 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Incorporating Pre-trained Model Prompting in Multimodal Stock Volume Movement Prediction
Sep 11, 2023
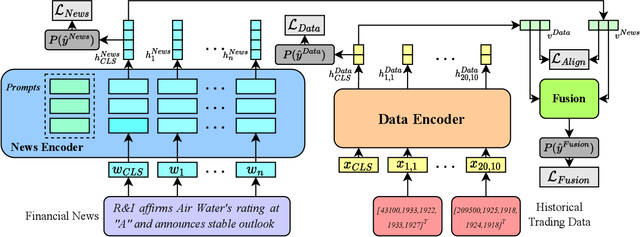
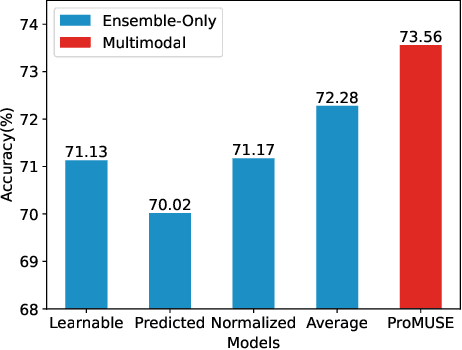
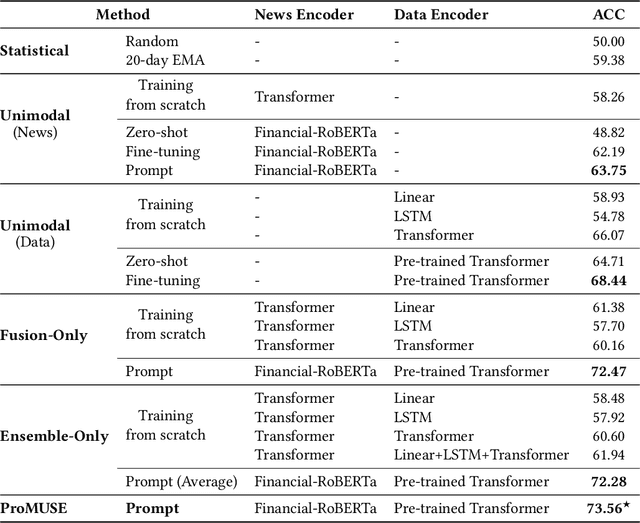
Multimodal stock trading volume movement prediction with stock-related news is one of the fundamental problems in the financial area. Existing multimodal works that train models from scratch face the problem of lacking universal knowledge when modeling financial news. In addition, the models ability may be limited by the lack of domain-related knowledge due to insufficient data in the datasets. To handle this issue, we propose the Prompt-based MUltimodal Stock volumE prediction model (ProMUSE) to process text and time series modalities. We use pre-trained language models for better comprehension of financial news and adopt prompt learning methods to leverage their capability in universal knowledge to model textual information. Besides, simply fusing two modalities can cause harm to the unimodal representations. Thus, we propose a novel cross-modality contrastive alignment while reserving the unimodal heads beside the fusion head to mitigate this problem. Extensive experiments demonstrate that our proposed ProMUSE outperforms existing baselines. Comprehensive analyses further validate the effectiveness of our architecture compared to potential variants and learning mechanisms.
