 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Scenario-based model predictive control of water reservoir systems
Sep 01, 2023
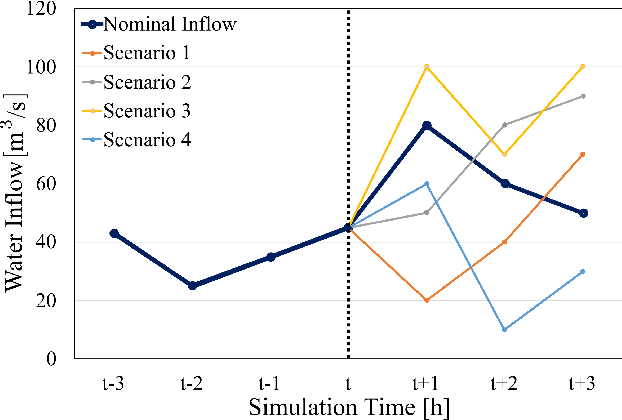
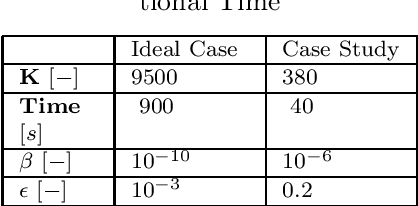
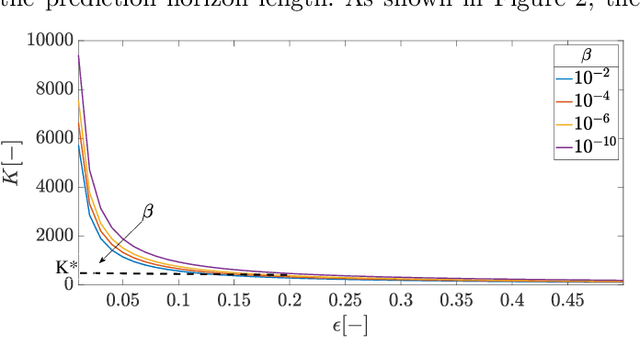
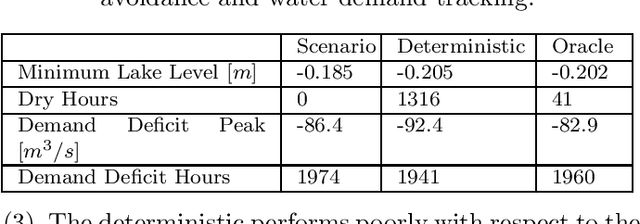
The optimal operation of water reservoir systems is a challenging task involving multiple conflicting objectives. The main source of complexity is the presence of the water inflow, which acts as an exogenous, highly uncertain disturbance on the system. When model predictive control (MPC) is employed, the optimal water release is usually computed based on the (predicted) trajectory of the inflow. This choice may jeopardize the closed-loop performance when the actual inflow differs from its forecast. In this work, we consider - for the first time - a stochastic MPC approach for water reservoirs, in which the control is optimized based on a set of plausible future inflows directly generated from past data. Such a scenario-based MPC strategy allows the controller to be more cautious, counteracting droughty periods (e.g., the lake level going below the dry limit) while at the same time guaranteeing that the agricultural water demand is satisfied. The method's effectiveness is validated through extensive Monte Carlo tests using actual inflow data from Lake Como, Italy.
