 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Multi-Relational Contrastive Learning for Recommendation
Sep 03, 2023
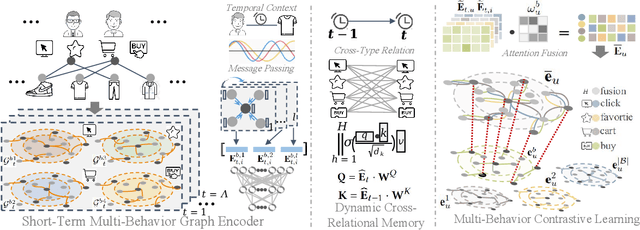

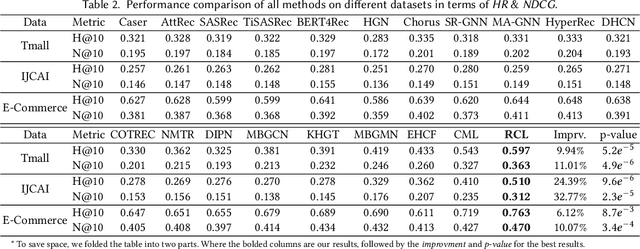

Personalized recommender systems play a crucial role in capturing users' evolving preferences over time to provide accurate and effective recommendations on various online platforms. However, many recommendation models rely on a single type of behavior learning, which limits their ability to represent the complex relationships between users and items in real-life scenarios. In such situations, users interact with items in multiple ways, including clicking, tagging as favorite, reviewing, and purchasing. To address this issue, we propose the Relation-aware Contrastive Learning (RCL) framework, which effectively models dynamic interaction heterogeneity. The RCL model incorporates a multi-relational graph encoder that captures short-term preference heterogeneity while preserving the dedicated relation semantics for different types of user-item interactions. Moreover, we design a dynamic cross-relational memory network that enables the RCL model to capture users' long-term multi-behavior preferences and the underlying evolving cross-type behavior dependencies over time. To obtain robust and informative user representations with both commonality and diversity across multi-behavior interactions, we introduce a multi-relational contrastive learning paradigm with heterogeneous short- and long-term interest modeling. Our extensive experimental studies on several real-world datasets demonstrate the superiority of the RCL recommender system over various state-of-the-art baselines in terms of recommendation accuracy and effectiveness.
An Effective and Efficient Time-aware Entity Alignment Framework via Two-aspect Three-view Label Propagation
Jul 12, 2023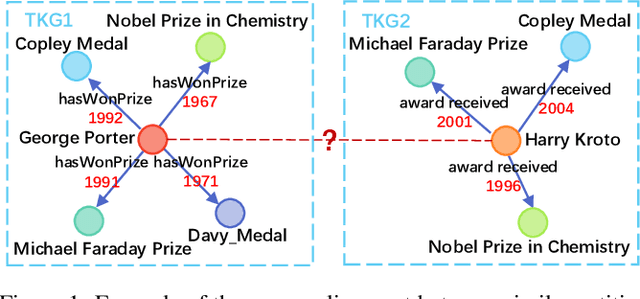

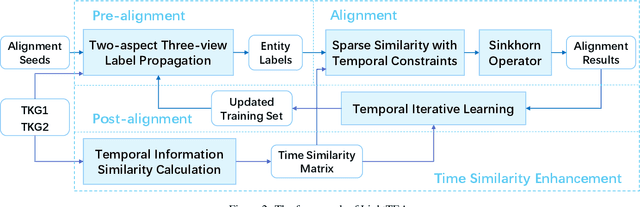
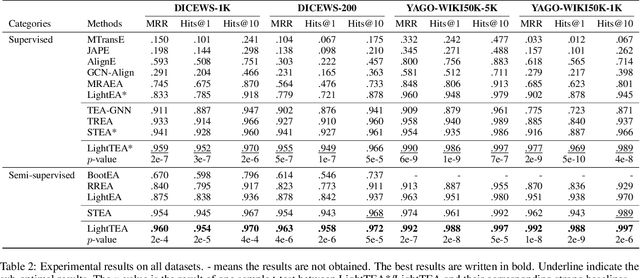
