 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Motion rejection and spectral unmixing for accurate estimation of in vivo oxygen saturation using multispectral optoacoustic tomography
Sep 15, 2023
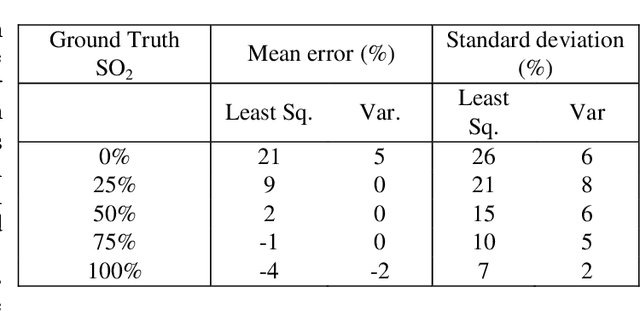
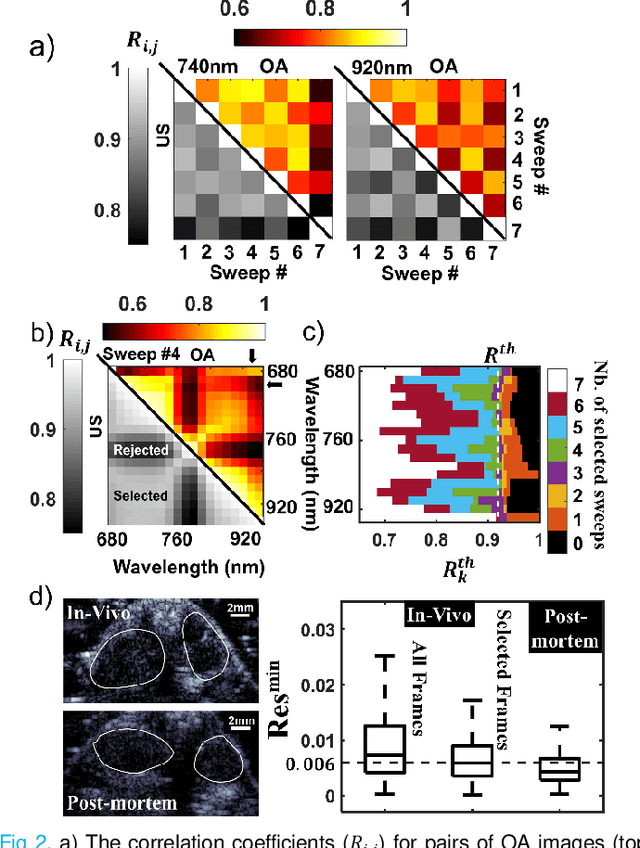

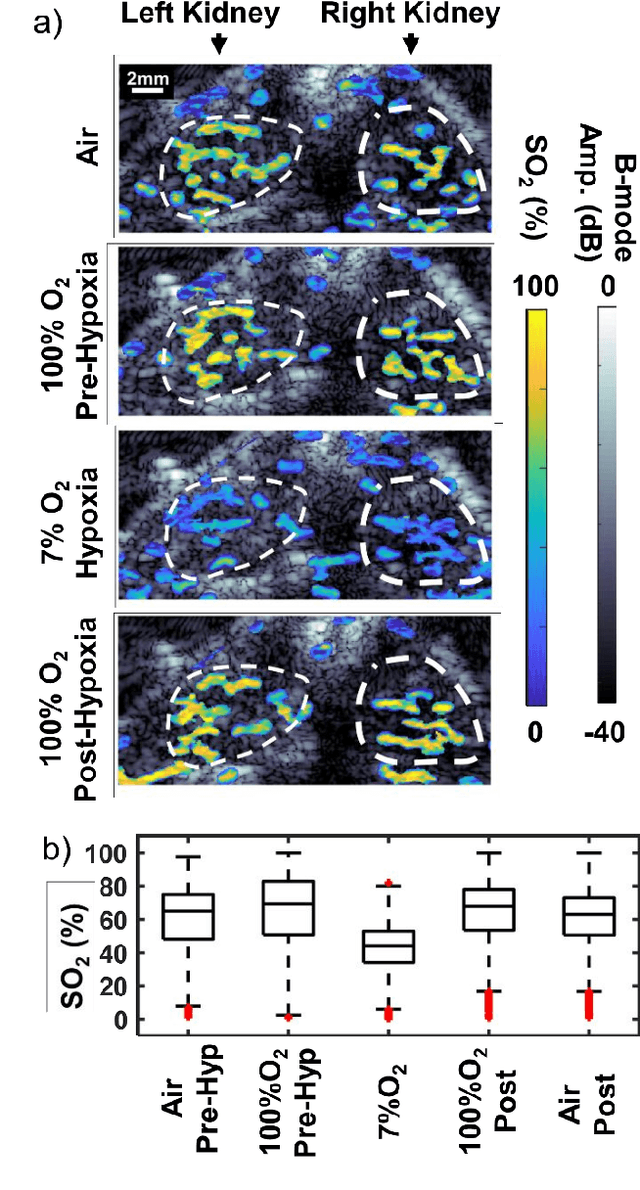
Multispectral Optoacoustic Tomography (MSOT) uniquely enables spatial mapping in high resolution of oxygen saturation (SO$_2$), with potential applications in studying pathological complications and therapy efficacy. MSOT offers seamless integration with ultrasonography, by using a common ultrasound detector array. However, MSOT relies on multiple successive acquisitions of optoacoustic (OA) images at different optical wavelengths and the low frame rate of OA imaging makes the MSOT acquisition sensitive to body/respiratory motion. Moreover, estimation of SO$_2$ is highly sensitive to noise, and artefacts related to the respiratory motion of the animal were identified as the primary source of noise in MSOT.In this work, we propose a two-step image processing method for SO$_2$ estimation in deep tissues. First, to mitigate motion artefacts, we propose a method of selection of OA images acquired only during the respiratory pause of the animal, using ultrafast ultrasound images (USIs) acquired immediately after each OA acquisition (USI acquisition duration of 1.4 ms and a total delay of 7 ms). We show that gating is more effective using USIs than OA images at different optical wavelengths. Secondly, we propose a novel method which can estimate directly the SO$_2$ value of a pixel and at the same time evaluate the amount of noise present in that pixel. Hence, the method can efficiently eliminate the pixels dominated by noise from the final SO$_2$ map. Our post-processing method is shown to outperform conventional methods for SO$_2$ estimation, and the method was validated by in vivo oxygen challenge experiments.
