 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Distributionally Robust Post-hoc Classifiers under Prior Shifts
Sep 16, 2023
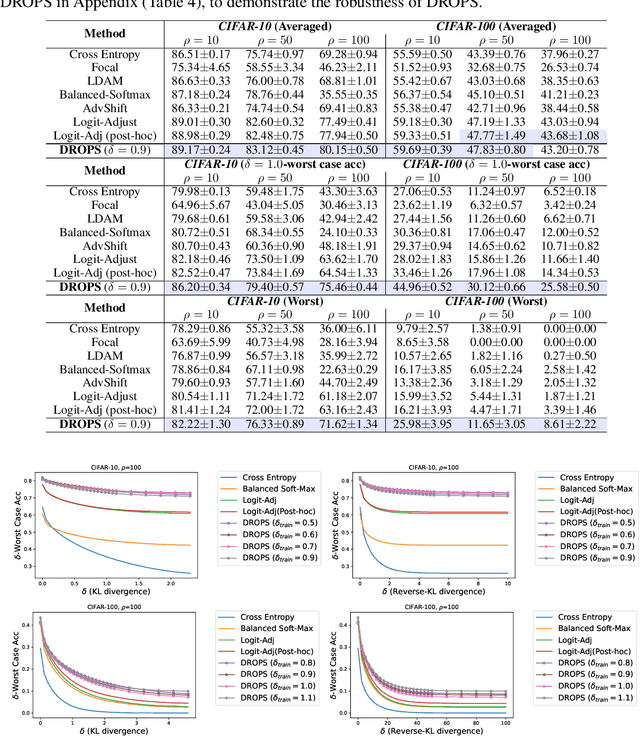
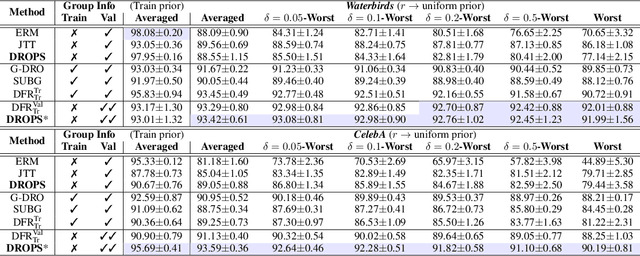
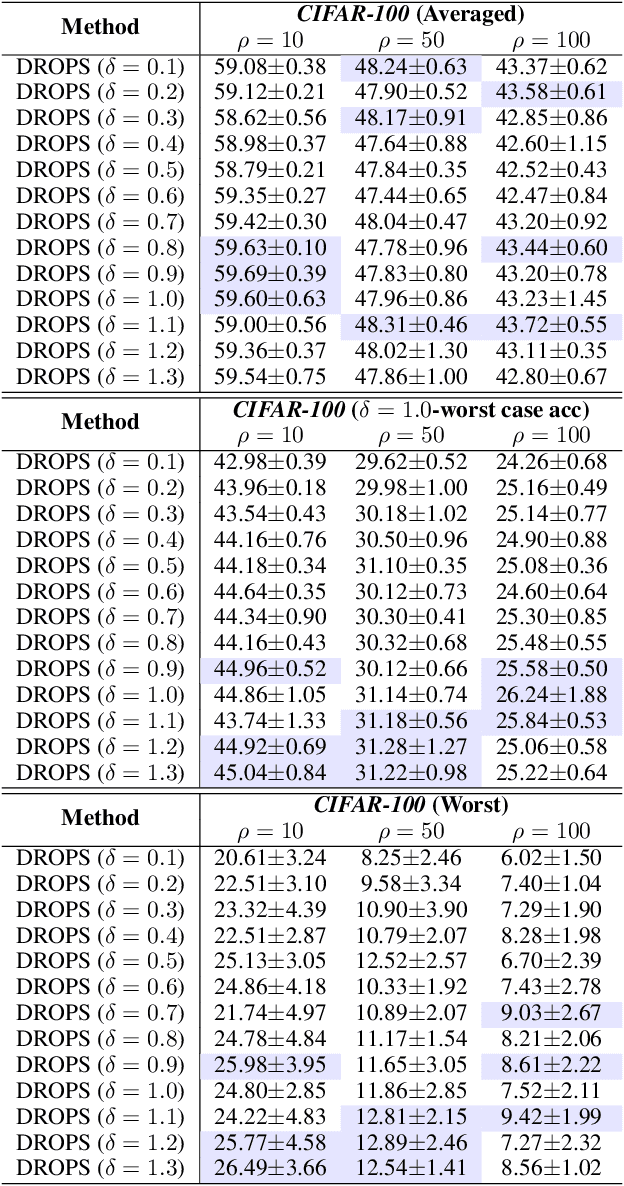

The generalization ability of machine learning models degrades significantly when the test distribution shifts away from the training distribution. We investigate the problem of training models that are robust to shifts caused by changes in the distribution of class-priors or group-priors. The presence of skewed training priors can often lead to the models overfitting to spurious features. Unlike existing methods, which optimize for either the worst or the average performance over classes or groups, our work is motivated by the need for finer control over the robustness properties of the model. We present an extremely lightweight post-hoc approach that performs scaling adjustments to predictions from a pre-trained model, with the goal of minimizing a distributionally robust loss around a chosen target distribution. These adjustments are computed by solving a constrained optimization problem on a validation set and applied to the model during test time. Our constrained optimization objective is inspired by a natural notion of robustness to controlled distribution shifts. Our method comes with provable guarantees and empirically makes a strong case for distributional robust post-hoc classifiers. An empirical implementation is available at https://github.com/weijiaheng/Drops.
