 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Enhancing Event Sequence Modeling with Contrastive Relational Inference
Sep 06, 2023
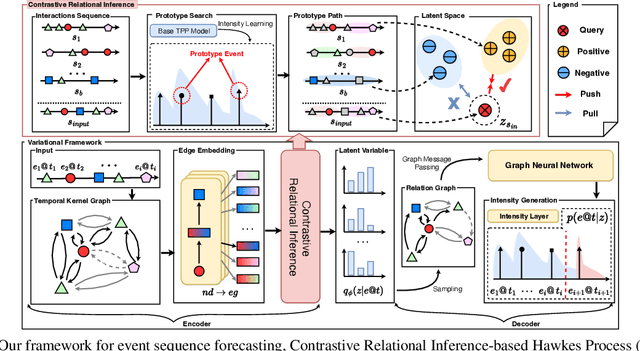
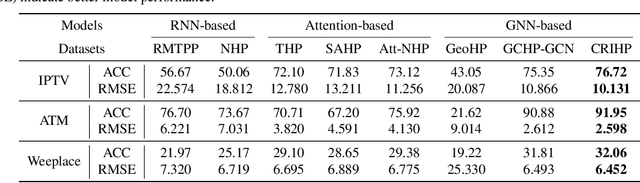
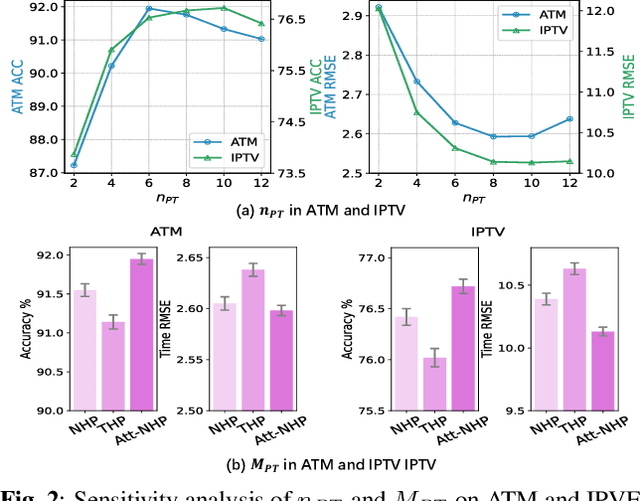
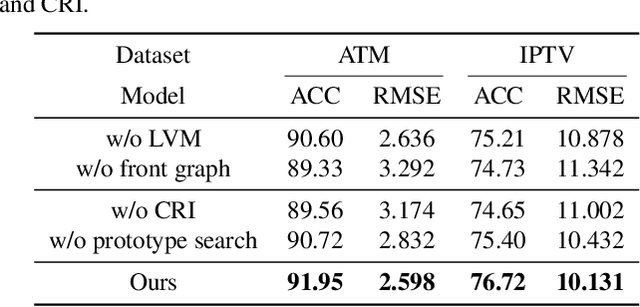
Neural temporal point processes(TPPs) have shown promise for modeling continuous-time event sequences. However, capturing the interactions between events is challenging yet critical for performing inference tasks like forecasting on event sequence data. Existing TPP models have focused on parameterizing the conditional distribution of future events but struggle to model event interactions. In this paper, we propose a novel approach that leverages Neural Relational Inference (NRI) to learn a relation graph that infers interactions while simultaneously learning the dynamics patterns from observational data. Our approach, the Contrastive Relational Inference-based Hawkes Process (CRIHP), reasons about event interactions under a variational inference framework. It utilizes intensity-based learning to search for prototype paths to contrast relationship constraints. Extensive experiments on three real-world datasets demonstrate the effectiveness of our model in capturing event interactions for event sequence modeling tasks.
