 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Neuromorphic Auditory Perception by Neural Spiketrum
Sep 11, 2023
Neuromorphic computing holds the promise to achieve the energy efficiency and robust learning performance of biological neural systems. To realize the promised brain-like intelligence, it needs to solve the challenges of the neuromorphic hardware architecture design of biological neural substrate and the hardware amicable algorithms with spike-based encoding and learning. Here we introduce a neural spike coding model termed spiketrum, to characterize and transform the time-varying analog signals, typically auditory signals, into computationally efficient spatiotemporal spike patterns. It minimizes the information loss occurring at the analog-to-spike transformation and possesses informational robustness to neural fluctuations and spike losses. The model provides a sparse and efficient coding scheme with precisely controllable spike rate that facilitates training of spiking neural networks in various auditory perception tasks. We further investigate the algorithm-hardware co-designs through a neuromorphic cochlear prototype which demonstrates that our approach can provide a systematic solution for spike-based artificial intelligence by fully exploiting its advantages with spike-based computation.
Stochastic Configuration Machines for Industrial Artificial Intelligence
Sep 11, 2023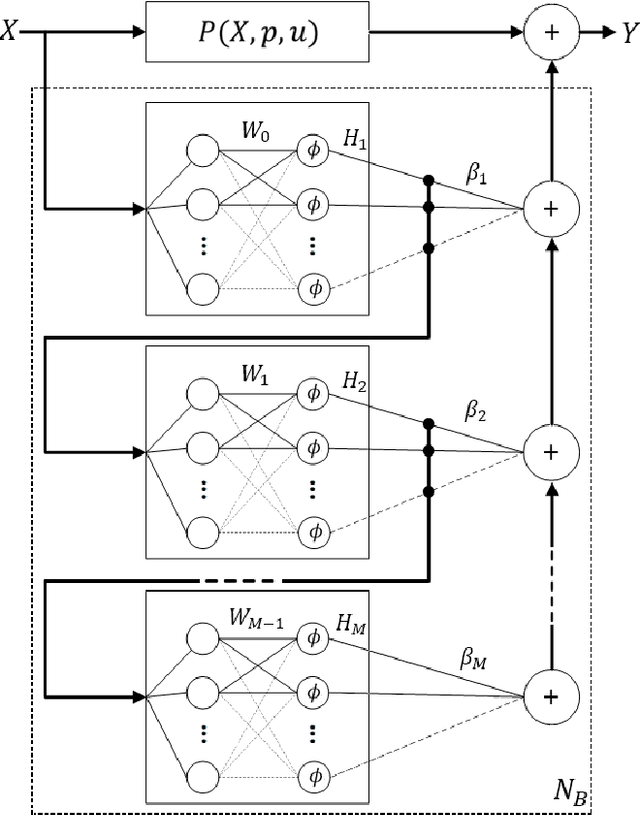
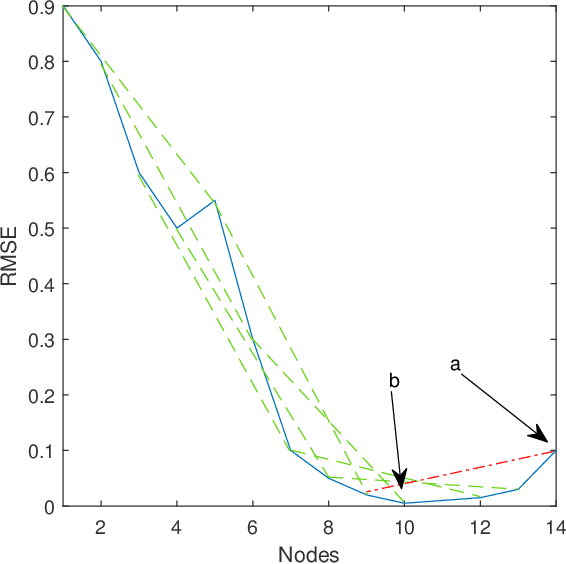
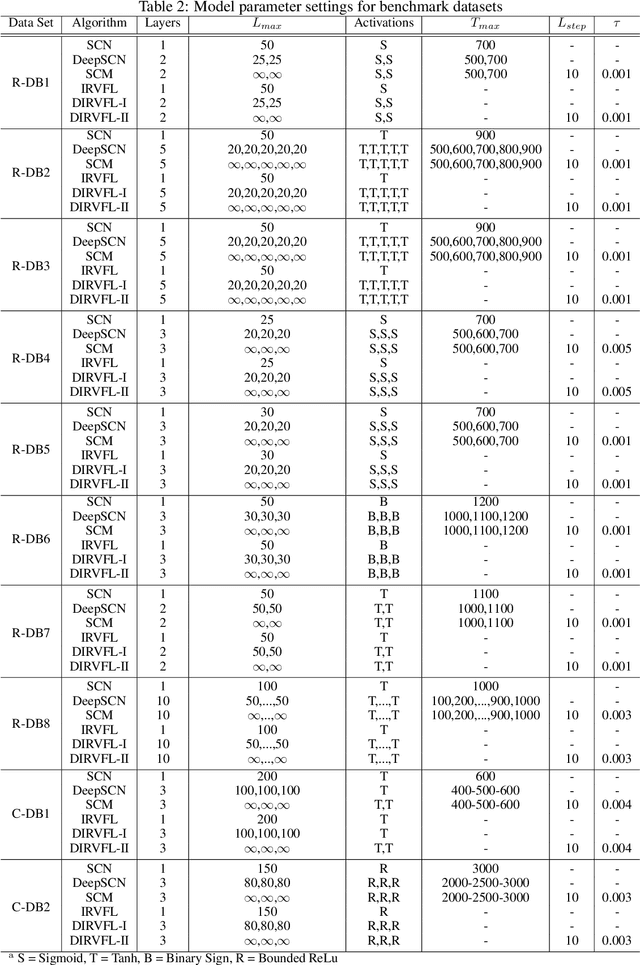
Real-time predictive modelling with desired accuracy is highly expected in industrial artificial intelligence (IAI), where neural networks play a key role. Neural networks in IAI require powerful, high-performance computing devices to operate a large number of floating point data. Based on stochastic configuration networks (SCNs), this paper proposes a new randomized learner model, termed stochastic configuration machines (SCMs), to stress effective modelling and data size saving that are useful and valuable for industrial applications. Compared to SCNs and random vector functional-link (RVFL) nets with binarized implementation, the model storage of SCMs can be significantly compressed while retaining favourable prediction performance. Besides the architecture of the SCM learner model and its learning algorithm, as an important part of this contribution, we also provide a theoretical basis on the learning capacity of SCMs by analysing the model's complexity. Experimental studies are carried out over some benchmark datasets and three industrial applications. The results demonstrate that SCM has great potential for dealing with industrial data analytics.
Minuteman: Machine and Human Joining Forces in Meeting Summarization
Sep 11, 2023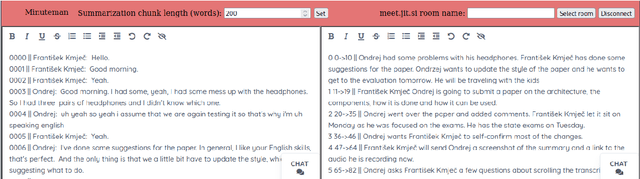


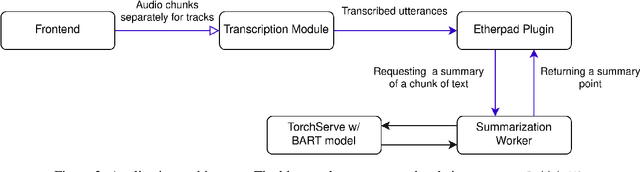
Many meetings require creating a meeting summary to keep everyone up to date. Creating minutes of sufficient quality is however very cognitively demanding. Although we currently possess capable models for both audio speech recognition (ASR) and summarization, their fully automatic use is still problematic. ASR models frequently commit errors when transcribing named entities while the summarization models tend to hallucinate and misinterpret the transcript. We propose a novel tool -- Minuteman -- to enable efficient semi-automatic meeting minuting. The tool provides a live transcript and a live meeting summary to the users, who can edit them in a collaborative manner, enabling correction of ASR errors and imperfect summary points in real time. The resulting application eases the cognitive load of the notetakers and allows them to easily catch up if they missed a part of the meeting due to absence or a lack of focus. We conduct several tests of the application in varied settings, exploring the worthiness of the concept and the possible user strategies.
