 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Enhancing Cardiac MRI Segmentation via Classifier-Guided Two-Stage Network and All-Slice Information Fusion Transformer
Sep 02, 2023
Cardiac Magnetic Resonance imaging (CMR) is the gold standard for assessing cardiac function. Segmenting the left ventricle (LV), right ventricle (RV), and LV myocardium (MYO) in CMR images is crucial but time-consuming. Deep learning-based segmentation methods have emerged as effective tools for automating this process. However, CMR images present additional challenges due to irregular and varying heart shapes, particularly in basal and apical slices. In this study, we propose a classifier-guided two-stage network with an all-slice fusion transformer to enhance CMR segmentation accuracy, particularly in basal and apical slices. Our method was evaluated on extensive clinical datasets and demonstrated better performance in terms of Dice score compared to previous CNN-based and transformer-based models. Moreover, our method produces visually appealing segmentation shapes resembling human annotations and avoids common issues like holes or fragments in other models' segmentations.
LM-Infinite: Simple On-the-Fly Length Generalization for Large Language Models
Aug 30, 2023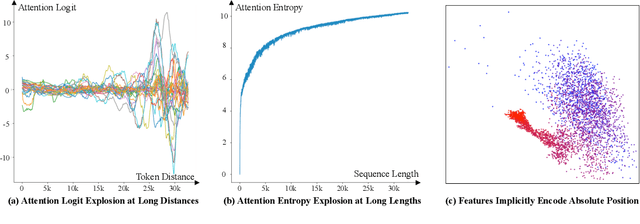
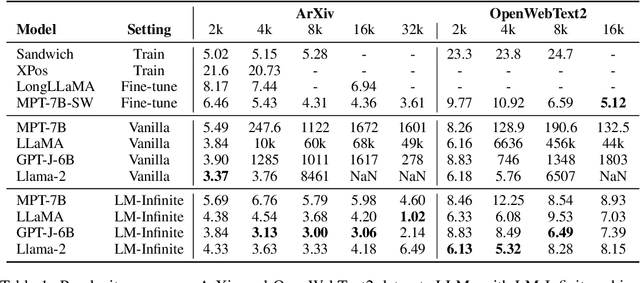
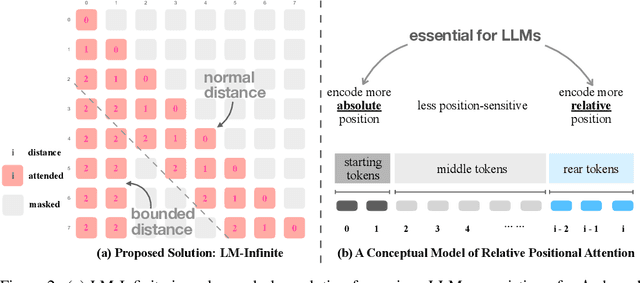
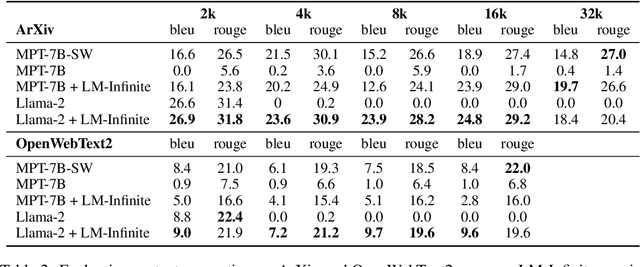
In recent years, there have been remarkable advancements in the performance of Transformer-based Large Language Models (LLMs) across various domains. As these LLMs are deployed for increasingly complex tasks, they often face the needs to conduct longer reasoning processes or understanding larger contexts. In these situations, the length generalization failure of LLMs on long sequences become more prominent. Most pre-training schemes truncate training sequences to a fixed length (such as 2048 for LLaMa). LLMs often struggle to generate fluent texts, let alone carry out downstream tasks, after longer contexts, even with relative positional encoding which is designed to cope with this problem. Common solutions such as finetuning on longer corpora often involves daunting hardware and time costs and requires careful training process design. To more efficiently leverage the generation capacity of existing LLMs, we theoretically and empirically investigate the main out-of-distribution (OOD) factors contributing to this problem. Inspired by this diagnosis, we propose a simple yet effective solution for on-the-fly length generalization, LM-Infinite, which involves only a $\Lambda$-shaped attention mask and a distance limit while requiring no parameter updates or learning. We find it applicable to a variety of LLMs using relative-position encoding methods. LM-Infinite is computational efficient with $O(n)$ time and space, and demonstrates consistent fluency and generation quality to as long as 32k tokens on ArXiv and OpenWebText2 datasets, with 2.72x decoding speedup. On downstream task such as passkey retrieval, it continues to work on inputs much longer than training lengths where vanilla models fail immediately.
