 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Reliable and Resilient Framework for Multi-UAV Mutual Localization
Sep 08, 2023
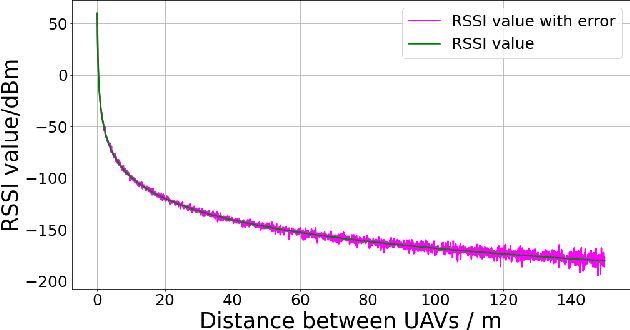
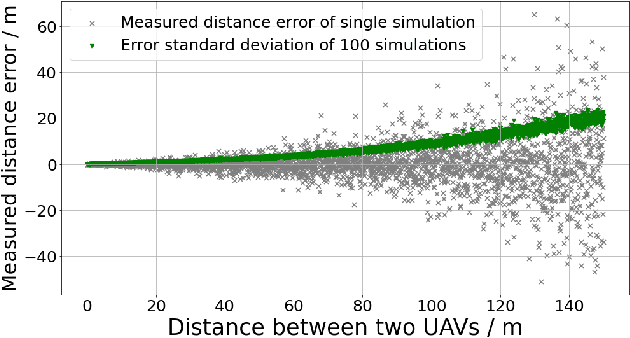
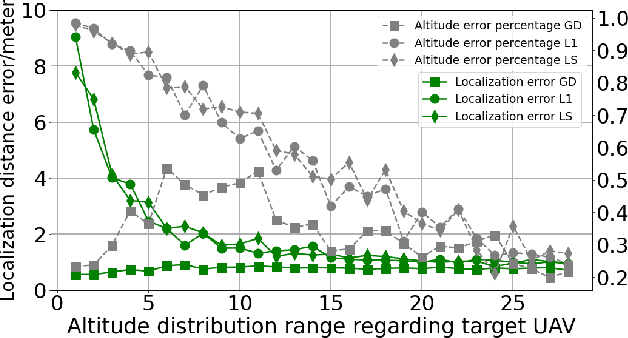
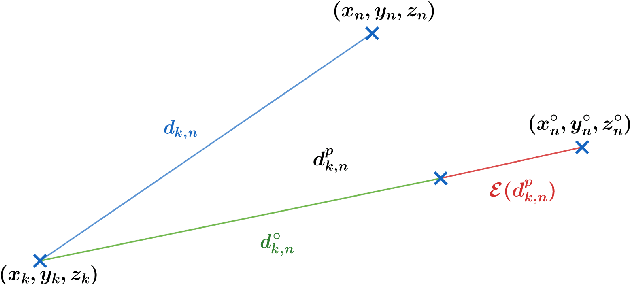
This paper presents a robust and secure framework for achieving accurate and reliable mutual localization in multiple unmanned aerial vehicle (UAV) systems. Challenges of accurate localization and security threats are addressed and corresponding solutions are brought forth and accessed in our paper with numerical simulations. The proposed solution incorporates two key components: the Mobility Adaptive Gradient Descent (MAGD) and Time-evolving Anomaly Detectio (TAD). The MAGD adapts the gradient descent algorithm to handle the configuration changes in the mutual localization system, ensuring accurate localization in dynamic scenarios. The TAD cooperates with reputation propagation (RP) scheme to detect and mitigate potential attacks by identifying UAVs with malicious data, enhancing the security and resilience of the mutual localization
Speech Emotion Recognition with Distilled Prosodic and Linguistic Affect Representations
Sep 09, 2023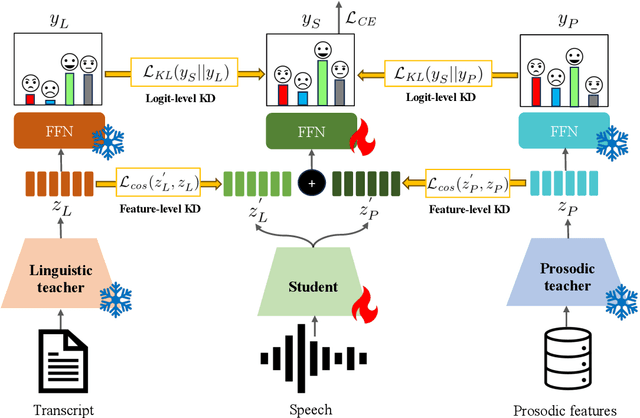
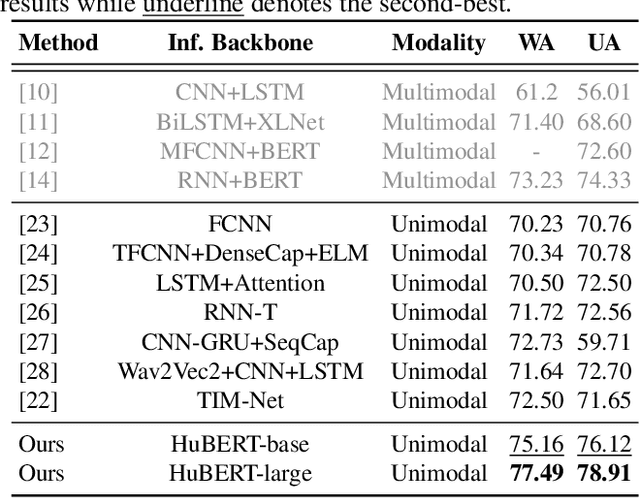
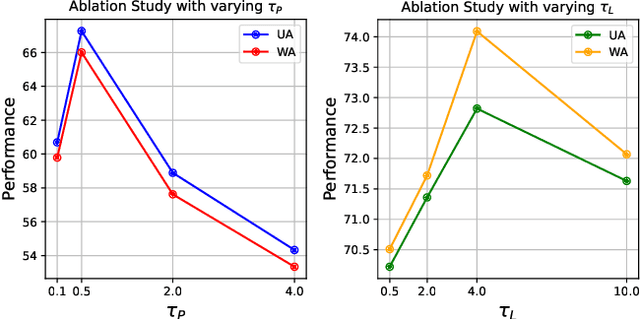
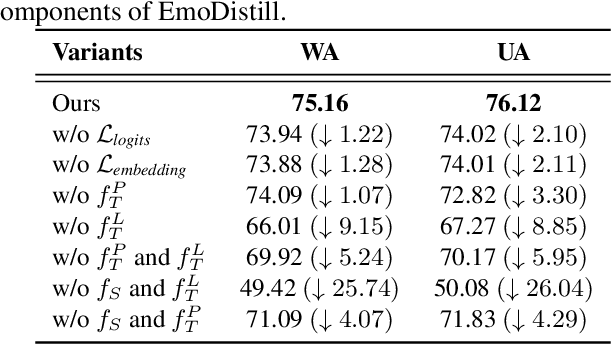
We propose EmoDistill, a novel speech emotion recognition (SER) framework that leverages cross-modal knowledge distillation during training to learn strong linguistic and prosodic representations of emotion from speech. During inference, our method only uses a stream of speech signals to perform unimodal SER thus reducing computation overhead and avoiding run-time transcription and prosodic feature extraction errors. During training, our method distills information at both embedding and logit levels from a pair of pre-trained Prosodic and Linguistic teachers that are fine-tuned for SER. Experiments on the IEMOCAP benchmark demonstrate that our method outperforms other unimodal and multimodal techniques by a considerable margin, and achieves state-of-the-art performance of 77.49% unweighted accuracy and 78.91% weighted accuracy. Detailed ablation studies demonstrate the impact of each component of our method.
Data Augmentation for Conversational AI
Sep 09, 2023Advancements in conversational systems have revolutionized information access, surpassing the limitations of single queries. However, developing dialogue systems requires a large amount of training data, which is a challenge in low-resource domains and languages. Traditional data collection methods like crowd-sourcing are labor-intensive and time-consuming, making them ineffective in this context. Data augmentation (DA) is an affective approach to alleviate the data scarcity problem in conversational systems. This tutorial provides a comprehensive and up-to-date overview of DA approaches in the context of conversational systems. It highlights recent advances in conversation augmentation, open domain and task-oriented conversation generation, and different paradigms of evaluating these models. We also discuss current challenges and future directions in order to help researchers and practitioners to further advance the field in this area.