CaloClouds II: Ultra-Fast Geometry-Independent Highly-Granular Calorimeter Simulation
Sep 11, 2023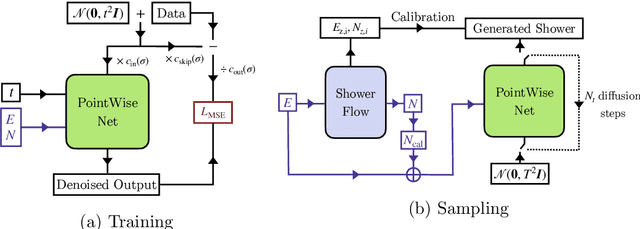

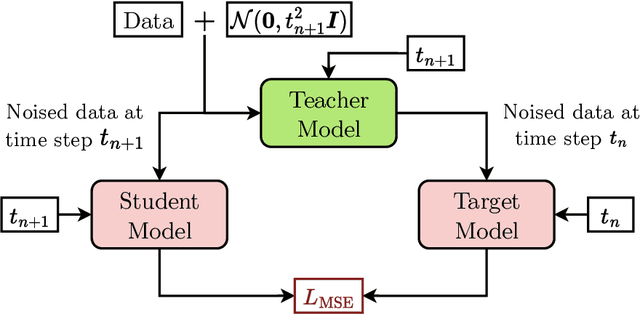

Fast simulation of the energy depositions in high-granular detectors is needed for future collider experiments with ever increasing luminosities. Generative machine learning (ML) models have been shown to speed up and augment the traditional simulation chain in physics analysis. However, the majority of previous efforts were limited to models relying on fixed, regular detector readout geometries. A major advancement is the recently introduced CaloClouds model, a geometry-independent diffusion model, which generates calorimeter showers as point clouds for the electromagnetic calorimeter of the envisioned International Large Detector (ILD). In this work, we introduce CaloClouds II which features a number of key improvements. This includes continuous time score-based modelling, which allows for a 25 step sampling with comparable fidelity to CaloClouds while yielding a $6\times$ speed-up over Geant4 on a single CPU ($5\times$ over CaloClouds). We further distill the diffusion model into a consistency model allowing for accurate sampling in a single step and resulting in a $46\times$ ($37\times$) speed-up. This constitutes the first application of consistency distillation for the generation of calorimeter showers.
Diffusion-Guided Reconstruction of Everyday Hand-Object Interaction Clips
Sep 11, 2023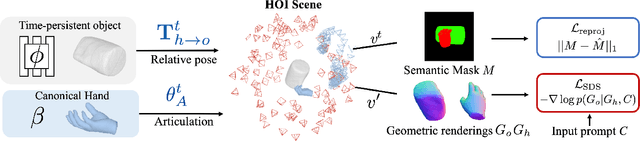
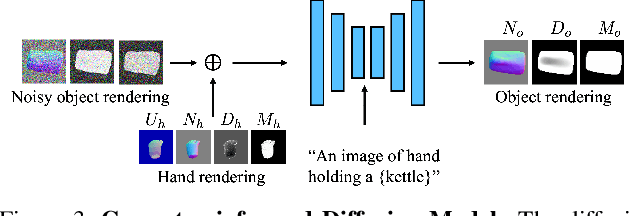

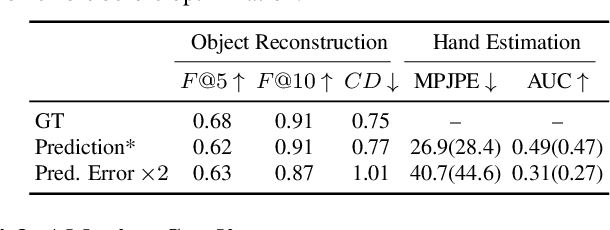
We tackle the task of reconstructing hand-object interactions from short video clips. Given an input video, our approach casts 3D inference as a per-video optimization and recovers a neural 3D representation of the object shape, as well as the time-varying motion and hand articulation. While the input video naturally provides some multi-view cues to guide 3D inference, these are insufficient on their own due to occlusions and limited viewpoint variations. To obtain accurate 3D, we augment the multi-view signals with generic data-driven priors to guide reconstruction. Specifically, we learn a diffusion network to model the conditional distribution of (geometric) renderings of objects conditioned on hand configuration and category label, and leverage it as a prior to guide the novel-view renderings of the reconstructed scene. We empirically evaluate our approach on egocentric videos across 6 object categories, and observe significant improvements over prior single-view and multi-view methods. Finally, we demonstrate our system's ability to reconstruct arbitrary clips from YouTube, showing both 1st and 3rd person interactions.
