 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
LFS-GAN: Lifelong Few-Shot Image Generation
Sep 05, 2023
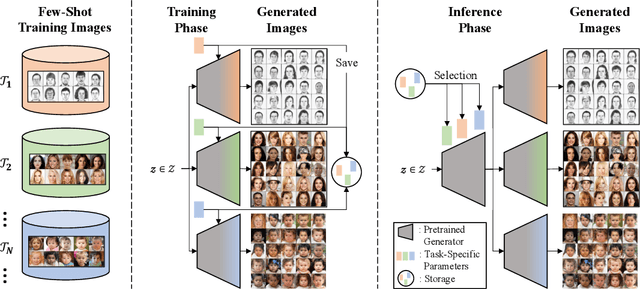
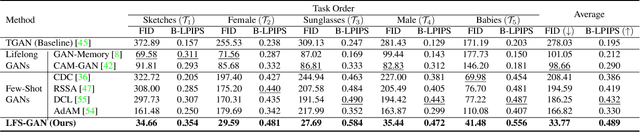
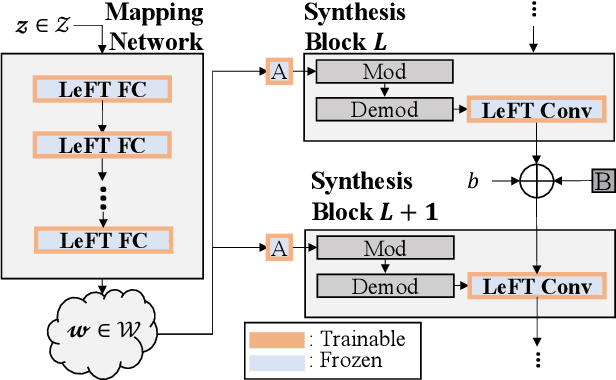
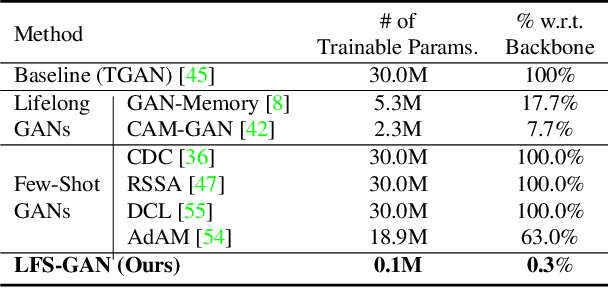
We address a challenging lifelong few-shot image generation task for the first time. In this situation, a generative model learns a sequence of tasks using only a few samples per task. Consequently, the learned model encounters both catastrophic forgetting and overfitting problems at a time. Existing studies on lifelong GANs have proposed modulation-based methods to prevent catastrophic forgetting. However, they require considerable additional parameters and cannot generate high-fidelity and diverse images from limited data. On the other hand, the existing few-shot GANs suffer from severe catastrophic forgetting when learning multiple tasks. To alleviate these issues, we propose a framework called Lifelong Few-Shot GAN (LFS-GAN) that can generate high-quality and diverse images in lifelong few-shot image generation task. Our proposed framework learns each task using an efficient task-specific modulator - Learnable Factorized Tensor (LeFT). LeFT is rank-constrained and has a rich representation ability due to its unique reconstruction technique. Furthermore, we propose a novel mode seeking loss to improve the diversity of our model in low-data circumstances. Extensive experiments demonstrate that the proposed LFS-GAN can generate high-fidelity and diverse images without any forgetting and mode collapse in various domains, achieving state-of-the-art in lifelong few-shot image generation task. Surprisingly, we find that our LFS-GAN even outperforms the existing few-shot GANs in the few-shot image generation task. The code is available at Github.