Implementing BDI Continual Temporal Planning for Robotic Agents
Sep 01, 2023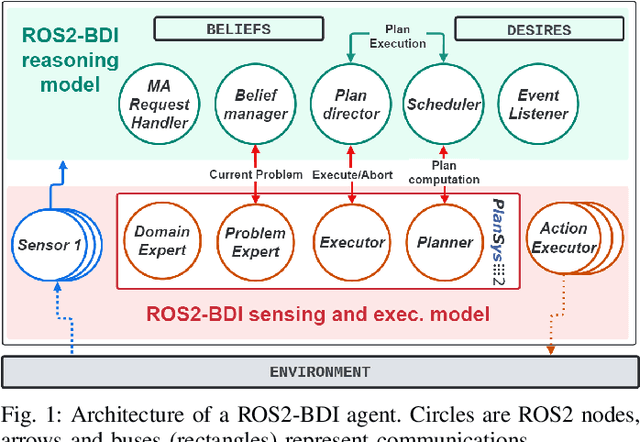

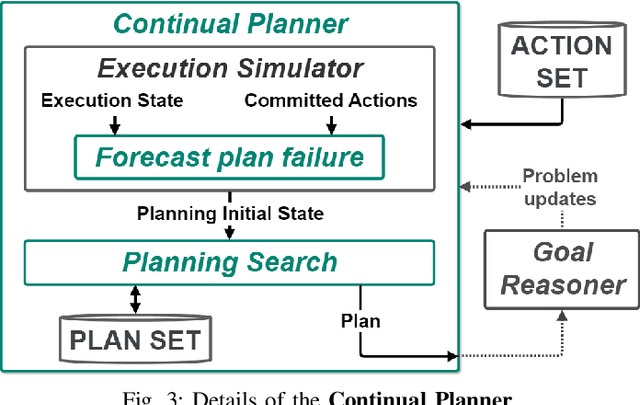
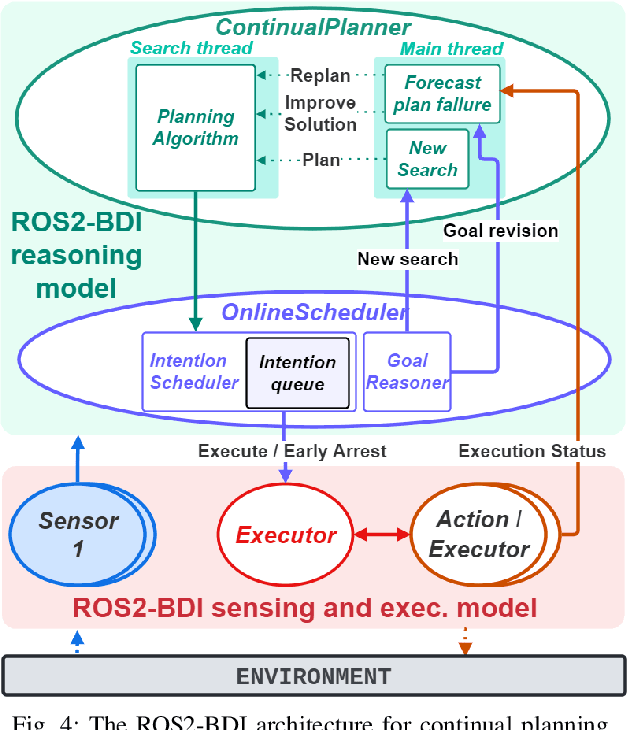
Making autonomous agents effective in real-life applications requires the ability to decide at run-time and a high degree of adaptability to unpredictable and uncontrollable events. Reacting to events is still a fundamental ability for an agent, but it has to be boosted up with proactive behaviors that allow the agent to explore alternatives and decide at run-time for optimal solutions. This calls for a continuous planning as part of the deliberation process that makes an agent able to reconsider plans on the base of temporal constraints and changes of the environment. Online planning literature offers several approaches used to select the next action on the base of a partial exploration of the solution space. In this paper, we propose a BDI continuous temporal planning framework, where interleave planning and execution loop is used to integrate online planning with the BDI control-loop. The framework has been implemented with the ROS2 robotic framework and planning algorithms offered by JavaFF.
Systematic Review of Experimental Paradigms and Deep Neural Networks for Electroencephalography-Based Cognitive Workload Detection
Sep 11, 2023This article summarizes a systematic review of the electroencephalography (EEG)-based cognitive workload (CWL) estimation. The focus of the article is twofold: identify the disparate experimental paradigms used for reliably eliciting discreet and quantifiable levels of cognitive load and the specific nature and representational structure of the commonly used input formulations in deep neural networks (DNNs) used for signal classification. The analysis revealed a number of studies using EEG signals in its native representation of a two-dimensional matrix for offline classification of CWL. However, only a few studies adopted an online or pseudo-online classification strategy for real-time CWL estimation. Further, only a couple of interpretable DNNs and a single generative model were employed for cognitive load detection till date during this review. More often than not, researchers were using DNNs as black-box type models. In conclusion, DNNs prove to be valuable tools for classifying EEG signals, primarily due to the substantial modeling power provided by the depth of their network architecture. It is further suggested that interpretable and explainable DNN models must be employed for cognitive workload estimation since existing methods are limited in the face of the non-stationary nature of the signal.
