 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Getting too personal(ized): The importance of feature choice in online adaptive algorithms
Sep 06, 2023
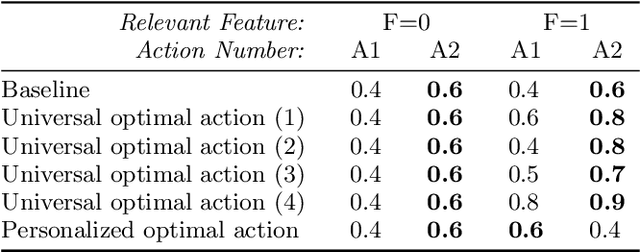
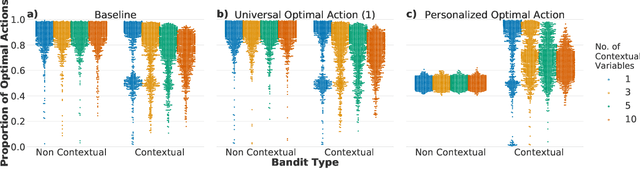

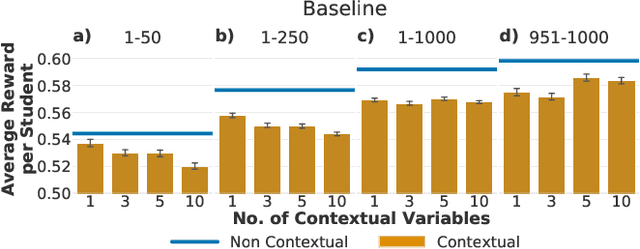
Digital educational technologies offer the potential to customize students' experiences and learn what works for which students, enhancing the technology as more students interact with it. We consider whether and when attempting to discover how to personalize has a cost, such as if the adaptation to personal information can delay the adoption of policies that benefit all students. We explore these issues in the context of using multi-armed bandit (MAB) algorithms to learn a policy for what version of an educational technology to present to each student, varying the relation between student characteristics and outcomes and also whether the algorithm is aware of these characteristics. Through simulations, we demonstrate that the inclusion of student characteristics for personalization can be beneficial when those characteristics are needed to learn the optimal action. In other scenarios, this inclusion decreases performance of the bandit algorithm. Moreover, including unneeded student characteristics can systematically disadvantage students with less common values for these characteristics. Our simulations do however suggest that real-time personalization will be helpful in particular real-world scenarios, and we illustrate this through case studies using existing experimental results in ASSISTments. Overall, our simulations show that adaptive personalization in educational technologies can be a double-edged sword: real-time adaptation improves student experiences in some contexts, but the slower adaptation and potentially discriminatory results mean that a more personalized model is not always beneficial.
Multiclass Alignment of Confidence and Certainty for Network Calibration
Sep 06, 2023Deep neural networks (DNNs) have made great strides in pushing the state-of-the-art in several challenging domains. Recent studies reveal that they are prone to making overconfident predictions. This greatly reduces the overall trust in model predictions, especially in safety-critical applications. Early work in improving model calibration employs post-processing techniques which rely on limited parameters and require a hold-out set. Some recent train-time calibration methods, which involve all model parameters, can outperform the postprocessing methods. To this end, we propose a new train-time calibration method, which features a simple, plug-and-play auxiliary loss known as multi-class alignment of predictive mean confidence and predictive certainty (MACC). It is based on the observation that a model miscalibration is directly related to its predictive certainty, so a higher gap between the mean confidence and certainty amounts to a poor calibration both for in-distribution and out-of-distribution predictions. Armed with this insight, our proposed loss explicitly encourages a confident (or underconfident) model to also provide a low (or high) spread in the presoftmax distribution. Extensive experiments on ten challenging datasets, covering in-domain, out-domain, non-visual recognition and medical image classification scenarios, show that our method achieves state-of-the-art calibration performance for both in-domain and out-domain predictions. Our code and models will be publicly released.