Integrated Robotics Networks with Co-optimization of Drone Placement and Air-Ground Communications
Sep 09, 2023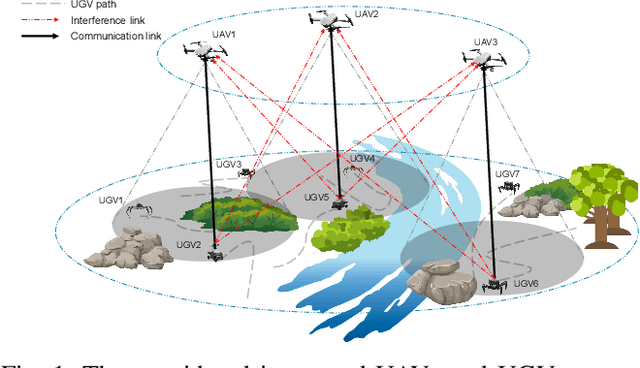
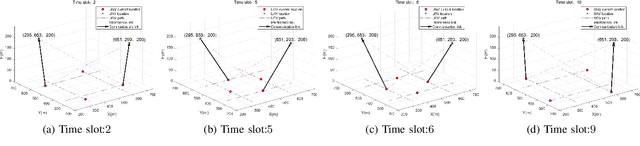

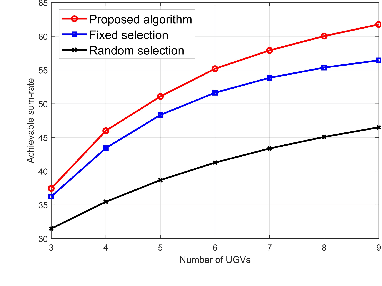
Terrestrial robots, i.e., unmanned ground vehicles (UGVs), and aerial robots, i.e., unmanned aerial vehicles (UAVs), operate in separate spaces. To exploit their complementary features (e.g., fields of views, communication links, computing capabilities), a promising paradigm termed integrated robotics network emerges, which provides communications for cooperative UAVs-UGVs applications. However, how to efficiently deploy UAVs and schedule the UAVs-UGVs connections according to different UGV tasks become challenging. In this paper, we propose a sum-rate maximization problem, where UGVs plan their trajectories autonomously and are dynamically associated with UAVs according to their planned trajectories. Although the problem is a NP-hard mixed integer program, a fast polynomial time algorithm using alternating gradient descent and penalty-based binary relaxation, is devised. Simulation results demonstrate the effectiveness of the proposed algorithm.
LEyes: A Lightweight Framework for Deep Learning-Based Eye Tracking using Synthetic Eye Images
Sep 12, 2023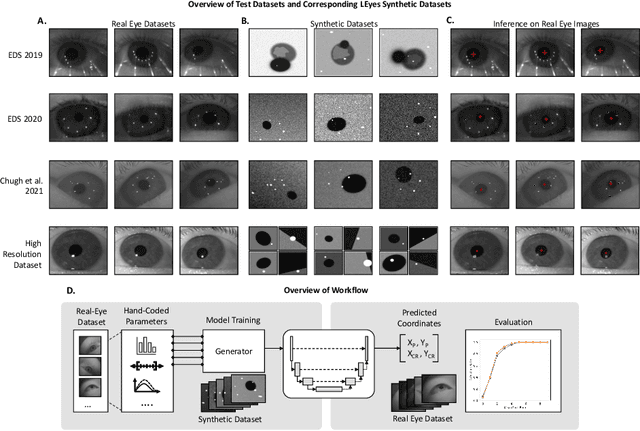
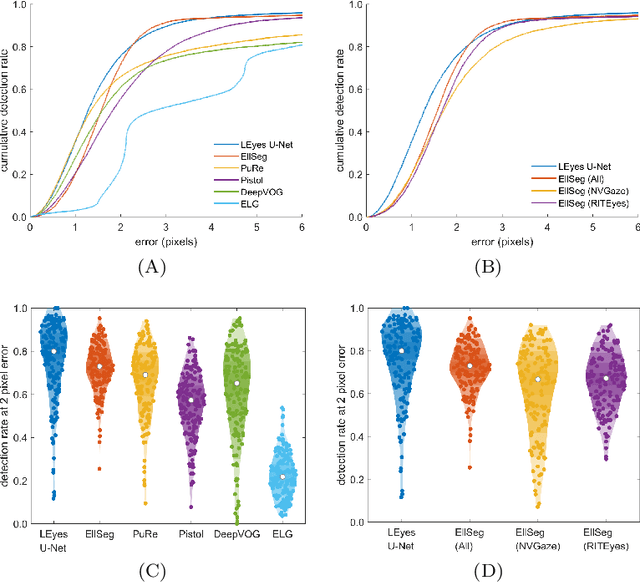
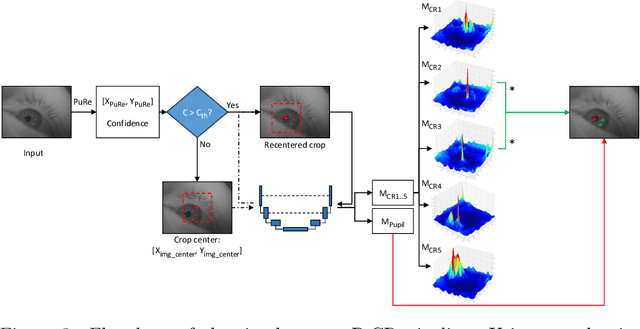
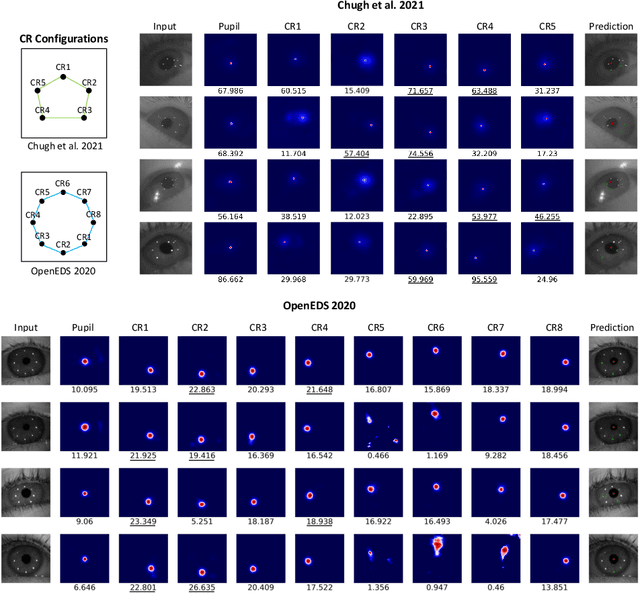
Deep learning has bolstered gaze estimation techniques, but real-world deployment has been impeded by inadequate training datasets. This problem is exacerbated by both hardware-induced variations in eye images and inherent biological differences across the recorded participants, leading to both feature and pixel-level variance that hinders the generalizability of models trained on specific datasets. While synthetic datasets can be a solution, their creation is both time and