A DRL-based Reflection Enhancement Method for RIS-assisted Multi-receiver Communications
Sep 11, 2023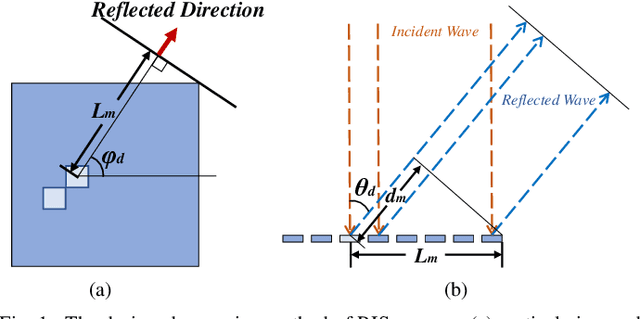

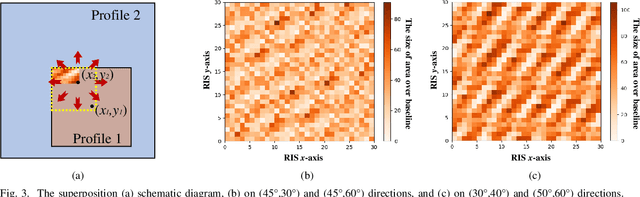
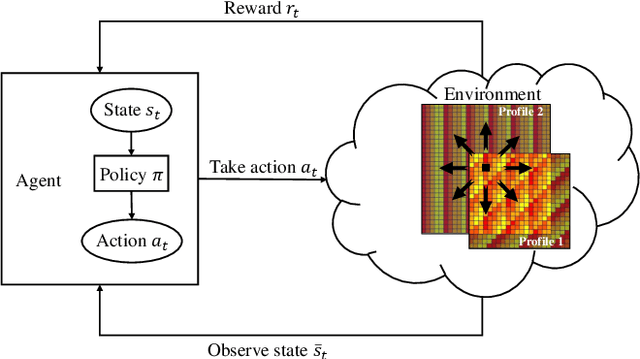
In reconfigurable intelligent surface (RIS)-assisted wireless communication systems, the pointing accuracy and intensity of reflections depend crucially on the 'profile,' representing the amplitude/phase state information of all elements in a RIS array. The superposition of multiple single-reflection profiles enables multi-reflection for distributed users. However, the optimization challenges from periodic element arrangements in single-reflection and multi-reflection profiles are understudied. The combination of periodical single-reflection profiles leads to amplitude/phase counteractions, affecting the performance of each reflection beam. This paper focuses on a dual-reflection optimization scenario and investigates the far-field performance deterioration caused by the misalignment of overlapped profiles. To address this issue, we introduce a novel deep reinforcement learning (DRL)-based optimization method. Comparative experiments against random and exhaustive searches demonstrate that our proposed DRL method outperforms both alternatives, achieving the shortest optimization time. Remarkably, our approach achieves a 1.2 dB gain in the reflection peak gain and a broader beam without any hardware modifications.
A class of non linear adaptive time-frequency transforms
Jun 26, 2023This paper introduces a couple of new time-frequency transforms, designed to adapt their scale to specific features of the analyzed function. Such an adaptation is implemented via so-called focus functions, which control the window scale as a function of the time variable, or the frequency variable. In this respect, these transforms are non-linear, which makes the analysis more complex than usual.Under appropriate assumptions, some norm control can be obtained for both transforms in L^2(R) spaces, which extend the classical continuous frame norm control and guarantees well-definedness on L^2. Given the non-linearity of the transforms, the existence of inverse transforms is not guaranteed anymore, and is an open question. However, the results of this paper represent a first step towards a more general theory.Besides mathematical results, some elementary examples of time and frequency focus functions are provided, which can serve as staring point for concrete applications.
