 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Astrocyte-Integrated Dynamic Function Exchange in Spiking Neural Networks
Sep 15, 2023
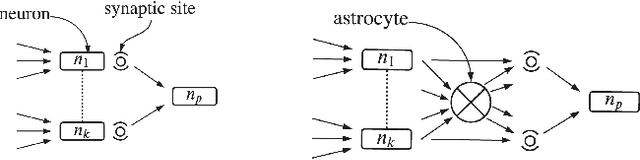
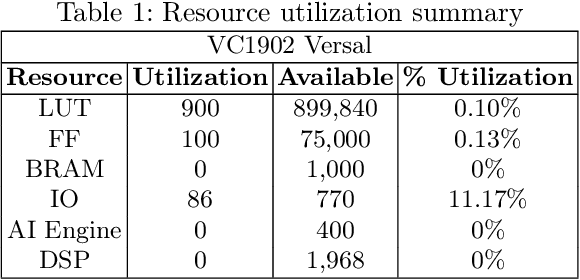

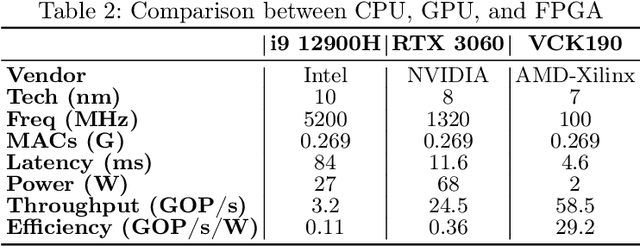
This paper presents an innovative methodology for improving the robustness and computational efficiency of Spiking Neural Networks (SNNs), a critical component in neuromorphic computing. The proposed approach integrates astrocytes, a type of glial cell prevalent in the human brain, into SNNs, creating astrocyte-augmented networks. To achieve this, we designed and implemented an astrocyte model in two distinct platforms: CPU/GPU and FPGA. Our FPGA implementation notably utilizes Dynamic Function Exchange (DFX) technology, enabling real-time hardware reconfiguration and adaptive model creation based on current operating conditions. The novel approach of leveraging astrocytes significantly improves the fault tolerance of SNNs, thereby enhancing their robustness. Notably, our astrocyte-augmented SNN displays near-zero latency and theoretically infinite throughput, implying exceptional computational efficiency. Through comprehensive comparative analysis with prior works, it's established that our model surpasses others in terms of neuron and synapse count while maintaining an efficient power consumption profile. These results underscore the potential of our methodology in shaping the future of neuromorphic computing, by providing robust and energy-efficient systems.
Foundation Model Assisted Automatic Speech Emotion Recognition: Transcribing, Annotating, and Augmenting
Sep 15, 2023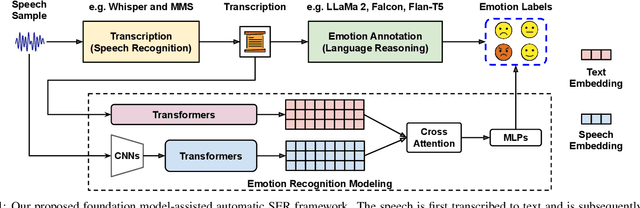
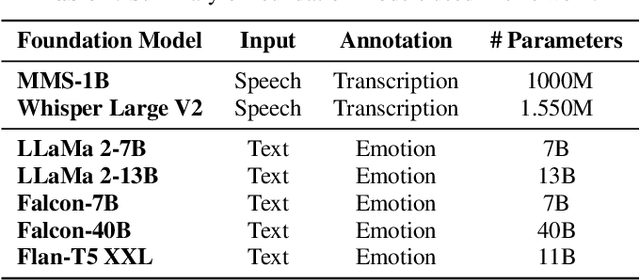
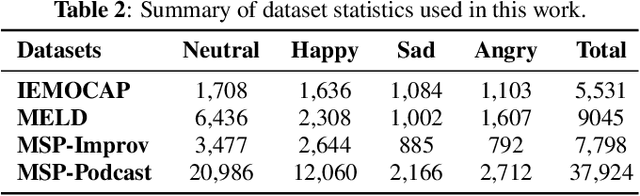
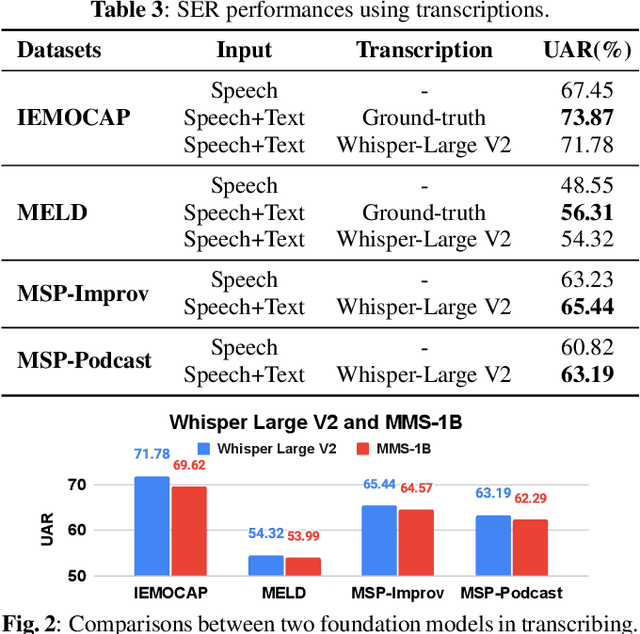
Significant advances are being made in speech emotion recognition (SER) using deep learning models. Nonetheless, training SER systems remains challenging, requiring both time and costly resources. Like many other machine learning tasks, acquiring datasets for SER requires substantial data annotation efforts, including transcription and labeling. These annotation processes present challenges when attempting to