 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Timely Fusion of Surround Radar/Lidar for Object Detection in Autonomous Driving Systems
Sep 09, 2023
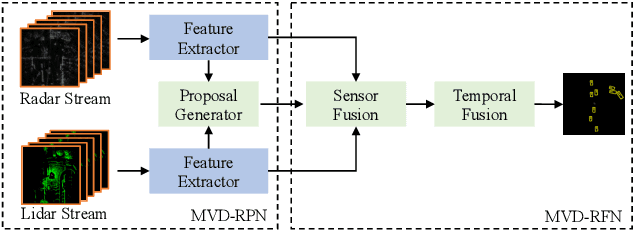
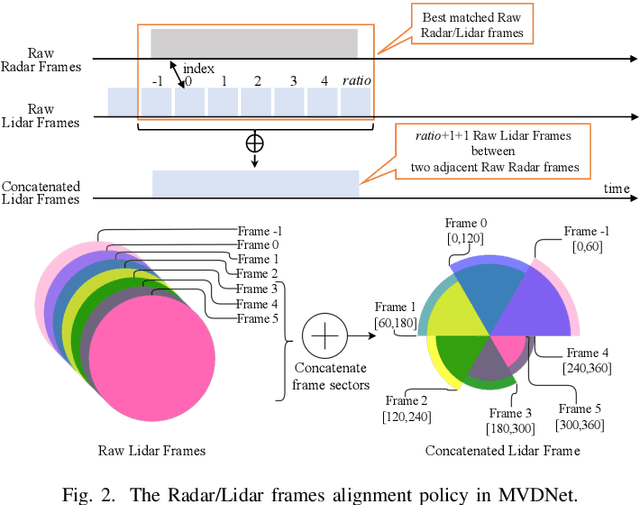
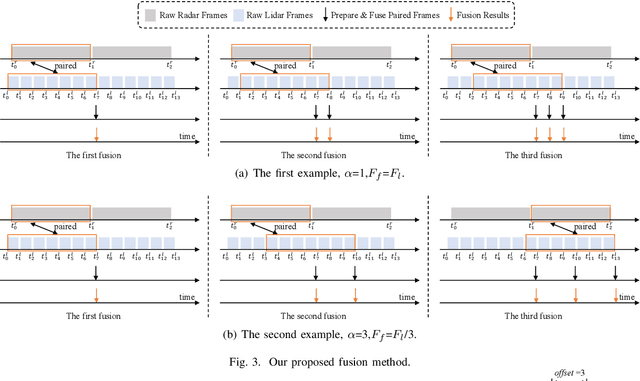
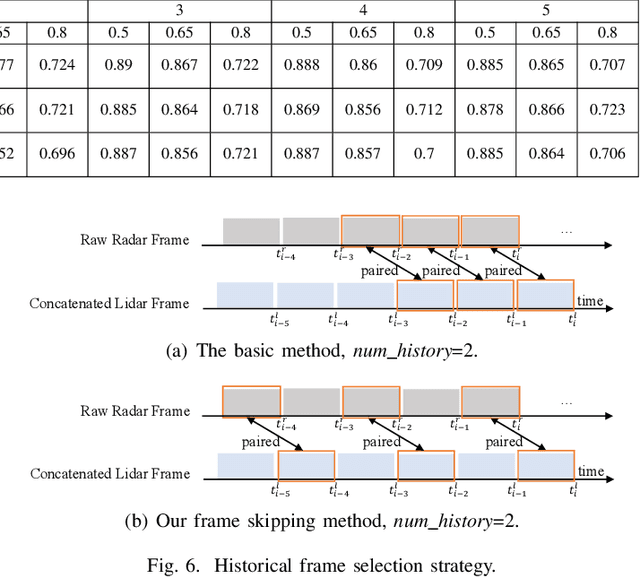
Fusing Radar and Lidar sensor data can fully utilize their complementary advantages and provide more accurate reconstruction of the surrounding for autonomous driving systems. Surround Radar/Lidar can provide 360-degree view sampling with the minimal cost, which are promising sensing hardware solutions for autonomous driving systems. However, due to the intrinsic physical constraints, the rotating speed of surround Radar, and thus the frequency to generate Radar data frames, is much lower than surround Lidar. Existing Radar/Lidar fusion methods have to work at the low frequency of surround Radar, which cannot meet the high responsiveness requirement of autonomous driving systems.This paper develops techniques to fuse surround Radar/Lidar with working frequency only limited by the faster surround Lidar instead of the slower surround Radar, based on the state-of-the-art object detection model MVDNet. The basic idea of our approach is simple: we let MVDNet work with temporally unaligned data from Radar/Lidar, so that fusion can take place at any time when a new Lidar data frame arrives, instead of waiting for the slow Radar data frame. However, directly applying MVDNet to temporally unaligned Radar/Lidar data greatly degrades its object detection accuracy. The key information revealed in this paper is that we can achieve high output frequency with little accuracy loss by enhancing the training procedure to explore the temporal redundancy in MVDNet so that it can tolerate the temporal unalignment of input data. We explore several different ways of training enhancement and compare them quantitatively with experiments.