Mobile Vision Transformer-based Visual Object Tracking
Sep 11, 2023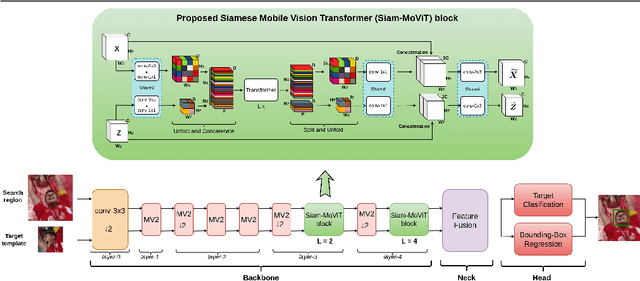
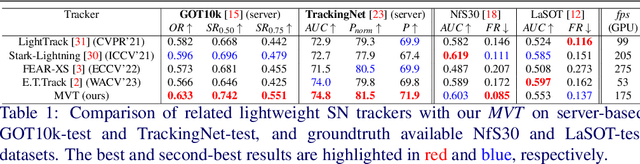
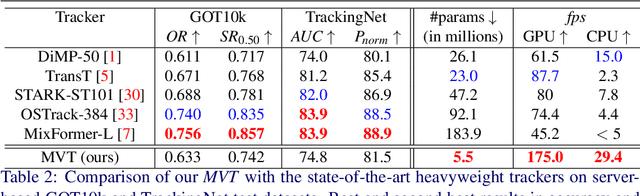
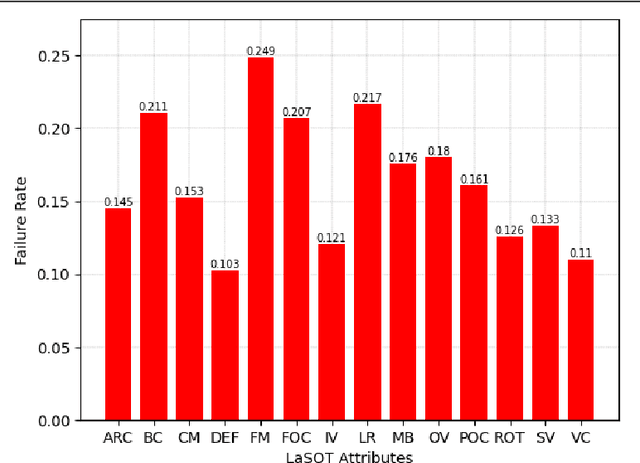
The introduction of robust backbones, such as Vision Transformers, has improved the performance of object tracking algorithms in recent years. However, these state-of-the-art trackers are computationally expensive since they have a large number of model parameters and rely on specialized hardware (e.g., GPU) for faster inference. On the other hand, recent lightweight trackers are fast but are less accurate, especially on large-scale datasets. We propose a lightweight, accurate, and fast tracking algorithm using Mobile Vision Transformers (MobileViT) as the backbone for the first time. We also present a novel approach of fusing the template and search region representations in the MobileViT backbone, thereby generating superior feature encoding for target localization. The experimental results show that our MobileViT-based Tracker, MVT, surpasses the performance of recent lightweight trackers on the large-scale datasets GOT10k and TrackingNet, and with a high inference speed. In addition, our method outperforms the popular DiMP-50 tracker despite having 4.7 times fewer model parameters and running at 2.8 times its speed on a GPU. The tracker code and models are available at https://github.com/goutamyg/MVT
PhotoVerse: Tuning-Free Image Customization with Text-to-Image Diffusion Models
Sep 11, 2023