scale up conventional SER systems. Recent developments in foundational models have had a tremendous impact, giving rise to applications such as ChatGPT. These models have enhanced human-computer interactions including bringing unique possibilities for streamlining data collection in fields like SER. In this research, we explore the use of foundational models to assist in automating SER from transcription and annotation to augmentation. Our study demonstrates that these models can generate transcriptions to enhance the performance of SER systems that rely solely on speech data. Furthermore, we note that annotating emotions from transcribed speech remains a challenging task. However, combining outputs from multiple LLMs enhances the quality of annotations. Lastly, our findings suggest the feasibility of augmenting existing speech emotion datasets by annotating unlabeled speech samples.
Stack-and-Delay: a new codebook pattern for music generation
Sep 15, 2023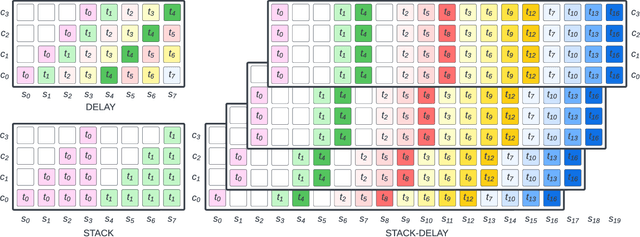
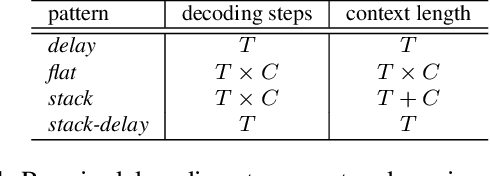
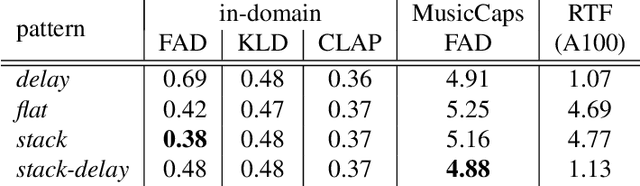
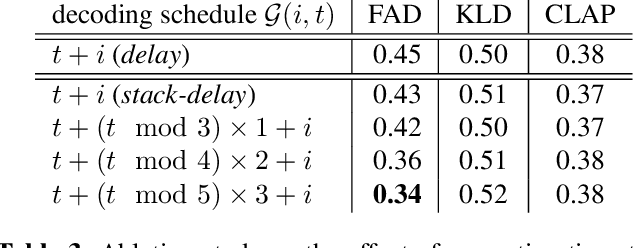
In language modeling based music generation, a generated waveform is represented by a sequence of hierarchical token stacks that can be decoded either in an auto-regressive manner or in parallel, depending on the codebook patterns. In particular, flattening the codebooks represents the highest quality decoding strategy, while being notoriously slow. To this end, we propose a novel stack-and-delay style of decoding strategy to improve upon the flat pattern decoding where generation speed is four times faster as opposed to vanilla flat decoding. This brings the inference time close to that of the delay decoding strategy, and allows for faster inference on GPU for small batch sizes. For the same inference efficiency budget as the delay pattern, we show that the proposed approach performs better in objective evaluations, almost closing the gap with the flat pattern in terms of quality. The results are corroborated by subjective evaluations which show that samples generated by the new model are slightly more often preferred to samples generated by the competing model given the same text prompts.