Multi-Modal Automatic Prosody Annotation with Contrastive Pretraining of SSWP
Sep 11, 2023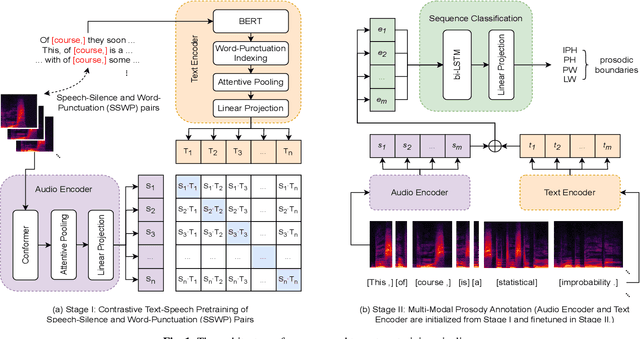
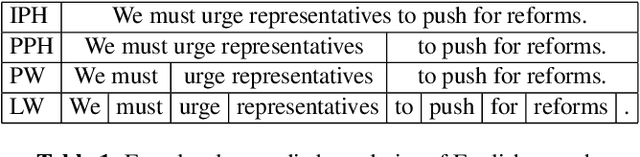
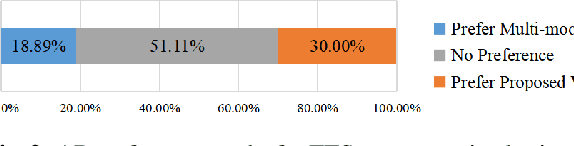
In the realm of expressive Text-to-Speech (TTS), explicit prosodic boundaries significantly advance the naturalness and controllability of synthesized speech. While human prosody annotation contributes a lot to the performance, it is a labor-intensive and time-consuming process, often resulting in inconsistent outcomes. Despite the availability of extensive supervised data, the current benchmark model still faces performance setbacks. To address this issue, a two-stage automatic annotation pipeline is novelly proposed in this paper. Specifically, in the first stage, we propose contrastive text-speech pretraining of Speech-Silence and Word-Punctuation (SSWP) pairs. The pretraining procedure hammers at enhancing the prosodic space extracted from joint text-speech space. In the second stage, we build a multi-modal prosody annotator, which consists of pretrained encoders, a straightforward yet effective text-speech feature fusion scheme, and a sequence classifier. Extensive experiments conclusively demonstrate that our proposed method excels at automatically generating prosody annotation and achieves state-of-the-art (SOTA) performance. Furthermore, our novel model has exhibited remarkable resilience when tested with varying amounts of data.
PAg-NeRF: Towards fast and efficient end-to-end panoptic 3D representations for agricultural robotics
Sep 11, 2023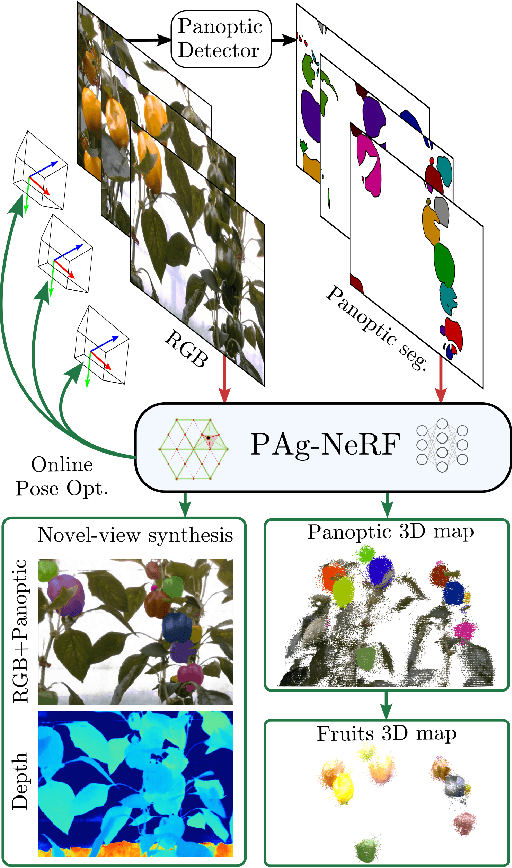

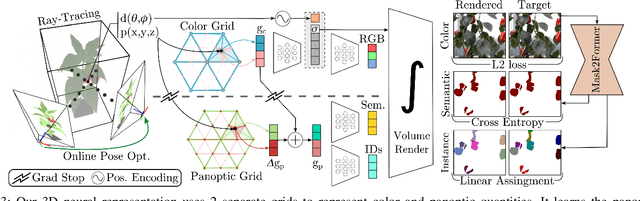

Precise scene understanding is key for most robot monitoring and intervention tasks in agriculture. In this work we present PAg-NeRF which is a novel NeRF-based system that enables 3D panoptic scene understanding. Our representation is trained using an image sequence with noisy robot odometry poses and automatic panoptic predictions with inconsistent IDs between frames. Despite this noisy input, our system is able to output scene geometry, photo-realistic renders and 3D consistent panoptic representations with consistent instance IDs. We evaluate this novel system in a very challenging horticultural scenario and in doing so demonstrate an end-to-end trainable system that can make use of noisy robot poses rather than precise poses that have to be pre-calculated. Compared to a baseline approach the peak signal to noise ratio is improved from 21.34dB to 23.37dB while the panoptic quality improves from 56.65% to 70.08%. Furthermore, our approach is faster and can be tuned to improve inference time by more than a factor of 2 while being memory efficient with approximately 12 times fewer parameters.
