 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
IIP-Mixer:Intra-Inter Patch Mixing Architecture for Battery Remaining Useful Life Prediction
Mar 27, 2024
Accurately estimating the Remaining Useful Life (RUL) of lithium-ion batteries is crucial for maintaining the safe and stable operation of rechargeable battery management systems. However, this task is often challenging due to the complex temporal dynamics involved. Recently, attention-based networks, such as Transformers and Informer, have been the popular architecture in time series forecasting. Despite their effectiveness, these models with abundant parameters necessitate substantial training time to unravel temporal patterns. To tackle these challenges, we propose a simple MLP-Mixer-based architecture named 'Intra-Inter Patch Mixer' (IIP-Mixer), which is an architecture based exclusively on multi-layer perceptrons (MLPs), extracting information by mixing operations along both intra-patch and inter-patch dimensions for battery RUL prediction. The proposed IIP-Mixer comprises parallel dual-head mixer layers: the intra-patch mixing MLP, capturing local temporal patterns in the short-term period, and the inter-patch mixing MLP, capturing global temporal patterns in the long-term period. Notably, to address the varying importance of features in RUL prediction, we introduce a weighted loss function in the MLP-Mixer-based architecture, marking the first time such an approach has been employed. Our experiments demonstrate that IIP-Mixer achieves competitive performance in battery RUL prediction, outperforming other popular time-series frameworks
Real-time Model Predictive Control with Zonotope-Based Neural Networks for Bipedal Social Navigation
Mar 25, 2024This study addresses the challenge of bipedal navigation in a dynamic human-crowded environment, a research area that remains largely underexplored in the field of legged navigation. We propose two cascaded zonotope-based neural networks: a Pedestrian Prediction Network (PPN) for pedestrians' future trajectory prediction and an Ego-agent Social Network (ESN) for ego-agent social path planning. Representing future paths as zonotopes allows for efficient reachability-based planning and collision checking. The ESN is then integrated with a Model Predictive Controller (ESN-MPC) for footstep planning for our bipedal robot Digit designed by Agility Robotics. ESN-MPC solves for a collision-free optimal trajectory by optimizing through the gradients of ESN. ESN-MPC optimal trajectory is sent to the low-level controller for full-order simulation of Digit. The overall proposed framework is validated with extensive simulations on randomly generated initial settings with varying human crowd densities.
Multi-hop Question Answering under Temporal Knowledge Editing
Mar 30, 2024Multi-hop question answering (MQA) under knowledge editing (KE) has garnered significant attention in the era of large language models. However, existing models for MQA under KE exhibit poor performance when dealing with questions containing explicit temporal contexts. To address this limitation, we propose a novel framework, namely TEMPoral knowLEdge augmented Multi-hop Question Answering (TEMPLE-MQA). Unlike previous methods, TEMPLE-MQA first constructs a time-aware graph (TAG) to store edit knowledge in a structured manner. Then, through our proposed inference path, structural retrieval, and joint reasoning stages, TEMPLE-MQA effectively discerns temporal contexts within the question query. Experiments on benchmark datasets demonstrate that TEMPLE-MQA significantly outperforms baseline models. Additionally, we contribute a new dataset, namely TKEMQA, which serves as the inaugural benchmark tailored specifically for MQA with temporal scopes.
How Much are LLMs Contaminated? A Comprehensive Survey and the LLMSanitize Library
Mar 31, 2024With the rise of Large Language Models (LLMs) in recent years, new opportunities are emerging, but also new challenges, and contamination is quickly becoming critical. Business applications and fundraising in AI have reached a scale at which a few percentage points gained on popular question-answering benchmarks could translate into dozens of millions of dollars, placing high pressure on model integrity. At the same time, it is becoming harder and harder to keep track of the data that LLMs have seen; if not impossible with closed-source models like GPT-4 and Claude-3 not divulging any information on the training set. As a result, contamination becomes a critical issue: LLMs' performance may not be reliable anymore, as the high performance may be at least partly due to their previous exposure to the data. This limitation jeopardizes the entire progress in the field of NLP, yet, there remains a lack of methods on how to efficiently address contamination, or a clear consensus on prevention, mitigation and classification of contamination. In this paper, we survey all recent work on contamination with LLMs, and help the community track contamination levels of LLMs by releasing an open-source Python library named LLMSanitize implementing major contamination detection algorithms, which link is: https://github.com/ntunlp/LLMSanitize.
