 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Hybrid of representation learning and reinforcement learning for dynamic and complex robotic motion planning
Sep 07, 2023
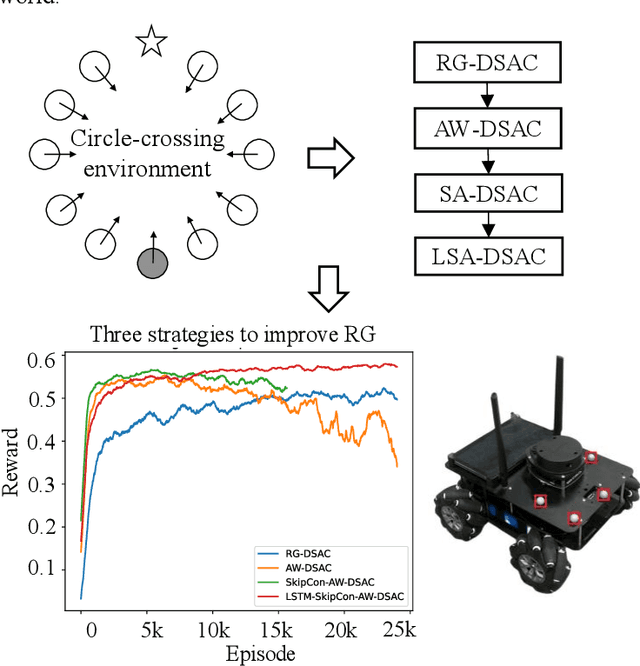
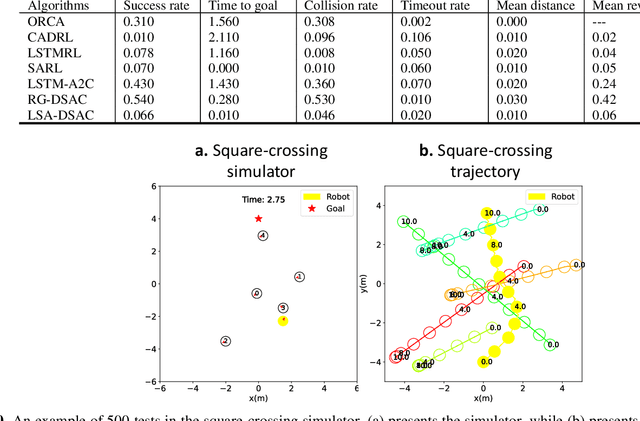

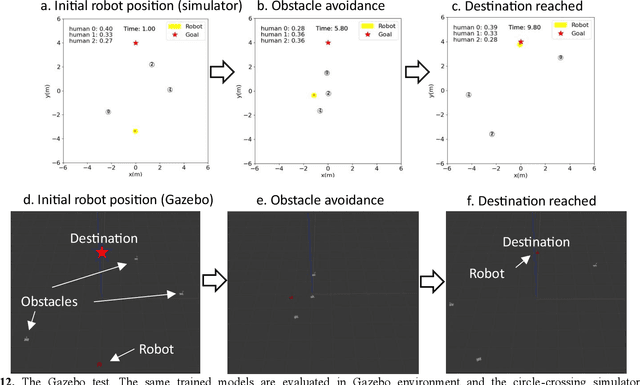
Motion planning is the soul of robot decision making. Classical planning algorithms like graph search and reaction-based algorithms face challenges in cases of dense and dynamic obstacles. Deep learning algorithms generate suboptimal one-step predictions that cause many collisions. Reinforcement learning algorithms generate optimal or near-optimal time-sequential predictions. However, they suffer from slow convergence, suboptimal converged results, and overfittings. This paper introduces a hybrid algorithm for robotic motion planning: long short-term memory (LSTM) pooling and skip connection for attention-based discrete soft actor critic (LSA-DSAC). First, graph network (relational graph) and attention network (attention weight) interpret the environmental state for the learning of the discrete soft actor critic algorithm. The expressive power of attention network outperforms that of graph in our task by difference analysis of these two representation methods. However, attention based DSAC faces the overfitting problem in training. Second, the skip connection method is integrated to attention based DSAC to mitigate overfitting and improve convergence speed. Third, LSTM pooling is taken to replace the sum operator of attention weigh and eliminate overfitting by slightly sacrificing convergence speed at early-stage training. Experiments show that LSA-DSAC outperforms the state-of-the-art in training and most evaluations. The physical robot is also implemented and tested in the real world.
