 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Semantic Parsing in Limited Resource Conditions
Sep 14, 2023
This thesis explores challenges in semantic parsing, specifically focusing on scenarios with limited data and computational resources. It offers solutions using techniques like automatic data curation, knowledge transfer, active learning, and continual learning. For tasks with no parallel training data, the thesis proposes generating synthetic training examples from structured database schemas. When there is abundant data in a source domain but limited parallel data in a target domain, knowledge from the source is leveraged to improve parsing in the target domain. For multilingual situations with limited data in the target languages, the thesis introduces a method to adapt parsers using a limited human translation budget. Active learning is applied to select source-language samples for manual translation, maximizing parser performance in the target language. In addition, an alternative method is also proposed to utilize machine translation services, supplemented by human-translated data, to train a more effective parser. When computational resources are limited, a continual learning approach is introduced to minimize training time and computational memory. This maintains the parser's efficiency in previously learned tasks while adapting it to new tasks, mitigating the problem of catastrophic forgetting. Overall, the thesis provides a comprehensive set of methods to improve semantic parsing in resource-constrained conditions.
Temporal-aware Hierarchical Mask Classification for Video Semantic Segmentation
Sep 14, 2023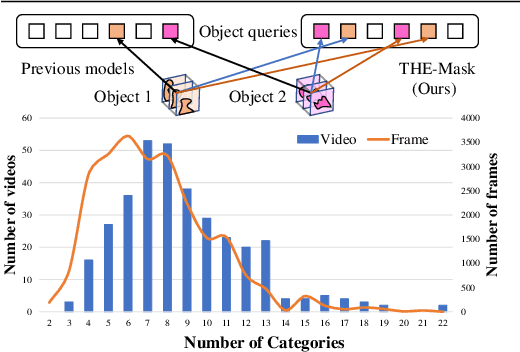
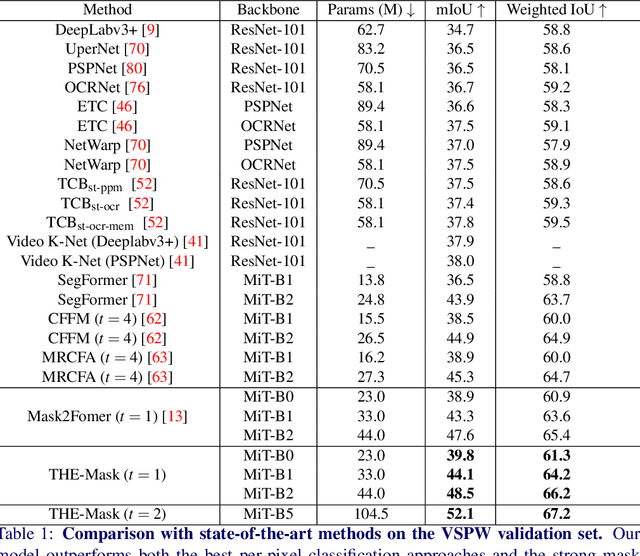
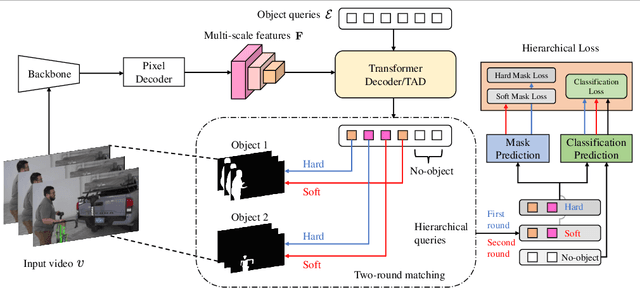

Modern approaches have proved the huge potential of addressing semantic segmentation as a mask classification task which is widely used in instance-level segmentation. This paradigm trains models by assigning part of object queries to ground truths via conventional one-to-one matching. However, we observe that the popular video semantic segmentation (VSS) dataset has limited categories per video, meaning less than 10% of queries could be matched to receive meaningful gradient updates during VSS training. This inefficiency limits the full expressive potential of all queries.Thus, we present a novel solution THE-Mask for VSS, which introduces temporal-aware hierarchical object queries for the first time. Specifically, we propose to use a simple two-round matching mechanism to involve more queries matched with minimal cost during training while without any extra cost during inference. To support our more-to-one assignment, in terms of the matching results, we further design a hierarchical loss to train queries with their corresponding hierarchy of primary or secondary. Moreover, to effectively capture temporal information across frames, we propose a temporal aggregation decoder that fits seamlessly into the mask-classification paradigm for VSS. Utilizing temporal-sensitive multi-level queries, our method achieves state-of-the-art performance on the latest challenging VSS benchmark VSPW without bells and whistles.