On the Estimation of Image-matching Uncertainty in Visual Place Recognition
Mar 31, 2024In Visual Place Recognition (VPR) the pose of a query image is estimated by comparing the image to a map of reference images with known reference poses. As is typical for image retrieval problems, a feature extractor maps the query and reference images to a feature space, where a nearest neighbor search is then performed. However, till recently little attention has been given to quantifying the confidence that a retrieved reference image is a correct match. Highly certain but incorrect retrieval can lead to catastrophic failure of VPR-based localization pipelines. This work compares for the first time the main approaches for estimating the image-matching uncertainty, including the traditional retrieval-based uncertainty estimation, more recent data-driven aleatoric uncertainty estimation, and the compute-intensive geometric verification. We further formulate a simple baseline method, ``SUE'', which unlike the other methods considers the freely-available poses of the reference images in the map. Our experiments reveal that a simple L2-distance between the query and reference descriptors is already a better estimate of image-matching uncertainty than current data-driven approaches. SUE outperforms the other efficient uncertainty estimation methods, and its uncertainty estimates complement the computationally expensive geometric verification approach. Future works for uncertainty estimation in VPR should consider the baselines discussed in this work.
Human-Robot Co-Transportation with Human Uncertainty-Aware MPC and Pose Optimization
Mar 31, 2024This paper proposes a new control algorithm for human-robot co-transportation based on a robot manipulator equipped with a mobile base and a robotic arm. The primary focus is to adapt to human uncertainties through the robot's whole-body dynamics and pose optimization. We introduce an augmented Model Predictive Control (MPC) formulation that explicitly models human uncertainties and contains extra variables than regular MPC to optimize the pose of the robotic arm. The core of our methodology involves a two-step iterative design: At each planning horizon, we select the best pose of the robotic arm (joint angle combination) from a candidate set, aiming to achieve the lowest estimated control cost. This selection is based on solving an uncertainty-aware Discrete Algebraic Ricatti Equation (DARE), which also informs the optimal control inputs for both the mobile base and the robotic arm. To validate the effectiveness of the proposed approach, we provide theoretical derivation for the uncertainty-aware DARE and perform simulated and proof-of-concept hardware experiments using a Fetch robot under varying conditions, including different nominal trajectories and noise levels. The results reveal that our proposed approach outperforms baseline algorithms, maintaining similar execution time with that do not consider human uncertainty or do not perform pose optimization.
Capacity Provisioning Motivated Online Non-Convex Optimization Problem with Memory and Switching Cost
Mar 26, 2024An online non-convex optimization problem is considered where the goal is to minimize the flow time (total delay) of a set of jobs by modulating the number of active servers, but with a switching cost associated with changing the number of active servers over time. Each job can be processed by at most one fixed speed server at any time. Compared to the usual online convex optimization (OCO) problem with switching cost, the objective function considered is non-convex and more importantly, at each time, it depends on all past decisions and not just the present one. Both worst-case and stochastic inputs are considered; for both cases, competitive algorithms are derived.