Multiagent Reinforcement Learning with an Attention Mechanism for Improving Energy Efficiency in LoRa Networks
Sep 16, 2023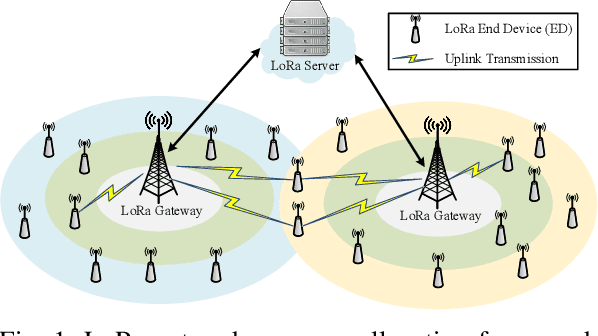
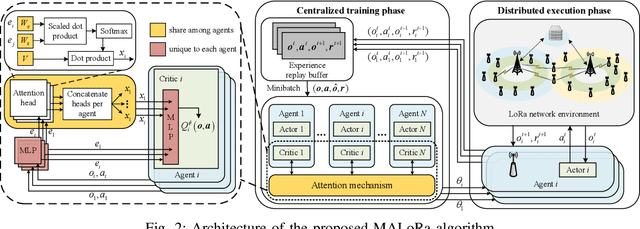
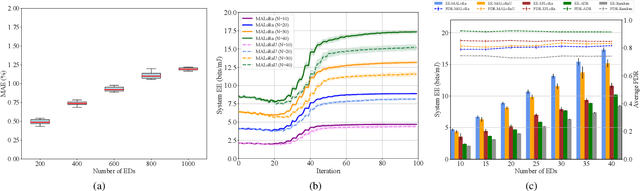
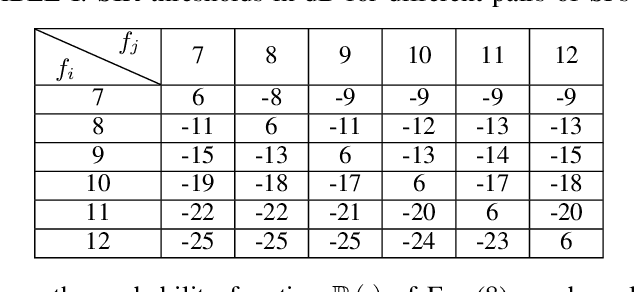
Long Range (LoRa) wireless technology, characterized by low power consumption and a long communication range, is regarded as one of the enabling technologies for the Industrial Internet of Things (IIoT). However, as the network scale increases, the energy efficiency (EE) of LoRa networks decreases sharply due to severe packet collisions. To address this issue, it is essential to appropriately assign transmission parameters such as the spreading factor and transmission power for each end device (ED). However, due to the sporadic traffic and low duty cycle of LoRa networks, evaluating the system EE performance under different parameter settings is time-consuming. Therefore, we first formulate an analytical model to calculate the system EE. On this basis, we propose a transmission parameter allocation algorithm based on multiagent reinforcement learning (MALoRa) with the aim of maximizing the system EE of LoRa networks. Notably, MALoRa employs an attention mechanism to guide each ED to better learn how much ''attention'' should be given to the parameter assignments for relevant EDs when seeking to improve the system EE. Simulation results demonstrate that MALoRa significantly improves the system EE compared with baseline algorithms with an acceptable degradation in packet delivery rate (PDR).