Robust Indoor Localization with Ranging-IMU Fusion
Sep 15, 2023Indoor wireless ranging localization is a promising approach for low-power and high-accuracy localization of wearable devices. A primary challenge in this domain stems from non-line of sight propagation of radio waves. This study tackles a fundamental issue in wireless ranging: the unpredictability of real-time multipath determination, especially in challenging conditions such as when there is no direct line of sight. We achieve this by fusing range measurements with inertial measurements obtained from a low cost Inertial Measurement Unit (IMU). For this purpose, we introduce a novel asymmetric noise model crafted specifically for non-Gaussian multipath disturbances. Additionally, we present a novel Levenberg-Marquardt (LM)-family trust-region adaptation of the iSAM2 fusion algorithm, which is optimized for robust performance for our ranging-IMU fusion problem. We evaluate our solution in a densely occupied real office environment. Our proposed solution can achieve temporally consistent localization with an average absolute accuracy of $\sim$0.3m in real-world settings. Furthermore, our results indicate that we can achieve comparable accuracy even with infrequent (1Hz) range measurements.
BANSAC: A dynamic BAyesian Network for adaptive SAmple Consensus
Sep 15, 2023RANSAC-based algorithms are the standard techniques for robust estimation in computer vision. These algorithms are iterative and computationally expensive; they alternate between random sampling of data, computing hypotheses, and running inlier counting. Many authors tried different approaches to improve efficiency. One of the major improvements is having a guided sampling, letting the RANSAC cycle stop sooner. This paper presents a new adaptive sampling process for RANSAC. Previous methods either assume no prior information about the inlier/outlier classification of data points or use some previously computed scores in the sampling. In this paper, we derive a dynamic Bayesian network that updates individual data points' inlier scores while iterating RANSAC. At each iteration, we apply weighted sampling using the updated scores. Our method works with or without prior data point scorings. In addition, we use the updated inlier/outlier scoring for deriving a new stopping criterion for the RANSAC loop. We test our method in multiple real-world datasets for several applications and obtain state-of-the-art results. Our method outperforms the baselines in accuracy while needing less computational time.
From random-walks to graph-sprints: a low-latency node embedding framework on continuous-time dynamic graphs
Jul 18, 2023
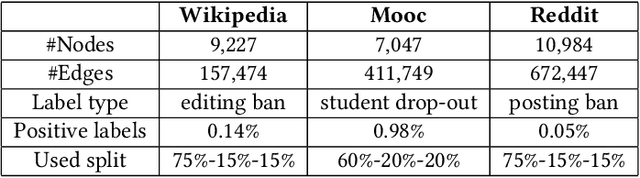
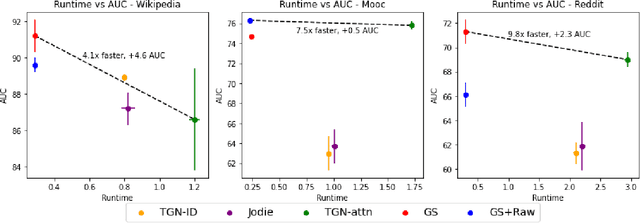
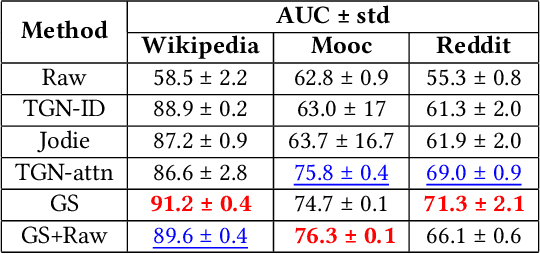
Many real-world datasets have an underlying dynamic graph structure, where entities and their interactions evolve over time. Machine learning models should consider these dynamics in order to harness their full potential in downstream tasks. Previous approaches for graph representation learning have focused on either sampling k-hop neighborhoods, akin to breadth-first search, or random walks, akin to depth-first search. However, these methods are computationally expensive and unsuitable for real-time, low-latency inference on dynamic graphs. To overcome these limitations, we propose graph-sprints a general purpose feature extraction framework for continuous-time-dynamic-graphs (CTDGs) that has low latency and is competitive with state-of-the-art, higher latency models. To achieve this, a streaming, low latency approximation to the random-walk based features is proposed. In our framework, time-aware node embeddings summarizing multi-hop information are computed using only single-hop operations on the incoming edges. We evaluate our proposed approach on three open-source datasets and two in-house datasets, and compare with three state-of-the-art algorithms (TGN-attn, TGN-ID, Jodie). We demonstrate that our graph-sprints features, combined with a machine learning classifier, achieve competitive performance (outperforming all baselines for the node classification tasks in five datasets). Simultaneously, graph-sprints significantly reduce inference latencies, achieving close to an order of magnitude speed-up in our experimental setting.