Activation Addition: Steering Language Models Without Optimization
Sep 01, 2023Reliably controlling the behavior of large language models is a pressing open problem. Existing methods include supervised finetuning, reinforcement learning from human feedback, prompt engineering, and guided decoding. We instead investigate activation engineering: modifying activations at inference time to predictably alter model behavior. In particular, we bias the forward pass with an added 'steering vector' implicitly specified through natural language. Unlike past work which learned these steering vectors, our Activation Addition (ActAdd) method computes them by taking the activation differences that result from pairs of prompts. We demonstrate ActAdd on GPT-2 on OpenWebText and ConceptNet. Our inference-time approach yields control over high-level properties of output and preserves off-target model performance. It involves far less compute and implementation effort than finetuning, allows users to provide natural language specifications, and its overhead scales naturally with model size.
SA-Solver: Stochastic Adams Solver for Fast Sampling of Diffusion Models
Sep 10, 2023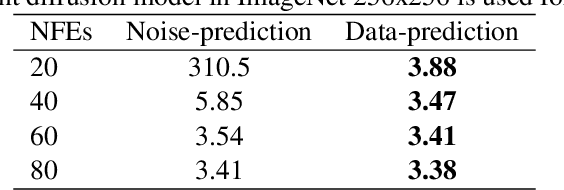
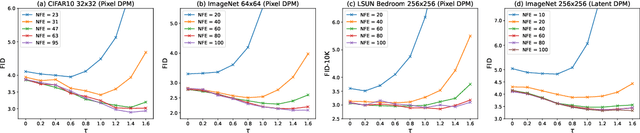
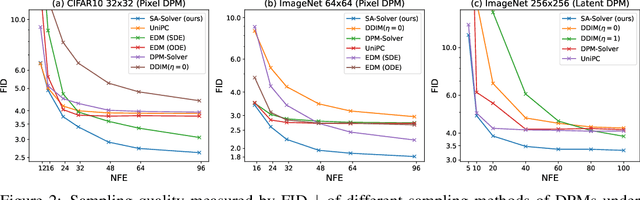
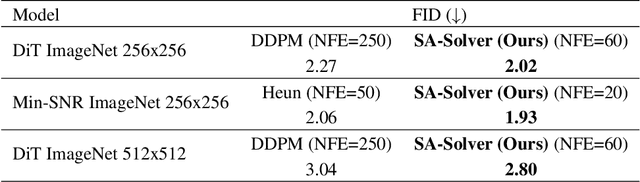
Diffusion Probabilistic Models (DPMs) have achieved considerable success in generation tasks. As sampling from DPMs is equivalent to solving diffusion SDE or ODE which is time-consuming, numerous fast sampling methods built upon improved differential equation solvers are proposed. The majority of such techniques consider solving the diffusion ODE due to its superior efficiency. However, stochastic sampling could offer additional advantages in generating diverse and high-quality data. In this work, we engage in a comprehensive analysis of stochastic sampling from two aspects: variance-controlled diffusion SDE and linear multi-step SDE solver. Based on our analysis, we propose SA-Solver, which is an improved efficient stochastic Adams method for solving diffusion SDE to generate data with high quality. Our experiments show that SA-Solver achieves: 1) improved or comparable performance compared with the existing state-of-the-art sampling methods for few-step sampling; 2) SOTA FID scores on substantial benchmark datasets under a suitable number of function evaluations (NFEs).