SdCT-GAN: Reconstructing CT from Biplanar X-Rays with Self-driven Generative Adversarial Networks
Sep 10, 2023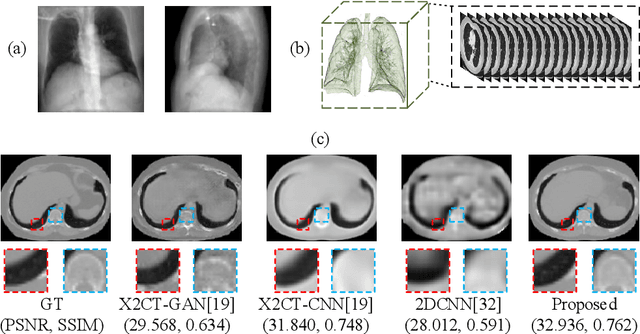
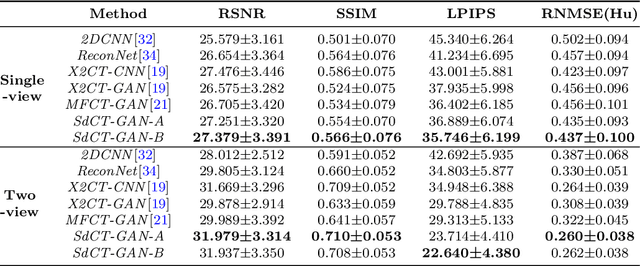
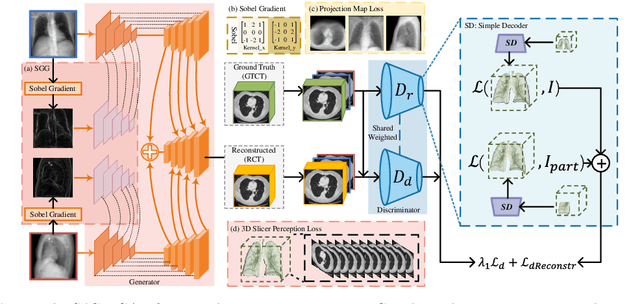

Computed Tomography (CT) is a medical imaging modality that can generate more informative 3D images than 2D X-rays. However, this advantage comes at the expense of more radiation exposure, higher costs, and longer acquisition time. Hence, the reconstruction of 3D CT images using a limited number of 2D X-rays has gained significant importance as an economical alternative. Nevertheless, existing methods primarily prioritize minimizing pixel/voxel-level intensity discrepancies, often neglecting the preservation of textural details in the synthesized images. This oversight directly impacts the quality of the reconstructed images and thus affects the clinical diagnosis. To address the deficits, this paper presents a new self-driven generative adversarial network model (SdCT-GAN), which is motivated to pay more attention to image details by introducing a novel auto-encoder structure in the discriminator. In addition, a Sobel Gradient Guider (SGG) idea is applied throughout the model, where the edge information from the 2D X-ray image at the input can be integrated. Moreover, LPIPS (Learned Perceptual Image Patch Similarity) evaluation metric is adopted that can quantitatively evaluate the fine contours and textures of reconstructed images better than the existing ones. Finally, the qualitative and quantitative results of the empirical studies justify the power of the proposed model compared to mainstream state-of-the-art baselines.
Comparative Analysis of Deep Learning Architectures for Breast Cancer Diagnosis Using the BreaKHis Dataset
Sep 10, 2023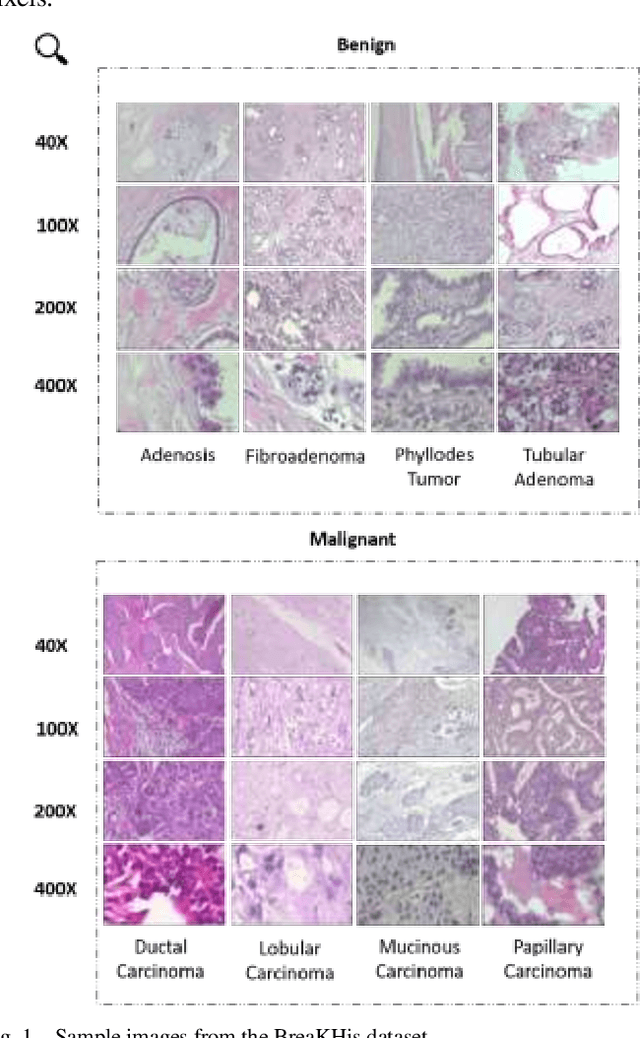

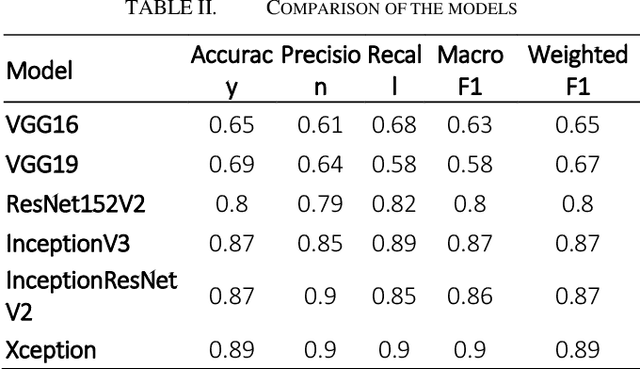
Cancer is an extremely difficult and dangerous health problem because it manifests in so many different ways and affects so many different organs and tissues. The primary goal of this research was to evaluate deep learning models' ability to correctly identify breast cancer cases using the BreakHis dataset. The BreakHis dataset covers a wide range of breast cancer subtypes