CPMR: Context-Aware Incremental Sequential Recommendation with Pseudo-Multi-Task Learning
Sep 09, 2023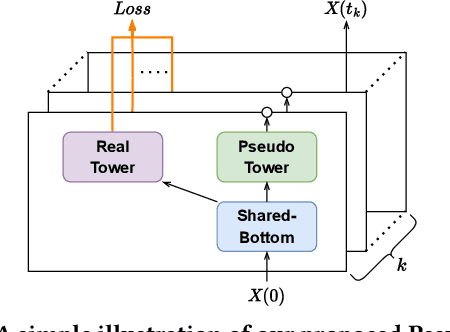


The motivations of users to make interactions can be divided into static preference and dynamic interest. To accurately model user representations over time, recent studies in sequential recommendation utilize information propagation and evolution to mine from batches of arriving interactions. However, they ignore the fact that people are easily influenced by the recent actions of other users in the contextual scenario, and applying evolution across all historical interactions dilutes the importance of recent ones, thus failing to model the evolution of dynamic interest accurately. To address this issue, we propose a Context-Aware Pseudo-Multi-Task Recommender System (CPMR) to model the evolution in both historical and contextual scenarios by creating three representations for each user and item under different dynamics: static embedding, historical temporal states, and contextual temporal states. To dually improve the performance of temporal states evolution and incremental recommendation, we design a Pseudo-Multi-Task Learning (PMTL) paradigm by stacking the incremental single-target recommendations into one multi-target task for joint optimization. Within the PMTL paradigm, CPMR employs a shared-bottom network to conduct the evolution of temporal states across historical and contextual scenarios, as well as the fusion of them at the user-item level. In addition, CPMR incorporates one real tower for incremental predictions, and two pseudo towers dedicated to updating the respective temporal states based on new batches of interactions. Experimental results on four benchmark recommendation datasets show that CPMR consistently outperforms state-of-the-art baselines and achieves significant gains on three of them. The code is available at: https://github.com/DiMarzioBian/CPMR.