Quantum-AI empowered Intelligent Surveillance: Advancing Public Safety Through Innovative Contraband Detection
Sep 05, 2023Surveillance systems have emerged as crucial elements in upholding peace and security in the modern world. Their ubiquity aids in monitoring suspicious activities effectively. However, in densely populated environments, continuous active monitoring becomes impractical, necessitating the development of intelligent surveillance systems. AI integration in the surveillance domain was a big revolution, however, speed issues have prevented its widespread implementation in the field. It has been observed that quantum artificial intelligence has led to a great breakthrough. Quantum artificial intelligence-based surveillance systems have shown to be more accurate as well as capable of performing well in real-time scenarios, which had never been seen before. In this research, a RentinaNet model is integrated with Quantum CNN and termed as Quantum-RetinaNet. By harnessing the Quantum capabilities of QCNN, Quantum-RetinaNet strikes a balance between accuracy and speed. This innovative integration positions it as a game-changer, addressing the challenges of active monitoring in densely populated scenarios. As demand for efficient surveillance solutions continues to grow, Quantum-RetinaNet offers a compelling alternative to existing CNN models, upholding accuracy standards without sacrificing real-time performance. The unique attributes of Quantum-RetinaNet have far-reaching implications for the future of intelligent surveillance. With its enhanced processing speed, it is poised to revolutionize the field, catering to the pressing need for rapid yet precise monitoring. As Quantum-RetinaNet becomes the new standard, it ensures public safety and security while pushing the boundaries of AI in surveillance.
The Rise and Potential of Large Language Model Based Agents: A Survey
Sep 15, 2023
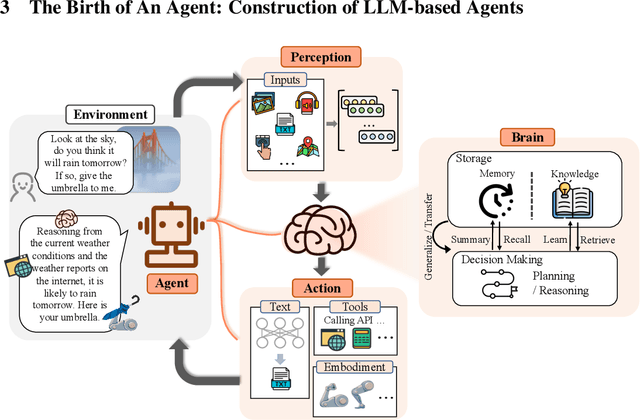
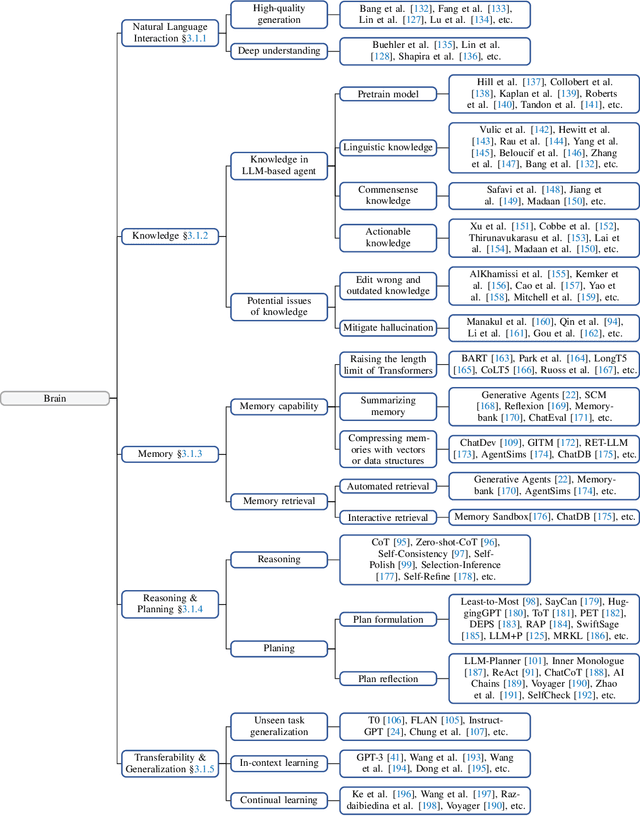
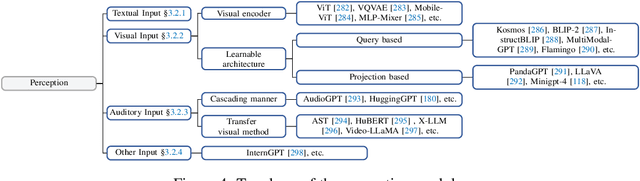
For a long time, humanity has pursued artificial intelligence (AI) equivalent to or surpassing the human level, with AI agents considered a promising vehicle for this pursuit. AI agents are artificial entities that sense their environment, make decisions, and take actions. Many efforts have been made to develop intelligent AI agents since the mid-20th century. However, these efforts have mainly focused on advancement in algorithms or training strategies to enhance