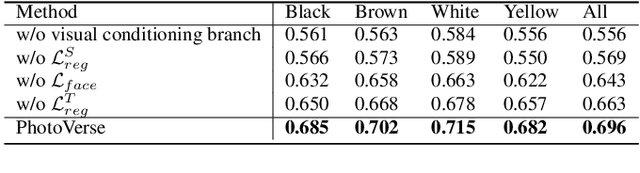
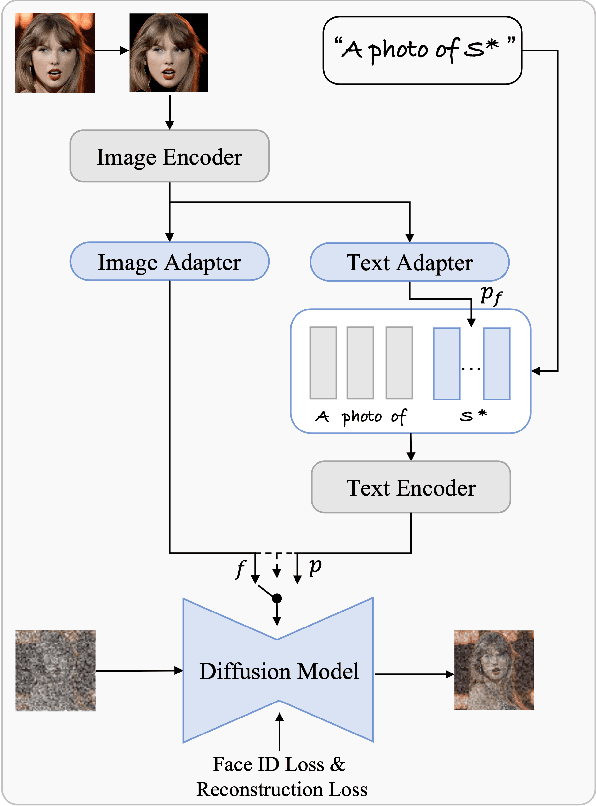
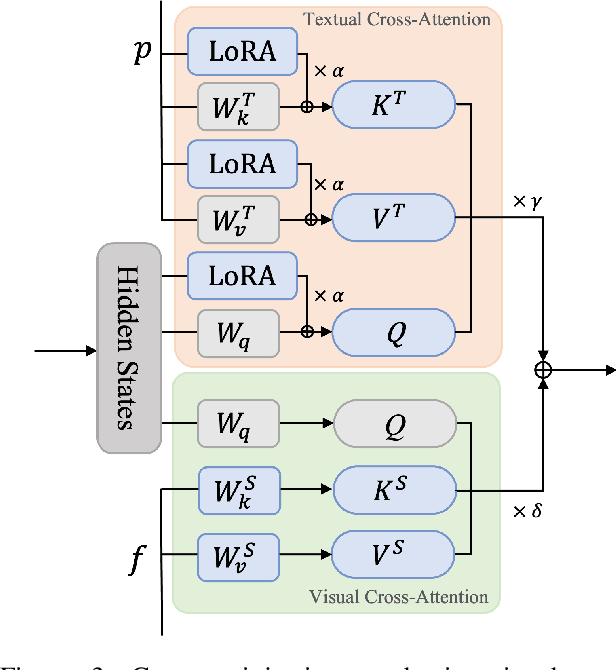
Personalized text-to-image generation has emerged as a powerful and sought-after tool, empowering users to create customized images based on their specific concepts and prompts. However, existing approaches to personalization encounter multiple challenges, including long tuning times, large storage requirements, the necessity for multiple input images per identity, and limitations in preserving identity and editability. To address these obstacles, we present PhotoVerse, an innovative methodology that incorporates a dual-branch conditioning mechanism in both text and image domains, providing effective control over the image generation process. Furthermore, we introduce facial identity loss as a novel component to enhance the preservation of identity during training. Remarkably, our proposed PhotoVerse eliminates the need for test time tuning and relies solely on a single facial photo of the target identity, significantly reducing the resource cost associated with image generation. After a single training phase, our approach enables generating high-quality images within only a few seconds. Moreover, our method can produce diverse images that encompass various scenes and styles. The extensive evaluation demonstrates the superior performance of our approach, which achieves the dual objectives of preserving identity and facilitating editability. Project page: https://photoverse2d.github.io/
Beamforming in Wireless Coded-Caching Systems
