 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning Space-Time Continuous Neural PDEs from Partially Observed States
Jul 09, 2023
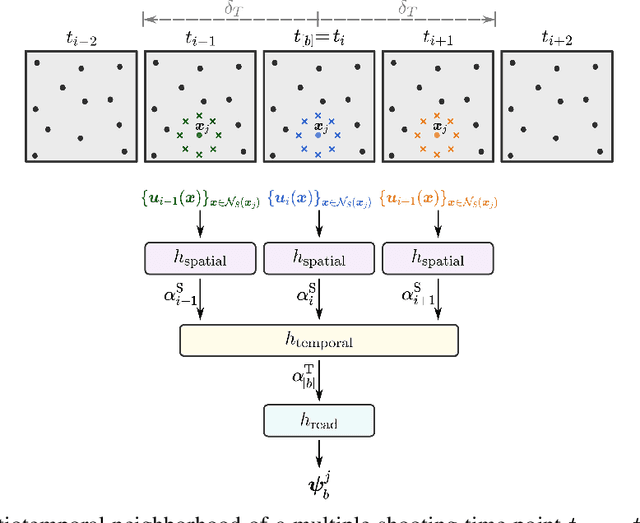
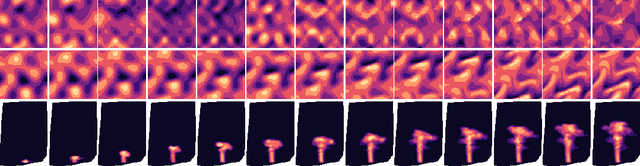
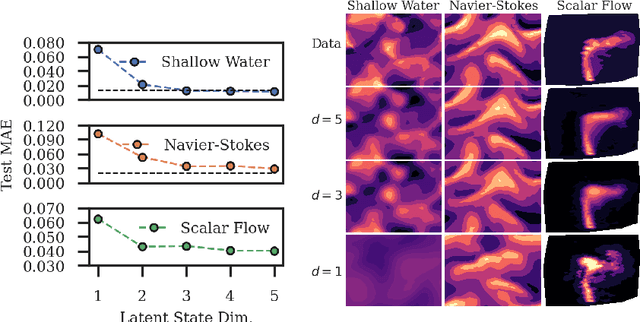
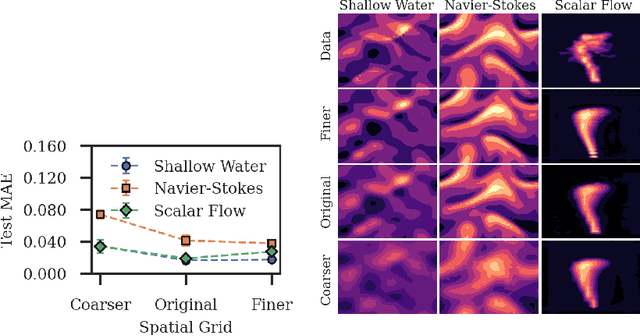
We introduce a novel grid-independent model for learning partial differential equations (PDEs) from noisy and partial observations on irregular spatiotemporal grids. We propose a space-time continuous latent neural PDE model with an efficient probabilistic framework and a novel encoder design for improved data efficiency and grid independence. The latent state dynamics are governed by a PDE model that combines the collocation method and the method of lines. We employ amortized variational inference for approximate posterior estimation and utilize a multiple shooting technique for enhanced training speed and stability. Our model demonstrates state-of-the-art performance on complex synthetic and real-world datasets, overcoming limitations of previous approaches and effectively handling partially-observed data. The proposed model outperforms recent methods, showing its potential to advance data-driven PDE modeling and enabling robust, grid-independent modeling of complex partially-observed dynamic processes.