UIVNAV: Underwater Information-driven Vision-based Navigation via Imitation Learning
Sep 15, 2023
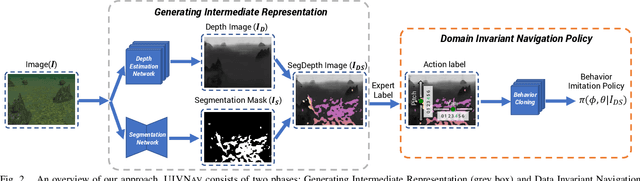
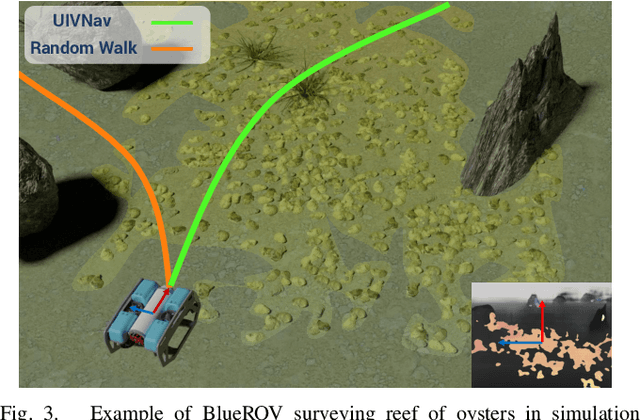

Autonomous navigation in the underwater environment is challenging due to limited visibility, dynamic changes, and the lack of a cost-efficient accurate localization system. We introduce UIVNav, a novel end-to-end underwater navigation solution designed to drive robots over Objects of Interest (OOI) while avoiding obstacles, without relying on localization. UIVNav uses imitation learning and is inspired by the navigation strategies used by human divers who do not rely on localization. UIVNav consists of the following phases: (1) generating an intermediate representation (IR), and (2) training the navigation policy based on human-labeled IR. By training the navigation policy on IR instead of raw data, the second phase is domain-invariant -- the navigation policy does not need to be retrained if the domain or the OOI changes. We show this by deploying the same navigation policy for surveying two different OOIs, oyster and rock reefs, in two different domains, simulation, and a real pool. We compared our method with complete coverage and random walk methods which showed that our method is more efficient in gathering information for OOIs while also avoiding obstacles. The results show that UIVNav chooses to visit the areas with larger area sizes of oysters or rocks with no prior information about the environment or localization. Moreover, a robot using UIVNav compared to complete coverage method surveys on average 36% more oysters when traveling the same distances. We also demonstrate the feasibility of real-time deployment of UIVNavin pool experiments with BlueROV underwater robot for surveying a bed of oyster shells.