DGC: Training Dynamic Graphs with Spatio-Temporal Non-Uniformity using Graph Partitioning by Chunks
Sep 07, 2023Dynamic Graph Neural Network (DGNN) has shown a strong capability of learning dynamic graphs by exploiting both spatial and temporal features. Although DGNN has recently received considerable attention by AI community and various DGNN models have been proposed, building a distributed system for efficient DGNN training is still challenging. It has been well recognized that how to partition the dynamic graph and assign workloads to multiple GPUs plays a critical role in training acceleration. Existing works partition a dynamic graph into snapshots or temporal sequences, which only work well when the graph has uniform spatio-temporal structures. However, dynamic graphs in practice are not uniformly structured, with some snapshots being very dense while others are sparse. To address this issue, we propose DGC, a distributed DGNN training system that achieves a 1.25x - 7.52x speedup over the state-of-the-art in our testbed. DGC's success stems from a new graph partitioning method that partitions dynamic graphs into chunks, which are essentially subgraphs with modest training workloads and few inter connections. This partitioning algorithm is based on graph coarsening, which can run very fast on large graphs. In addition, DGC has a highly efficient run-time, powered by the proposed chunk fusion and adaptive stale aggregation techniques. Extensive experimental results on 3 typical DGNN models and 4 popular dynamic graph datasets are presented to show the effectiveness of DGC.
Separable Self and Mixed Attention Transformers for Efficient Object Tracking