Exploring Multi-Modal Contextual Knowledge for Open-Vocabulary Object Detection
Aug 30, 2023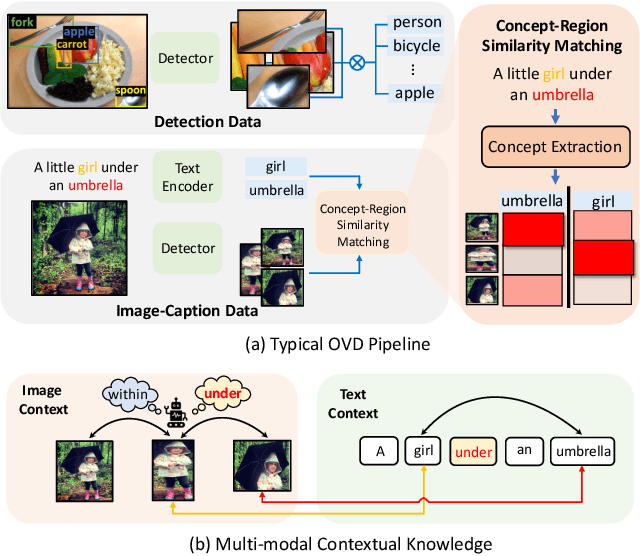
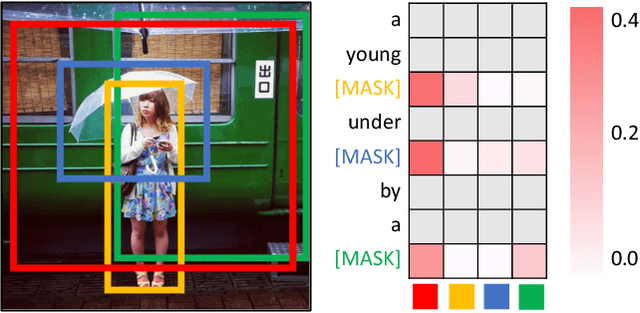
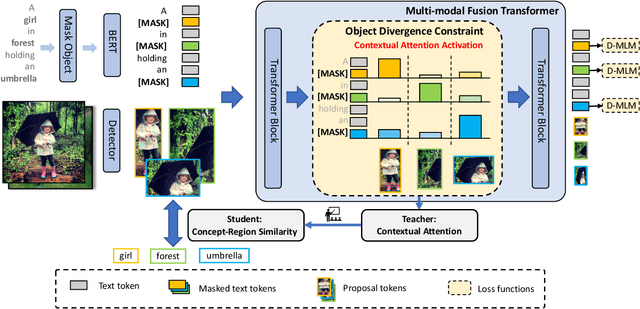
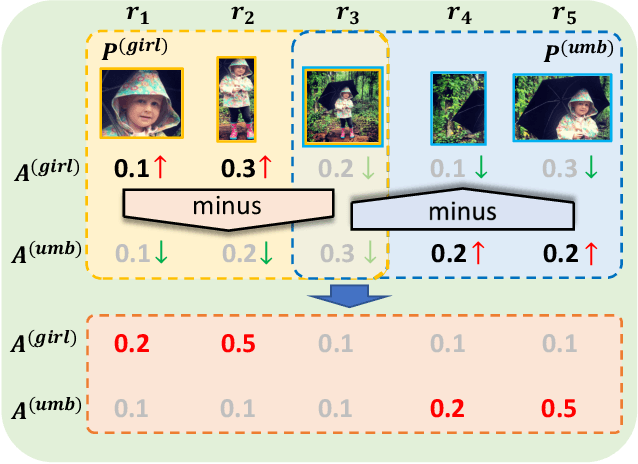
In this paper, we for the first time explore helpful multi-modal contextual knowledge to understand novel categories for open-vocabulary object detection (OVD). The multi-modal contextual knowledge stands for the joint relationship across regions and words. However, it is challenging to incorporate such multi-modal contextual knowledge into OVD. The reason is that previous detection frameworks fail to jointly model multi-modal contextual knowledge, as object detectors only support vision inputs and no caption description is provided at test time. To this end, we propose a multi-modal contextual knowledge distillation framework, MMC-Det, to transfer the learned contextual knowledge from a teacher fusion transformer with diverse multi-modal masked language modeling (D-MLM) to a student detector. The diverse multi-modal masked language modeling is realized by an object divergence constraint upon traditional multi-modal masked language modeling (MLM), in order to extract fine-grained region-level visual contexts, which are vital to object detection. Extensive experiments performed upon various detection datasets show the effectiveness of our multi-modal context learning strategy, where our approach well outperforms the recent state-of-the-art methods.
