 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning Quasi-Static 3D Models of Markerless Deformable Linear Objects for Bimanual Robotic Manipulation
Sep 14, 2023

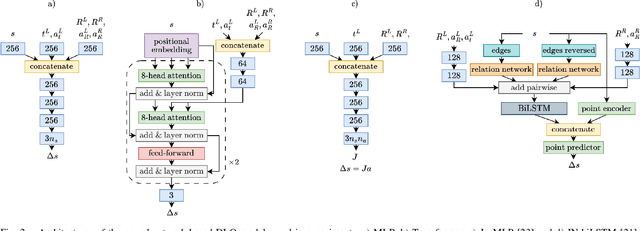
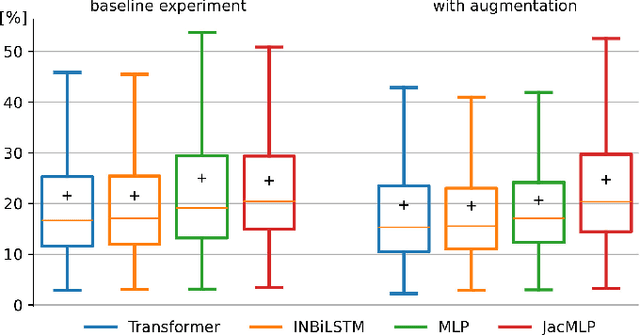
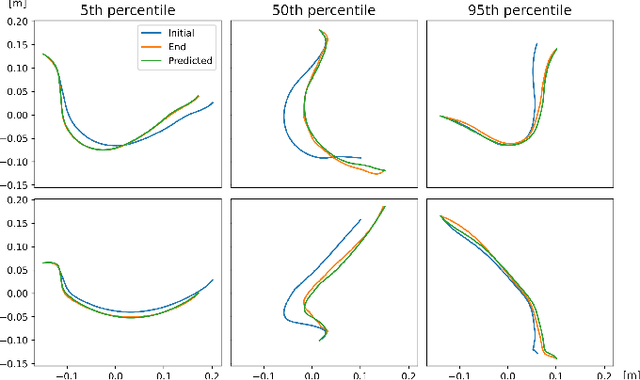
The robotic manipulation of Deformable Linear Objects (DLOs) is a vital and challenging task that is important in many practical applications. Classical model-based approaches to this problem require an accurate model to capture how robot motions affect the deformation of the DLO. Nowadays, data-driven models offer the best tradeoff between quality and computation time. This paper analyzes several learning-based 3D models of the DLO and proposes a new one based on the Transformer architecture that achieves superior accuracy, even on the DLOs of different lengths, thanks to the proposed scaling method. Moreover, we introduce a data augmentation technique, which improves the prediction performance of almost all considered DLO data-driven models. Thanks to this technique, even a simple Multilayer Perceptron (MLP) achieves close to state-of-the-art performance while being significantly faster to evaluate. In the experiments, we compare the performance of the learning-based 3D models of the DLO on several challenging datasets quantitatively and demonstrate their applicability in the task of shaping a DLO.
Assessing the nature of large language models: A caution against anthropocentrism
Sep 14, 2023Generative AI models garnered a large amount of public attention and speculation with the release of OpenAIs chatbot, ChatGPT. At least two opinion camps exist: one excited about possibilities these models offer for fundamental changes to human tasks, and another highly concerned about power these models seem to have. To address these concerns, we assessed GPT3.5 using standard, normed, and validated cognitive and personality measures. For this seedling project, we developed a battery of tests that allowed us to estimate the boundaries of some of these models capabilities, how stable those capabilities are over a short period of time, and how they compare to humans. Our results indicate that GPT 3.5 is unlikely to have developed sentience, although its ability to respond to personality inventories is interesting. It did display large variability in both cognitive and personality measures over repeated observations, which is not expected if it had a human-like personality. Variability notwithstanding, GPT3.5 displays what in a human would be considered poor mental health, including low self-esteem and marked dissociation from reality despite upbeat and helpful responses.