Comparative Analysis of CPU and GPU Profiling for Deep Learning Models
Sep 05, 2023
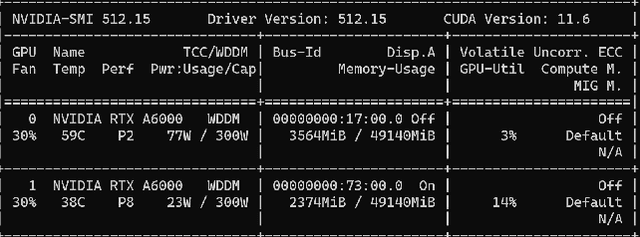
Deep Learning(DL) and Machine Learning(ML) applications are rapidly increasing in recent days. Massive amounts of data are being generated over the internet which can derive meaningful results by the use of ML and DL algorithms. Hardware resources and open-source libraries have made it easy to implement these algorithms. Tensorflow and Pytorch are one of the leading frameworks for implementing ML projects. By using those frameworks, we can trace the operations executed on both GPU and CPU to analyze the resource allocations and consumption. This paper presents the time and memory allocation of CPU and GPU while training deep neural networks using Pytorch. This paper analysis shows that GPU has a lower running time as compared to CPU for deep neural networks. For a simpler network, there are not many significant improvements in GPU over the CPU.
C-Pack: Packaged Resources To Advance General Chinese Embedding
Sep 14, 2023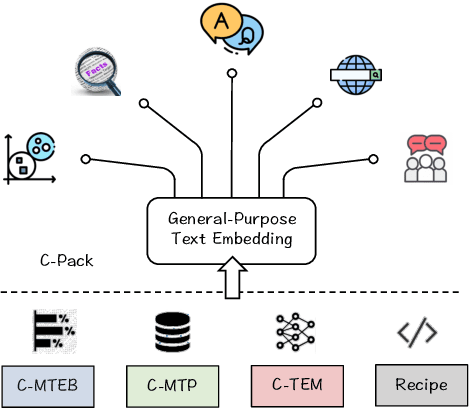
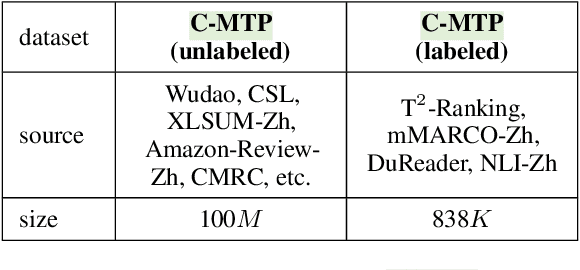
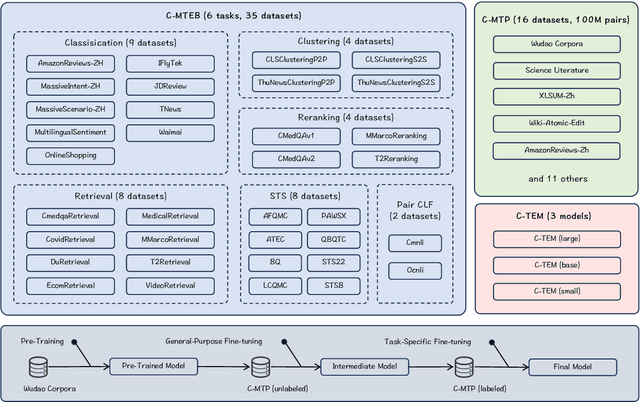
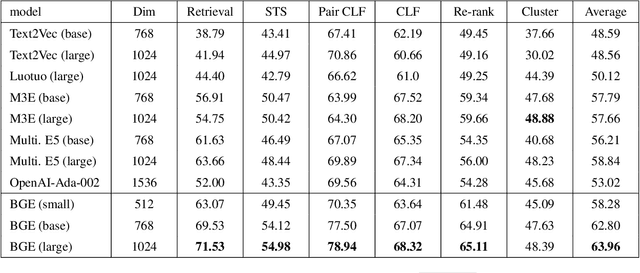
We introduce C-Pack, a package of resources that significantly advance the field of general Chinese embeddings. C-Pack includes three critical resources. 1) C-MTEB is a comprehensive benchmark for Chinese text embeddings covering 6 tasks and 35 datasets. 2) C-MTP is a massive text embedding dataset curated from labeled and unlabeled Chinese corpora for training embedding models. 3) C-TEM is a family of embedding models covering multiple sizes. Our models outperform all prior Chinese text embeddings on C-MTEB by up to +10% upon the time of the release. We also integrate and optimize the entire suite of training methods for C-TEM. Along with our resources on general Chinese embedding, we release our data and models for English text embeddings. The English models achieve state-of-the-art performance on MTEB benchmark; meanwhile, our released English data is 2 times larger than the Chinese data. All these resources are made publicly available at https://github.com/FlagOpen/FlagEmbedding.
VCD: A Video Conferencing Dataset for Video Compression