Entity alignment (EA) aims to find the equivalent entity pairs between different knowledge graphs (KGs), which is crucial to promote knowledge fusion. With the wide use of temporal knowledge graphs (TKGs), time-aware EA (TEA) methods appear to enhance EA. Existing TEA models are based on Graph Neural Networks (GNN) and achieve state-of-the-art (SOTA) performance, but it is difficult to transfer them to large-scale TKGs due to the scalability issue of GNN. In this paper, we propose an effective and efficient non-neural EA framework between TKGs, namely LightTEA, which consists of four essential components: (1) Two-aspect Three-view Label Propagation, (2) Sparse Similarity with Temporal Constraints, (3) Sinkhorn Operator, and (4) Temporal Iterative Learning. All of these modules work together to improve the performance of EA while reducing the time consumption of the model. Extensive experiments on public datasets indicate that our proposed model significantly outperforms the SOTA methods for EA between TKGs, and the time consumed by LightTEA is only dozens of seconds at most, no more than 10% of the most efficient TEA method.
From continuous-time formulations to discretization schemes: tensor trains and robust regression for BSDEs and parabolic PDEs
Jul 28, 2023

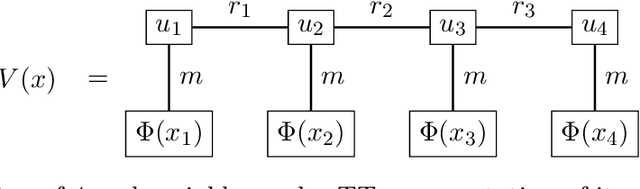
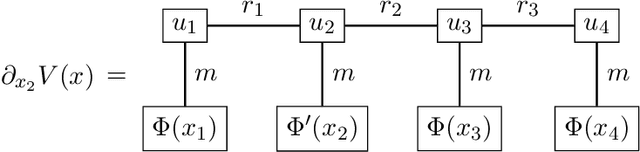
The numerical approximation of partial differential equations (PDEs) poses formidable challenges in high dimensions since classical grid-based methods suffer from the so-called curse of dimensionality. Recent attempts rely on a combination of Monte Carlo methods and variational formulations, using neural networks for function approximation. Extending previous work (Richter et al., 2021), we argue that tensor trains provide an appealing framework for parabolic PDEs: The combination of reformulations in terms of backward stochastic differential equations and regression-type methods holds the promise of leveraging latent low-rank structures, enabling both compression and efficient computation. Emphasizing a continuous-time viewpoint, we develop iterative schemes, which differ in terms of computational efficiency and robustness. We demonstrate both theoretically and numerically that our methods can achieve a favorable trade-off between accuracy and computational efficiency. While previous methods have been either accurate or fast, we have identified a novel numerical strategy that can often combine both of these aspects.