Where2Explore: Few-shot Affordance Learning for Unseen Novel Categories of Articulated Objects
Sep 14, 2023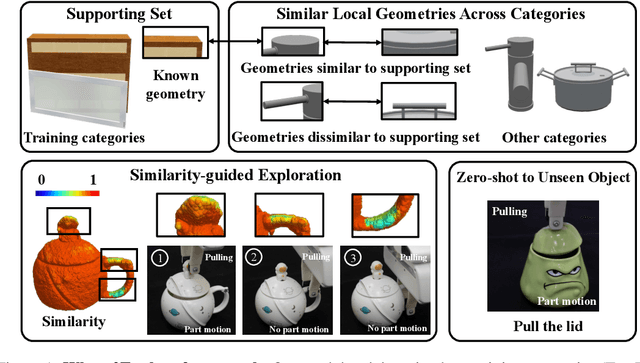
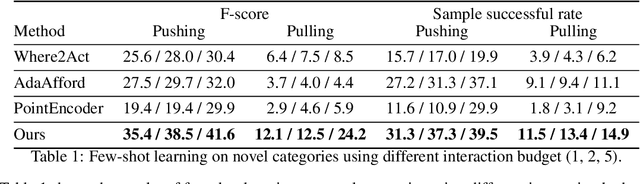
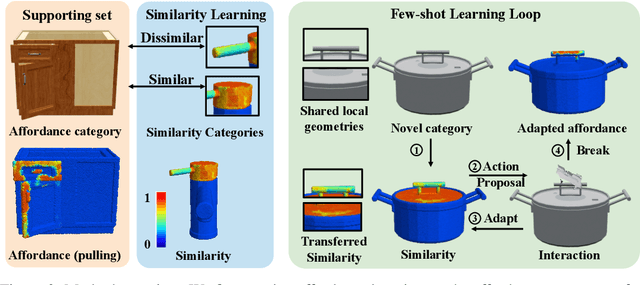
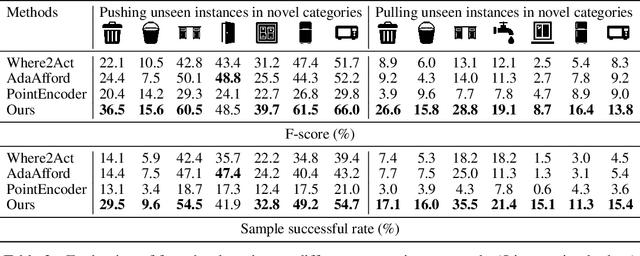
Articulated object manipulation is a fundamental yet challenging task in robotics. Due to significant geometric and semantic variations across object categories, previous manipulation models struggle to generalize to novel categories. Few-shot learning is a promising solution for alleviating this issue by allowing robots to perform a few interactions with unseen objects. However, extant approaches often necessitate costly and inefficient test-time interactions with each unseen instance. Recognizing this limitation, we observe that despite their distinct shapes, different categories often share similar local geometries essential for manipulation, such as pullable handles and graspable edges - a factor typically underutilized in previous few-shot learning works. To harness this commonality, we introduce 'Where2Explore', an affordance learning framework that effectively explores novel categories with minimal interactions on a limited number of instances. Our framework explicitly estimates the geometric similarity across different categories, identifying local areas that differ from shapes in the training categories for efficient exploration while concurrently transferring affordance knowledge to similar parts of the objects. Extensive experiments in simulated and real-world environments demonstrate our framework's capacity for efficient few-shot exploration and generalization.