* Accepted by CIKM 2023
ZC3: Zero-Shot Cross-Language Code Clone Detection
Sep 07, 2023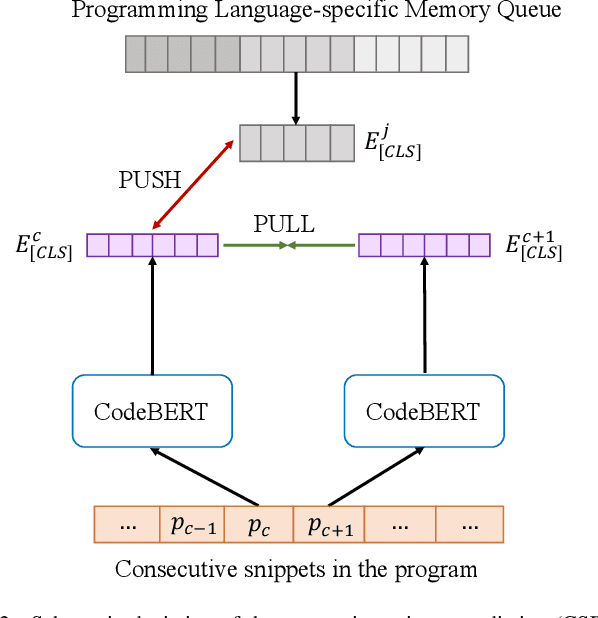
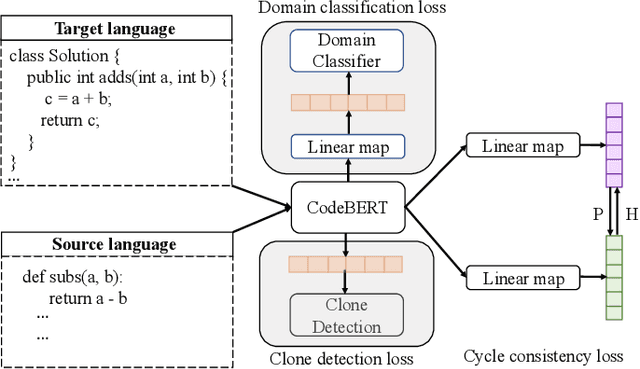
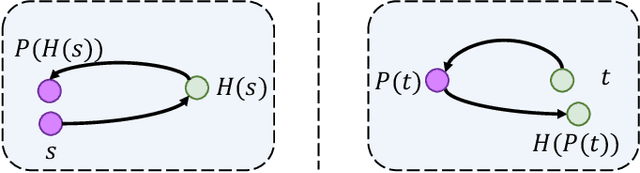
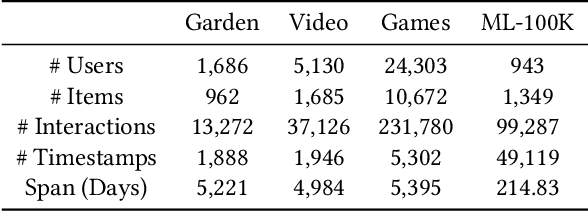
Developers introduce code clones to improve programming productivity. Many existing studies have achieved impressive performance in monolingual code clone detection. However, during software development, more and more developers write semantically equivalent programs with different languages to support different platforms and help developers translate projects from one language to another. Considering that collecting cross-language parallel data, especially for low-resource languages, is expensive and time-consuming, how designing an effective cross-language model that does not rely on any parallel data is a significant problem. In this paper, we propose a novel method named ZC3 for Zero-shot Cross-language Code Clone detection. ZC3 designs the contrastive snippet prediction to form an isomorphic representation space among different programming languages. Based on this, ZC3 exploits domain-aware learning and cycle consistency learning to further constrain the model to generate representations that are aligned among different languages meanwhile are diacritical for different types of clones. To evaluate our approach, we conduct extensive experiments on four representative cross-language clone detection datasets. Experimental results show that ZC3 outperforms the state-of-the-art baselines by 67.12%, 51.39%, 14.85%, and 53.01% on the MAP score, respectively. We further investigate the representational distribution of different languages and discuss the effectiveness of our method.
Enhancing Pipeline-Based Conversational Agents with Large Language Models
Sep 07, 2023The latest advancements in AI and deep learning have led to a breakthrough in large language model (LLM)-based agents such as GPT-4. However, many commercial conversational agent development tools are pipeline-based and have limitations in holding a human-like conversation. This paper investigates the capabilities of LLMs to enhance pipeline-based conversational agents during two phases: 1) in the design and development phase and 2) during operations. In 1) LLMs can aid in generating training data, extracting entities and synonyms, localization, and persona design. In 2) LLMs can assist in contextualization, intent classification to prevent conversational breakdown and handle out-of-scope questions, auto-correcting utterances, rephrasing responses, formulating disambiguation questions, summarization, and enabling closed question-answering capabilities. We conducted informal experiments with GPT-4 in the private banking domain to demonstrate the scenarios above with a practical example. Companies may be hesitant to replace their pipeline-based agents with LLMs entirely due to privacy concerns and the need for deep integration within their existing ecosystems. A hybrid approach in which LLMs' are integrated into the pipeline-based agents allows them to save time and costs of building and running agents by capitalizing on the capabilities of LLMs while retaining the integration and privacy safeguards of their existing systems.
