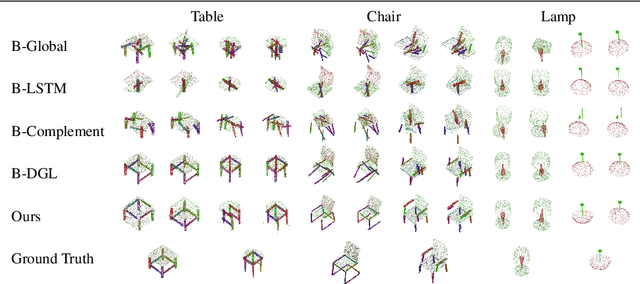
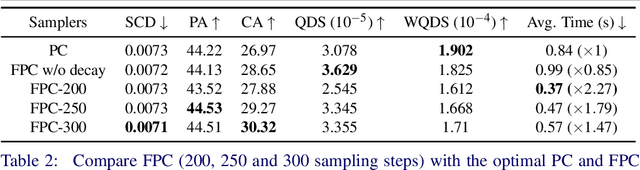

Autonomous 3D part assembly is a challenging task in the areas of robotics and 3D computer vision. This task aims to assemble individual components into a complete shape without relying on predefined instructions. In this paper, we formulate this task from a novel generative perspective, introducing the Score-based 3D Part Assembly framework (Score-PA) for 3D part assembly. Knowing that score-based methods are typically time-consuming during the inference stage. To address this issue, we introduce a novel algorithm called the Fast Predictor-Corrector Sampler (FPC) that accelerates the sampling process within the framework. We employ various metrics to assess assembly quality and diversity, and our evaluation results demonstrate that our algorithm outperforms existing state-of-the-art approaches. We release our code at https://github.com/J-F-Cheng/Score-PA_Score-based-3D-Part-Assembly.