Efficient Memory Management for Large Language Model Serving with PagedAttention
Sep 12, 2023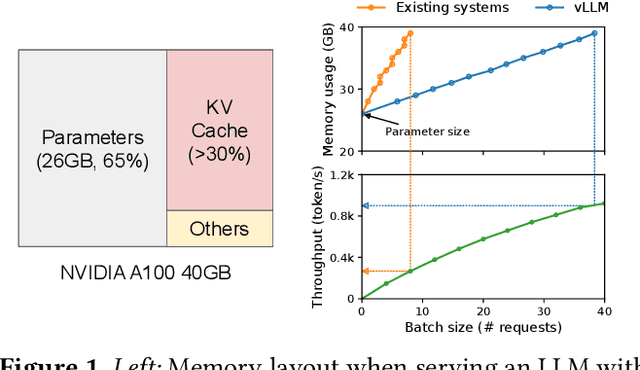
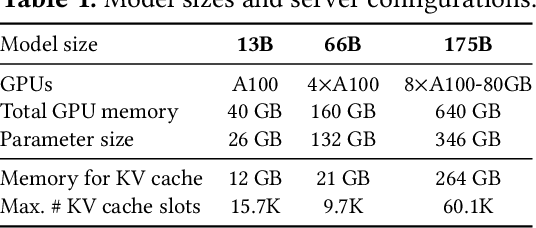
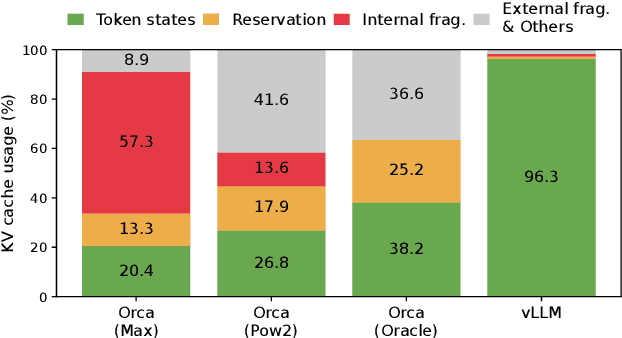

High throughput serving of large language models (LLMs) requires batching sufficiently many requests at a time. However, existing systems struggle because the key-value cache (KV cache) memory for each request is huge and grows and shrinks dynamically. When managed inefficiently, this memory can be significantly wasted by fragmentation and redundant duplication, limiting the batch size. To address this problem, we propose PagedAttention, an attention algorithm inspired by the classical virtual memory and paging techniques in operating systems. On top of it, we build vLLM, an LLM serving system that achieves (1) near-zero waste in KV cache memory and (2) flexible sharing of KV cache within and across requests to further reduce memory usage. Our evaluations show that vLLM improves the throughput of popular LLMs by 2-4$\times$ with the same level of latency compared to the state-of-the-art systems, such as FasterTransformer and Orca. The improvement is more pronounced with longer sequences, larger models, and more complex decoding algorithms. vLLM's source code is publicly available at https://github.com/vllm-project/vllm
A Distributed Data-Parallel PyTorch Implementation of the Distributed Shampoo Optimizer for Training Neural Networks At-Scale
Sep 12, 2023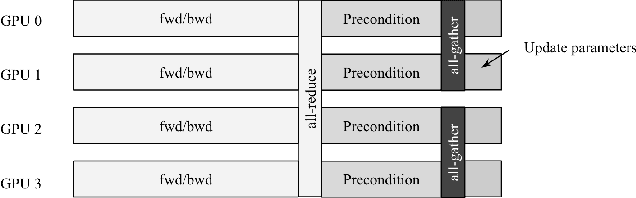

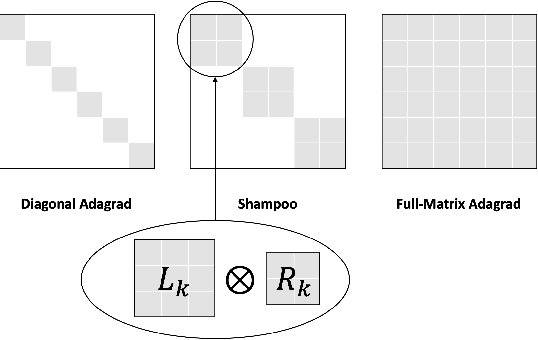
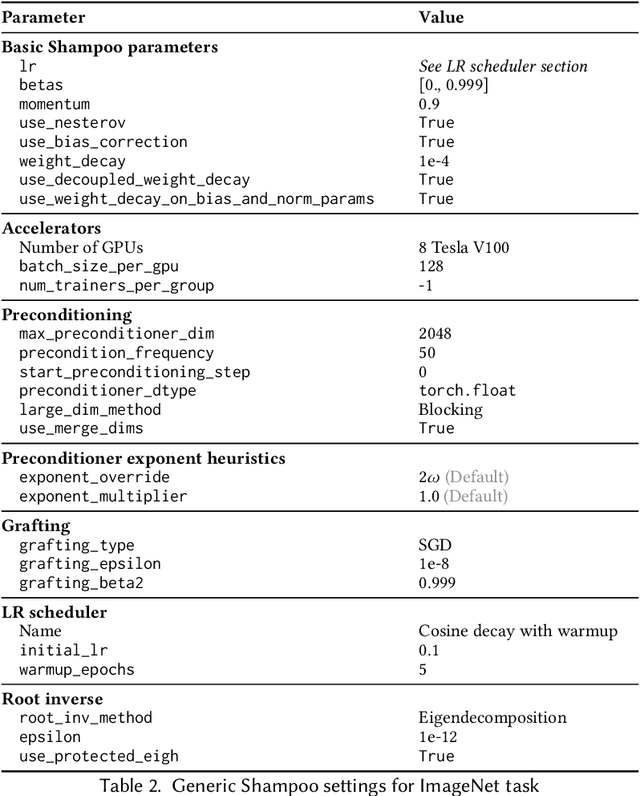
Shampoo is an online and stochastic optimization algorithm belonging to the AdaGrad family of methods for training neural networks. It constructs a block-diagonal preconditioner where each block consists of a coarse Kronecker product approximation to full-matrix AdaGrad for each parameter of the neural network. In this work, we provide a complete description of the algorithm as well as the performance optimizations that our implementation leverages to train deep networks at-scale in