MDTD: A Multi Domain Trojan Detector for Deep Neural Networks
Aug 30, 2023

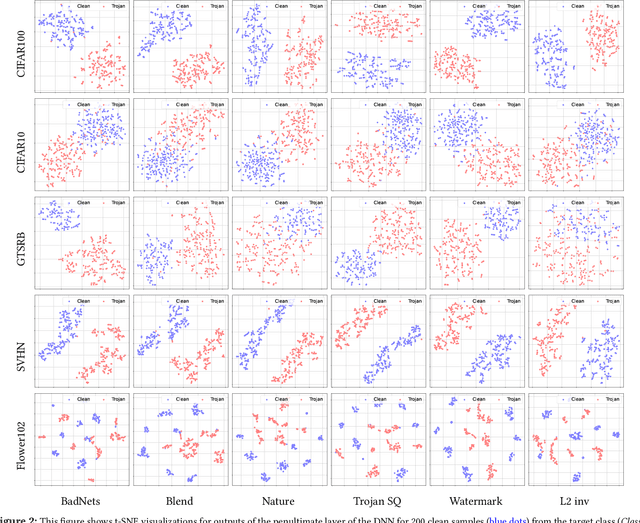

Machine learning models that use deep neural networks (DNNs) are vulnerable to backdoor attacks. An adversary carrying out a backdoor attack embeds a predefined perturbation called a trigger into a small subset of input samples and trains the DNN such that the presence of the trigger in the input results in an adversary-desired output class. Such adversarial retraining however needs to ensure that outputs for inputs without the trigger remain unaffected and provide high classification accuracy on clean samples. In this paper, we propose MDTD, a Multi-Domain Trojan Detector for DNNs, which detects inputs containing a Trojan trigger at testing time. MDTD does not require knowledge of trigger-embedding strategy of the attacker and can be applied to a pre-trained DNN model with image, audio, or graph-based inputs. MDTD leverages an insight that input samples containing a Trojan trigger are located relatively farther away from a decision boundary than clean samples. MDTD estimates the distance to a decision boundary using adversarial learning methods and uses this distance to infer whether a test-time input sample is Trojaned or not. We evaluate MDTD against state-of-the-art Trojan detection methods across five widely used image-based datasets: CIFAR100, CIFAR10, GTSRB, SVHN, and Flowers102; four graph-based datasets: AIDS, WinMal, Toxicant, and COLLAB; and the SpeechCommand audio dataset. MDTD effectively identifies samples that contain different types of Trojan triggers. We evaluate MDTD against adaptive attacks where an adversary trains a robust DNN to increase (decrease) distance of benign (Trojan) inputs from a decision boundary.
MRNAV: Multi-Robot Aware Planning and Control Stack for Collision and Deadlock-free Navigation in Cluttered Environments
Aug 25, 2023Multi-robot collision-free and deadlock-free navigation in cluttered environments with static and dynamic obstacles is a fundamental problem for many applications. We introduce MRNAV, a framework for planning and control to effectively navigate in such environments. Our design utilizes short, medium, and long horizon decision making modules with qualitatively different properties, and defines the responsibilities of them. The decision making modules complement each other and provide the effective navigation capability. MRNAV is the first hierarchical approach combining these three levels of decision making modules and explicitly defining their responsibilities. We implement our design for simulated multi-quadrotor flight. In our evaluations, we show that all three modules are required for effective navigation in diverse situations. We show the long-term executability of our approach in an eight hour long wall time (six hour long simulation time) uninterrupted simulation without collisions or deadlocks.