specific capabilities or performance on particular tasks. Actually, what the community lacks is a sufficiently general and powerful model to serve as a starting point for designing AI agents that can adapt to diverse scenarios. Due to the versatile and remarkable capabilities they demonstrate, large language models (LLMs) are regarded as potential sparks for Artificial General Intelligence (AGI), offering hope for building general AI agents. Many research efforts have leveraged LLMs as the foundation to build AI agents and have achieved significant progress. We start by tracing the concept of agents from its philosophical origins to its development in AI, and explain why LLMs are suitable foundations for AI agents. Building upon this, we present a conceptual framework for LLM-based agents, comprising three main components: brain, perception, and action, and the framework can be tailored to suit different applications. Subsequently, we explore the extensive applications of LLM-based agents in three aspects: single-agent scenarios, multi-agent scenarios, and human-agent cooperation. Following this, we delve into agent societies, exploring the behavior and personality of LLM-based agents, the social phenomena that emerge when they form societies, and the insights they offer for human society. Finally, we discuss a range of key topics and open problems within the field.
Simple LLM Prompting is State-of-the-Art for Robust and Multilingual Dialogue Evaluation
Sep 08, 2023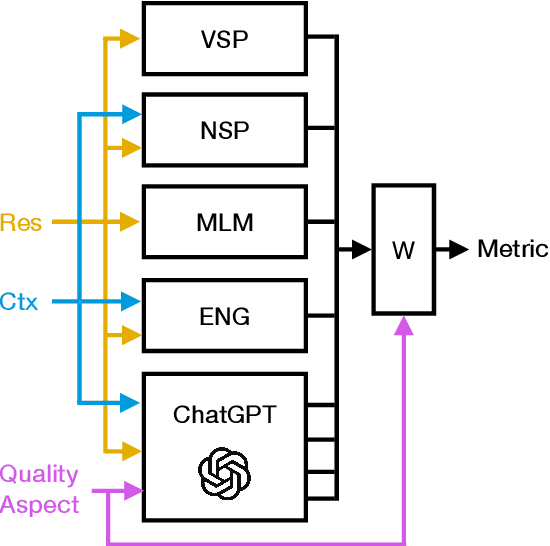
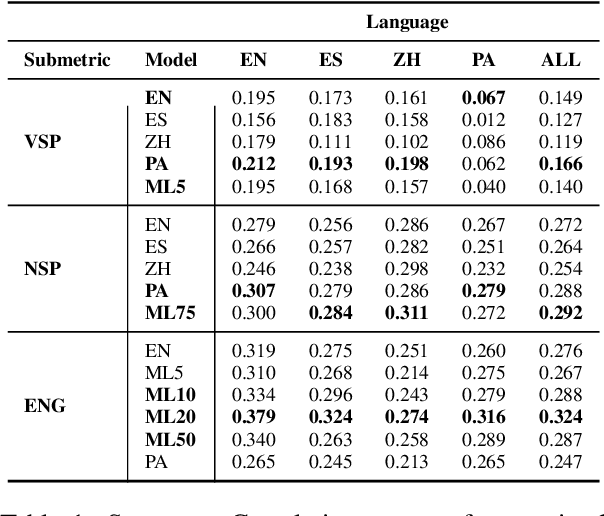

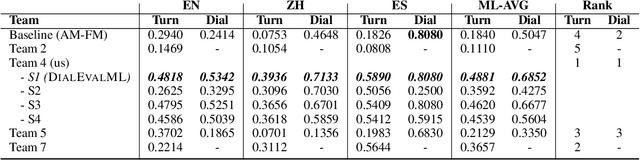
Despite significant research effort in the development of automatic dialogue evaluation metrics, little thought is given to evaluating dialogues other than in English. At the same time, ensuring metrics are invariant to semantically similar responses is also an overlooked topic. In order to achieve the desired properties of robustness and multilinguality for dialogue evaluation metrics, we propose a novel framework that takes advantage of the strengths of current evaluation models with the newly-established paradigm of prompting Large Language Models (LLMs). Empirical results show our framework achieves state of the art results in terms of mean Spearman correlation scores across several benchmarks and ranks first place on both the Robust and Multilingual tasks of the DSTC11 Track 4 "Automatic Evaluation Metrics for Open-Domain Dialogue Systems", proving the evaluation capabilities of prompted LLMs.