Prime and Modulate Learning: Generation of forward models with signed back-propagation and environmental cues
Sep 07, 2023Deep neural networks employing error back-propagation for learning can suffer from exploding and vanishing gradient problems. Numerous solutions have been proposed such as normalisation techniques or limiting activation functions to linear rectifying units. In this work we follow a different approach which is particularly applicable to closed-loop learning of forward models where back-propagation makes exclusive use of the sign of the error signal to prime the learning, whilst a global relevance signal modulates the rate of learning. This is inspired by the interaction between local plasticity and a global neuromodulation. For example, whilst driving on an empty road, one can allow for slow step-wise optimisation of actions, whereas, at a busy junction, an error must be corrected at once. Hence, the error is the priming signal and the intensity of the experience is a modulating factor in the weight change. The advantages of this Prime and Modulate paradigm is twofold: it is free from normalisation and it makes use of relevant cues from the environment to enrich the learning. We present a mathematical derivation of the learning rule in z-space and demonstrate the real-time performance with a robotic platform. The results show a significant improvement in the speed of convergence compared to that of the conventional back-propagation.
Efficient Single Object Detection on Image Patches with Early Exit Enhanced High-Precision CNNs
Sep 07, 2023This paper proposes a novel approach for detecting objects using mobile robots in the context of the RoboCup Standard Platform League, with a primary focus on detecting the ball. The challenge lies in detecting a dynamic object in varying lighting conditions and blurred images caused by fast movements. To address this challenge, the paper presents a convolutional neural network architecture designed specifically for computationally constrained robotic platforms. The proposed CNN is trained to achieve high precision classification of single objects in image patches and to determine their precise spatial positions. The paper further integrates Early Exits into the existing high-precision CNN architecture to reduce the computational cost of easily rejectable cases in the background class. The training process involves a composite loss function based on confidence and positional losses with dynamic weighting and data augmentation. The proposed approach achieves a precision of 100% on the validation dataset and a recall of almost 87%, while maintaining an execution time of around 170 $\mu$s per hypotheses. By combining the proposed approach with an Early Exit, a runtime optimization of more than 28%, on average, can be achieved compared to the original CNN. Overall, this paper provides an efficient solution for an enhanced detection of objects, especially the ball, in computationally constrained robotic platforms.
Joint Beamforming and Power Allocation for RIS Aided Full-Duplex Integrated Sensing and Uplink Communication System
Sep 07, 2023Integrated sensing and communication (ISAC) capability is envisioned as one key feature for future cellular networks. Classical half-duplex (HD) radar sensing is conducted in a "first-emit-then-listen" manner. One challenge to realize HD ISAC lies in the discrepancy of the two systems' time scheduling for transmitting and receiving. This difficulty can be overcome by full-duplex (FD) transceivers. Besides, ISAC generally has to comprise its communication rate due to realizing sensing functionality. This loss can be compensated by the emerging reconfigurable intelligent surface (RIS) technology. This paper considers the joint design of beamforming, power allocation and signal processing in a FD uplink communication system aided by RIS, which is a highly nonconvex problem. To resolve this challenge, via leveraging the cutting-the-edge majorization-minimization (MM) and penalty-dual-decomposition (PDD) methods, we develop an iterative solution that optimizes all variables via using convex optimization techniques. Besides, by wisely exploiting alternative direction method of multipliers (ADMM) and optimality analysis, we further develop a low complexity solution that updates all variables analytically and runs highly efficiently. Numerical results are provided to verify the effectiveness and efficiency of our proposed algorithms and demonstrate the significant performance boosting by employing RIS in the FD ISAC system.