Masked Generative Modeling with Enhanced Sampling Scheme
Sep 14, 2023This paper presents a novel sampling scheme for masked non-autoregressive generative modeling. We identify the limitations of TimeVQVAE, MaskGIT, and Token-Critic in their sampling processes, and propose Enhanced Sampling Scheme (ESS) to overcome these limitations. ESS explicitly ensures both sample diversity and fidelity, and consists of three stages: Naive Iterative Decoding, Critical Reverse Sampling, and Critical Resampling. ESS starts by sampling a token set using the naive iterative decoding as proposed in MaskGIT, ensuring sample diversity. Then, the token set undergoes the critical reverse sampling, masking tokens leading to unrealistic samples. After that, critical resampling reconstructs masked tokens until the final sampling step is reached to ensure high fidelity. Critical resampling uses confidence scores obtained from a self-Token-Critic to better measure the realism of sampled tokens, while critical reverse sampling uses the structure of the quantized latent vector space to discover unrealistic sample paths. We demonstrate significant performance gains of ESS in both unconditional sampling and class-conditional sampling using all the 128 datasets in the UCR Time Series archive.
DiariST: Streaming Speech Translation with Speaker Diarization
Sep 14, 2023End-to-end speech translation (ST) for conversation recordings involves several under-explored challenges such as speaker diarization (SD) without accurate word time stamps and handling of overlapping speech in a streaming fashion. In this work, we propose DiariST, the first streaming ST and SD solution. It is built upon a neural transducer-based streaming ST system and integrates token-level serialized output training and t-vector, which were originally developed for multi-talker speech recognition. Due to the absence of evaluation benchmarks in this area, we develop a new evaluation dataset, DiariST-AliMeeting, by translating the reference Chinese transcriptions of the AliMeeting corpus into English. We also propose new metrics, called speaker-agnostic BLEU and speaker-attributed BLEU, to measure the ST quality while taking SD accuracy into account. Our system achieves a strong ST and SD capability compared to offline systems based on Whisper, while performing streaming inference for overlapping speech. To facilitate the research in this new direction, we release the evaluation data, the offline baseline systems, and the evaluation code.
Non-Ideal Program-Time Conservation in Charge Trap Flash for Deep Learning
Jul 12, 2023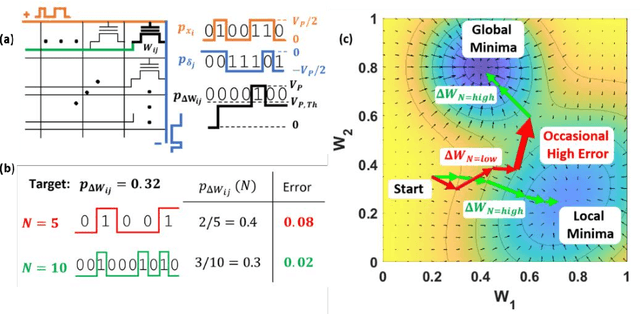
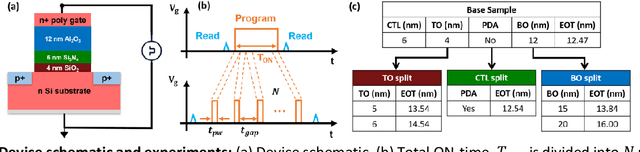
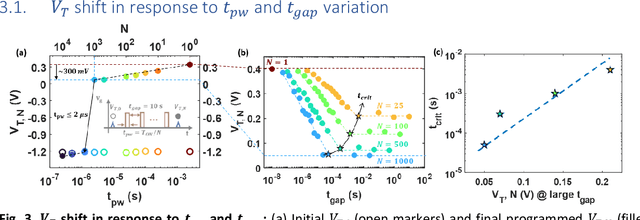
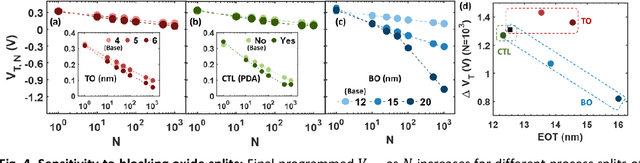
