 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Drift Analysis with Fitness Levels for Elitist Evolutionary Algorithms
Sep 02, 2023

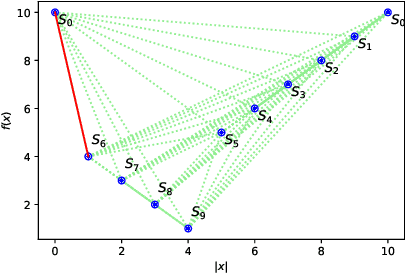
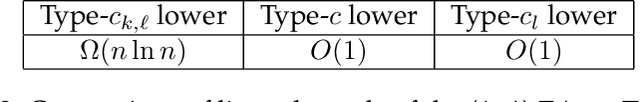

The fitness level method is a popular tool for analyzing the computation time of elitist evolutionary algorithms. Its idea is to divide the search space into multiple fitness levels and estimate lower and upper bounds on the computation time using transition probabilities between fitness levels. However, the lower bound generated from this method is often not tight. To improve the lower bound, this paper rigorously studies an open question about the fitness level method: what are the tightest lower and upper time bounds that can be constructed based on fitness levels? To answer this question, drift analysis with fitness levels is developed, and the tightest bound problem is formulated as a constrained multi-objective optimization problem subject to fitness level constraints. The tightest metric bounds from fitness levels are constructed and proven for the first time. Then the metric bounds are converted into linear bounds, where existing linear bounds are special cases. This paper establishes a general framework that can cover various linear bounds from trivial to best coefficients. It is generic and promising, as it can be used not only to draw the same bounds as existing ones, but also to draw tighter bounds, especially on fitness landscapes where shortcuts exist. This is demonstrated in the case study of the (1+1) EA maximizing the TwoPath function.
Retrieving Supporting Evidence for Generative Question Answering
Sep 20, 2023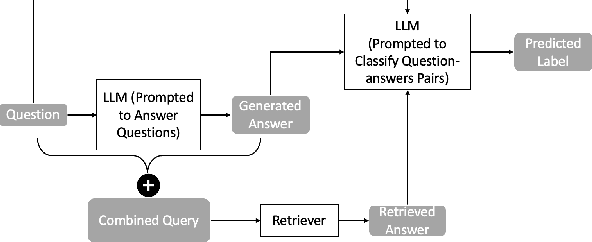
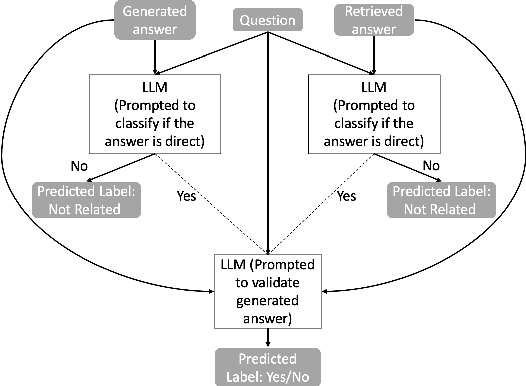
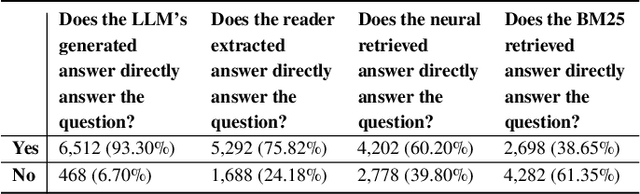

Current large language models (LLMs) can exhibit near-human levels of performance on many natural language-based tasks, including open-domain question answering. Unfortunately, at this time, they also convincingly hallucinate incorrect answers, so that responses to questions must be verified against external sources before they can be accepted at face value. In this paper, we report two simple experiments to automatically validate generated answers against a corpus. We base our experiments on questions and passages from the MS MARCO (V1) test collection, and a retrieval pipeline consisting of sparse retrieval, dense retrieval and neural rerankers. In the first experiment, we validate the generated answer in its entirety. After presenting a question to an LLM and receiving a generated answer, we query the corpus with the combination of the question + generated answer. We then present the LLM with the combination of the question + generated answer + retrieved answer, prompting it to indicate if the generated answer can be supported by the retrieved answer. In the second experiment, we consider the generated answer at a more granular level, prompting the LLM to extract a list of factual statements from the answer and verifying each statement separately. We query the corpus with each factual statement and then present the LLM with the statement and the corresponding retrieved evidence. The LLM is prompted to indicate if the statement can be supported and make necessary edits using the retrieved material. With an accuracy of over 80%, we find that an LLM is capable of verifying its generated answer when a corpus of supporting material is provided. However, manual assessment of a random sample of questions reveals that incorrect generated answers are missed by this verification process. While this verification process can reduce hallucinations, it can not entirely eliminate them.