Sep 14, 2023
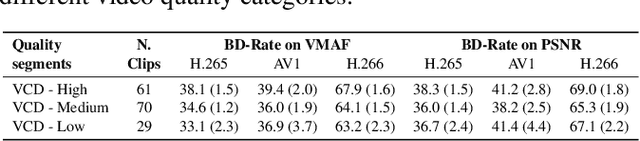
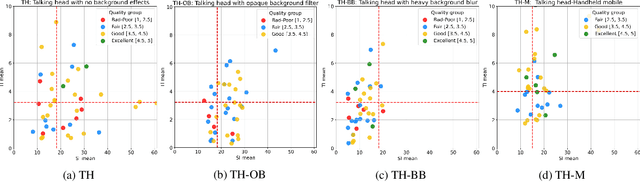
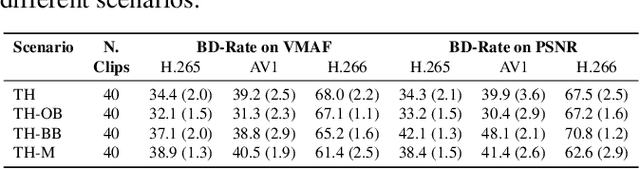
Commonly used datasets for evaluating video codecs are all very high quality and not representative of video typically used in video conferencing scenarios. We present the Video Conferencing Dataset (VCD) for evaluating video codecs for real-time communication, the first such dataset focused on video conferencing. VCD includes a wide variety of camera qualities and spatial and temporal information. It includes both desktop and mobile scenarios and two types of video background processing. We report the compression efficiency of H.264, H.265, H.266, and AV1 in low-delay settings on VCD and compare it with the non-video conferencing datasets UVC, MLC-JVC, and HEVC. The results show the source quality and the scenarios have a significant effect on the compression efficiency of all the codecs. VCD enables the evaluation and tuning of codecs for this important scenario. The VCD is publicly available as an open-source dataset at https://github.com/microsoft/VCD.
Proximal Bellman mappings for reinforcement learning and their application to robust adaptive filtering
Sep 14, 2023This paper aims at the algorithmic/theoretical core of reinforcement learning (RL) by introducing the novel class of proximal Bellman mappings. These mappings are defined in reproducing kernel Hilbert spaces (RKHSs), to benefit from the rich approximation properties and inner product of RKHSs, they are shown to belong to the powerful Hilbertian family of (firmly) nonexpansive mappings, regardless of the values of their discount factors, and possess ample degrees of design freedom to even reproduce attributes of the classical Bellman mappings and to pave the way for novel RL designs. An approximate policy-iteration scheme is built on the proposed class of mappings to solve the problem of selecting online, at every time instance, the "optimal" exponent $p$ in a $p$-norm loss to combat outliers in linear adaptive filtering, without training data and any knowledge on the statistical properties of the outliers. Numerical tests on synthetic data showcase the superior performance of the proposed framework over several non-RL and kernel-based RL schemes.