Online Distributed Learning with Quantized Finite-Time Coordination
Jul 13, 2023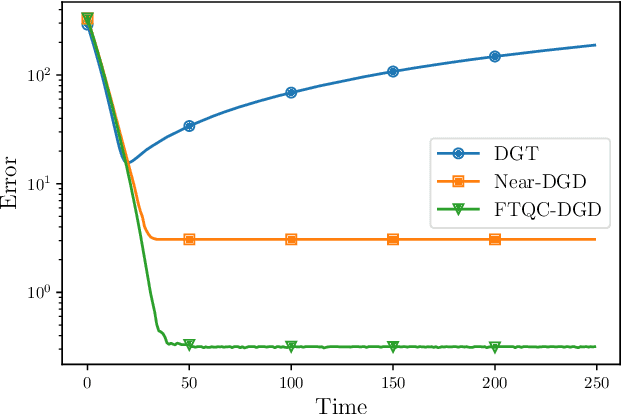
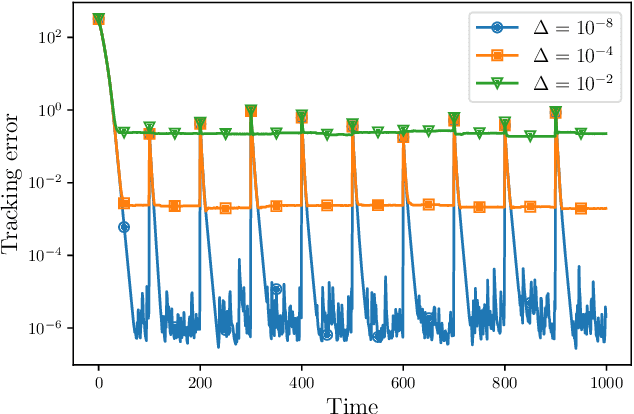
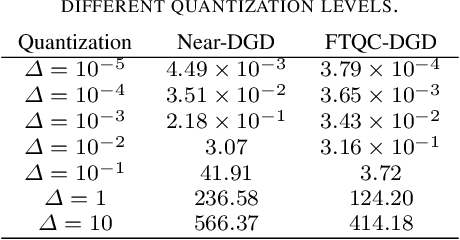

In this paper we consider online distributed learning problems. Online distributed learning refers to the process of training learning models on distributed data sources. In our setting a set of agents need to cooperatively train a learning model from streaming data. Differently from federated learning, the proposed approach does not rely on a central server but only on peer-to-peer communications among the agents. This approach is often used in scenarios where data cannot be moved to a centralized location due to privacy, security, or cost reasons. In order to overcome the absence of a central server, we propose a distributed algorithm that relies on a quantized, finite-time coordination protocol to aggregate the locally trained models. Furthermore, our algorithm allows for the use of stochastic gradients during local training. Stochastic gradients are computed using a randomly sampled subset of the local training data, which makes the proposed algorithm more efficient and scalable than traditional gradient descent. In our paper, we analyze the performance of the proposed algorithm in terms of the mean distance from the online solution. Finally, we present numerical results for a logistic regression task.
Staged Contact-Aware Global Human Motion Forecasting
Sep 16, 2023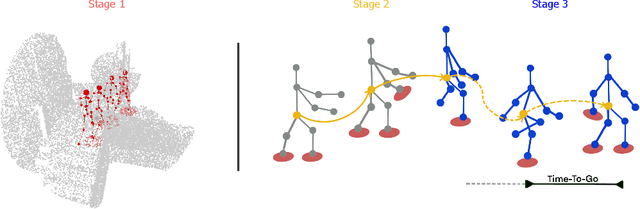

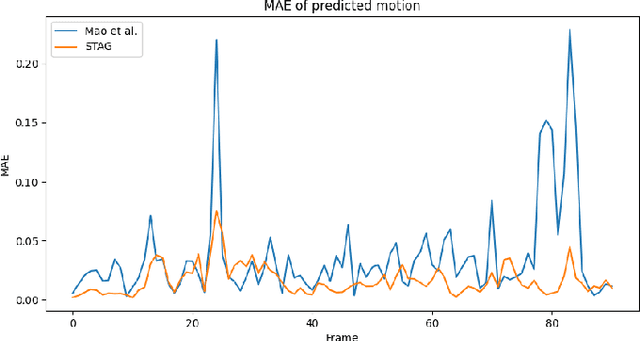

Scene-aware global human motion forecasting is critical for manifold applications, including virtual reality, robotics, and sports. The task combines human trajectory and pose forecasting within the provided scene context, which represents a significant challenge. So far, only Mao et al. NeurIPS'22 have addressed scene-aware global motion, cascading the prediction of future scene contact points and the global motion estimation. They perform the latter as the end-to-end forecasting of future trajectories and poses. However, end-to-end contrasts with the coarse-to-fine nature of the task and it results in lower performance, as we demonstrate here empirically. We propose a STAGed contact-aware global human motion forecasting STAG, a novel three-stage pipeline for predicting global human motion in a 3D environment. We first consider the scene and the respective human interaction as contact points. Secondly, we model the human trajectory