Actor critic learning algorithms for mean-field control with moment neural networks
Sep 08, 2023We develop a new policy gradient and actor-critic algorithm for solving mean-field control problems within a continuous time reinforcement learning setting. Our approach leverages a gradient-based representation of the value function, employing parametrized randomized policies. The learning for both the actor (policy) and critic (value function) is facilitated by a class of moment neural network functions on the Wasserstein space of probability measures, and the key feature is to sample directly trajectories of distributions. A central challenge addressed in this study pertains to the computational treatment of an operator specific to the mean-field framework. To illustrate the effectiveness of our methods, we provide a comprehensive set of numerical results. These encompass diverse examples, including multi-dimensional settings and nonlinear quadratic mean-field control problems with controlled volatility.
Predictive and Robust Robot Assistance for Sequential Manipulation
Sep 08, 2023This paper presents a novel concept to support physically impaired humans in daily object manipulation tasks with a robot. Given a user's manipulation sequence, we propose a predictive model that uniquely casts the user's sequential behavior as well as a robot support intervention into a hierarchical multi-objective optimization problem. A major contribution is the prediction formulation, which allows to consider several different future paths concurrently. The second contribution is the encoding of a general notion of constancy constraints, which allows to consider dependencies between consecutive or far apart keyframes (in time or space) of a sequential task. We perform numerical studies, simulations and robot experiments to analyse and evaluate the proposed method in several table top tasks where a robot supports impaired users by predicting their posture and proactively re-arranging objects.
Pointwise-in-Time Explanation for Linear Temporal Logic Rules
Jun 24, 2023This work introduces a framework to assess the relevance of individual linear temporal logic (LTL) constraints at specific times in a given path plan, a task we refer to as "pointwise-in-time" explanation. We develop this framework, featuring a status assessment algorithm, for agents which execute finite plans in a discrete-time, discrete-space setting expressible via a Kripke structure. Given a plan on this structure and a set of LTL rules which are known to constrain the agent, the algorithm responds to two types of user queries to produce explanation. For the selected query time, explanations identify which rules are active, which have just been satisfied, and which are inactive, where the framework status criteria are formally and intuitively defined. Explanations may also include the status of individual rule arguments to provide further insight. In this paper, we systematically present this novel framework and provide an example of its implementation.