Training deep neural networks (DNNs) is computationally intensive but arrays of non-volatile memories like Charge Trap Flash (CTF) can accelerate DNN operations using in-memory computing. Specifically, the Resistive Processing Unit (RPU) architecture uses the voltage-threshold program by stochastic encoded pulse trains and analog memory features to accelerate vector-vector outer product and weight update for the gradient descent algorithms. Although CTF, offering high precision, has been regarded as an excellent choice for implementing RPU, the accumulation of charge due to the applied stochastic pulse trains is ultimately of critical significance in determining the final weight update. In this paper, we report the non-ideal program-time conservation in CTF through pulsing input measurements. We experimentally measure the effect of pulse width and pulse gap, keeping the total ON-time of the input pulse train constant, and report three non-idealities: (1) Cumulative V_T shift reduces when total ON-time is fragmented into a larger number of shorter pulses, (2) Cumulative V_T shift drops abruptly for pulse widths < 2 {\mu}s, (3) Cumulative V_T shift depends on the gap between consecutive pulses and the V_T shift reduction gets recovered for smaller gaps. We present an explanation based on a transient tunneling field enhancement due to blocking oxide trap-charge dynamics to explain these non-idealities. Identifying and modeling the responsible mechanisms and predicting their system-level effects during learning is critical. This non-ideal accumulation is expected to affect algorithms and architectures relying on devices for implementing mathematically equivalent functions for in-memory computing-based acceleration.
Enhancing Continuous Time Series Modelling with a Latent ODE-LSTM Approach
Jul 11, 2023
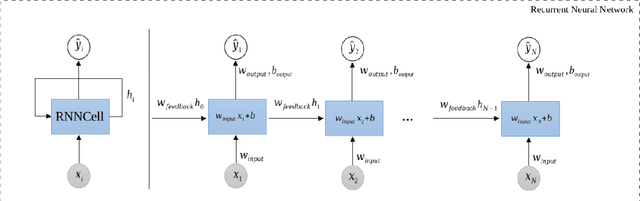
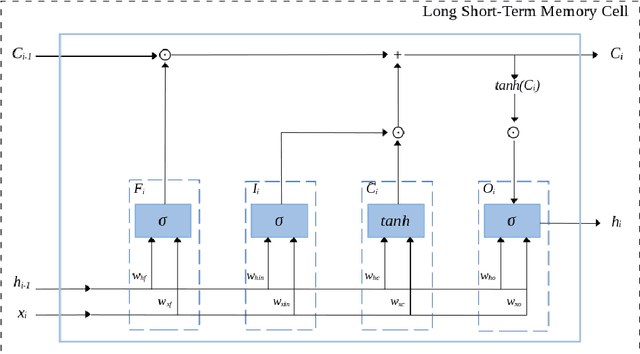

Due to their dynamic properties such as irregular sampling rate and high-frequency sampling, Continuous Time Series (CTS) are found in many applications. Since CTS with irregular sampling rate are difficult to model with standard Recurrent Neural Networks (RNNs), RNNs have been generalised to have continuous-time hidden dynamics defined by a Neural Ordinary Differential Equation (Neural ODE), leading to the ODE-RNN model. Another approach that provides a better modelling is that of the Latent ODE model, which constructs a continuous-time model where a latent state is defined at all times. The Latent ODE model uses a standard RNN as the encoder and a Neural ODE as the decoder. However, since the RNN encoder leads to difficulties with missing data and ill-defined latent variables, a Latent ODE-RNN model has recently been proposed that uses a ODE-RNN model as the encoder instead. Both the Latent ODE and Latent ODE-RNN models are difficult to train due to the vanishing and exploding gradients problem. To overcome this problem, the main contribution of this paper is to propose and illustrate a new model based on a new Latent ODE using an ODE-LSTM (Long Short-Term Memory) network as an encoder -- the Latent ODE-LSTM model. To limit the growth of the gradients the Norm Gradient Clipping strategy was embedded on the Latent ODE-LSTM model. The performance evaluation of the new Latent ODE-LSTM (with and without Norm Gradient Clipping) for modelling CTS with regular and irregular sampling rates is then demonstrated. Numerical experiments show that the new Latent ODE-LSTM performs better than Latent ODE-RNNs and can avoid the vanishing and exploding gradients during training.