Nonparametric Bellman Mappings for Reinforcement Learning: Application to Robust Adaptive Filtering
Mar 29, 2024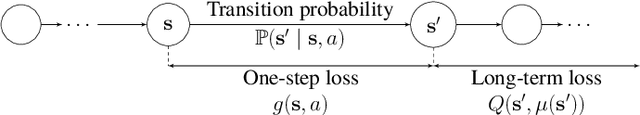
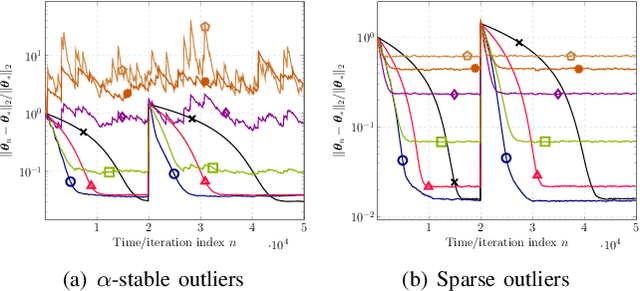
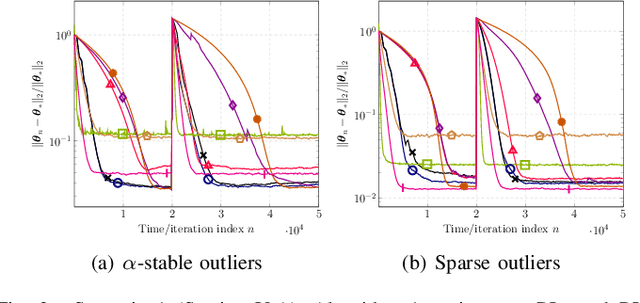
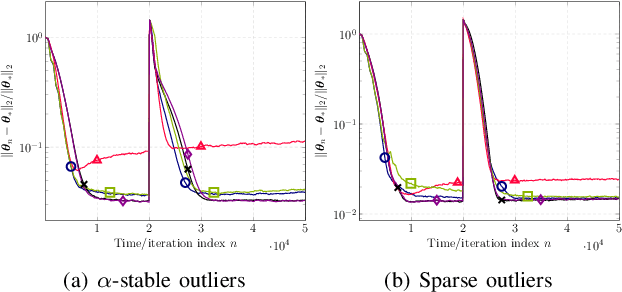
This paper designs novel nonparametric Bellman mappings in reproducing kernel Hilbert spaces (RKHSs) for reinforcement learning (RL). The proposed mappings benefit from the rich approximating properties of RKHSs, adopt no assumptions on the statistics of the data owing to their nonparametric nature, require no knowledge on transition probabilities of Markov decision processes, and may operate without any training data. Moreover, they allow for sampling on-the-fly via the design of trajectory samples, re-use past test data via experience replay, effect dimensionality reduction by random Fourier features, and enable computationally lightweight operations to fit into efficient online or time-adaptive learning. The paper offers also a variational framework to design the free parameters of the proposed Bellman mappings, and shows that appropriate choices of those parameters yield several popular Bellman-mapping designs. As an application, the proposed mappings are employed to offer a novel solution to the problem of countering outliers in adaptive filtering. More specifically, with no prior information on the statistics of the outliers and no training data, a policy-iteration algorithm is introduced to select online, per time instance, the ``optimal'' coefficient p in the least-mean-p-power-error method. Numerical tests on synthetic data showcase, in most of the cases, the superior performance of the proposed solution over several RL and non-RL schemes.