forecasting within the scene, predicting the coarse motion of the human body as a whole. The third and last stage matches a plausible fine human joint motion to complement the trajectory considering the estimated contacts. Compared to the state-of-the-art (SoA), STAG achieves a 1.8% and 16.2% overall improvement in pose and trajectory prediction, respectively, on the scene-aware GTA-IM dataset. A comprehensive ablation study confirms the advantages of staged modeling over end-to-end approaches. Furthermore, we establish the significance of a newly proposed temporal counter called the "time-to-go", which tells how long it is before reaching scene contact and endpoints. Notably, STAG showcases its ability to generalize to datasets lacking a scene and achieves a new state-of-the-art performance on CMU-Mocap, without leveraging any social cues. Our code is released at: https://github.com/L-Scofano/STAG
A Robust SINDy Approach by Combining Neural Networks and an Integral Form
Sep 13, 2023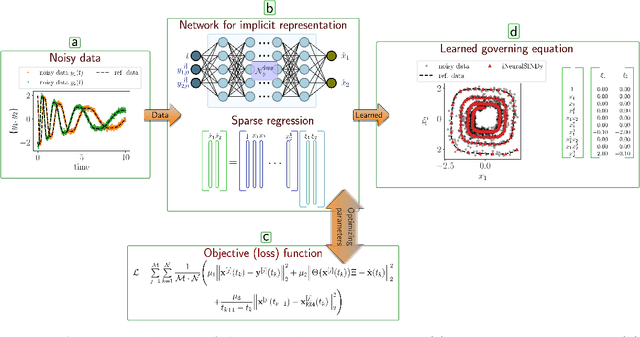
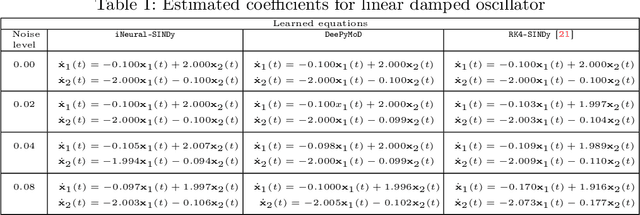
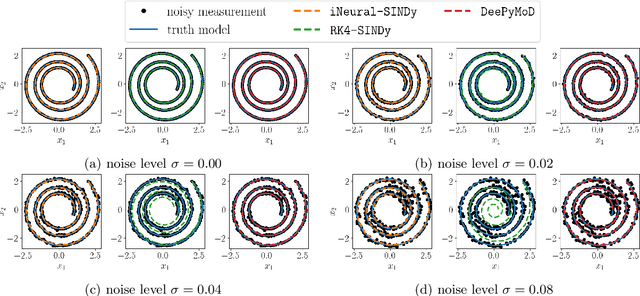
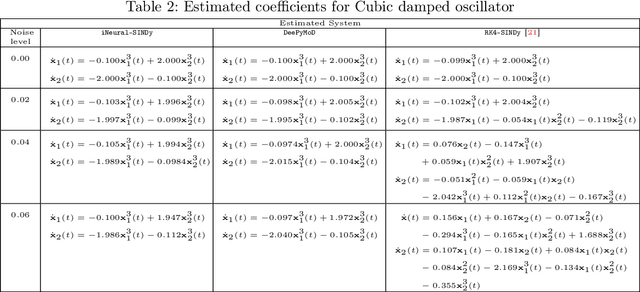
The discovery of governing equations from data has been an active field of research for decades. One widely used methodology for this purpose is sparse regression for nonlinear dynamics, known as SINDy. Despite several attempts, noisy and scarce data still pose a severe challenge to the success of the SINDy approach. In this work, we discuss a robust method to discover nonlinear governing equations from noisy and scarce data. To do this, we make use of neural networks to learn an implicit representation based on measurement data so that not only it produces the output in the vicinity of the measurements but also the time-evolution of output can be described by a dynamical system. Additionally, we learn such a dynamic system in the spirit of the SINDy framework. Leveraging the implicit representation using neural networks, we obtain the derivative information -- required for SINDy -- using an automatic differentiation tool. To enhance the robustness of our methodology, we further incorporate an integral condition on the output of the implicit networks. Furthermore, we extend our methodology to handle data collected from multiple initial conditions. We demonstrate the efficiency of the proposed methodology to discover governing equations under noisy and scarce data regimes by means of several examples and compare its performance with existing methods.