Natural and Robust Walking using Reinforcement Learning without Demonstrations in High-Dimensional Musculoskeletal Models
Sep 07, 2023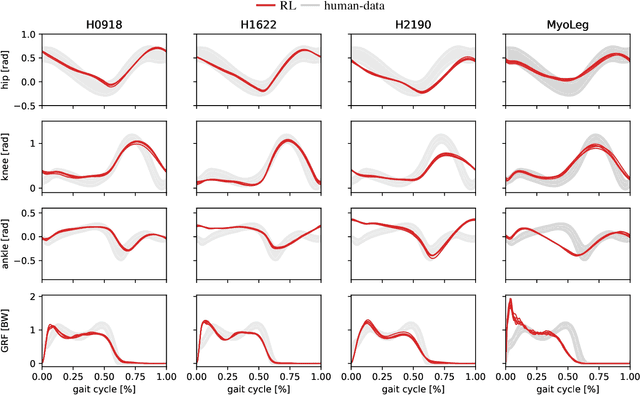
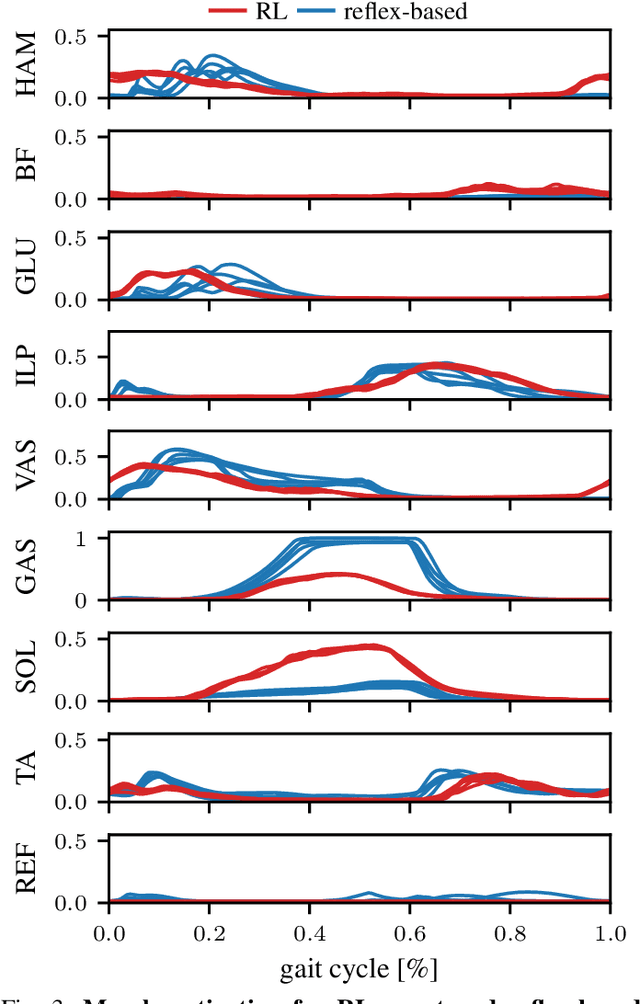
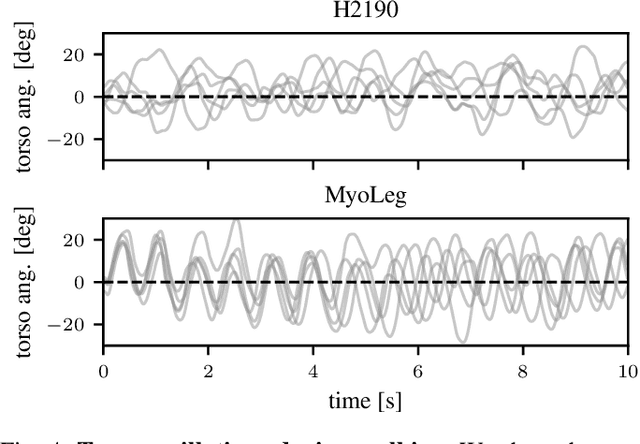
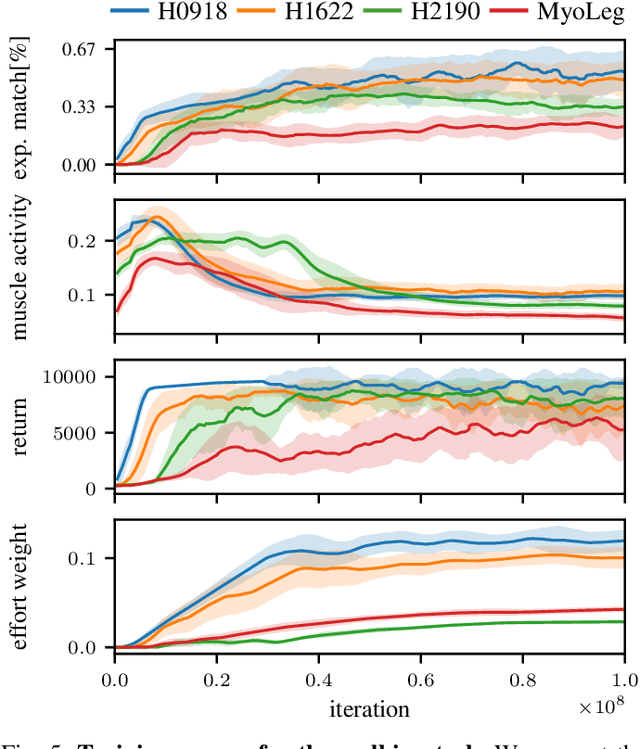
Humans excel at robust bipedal walking in complex natural environments. In each step, they adequately tune the interaction of biomechanical muscle dynamics and neuronal signals to be robust against uncertainties in ground conditions. However, it is still not fully understood how the nervous system resolves the musculoskeletal redundancy to solve the multi-objective control problem considering stability, robustness, and energy efficiency. In computer simulations, energy minimization has been shown to be a successful optimization target, reproducing natural walking with trajectory optimization or reflex-based control methods. However, these methods focus on particular motions at a time and the resulting controllers are limited when compensating for perturbations. In robotics, reinforcement learning~(RL) methods recently achieved highly stable (and efficient) locomotion on quadruped systems, but the generation of human-like walking with bipedal biomechanical models has required extensive use of expert data sets. This strong reliance on demonstrations often results in brittle policies and limits the application to new behaviors, especially considering the potential variety of movements for high-dimensional musculoskeletal models in 3D. Achieving natural locomotion with RL without sacrificing its incredible robustness might pave the way for a novel approach to studying human walking in complex natural environments. Videos: https://sites.google.com/view/naturalwalkingrl
