 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Fusing Domain-Specific Content from Large Language Models into Knowledge Graphs for Enhanced Zero Shot Object State Classification
Mar 25, 2024
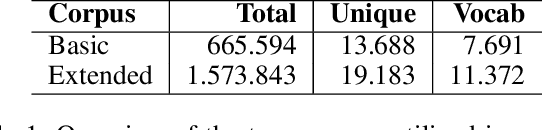
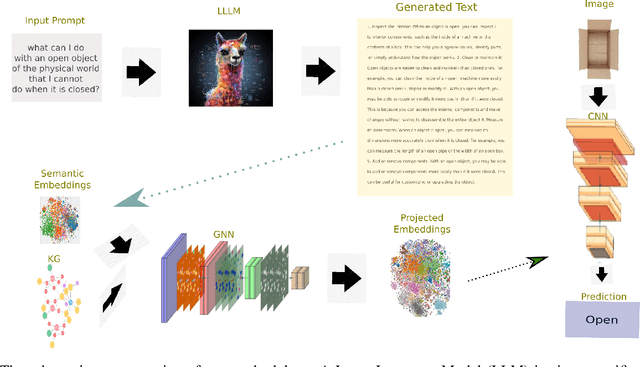


Domain-specific knowledge can significantly contribute to addressing a wide variety of vision tasks. However, the generation of such knowledge entails considerable human labor and time costs. This study investigates the potential of Large Language Models (LLMs) in generating and providing domain-specific information through semantic embeddings. To achieve this, an LLM is integrated into a pipeline that utilizes Knowledge Graphs and pre-trained semantic vectors in the context of the Vision-based Zero-shot Object State Classification task. We thoroughly examine the behavior of the LLM through an extensive ablation study. Our findings reveal that the integration of LLM-based embeddings, in combination with general-purpose pre-trained embeddings, leads to substantial performance improvements. Drawing insights from this ablation study, we conduct a comparative analysis against competing models, thereby highlighting the state-of-the-art performance achieved by the proposed approach.
Learning-Enhanced Neighborhood Selection for the Vehicle Routing Problem with Time Windows
Mar 13, 2024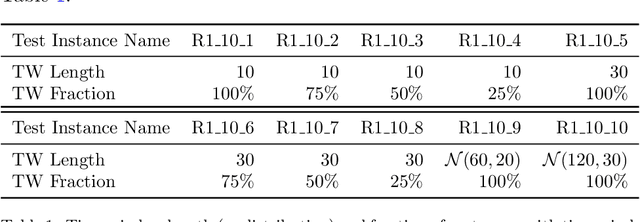
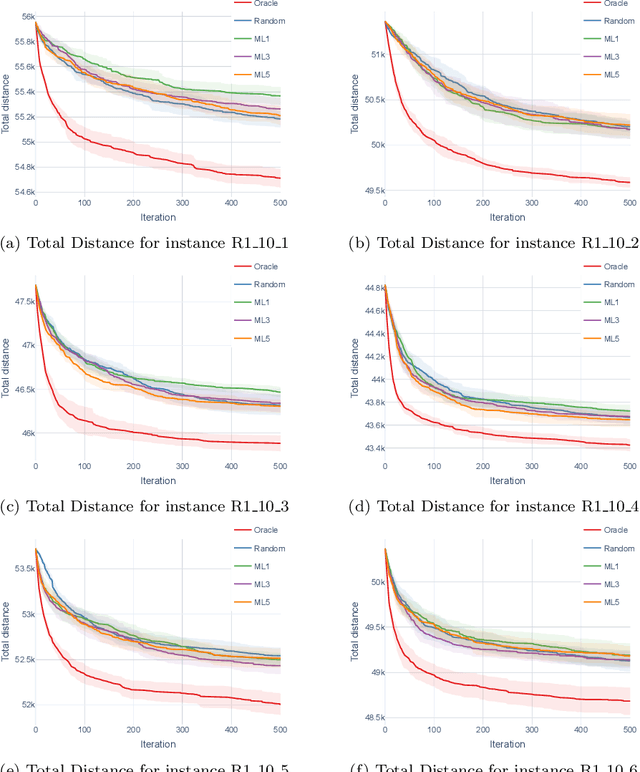
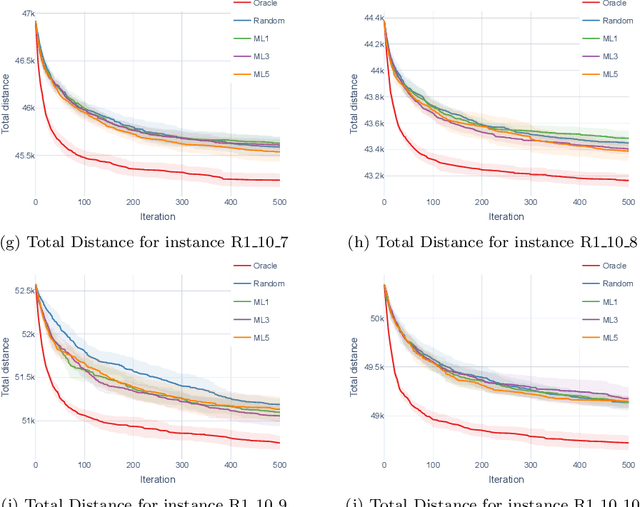

Large Neighborhood Search (LNS) is a universal approach that is broadly applicable and has proven to be highly efficient in practice for solving optimization problems. We propose to integrate machine learning (ML) into LNS to assist in deciding which parts of the solution should be destroyed and repaired in each iteration of LNS. We refer to our new approach as Learning-Enhanced Neighborhood Selection (LENS for short). Our approach is universally applicable, i.e., it can be applied to any LNS algorithm to amplify