Fast Safe Rectangular Corridor-based Online AGV Trajectory Optimization with Obstacle Avoidance
Sep 14, 2023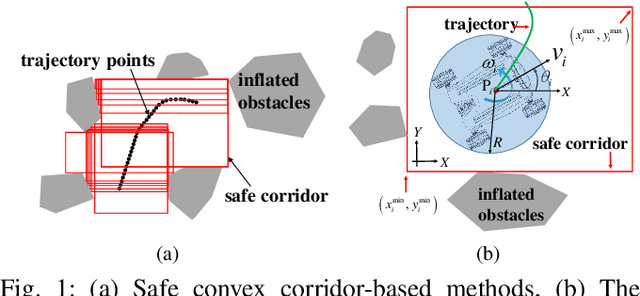
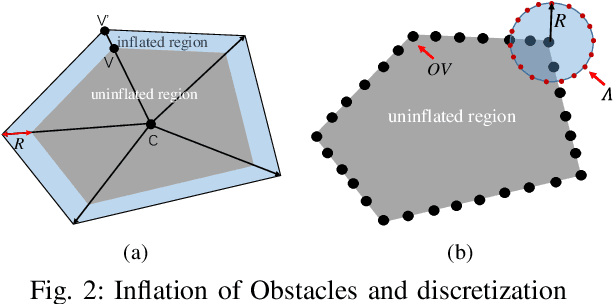
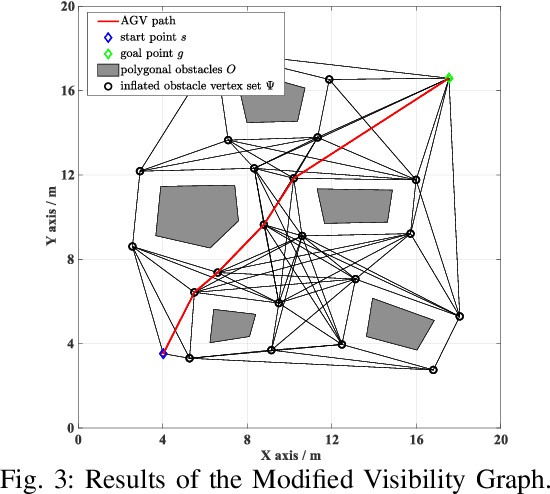
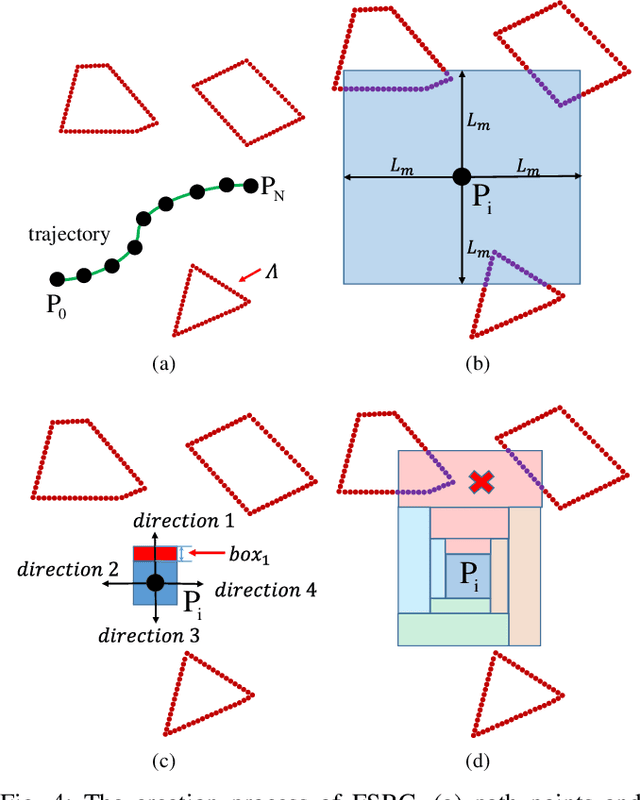
Automated Guided Vehicles (AGVs) are widely adopted in various industries due to their efficiency and adaptability. However, safely deploying AGVs in dynamic environments remains a significant challenge. This paper introduces an online trajectory optimization framework, the Fast Safe Rectangular Corridor (FSRC), designed for AGVs in obstacle-rich settings. The primary challenge is efficiently planning trajectories that prioritize safety and collision avoidance. To tackle this challenge, the FSRC algorithm constructs convex regions, represented as rectangular corridors, to address obstacle avoidance constraints within an optimal control problem. This conversion from non-convex to box constraints improves the collision avoidance efficiency and quality. Additionally, the Modified Visibility Graph algorithm speeds up path planning, and a boundary discretization strategy expedites FSRC construction. The framework also includes a dynamic obstacle avoidance strategy for real-time adaptability. Our framework's effectiveness and superiority have been demonstrated in experiments, particularly in computational efficiency (see Fig. \ref{fig:case1} and \ref{fig:case23}). Compared to state-of-the-art frameworks, our trajectory planning framework significantly enhances computational efficiency, ranging from 1 to 2 orders of magnitude (see Table \ref{tab:res}). Notably, the FSRC algorithm outperforms other safe convex corridor-based methods, substantially improving computational efficiency by 1 to 2 orders of magnitude (see Table \ref{tab:FRSC}).
Landscape-Sketch-Step: An AI/ML-Based Metaheuristic for Surrogate Optimization Problems
Sep 14, 2023

In this paper, we introduce a new heuristics for global optimization in scenarios where extensive evaluations of the cost function are expensive, inaccessible, or even prohibitive. The method, which we call Landscape-Sketch-and-Step (LSS), combines Machine Learning, Stochastic Optimization, and Reinforcement Learning techniques, relying on historical information from previously sampled points to make judicious choices of parameter values where the cost function should be evaluated at. Unlike optimization by Replica Exchange Monte Carlo methods, the number of evaluations of the cost function required in this approach is comparable to that used by Simulated Annealing, quality that is especially important in contexts like high-throughput computing or high-performance computing tasks, where evaluations are either computationally expensive or take a long time to be performed. The method also differs from standard Surrogate Optimization techniques, for it does not construct a surrogate model that aims at approximating or reconstructing the objective function. We illustrate our method by applying it to low dimensional optimization problems (dimensions 1, 2, 4, and 8) that mimick known difficulties of minimization on rugged energy landscapes often seen in Condensed Matter Physics, where cost functions are rugged and plagued with local minima. When compared to classical Simulated Annealing, the LSS shows an effective acceleration of the optimization process.