PyTorch. Our implementation enables fast multi-GPU distributed data-parallel training by distributing the memory and computation associated with blocks of each parameter via PyTorch's DTensor data structure and performing an AllGather primitive on the computed search directions at each iteration. This major performance enhancement enables us to achieve at most a 10% performance reduction in per-step wall-clock time compared against standard diagonal-scaling-based adaptive gradient methods. We validate our implementation by performing an ablation study on training ImageNet ResNet50, demonstrating Shampoo's superiority over standard training recipes with minimal hyperparameter tuning.
Non-smooth Control Barrier Functions for Stochastic Dynamical Systems
Sep 12, 2023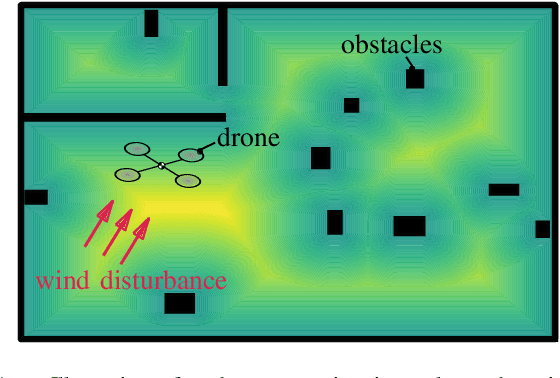
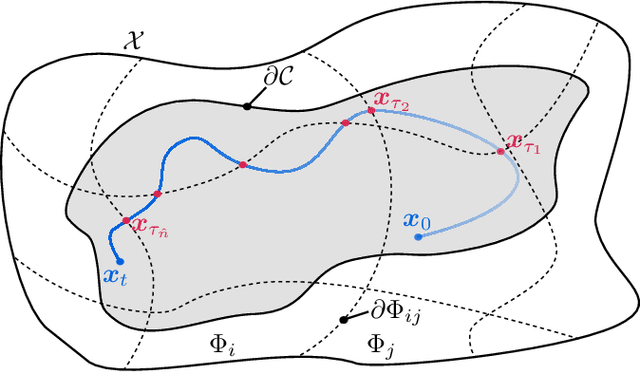
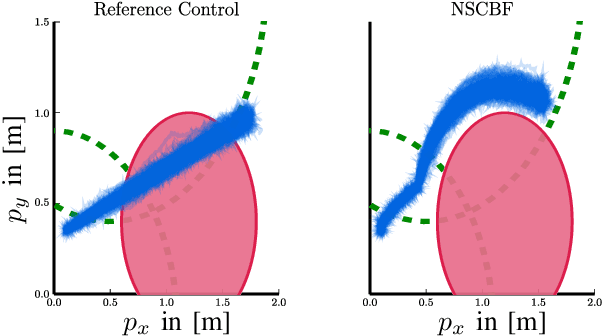
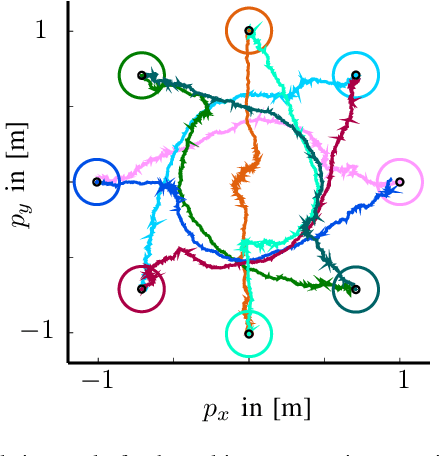
Uncertainties arising in various control systems, such as robots that are subject to unknown disturbances or environmental variations, pose significant challenges for ensuring system safety, such as collision avoidance. At the same time, safety specifications are getting more and more complex, e.g., by composing multiple safety objectives through Boolean operators resulting in non-smooth descriptions of safe sets. Control Barrier Functions (CBFs) have emerged as a control technique to provably guarantee system safety. In most settings, they rely on an assumption of having deterministic dynamics and smooth safe sets. This paper relaxes these two assumptions by extending CBFs to encompass control systems with stochastic dynamics and safe sets defined by non-smooth functions. By explicitly considering the stochastic nature of system dynamics and accommodating complex safety specifications, our method enables the design of safe control strategies in uncertain and complex systems. We provide formal guarantees on the safety of the system by leveraging the theoretical foundations of stochastic CBFs and non-smooth safe sets. Numerical simulations demonstrate the effectiveness of the approach in various scenarios.