resource-intensive. To address this problem, we present a framework called Light Eyes or "LEyes" which, unlike conventional photorealistic methods, only models key image features required for video-based eye tracking using simple light distributions. LEyes facilitates easy configuration for training neural networks across diverse gaze-estimation tasks. We demonstrate that models trained using LEyes outperform other state-of-the-art algorithms in terms of pupil and CR localization across well-known datasets. In addition, a LEyes trained model outperforms the industry standard eye tracker using significantly more cost-effective hardware. Going forward, we are confident that LEyes will revolutionize synthetic data generation for gaze estimation models, and lead to significant improvements of the next generation video-based eye trackers.
Accelerating Deep Neural Networks via Semi-Structured Activation Sparsity
Sep 12, 2023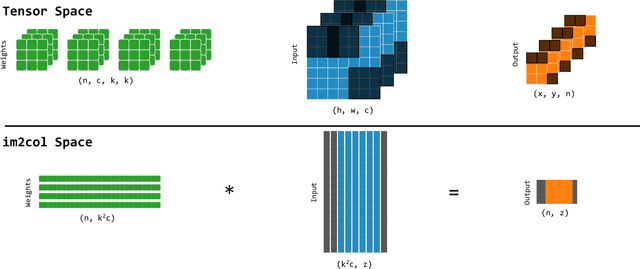
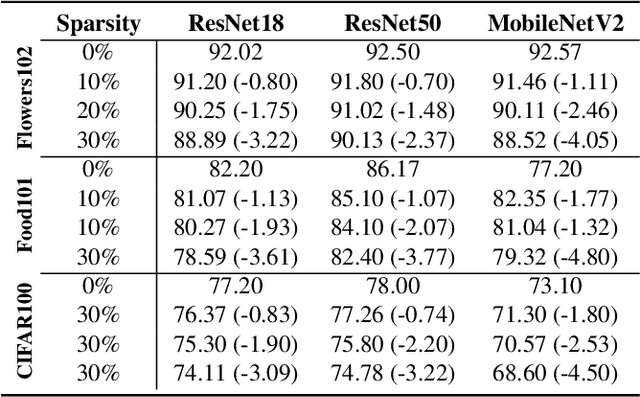
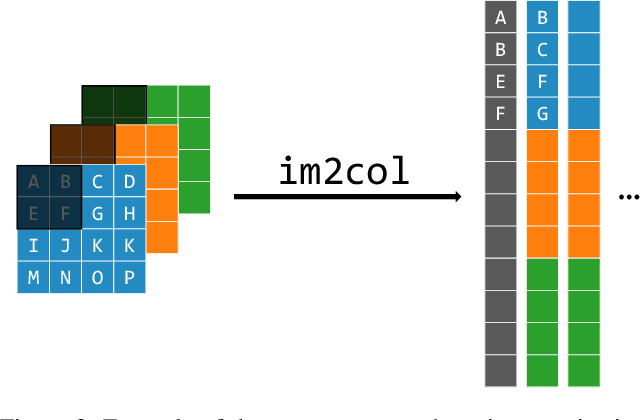
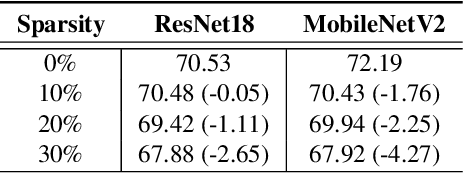
The demand for efficient processing of deep neural networks (DNNs) on embedded devices is a significant challenge limiting their deployment. Exploiting sparsity in the network's feature maps is one of the ways to reduce its inference latency. It is known that unstructured sparsity results in lower accuracy degradation with respect to structured sparsity but the former needs extensive inference engine changes to get latency benefits. To tackle this challenge, we propose a solution to induce semi-structured activation sparsity exploitable through minor runtime modifications. To attain high speedup levels at inference time, we design a sparse training procedure with awareness of the final position of the activations while computing the General Matrix Multiplication (GEMM). We extensively evaluate the proposed solution across various models for