VEATIC: Video-based Emotion and Affect Tracking in Context Dataset
Sep 13, 2023
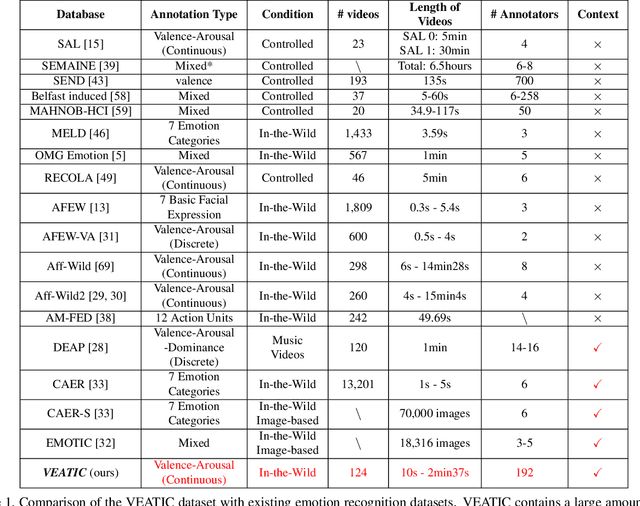

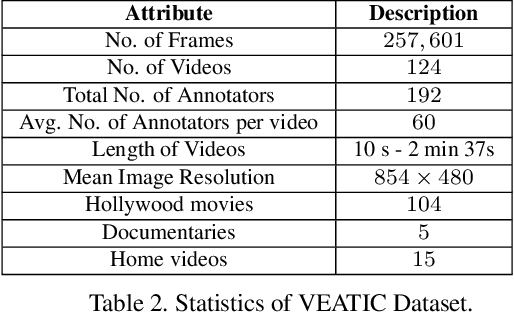
Human affect recognition has been a significant topic in psychophysics and computer vision. However, the currently published datasets have many limitations. For example, most datasets contain frames that contain only information about facial expressions. Due to the limitations of previous datasets, it is very hard to either understand the mechanisms for affect recognition of humans or generalize well on common cases for computer vision models trained on those datasets. In this work, we introduce a brand new large dataset, the Video-based Emotion and Affect Tracking in Context Dataset (VEATIC), that can conquer the limitations of the previous datasets. VEATIC has 124 video clips from Hollywood movies, documentaries, and home videos with continuous valence and arousal ratings of each frame via real-time annotation. Along with the dataset, we propose a new computer vision task to infer the affect of the selected character via both context and character information in each video frame. Additionally, we propose a simple model to benchmark this new computer vision task. We also compare the performance of the pretrained model using our dataset with other similar datasets. Experiments show the competing results of our pretrained model via VEATIC, indicating the generalizability of VEATIC. Our dataset is available at https://veatic.github.io.
Topology-inspired Cross-domain Network for Developmental Cervical Stenosis Quantification
Sep 13, 2023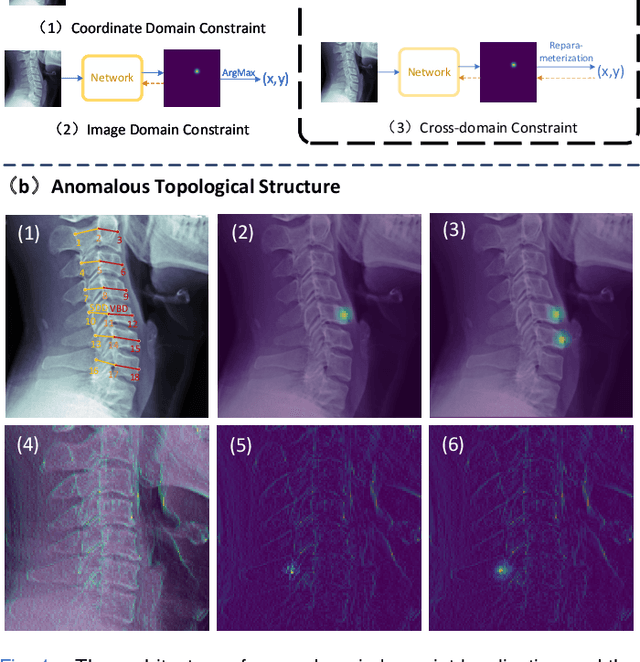