HARMamba: Efficient Wearable Sensor Human Activity Recognition Based on Bidirectional Selective SSM
Mar 29, 2024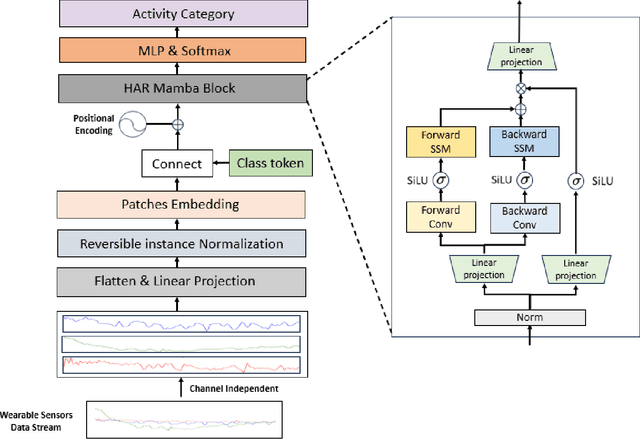
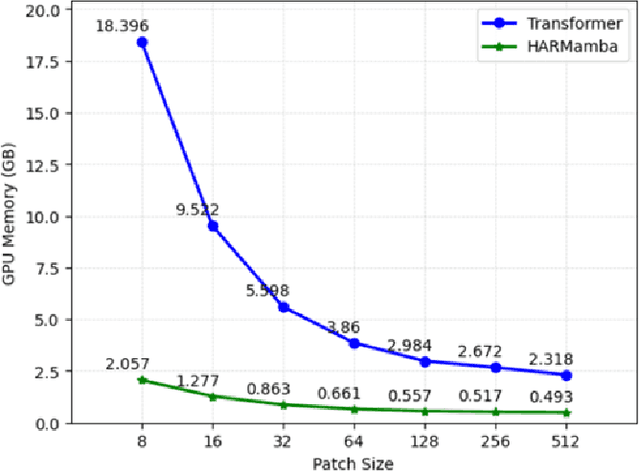
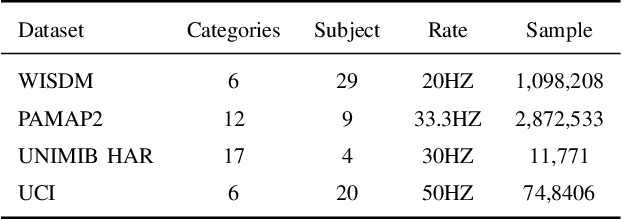
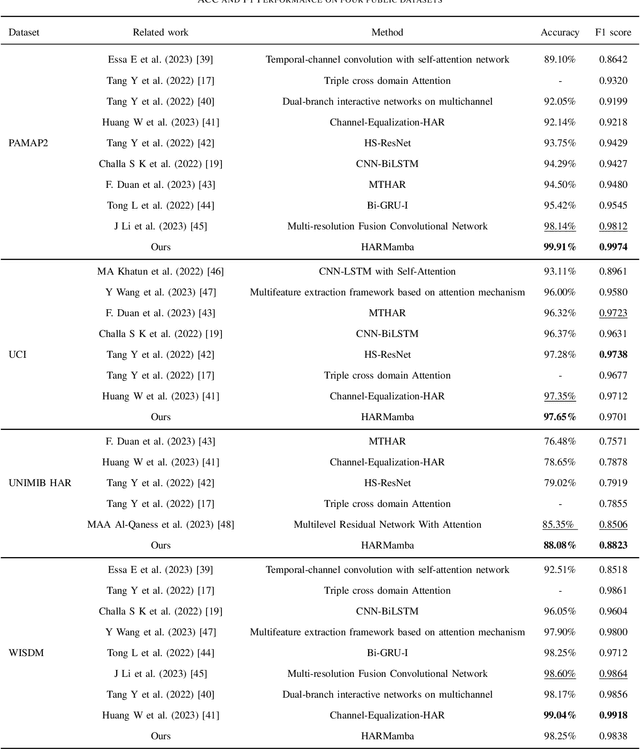
Wearable sensor human activity recognition (HAR) is a crucial area of research in activity sensing. While transformer-based temporal deep learning models have been extensively studied and implemented, their large number of parameters present significant challenges in terms of system computing load and memory usage, rendering them unsuitable for real-time mobile activity recognition applications. Recently, an efficient hardware-aware state space model (SSM) called Mamba has emerged as a promising alternative. Mamba demonstrates strong potential in long sequence modeling, boasts a simpler network architecture, and offers an efficient hardware-aware design. Leveraging SSM for activity recognition represents an appealing avenue for exploration. In this study, we introduce HARMamba, which employs a more lightweight selective SSM as the foundational model architecture for activity recognition. The goal is to address the computational resource constraints encountered in real-time activity recognition scenarios. Our approach involves processing sensor data flow by independently learning each channel and segmenting the data into "patches". The marked sensor sequence's position embedding serves as the input token for the bidirectional state space model, ultimately leading to activity categorization through the classification head. Compared to established activity recognition frameworks like Transformer-based models, HARMamba achieves superior performance while also reducing computational and memory overhead. Furthermore, our proposed method has been extensively tested on four public activity datasets: PAMAP2, WISDM, UNIMIB, and UCI, demonstrating impressive performance in activity recognition tasks.