Jade: A Differentiable Physics Engine for Articulated Rigid Bodies with Intersection-Free Frictional Contact
Sep 09, 2023
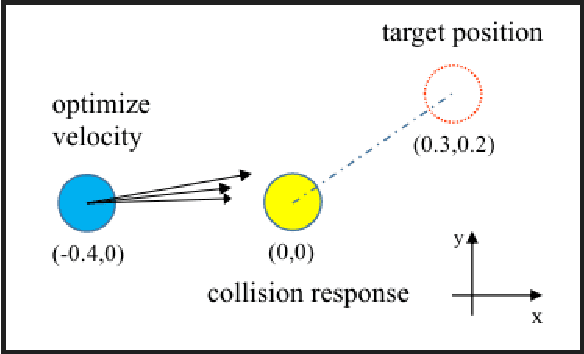
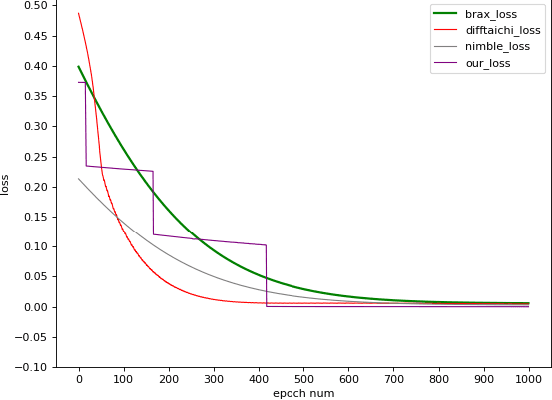
We present Jade, a differentiable physics engine for articulated rigid bodies. Jade models contacts as the Linear Complementarity Problem (LCP). Compared to existing differentiable simulations, Jade offers features including intersection-free collision simulation and stable LCP solutions for multiple frictional contacts. We use continuous collision detection to detect the time of impact and adopt the backtracking strategy to prevent intersection between bodies with complex geometry shapes. We derive the gradient calculation to ensure the whole simulation process is differentiable under the backtracking mechanism. We modify the popular Dantzig algorithm to get valid solutions under multiple frictional contacts. We conduct extensive experiments to demonstrate the effectiveness of our differentiable physics simulation over a variety of contact-rich tasks.
Extending Transductive Knowledge Graph Embedding Models for Inductive Logical Relational Inference
Sep 07, 2023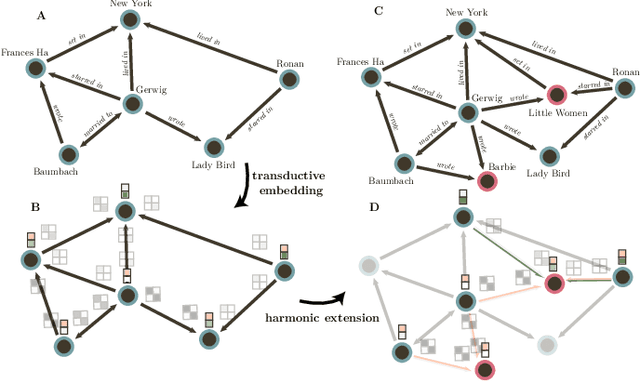
Many downstream inference tasks for knowledge graphs, such as relation prediction, have been handled successfully by knowledge graph embedding techniques in the transductive setting. To address the inductive setting wherein new entities are introduced into the knowledge graph at inference time, more recent work opts for models which learn implicit representations of the knowledge graph through a complex function of a network's subgraph structure, often parametrized by graph neural network architectures. These come at the cost of increased parametrization, reduced interpretability and limited generalization to other downstream inference tasks. In this work, we bridge the gap between traditional transductive knowledge graph embedding approaches and more recent inductive relation prediction models by introducing a generalized form of harmonic extension which leverages representations learned through transductive embedding methods to infer representations of new entities introduced at inference time as in the inductive setting. This harmonic extension technique provides the best such approximation, can be implemented via an efficient iterative scheme, and can be employed to answer a family of conjunctive logical queries over the knowledge graph, further expanding the capabilities of transductive embedding methods. In experiments on a number of large-scale knowledge graph embedding benchmarks, we find that this approach for extending the functionality of transductive knowledge graph embedding models to perform knowledge graph completion and answer logical queries in the inductive setting is competitive with--and in some scenarios outperforms--several state-of-the-art models derived explicitly for such inductive tasks.