through its huge collection of histopathological pictures. In this study, we use and compare the performance of five well-known deep learning models for cancer classification: VGG, ResNet, Xception, Inception, and InceptionResNet. The results placed the Xception model at the top, with an F1 score of 0.9 and an accuracy of 89%. At the same time, the Inception and InceptionResNet models both hit accuracy of 87% . However, the F1 score for the Inception model was 87, while that for the InceptionResNet model was 86. These results demonstrate the importance of deep learning methods in making correct breast cancer diagnoses. This highlights the potential to provide improved diagnostic services to patients. The findings of this study not only improve current methods of cancer diagnosis, but also make significant contributions to the creation of new and improved cancer treatment strategies. In a nutshell, the results of this study represent a major advancement in the direction of achieving these vital healthcare goals.
Online Distributed Learning over Random Networks
Sep 01, 2023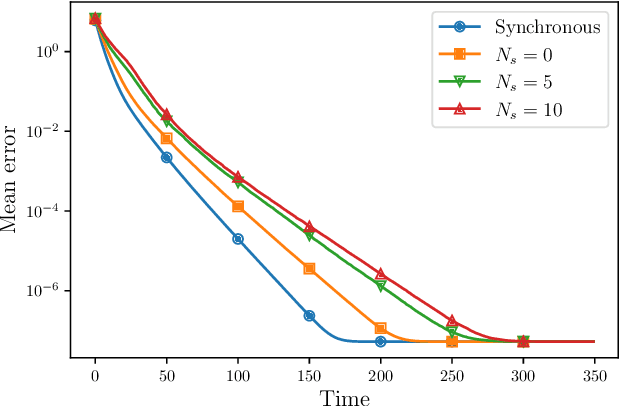
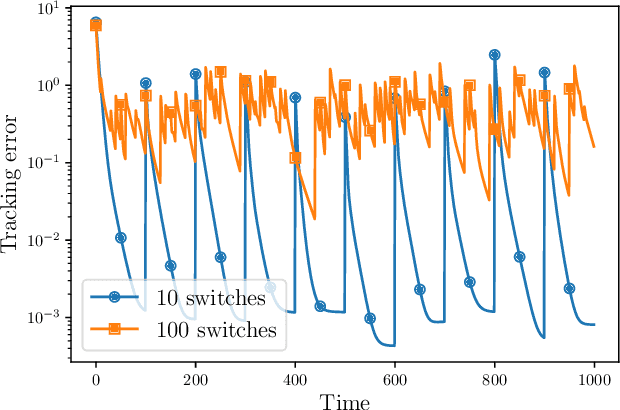
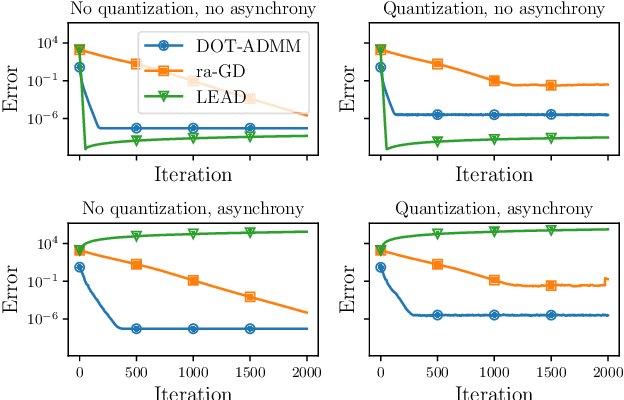
The recent deployment of multi-agent systems in a wide range of scenarios has enabled the solution of learning problems in a distributed fashion. In this context, agents are tasked with collecting local data and then cooperatively train a model, without directly sharing the data. While distributed learning offers the advantage of preserving agents' privacy, it also poses several challenges in terms of designing and analyzing suitable algorithms. This work focuses specifically on the following challenges motivated by practical implementation: (i) online learning, where the local data change over time; (ii) asynchronous agent computations; (iii) unreliable and limited communications; and (iv) inexact local computations. To tackle these challenges, we introduce the Distributed Operator Theoretical (DOT) version of the Alternating Direction Method of Multipliers (ADMM), which we call the DOT-ADMM Algorithm. We prove that it converges with a linear rate for a large class of convex learning problems (e.g., linear and logistic regression