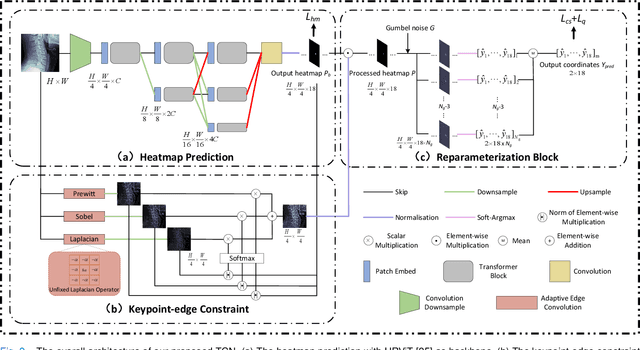
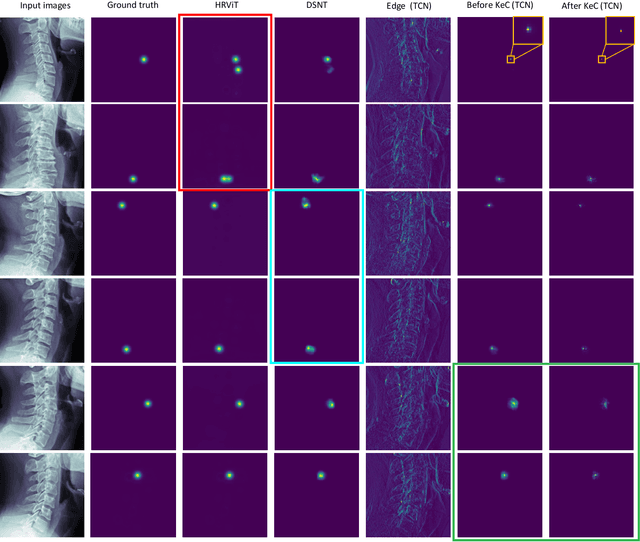
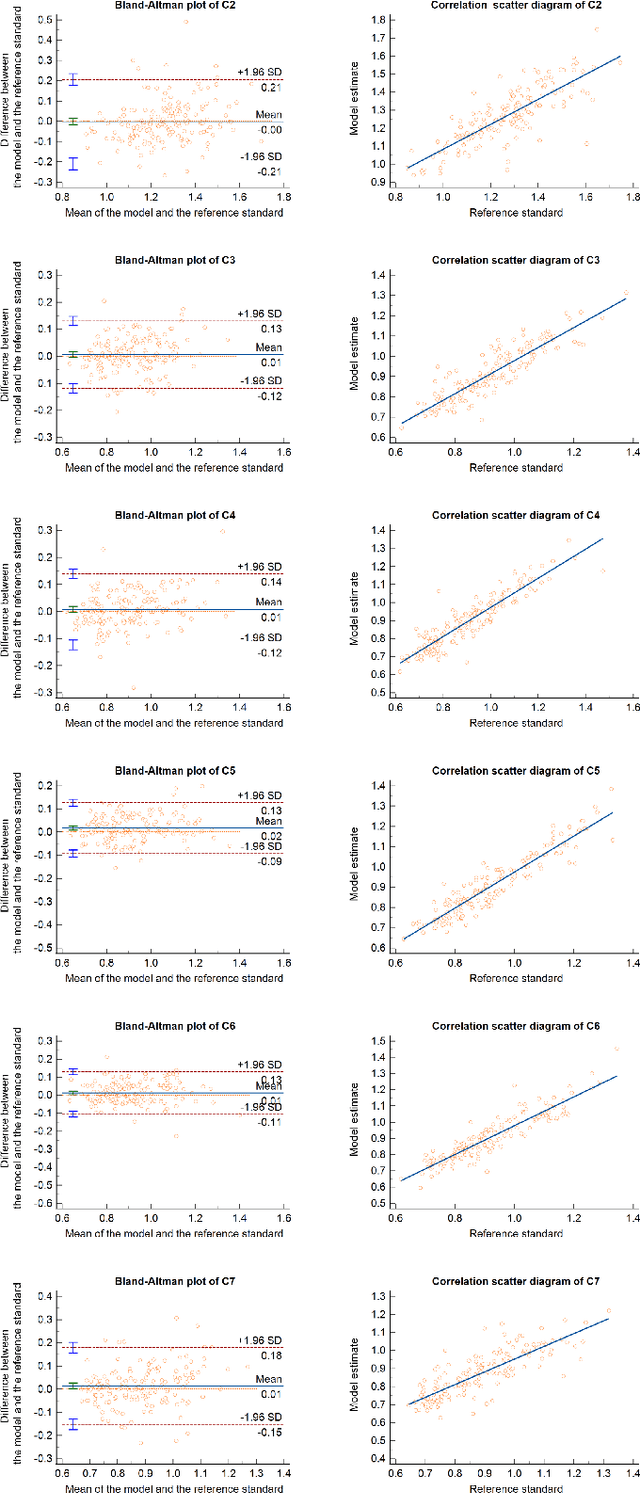
Developmental Canal Stenosis (DCS) quantification is crucial in cervical spondylosis screening. Compared with quantifying DCS manually, a more efficient and time-saving manner is provided by deep keypoint localization networks, which can be implemented in either the coordinate or the image domain. However, the vertebral visualization features often lead to abnormal topological structures during keypoint localization, including keypoint distortion with edges and weakly connected structures, which cannot be fully suppressed in either the coordinate or image domain alone. To overcome this limitation, a keypoint-edge and a reparameterization modules are utilized to restrict these abnormal structures in a cross-domain manner. The keypoint-edge constraint module restricts the keypoints on the edges of vertebrae, which ensures that the distribution pattern of keypoint coordinates is consistent with those for DCS quantification. And the reparameterization module constrains the weakly connected structures in image-domain heatmaps with coordinates combined. Moreover, the cross-domain network improves spatial generalization by utilizing heatmaps and incorporating coordinates for accurate localization, which avoids the trade-off between these two properties in an individual domain. Comprehensive results of distinct quantification tasks show the superiority and generability of the proposed Topology-inspired Cross-domain Network (TCN) compared with other competing localization methods.