Reducing Memory Requirements for the IPU using Butterfly Factorizations
Sep 16, 2023High Performance Computing (HPC) benefits from different improvements during last decades, specially in terms of hardware platforms to provide more processing power while maintaining the power consumption at a reasonable level. The Intelligence Processing Unit (IPU) is a new type of massively parallel processor, designed to speedup parallel computations with huge number of processing cores and on-chip memory components connected with high-speed fabrics. IPUs mainly target machine learning applications, however, due to the architectural differences between GPUs and IPUs, especially significantly less memory capacity on an IPU, methods for reducing model size by sparsification have to be considered. Butterfly factorizations are well-known replacements for fully-connected and convolutional layers. In this paper, we examine how butterfly structures can be implemented on an IPU and study their behavior and performance compared to a GPU. Experimental results indicate that these methods can provide 98.5% compression ratio to decrease the immense need for memory, the IPU implementation can benefit from 1.3x and 1.6x performance improvement for butterfly and pixelated butterfly, respectively. We also reach to 1.62x training time speedup on a real-word dataset such as CIFAR10.
Uncovering Drift in Textual Data: An Unsupervised Method for Detecting and Mitigating Drift in Machine Learning Models
Sep 07, 2023Drift in machine learning refers to the phenomenon where the statistical properties of data or context, in which the model operates, change over time leading to a decrease in its performance. Therefore, maintaining a constant monitoring process for machine learning model performance is crucial in order to proactively prevent any potential performance regression. However, supervised drift detection methods require human annotation and consequently lead to a longer time to detect and mitigate the drift. In our proposed unsupervised drift detection method, we follow a two step process. Our first step involves encoding a sample of production data as the target distribution, and the model training data as the reference distribution. In the second step, we employ a kernel-based statistical test that utilizes the maximum mean discrepancy (MMD) distance metric to compare the reference and target distributions and estimate any potential drift. Our method also identifies the subset of production data that is the root cause of the drift. The models retrained using these identified high drift samples show improved performance on online customer experience quality metrics.