LMBiS-Net: A Lightweight Multipath Bidirectional Skip Connection based CNN for Retinal Blood Vessel Segmentation
Sep 10, 2023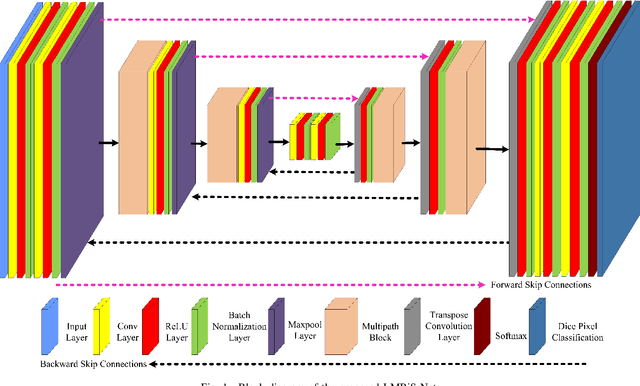
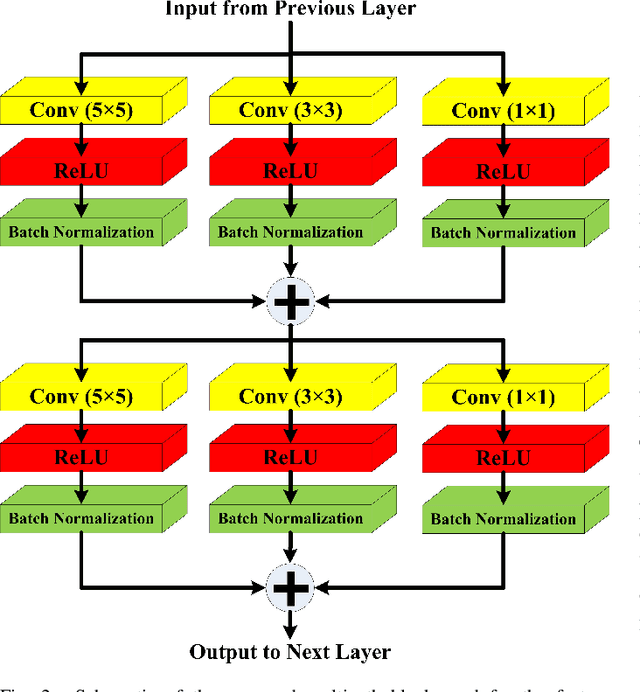
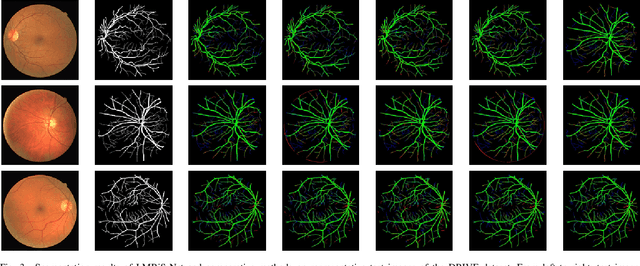
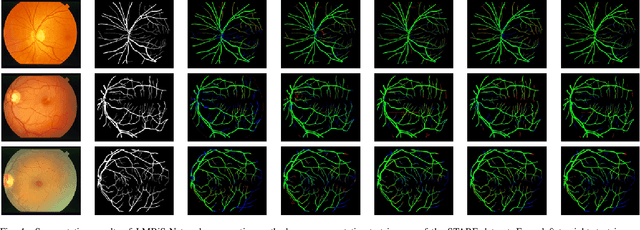
Blinding eye diseases are often correlated with altered retinal morphology, which can be clinically identified by segmenting retinal structures in fundus images. However, current methodologies often fall short in accurately segmenting delicate vessels. Although deep learning has shown promise in medical image segmentation, its reliance on repeated convolution and pooling operations can hinder the representation of edge information, ultimately limiting overall segmentation accuracy. In this paper, we propose a lightweight pixel-level CNN named LMBiS-Net for the segmentation of retinal vessels with an exceptionally low number of learnable parameters \textbf{(only 0.172 M)}. The network used multipath feature extraction blocks and incorporates bidirectional skip connections for the information flow between the encoder and decoder. Additionally, we have optimized the efficiency of the model by carefully selecting the number of filters to avoid filter overlap. This optimization significantly reduces training time and enhances computational efficiency. To assess the robustness and generalizability of LMBiS-Net, we performed comprehensive evaluations on various aspects of retinal images. Specifically, the model was subjected to rigorous tests to accurately segment retinal vessels, which play a vital role in ophthalmological diagnosis and treatment. By focusing on the retinal blood vessels, we were able to thoroughly analyze the performance and effectiveness of the LMBiS-Net model. The results of our tests demonstrate that LMBiS-Net is not only robust and generalizable but also capable of maintaining high levels of segmentation accuracy. These characteristics highlight the potential of LMBiS-Net as an efficient tool for high-speed and accurate segmentation of retinal images in various clinical applications.