Efficient Learning of PDEs via Taylor Expansion and Sparse Decomposition into Value and Fourier Domains
Sep 13, 2023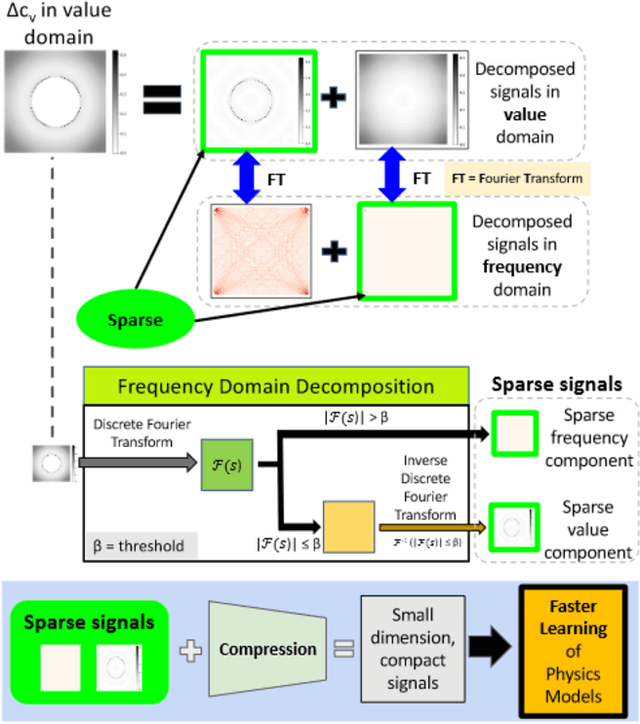
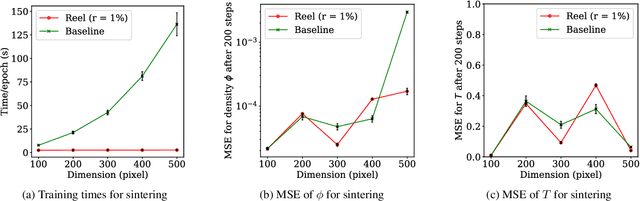
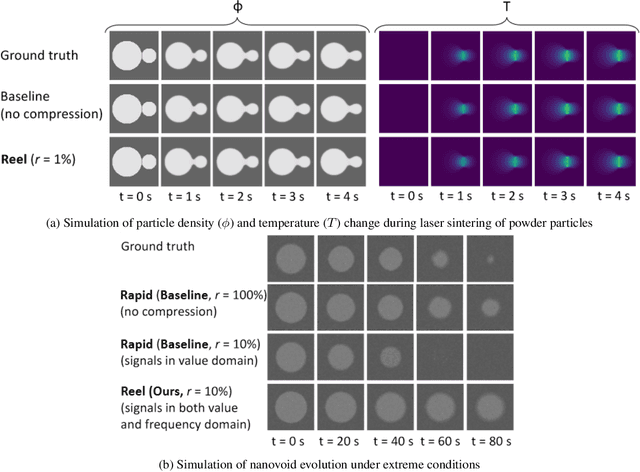
Accelerating the learning of Partial Differential Equations (PDEs) from experimental data will speed up the pace of scientific discovery. Previous randomized algorithms exploit sparsity in PDE updates for acceleration. However such methods are applicable to a limited class of decomposable PDEs, which have sparse features in the value domain. We propose Reel, which accelerates the learning of PDEs via random projection and has much broader applicability. Reel exploits the sparsity by decomposing dense updates into sparse ones in both the value and frequency domains. This decomposition enables efficient learning when the source of the updates consists of gradually changing terms across large areas (sparse in the frequency domain) in addition to a few rapid updates concentrated in a small set of "interfacial" regions (sparse in the value domain). Random projection is then applied to compress the sparse signals for learning. To expand the model applicability, Taylor series expansion is used in Reel to approximate the nonlinear PDE updates with polynomials in the decomposable form. Theoretically, we derive a constant factor approximation between the projected loss function and the original one with poly-logarithmic number of projected dimensions. Experimentally, we provide empirical evidence that our proposed Reel can lead to faster learning of PDE models (70-98% reduction in training time when the data is compressed to 1% of its original size) with comparable quality as the non-compressed models.