Simple Cycle Reservoirs are Universal
Aug 21, 2023Reservoir computation models form a subclass of recurrent neural networks with fixed non-trainable input and dynamic coupling weights. Only the static readout from the state space (reservoir) is trainable, thus avoiding the known problems with propagation of gradient information backwards through time. Reservoir models have been successfully applied in a variety of tasks and were shown to be universal approximators of time-invariant fading memory dynamic filters under various settings. Simple cycle reservoirs (SCR) have been suggested as severely restricted reservoir architecture, with equal weight ring connectivity of the reservoir units and input-to-reservoir weights of binary nature with the same absolute value. Such architectures are well suited for hardware implementations without performance degradation in many practical tasks. In this contribution, we rigorously study the expressive power of SCR in the complex domain and show that they are capable of universal approximation of any unrestricted linear reservoir system (with continuous readout) and hence any time-invariant fading memory filter over uniformly bounded input streams.
A Joint Time-frequency Domain Transformer for Multivariate Time Series Forecasting
May 24, 2023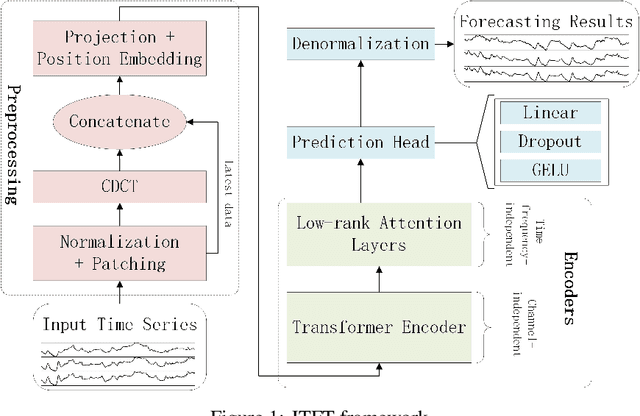
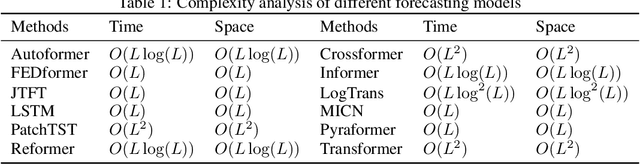
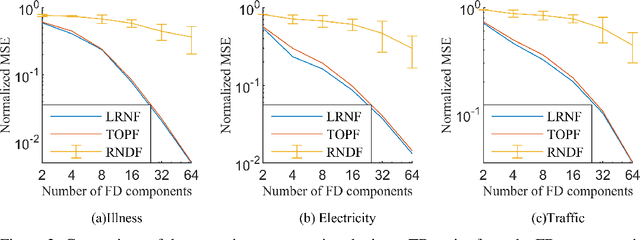
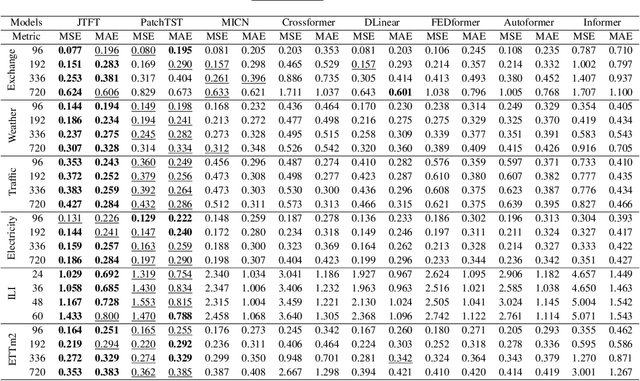
To enhance predicting performance while minimizing computational demands, this paper introduces a joint time-frequency domain Transformer (JTFT) for multivariate forecasting. The method exploits the sparsity of time series in the frequency domain using a small number of learnable frequencies to extract temporal dependencies effectively. Alongside the frequency domain representation, a fixed number of the most recent data points are directly encoded in the time domain, bolstering the learning of local relationships and mitigating the adverse effects of non-stationarity. JTFT achieves linear complexity since the length of the internal representation remains independent of the input sequence length. Additionally, a low-rank attention layer is proposed to efficiently capture cross-dimensional dependencies and prevent performance degradation due to the entanglement of temporal and channel-wise modeling. Experiments conducted on six real-world datasets demonstrate that JTFT outperforms state-of-the-art methods.