Impression-Informed Multi-Behavior Recommender System: A Hierarchical Graph Attention Approach
Sep 07, 2023While recommender systems have significantly benefited from implicit feedback, they have often missed the nuances of multi-behavior interactions between users and items. Historically, these systems either amalgamated all behaviors, such as \textit{impression} (formerly \textit{view}), \textit{add-to-cart}, and \textit{buy}, under a singular 'interaction' label, or prioritized only the target behavior, often the \textit{buy} action, discarding valuable auxiliary signals. Although recent advancements tried addressing this simplification, they primarily gravitated towards optimizing the target behavior alone, battling with data scarcity. Additionally, they tended to bypass the nuanced hierarchy intrinsic to behaviors. To bridge these gaps, we introduce the \textbf{H}ierarchical \textbf{M}ulti-behavior \textbf{G}raph Attention \textbf{N}etwork (HMGN). This pioneering framework leverages attention mechanisms to discern information from both inter and intra-behaviors while employing a multi-task Hierarchical Bayesian Personalized Ranking (HBPR) for optimization. Recognizing the need for scalability, our approach integrates a specialized multi-behavior sub-graph sampling technique. Moreover, the adaptability of HMGN allows for the seamless inclusion of knowledge metadata and time-series data. Empirical results attest to our model's prowess, registering a notable performance boost of up to 64\% in NDCG@100 metrics over conventional graph neural network methods.