Sep 07, 2023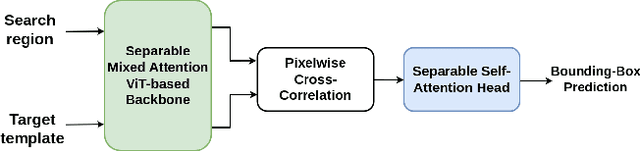

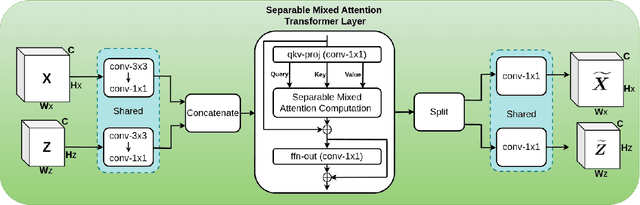
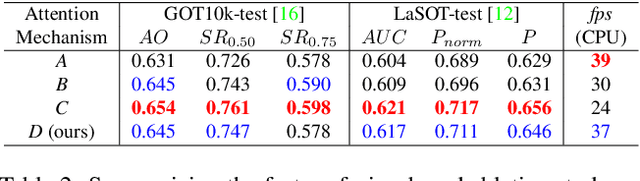
The deployment of transformers for visual object tracking has shown state-of-the-art results on several benchmarks. However, the transformer-based models are under-utilized for Siamese lightweight tracking due to the computational complexity of their attention blocks. This paper proposes an efficient self and mixed attention transformer-based architecture for lightweight tracking. The proposed backbone utilizes the separable mixed attention transformers to fuse the template and search regions during feature extraction to generate superior feature encoding. Our prediction head performs global contextual modeling of the encoded features by leveraging efficient self-attention blocks for robust target state estimation. With these contributions, the proposed lightweight tracker deploys a transformer-based backbone and head module concurrently for the first time. Our ablation study testifies to the effectiveness of the proposed combination of backbone and head modules. Simulations show that our Separable Self and Mixed Attention-based Tracker, SMAT, surpasses the performance of related lightweight trackers on GOT10k, TrackingNet, LaSOT, NfS30, UAV123, and AVisT datasets, while running at 37 fps on CPU, 158 fps on GPU, and having 3.8M parameters. For example, it significantly surpasses the closely related trackers E.T.Track and MixFormerV2-S on GOT10k-test by a margin of 7.9% and 5.8%, respectively, in the AO metric. The tracker code and model is available at https://github.com/goutamyg/SMAT
SRN-SZ: Deep Leaning-Based Scientific Error-bounded Lossy Compression with Super-resolution Neural Networks