LEAP Hand: Low-Cost, Efficient, and Anthropomorphic Hand for Robot Learning
Sep 12, 2023


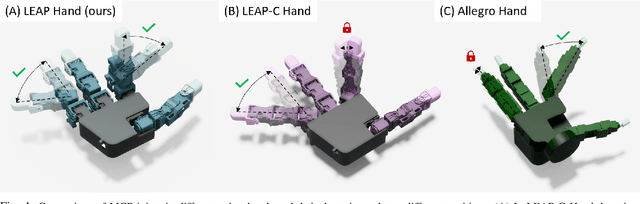
Dexterous manipulation has been a long-standing challenge in robotics. While machine learning techniques have shown some promise, results have largely been currently limited to simulation. This can be mostly attributed to the lack of suitable hardware. In this paper, we present LEAP Hand, a low-cost dexterous and anthropomorphic hand for machine learning research. In contrast to previous hands, LEAP Hand has a novel kinematic structure that allows maximal dexterity regardless of finger pose. LEAP Hand is low-cost and can be assembled in 4 hours at a cost of 2000 USD from readily available parts. It is capable of consistently exerting large torques over long durations of time. We show that LEAP Hand can be used to perform several manipulation tasks in the real world -- from visual teleoperation to learning from passive video data and sim2real. LEAP Hand significantly outperforms its closest competitor Allegro Hand in all our experiments while being 1/8th of the cost. We release detailed assembly instructions, the Sim2Real pipeline and a development platform with useful APIs on our website at https://leap-hand.github.io/
360$^\circ$ from a Single Camera: A Few-Shot Approach for LiDAR Segmentation
Sep 12, 2023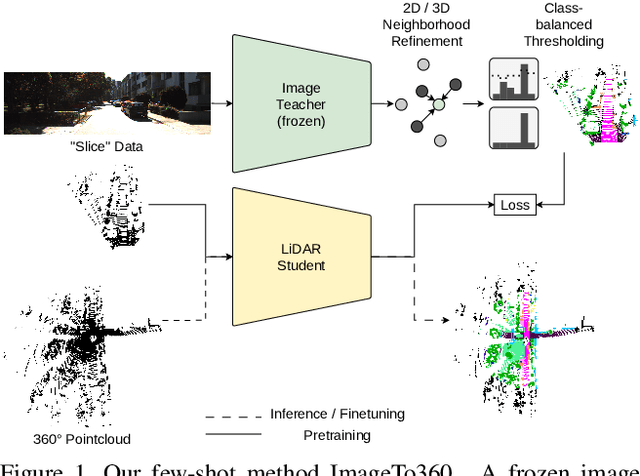

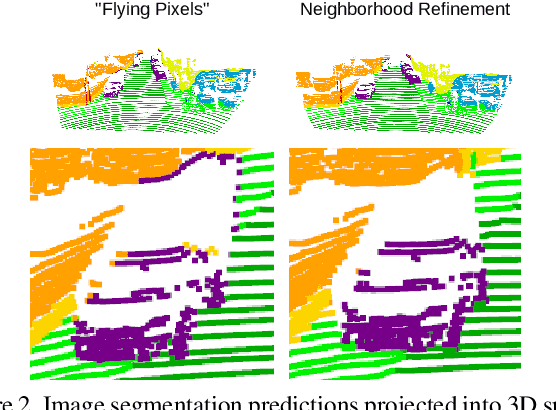
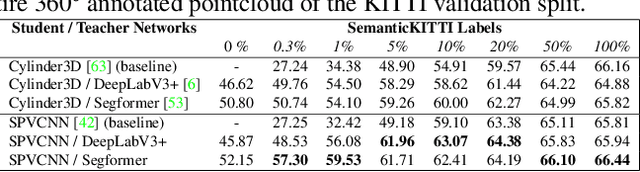
Deep learning applications on LiDAR data suffer from a strong domain gap when applied to different sensors or tasks. In order for these methods to obtain similar accuracy on different data in comparison to values reported on public benchmarks, a large scale annotated dataset is necessary. However, in practical applications labeled data is costly and time consuming to obtain. Such factors have triggered various research in label-efficient methods, but a large gap remains to their fully-supervised counterparts. Thus, we propose ImageTo360, an effective and streamlined