Efficient Bayesian travel-time tomography with geologically-complex priors using sensitivity-informed polynomial chaos expansion and deep generative networks
Jul 29, 2023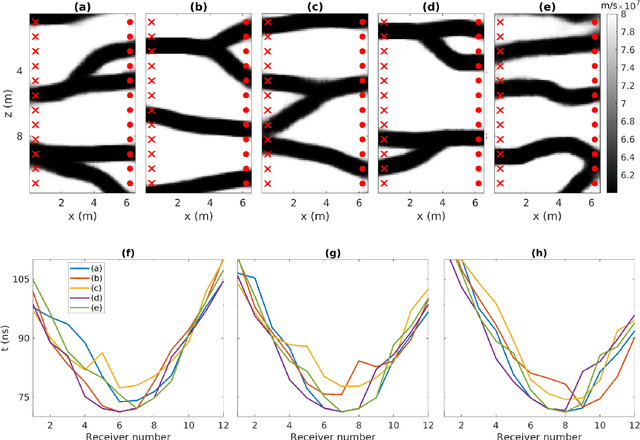

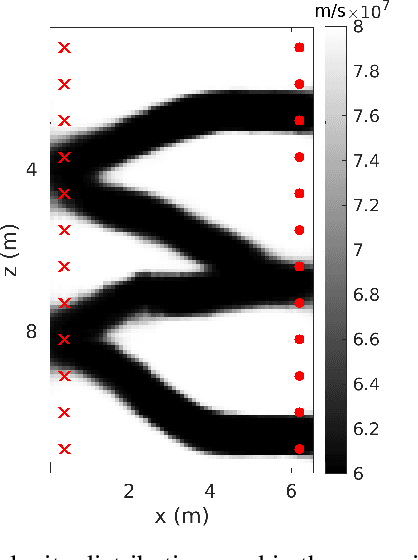

Monte Carlo Markov Chain (MCMC) methods commonly confront two fundamental challenges: the accurate characterization of the prior distribution and the efficient evaluation of the likelihood. In the context of Bayesian studies on tomography, principal component analysis (PCA) can in some cases facilitate the straightforward definition of the prior distribution, while simultaneously enabling the implementation of accurate surrogate models based on polynomial chaos expansion (PCE) to replace computationally intensive full-physics forward solvers. When faced with scenarios where PCA does not offer a direct means of easily defining the prior distribution alternative methods like deep generative models (e.g., variational autoencoders (VAEs)), can be employed as viable options. However, accurately producing a surrogate capable of capturing the intricate non-linear relationship between the latent parameters of a VAE and the outputs of forward modeling presents a notable challenge. Indeed, while PCE models provide high accuracy when the input-output relationship can be effectively approximated by relatively low-degree multivariate polynomials, this condition is typically unmet when utilizing latent variables derived from deep generative models. In this contribution, we present a strategy that combines the excellent reconstruction performances of VAE in terms of prio representation with the accuracy of PCA-PCE surrogate modeling in the context of Bayesian ground penetrating radar (GPR) travel-time tomography. Within the MCMC process, the parametrization of the VAE is leveraged for prior exploration and sample proposal. Concurrently, modeling is conducted using PCE, which operates on either globally or locally defined principal components of the VAE samples under examination.