problems) toward a bounded neighborhood of the optimal time-varying solution, and characterize how the neighborhood depends on~$\text{(i)--(iv)}$. We corroborate the theoretical analysis with numerical simulations comparing the DOT-ADMM Algorithm with other state-of-the-art algorithms, showing that only the proposed algorithm exhibits robustness to (i)--(iv).
MDTD: A Multi Domain Trojan Detector for Deep Neural Networks
Sep 03, 2023

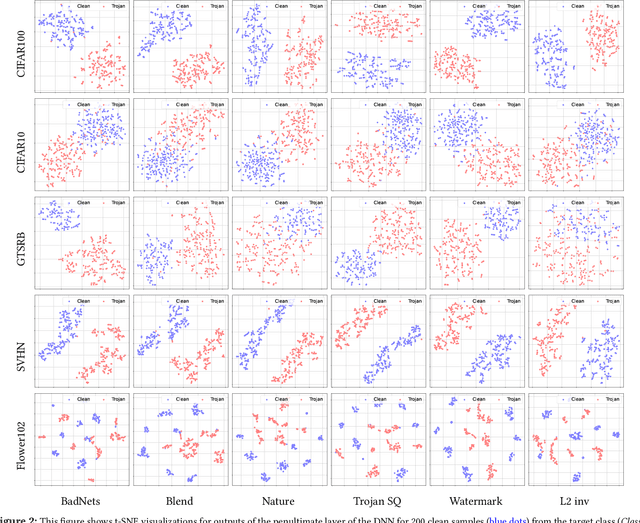

Machine learning models that use deep neural networks (DNNs) are vulnerable to backdoor attacks. An adversary carrying out a backdoor attack embeds a predefined perturbation called a trigger into a small subset of input samples and trains the DNN such that the presence of the trigger in the input results in an adversary-desired output class. Such adversarial retraining however needs to ensure that outputs for inputs without the trigger remain unaffected and provide high classification accuracy on clean samples. In this paper, we propose MDTD, a Multi-Domain Trojan Detector for DNNs, which detects inputs containing a Trojan trigger at testing time. MDTD does not require knowledge of trigger-embedding strategy of the attacker and can be applied to a pre-trained DNN model with image, audio, or graph-based inputs. MDTD leverages an insight that input samples containing a Trojan trigger are located relatively farther away from a decision boundary than clean samples. MDTD estimates the distance to a decision boundary using adversarial learning methods and uses this distance to infer whether a test-time input sample is Trojaned or not. We evaluate MDTD against state-of-the-art Trojan detection methods across five widely used image-based datasets: CIFAR100, CIFAR10, GTSRB, SVHN, and Flowers102; four graph-based datasets: AIDS, WinMal, Toxicant, and COLLAB; and the SpeechCommand audio dataset. MDTD effectively identifies samples that contain different types of Trojan triggers. We evaluate MDTD against adaptive attacks where an adversary trains a robust DNN to increase (decrease) distance of benign (Trojan) inputs from a decision boundary.
Combining predictive distributions of electricity prices: Does minimizing the CRPS lead to optimal decisions in day-ahead bidding?