Preserved Edge Convolutional Neural Network for Sensitivity Enhancement of Deuterium Metabolic Imaging (DMI)
Sep 13, 2023
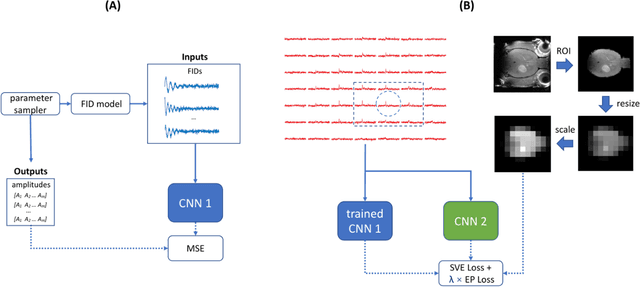
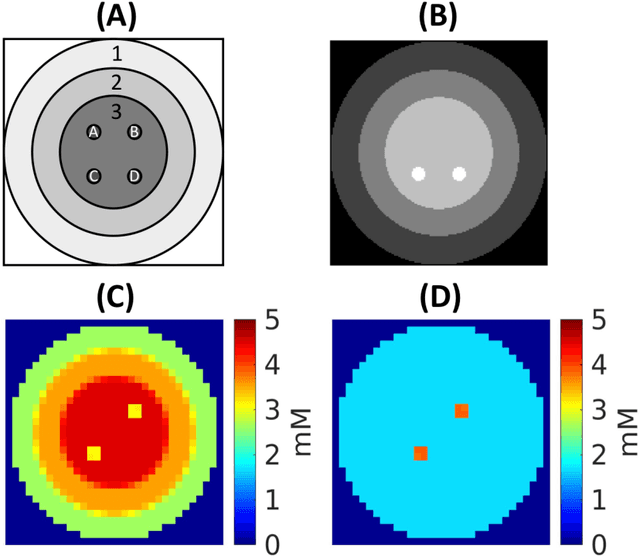
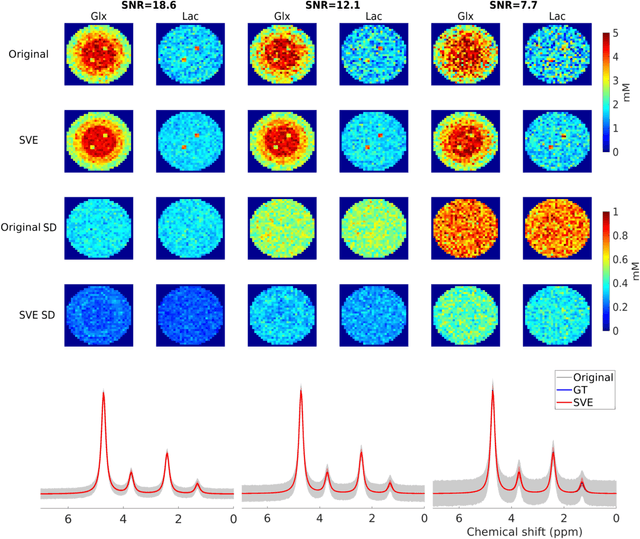
Purpose: Common to most MRSI techniques, the spatial resolution and the minimal scan duration of Deuterium Metabolic Imaging (DMI) are limited by the achievable SNR. This work presents a deep learning method for sensitivity enhancement of DMI. Methods: A convolutional neural network (CNN) was designed to estimate the 2H-labeled metabolite concentrations from low SNR and distorted DMI FIDs. The CNN was trained with synthetic data that represent a range of SNR levels typically encountered in vivo. The estimation precision was further improved by fine-tuning the CNN with MRI-based edge-preserving regularization for each DMI dataset. The proposed processing method, PReserved Edge ConvolutIonal neural network for Sensitivity Enhanced DMI (PRECISE-DMI), was applied to simulation studies and in vivo experiments to evaluate the anticipated improvements in SNR and investigate the potential for inaccuracies. Results: PRECISE-DMI visually improved the metabolic maps of low SNR datasets, and quantitatively provided higher precision than the standard Fourier reconstruction. Processing of DMI data acquired in rat brain tumor models resulted in more precise determination of 2H-labeled lactate and glutamate + glutamine levels, at increased spatial resolution (from >8 to 2 $\mu$L) or shortened scan time (from 32 to 4 min) compared to standard acquisitions. However, rigorous SD-bias analyses showed that overuse of the edge-preserving regularization can compromise the accuracy of the results. Conclusion: PRECISE-DMI allows a flexible trade-off between enhancing the sensitivity of DMI and minimizing the inaccuracies. With typical settings, the DMI sensitivity can be improved by 3-fold while retaining the capability to detect local signal variations.