TransformerG2G: Adaptive time-stepping for learning temporal graph embeddings using transformers
Jul 05, 2023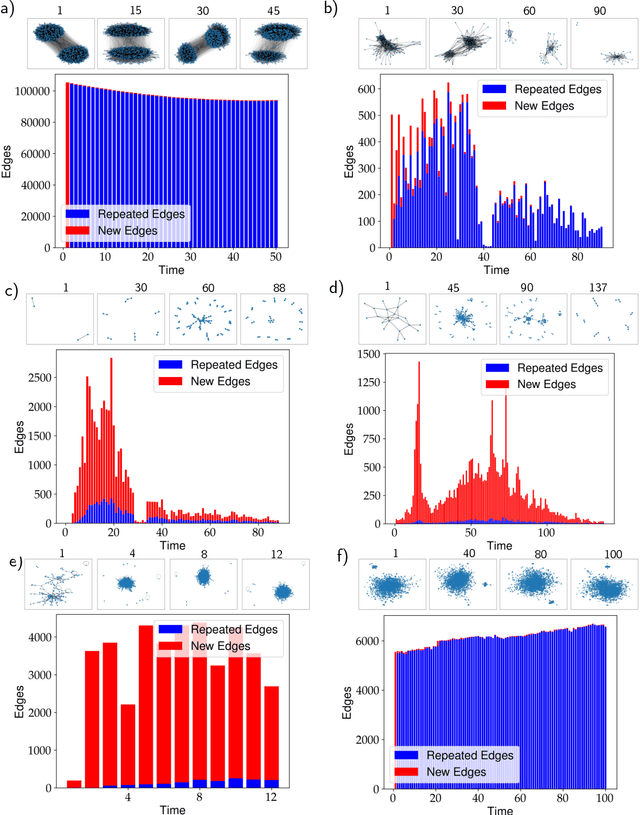
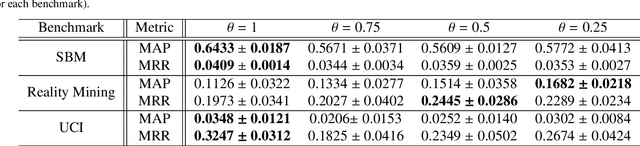
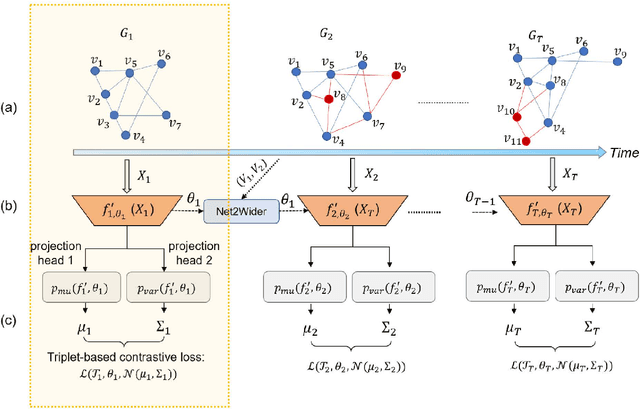

Dynamic graph embedding has emerged as a very effective technique for addressing diverse temporal graph analytic tasks (i.e., link prediction, node classification, recommender systems, anomaly detection, and graph generation) in various applications. Such temporal graphs exhibit heterogeneous transient dynamics, varying time intervals, and highly evolving node features throughout their evolution. Hence, incorporating long-range dependencies from the historical graph context plays a crucial role in accurately learning their temporal dynamics. In this paper, we develop a graph embedding model with uncertainty quantification, TransformerG2G, by exploiting the advanced transformer encoder to first learn intermediate node representations from its current state ($t$) and previous context (over timestamps [$t-1, t-l$], $l$ is the length of context). Moreover, we employ two projection layers to generate lower-dimensional multivariate Gaussian distributions as each node's latent embedding at timestamp $t$. We consider diverse benchmarks with varying levels of ``novelty" as measured by the TEA plots. Our experiments demonstrate that the proposed TransformerG2G model outperforms conventional multi-step methods and our prior work (DynG2G) in terms of both link prediction accuracy and computational efficiency, especially for high degree of novelty. Furthermore, the learned time-dependent attention weights across multiple graph snapshots reveal the development of an automatic adaptive time stepping enabled by the transformer. Importantly, by examining the attention weights, we can uncover temporal dependencies, identify influential elements, and gain insights into the complex interactions within the graph structure. For example, we identified a strong correlation between attention weights and node degree at the various stages of the graph topology evolution.