Evaluating Deep Learning Assisted Automated Aquaculture Net Pens Inspection Using ROV
Aug 26, 2023


In marine aquaculture, inspecting sea cages is an essential activity for managing both the facilities' environmental impact and the quality of the fish development process. Fish escape from fish farms into the open sea due to net damage, which can result in significant financial losses and compromise the nearby marine ecosystem. The traditional inspection system in use relies on visual inspection by expert divers or ROVs, which is not only laborious, time-consuming, and inaccurate but also largely dependent on the level of knowledge of the operator and has a poor degree of verifiability. This article presents a robotic-based automatic net defect detection system for aquaculture net pens oriented to on-ROV processing and real-time detection. The proposed system takes a video stream from an onboard camera of the ROV, employs a deep learning detector, and segments the defective part of the image from the background under different underwater conditions. The system was first tested using a set of collected images for comparison with the state-of-the-art approaches and then using the ROV inspection sequences to evaluate its effectiveness in real-world scenarios. Results show that our approach presents high levels of accuracy even for adverse scenarios and is adequate for real-time processing on embedded platforms.
Tempestas ex machina: A review of machine learning methods for wavefront control
Sep 01, 2023As we look to the next generation of adaptive optics systems, now is the time to develop and explore the technologies that will allow us to image rocky Earth-like planets; wavefront control algorithms are not only a crucial component of these systems, but can benefit our adaptive optics systems without requiring increased detector speed and sensitivity or more effective and efficient deformable mirrors. To date, most observatories run the workhorse of their wavefront control as a classic integral controller, which estimates a correction from wavefront sensor residuals, and attempts to apply that correction as fast as possible in closed-loop. An integrator of this nature fails to address temporal lag errors that evolve over scales faster than the correction time, as well as vibrations or dynamic errors within the system that are not encapsulated in the wavefront sensor residuals; these errors impact high contrast imaging systems with complex coronagraphs. With the rise in popularity of machine learning, many are investigating applying modern machine learning methods to wavefront control. Furthermore, many linear implementations of machine learning methods (under varying aliases) have been in development for wavefront control for the last 30-odd years. With this work we define machine learning in its simplest terms, explore the most common machine learning methods applied in the context of this problem, and present a review of the literature concerning novel machine learning approaches to wavefront control.
