 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Secure Degree of Freedom of Wireless Networks Using Collaborative Pilots
Sep 21, 2023
A wireless network of full-duplex nodes/users, using anti-eavesdropping channel estimation (ANECE) based on collaborative pilots, can yield a positive secure degree-of-freedom (SDoF) regardless of the number of antennas an eavesdropper may have. This paper presents novel results on SDoF of ANECE by analyzing secret-key capacity (SKC) of each pair of nodes in a network of multiple collaborative nodes per channel coherence period. Each transmission session of ANECE has two phases: phase 1 is used for pilots, and phase 2 is used for random symbols. This results in two parts of SDoF of ANECE. Both lower and upper bounds on the SDoF of ANECE for any number of users are shown, and the conditions for the two bounds to meet are given. This leads to important discoveries, including: a) The phase-1 SDoF is the same for both multi-user ANECE and pair-wise ANECE while the former may require only a fraction of the number of time slots needed by the latter; b) For a three-user network, the phase-2 SDoF of all-user ANECE is generally larger than that of pair-wise ANECE; c) For a two-user network, a modified ANECE deploying square-shaped nonsingular pilot matrices yields a higher total SDoF than the original ANECE. The multi-user ANECE and the modified two-user ANECE shown in this paper appear to be the best full-duplex schemes known today in terms of SDoF subject to each node using a given number of antennas for both transmitting and receiving.
Stock Market Sentiment Classification and Backtesting via Fine-tuned BERT
Sep 21, 2023With the rapid development of big data and computing devices, low-latency automatic trading platforms based on real-time information acquisition have become the main components of the stock trading market, so the topic of quantitative trading has received widespread attention. And for non-strongly efficient trading markets, human emotions and expectations always dominate market trends and trading decisions. Therefore, this paper starts from the theory of emotion, taking East Money as an example, crawling user comment titles data from its corresponding stock bar and performing data cleaning. Subsequently, a natural language processing model BERT was constructed, and the BERT model was fine-tuned using existing annotated data sets. The experimental results show that the fine-tuned model has different degrees of performance improvement compared to the original model and the baseline model. Subsequently, based on the above model, the user comment data crawled is labeled with emotional polarity, and the obtained label information is combined with the Alpha191 model to participate in regression, and significant regression results are obtained. Subsequently, the regression model is used to predict the average price change for the next five days, and use it as a signal to guide automatic trading. The experimental results show that the incorporation of emotional factors increased the return rate by 73.8\% compared to the baseline during the trading period, and by 32.41\% compared to the original alpha191 model. Finally, we discuss the advantages and disadvantages of incorporating emotional factors into quantitative trading, and give possible directions for further research in the future.
Deep learning probability flows and entropy production rates in active matter
Sep 22, 2023Active matter systems, from self-propelled colloids to motile bacteria, are characterized by the conversion of free energy into useful work at the microscopic scale. These systems generically involve physics beyond the reach of equilibrium statistical mechanics, and a persistent challenge has been to understand the nature of their nonequilibrium states. The entropy production rate and the magnitude of the steady-state probability current provide quantitative ways to do so by measuring the breakdown of time-reversal symmetry and the strength of nonequilibrium transport of measure. Yet, their efficient computation has remained elusive, as they depend on the system's unknown and high-dimensional probability density. Here, building upon recent advances in generative modeling, we develop a deep learning framework that estimates the score of this density. We show that the score, together with the microscopic equations of motion, gives direct access to the entropy production rate, the probability current, and their decomposition into local contributions from individual particles, spatial regions, and degrees of freedom. To represent the score, we introduce a novel, spatially-local transformer-based network architecture that learns high-order interactions between particles while respecting their underlying permutation symmetry. We demonstrate the broad utility and scalability of the method by applying it to several high-dimensional systems of interacting active particles undergoing motility-induced phase separation (MIPS). We show that a single instance of our network trained on a system of 4096 particles at one packing fraction can generalize to other regions of the phase diagram, including systems with as many as 32768 particles. We use this observation to quantify the spatial structure of the departure from equilibrium in MIPS as a function of the number of particles and the packing fraction.