the workings of the destroy algorithm. In this paper, we demonstrate the potential of LENS on the fundamental Vehicle Routing Problem with Time Windows (VRPTW). We implemented an LNS algorithm for VRPTW and collected data on generated novel training instances derived from well-known, extensively utilized benchmark datasets. We trained our LENS approach with this data and compared the experimental results of our approach with two benchmark algorithms: a random neighborhood selection method to show that LENS learns to make informed choices and an oracle neighborhood selection method to demonstrate the potential of our LENS approach. With LENS, we obtain results that significantly improve the quality of the solutions.
Step-Calibrated Diffusion for Biomedical Optical Image Restoration
Mar 26, 2024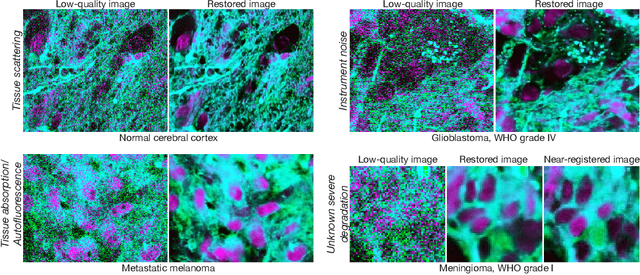

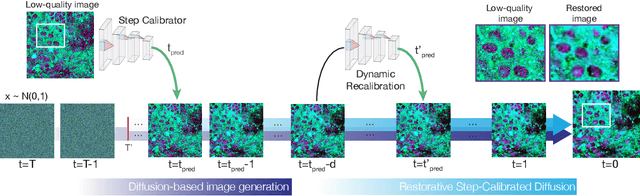
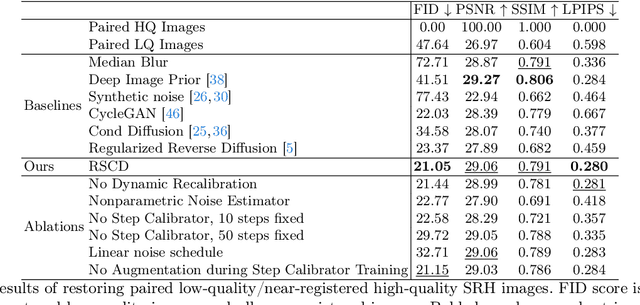
High-quality, high-resolution medical imaging is essential for clinical care. Raman-based biomedical optical imaging uses non-ionizing infrared radiation to evaluate human tissues in real time and is used for early cancer detection, brain tumor diagnosis, and intraoperative tissue analysis. Unfortunately, optical imaging is vulnerable to image degradation due to laser scattering and absorption, which can result in diagnostic errors and misguided treatment. Restoration of optical images is a challenging computer vision task because the sources of image degradation are multi-factorial, stochastic, and tissue-dependent, preventing a straightforward method to obtain paired low-quality/high-quality data. Here, we present Restorative Step-Calibrated Diffusion (RSCD), an unpaired image restoration method that views the image restoration problem as completing the finishing steps of a diffusion-based image generation task. RSCD uses a step calibrator model to dynamically determine the severity of image degradation and the number of steps required to complete the reverse diffusion