image classification and object detection tasks. Remarkably, our approach yields a speed improvement of $1.25 \times$ with a minimal accuracy drop of $1.1\%$ for the ResNet18 model on the ImageNet dataset. Furthermore, when combined with a state-of-the-art structured pruning method, the resulting models provide a good latency-accuracy trade-off, outperforming models that solely employ structured pruning techniques.
CloudBrain-NMR: An Intelligent Cloud Computing Platform for NMR Spectroscopy Processing, Reconstruction and Analysis
Sep 12, 2023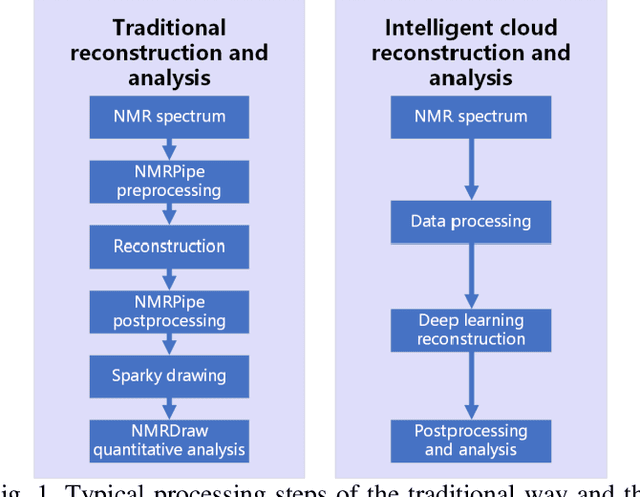
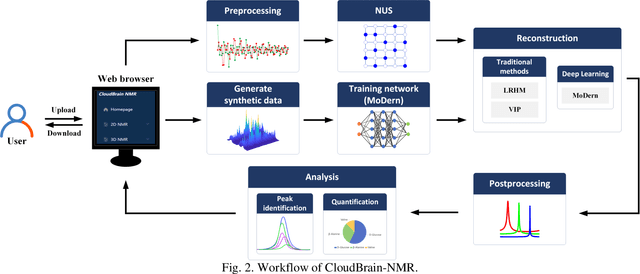
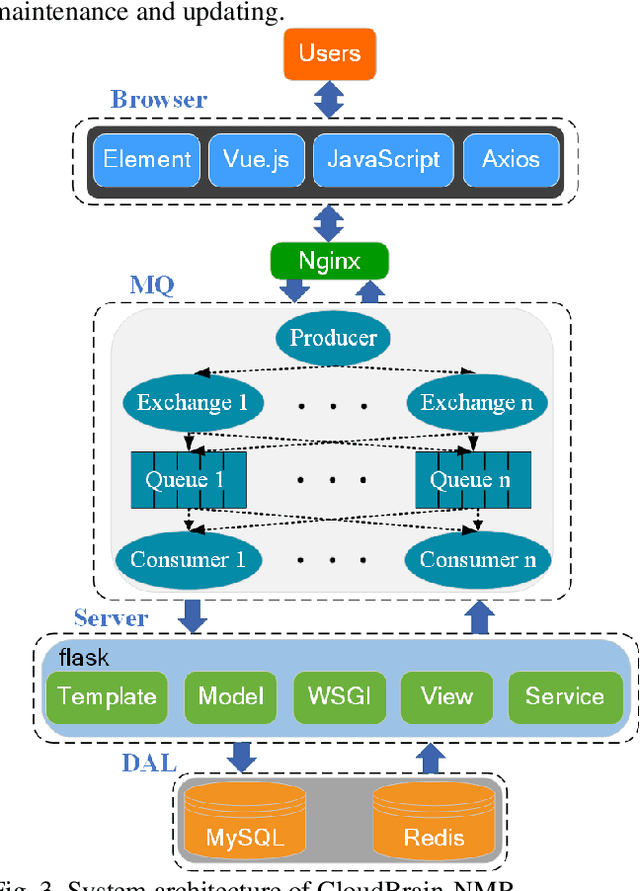
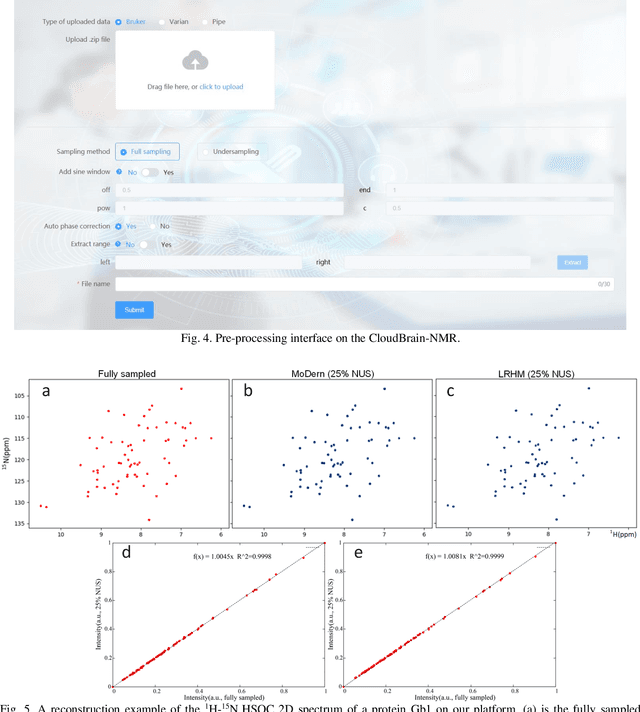
Nuclear Magnetic Resonance (NMR) spectroscopy has served as a powerful analytical tool for studying molecular structure and dynamics in chemistry and biology. However, the processing of raw data acquired from NMR spectrometers and subsequent quantitative analysis involves various specialized tools, which necessitates comprehensive knowledge in programming and NMR. Particularly, the emerging deep learning tools is hard to be widely used in NMR due to the sophisticated setup of computation. Thus, NMR processing is not an easy task for chemist and biologists. In this work, we present CloudBrain-NMR, an intelligent online cloud computing platform designed for NMR data reading, processing, reconstruction, and quantitative analysis. The platform is conveniently accessed through a web browser, eliminating the need for any program installation on the user side. CloudBrain-NMR uses parallel computing with graphics processing units and central processing units, resulting in significantly shortened computation time. Furthermore, it incorporates state-of-the-art deep learning-based algorithms offering comprehensive functionalities that allow users to complete the entire processing procedure without relying on additional software. This platform has empowered NMR applications with advanced artificial intelligence processing. CloudBrain-NMR is openly accessible for free usage at https://csrc.xmu.edu.cn/CloudBrain.html