Enhancing Cell Tracking with a Time-Symmetric Deep Learning Approach
Aug 04, 2023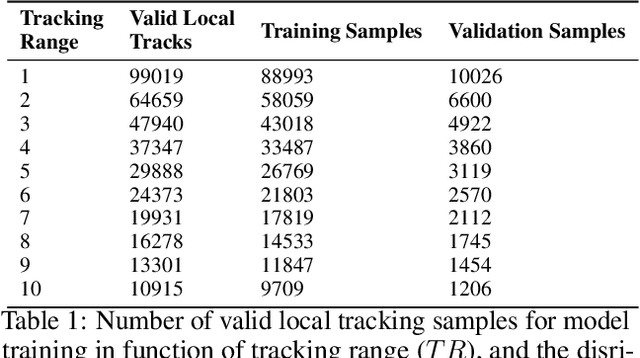
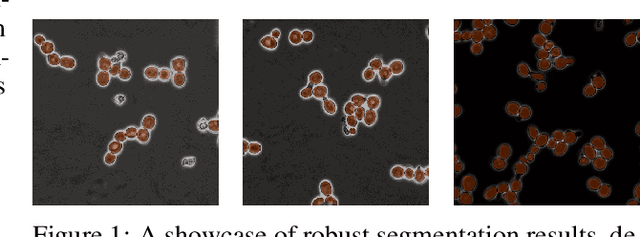

The accurate tracking of live cells using video microscopy recordings remains a challenging task for popular state-of-the-art image processing based object tracking methods. In recent years, several existing and new applications have attempted to integrate deep-learning based frameworks for this task, but most of them still heavily rely on consecutive frame based tracking embedded in their architecture or other premises that hinder generalized learning. To address this issue, we aimed to develop a new deep-learning based tracking method that relies solely on the assumption that cells can be tracked based on their spatio-temporal neighborhood, without restricting it to consecutive frames. The proposed method has the additional benefit that the motion patterns of the cells can be learned completely by the predictor without any prior assumptions, and it has the potential to handle a large number of video frames with heavy artifacts. The efficacy of the proposed method is demonstrated through multiple biologically motivated validation strategies and compared against several state-of-the-art cell tracking methods.
Dynamic Encoding and Decoding of Information for Split Learning in Mobile-Edge Computing: Leveraging Information Bottleneck Theory
Sep 06, 2023Split learning is a privacy-preserving distributed learning paradigm in which an ML model (e.g., a neural network) is split into two parts (i.e., an encoder and a decoder). The encoder shares so-called latent representation, rather than raw data, for model training. In mobile-edge computing, network functions (such as traffic forecasting) can be trained via split learning where an encoder resides in a user equipment (UE) and a decoder resides in the edge network. Based on the data processing inequality and the information bottleneck (IB) theory, we present a new framework and training mechanism to enable a dynamic balancing of the transmission resource consumption with the informativeness of the shared latent representations, which directly impacts the predictive performance. The proposed training mechanism offers an encoder-decoder neural network architecture featuring multiple modes of complexity-relevance tradeoffs, enabling tunable performance. The adaptability can accommodate varying real-time network conditions and application requirements, potentially reducing operational expenditure and enhancing network agility. As a proof of concept, we apply the training mechanism to a millimeter-wave (mmWave)-enabled throughput prediction problem. We also offer new insights and highlight some challenges related to recurrent neural networks from the perspective of the IB theory. Interestingly, we find a compression phenomenon across the temporal domain of the sequential model, in addition to the compression phase that occurs with the number of training epochs.
Ultrafast-and-Ultralight ConvNet-Based Intelligent Monitoring System for Diagnosing Early-Stage Mpox Anytime and Anywhere
Aug 25, 2023Due to the lack of more efficient diagnostic tools for monkeypox, its spread remains unchecked, presenting a formidable challenge to global health. While the high efficacy of deep learning models for monkeypox diagnosis has been demonstrated in related studies, the overlook of inference speed, the parameter size and diagnosis performance for early-stage monkeypox renders the models inapplicable in real-world settings. To address these challenges, we proposed an ultrafast and ultralight network named Fast-MpoxNet. Fast-MpoxNet possesses only 0.27M parameters and can process input images at 68 frames per second (FPS) on the CPU. To counteract the diagnostic performance limitation brought about by the small model capacity, it integrates the attention-based feature fusion module and the multiple auxiliary losses enhancement strategy for better detecting subtle image changes and optimizing weights. Using transfer learning and five-fold cross-validation, Fast-MpoxNet achieves 94.26% Accuracy on the Mpox dataset. Notably, its recall for early-stage monkeypox achieves 93.65%. By adopting data augmentation, our model's Accuracy rises to 98.40% and attains a Practicality Score (A new metric for measuring model practicality in real-time diagnosis application) of 0.80. We also developed an application system named Mpox-AISM V2 for both personal computers and mobile phones. Mpox-AISM V2 features ultrafast responses, offline functionality, and easy deployment, enabling accurate and real-time diagnosis for both the public and individuals in various real-world settings, especially in populous settings during the outbreak. Our work could potentially mitigate future monkeypox outbreak and illuminate a fresh paradigm for developing real-time diagnostic tools in the healthcare field.