Q-YOLO: Efficient Inference for Real-time Object Detection
Jul 01, 2023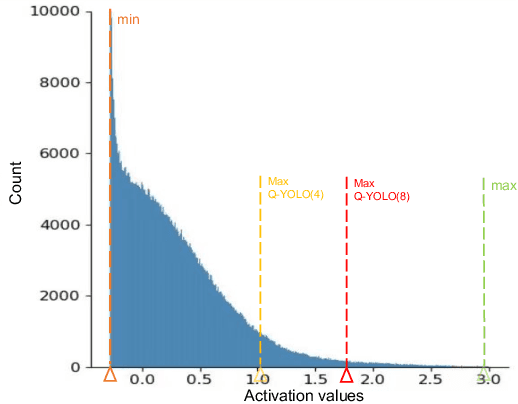
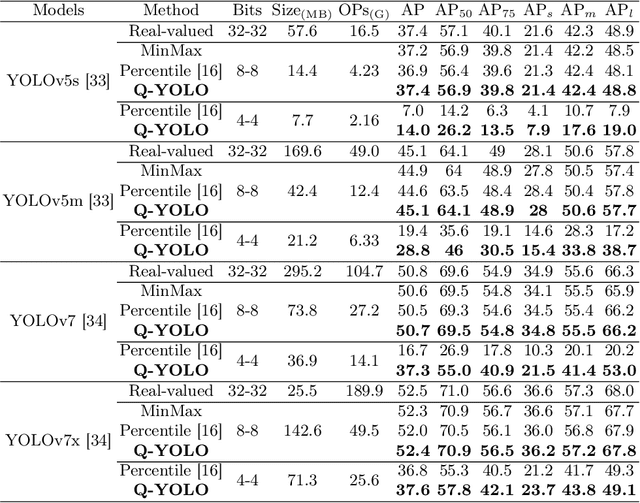
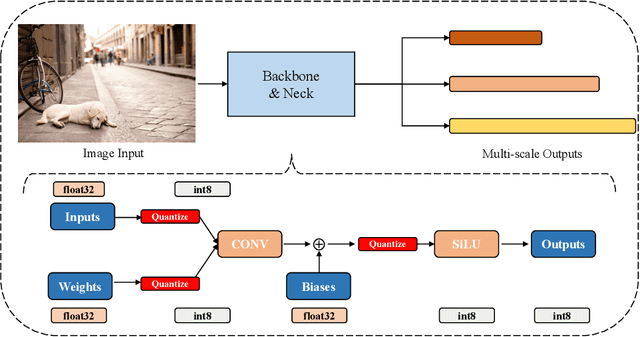
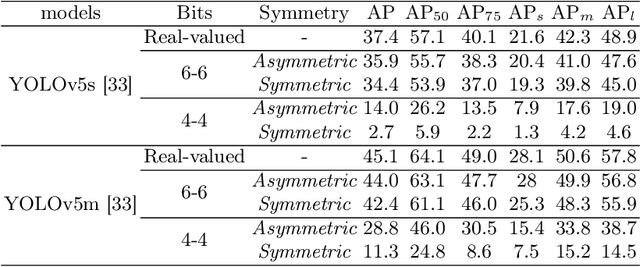
Real-time object detection plays a vital role in various computer vision applications. However, deploying real-time object detectors on resource-constrained platforms poses challenges due to high computational and memory requirements. This paper describes a low-bit quantization method to build a highly efficient one-stage detector, dubbed as Q-YOLO, which can effectively address the performance degradation problem caused by activation distribution imbalance in traditional quantized YOLO models. Q-YOLO introduces a fully end-to-end Post-Training Quantization (PTQ) pipeline with a well-designed Unilateral Histogram-based (UH) activation quantization scheme, which determines the maximum truncation values through histogram analysis by minimizing the Mean Squared Error (MSE) quantization errors. Extensive experiments on the COCO dataset demonstrate the effectiveness of Q-YOLO, outperforming other PTQ methods while achieving a more favorable balance between accuracy and computational cost. This research contributes to advancing the efficient deployment of object detection models on resource-limited edge devices, enabling real-time detection with reduced computational and memory overhead.