few-shot approach to label-efficient LiDAR segmentation. Our method utilizes an image teacher network to generate semantic predictions for LiDAR data within a single camera view. The teacher is used to pretrain the LiDAR segmentation student network, prior to optional fine-tuning on 360$^\circ$ data. Our method is implemented in a modular manner on the point level and as such is generalizable to different architectures. We improve over the current state-of-the-art results for label-efficient methods and even surpass some traditional fully-supervised segmentation networks.
TSMixer: Lightweight MLP-Mixer Model for Multivariate Time Series Forecasting
Jun 28, 2023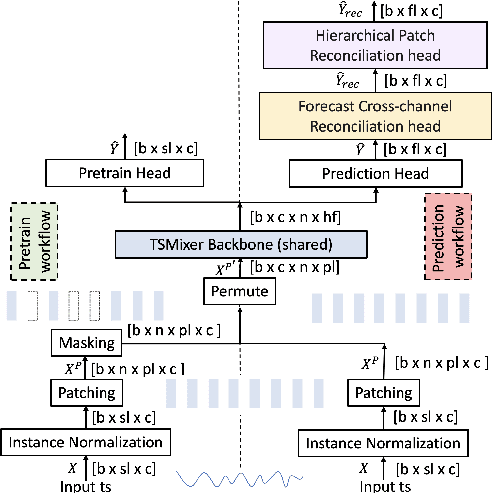
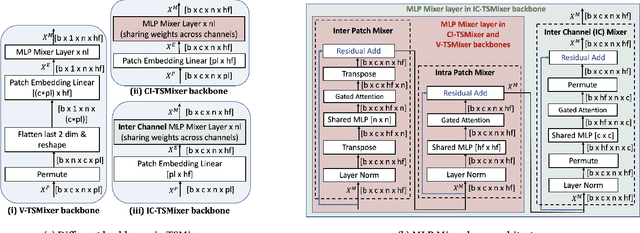
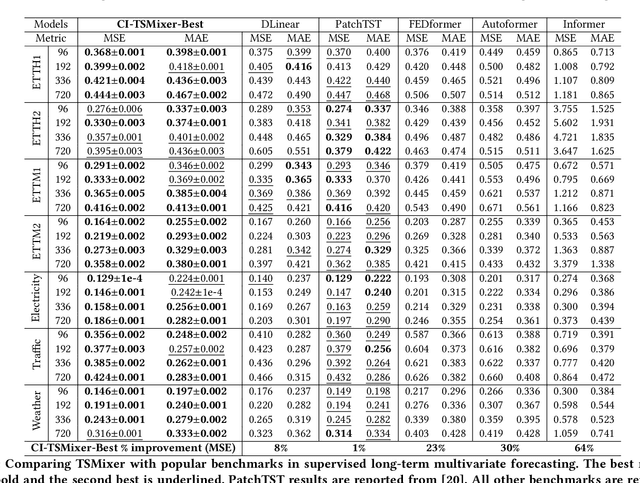
Transformers have gained popularity in time series forecasting for their ability to capture long-sequence interactions. However, their high memory and computing requirements pose a critical bottleneck for long-term forecasting. To address this, we propose TSMixer, a lightweight neural architecture exclusively composed of multi-layer perceptron (MLP) modules. TSMixer is designed for multivariate forecasting and representation learning on patched time series, providing an efficient alternative to Transformers. Our model draws inspiration from the success of MLP-Mixer models in computer vision. We demonstrate the challenges involved in adapting Vision MLP-Mixer for time series and introduce empirically validated components to enhance accuracy. This includes a novel design paradigm of attaching online reconciliation heads to the MLP-Mixer backbone, for explicitly modeling the time-series properties such as hierarchy and channel-correlations. We also propose a Hybrid channel modeling approach to effectively handle noisy channel interactions and generalization across diverse datasets, a common challenge in existing patch channel-mixing methods. Additionally, a simple gated attention mechanism is introduced in the backbone to prioritize important features. By incorporating these lightweight components, we