Reaction coordinate flows for model reduction of molecular kinetics
Sep 11, 2023In this work, we introduce a flow based machine learning approach, called reaction coordinate (RC) flow, for discovery of low-dimensional kinetic models of molecular systems. The RC flow utilizes a normalizing flow to design the coordinate transformation and a Brownian dynamics model to approximate the kinetics of RC, where all model parameters can be estimated in a data-driven manner. In contrast to existing model reduction methods for molecular kinetics, RC flow offers a trainable and tractable model of reduced kinetics in continuous time and space due to the invertibility of the normalizing flow. Furthermore, the Brownian dynamics-based reduced kinetic model investigated in this work yields a readily discernible representation of metastable states within the phase space of the molecular system. Numerical experiments demonstrate how effectively the proposed method discovers interpretable and accurate low-dimensional representations of given full-state kinetics from simulations.
Boundary Peeling: Outlier Detection Method Using One-Class Peeling
Sep 11, 2023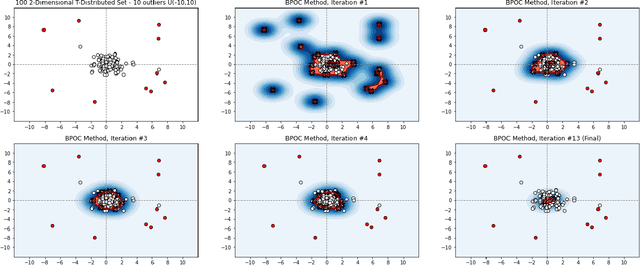
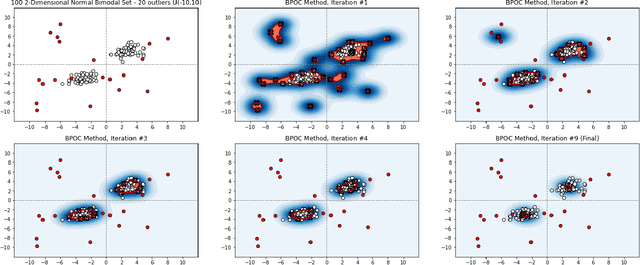
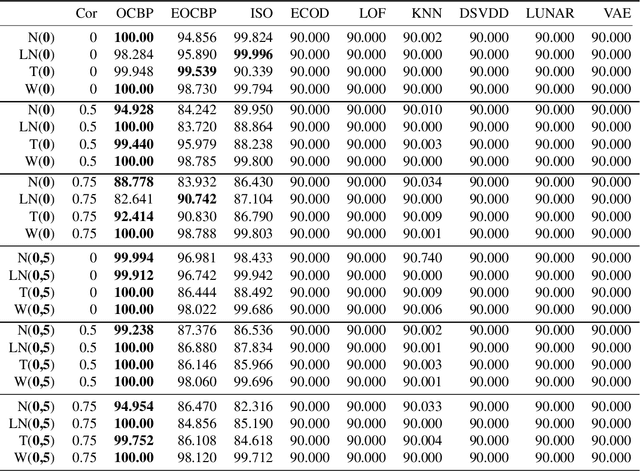
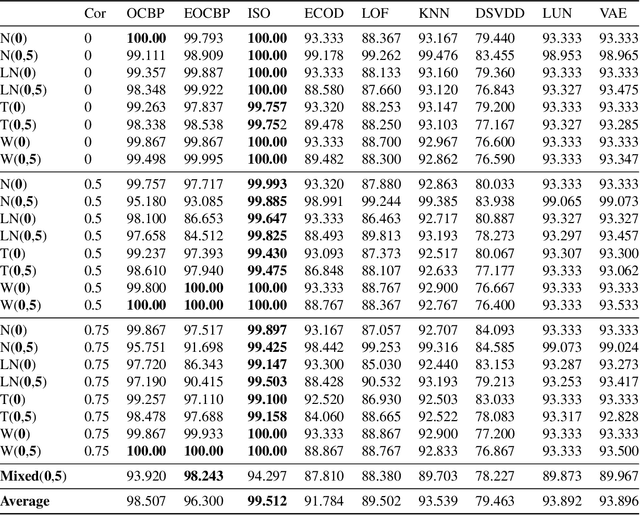
Unsupervised outlier detection constitutes a crucial phase within data analysis and remains a dynamic realm of research. A good outlier detection algorithm should be computationally efficient, robust to tuning parameter selection, and perform consistently well across diverse underlying data distributions. We introduce One-Class Boundary Peeling, an unsupervised outlier detection algorithm. One-class Boundary Peeling uses the average signed distance from iteratively-peeled, flexible