Active Learning for Semantic Segmentation with Multi-class Label Query
Sep 17, 2023This paper proposes a new active learning method for semantic segmentation. The core of our method lies in a new annotation query design. It samples informative local image regions (e.g., superpixels), and for each of such regions, asks an oracle for a multi-hot vector indicating all classes existing in the region. This multi-class labeling strategy is substantially more efficient than existing ones like segmentation, polygon, and even dominant class labeling in terms of annotation time per click. However, it introduces the class ambiguity issue in training since it assigns partial labels (i.e., a set of candidate classes) to individual pixels. We thus propose a new algorithm for learning semantic segmentation while disambiguating the partial labels in two stages. In the first stage, it trains a segmentation model directly with the partial labels through two new loss functions motivated by partial label learning and multiple instance learning. In the second stage, it disambiguates the partial labels by generating pixel-wise pseudo labels, which are used for supervised learning of the model. Equipped with a new acquisition function dedicated to the multi-class labeling, our method outperformed previous work on Cityscapes and PASCAL VOC 2012 while spending less annotation cost.
Real-time Strawberry Detection Based on Improved YOLOv5s Architecture for Robotic Harvesting in open-field environment
Aug 08, 2023
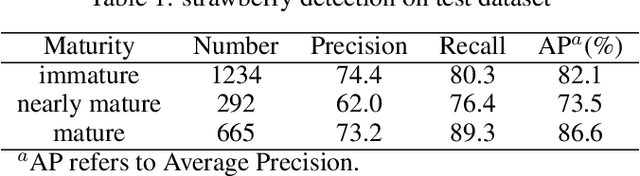


This study proposed a YOLOv5-based custom object detection model to detect strawberries in an outdoor environment. The original architecture of the YOLOv5s was modified by replacing the C3 module with the C2f module in the backbone network, which provided a better feature gradient flow. Secondly, the Spatial Pyramid Pooling Fast in the final layer of the backbone network of YOLOv5s was combined with Cross Stage Partial Net to improve the generalization ability over the strawberry dataset in this study. The proposed architecture was named YOLOv5s-Straw. The RGB images dataset of the strawberry canopy with three maturity classes (immature, nearly mature, and mature) was collected in open-field environment and augmented through a series of operations including brightness reduction, brightness increase, and noise adding. To verify the superiority of the proposed method for strawberry detection in open-field environment, four competitive detection models (YOLOv3-tiny, YOLOv5s, YOLOv5s-C2f, and YOLOv8s) were trained, and tested under the same computational environment and compared with YOLOv5s-Straw. The results showed that the highest mean average precision of 80.3% was achieved using the proposed architecture whereas the same was achieved with YOLOv3-tiny, YOLOv5s, YOLOv5s-C2f, and YOLOv8s were 73.4%, 77.8%, 79.8%, 79.3%, respectively. Specifically, the average precision of YOLOv5s-Straw was 82.1% in the immature class, 73.5% in the nearly mature class, and 86.6% in the mature class, which were 2.3% and 3.7%, respectively, higher than that of the latest YOLOv8s. The model included 8.6*10^6 network parameters with an inference speed of 18ms per image while the inference speed of YOLOv8s had a slower inference speed of 21.0ms and heavy parameters of 11.1*10^6, which indicates that the proposed model is fast enough for real time strawberry detection and localization for the robotic picking.