Secure Control of Networked Inverted Pendulum Visual Servo System with Adverse Effects of Image Computation (Extended Version)
Sep 07, 2023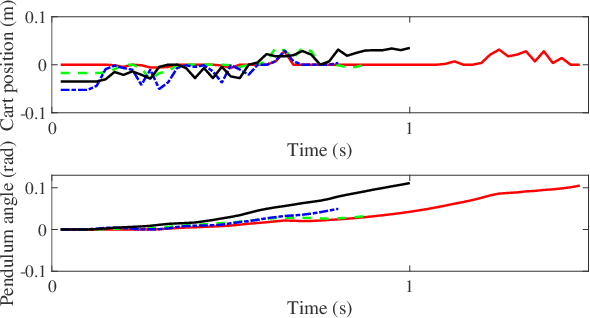
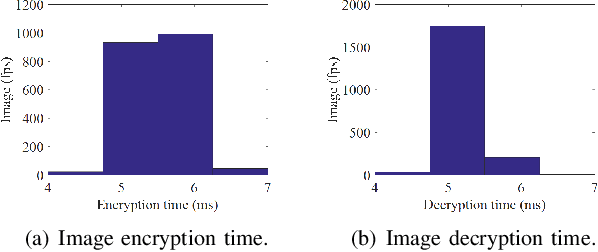
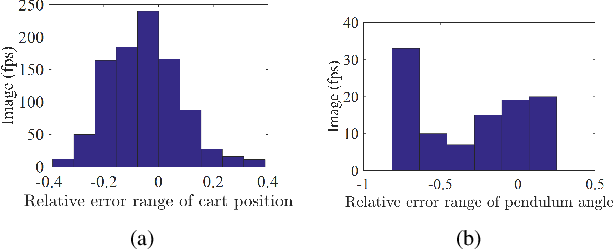

When visual image information is transmitted via communication networks, it easily suffers from image attacks, leading to system performance degradation or even crash. This paper investigates secure control of networked inverted pendulum visual servo system (NIPVSS) with adverse effects of image computation. Firstly, the image security limitation of the traditional NIPVSS is revealed, where its stability will be destroyed by eavesdropping-based image attacks. Then, a new NIPVSS with the fast scaled-selective image encryption (F2SIE) algorithm is proposed, which not only meets the real-time requirement by reducing the computational complexity, but also improve the security by reducing the probability of valuable information being compromised by eavesdropping-based image attacks. Secondly, adverse effects of the F2SIE algorithm and image attacks are analysed, which will produce extra computational delay and errors. Then, a closed-loop uncertain time-delay model of the new NIPVSS is established, and a robust controller is designed to guarantee system asymptotic stability. Finally, experimental results of the new NIPVSS demonstrate the feasibility and effectiveness of the proposed method.
Contrastive Learning and Data Augmentation in Traffic Classification Using a Flowpic Input Representation
Sep 18, 2023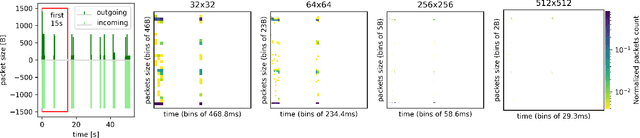

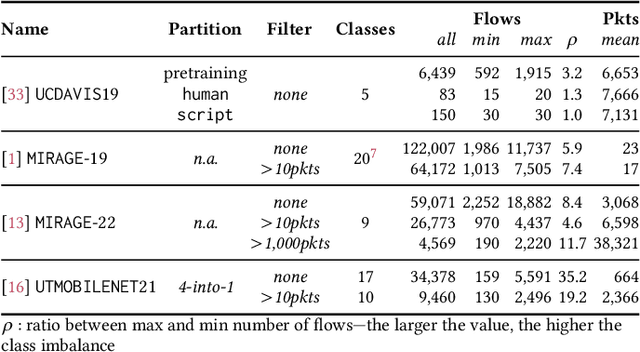
Over the last years we witnessed a renewed interest towards Traffic Classification (TC) captivated by the rise of Deep Learning (DL). Yet, the vast majority of TC literature lacks code artifacts, performance assessments across datasets and reference comparisons against Machine Learning (ML) methods. Among those works, a recent study from IMC'22 [17] is worth of attention since it adopts recent DL methodologies (namely, few-shot learning, self-supervision via contrastive learning and data augmentation) appealing for networking as they enable to learn from a few samples and transfer across datasets. The main result of [17] on the UCDAVIS19, ISCX-VPN and ISCX-Tor datasets is that, with such DL methodologies, 100 input samples are enough to achieve very high accuracy using an input representation called "flowpic" (i.e., a per-flow 2d histograms of the packets size evolution over time). In this paper (i) we reproduce [17] on the same datasets and (ii) we replicate its most salient aspect (the importance of data augmentation) on three additional public datasets, MIRAGE-19, MIRAGE-22 and UTMOBILENET21. While we confirm most of the original results, we also found a 20% accuracy drop on some of the investigated scenarios due to a data shift in the original dataset that we uncovered. Additionally, our study validates that the data augmentation strategies studied in [17] perform well on other datasets too. In the spirit of reproducibility and replicability we make all artifacts (code and data) available at [10].