boundaries generated by one-class support vector machines. One-class Boundary Peeling has robust hyperparameter settings and, for increased flexibility, can be cast as an ensemble method. In synthetic data simulations One-Class Boundary Peeling outperforms all state of the art methods when no outliers are present while maintaining comparable or superior performance in the presence of outliers, as compared to benchmark methods. One-Class Boundary Peeling performs competitively in terms of correct classification, AUC, and processing time using common benchmark data sets.
Panoptic Vision-Language Feature Fields
Sep 11, 2023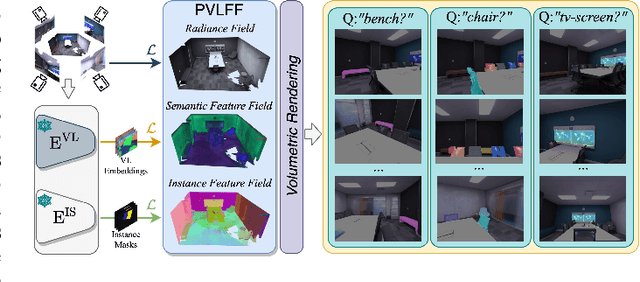
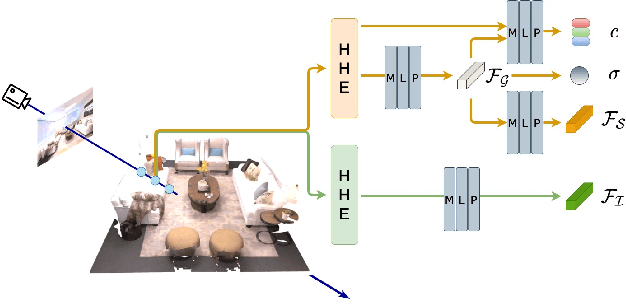
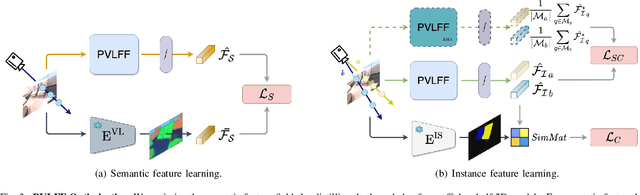

Recently, methods have been proposed for 3D open-vocabulary semantic segmentation. Such methods are able to segment scenes into arbitrary classes given at run-time using their text description. In this paper, we propose to our knowledge the first algorithm for open-vocabulary panoptic segmentation, simultaneously performing both semantic and instance segmentation. Our algorithm, Panoptic Vision-Language Feature Fields (PVLFF) learns a feature field of the scene, jointly learning vision-language features and hierarchical instance features through a contrastive loss function from 2D instance segment proposals on input frames. Our method achieves comparable performance against the state-of-the-art close-set 3D panoptic systems on the HyperSim, ScanNet and Replica dataset and outperforms current 3D open-vocabulary systems in terms of semantic segmentation. We additionally ablate our method to demonstrate the effectiveness of our model architecture. Our code will be available at https://github.com/ethz-asl/autolabel.