Towards Practical Capture of High-Fidelity Relightable Avatars
Sep 08, 2023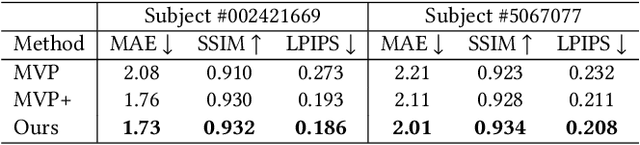
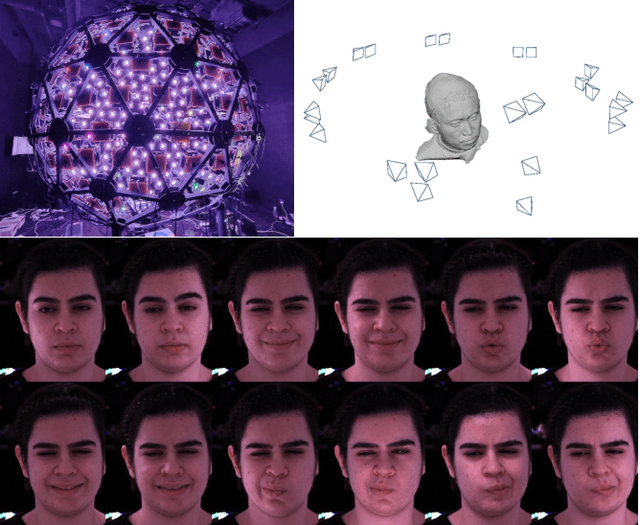
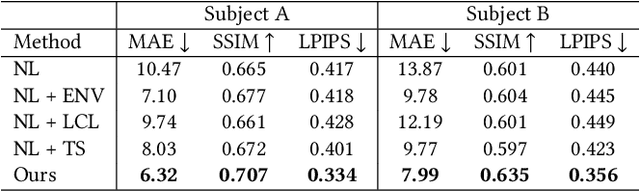
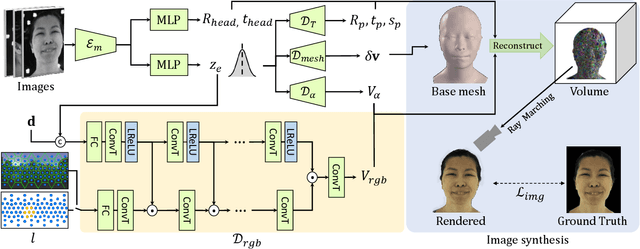
In this paper, we propose a novel framework, Tracking-free Relightable Avatar (TRAvatar), for capturing and reconstructing high-fidelity 3D avatars. Compared to previous methods, TRAvatar works in a more practical and efficient setting. Specifically, TRAvatar is trained with dynamic image sequences captured in a Light Stage under varying lighting conditions, enabling realistic relighting and real-time animation for avatars in diverse scenes. Additionally, TRAvatar allows for tracking-free avatar capture and obviates the need for accurate surface tracking under varying illumination conditions. Our contributions are two-fold: First, we propose a novel network architecture that explicitly builds on and ensures the satisfaction of the linear nature of lighting. Trained on simple group light captures, TRAvatar can predict the appearance in real-time with a single forward pass, achieving high-quality relighting effects under illuminations of arbitrary environment maps. Second, we jointly optimize the facial geometry and relightable appearance from scratch based on image sequences, where the tracking is implicitly learned. This tracking-free approach brings robustness for establishing temporal correspondences between frames under different lighting conditions. Extensive qualitative and quantitative experiments demonstrate that our framework achieves superior performance for photorealistic avatar animation and relighting.