Learning Behavioral Representations of Routines From Large-scale Unlabeled Wearable Time-series Data Streams using Hawkes Point Process
Jul 10, 2023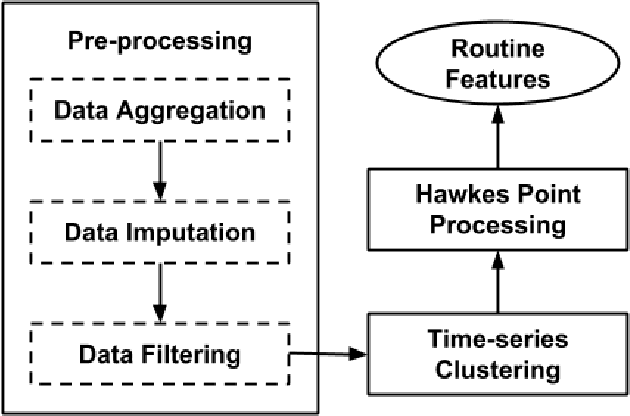
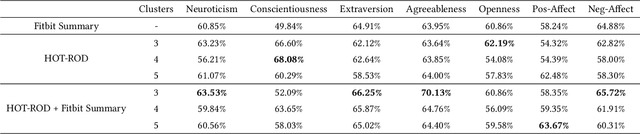
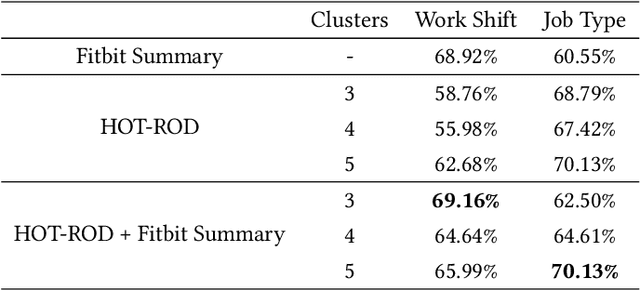
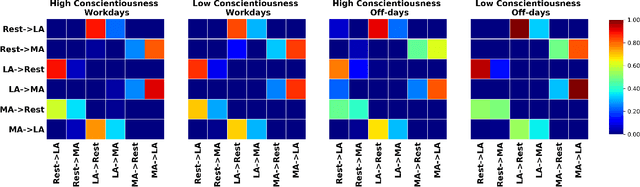
Continuously-worn wearable sensors enable researchers to collect copious amounts of rich bio-behavioral time series recordings of real-life activities of daily living, offering unprecedented opportunities to infer novel human behavior patterns during daily routines. Existing approaches to routine discovery through bio-behavioral data rely either on pre-defined notions of activities or use additional non-behavioral measurements as contexts, such as GPS location or localization within the home, presenting risks to user privacy. In this work, we propose a novel wearable time-series mining framework, Hawkes point process On Time series clusters for ROutine Discovery (HOT-ROD), for uncovering behavioral routines from completely unlabeled wearable recordings. We utilize a covariance-based method to generate time-series clusters and discover routines via the Hawkes point process learning algorithm. We empirically validate our approach for extracting routine behaviors using a completely unlabeled time-series collected continuously from over 100 individuals both in and outside of the workplace during a period of ten weeks. Furthermore, we demonstrate this approach intuitively captures daily transitional relationships between physical activity states without using prior knowledge. We also show that the learned behavioral patterns can assist in illuminating an individual's personality and affect.
Hybrid ASR for Resource-Constrained Robots: HMM - Deep Learning Fusion
Sep 11, 2023This paper presents a novel hybrid Automatic Speech Recognition (ASR) system designed specifically for resource-constrained robots. The proposed approach combines Hidden Markov Models (HMMs) with deep learning models and leverages socket programming to distribute processing tasks effectively. In this architecture, the HMM-based processing takes place within the robot, while a separate PC handles the deep learning model. This synergy between HMMs and deep learning enhances speech recognition accuracy significantly. We conducted experiments across various robotic platforms, demonstrating real-time and precise speech recognition capabilities. Notably, the system exhibits adaptability to changing acoustic conditions and compatibility with low-power hardware, making it highly effective in environments with limited computational resources. This hybrid ASR paradigm opens up promising possibilities for seamless human-robot interaction. In conclusion, our research introduces a pioneering dimension to ASR techniques tailored for robotics. By employing socket programming to distribute processing tasks across distinct devices and strategically combining HMMs with deep learning models, our hybrid ASR system showcases its potential to enable robots to comprehend and respond to spoken language adeptly, even in environments with restricted computational resources. This paradigm sets a innovative course for enhancing human-robot interaction across a wide range of real-world scenarios.