Leveraging Foundation models for Unsupervised Audio-Visual Segmentation
Sep 13, 2023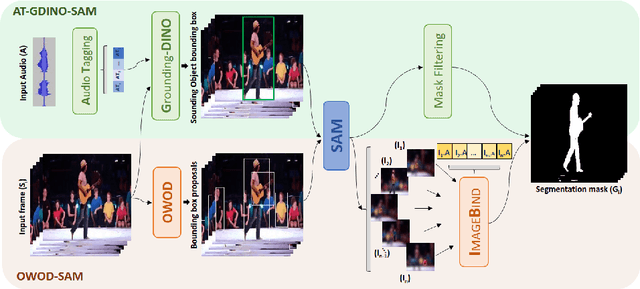
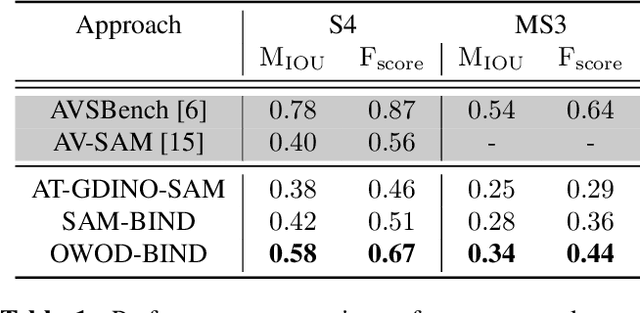

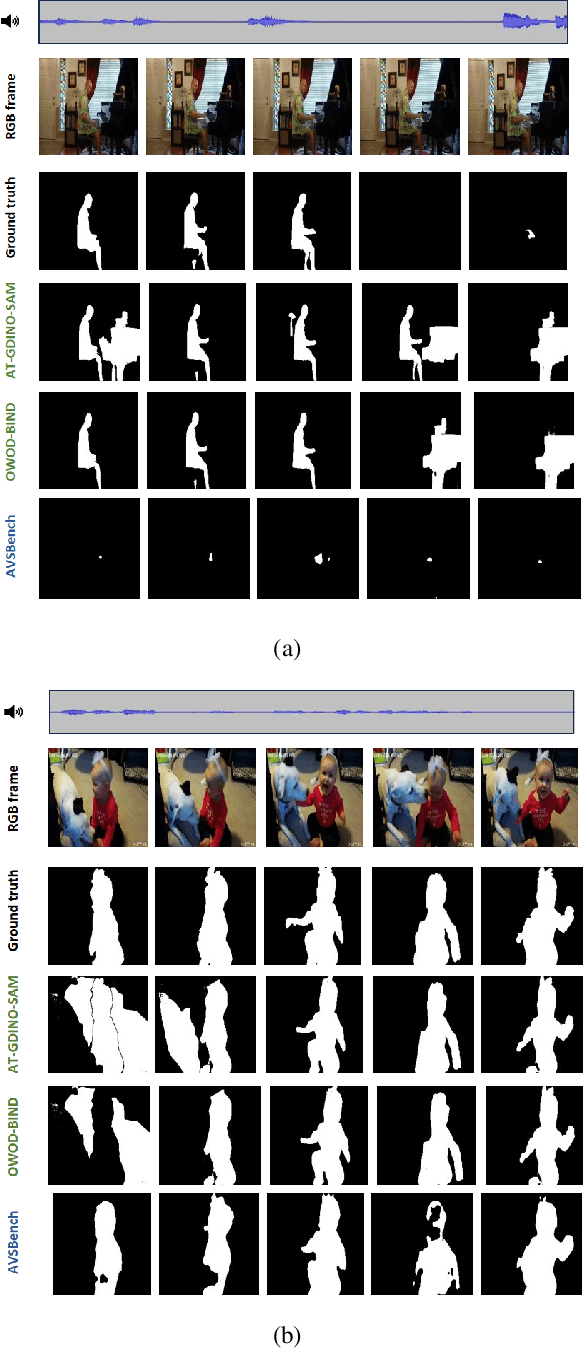
Audio-Visual Segmentation (AVS) aims to precisely outline audible objects in a visual scene at the pixel level. Existing AVS methods require fine-grained annotations of audio-mask pairs in supervised learning fashion. This limits their scalability since it is time consuming and tedious to acquire such cross-modality pixel level labels. To overcome this obstacle, in this work we introduce unsupervised audio-visual segmentation with no need for task-specific data annotations and model training. For tackling this newly proposed problem, we formulate a novel Cross-Modality Semantic Filtering (CMSF) approach to accurately associate the underlying audio-mask pairs by leveraging the off-the-shelf multi-modal foundation models (e.g., detection [1], open-world segmentation [2] and multi-modal alignment [3]). Guiding the proposal generation by either audio or visual cues, we design two training-free variants: AT-GDINO-SAM and OWOD-BIND. Extensive experiments on the AVS-Bench dataset show that our unsupervised approach can perform well in comparison to prior art supervised counterparts across complex scenarios with multiple auditory objects. Particularly, in situations where existing supervised AVS methods struggle with overlapping foreground objects, our models still excel in accurately segmenting overlapped auditory objects. Our code will be publicly released.