Remote Inference of Cognitive Scores in ALS Patients Using a Picture Description
Sep 13, 2023Amyotrophic lateral sclerosis is a fatal disease that not only affects movement, speech, and breath but also cognition. Recent studies have focused on the use of language analysis techniques to detect ALS and infer scales for monitoring functional progression. In this paper, we focused on another important aspect, cognitive impairment, which affects 35-50% of the ALS population. In an effort to reach the ALS population, which frequently exhibits mobility limitations, we implemented the digital version of the Edinburgh Cognitive and Behavioral ALS Screen (ECAS) test for the first time. This test which is designed to measure cognitive impairment was remotely performed by 56 participants from the EverythingALS Speech Study. As part of the study, participants (ALS and non-ALS) were asked to describe weekly one picture from a pool of many pictures with complex scenes displayed on their computer at home. We analyze the descriptions performed within +/- 60 days from the day the ECAS test was administered and extract different types of linguistic and acoustic features. We input those features into linear regression models to infer 5 ECAS sub-scores and the total score. Speech samples from the picture description are reliable enough to predict the ECAS subs-scores, achieving statistically significant Spearman correlation values between 0.32 and 0.51 for the model's performance using 10-fold cross-validation.
A Wearable Ultra-Low-Power sEMG-Triggered Ultrasound System for Long-Term Muscle Activity Monitoring