Evaluating the Ebb and Flow: An In-depth Analysis of Question-Answering Trends across Diverse Platforms
Sep 12, 2023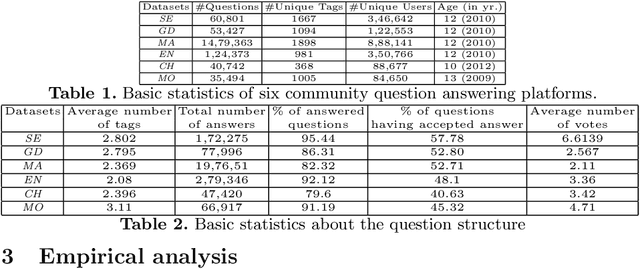
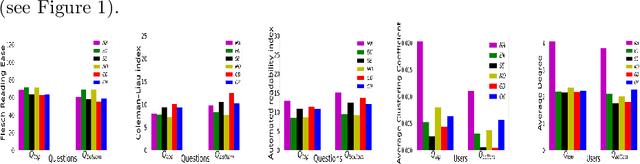


Community Question Answering (CQA) platforms steadily gain popularity as they provide users with fast responses to their queries. The swiftness of these responses is contingent on a mixture of query-specific and user-related elements. This paper scrutinizes these contributing factors within the context of six highly popular CQA platforms, identified through their standout answering speed. Our investigation reveals a correlation between the time taken to yield the first response to a question and several variables: the metadata, the formulation of the questions, and the level of interaction among users. Additionally, by employing conventional machine learning models to analyze these metadata and patterns of user interaction, we endeavor to predict which queries will receive their initial responses promptly.
On the Local Quadratic Stability of T-S Fuzzy Systems in the Vicinity of the Origin
Sep 14, 2023The main goal of this paper is to introduce new local stability conditions for continuous-time Takagi-Sugeno (T-S) fuzzy systems. These stability conditions are based on linear matrix inequalities (LMIs) in combination with quadratic Lyapunov functions. Moreover, they integrate information on the membership functions at the origin and effectively leverage the linear structure of the underlying nonlinear system in the vicinity of the origin. As a result, the proposed conditions are proved to be less conservative compared to existing methods using fuzzy Lyapunov functions in the literature. Moreover, we establish that the proposed methods offer necessary and sufficient conditions for the local exponential stability of T-S fuzzy systems. The paper also includes discussions on the inherent limitations associated with fuzzy Lyapunov approaches. To demonstrate the theoretical results, we provide comprehensive examples that elucidate the core concepts and validate the efficacy of the proposed conditions.
Asynchronous Spatial Allocation Protocol for Trajectory Planning of Heterogeneous Multi-Agent Systems
Sep 14, 2023


To plan the trajectories of a large and heterogeneous swarm, sequential or synchronous distributed methods usually become intractable, due to the lack of global connectivity and clock synchronization, Moreover, the existing asynchronously distributed schemes usually require recheck-like mechanisms instead of inherently considering the other' moving tendency. To this end, we propose a novel asynchronous protocol to allocate the agents' derivable space in a distributed way, by which each agent can replan trajectory depending on its own timetable. Properties such as collision avoidance and recursive feasibility are theoretically shown and a lower bound of protocol updating is provided. Comprehensive simulations and comparisons with five state-of-the-art methods validate the effectiveness of our method and illustrate the improvement in both the completion time and the moving distance. Finally, hardware experiments are carried out, where 8 heterogeneous unmanned ground vehicles with onboard computation navigate in cluttered scenarios at a high agility.