Multimodal Transformers for Real-Time Surgical Activity Prediction
Mar 11, 2024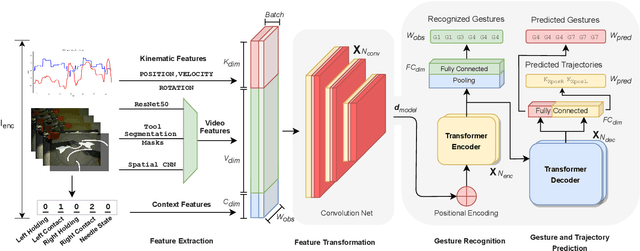

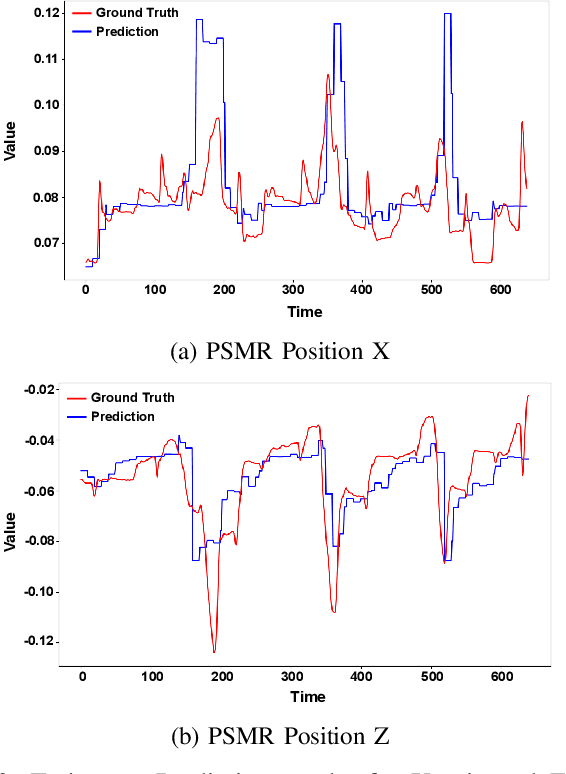
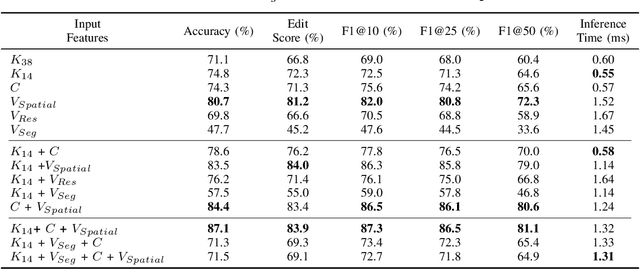
Real-time recognition and prediction of surgical activities are fundamental to advancing safety and autonomy in robot-assisted surgery. This paper presents a multimodal transformer architecture for real-time recognition and prediction of surgical gestures and trajectories based on short segments of kinematic and video data. We conduct an ablation study to evaluate the impact of fusing different input modalities and their representations on gesture recognition and prediction performance. We perform an end-to-end assessment of the proposed architecture using the JHU-ISI Gesture and Skill Assessment Working Set (JIGSAWS) dataset. Our model outperforms the state-of-the-art (SOTA) with 89.5\% accuracy for gesture prediction through effective fusion of kinematic features with spatial and contextual video features. It achieves the real-time performance of 1.1-1.3ms for processing a 1-second input window by relying on a computationally efficient model.