Self-Supervised Pretraining Improves Performance and Inference Efficiency in Multiple Lung Ultrasound Interpretation Tasks
Sep 05, 2023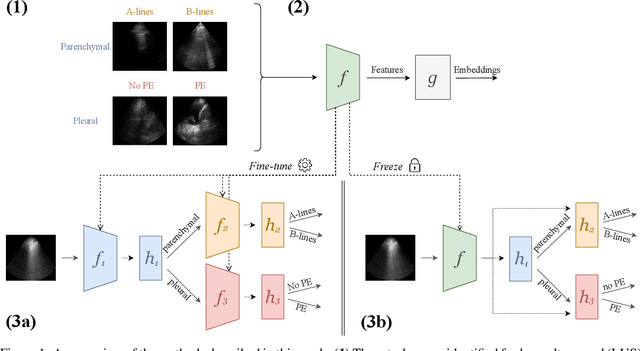

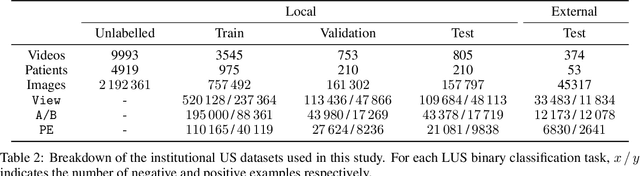
In this study, we investigated whether self-supervised pretraining could produce a neural network feature extractor applicable to multiple classification tasks in B-mode lung ultrasound analysis. When fine-tuning on three lung ultrasound tasks, pretrained models resulted in an improvement of the average across-task area under the receiver operating curve (AUC) by 0.032 and 0.061 on local and external test sets respectively. Compact nonlinear classifiers trained on features outputted by a single pretrained model did not improve performance across all tasks; however, they did reduce inference time by 49% compared to serial execution of separate fine-tuned models. When training using 1% of the available labels, pretrained models consistently outperformed fully supervised models, with a maximum observed test AUC increase of 0.396 for the task of view classification. Overall, the results indicate that self-supervised pretraining is useful for producing initial weights for lung ultrasound classifiers.
GO-SLAM: Global Optimization for Consistent 3D Instant Reconstruction
Sep 05, 2023Neural implicit representations have recently demonstrated compelling results on dense Simultaneous Localization And Mapping (SLAM) but suffer from the accumulation of errors in camera tracking and distortion in the reconstruction. Purposely, we present GO-SLAM, a deep-learning-based dense visual SLAM framework globally optimizing poses and 3D reconstruction in real-time. Robust pose estimation is at its core, supported by efficient loop closing and online full bundle adjustment, which optimize per frame by utilizing the learned global geometry of the complete history of input frames. Simultaneously, we update the implicit and continuous surface representation on-the-fly to ensure global consistency of 3D reconstruction. Results on various synthetic and real-world datasets demonstrate that GO-SLAM outperforms state-of-the-art approaches at tracking robustness and reconstruction accuracy. Furthermore, GO-SLAM is versatile and can run with monocular, stereo, and RGB-D input.
Latent Disentanglement in Mesh Variational Autoencoders Improves the Diagnosis of Craniofacial Syndromes and Aids Surgical Planning
Sep 05, 2023
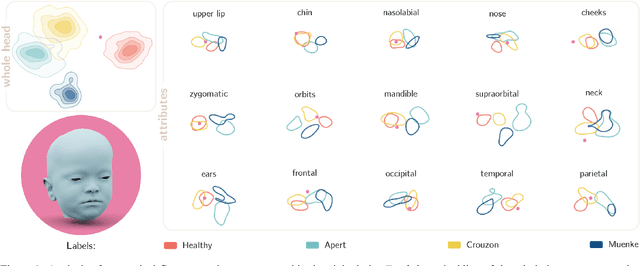
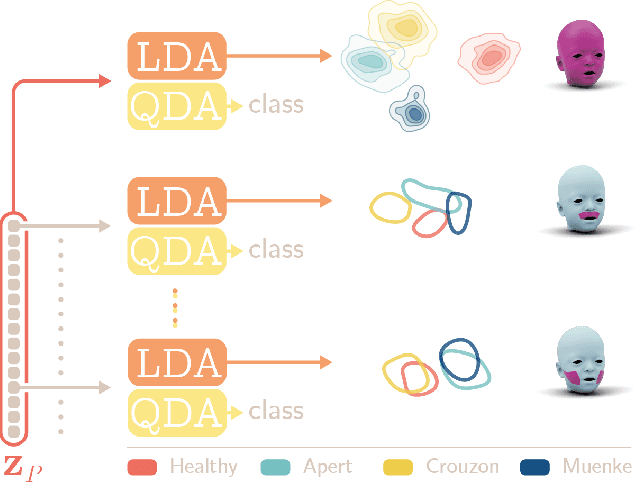
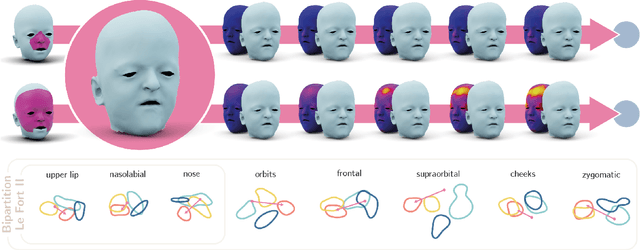
The use of deep learning to undertake shape analysis of the complexities of the human head holds great promise. However, there have traditionally been a number of barriers to accurate modelling, especially when operating on both a global and local level. In this work, we will discuss the application of the Swap Disentangled Variational Autoencoder (SD-VAE) with relevance to Crouzon, Apert and Muenke syndromes. Although syndrome classification is performed on the entire mesh, it is also possible, for the first time, to analyse the influence of each region of the head on the syndromic phenotype. By manipulating specific parameters of the generative model, and producing procedure-specific new shapes, it is also possible to simulate the outcome of a range of craniofacial surgical procedures. This opens new avenues to advance diagnosis, aids surgical planning and allows for the objective evaluation of surgical outcomes.