Temporal compressive edge imaging enabled by a lensless diffuser camera
Sep 13, 2023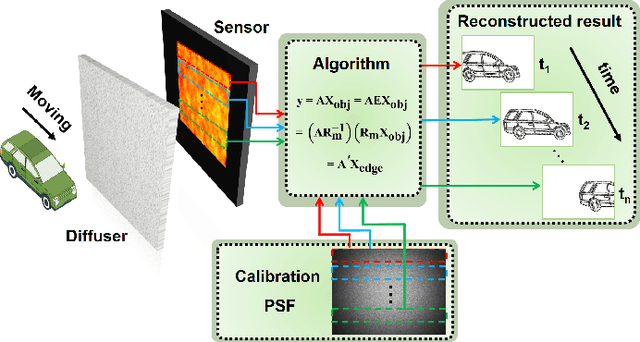

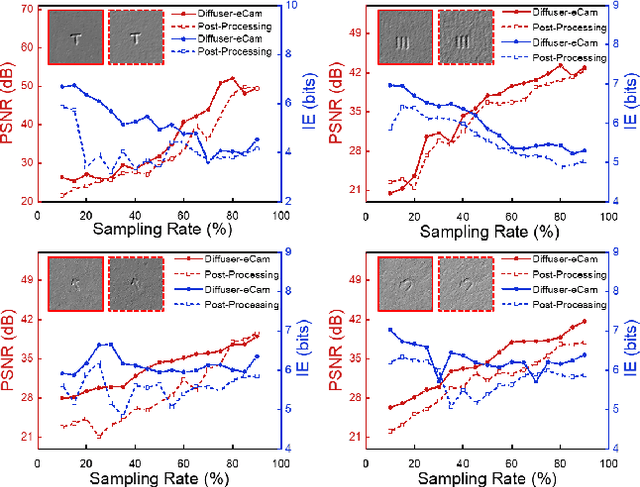

Lensless imagers based on diffusers or encoding masks enable high-dimensional imaging from a single shot measurement and have been applied in various applications. However, to further extract image information such as edge detection, conventional post-processing filtering operations are needed after the reconstruction of the original object images in the diffuser imaging systems. Here, we present the concept of a temporal compressive edge detection method based on a lensless diffuser camera, which can directly recover a time sequence of edge images of a moving object from a single-shot measurement, without further post-processing steps. Our approach provides higher image quality during edge detection, compared with the conventional post-processing method. We demonstrate the effectiveness of this approach by both numerical simulation and experiments. The proof-of-concept approach can be further developed with other image post-process operations or versatile computer vision assignments toward task-oriented intelligent lensless imaging systems.