process for image restoration. RSCD outperforms other widely used unpaired image restoration methods on both image quality and perceptual evaluation metrics for restoring optical images. Medical imaging experts consistently prefer images restored using RSCD in blinded comparison experiments and report minimal to no hallucinations. Finally, we show that RSCD improves performance on downstream clinical imaging tasks, including automated brain tumor diagnosis and deep tissue imaging. Our code is available at https://github.com/MLNeurosurg/restorative_step-calibrated_diffusion.
Online Tree Reconstruction and Forest Inventory on a Mobile Robotic System
Mar 26, 2024Terrestrial laser scanning (TLS) is the standard technique used to create accurate point clouds for digital forest inventories. However, the measurement process is demanding, requiring up to two days per hectare for data collection, significant data storage, as well as resource-heavy post-processing of 3D data. In this work, we present a real-time mapping and analysis system that enables online generation of forest inventories using mobile laser scanners that can be mounted e.g. on mobile robots. Given incrementally created and locally accurate submaps-data payloads-our approach extracts tree candidates using a custom, Voronoi-inspired clustering algorithm. Tree candidates are reconstructed using an adapted Hough algorithm, which enables robust modeling of the tree stem. Further, we explicitly incorporate the incremental nature of the data collection by consistently updating the database using a pose graph LiDAR SLAM system. This enables us to refine our estimates of the tree traits if an area is revisited later during a mission. We demonstrate competitive accuracy to TLS or manual measurements using laser scanners that we mounted on backpacks or mobile robots operating in conifer, broad-leaf and mixed forests. Our results achieve RMSE of 1.93 cm, a bias of 0.65 cm and a standard deviation of 1.81 cm (averaged across these sequences)-with no post-processing required after the mission is complete.