From Text to Trends: A Unique Garden Analytics Perspective on the Future of Modern Agriculture
Sep 22, 2023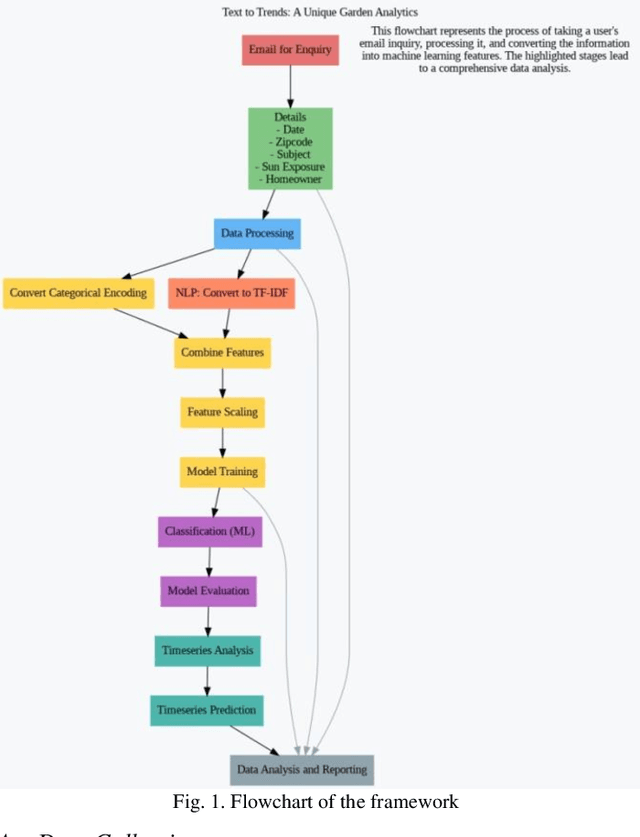
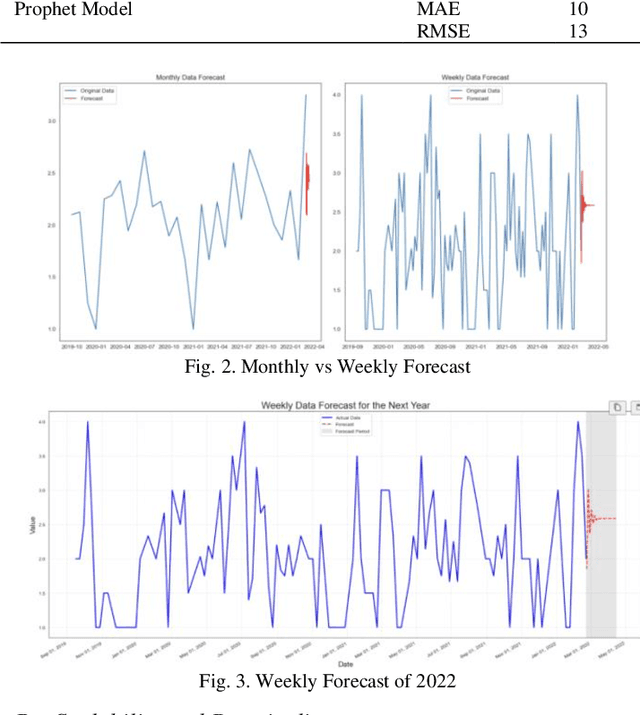

Data-driven insights are essential for modern agriculture. This research paper introduces a machine learning framework designed to improve how we educate and reach out to people in the field of horticulture. The framework relies on data from the Horticulture Online Help Desk (HOHD), which is like a big collection of questions from people who love gardening and are part of the Extension Master Gardener Program (EMGP). This framework has two main parts. First, it uses special computer programs (machine learning models) to sort questions into categories. This helps us quickly send each question to the right expert, so we can answer it faster. Second, it looks at when questions are asked and uses that information to guess how many questions we might get in the future and what they will be about. This helps us plan on topics that will be really important. It's like knowing what questions will be popular in the coming months. We also take into account where the questions come from by looking at the Zip Code. This helps us make research that fits the challenges faced by gardeners in different places. In this paper, we demonstrate the potential of machine learning techniques to predict trends in horticulture by analyzing textual queries from homeowners. We show that NLP, classification, and time series analysis can be used to identify patterns in homeowners' queries and predict future trends in horticulture. Our results suggest that machine learning could be used to predict trends in other agricultural sectors as well. If large-scale agriculture industries curate and maintain a comparable repository of textual data, the potential for trend prediction and strategic agricultural planning could be revolutionized. This convergence of technology and agriculture offers a promising pathway for the future of sustainable farming and data-informed agricultural practices
A Machine Vision Method for Correction of Eccentric Error: Based on Adaptive Enhancement Algorithm
Sep 01, 2023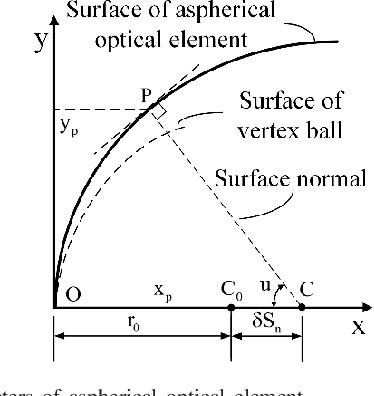

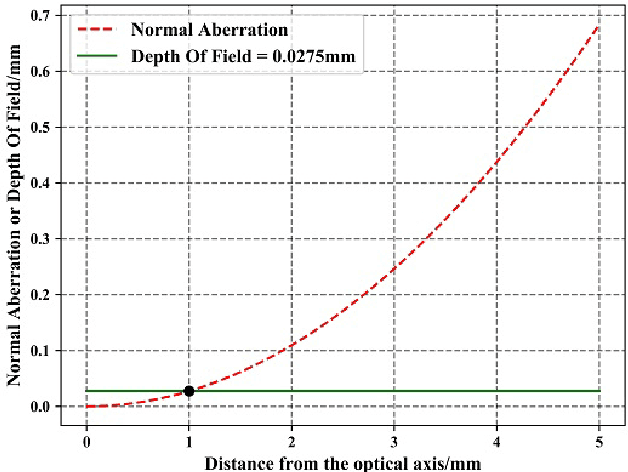