Real-time Traffic Classification for 5G NSA Encrypted Data Flows With Physical Channel Records
Jul 15, 2023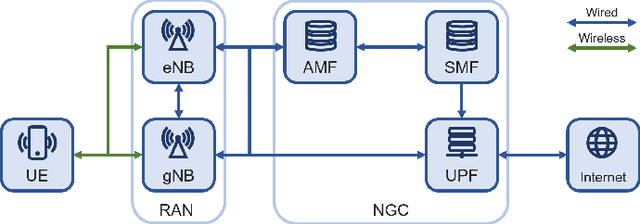
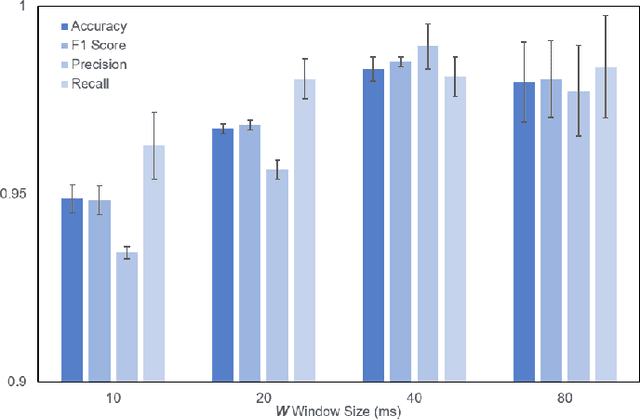
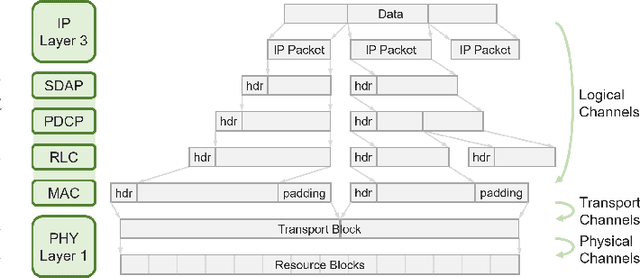
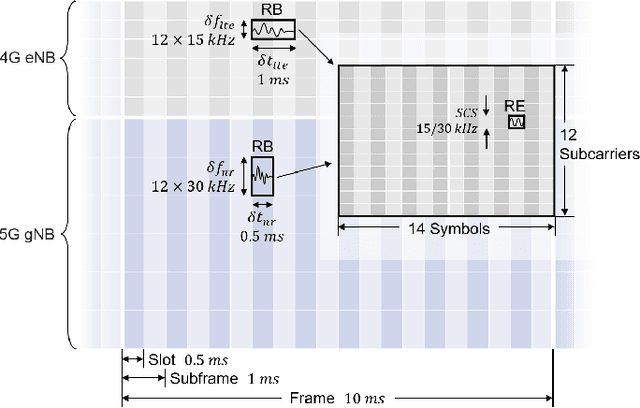
The classification of fifth-generation New-Radio (5G-NR) mobile network traffic is an emerging topic in the field of telecommunications. It can be utilized for quality of service (QoS) management and dynamic resource allocation. However, traditional approaches such as Deep Packet Inspection (DPI) can not be directly applied to encrypted data flows. Therefore, new real-time encrypted traffic classification algorithms need to be investigated to handle dynamic transmission. In this study, we examine the real-time encrypted 5G Non-Standalone (NSA) application-level traffic classification using physical channel records. Due to the vastness of their features, decision-tree-based gradient boosting algorithms are a viable approach for classification. We generate a noise-limited 5G NSA trace dataset with traffic from multiple applications. We develop a new pipeline to convert sequences of physical channel records into numerical vectors. A set of machine learning models are tested, and we propose our solution based on Light Gradient Boosting Machine (LGBM) due to its advantages in fast parallel training and low computational burden in practical scenarios. Our experiments demonstrate that our algorithm can achieve 95% accuracy on the classification task with a state-of-the-art response time as quick as 10ms.