Sep 13, 2023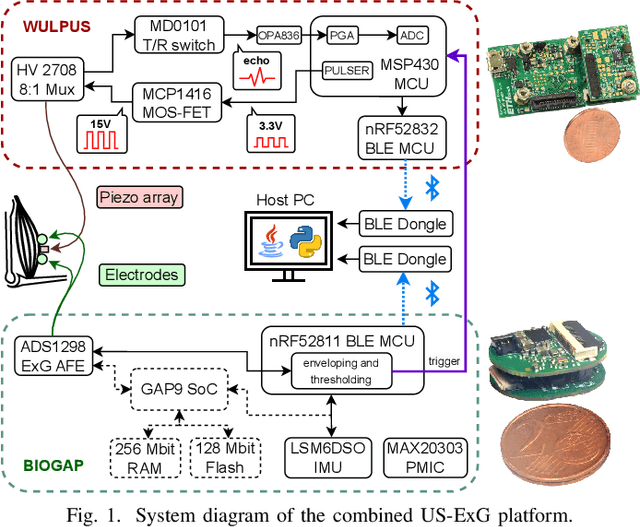
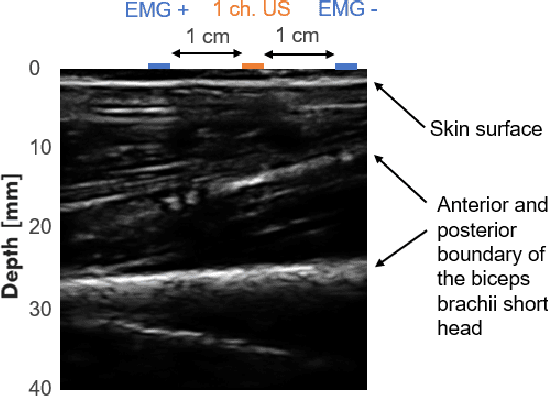
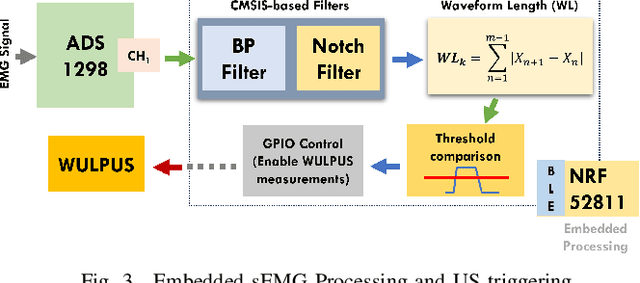
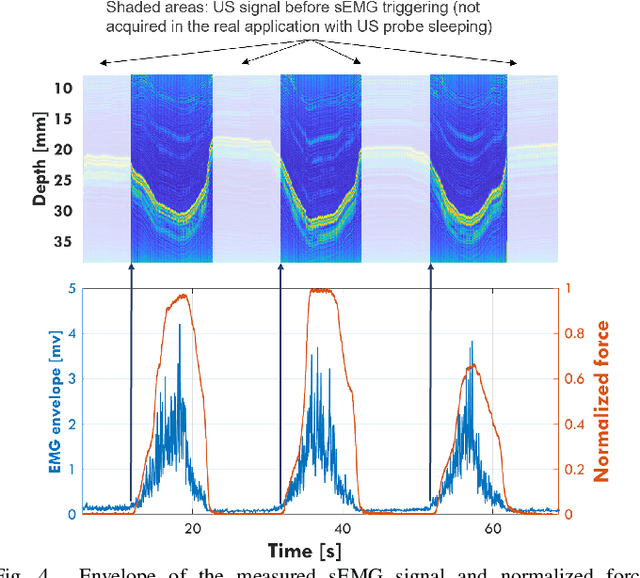
Wearable biosignal processing applications are driving significant progress toward miniaturized, energy-efficient Internet-of-Things solutions for both clinical and consumer applications. However, scaling toward high-density multi-channel front-ends is only feasible by performing data processing and \ac{ML} near-sensor through energy-efficient edge processing. To tackle these challenges, we introduce BioGAP, a novel, compact, modular, and lightweight (6g) medical-grade biosignal acquisition and processing platform powered by GAP9, a ten-core ultra-low-power SoC designed for efficient multi-precision (from FP to aggressively quantized integer) processing, as required for advanced ML and DSP. BioGAP's form factor is 16x21x14~mm$^3$ and comprises two stacked PCBs: a baseboard integrating the GAP9 SoC, a wireless \ac{BLE} capable SoC, a power management circuit, and an accelerometer; and a shield including an \ac{AFE} for ExG acquisition. Finally, the system also includes a flexibly placeable \ac{PPG} PCB with a size of 9x7x3~mm$^3$ and a rechargeable battery ($\phi$ 12x5~mm$^2$). We demonstrate BioGAP on a \ac{SSVEP}-based \ac{BCI} application. We achieve 3.6~$\mu J/sample$ in streaming and 2.2~$\mu J/sample$ in onboard processing mode, thanks to an efficiency on the FFT computation task of 16.7~Mflops/s/mW with wireless bandwidth reduction of 97\%, within a power budget of just 18.2~mW allowing for an operation time of 15~h.