BEA: Revisiting anchor-based object detection DNN using Budding Ensemble Architecture
Sep 14, 2023
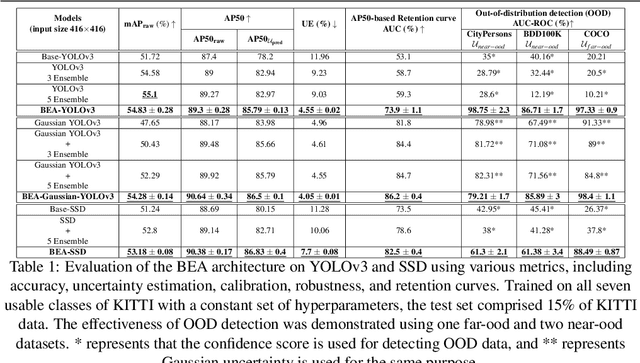
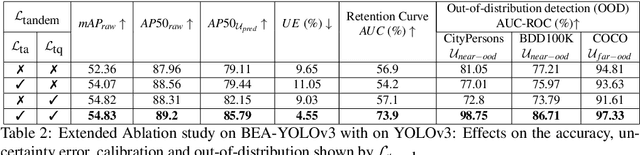
This paper introduces the Budding Ensemble Architecture (BEA), a novel reduced ensemble architecture for anchor-based object detection models. Object detection models are crucial in vision-based tasks, particularly in autonomous systems. They should provide precise bounding box detections while also calibrating their predicted confidence scores, leading to higher-quality uncertainty estimates. However, current models may make erroneous decisions due to false positives receiving high scores or true positives being discarded due to low scores. BEA aims to address these issues. The proposed loss functions in BEA improve the confidence score calibration and lower the uncertainty error, which results in a better distinction of true and false positives and, eventually, higher accuracy of the object detection models. Both Base-YOLOv3 and SSD models were enhanced using the BEA method and its proposed loss functions. The BEA on Base-YOLOv3 trained on the KITTI dataset results in a 6% and 3.7% increase in mAP and AP50, respectively. Utilizing a well-balanced uncertainty estimation threshold to discard samples in real-time even leads to a 9.6% higher AP50 than its base model. This is attributed to a 40% increase in the area under the AP50-based retention curve used to measure the quality of calibration of confidence scores. Furthermore, BEA-YOLOV3 trained on KITTI provides superior out-of-distribution detection on Citypersons, BDD100K, and COCO datasets compared to the ensembles and vanilla models of YOLOv3 and Gaussian-YOLOv3.