Asynchronous Perception-Action-Communication with Graph Neural Networks
Sep 18, 2023Collaboration in large robot swarms to achieve a common global objective is a challenging problem in large environments due to limited sensing and communication capabilities. The robots must execute a Perception-Action-Communication (PAC) loop -- they perceive their local environment, communicate with other robots, and take actions in real time. A fundamental challenge in decentralized PAC systems is to decide what information to communicate with the neighboring robots and how to take actions while utilizing the information shared by the neighbors. Recently, this has been addressed using Graph Neural Networks (GNNs) for applications such as flocking and coverage control. Although conceptually, GNN policies are fully decentralized, the evaluation and deployment of such policies have primarily remained centralized or restrictively decentralized. Furthermore, existing frameworks assume sequential execution of perception and action inference, which is very restrictive in real-world applications. This paper proposes a framework for asynchronous PAC in robot swarms, where decentralized GNNs are used to compute navigation actions and generate messages for communication. In particular, we use aggregated GNNs, which enable the exchange of hidden layer information between robots for computational efficiency and decentralized inference of actions. Furthermore, the modules in the framework are asynchronous, allowing robots to perform sensing, extracting information, communication, action inference, and control execution at different frequencies. We demonstrate the effectiveness of GNNs executed in the proposed framework in navigating large robot swarms for collaborative coverage of large environments.
Selective Volume Mixup for Video Action Recognition
Sep 18, 2023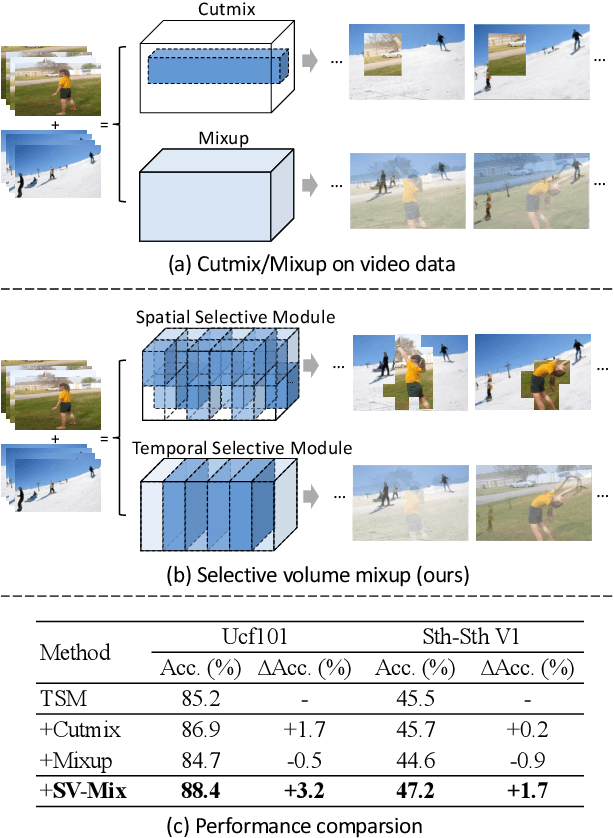
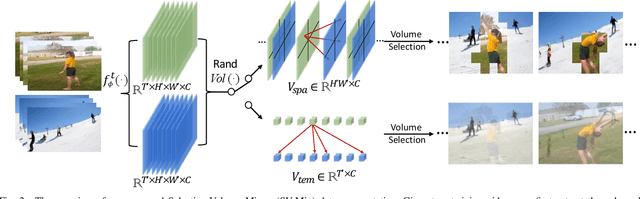
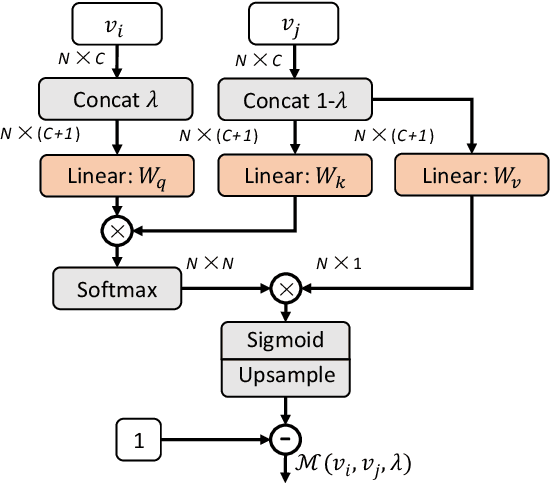
The recent advances in Convolutional Neural Networks (CNNs) and Vision Transformers have convincingly demonstrated high learning capability for video action recognition on large datasets. Nevertheless, deep models often suffer from the overfitting effect on small-scale datasets with a limited number of training videos. A common solution is to exploit the existing image augmentation strategies for each frame individually including