Sep 11, 2023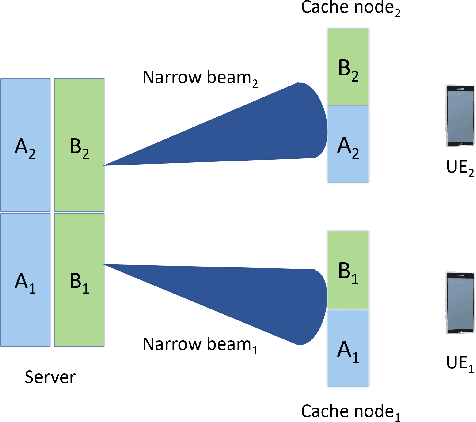
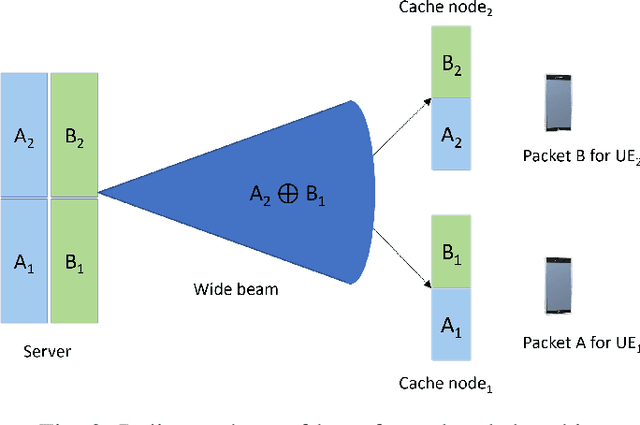
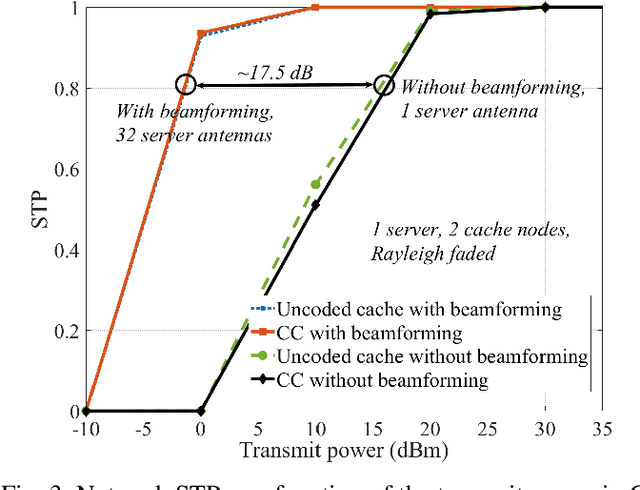
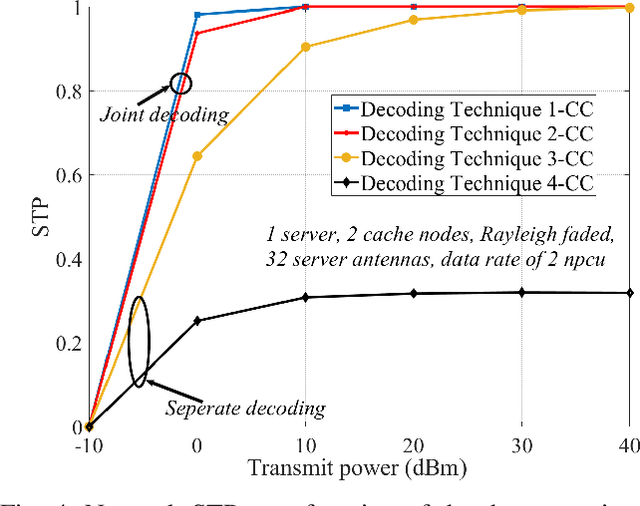
Increased capacity in the access network poses capacity challenges on the transport network due to the aggregated traffic. However, there are spatial and time correlation in the user data demands that could potentially be utilized. To that end, we investigate a wireless transport network architecture that integrates beamforming and coded-caching strategies. Especially, our proposed design entails a server with multiple antennas that broadcasts content to cache nodes responsible for serving users. Traditional caching methods face the limitation of relying on the individual memory with additional overhead. Hence, we develop an efficient genetic algorithm-based scheme for beam optimization in the coded-caching system. By exploiting the advantages of beamforming and coded-caching, the architecture achieves gains in terms of multicast opportunities, interference mitigation, and reduced peak backhaul traffic. A comparative analysis of this joint design with traditional, un-coded caching schemes is also conducted to assess the benefits of the proposed approach. Additionally, we examine the impact of various buffering and decoding methods on the performance of the coded-caching scheme. Our findings suggest that proper beamforming is useful in enhancing the effectiveness of the coded-caching technique, resulting in significant reduction in peak backhaul traffic.
