 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Connecting NTK and NNGP: A Unified Theoretical Framework for Neural Network Learning Dynamics in the Kernel Regime
Sep 08, 2023
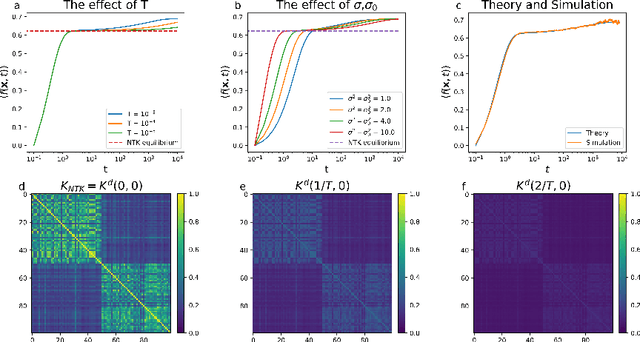
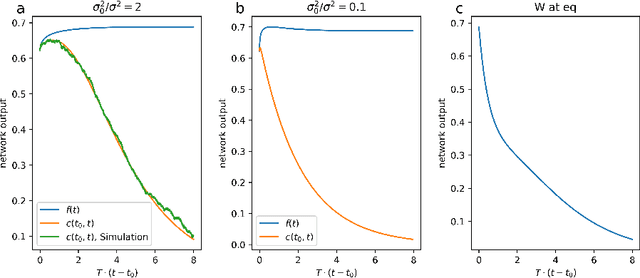
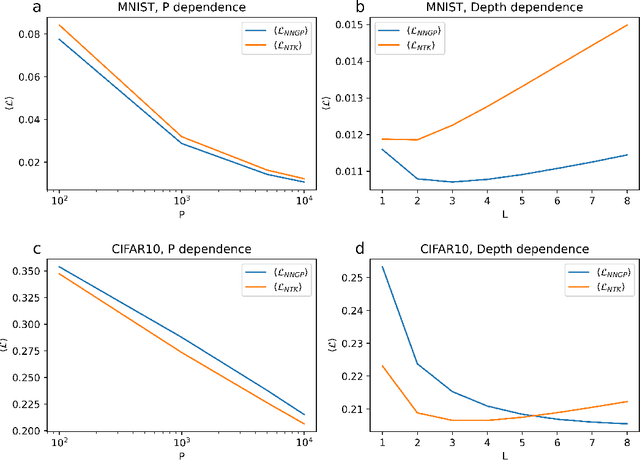
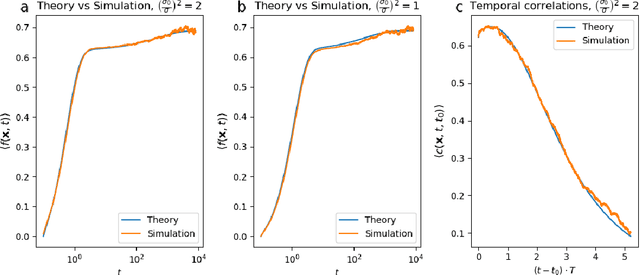
Artificial neural networks have revolutionized machine learning in recent years, but a complete theoretical framework for their learning process is still lacking. Substantial progress has been made for infinitely wide networks. In this regime, two disparate theoretical frameworks have been used, in which the network's output is described using kernels: one framework is based on the Neural Tangent Kernel (NTK) which assumes linearized gradient descent dynamics, while the Neural Network Gaussian Process (NNGP) kernel assumes a Bayesian framework. However, the relation between these two frameworks has remained elusive. This work unifies these two distinct theories using a Markov proximal learning model for learning dynamics in an ensemble of randomly initialized infinitely wide deep networks. We derive an exact analytical expression for the network input-output function during and after learning, and introduce a new time-dependent Neural Dynamical Kernel (NDK) from which both NTK and NNGP kernels can be derived. We identify two learning phases characterized by different time scales: gradient-driven and diffusive learning. In the initial gradient-driven learning phase, the dynamics is dominated by deterministic gradient descent, and is described by the NTK theory. This phase is followed by the diffusive learning stage, during which the network parameters sample the solution space, ultimately approaching the equilibrium distribution corresponding to NNGP. Combined with numerical evaluations on synthetic and benchmark datasets, we provide novel insights into the different roles of initialization, regularization, and network depth, as well as phenomena such as early stopping and representational drift. This work closes the gap between the NTK and NNGP theories, providing a comprehensive framework for understanding the learning process of deep neural networks in the infinite width limit.