Heuristic Satisficing Inferential Decision Making in Human and Robot Active Perception
Sep 14, 2023
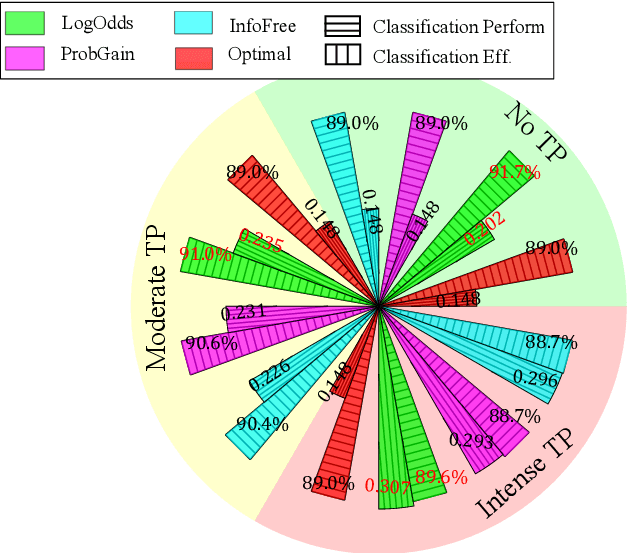
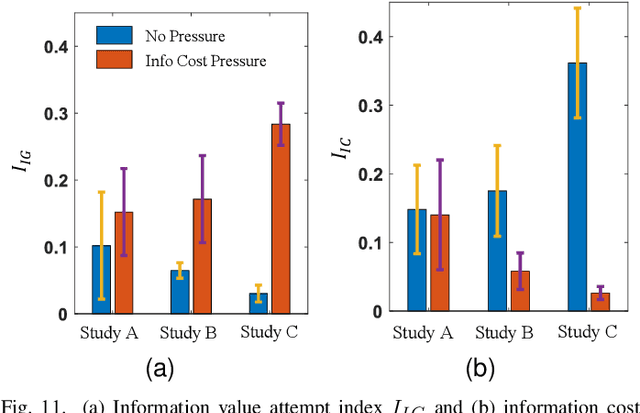
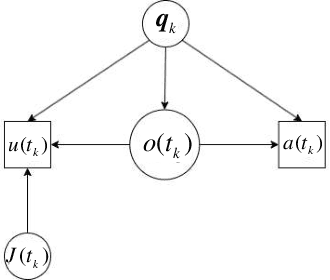
Inferential decision-making algorithms typically assume that an underlying probabilistic model of decision alternatives and outcomes may be learned a priori or online. Furthermore, when applied to robots in real-world settings they often perform unsatisfactorily or fail to accomplish the necessary tasks because this assumption is violated and/or they experience unanticipated external pressures and constraints. Cognitive studies presented in this and other papers show that humans cope with complex and unknown settings by modulating between near-optimal and satisficing solutions, including heuristics, by leveraging information value of available environmental cues that are possibly redundant. Using the benchmark inferential decision problem known as ``treasure hunt", this paper develops a general approach for investigating and modeling active perception solutions under pressure. By simulating treasure hunt problems in virtual worlds, our approach learns generalizable strategies from high performers that, when applied to robots, allow them to modulate between optimal and heuristic solutions on the basis of external pressures and probabilistic models, if and when available. The result is a suite of active perception algorithms for camera-equipped robots that outperform treasure-hunt solutions obtained via cell decomposition, information roadmap, and information potential algorithms, in both high-fidelity numerical simulations and physical experiments. The effectiveness of the new active perception strategies is demonstrated under a broad range of unanticipated conditions that cause existing algorithms to fail to complete the search for treasures, such as unmodelled time constraints, resource constraints, and adverse weather (fog).