On Reducing Undesirable Behavior in Deep Reinforcement Learning Models
Sep 11, 2023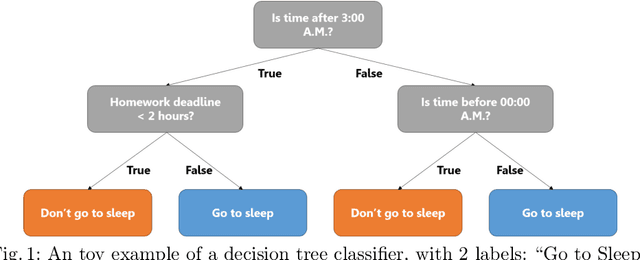
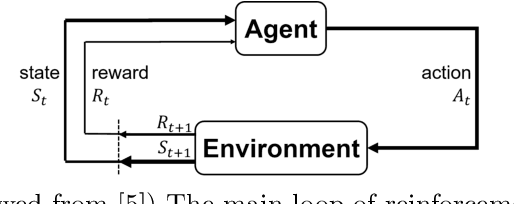
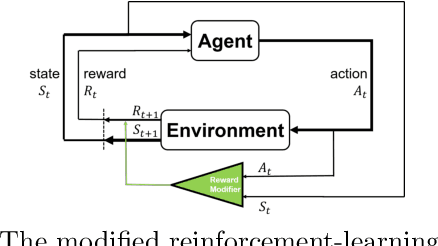
Deep reinforcement learning (DRL) has proven extremely useful in a large variety of application domains. However, even successful DRL-based software can exhibit highly undesirable behavior. This is due to DRL training being based on maximizing a reward function, which typically captures general trends but cannot precisely capture, or rule out, certain behaviors of the system. In this paper, we propose a novel framework aimed at drastically reducing the undesirable behavior of DRL-based software, while maintaining its excellent performance. In addition, our framework can assist in providing engineers with a comprehensible characterization of such undesirable behavior. Under the hood, our approach is based on extracting decision tree classifiers from erroneous state-action pairs, and then integrating these trees into the DRL training loop, penalizing the system whenever it performs an error. We provide a proof-of-concept implementation of our approach, and use it to evaluate the technique on three significant case studies. We find that our approach can extend existing frameworks in a straightforward manner, and incurs only a slight overhead in training time. Further, it incurs only a very slight hit to performance, or even in some cases - improves it, while significantly reducing the frequency of undesirable behavior.
EANet: Expert Attention Network for Online Trajectory Prediction
Sep 11, 2023


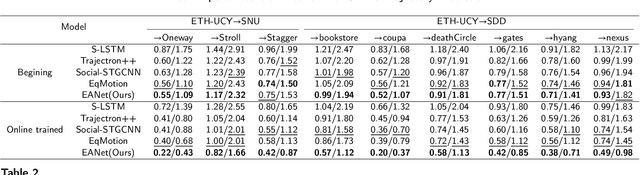
Trajectory prediction plays a crucial role in autonomous driving. Existing mainstream research and continuoual learning-based methods all require training on complete datasets, leading to poor prediction accuracy when sudden changes in scenarios occur and failing to promptly respond and update the model. Whether these methods can make a prediction in real-time and use data instances to update the model immediately(i.e., online learning settings) remains a question. The problem of gradient explosion or vanishing caused by data instance streams also needs to be addressed. Inspired by Hedge Propagation algorithm, we propose Expert Attention Network, a complete online learning framework for trajectory prediction. We introduce expert attention, which adjusts the weights of different depths of network layers, avoiding the model updated slowly due to gradient problem and enabling fast learning of new scenario's knowledge to restore prediction accuracy. Furthermore, we propose a short-term motion trend kernel function which is sensitive to scenario change, allowing the model to respond quickly. To the best of our knowledge, this work is the first attempt to address the online learning problem in trajectory prediction. The experimental results indicate that traditional methods suffer from gradient problems and that our method can quickly reduce prediction errors and reach the state-of-the-art prediction accuracy.