Mixup, Cutmix, and RandAugment, which are not particularly optimized for video data. In this paper, we propose a novel video augmentation strategy named Selective Volume Mixup (SV-Mix) to improve the generalization ability of deep models with limited training videos. SV-Mix devises a learnable selective module to choose the most informative volumes from two videos and mixes the volumes up to achieve a new training video. Technically, we propose two new modules, i.e., a spatial selective module to select the local patches for each spatial position, and a temporal selective module to mix the entire frames for each timestamp and maintain the spatial pattern. At each time, we randomly choose one of the two modules to expand the diversity of training samples. The selective modules are jointly optimized with the video action recognition framework to find the optimal augmentation strategy. We empirically demonstrate the merits of the SV-Mix augmentation on a wide range of video action recognition benchmarks and consistently boot the performances of both CNN-based and transformer-based models.
Scalable Label-efficient Footpath Network Generation Using Remote Sensing Data and Self-supervised Learning
Sep 18, 2023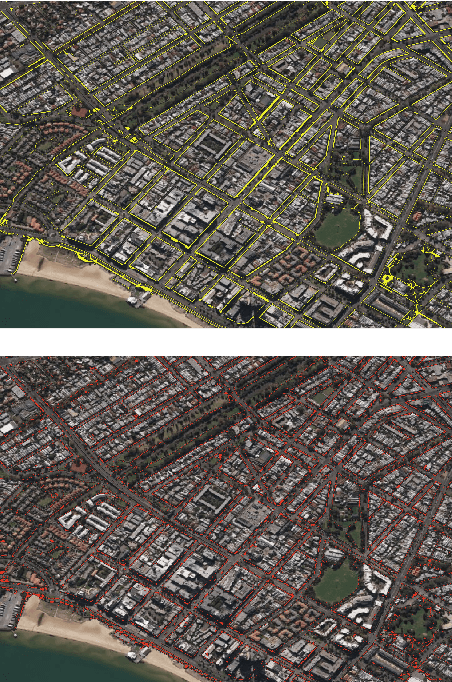
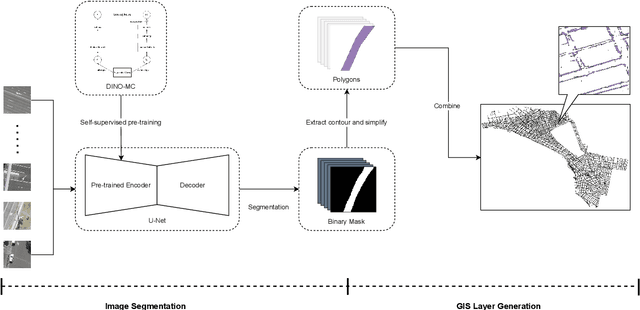
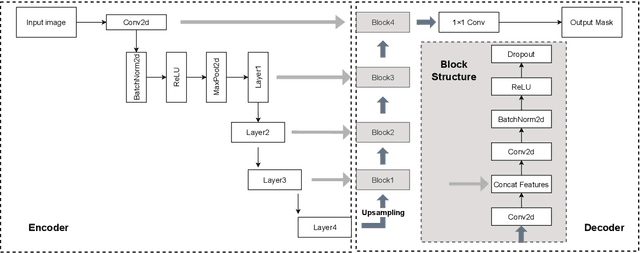
Footpath mapping, modeling, and analysis can provide important geospatial insights to many fields of study, including transport, health, environment and urban planning. The availability of robust Geographic Information System (GIS) layers can benefit the management of infrastructure inventories, especially at local government level with urban planners responsible for the deployment and maintenance of such infrastructure. However, many cities still lack real-time information on the location, connectivity, and width of footpaths, and/or employ costly and manual survey means to gather this information. This work designs and implements an automatic pipeline for generating footpath networks based on remote sensing images using machine learning models. The annotation of segmentation tasks, especially labeling remote sensing images with specialized requirements, is very expensive, so we aim to introduce a pipeline requiring less labeled data. Considering supervised methods require large amounts of training data, we use a self-supervised method for feature representation