Time-Domain Wideband ISM for Spherical Microphone Arrays
Jun 15, 2023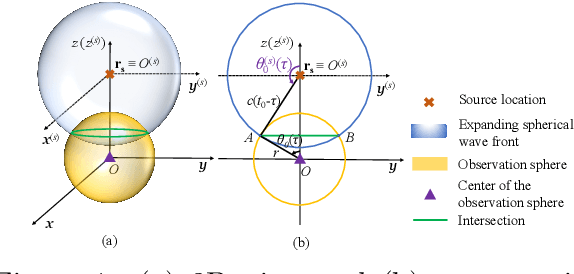
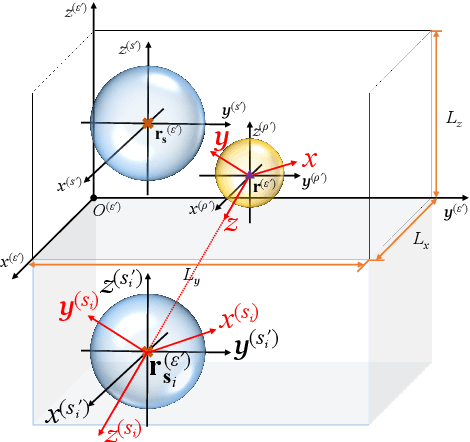
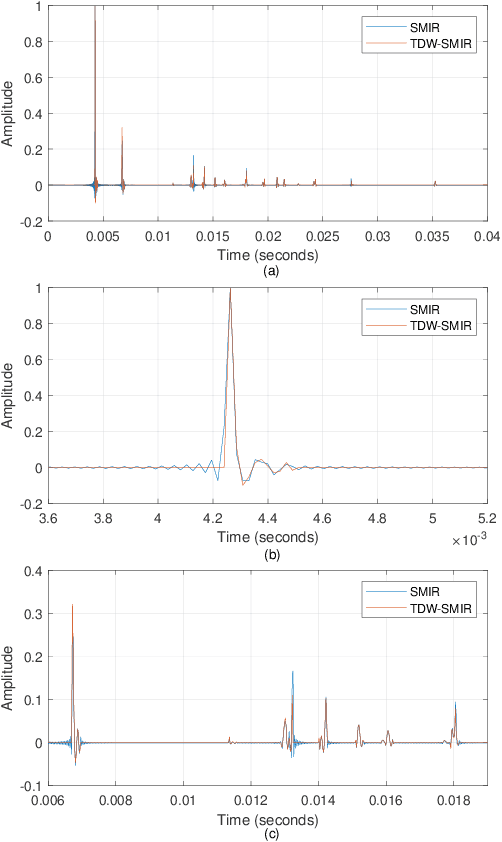
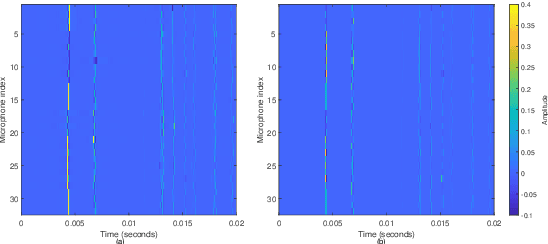
This paper presents the time-domain wideband spherical microphone array impulse response generator (TDW-SMIR generator), which is a time-domain wideband image source method (ISM) for generating the room impulse responses captured by an open spherical microphone array. To incorporate loudspeaker directivity, the TDW-SMIR generator considers a source that emits a sequence of spherical wave fronts whose amplitudes are related to the loudspeaker directional impulse responses measured in the far-field. The TDW-SMIR generator uses geometric models to derive the time-domain signals recorded by the spherical microphone array. Comparisons are made with frequency-domain single band ISMs. Simulation results prove the results of the TDW-SMIR generator are similar to those of frequency-domain single band ISMs.