Sep 07, 2023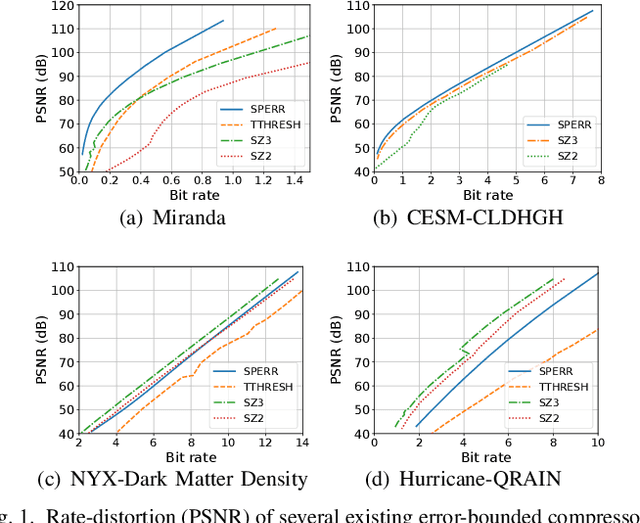
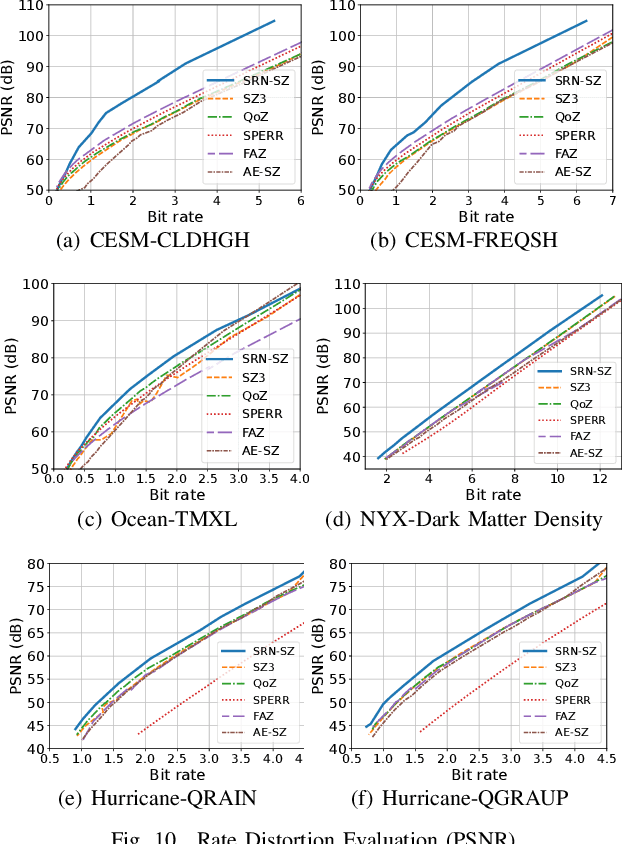
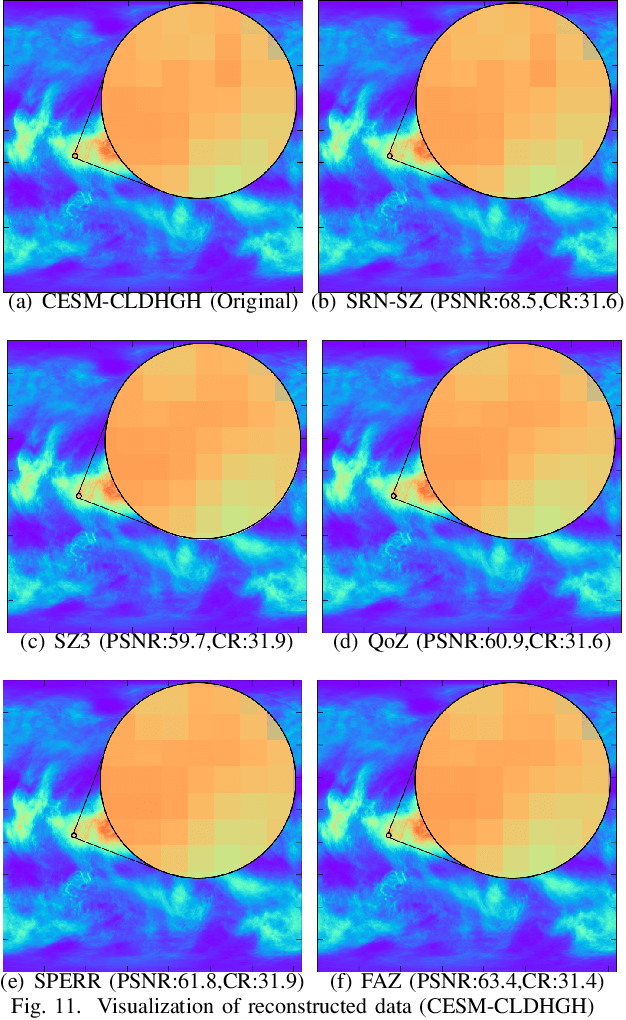
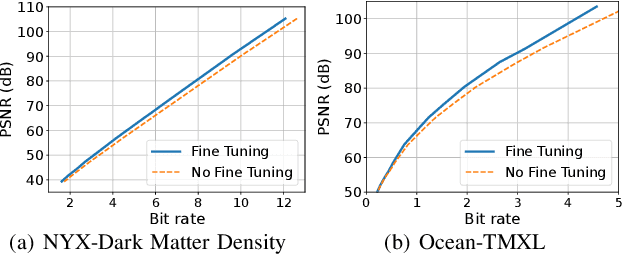
The fast growth of computational power and scales of modern super-computing systems have raised great challenges for the management of exascale scientific data. To maintain the usability of scientific data, error-bound lossy compression is proposed and developed as an essential technique for the size reduction of scientific data with constrained data distortion. Among the diverse datasets generated by various scientific simulations, certain datasets cannot be effectively compressed by existing error-bounded lossy compressors with traditional techniques. The recent success of Artificial Intelligence has inspired several researchers to integrate neural networks into error-bounded lossy compressors. However, those works still suffer from limited compression ratios and/or extremely low efficiencies. To address those issues and improve the compression on the hard-to-compress datasets, in this paper, we propose SRN-SZ, which is a deep learning-based scientific error-bounded lossy compressor leveraging the hierarchical data grid expansion paradigm implemented by super-resolution neural networks. SRN-SZ applies the most advanced super-resolution network HAT for its compression, which is free of time-costing per-data training. In experiments compared with various state-of-the-art compressors, SRN-SZ achieves up to 75% compression ratio improvements under the same error bound and up to 80% compression ratio improvements under the same PSNR than the second-best compressor.