significantly enhance the learning capability of simple MLP structures, outperforming complex Transformer models with minimal computing usage. Moreover, TSMixer's modular design enables compatibility with both supervised and masked self-supervised learning methods, making it a promising building block for time-series Foundation Models. TSMixer outperforms state-of-the-art MLP and Transformer models in forecasting by a considerable margin of 8-60%. It also outperforms the latest strong benchmarks of Patch-Transformer models (by 1-2%) with a significant reduction in memory and runtime (2-3X).
Improving the Transferability of Time Series Forecasting with Decomposition Adaptation
Jun 30, 2023
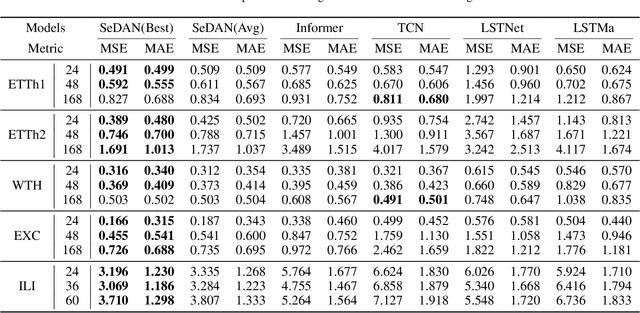
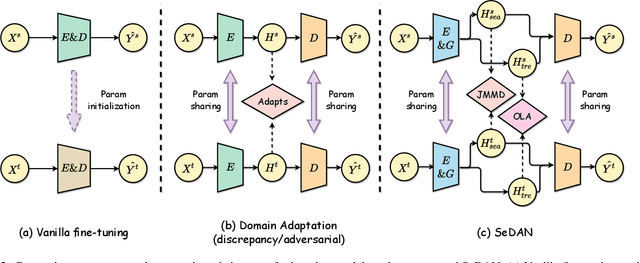
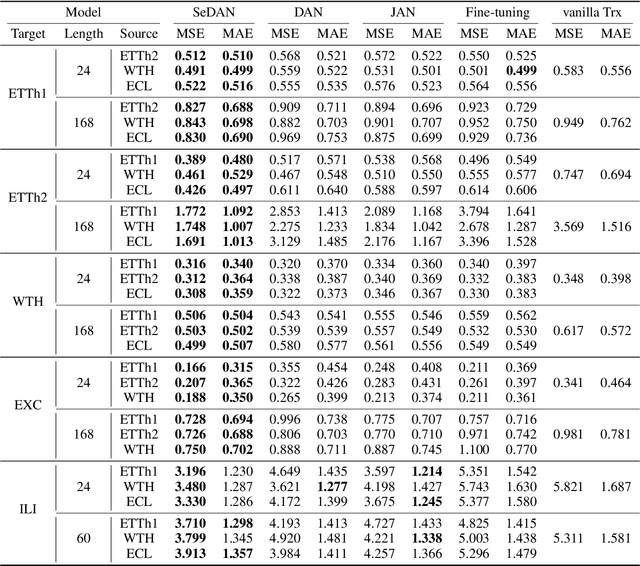
Due to effective pattern mining and feature representation, neural forecasting models based on deep learning have achieved great progress. The premise of effective learning is to collect sufficient data. However, in time series forecasting, it is difficult to obtain enough data, which limits the performance of neural forecasting models. To alleviate the data scarcity limitation, we design Sequence Decomposition Adaptation Network (SeDAN) which is a novel transfer architecture to improve forecasting performance on the target domain by aligning transferable knowledge from cross-domain datasets. Rethinking the transferability of features in time series data, we propose Implicit Contrastive Decomposition to decompose the original features into components including seasonal and trend features, which are easier to transfer. Then we design the corresponding adaptation methods for decomposed features in different domains. Specifically, for seasonal features, we perform joint distribution adaptation and for trend features, we design an Optimal Local Adaptation. We conduct extensive experiments on five benchmark datasets for multivariate time series forecasting. The results demonstrate the effectiveness of our SeDAN. It can provide more efficient and stable knowledge transfer.