Task-Oriented Cross-System Design for Timely and Accurate Modeling in the Metaverse
Sep 11, 2023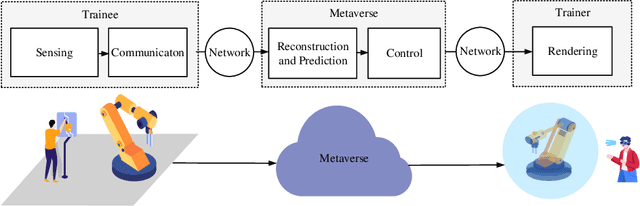
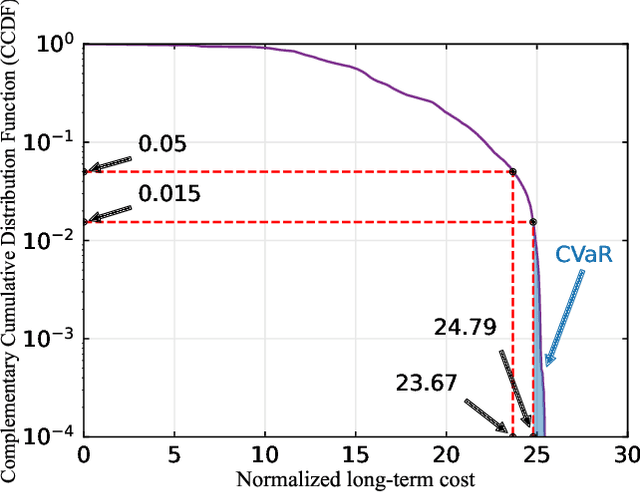
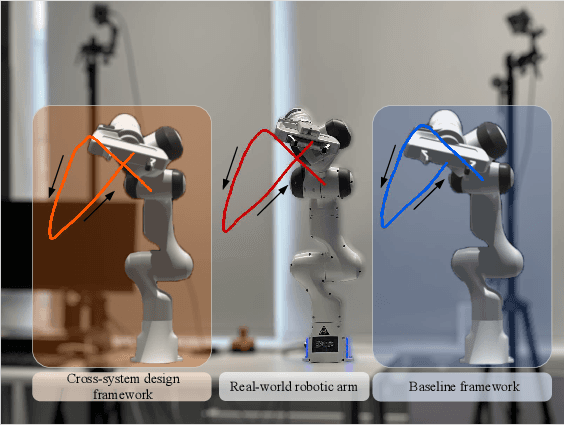
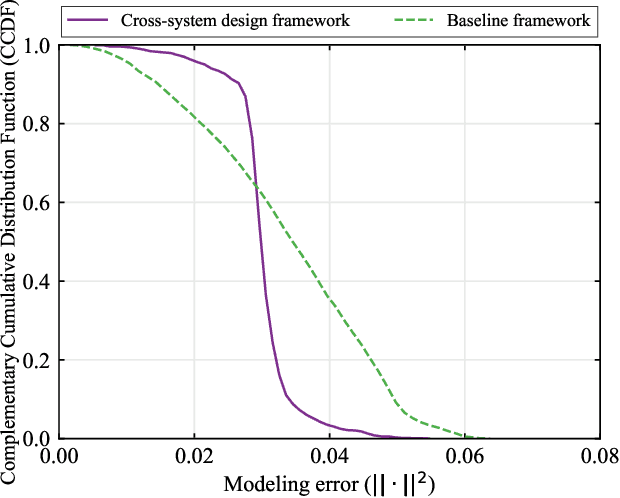
In this paper, we establish a task-oriented cross-system design framework to minimize the required packet rate for timely and accurate modeling of a real-world robotic arm in the Metaverse, where sensing, communication, prediction, control, and rendering are considered. To optimize a scheduling policy and prediction horizons, we design a Constraint Proximal Policy Optimization(C-PPO) algorithm by integrating domain knowledge from relevant systems into the advanced reinforcement learning algorithm, Proximal Policy Optimization(PPO). Specifically, the Jacobian matrix for analyzing the motion of the robotic arm is included in the state of the C-PPO algorithm, and the Conditional Value-at-Risk(CVaR) of the state-value function characterizing the long-term modeling error is adopted in the constraint. Besides, the policy is represented by a two-branch neural network determining the scheduling policy and the prediction horizons, respectively. To evaluate our algorithm, we build a prototype including a real-world robotic arm and its digital model in the Metaverse. The experimental results indicate that domain knowledge helps to reduce the convergence time and the required packet rate by up to 50%, and the cross-system design framework outperforms a baseline framework in terms of the required packet rate and the tail distribution of the modeling error.