Temporal Patience: Efficient Adaptive Deep Learning for Embedded Radar Data Processing
Sep 11, 2023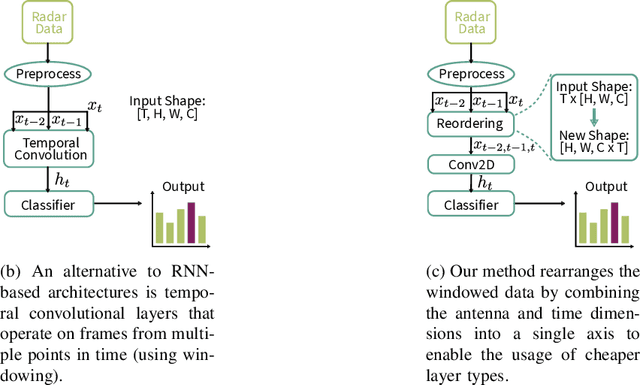
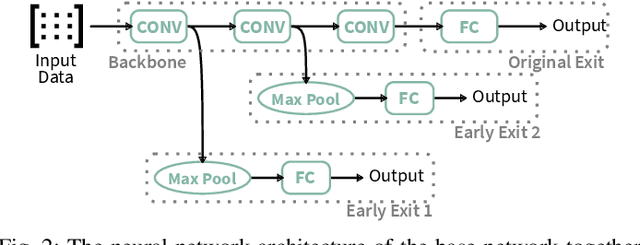
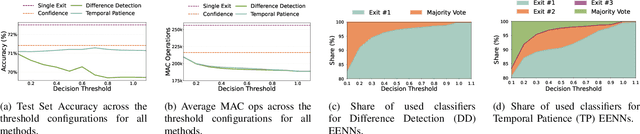
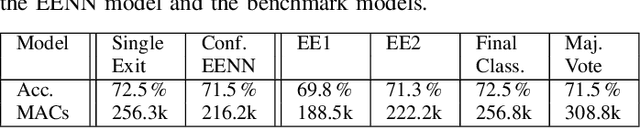
Radar sensors offer power-efficient solutions for always-on smart devices, but processing the data streams on resource-constrained embedded platforms remains challenging. This paper presents novel techniques that leverage the temporal correlation present in streaming radar data to enhance the efficiency of Early Exit Neural Networks for Deep Learning inference on embedded devices. These networks add additional classifier branches between the architecture's hidden layers that allow for an early termination of the inference if their result is deemed sufficient enough by an at-runtime decision mechanism. Our methods enable more informed decisions on when to terminate the inference, reducing computational costs while maintaining a minimal loss of accuracy. Our results demonstrate that our techniques save up to 26% of operations per inference over a Single Exit Network and 12% over a confidence-based Early Exit version. Our proposed techniques work on commodity hardware and can be combined with traditional optimizations, making them accessible for resource-constrained embedded platforms commonly used in smart devices. Such efficiency gains enable real-time radar data processing on resource-constrained platforms, allowing for new applications in the context of smart homes, Internet-of-Things, and human-computer interaction.
Proceedings of the 2nd International Workshop on Adaptive Cyber Defense
Sep 06, 2023The 2nd International Workshop on Adaptive Cyber Defense was held at the Florida Institute of Technology, Florida. This workshop was organized to share research that explores unique applications of Artificial Intelligence (AI) and Machine Learning (ML) as foundational capabilities for the pursuit of adaptive cyber defense. The cyber domain cannot currently be reliably and effectively defended without extensive reliance on human experts. Skilled cyber defenders are in short supply and often cannot respond fast enough to cyber threats. Building on recent advances in AI and ML the Cyber defense research community has been motivated to develop new dynamic and sustainable defenses through the adoption of AI and ML techniques to cyber settings. Bridging critical gaps between AI and Cyber researchers and practitioners can accelerate efforts to create semi-autonomous cyber defenses that can learn to recognize and respond to cyber attacks or discover and mitigate weaknesses in cooperation with other cyber operation systems and human experts. Furthermore, these defenses are expected to be adaptive and able to evolve over time to thwart changes in attacker behavior, changes in the system health and readiness, and natural shifts in user behavior over time. The workshop was comprised of invited keynote talks, technical presentations and a panel discussion about how AI/ML can enable autonomous mitigation of current and future cyber attacks. Workshop submissions were peer reviewed by a panel of domain experts with a proceedings consisting of six technical articles exploring challenging problems of critical importance to national and global security. Participation in this workshop offered new opportunities to stimulate research and innovation in the emerging domain of adaptive and autonomous cyber defense.