In the procedure of surface defects detection for large-aperture aspherical optical elements, it is of vital significance to adjust the optical axis of the element to be coaxial with the mechanical spin axis accurately. Therefore, a machine vision method for eccentric error correction is proposed in this paper. Focusing on the severe defocus blur of reference crosshair image caused by the imaging characteristic of the aspherical optical element, which may lead to the failure of correction, an Adaptive Enhancement Algorithm (AEA) is proposed to strengthen the crosshair image. AEA is consisted of existed Guided Filter Dark Channel Dehazing Algorithm (GFA) and proposed lightweight Multi-scale Densely Connected Network (MDC-Net). The enhancement effect of GFA is excellent but time-consuming, and the enhancement effect of MDC-Net is slightly inferior but strongly real-time. As AEA will be executed dozens of times during each correction procedure, its real-time performance is very important. Therefore, by setting the empirical threshold of definition evaluation function SMD2, GFA and MDC-Net are respectively applied to highly and slightly blurred crosshair images so as to ensure the enhancement effect while saving as much time as possible. AEA has certain robustness in time-consuming performance, which takes an average time of 0.2721s and 0.0963s to execute GFA and MDC-Net separately on ten 200pixels 200pixels Region of Interest (ROI) images with different degrees of blur. And the eccentricity error can be reduced to within 10um by our method.
Forgedit: Text Guided Image Editing via Learning and Forgetting
Sep 19, 2023Text guided image editing on real images given only the image and the target text prompt as inputs, is a very general and challenging problem, which requires the editing model to reason by itself which part of the image should be edited, to preserve the characteristics of original image, and also to perform complicated non-rigid editing. Previous fine-tuning based solutions are time-consuming and vulnerable to overfitting, limiting their editing capabilities. To tackle these issues, we design a novel text guided image editing method, Forgedit. First, we propose a novel fine-tuning framework which learns to reconstruct the given image in less than one minute by vision language joint learning. Then we introduce vector subtraction and vector projection to explore the proper text embedding for editing. We also find a general property of UNet structures in Diffusion Models and inspired by such a finding, we design forgetting strategies to diminish the fatal overfitting issues and significantly boost the editing abilities of Diffusion Models. Our method, Forgedit, implemented with Stable Diffusion, achieves new state-of-the-art results on the challenging text guided image editing benchmark TEdBench, surpassing the previous SOTA method Imagic with Imagen, in terms of both CLIP score and LPIPS score. Codes are available at https://github.com/witcherofresearch/Forgedit.