Probing the Robustness of Time-series Forecasting Models with CounterfacTS
Mar 06, 2024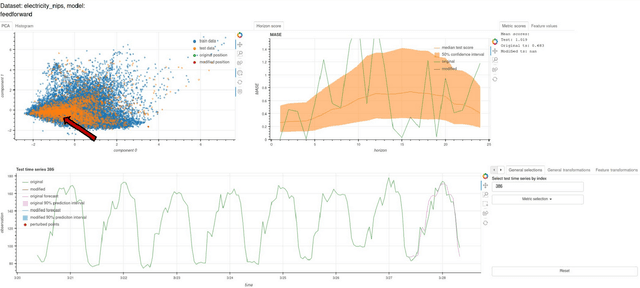
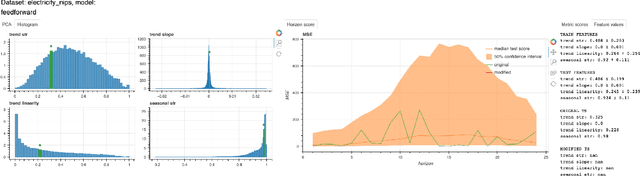
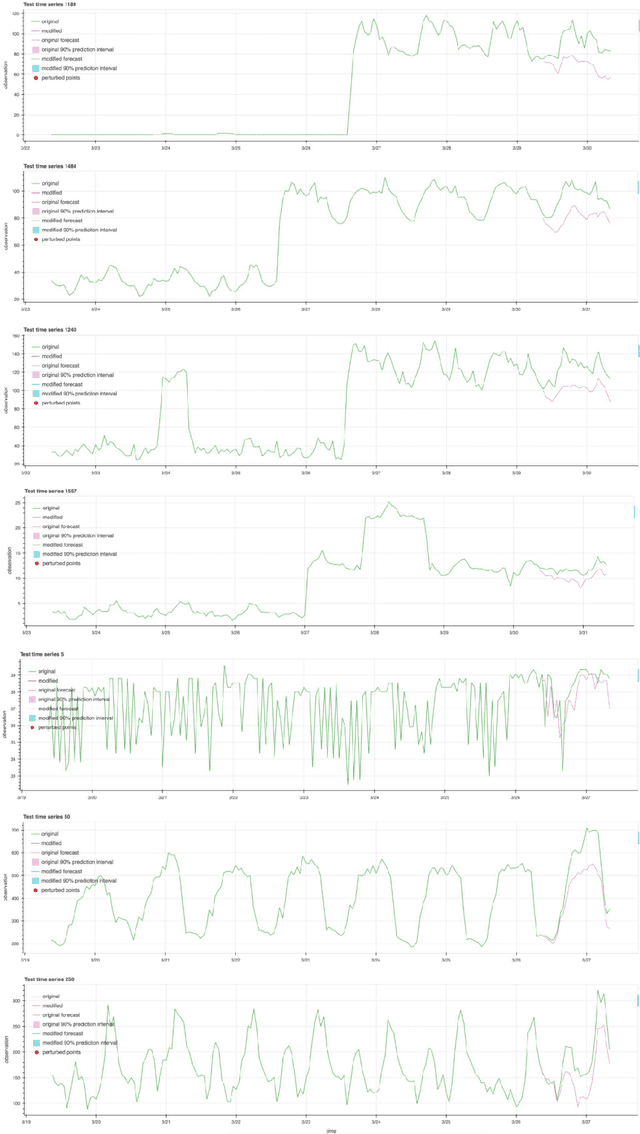
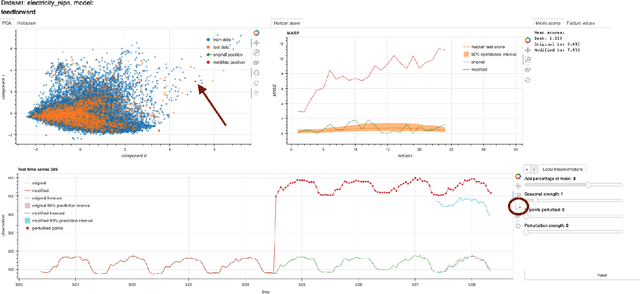
A common issue for machine learning models applied to time-series forecasting is the temporal evolution of the data distributions (i.e., concept drift). Because most of the training data does not reflect such changes, the models present poor performance on the new out-of-distribution scenarios and, therefore, the impact of such events cannot be reliably anticipated ahead of time. We present and publicly release CounterfacTS, a tool to probe the robustness of deep learning models in time-series forecasting tasks via counterfactuals. CounterfacTS has a user-friendly interface that allows the user to visualize, compare and quantify time series data and their forecasts, for a number of datasets and deep learning models. Furthermore, the user can apply various transformations to the time series and explore the resulting changes in the forecasts in an interpretable manner. Through example cases, we illustrate how CounterfacTS can be used to i) identify the main features characterizing and differentiating sets of time series, ii) assess how the model performance depends on these characateristics, and iii) guide transformations of the original time series to create counterfactuals with desired properties for training and increasing the forecasting performance in new regions of the data distribution. We discuss the importance of visualizing and considering the location of the data in a projected feature space to transform time-series and create effective counterfactuals for training the models. Overall, CounterfacTS aids at creating counterfactuals to efficiently explore the impact of hypothetical scenarios not covered by the original data in time-series forecasting tasks.