A Generic Machine Learning Framework for Fully-Unsupervised Anomaly Detection with Contaminated Data
Sep 07, 2023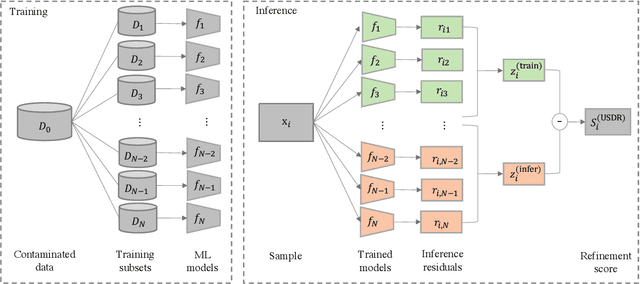
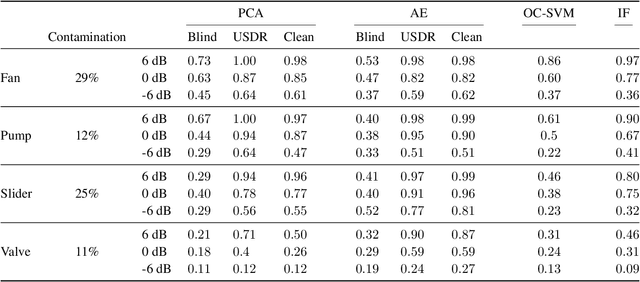
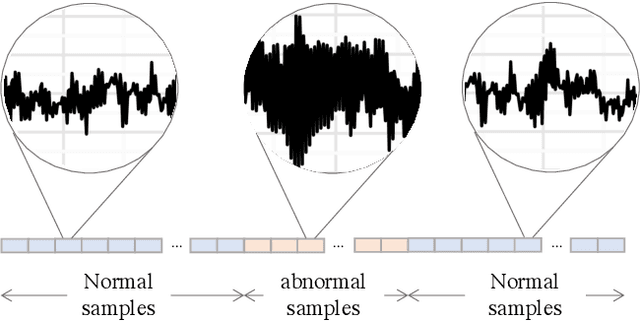
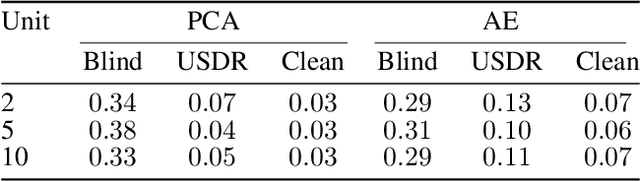
Anomaly detection (AD) tasks have been solved using machine learning algorithms in various domains and applications. The great majority of these algorithms use normal data to train a residual-based model, and assign anomaly scores to unseen samples based on their dissimilarity with the learned normal regime. The underlying assumption of these approaches is that anomaly-free data is available for training. This is, however, often not the case in real-world operational settings, where the training data may be contaminated with a certain fraction of abnormal samples. Training with contaminated data, in turn, inevitably leads to a deteriorated AD performance of the residual-based algorithms. In this paper we introduce a framework for a fully unsupervised refinement of contaminated training data for AD tasks. The framework is generic and can be applied to any residual-based machine learning model. We demonstrate the application of the framework to two public datasets of multivariate time series machine data from different application fields. We show its clear superiority over the naive approach of training with contaminated data without refinement. Moreover, we compare it to the ideal, unrealistic reference in which anomaly-free data would be available for training. Since the approach exploits information from the anomalies, and not only from the normal regime, it is comparable and often outperforms the ideal baseline as well.
ColNav: Real-Time Colon Navigation for Colonoscopy
Jun 07, 2023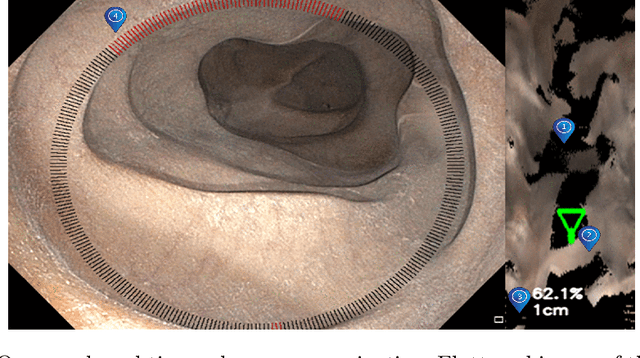


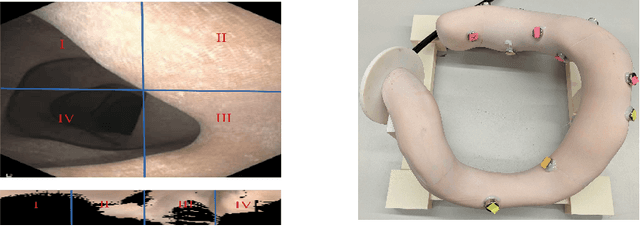
Colorectal cancer screening through colonoscopy continues to be the dominant global standard, as it allows identifying pre-cancerous or adenomatous lesions and provides the ability to remove them during the procedure itself. Nevertheless, failure by the endoscopist to identify such lesions increases the likelihood of lesion progression to subsequent colorectal cancer. Ultimately, colonoscopy remains operator-dependent, and the wide range of quality in colonoscopy examinations among endoscopists is influenced by variations in their technique, training, and diligence. This paper presents a novel real-time navigation guidance system for Optical Colonoscopy (OC). Our proposed system employs a real-time approach that displays both an unfolded representation of the colon and a local indicator directing to un-inspected areas. These visualizations are presented to the physician during the procedure, providing actionable and comprehensible guidance to un-surveyed areas in real-time, while seamlessly integrating into the physician's workflow. Through coverage experimental evaluation, we demonstrated that our system resulted in a higher polyp recall (PR) and high inter-rater reliability with physicians for coverage prediction. These results suggest that our real-time navigation guidance system has the potential to improve the quality and effectiveness of Optical Colonoscopy and ultimately benefit patient outcomes.