Biquality Learning: a Framework to Design Algorithms Dealing with Closed-Set Distribution Shifts
Aug 29, 2023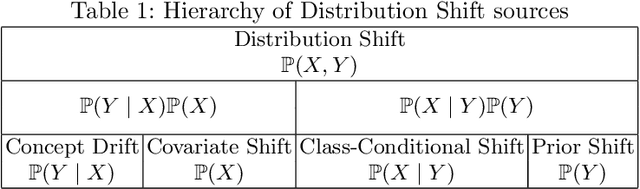
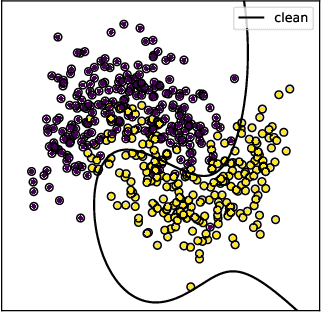
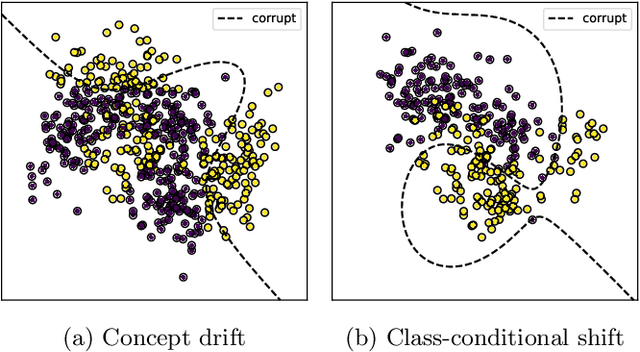
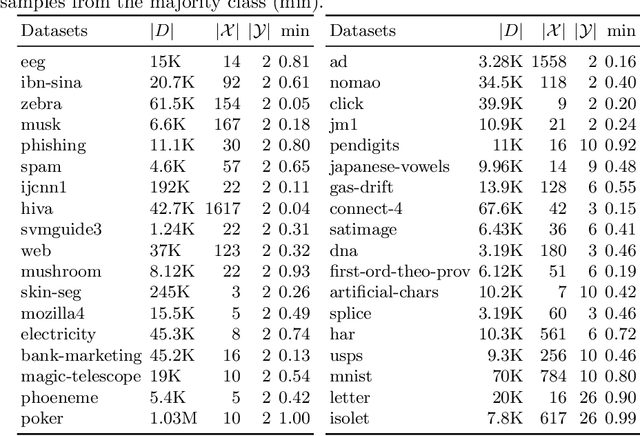
Training machine learning models from data with weak supervision and dataset shifts is still challenging. Designing algorithms when these two situations arise has not been explored much, and existing algorithms cannot always handle the most complex distributional shifts. We think the biquality data setup is a suitable framework for designing such algorithms. Biquality Learning assumes that two datasets are available at training time: a trusted dataset sampled from the distribution of interest and the untrusted dataset with dataset shifts and weaknesses of supervision (aka distribution shifts). The trusted and untrusted datasets available at training time make designing algorithms dealing with any distribution shifts possible. We propose two methods, one inspired by the label noise literature and another by the covariate shift literature for biquality learning. We experiment with two novel methods to synthetically introduce concept drift and class-conditional shifts in real-world datasets across many of them. We opened some discussions and assessed that developing biquality learning algorithms robust to distributional changes remains an interesting problem for future research.