Aug 29, 2023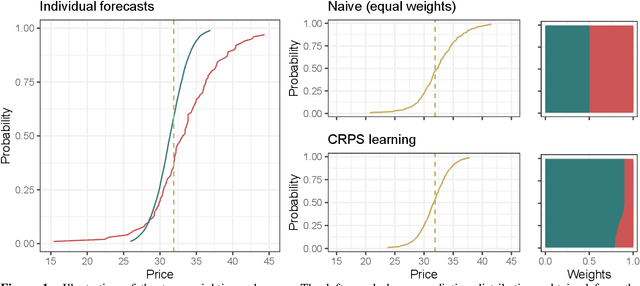
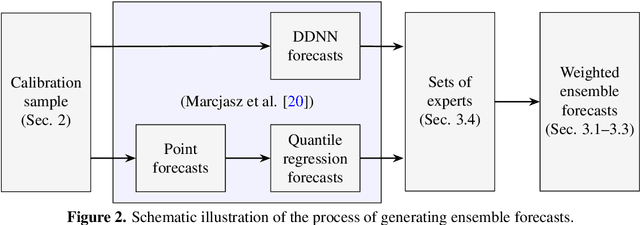
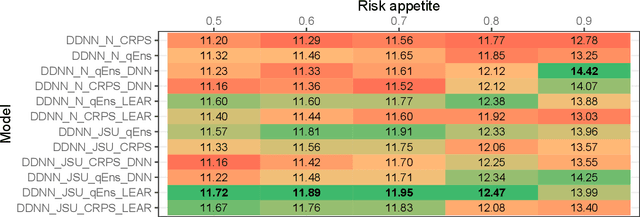
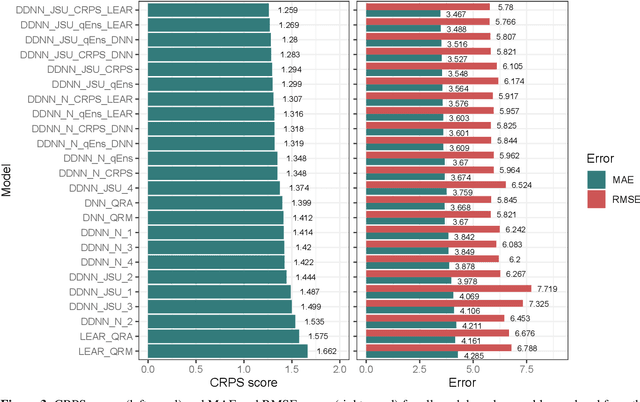
Probabilistic price forecasting has recently gained attention in power trading because decisions based on such predictions can yield significantly higher profits than those made with point forecasts alone. At the same time, methods are being developed to combine predictive distributions, since no model is perfect and averaging generally improves forecasting performance. In this article we address the question of whether using CRPS learning, a novel weighting technique minimizing the continuous ranked probability score (CRPS), leads to optimal decisions in day-ahead bidding. To this end, we conduct an empirical study using hourly day-ahead electricity prices from the German EPEX market. We find that increasing the diversity of an ensemble can have a positive impact on accuracy. At the same time, the higher computational cost of using CRPS learning compared to an equal-weighted aggregation of distributions is not offset by higher profits, despite significantly more accurate predictions.
Grid-based Hybrid 3DMA GNSS and Terrestrial Positioning
Sep 11, 2023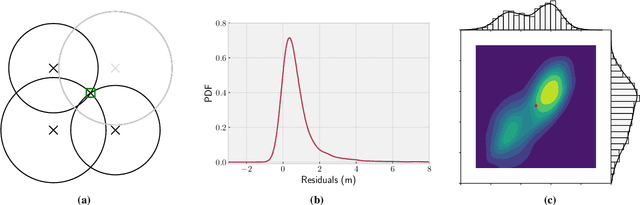
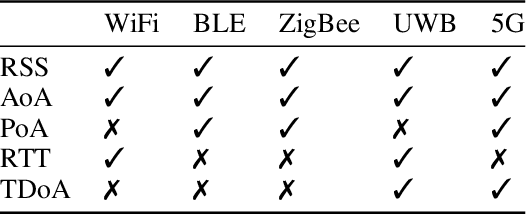

The paper discusses the increasing use of hybridized sensor information for GNSS-based localization and navigation, including the use of 3D map-aided GNSS positioning and terrestrial systems based on different geometric measurement principles. However, both GNSS and terrestrial systems are subject to negative impacts from the propagation environment, which can violate the assumptions of conventionally applied parametric state estimators. Furthermore, dynamic parametric state estimation does not account for multi-modalities within the state space leading to an information loss within the prediction step. In addition, the synchronization of non-deterministic multi-rate measurement systems needs to be accounted. In order to address these challenges, the paper proposes the use of a non-parametric filtering method, specifically a 3DMA multi-epoch Grid Filter, for the tight integration of GNSS and terrestrial signals. Specifically, the fusion of GNSS, Ultra-wide Band (UWB) and vehicle motion data is introduced based on a discrete state representation. Algorithmic challenges, including the use of different measurement models and time synchronization, are addressed. In order to evaluate the proposed method, real-world tests were conducted on an urban automotive testbed in both static and dynamic scenarios. We empirically show that we achieve sub-meter accuracy in the static scenario by averaging a positioning error of $0.64$ m, whereas in the dynamic scenario the average positioning error amounts to $1.62$ m. The paper provides a proof-of-concept of the introduced method and shows the feasibility of the inclusion of terrestrial signals in a 3DMA positioning framework in order to further enhance localization in GNSS-degraded environments.