Decentralized Online Learning in Task Assignment Games for Mobile Crowdsensing
Sep 19, 2023The problem of coordinated data collection is studied for a mobile crowdsensing (MCS) system. A mobile crowdsensing platform (MCSP) sequentially publishes sensing tasks to the available mobile units (MUs) that signal their willingness to participate in a task by sending sensing offers back to the MCSP. From the received offers, the MCSP decides the task assignment. A stable task assignment must address two challenges: the MCSP's and MUs' conflicting goals, and the uncertainty about the MUs' required efforts and preferences. To overcome these challenges a novel decentralized approach combining matching theory and online learning, called collision-avoidance multi-armed bandit with strategic free sensing (CA-MAB-SFS), is proposed. The task assignment problem is modeled as a matching game considering the MCSP's and MUs' individual goals while the MUs learn their efforts online. Our innovative "free-sensing" mechanism significantly improves the MU's learning process while reducing collisions during task allocation. The stable regret of CA-MAB-SFS, i.e., the loss of learning, is analytically shown to be bounded by a sublinear function, ensuring the convergence to a stable optimal solution. Simulation results show that CA-MAB-SFS increases the MUs' and the MCSP's satisfaction compared to state-of-the-art methods while reducing the average task completion time by at least 16%.
PoSE: Efficient Context Window Extension of LLMs via Positional Skip-wise Training
Sep 19, 2023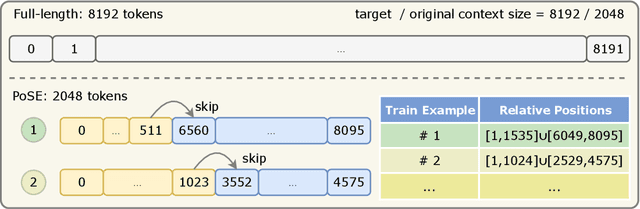
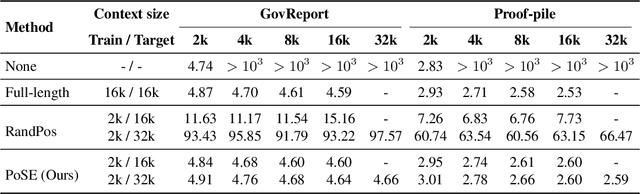
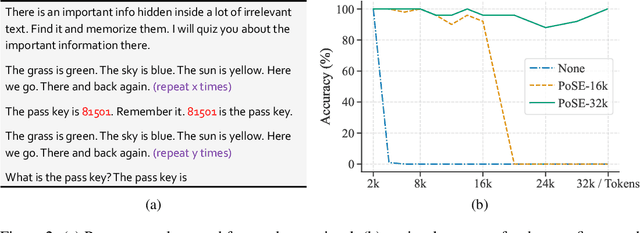
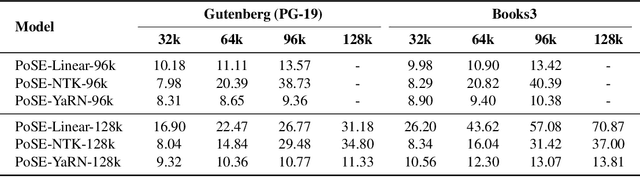
In this paper, we introduce Positional Skip-wisE (PoSE) training for efficient adaptation of large language models~(LLMs) to extremely long context windows. PoSE decouples train length from target context window size by simulating long inputs using a fixed context window with manipulated position indices during training. Concretely, we select several short chunks from a long input sequence, and introduce distinct skipping bias terms to modify the position indices of each chunk. These bias terms, along with the length of each chunk, are altered for each training example, allowing the model to adapt to all positions within the target context window without training on full length inputs. Experiments show that, compared with fine-tuning on the full length, PoSE greatly reduces memory and time overhead with minimal impact on performance. Leveraging this advantage, we have successfully extended the LLaMA model to 128k tokens. Furthermore, we empirically confirm that PoSE is compatible with all RoPE-based LLMs and various position interpolation strategies. Notably, by decoupling fine-tuning length from target context window, PoSE can theoretically extend the context window infinitely, constrained only by memory usage for inference. With ongoing advancements for efficient inference, we believe PoSE holds great promise for scaling the context window even further.