MaskRenderer: 3D-Infused Multi-Mask Realistic Face Reenactment
Sep 10, 2023
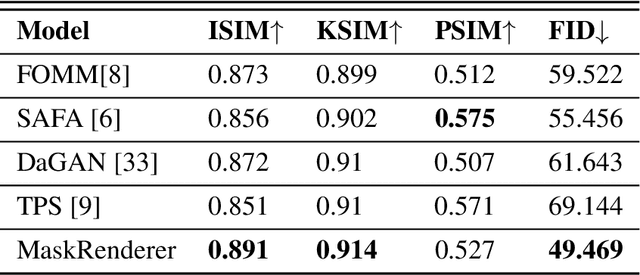
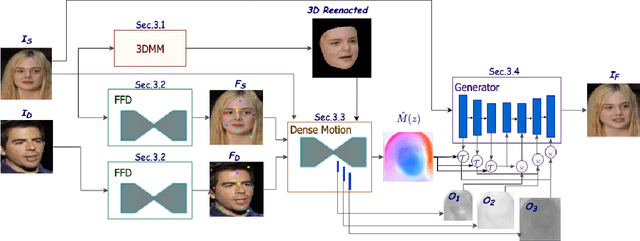
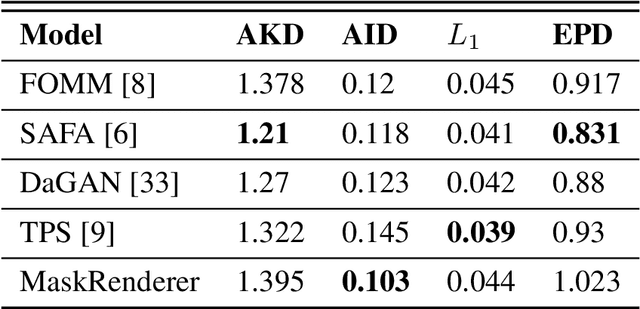
We present a novel end-to-end identity-agnostic face reenactment system, MaskRenderer, that can generate realistic, high fidelity frames in real-time. Although recent face reenactment works have shown promising results, there are still significant challenges such as identity leakage and imitating mouth movements, especially for large pose changes and occluded faces. MaskRenderer tackles these problems by using (i) a 3DMM to model 3D face structure to better handle pose changes, occlusion, and mouth movements compared to 2D representations; (ii) a triplet loss function to embed the cross-reenactment during training for better identity preservation; and (iii) multi-scale occlusion, improving inpainting and restoring missing areas. Comprehensive quantitative and qualitative experiments conducted on the VoxCeleb1 test set, demonstrate that MaskRenderer outperforms state-of-the-art models on unseen faces, especially when the Source and Driving identities are very different.
Sculpting Efficiency: Pruning Medical Imaging Models for On-Device Inference
Sep 10, 2023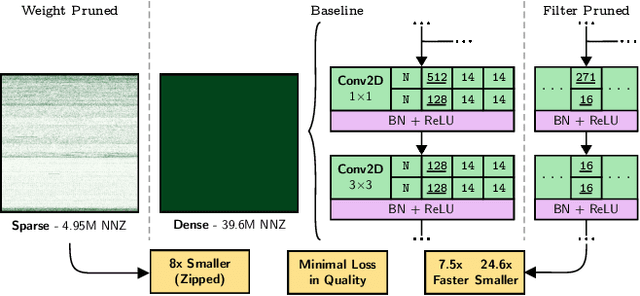
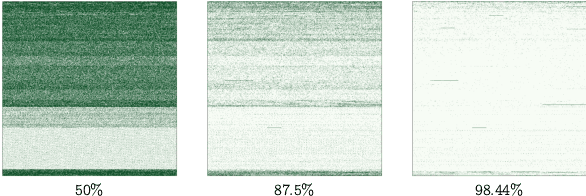

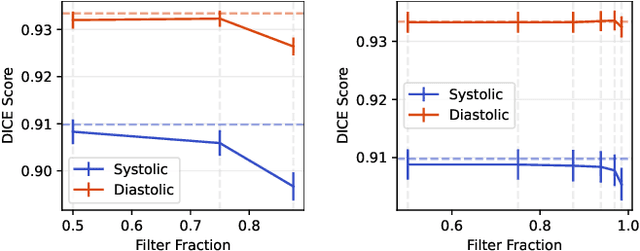
Applying ML advancements to healthcare can improve patient outcomes. However, the sheer operational complexity of ML models, combined with legacy hardware and multi-modal gigapixel images, poses a severe deployment limitation for real-time, on-device inference. We consider filter pruning as a solution, exploring segmentation models in cardiology and ophthalmology. Our preliminary results show a compression rate of up to 1148x with minimal loss in quality, stressing the need to consider task complexity and architectural details when using off-the-shelf models. At high compression rates, filter-pruned models exhibit faster inference on a CPU than the GPU baseline. We also demonstrate that such models' robustness and generalisability characteristics exceed that of the baseline and weight-pruned counterparts. We uncover intriguing questions and take a step towards realising cost-effective disease diagnosis, monitoring, and preventive solutions.