VLSlice: Interactive Vision-and-Language Slice Discovery
Sep 13, 2023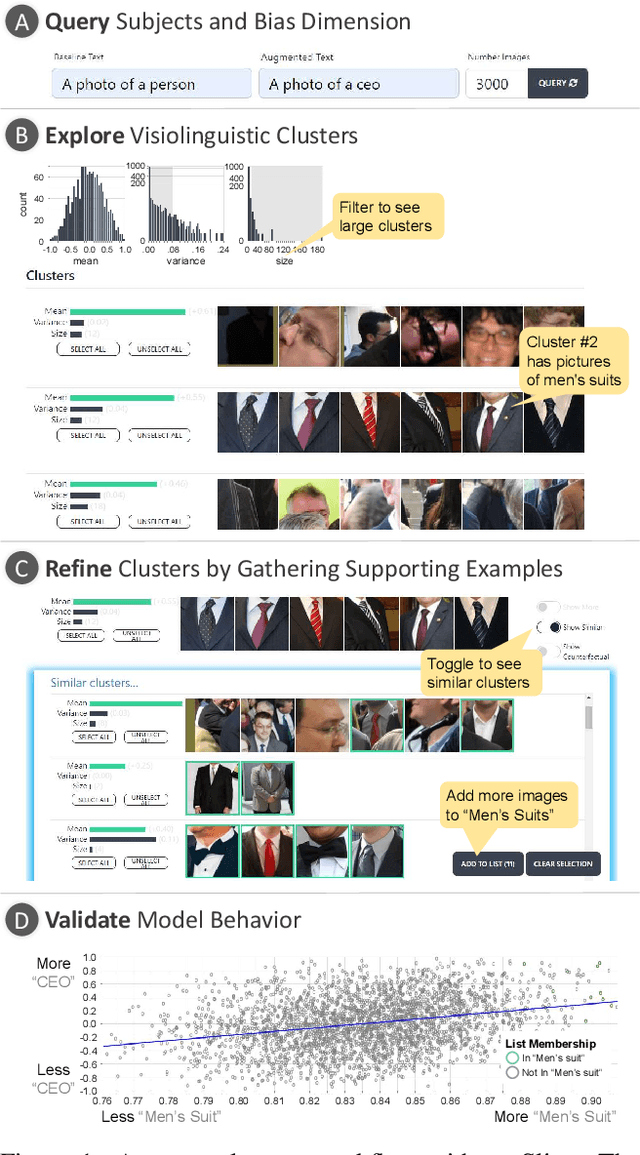
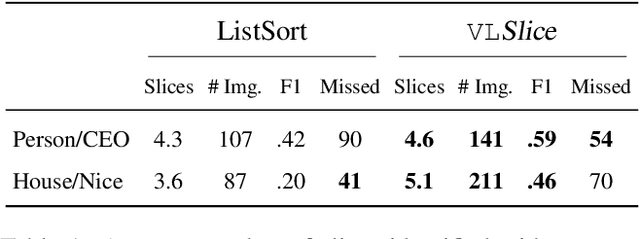

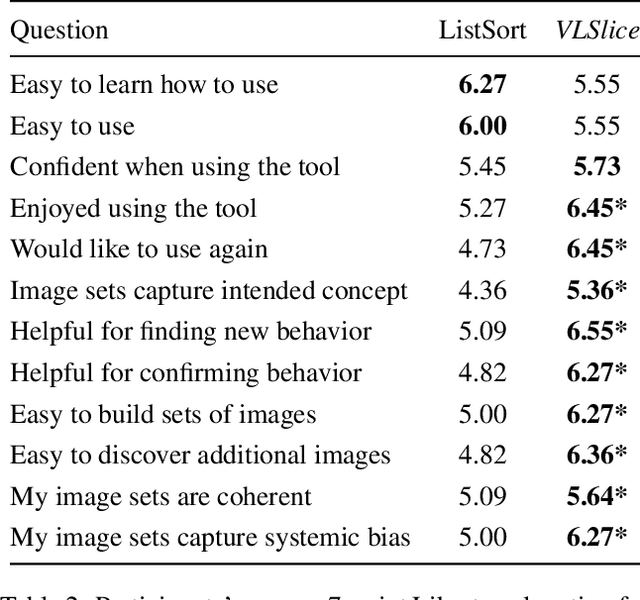
Recent work in vision-and-language demonstrates that large-scale pretraining can learn generalizable models that are efficiently transferable to downstream tasks. While this may improve dataset-scale aggregate metrics, analyzing performance around hand-crafted subgroups targeting specific bias dimensions reveals systemic undesirable behaviors. However, this subgroup analysis is frequently stalled by annotation efforts, which require extensive time and resources to collect the necessary data. Prior art attempts to automatically discover subgroups to circumvent these constraints but typically leverages model behavior on existing task-specific annotations and rapidly degrades on more complex inputs beyond "tabular" data, none of which study vision-and-language models. This paper presents VLSlice, an interactive system enabling user-guided discovery of coherent representation-level subgroups with consistent visiolinguistic behavior, denoted as vision-and-language slices, from unlabeled image sets. We show that VLSlice enables users to quickly generate diverse high-coherency slices in a user study (n=22) and release the tool publicly.