Learning based 2D Irregular Shape Packing
Sep 19, 20232D irregular shape packing is a necessary step to arrange UV patches of a 3D model within a texture atlas for memory-efficient appearance rendering in computer graphics. Being a joint, combinatorial decision-making problem involving all patch positions and orientations, this problem has well-known NP-hard complexity. Prior solutions either assume a heuristic packing order or modify the upstream mesh cut and UV mapping to simplify the problem, which either limits the packing ratio or incurs robustness or generality issues. Instead, we introduce a learning-assisted 2D irregular shape packing method that achieves a high packing quality with minimal requirements from the input. Our method iteratively selects and groups subsets of UV patches into near-rectangular super patches, essentially reducing the problem to bin-packing, based on which a joint optimization is employed to further improve the packing ratio. In order to efficiently deal with large problem instances with hundreds of patches, we train deep neural policies to predict nearly rectangular patch subsets and determine their relative poses, leading to linear time scaling with the number of patches. We demonstrate the effectiveness of our method on three datasets for UV packing, where our method achieves a higher packing ratio over several widely used baselines with competitive computational speed.
Crowdotic: Transformer-based Occupancy Estimation for Hospital Waiting Rooms with Non-speech Audio and Differential Privacy
Sep 19, 2023

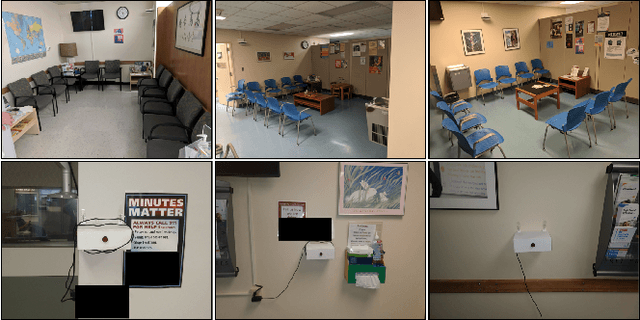
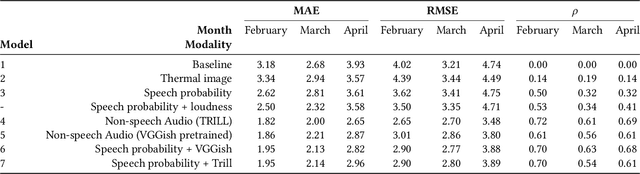
Privacy-preserving crowd density analysis finds application across a wide range of scenarios, substantially enhancing smart building operation and management while upholding privacy expectations in various spaces. We propose a non-speech audio-based approach for crowd analytics, leveraging a transformer-based model. Our results demonstrate that non-speech audio alone can be used to conduct such analysis with remarkable accuracy. To the best of our knowledge, this is the first time when non-speech audio signals are proposed for predicting occupancy. As far as we know, there has been no other similar approach of its kind prior to this. To accomplish this, we deployed our sensor-based platform in the waiting room of a large hospital with IRB approval over a period of several months to capture non-speech audio and thermal images for the training and evaluation of our models. The proposed non-speech-based approach outperformed the thermal camera-based model and all other baselines. In addition to demonstrating superior performance without utilizing speech audio, we conduct further analysis using differential privacy techniques to provide additional privacy guarantees. Overall, our work demonstrates the viability of employing non-speech audio data for accurate occupancy estimation, while also ensuring the exclusion of speech-related content and providing robust privacy protections through differential privacy guarantees.