A Comparative Analysis of Deep Reinforcement Learning-based xApps in O-RAN
Sep 11, 2023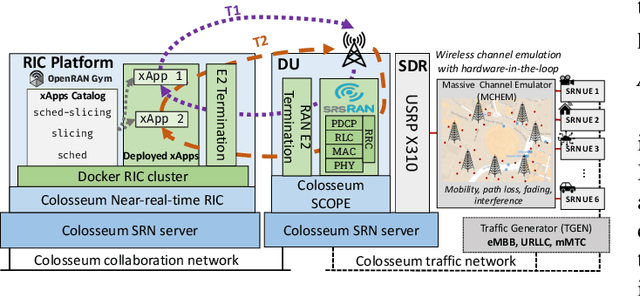
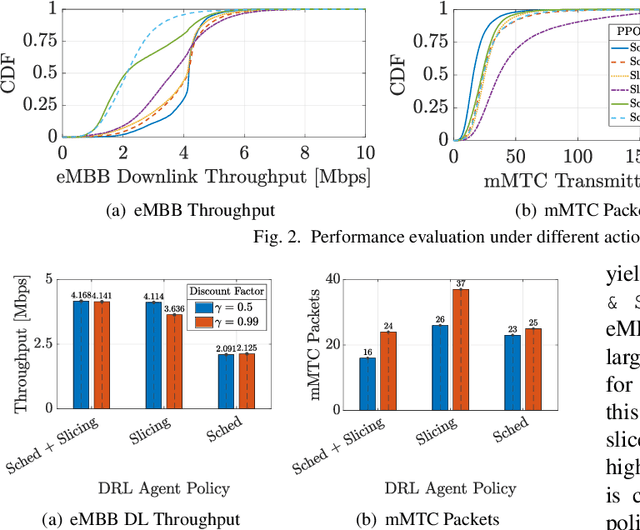
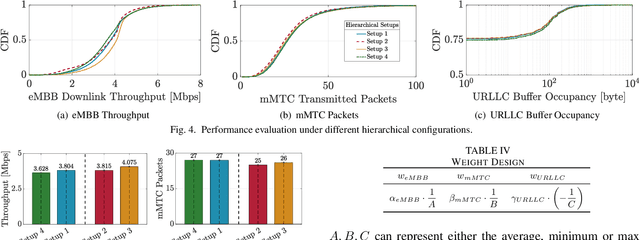
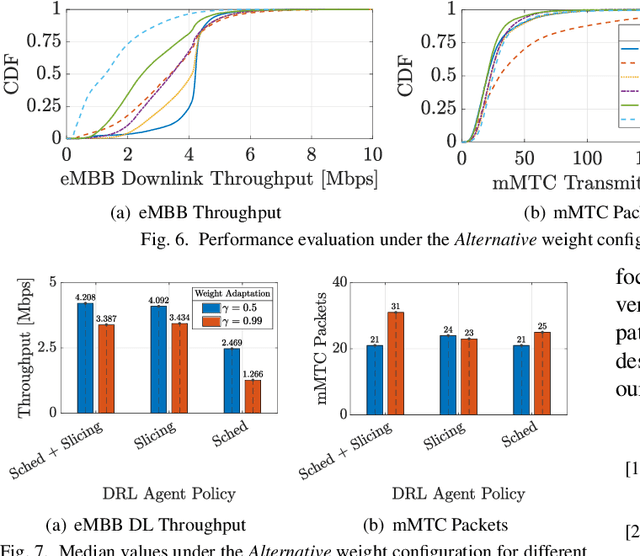
The highly heterogeneous ecosystem of Next Generation (NextG) wireless communication systems calls for novel networking paradigms where functionalities and operations can be dynamically and optimally reconfigured in real time to adapt to changing traffic conditions and satisfy stringent and diverse Quality of Service (QoS) demands. Open Radio Access Network (RAN) technologies, and specifically those being standardized by the O-RAN Alliance, make it possible to integrate network intelligence into the once monolithic RAN via intelligent applications, namely, xApps and rApps. These applications enable flexible control of the network resources and functionalities, network management, and orchestration through data-driven control loops. Despite recent work demonstrating the effectiveness of Deep Reinforcement Learning (DRL) in controlling O-RAN systems, how to design these solutions in a way that does not create conflicts and unfair resource allocation policies is still an open challenge. In this paper, we perform a comparative analysis where we dissect the impact of different DRL-based xApp designs on network performance. Specifically, we benchmark 12 different xApps that embed DRL agents trained using different reward functions, with different action spaces and with the ability to hierarchically control different network parameters. We prototype and evaluate these xApps on Colosseum, the world's largest O-RAN-compliant wireless network emulator with hardware-in-the-loop. We share the lessons learned and discuss our experimental results, which demonstrate how certain design choices deliver the highest performance while others might result in a competitive behavior between different classes of traffic with similar objectives.