Enhancing Child Vocalization Classification in Multi-Channel Child-Adult Conversations Through Wav2vec2 Children ASR Features
Sep 13, 2023Autism Spectrum Disorder (ASD) is a neurodevelopmental disorder that often emerges in early childhood. ASD assessment typically involves an observation protocol including note-taking and ratings of child's social behavior conducted by a trained clinician. A robust machine learning (ML) model that is capable of labeling adult and child audio has the potential to save significant time and labor in manual coding children's behaviors. This may assist clinicians capture events of interest, better communicate events with parents, and educate new clinicians. In this study, we leverage the self-supervised learning model, Wav2Vec 2.0 (W2V2), pretrained on 4300h of home recordings of children under 5 years old, to build a unified system that performs both speaker diarization (SD) and vocalization classification (VC) tasks. We apply this system to two-channel audio recordings of brief 3-5 minute clinician-child interactions using the Rapid-ABC corpus. We propose a novel technique by introducing auxiliary features extracted from W2V2-based automatic speech recognition (ASR) system for children under 4 years old to improve children's VC task. We test our proposed method of improving children's VC task on two corpora (Rapid-ABC and BabbleCor) and observe consistent improvements. Furthermore, we reach, or perhaps outperform, the state-of-the-art performance of BabbleCor.
PhantomSound: Black-Box, Query-Efficient Audio Adversarial Attack via Split-Second Phoneme Injection
Sep 13, 2023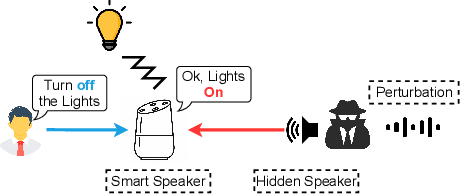
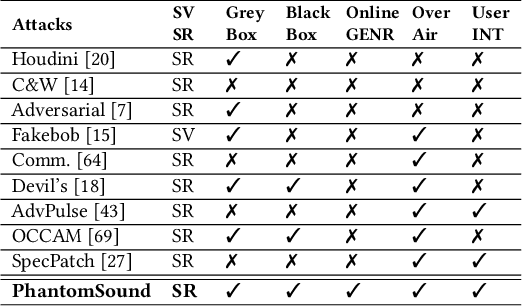
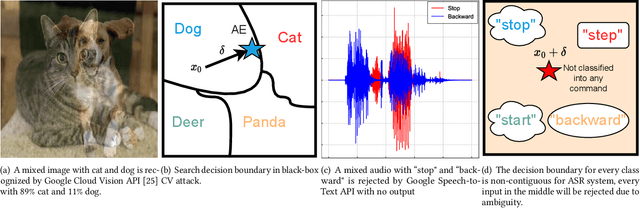

In this paper, we propose PhantomSound, a query-efficient black-box attack toward voice assistants. Existing black-box adversarial attacks on voice assistants either apply substitution models or leverage the intermediate model output to estimate the gradients for crafting adversarial audio samples. However, these attack approaches require a significant amount of queries with a lengthy training stage. PhantomSound leverages the decision-based attack to produce effective adversarial audios, and reduces the number of queries by optimizing the gradient estimation. In the experiments, we perform our attack against 4 different speech-to-text APIs under 3 real-world scenarios to demonstrate the real-time attack impact. The results show that PhantomSound is practical and robust in attacking 5 popular commercial voice controllable devices over the air, and is able to bypass 3 liveness detection mechanisms with >95% success rate. The benchmark result shows that PhantomSound can generate adversarial examples and launch the attack in a few minutes. We significantly enhance the query efficiency and reduce the cost of a successful untargeted and targeted adversarial attack by 93.1% and 65.5% compared with the state-of-the-art black-box attacks, using merely ~300 queries (~5 minutes) and ~1,500 queries (~25 minutes), respectively.