Time-Optimal Path Tracking with ISO Safety Guarantees
Jun 08, 2023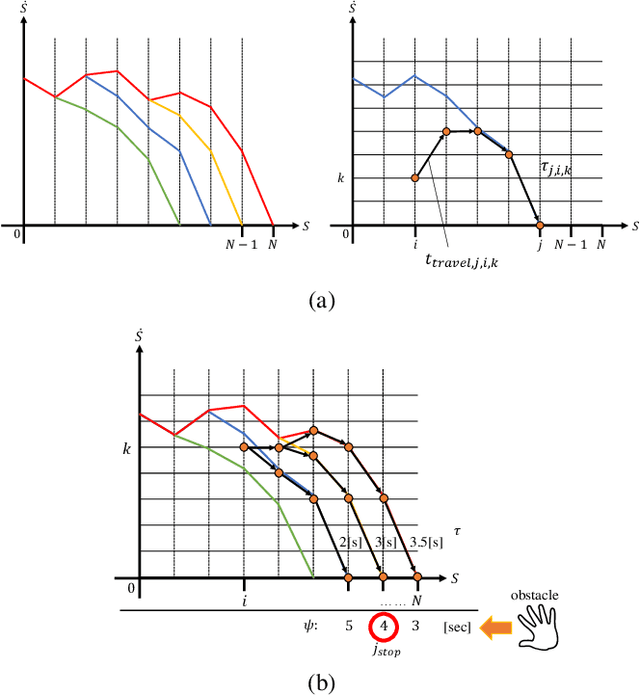
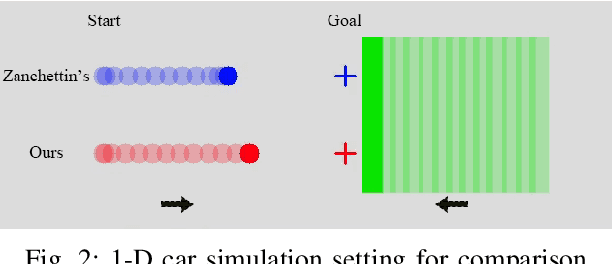
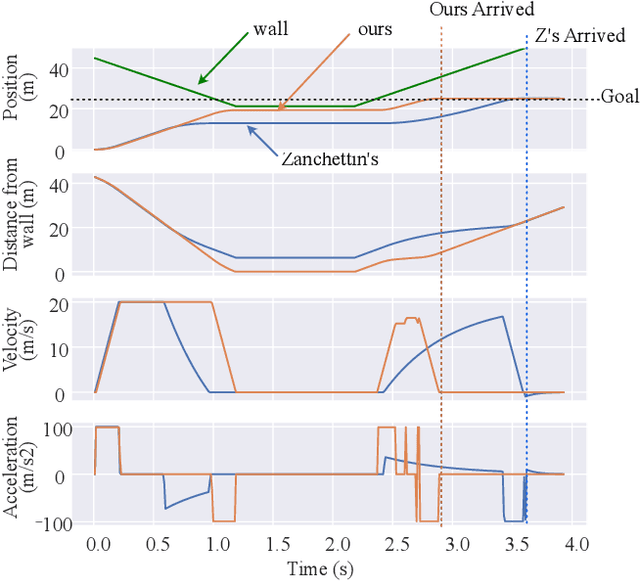
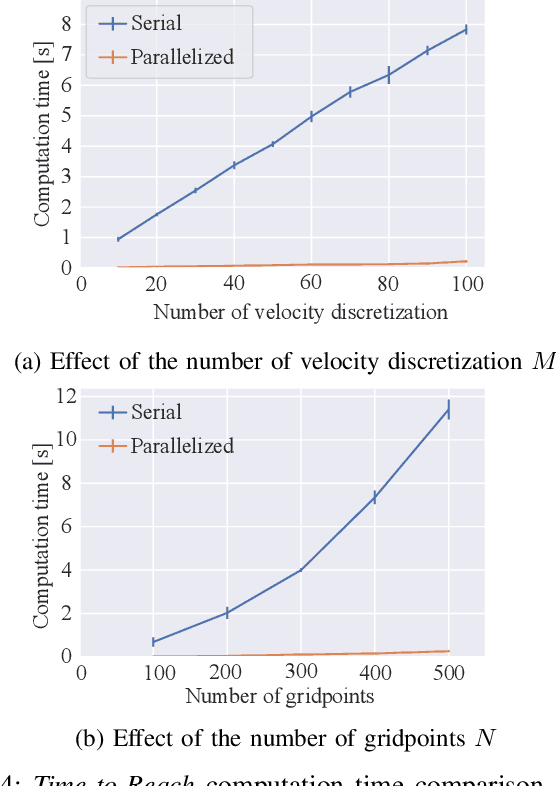
One way of ensuring operator's safety during human-robot collaboration is through Speed and Separation Monitoring (SSM), as defined in ISO standard ISO/TS 15066. In general, it is impossible to avoid all human-robot collisions: consider for instance the case when the robot does not move at all, a human operator can still collide with it by hitting it of her own voluntary motion. In the SSM framework, it is possible however to minimize harm by requiring this: \emph{if} a collision ever occurs, then the robot must be in a \emph{stationary state} (all links have zero velocity) at the time instant of the collision. In this paper, we propose a time-optimal control policy based on Time-Optimal Path Parameterization (TOPP) to guarantee such a behavior. Specifically, we show that: for any robot motion that is strictly faster than the motion recommended by our policy, there exists a human motion that results in a collision with the robot in a non-stationary state. Correlatively, we show, in simulation, that our policy is strictly less conservative than state-of-the-art safe robot control methods. Additionally, we propose a parallelization method to reduce the computation time of our pre-computation phase (down to 0.5 sec, practically), which enables the whole pipeline (including the pre-computation) to be executed at runtime, nearly in real-time. Finally, we demonstrate the application of our method in a scenario: time-optimal, safe control of a 6-dof industrial robot.
A Recycling Training Strategy for Medical Image Segmentation with Diffusion Denoising Models