Efficient Baselines for Motion Prediction in Autonomous Driving
Sep 06, 2023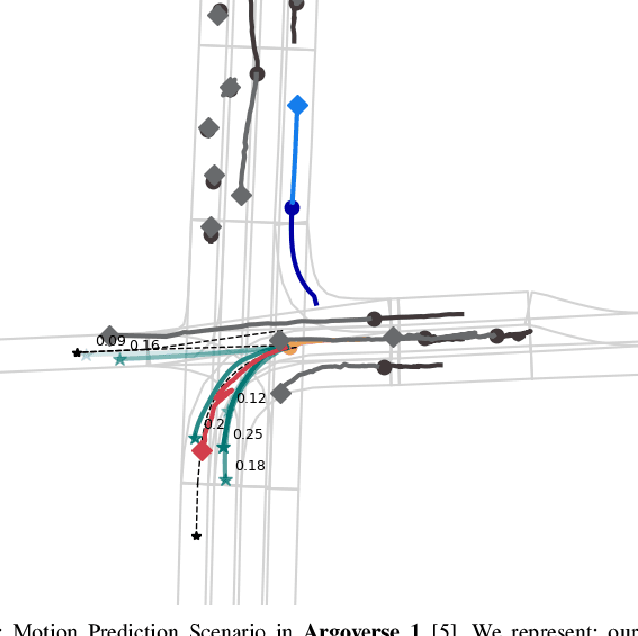
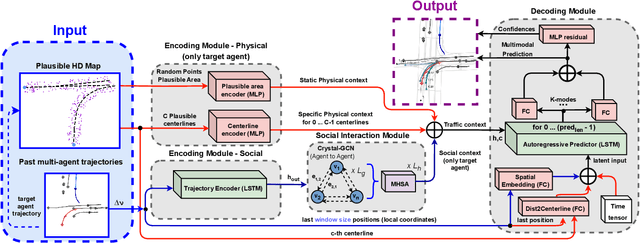
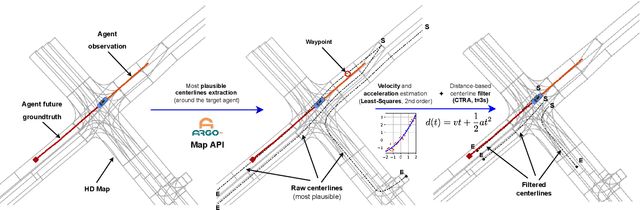
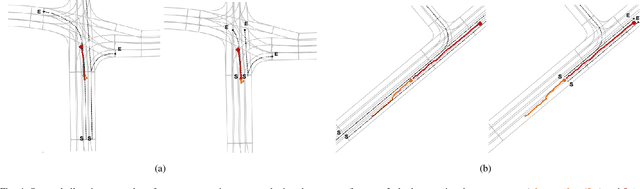
Motion Prediction (MP) of multiple surroundings agents is a crucial task in arbitrarily complex environments, from simple robots to Autonomous Driving Stacks (ADS). Current techniques tackle this problem using end-to-end pipelines, where the input data is usually a rendered top-view of the physical information and the past trajectories of the most relevant agents; leveraging this information is a must to obtain optimal performance. In that sense, a reliable ADS must produce reasonable predictions on time. However, despite many approaches use simple ConvNets and LSTMs to obtain the social latent features, State-Of-The-Art (SOTA) models might be too complex for real-time applications when using both sources of information (map and past trajectories) as well as little interpretable, specially considering the physical information. Moreover, the performance of such models highly depends on the number of available inputs for each particular traffic scenario, which are expensive to obtain, particularly, annotated High-Definition (HD) maps. In this work, we propose several efficient baselines for the well-known Argoverse 1 Motion Forecasting Benchmark. We aim to develop compact models using SOTA techniques for MP, including attention mechanisms and GNNs. Our lightweight models use standard social information and interpretable map information such as points from the driveable area and plausible centerlines by means of a novel preprocessing step based on kinematic constraints, in opposition to black-box CNN-based or too-complex graphs methods for map encoding, to generate plausible multimodal trajectories achieving up-to-pair accuracy with less operations and parameters than other SOTA methods. Our code is publicly available at https://github.com/Cram3r95/mapfe4mp .