SegmentAnything helps microscopy images based automatic and quantitative organoid detection and analysis
Sep 11, 2023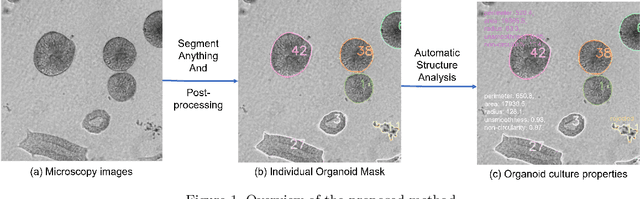
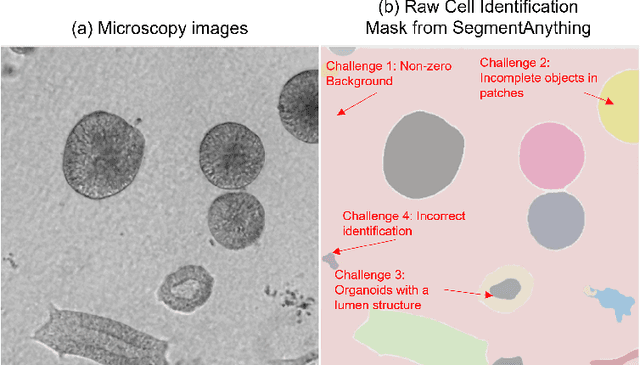
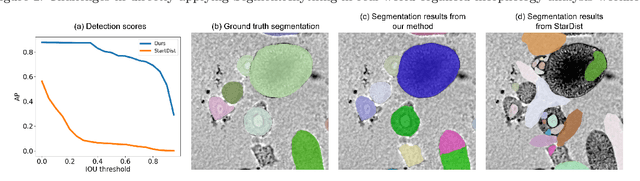
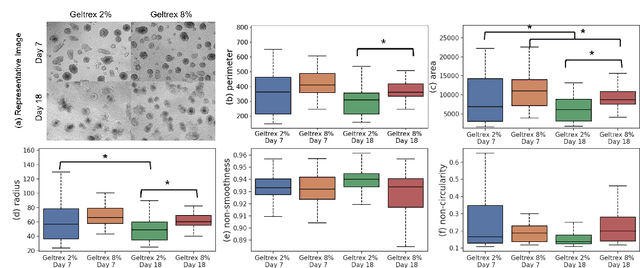
Organoids are self-organized 3D cell clusters that closely mimic the architecture and function of in vivo tissues and organs. Quantification of organoid morphology helps in studying organ development, drug discovery, and toxicity assessment. Recent microscopy techniques provide a potent tool to acquire organoid morphology features, but manual image analysis remains a labor and time-intensive process. Thus, this paper proposes a comprehensive pipeline for microscopy analysis that leverages the SegmentAnything to precisely demarcate individual organoids. Additionally, we introduce a set of morphological properties, including perimeter, area, radius, non-smoothness, and non-circularity, allowing researchers to analyze the organoid structures quantitatively and automatically. To validate the effectiveness of our approach, we conducted tests on bright-field images of human induced pluripotent stem cells (iPSCs) derived neural-epithelial (NE) organoids. The results obtained from our automatic pipeline closely align with manual organoid detection and measurement, showcasing the capability of our proposed method in accelerating organoids morphology analysis.