learning to reduce annotation requirements. Then the pre-trained model is used as the encoder of the U-Net for footpath segmentation. Based on the generated masks, the footpath polygons are extracted and converted to footpath networks which can be loaded and visualized by geographic information systems conveniently. Validation results indicate considerable consistency when compared to manually collected GIS layers. The footpath network generation pipeline proposed in this work is low-cost and extensible, and it can be applied where remote sensing images are available. Github: https://github.com/WennyXY/FootpathSeg.
From random-walks to graph-sprints: a low-latency node embedding framework on continuous-time dynamic graphs
Jul 18, 2023
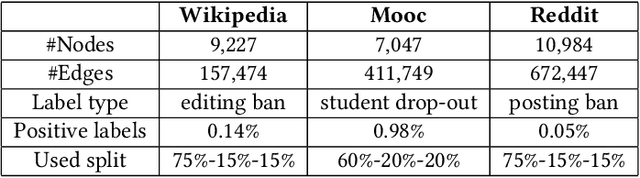
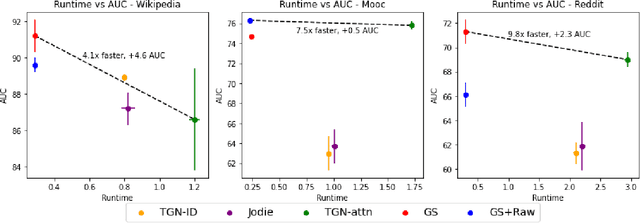
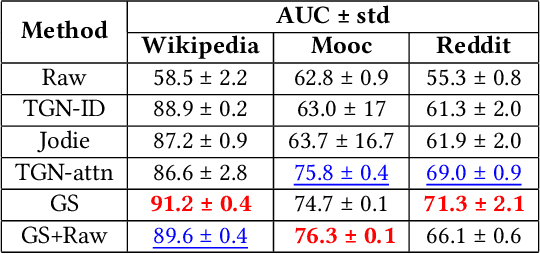
Many real-world datasets have an underlying dynamic graph structure, where entities and their interactions evolve over time. Machine learning models should consider these dynamics in order to harness their full potential in downstream tasks. Previous approaches for graph representation learning have focused on either sampling k-hop neighborhoods, akin to breadth-first search, or random walks, akin to depth-first search. However, these methods are computationally expensive and unsuitable for real-time, low-latency inference on dynamic graphs. To overcome these limitations, we propose graph-sprints a general purpose feature extraction framework for continuous-time-dynamic-graphs (CTDGs) that has low latency and is competitive with state-of-the-art, higher latency models. To achieve this, a streaming, low latency approximation to the random-walk based features is proposed. In our framework, time-aware node embeddings summarizing multi-hop information are computed using only single-hop operations on the incoming edges. We evaluate our proposed approach on three open-source datasets and two in-house datasets, and compare with three state-of-the-art algorithms (TGN-attn, TGN-ID, Jodie). We demonstrate that our graph-sprints features, combined with a machine learning classifier, achieve competitive performance (outperforming all baselines for the node classification tasks in five datasets). Simultaneously, graph-sprints significantly reduce inference latencies, achieving close to an order of magnitude speed-up in our experimental setting.