Feature Programming for Multivariate Time Series Prediction
Jun 09, 2023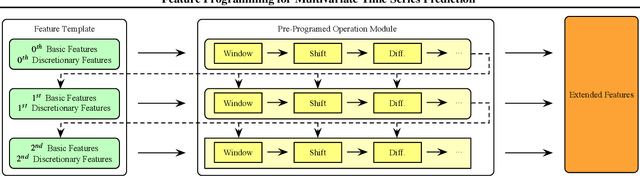
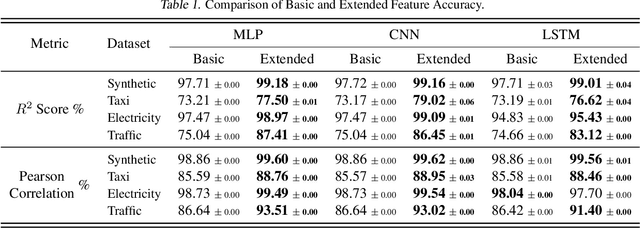

We introduce the concept of programmable feature engineering for time series modeling and propose a feature programming framework. This framework generates large amounts of predictive features for noisy multivariate time series while allowing users to incorporate their inductive bias with minimal effort. The key motivation of our framework is to view any multivariate time series as a cumulative sum of fine-grained trajectory increments, with each increment governed by a novel spin-gas dynamical Ising model. This fine-grained perspective motivates the development of a parsimonious set of operators that summarize multivariate time series in an abstract fashion, serving as the foundation for large-scale automated feature engineering. Numerically, we validate the efficacy of our method on several synthetic and real-world noisy time series datasets.
Spiking based Cellular Learning Automata (SCLA) algorithm for mobile robot motion formulation
Sep 01, 2023
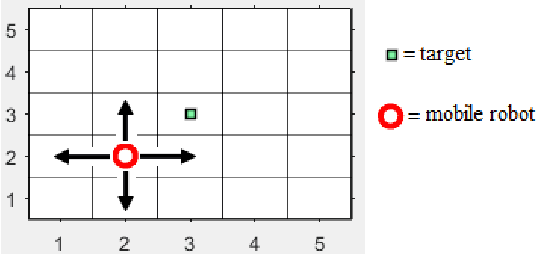
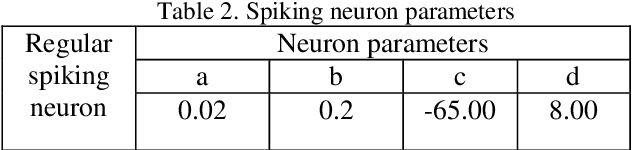
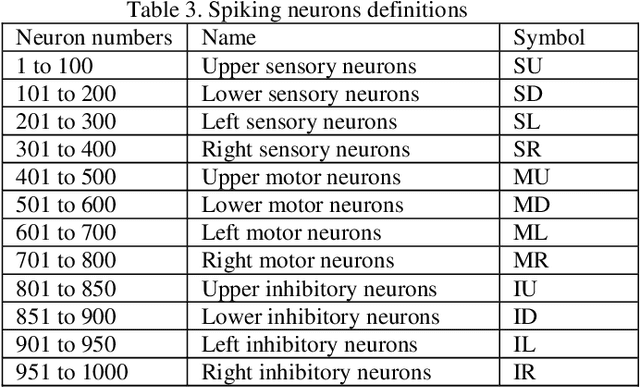
In this paper a new method called SCLA which stands for Spiking based Cellular Learning Automata is proposed for a mobile robot to get to the target from any random initial point. The proposed method is a result of the integration of both cellular automata and spiking neural networks. The environment consists of multiple squares of the same size and the robot only observes the neighboring squares of its current square. It should be stated that the robot only moves either up and down or right and left. The environment returns feedback to the learning automata to optimize its decision making in the next steps resulting in cellular automata training. Simultaneously a spiking neural network is trained to implement long term improvements and reductions on the paths. The results show that the integration of both cellular automata and spiking neural network ends up in reinforcing the proper paths and training time reduction at the same time.