Learning Hybrid Dynamics Models With Simulator-Informed Latent States
Sep 06, 2023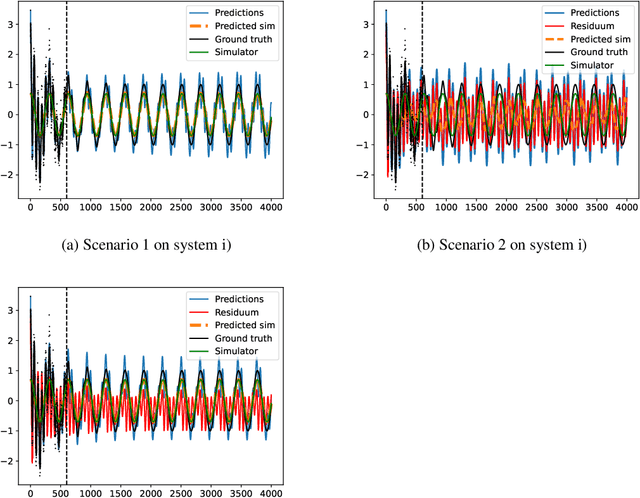
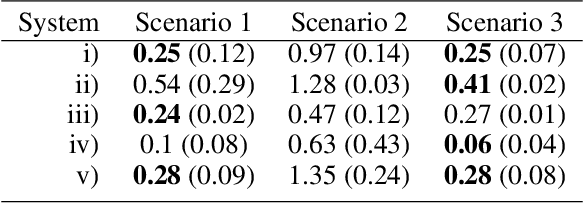
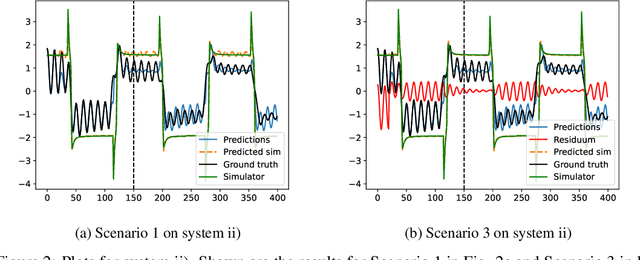

Dynamics model learning deals with the task of inferring unknown dynamics from measurement data and predicting the future behavior of the system. A typical approach to address this problem is to train recurrent models. However, predictions with these models are often not physically meaningful. Further, they suffer from deteriorated behavior over time due to accumulating errors. Often, simulators building on first principles are available being physically meaningful by design. However, modeling simplifications typically cause inaccuracies in these models. Consequently, hybrid modeling is an emerging trend that aims to combine the best of both worlds. In this paper, we propose a new approach to hybrid modeling, where we inform the latent states of a learned model via a black-box simulator. This allows to control the predictions via the simulator preventing them from accumulating errors. This is especially challenging since, in contrast to previous approaches, access to the simulator's latent states is not available. We tackle the task by leveraging observers, a well-known concept from control theory, inferring unknown latent states from observations and dynamics over time. In our learning-based setting, we jointly learn the dynamics and an observer that infers the latent states via the simulator. Thus, the simulator constantly corrects the latent states, compensating for modeling mismatch caused by learning. To maintain flexibility, we train an RNN-based residuum for the latent states that cannot be informed by the simulator.