CrisisTransformers: Pre-trained language models and sentence encoders for crisis-related social media texts
Sep 11, 2023
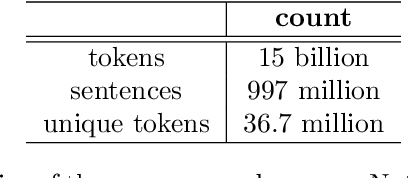
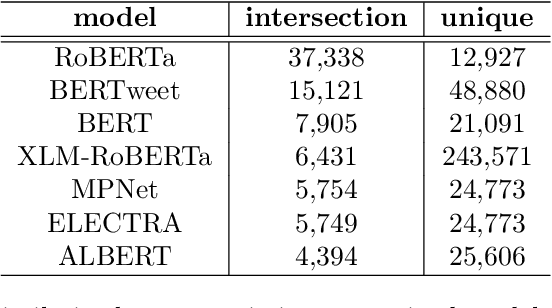
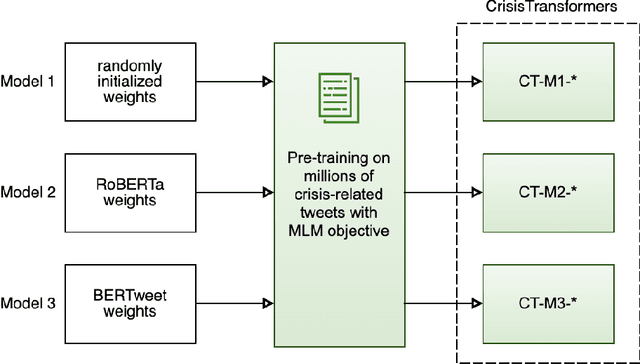
Social media platforms play an essential role in crisis communication, but analyzing crisis-related social media texts is challenging due to their informal nature. Transformer-based pre-trained models like BERT and RoBERTa have shown success in various NLP tasks, but they are not tailored for crisis-related texts. Furthermore, general-purpose sentence encoders are used to generate sentence embeddings, regardless of the textual complexities in crisis-related texts. Advances in applications like text classification, semantic search, and clustering contribute to effective processing of crisis-related texts, which is essential for emergency responders to gain a comprehensive view of a crisis event, whether historical or real-time. To address these gaps in crisis informatics literature, this study introduces CrisisTransformers, an ensemble of pre-trained language models and sentence encoders trained on an extensive corpus of over 15 billion word tokens from tweets associated with more than 30 crisis events, including disease outbreaks, natural disasters, conflicts, and other critical incidents. We evaluate existing models and CrisisTransformers on 18 crisis-specific public datasets. Our pre-trained models outperform strong baselines across all datasets in classification tasks, and our best-performing sentence encoder improves the state-of-the-art by 17.43% in sentence encoding tasks. Additionally, we investigate the impact of model initialization on convergence and evaluate the significance of domain-specific models in generating semantically meaningful sentence embeddings. All models are publicly released (https://huggingface.co/crisistransformers), with the anticipation that they will serve as a robust baseline for tasks involving the analysis of crisis-related social media texts.