Implicit regularization of deep residual networks towards neural ODEs
Sep 03, 2023Residual neural networks are state-of-the-art deep learning models. Their continuous-depth analog, neural ordinary differential equations (ODEs), are also widely used. Despite their success, the link between the discrete and continuous models still lacks a solid mathematical foundation. In this article, we take a step in this direction by establishing an implicit regularization of deep residual networks towards neural ODEs, for nonlinear networks trained with gradient flow. We prove that if the network is initialized as a discretization of a neural ODE, then such a discretization holds throughout training. Our results are valid for a finite training time, and also as the training time tends to infinity provided that the network satisfies a Polyak-Lojasiewicz condition. Importantly, this condition holds for a family of residual networks where the residuals are two-layer perceptrons with an overparameterization in width that is only linear, and implies the convergence of gradient flow to a global minimum. Numerical experiments illustrate our results.
Getting too personal(ized): The importance of feature choice in online adaptive algorithms
Sep 06, 2023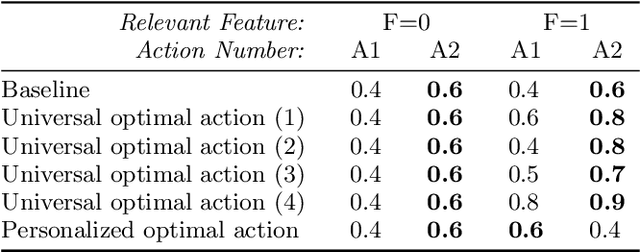
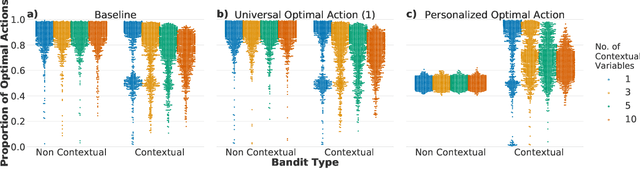

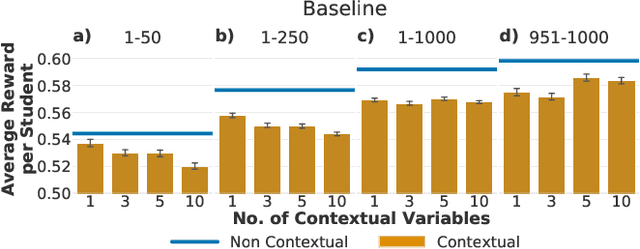
Digital educational technologies offer the potential to customize students' experiences and learn what works for which students, enhancing the technology as more students interact with it. We consider whether and when attempting to discover how to personalize has a cost, such as if the adaptation to personal information can delay the adoption of policies that benefit all students. We explore these issues in the context of using multi-armed bandit (MAB) algorithms to learn a policy for what version of an educational technology to present to each student, varying the relation between student characteristics and outcomes and also whether the algorithm is aware of these characteristics. Through simulations, we demonstrate that the inclusion of student characteristics for personalization can be beneficial when those characteristics are needed to learn the optimal action. In other scenarios, this inclusion decreases performance of the bandit algorithm. Moreover, including unneeded student characteristics can systematically disadvantage students with less common values for these characteristics. Our simulations do however suggest that real-time personalization will be helpful in particular real-world scenarios, and we illustrate this through case studies using existing experimental results in ASSISTments. Overall, our simulations show that adaptive personalization in educational technologies can be a double-edged sword: real-time adaptation improves student experiences in some contexts, but the slower adaptation and potentially discriminatory results mean that a more personalized model is not always beneficial.
Multiclass Alignment of Confidence and Certainty for Network Calibration
Sep 06, 2023Deep neural networks (DNNs) have made great strides in pushing the state-of-the-art in several challenging domains. Recent studies reveal that they are prone to making overconfident predictions. This greatly reduces the overall trust in model predictions, especially in safety-critical applications. Early work in improving model calibration employs post-processing techniques which rely on limited parameters and require a hold-out set. Some recent train-time calibration methods, which involve all model parameters, can outperform the postprocessing methods. To this end, we propose a new train-time calibration method, which features a simple, plug-and-play auxiliary loss known as multi-class alignment of predictive mean confidence and predictive certainty (MACC). It is based on the observation that a model miscalibration is directly related to its predictive certainty, so a higher gap between the mean confidence and certainty amounts to a poor calibration both for in-distribution and out-of-distribution predictions. Armed with this insight, our proposed loss explicitly encourages a confident (or underconfident) model to also provide a low (or high) spread in the presoftmax distribution. Extensive experiments on ten challenging datasets, covering in-domain, out-domain, non-visual recognition and medical image classification scenarios, show that our method achieves state-of-the-art calibration performance for both in-domain and out-domain predictions. Our code and models will be publicly released.