Towards Trustworthy Automated Driving through Qualitative Scene Understanding and Explanations
Mar 25, 2024Understanding driving scenes and communicating automated vehicle decisions are key requirements for trustworthy automated driving. In this article, we introduce the Qualitative Explainable Graph (QXG), which is a unified symbolic and qualitative representation for scene understanding in urban mobility. The QXG enables interpreting an automated vehicle's environment using sensor data and machine learning models. It utilizes spatio-temporal graphs and qualitative constraints to extract scene semantics from raw sensor inputs, such as LiDAR and camera data, offering an interpretable scene model. A QXG can be incrementally constructed in real-time, making it a versatile tool for in-vehicle explanations across various sensor types. Our research showcases the potential of QXG, particularly in the context of automated driving, where it can rationalize decisions by linking the graph with observed actions. These explanations can serve diverse purposes, from informing passengers and alerting vulnerable road users to enabling post-hoc analysis of prior behaviors.
Learning from Reduced Labels for Long-Tailed Data
Mar 25, 2024Long-tailed data is prevalent in real-world classification tasks and heavily relies on supervised information, which makes the annotation process exceptionally labor-intensive and time-consuming. Unfortunately, despite being a common approach to mitigate labeling costs, existing weakly supervised learning methods struggle to adequately preserve supervised information for tail samples, resulting in a decline in accuracy for the tail classes. To alleviate this problem, we introduce a novel weakly supervised labeling setting called Reduced Label. The proposed labeling setting not only avoids the decline of supervised information for the tail samples, but also decreases the labeling costs associated with long-tailed data. Additionally, we propose an straightforward and highly efficient unbiased framework with strong theoretical guarantees to learn from these Reduced Labels. Extensive experiments conducted on benchmark datasets including ImageNet validate the effectiveness of our approach, surpassing the performance of state-of-the-art weakly supervised methods.
Natural Language Requirements Testability Measurement Based on Requirement Smells
Mar 26, 2024Requirements form the basis for defining software systems' obligations and tasks. Testable requirements help prevent failures, reduce maintenance costs, and make it easier to perform acceptance tests. However, despite the importance of measuring and quantifying requirements testability, no automatic approach for measuring requirements testability has been proposed based on the requirements smells, which are at odds with the requirements testability. This paper presents a mathematical model to evaluate and rank the natural language requirements testability based on an extensive set of nine requirements smells, detected automatically, and acceptance test efforts determined by requirement length and its application domain. Most of the smells stem from uncountable adjectives, context-sensitive, and ambiguous words. A comprehensive dictionary is required to detect such words. We offer a neural word-embedding technique to generate such a dictionary automatically. Using the dictionary, we could automatically detect Polysemy smell (domain-specific ambiguity) for the first time in 10 application domains. Our empirical study on nearly 1000 software requirements from six well-known industrial and academic projects demonstrates that the proposed smell detection approach outperforms Smella, a state-of-the-art tool, in detecting requirements smells. The precision and recall of smell detection are improved with an average of 0.03 and 0.33, respectively, compared to the state-of-the-art. The proposed requirement testability model measures the testability of 985 requirements with a mean absolute error of 0.12 and a mean squared error of 0.03, demonstrating the model's potential for practical use.
Towards a RAG-based Summarization Agent for the Electron-Ion Collider
Mar 26, 2024The complexity and sheer volume of information encompassing documents, papers, data, and other resources from large-scale experiments demand significant time and effort to navigate, making the task of accessing and utilizing these varied forms of information daunting, particularly for new collaborators and early-career scientists. To tackle this issue, a Retrieval Augmented Generation (RAG)--based Summarization AI for EIC (RAGS4EIC) is under development. This AI-Agent not only condenses information but also effectively references relevant responses, offering substantial advantages for collaborators. Our project involves a two-step approach: first, querying a comprehensive vector database containing all pertinent experiment information; second, utilizing a Large Language Model (LLM) to generate concise summaries enriched with citations based on user queries and retrieved data. We describe the evaluation methods that use RAG assessments (RAGAs) scoring mechanisms to assess the effectiveness of responses. Furthermore, we describe the concept of prompt template-based instruction-tuning which provides flexibility and accuracy in summarization. Importantly, the implementation relies on LangChain, which serves as the foundation of our entire workflow. This integration ensures efficiency and scalability, facilitating smooth deployment and accessibility for various user groups within the Electron Ion Collider (EIC) community. This innovative AI-driven framework not only simplifies the understanding of vast datasets but also encourages collaborative participation, thereby empowering researchers. As a demonstration, a web application has been developed to explain each stage of the RAG Agent development in detail.