Aug 30, 2023Denoising diffusion models have found applications in image segmentation by generating segmented masks conditioned on images. Existing studies predominantly focus on adjusting model architecture or improving inference such as test-time sampling strategies. In this work, we focus on training strategy improvements and propose a novel recycling method. During each training step, a segmentation mask is first predicted given an image and a random noise. This predicted mask, replacing the conventional ground truth mask, is used for denoising task during training. This approach can be interpreted as aligning the training strategy with inference by eliminating the dependence on ground truth masks for generating noisy samples. Our proposed method significantly outperforms standard diffusion training, self-conditioning, and existing recycling strategies across multiple medical imaging data sets: muscle ultrasound, abdominal CT, prostate MR, and brain MR. This holds true for two widely adopted sampling strategies: denoising diffusion probabilistic model and denoising diffusion implicit model. Importantly, existing diffusion models often display a declining or unstable performance during inference, whereas our novel recycling consistently enhances or maintains performance. Furthermore, we show for the first time that, under a fair comparison with the same network architectures and computing budget, the proposed recycling-based diffusion models achieved on-par performance with non-diffusion-based supervised training. This paper summarises these quantitative results and discusses their values, with a fully reproducible JAX-based implementation, released at https://github.com/mathpluscode/ImgX-DiffSeg.