FlowIBR: Leveraging Pre-Training for Efficient Neural Image-Based Rendering of Dynamic Scenes
Sep 11, 2023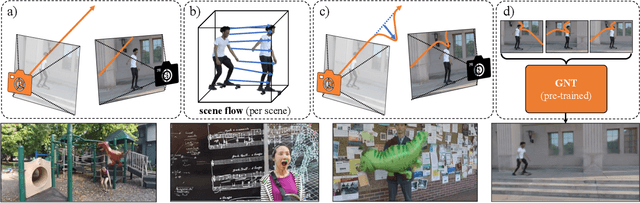
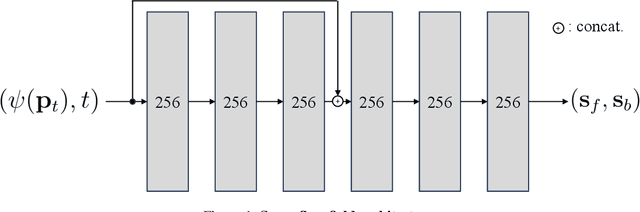
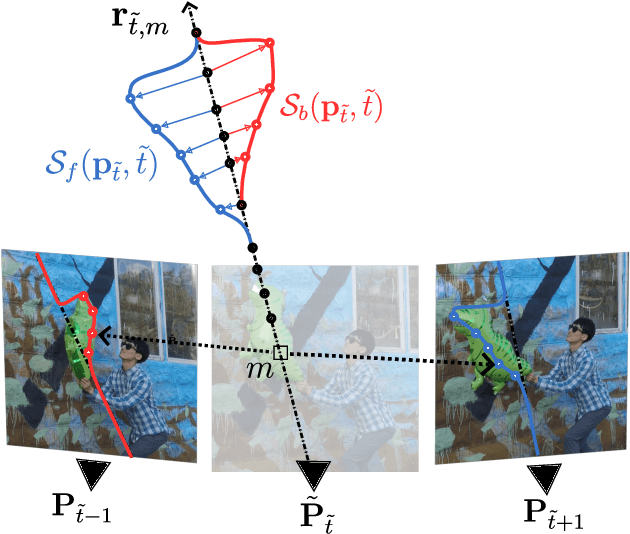
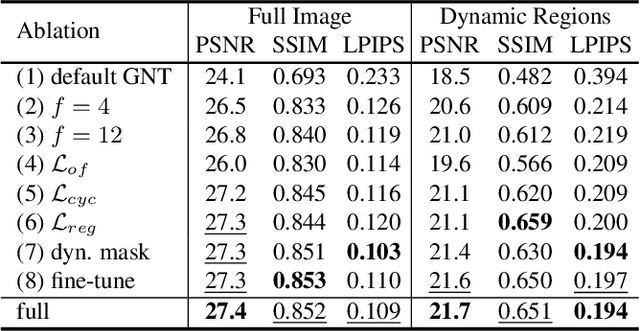
We introduce a novel approach for monocular novel view synthesis of dynamic scenes. Existing techniques already show impressive rendering quality but tend to focus on optimization within a single scene without leveraging prior knowledge. This limitation has been primarily attributed to the lack of datasets of dynamic scenes available for training and the diversity of scene dynamics. Our method FlowIBR circumvents these issues by integrating a neural image-based rendering method, pre-trained on a large corpus of widely available static scenes, with a per-scene optimized scene flow field. Utilizing this flow field, we bend the camera rays to counteract the scene dynamics, thereby presenting the dynamic scene as if it were static to the rendering network. The proposed method reduces per-scene optimization time by an order of magnitude, achieving comparable results to existing methods - all on a single consumer-grade GPU.