Can Whisper perform speech-based in-context learning
Sep 13, 2023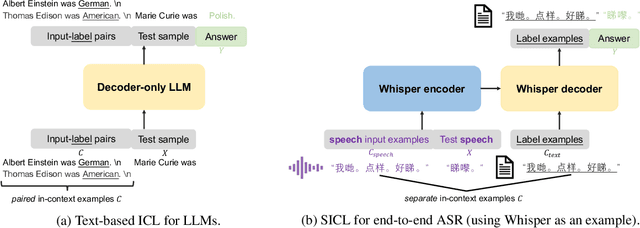
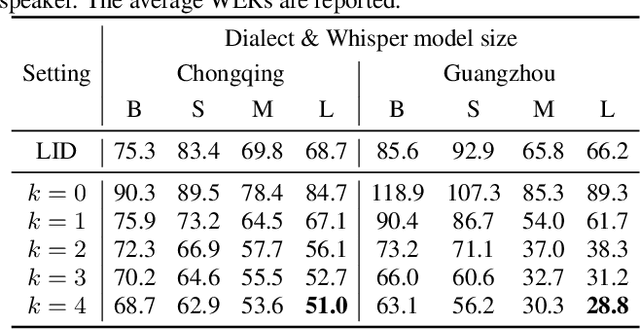
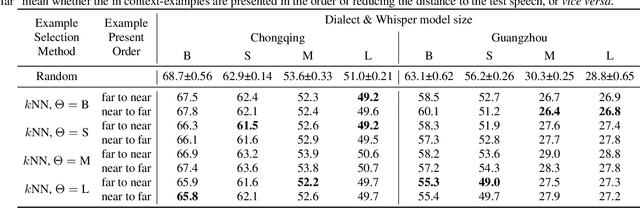
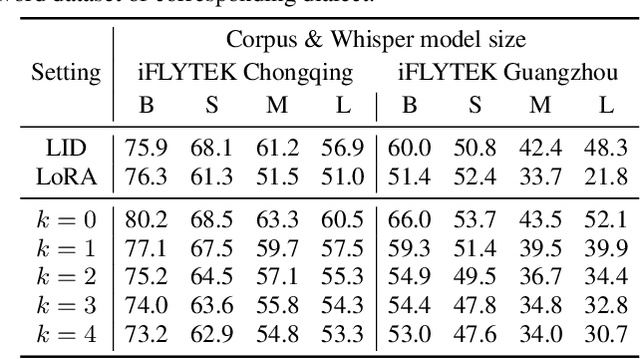
This paper investigates the in-context learning abilities of the Whisper automatic speech recognition (ASR) models released by OpenAI. A novel speech-based in-context learning (SICL) approach is proposed for test-time adaptation, which can reduce the word error rates (WERs) with only a small number of labelled speech samples without gradient descent. Language-level adaptation experiments using Chinese dialects showed that when applying SICL to isolated word ASR, consistent and considerable relative WER reductions can be achieved using Whisper models of any size on two dialects, which is on average 32.3%. A k-nearest-neighbours-based in-context example selection technique can be applied to further improve the efficiency of SICL, which can increase the average relative WER reduction to 36.4%. The findings are verified using speaker adaptation or continuous speech recognition tasks, and both achieved considerable relative WER reductions. Detailed quantitative analyses are also provided to shed light on SICL's adaptability to phonological variances and dialect-specific lexical nuances.