KD-FixMatch: Knowledge Distillation Siamese Neural Networks
Sep 11, 2023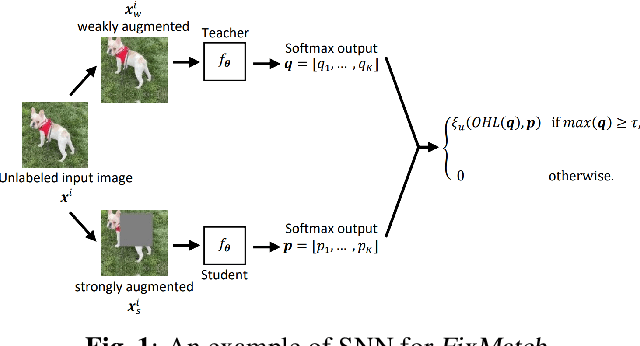
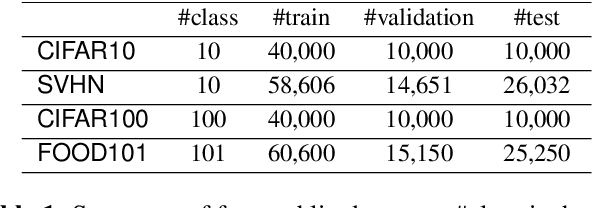
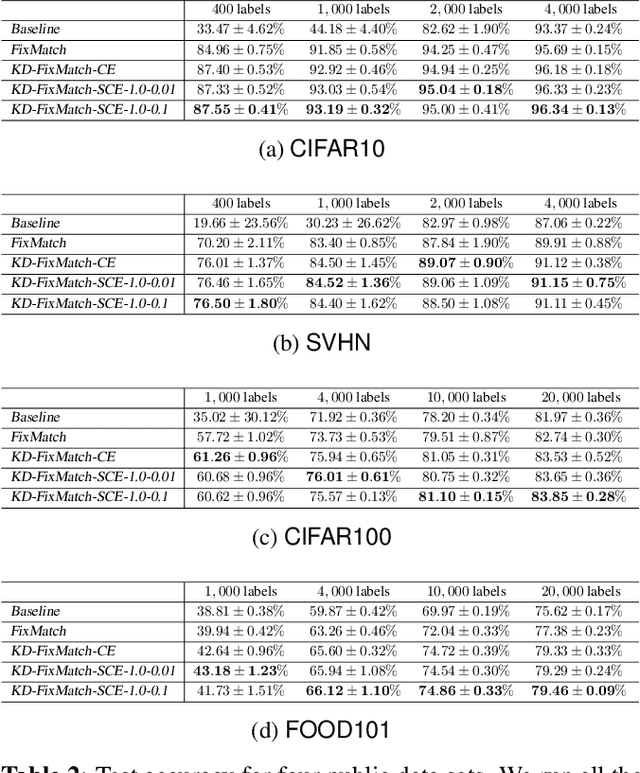
Semi-supervised learning (SSL) has become a crucial approach in deep learning as a way to address the challenge of limited labeled data. The success of deep neural networks heavily relies on the availability of large-scale high-quality labeled data. However, the process of data labeling is time-consuming and unscalable, leading to shortages in labeled data. SSL aims to tackle this problem by leveraging additional unlabeled data in the training process. One of the popular SSL algorithms, FixMatch, trains identical weight-sharing teacher and student networks simultaneously using a siamese neural network (SNN). However, it is prone to performance degradation when the pseudo labels are heavily noisy in the early training stage. We present KD-FixMatch, a novel SSL algorithm that addresses the limitations of FixMatch by incorporating knowledge distillation. The algorithm utilizes a combination of sequential and simultaneous training of SNNs to enhance performance and reduce performance degradation. Firstly, an outer SNN is trained using labeled and unlabeled data. After that, the network of the well-trained outer SNN generates pseudo labels for the unlabeled data, from which a subset of unlabeled data with trusted pseudo labels is then carefully created through high-confidence sampling and deep embedding clustering. Finally, an inner SNN is trained with the labeled data, the unlabeled data, and the subset of unlabeled data with trusted pseudo labels. Experiments on four public data sets demonstrate that KD-FixMatch outperforms FixMatch in all cases. Our results indicate that KD-FixMatch has a better training starting point that leads to improved model performance compared to FixMatch.