Benchmarking ground truth trajectories with robotic total stations
Sep 10, 2023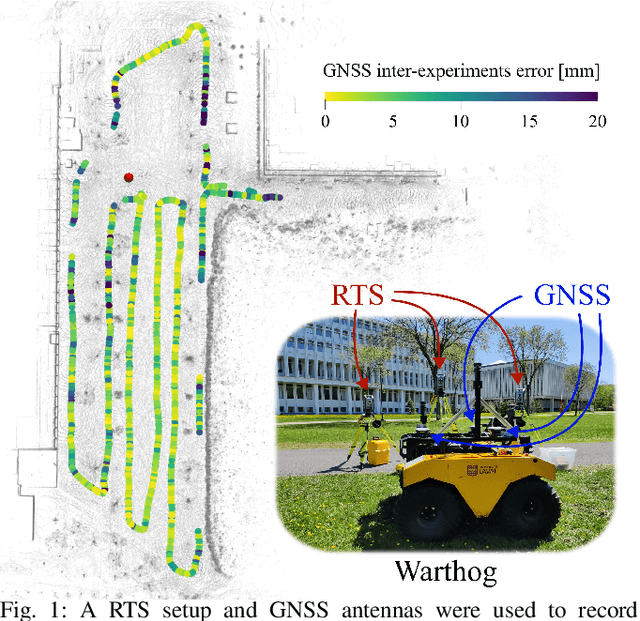
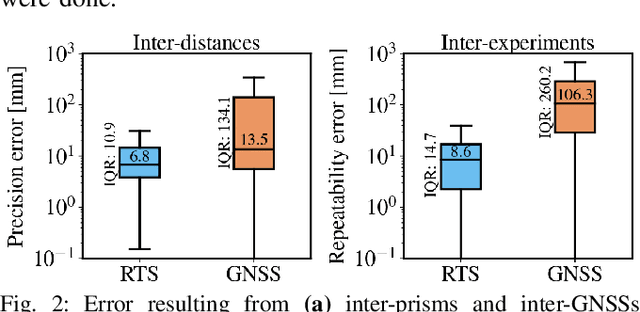
Benchmarks stand as vital cornerstones in elevating SLAM algorithms within mobile robotics. Consequently, ensuring accurate and reproducible ground truth generation is vital for fair evaluation. A majority of outdoor ground truths are generated by GNSS, which can lead to discrepancies over time, especially in covered areas. However, research showed that RTS setups are more precise and can alternatively be used to generate these ground truths. In our work, we compare both RTS and GNSS systems' precision and repeatability through a set of experiments conducted weeks and months apart in the same area. We demonstrated that RTS setups give more reproducible results, with disparities having a median value of 8.6 mm compared to a median value of 10.6 cm coming from a GNSS setup. These results highlight that RTS can be considered to benchmark process for SLAM algorithms with higher precision.