Learned Full Waveform Inversion Incorporating Task Information for Ultrasound Computed Tomography
Aug 30, 2023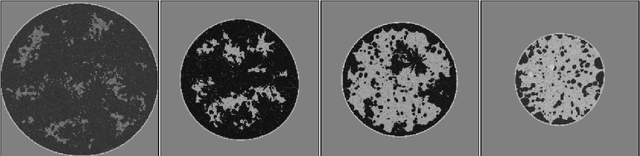
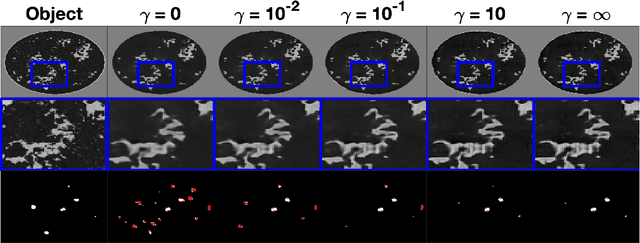
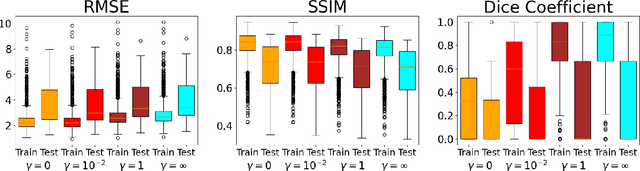
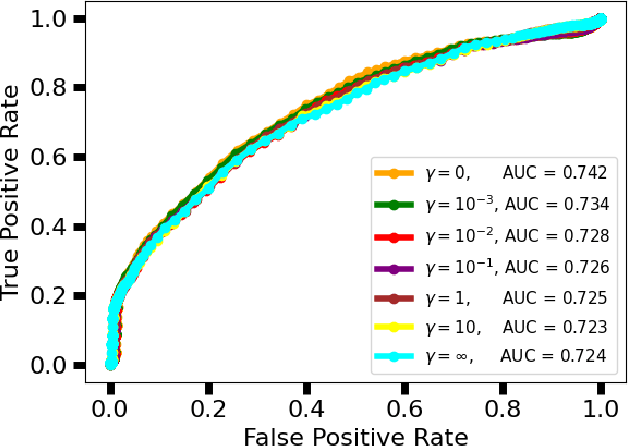
Ultrasound computed tomography (USCT) is an emerging imaging modality that holds great promise for breast imaging. Full-waveform inversion (FWI)-based image reconstruction methods incorporate accurate wave physics to produce high spatial resolution quantitative images of speed of sound or other acoustic properties of the breast tissues from USCT measurement data. However, the high computational cost of FWI reconstruction represents a significant burden for its widespread application in a clinical setting. The research reported here investigates the use of a convolutional neural network (CNN) to learn a mapping from USCT waveform data to speed of sound estimates. The CNN was trained using a supervised approach with a task-informed loss function aiming at preserving features of the image that are relevant to the detection of lesions. A large set of anatomically and physiologically realistic numerical breast phantoms (NBPs) and corresponding simulated USCT measurements was employed during training. Once trained, the CNN can perform real-time FWI image reconstruction from USCT waveform data. The performance of the proposed method was assessed and compared against FWI using a hold-out sample of 41 NBPs and corresponding USCT data. Accuracy was measured using relative mean square error (RMSE), structural self-similarity index measure (SSIM), and lesion detection performance (DICE score). This numerical experiment demonstrates that a supervised learning model can achieve accuracy comparable to FWI in terms of RMSE and SSIM, and better performance in terms of task performance, while significantly reducing computational time.
LTLf Synthesis Under Environment Specifications for Reachability and Safety Properties
Aug 29, 2023In this paper, we study LTLf synthesis under environment specifications for arbitrary reachability and safety properties. We consider both kinds of properties for both agent tasks and environment specifications, providing a complete landscape of synthesis algorithms. For each case, we devise a specific algorithm (optimal wrt complexity of the problem) and prove its correctness. The algorithms combine common building blocks in different ways. While some cases are already studied in literature others are studied here for the first time.