Improved Outlier Robust Seeding for k-means
Sep 06, 2023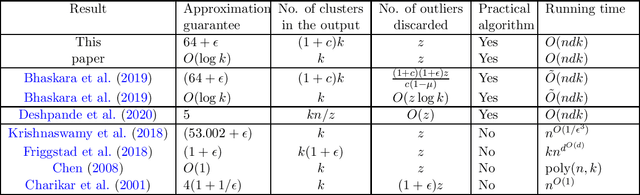
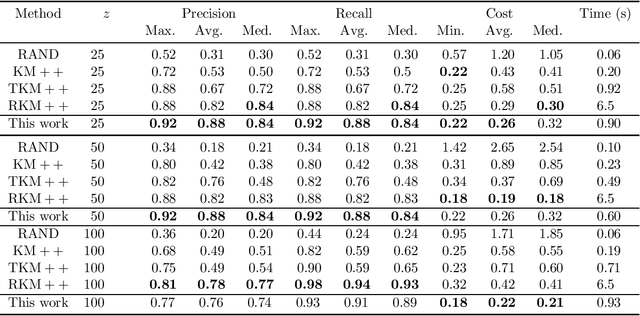
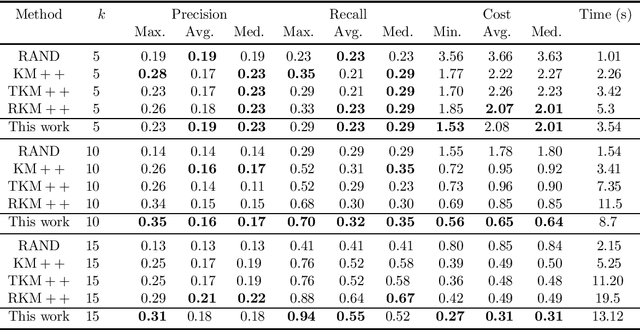
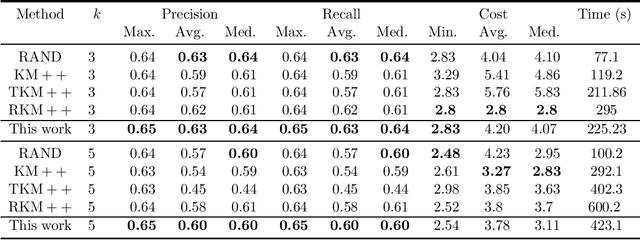
The $k$-means is a popular clustering objective, although it is inherently non-robust and sensitive to outliers. Its popular seeding or initialization called $k$-means++ uses $D^{2}$ sampling and comes with a provable $O(\log k)$ approximation guarantee \cite{AV2007}. However, in the presence of adversarial noise or outliers, $D^{2}$ sampling is more likely to pick centers from distant outliers instead of inlier clusters, and therefore its approximation guarantees \textit{w.r.t.} $k$-means solution on inliers, does not hold. Assuming that the outliers constitute a constant fraction of the given data, we propose a simple variant in the $D^2$ sampling distribution, which makes it robust to the outliers. Our algorithm runs in $O(ndk)$ time, outputs $O(k)$ clusters, discards marginally more points than the optimal number of outliers, and comes with a provable $O(1)$ approximation guarantee. Our algorithm can also be modified to output exactly $k$ clusters instead of $O(k)$ clusters, while keeping its running time linear in $n$ and $d$. This is an improvement over previous results for robust $k$-means based on LP relaxation and rounding \cite{Charikar}, \cite{KrishnaswamyLS18} and \textit{robust $k$-means++} \cite{DeshpandeKP20}. Our empirical results show the advantage of our algorithm over $k$-means++~\cite{AV2007}, uniform random seeding, greedy sampling for $k$ means~\cite{tkmeanspp}, and robust $k$-means++~\cite{DeshpandeKP20}, on standard real-world and synthetic data sets used in previous work. Our proposal is easily amenable to scalable, faster, parallel implementations of $k$-means++ \cite{Bahmani,BachemL017} and is of independent interest for coreset constructions in the presence of outliers \cite{feldman2007ptas,langberg2010universal,feldman2011unified}.