Efficient Defense Against Model Stealing Attacks on Convolutional Neural Networks
Sep 11, 2023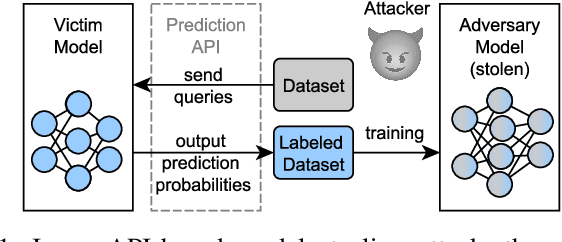
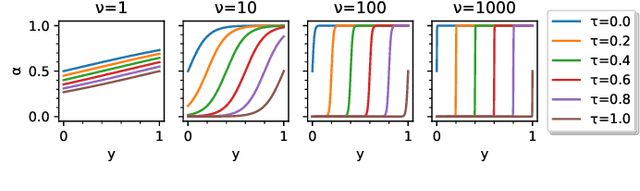
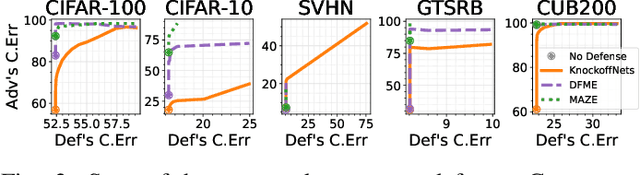
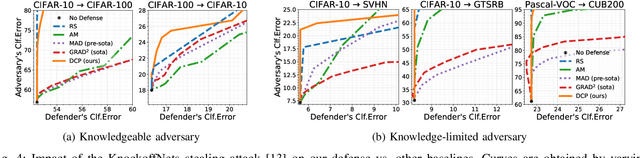
Model stealing attacks have become a serious concern for deep learning models, where an attacker can steal a trained model by querying its black-box API. This can lead to intellectual property theft and other security and privacy risks. The current state-of-the-art defenses against model stealing attacks suggest adding perturbations to the prediction probabilities. However, they suffer from heavy computations and make impracticable assumptions about the adversary. They often require the training of auxiliary models. This can be time-consuming and resource-intensive which hinders the deployment of these defenses in real-world applications. In this paper, we propose a simple yet effective and efficient defense alternative. We introduce a heuristic approach to perturb the output probabilities. The proposed defense can be easily integrated into models without additional training. We show that our defense is effective in defending against three state-of-the-art stealing attacks. We evaluate our approach on large and quantized (i.e., compressed) Convolutional Neural Networks (CNNs) trained on several vision datasets. Our technique outperforms the state-of-the-art defenses with a $\times37$ faster inference latency without requiring any additional model and with a low impact on the model's performance. We validate that our defense is also effective for quantized CNNs targeting edge devices.