Cross-Consistent Deep Unfolding Network for Adaptive All-In-One Video Restoration
Sep 07, 2023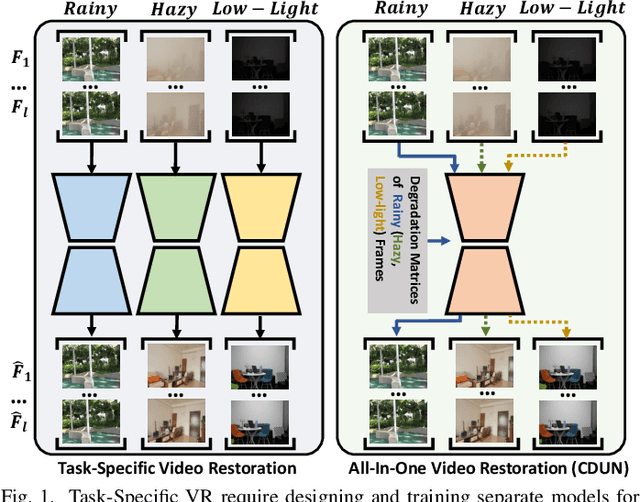

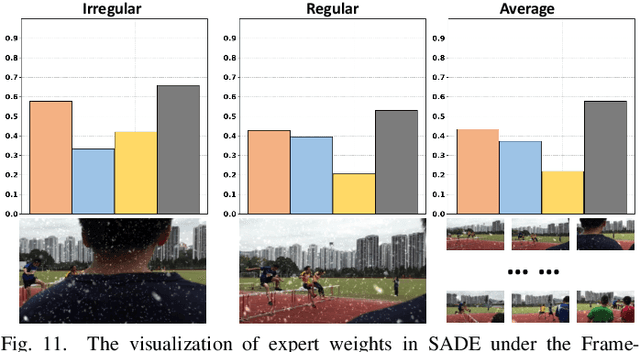
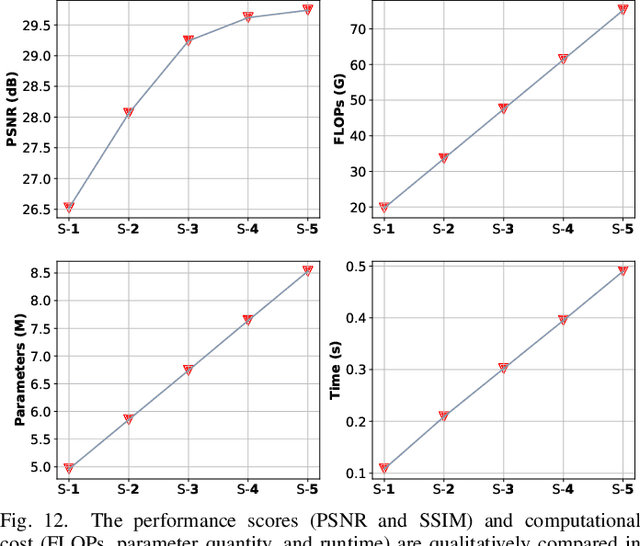
Existing Video Restoration (VR) methods always necessitate the individual deployment of models for each adverse weather to remove diverse adverse weather degradations, lacking the capability for adaptive processing of degradations. Such limitation amplifies the complexity and deployment costs in practical applications. To overcome this deficiency, in this paper, we propose a Cross-consistent Deep Unfolding Network (CDUN) for All-In-One VR, which enables the employment of a single model to remove diverse degradations for the first time. Specifically, the proposed CDUN accomplishes a novel iterative optimization framework, capable of restoring frames corrupted by corresponding degradations according to the degradation features given in advance. To empower the framework for eliminating diverse degradations, we devise a Sequence-wise Adaptive Degradation Estimator (SADE) to estimate degradation features for the input corrupted video. By orchestrating these two cascading procedures, CDUN achieves adaptive processing for diverse degradation. In addition, we introduce a window-based inter-frame fusion strategy to utilize information from more adjacent frames. This strategy involves the progressive stacking of temporal windows in multiple iterations, effectively enlarging the temporal receptive field and enabling each frame's restoration to leverage information from distant frames. Extensive experiments demonstrate that the proposed method achieves state-of-the-art performance in All-In-One VR.