Efficiently Robustify Pre-trained Models
Sep 14, 2023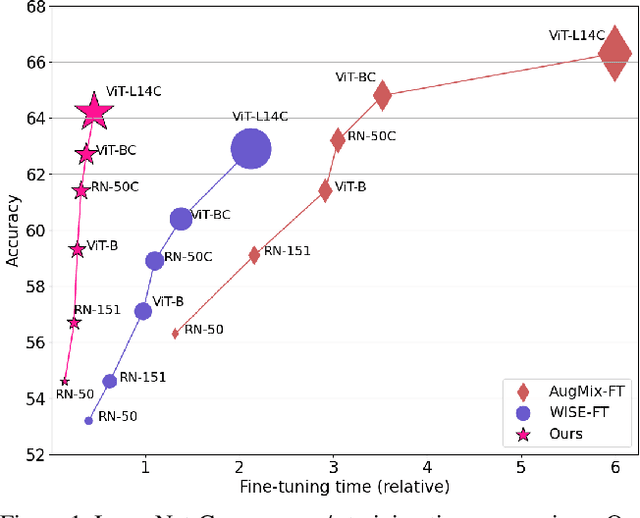
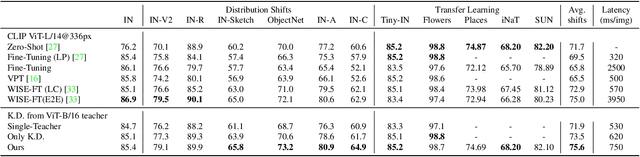
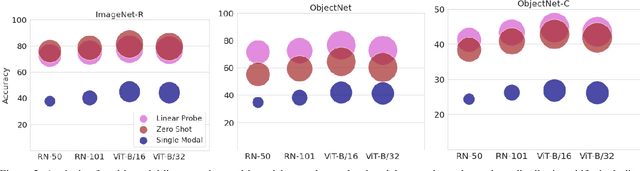

A recent trend in deep learning algorithms has been towards training large scale models, having high parameter count and trained on big dataset. However, robustness of such large scale models towards real-world settings is still a less-explored topic. In this work, we first benchmark the performance of these models under different perturbations and datasets thereby representing real-world shifts, and highlight their degrading performance under these shifts. We then discuss on how complete model fine-tuning based existing robustification schemes might not be a scalable option given very large scale networks and can also lead them to forget some of the desired characterstics. Finally, we propose a simple and cost-effective method to solve this problem, inspired by knowledge transfer literature. It involves robustifying smaller models, at a lower computation cost, and then use them as teachers to tune a fraction of these large scale networks, reducing the overall computational overhead. We evaluate our proposed method under various vision perturbations including ImageNet-C,R,S,A datasets and also for transfer learning, zero-shot evaluation setups on different datasets. Benchmark results show that our method is able to induce robustness to these large scale models efficiently, requiring significantly lower time and also preserves the transfer learning, zero-shot properties of the original model which none of the existing methods are able to achieve.
Applying Deep Learning to Calibrate Stochastic Volatility Models
Sep 14, 2023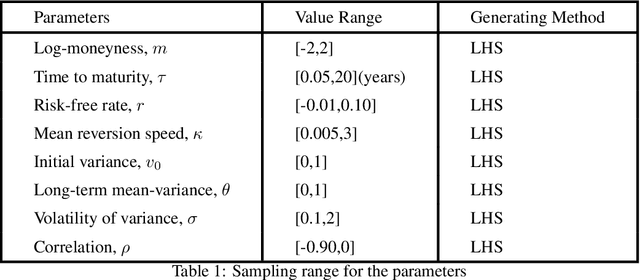

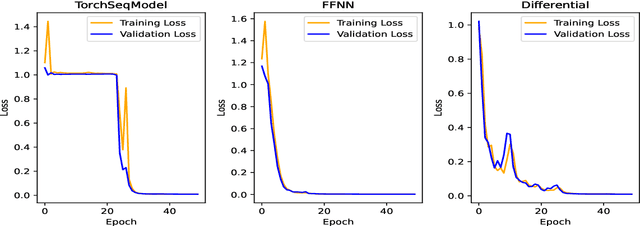
Stochastic volatility models, where the volatility is a stochastic process, can capture most of the essential stylized facts of implied volatility surfaces and give more realistic dynamics of the volatility smile or skew. However, they come with the significant issue that they take too long to calibrate. Alternative calibration methods based on Deep Learning (DL) techniques have been recently used to build fast and accurate solutions to the calibration problem. Huge and Savine developed a Differential Deep Learning (DDL) approach, where Machine Learning models are trained on samples of not only features and labels but also differentials of labels to features. The present work aims to apply the DDL technique to price vanilla European options (i.e. the calibration instruments), more specifically, puts when the underlying asset follows a Heston model and then calibrate the model on the trained network. DDL allows for fast training and accurate pricing. The trained neural network dramatically reduces Heston calibration's computation time. In this work, we also introduce different regularisation techniques, and we apply them notably in the case of the DDL. We compare their performance in reducing overfitting and improving the generalisation error. The DDL performance is also compared to the classical DL (without differentiation) one in the case of Feed-Forward Neural Networks. We show that the DDL outperforms the DL.