Take Care of Your Prompt Bias! Investigating and Mitigating Prompt Bias in Factual Knowledge Extraction
Mar 26, 2024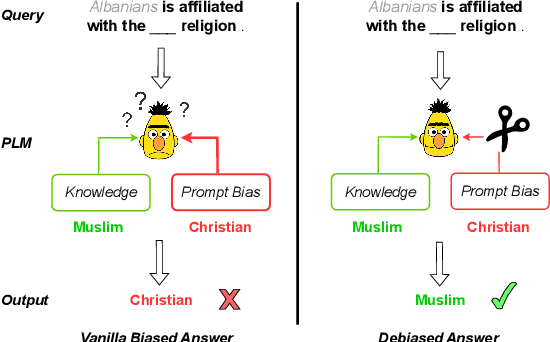
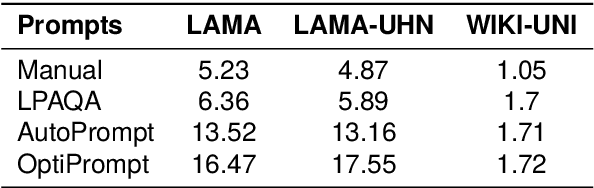
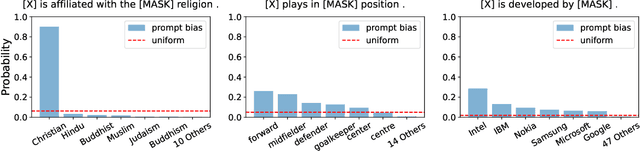
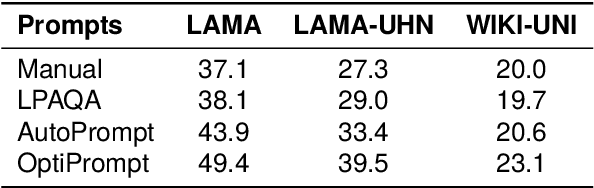
Recent research shows that pre-trained language models (PLMs) suffer from "prompt bias" in factual knowledge extraction, i.e., prompts tend to introduce biases toward specific labels. Prompt bias presents a significant challenge in assessing the factual knowledge within PLMs. Therefore, this paper aims to improve the reliability of existing benchmarks by thoroughly investigating and mitigating prompt bias. We show that: 1) all prompts in the experiments exhibit non-negligible bias, with gradient-based prompts like AutoPrompt and OptiPrompt displaying significantly higher levels of bias; 2) prompt bias can amplify benchmark accuracy unreasonably by overfitting the test datasets, especially on imbalanced datasets like LAMA. Based on these findings, we propose a representation-based approach to mitigate the prompt bias during inference time. Specifically, we first estimate the biased representation using prompt-only querying, and then remove it from the model's internal representations to generate the debiased representations, which are used to produce the final debiased outputs. Experiments across various prompts, PLMs, and benchmarks show that our approach can not only correct the overfitted performance caused by prompt bias, but also significantly improve the prompt retrieval capability (up to 10% absolute performance gain). These results indicate that our approach effectively alleviates prompt bias in knowledge evaluation, thereby enhancing the reliability of benchmark assessments. Hopefully, our plug-and-play approach can be a golden standard to strengthen PLMs toward reliable knowledge bases. Code and data are released in https://github.com/FelliYang/PromptBias.