SegmentAnything helps microscopy images based automatic and quantitative organoid detection and analysis
Sep 11, 2023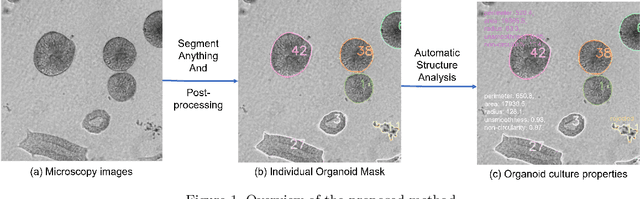
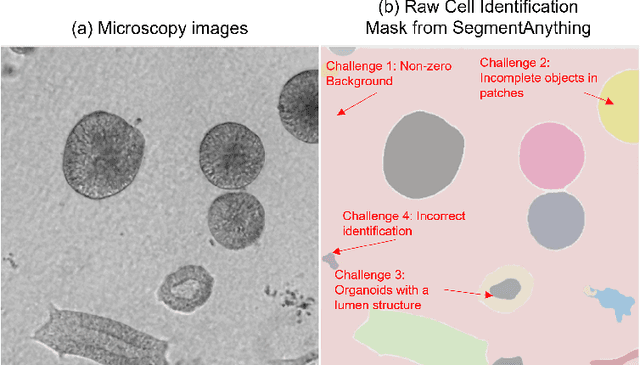
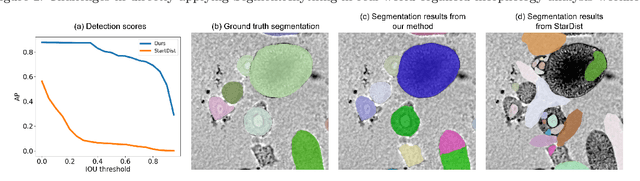
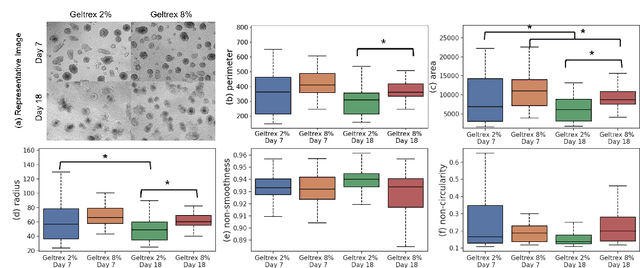
Organoids are self-organized 3D cell clusters that closely mimic the architecture and function of in vivo tissues and organs. Quantification of organoid morphology helps in studying organ development, drug discovery, and toxicity assessment. Recent microscopy techniques provide a potent tool to acquire organoid morphology features, but manual image analysis remains a labor and time-intensive process. Thus, this paper proposes a comprehensive pipeline for microscopy analysis that leverages the SegmentAnything to precisely demarcate individual organoids. Additionally, we introduce a set of morphological properties, including perimeter, area, radius, non-smoothness, and non-circularity, allowing researchers to analyze the organoid structures quantitatively and automatically. To validate the effectiveness of our approach, we conducted tests on bright-field images of human induced pluripotent stem cells (iPSCs) derived neural-epithelial (NE) organoids. The results obtained from our automatic pipeline closely align with manual organoid detection and measurement, showcasing the capability of our proposed method in accelerating organoids morphology analysis.
Neuromorphic Auditory Perception by Neural Spiketrum
Sep 11, 2023Neuromorphic computing holds the promise to achieve the energy efficiency and robust learning performance of biological neural systems. To realize the promised brain-like intelligence, it needs to solve the challenges of the neuromorphic hardware architecture design of biological neural substrate and the hardware amicable algorithms with spike-based encoding and learning. Here we introduce a neural spike coding model termed spiketrum, to characterize and transform the time-varying analog signals, typically auditory signals, into computationally efficient spatiotemporal spike patterns. It minimizes the information loss occurring at the analog-to-spike transformation and possesses informational robustness to neural fluctuations and spike losses. The model provides a sparse and efficient coding scheme with precisely controllable spike rate that facilitates training of spiking neural networks in various auditory perception tasks. We further investigate the algorithm-hardware co-designs through a neuromorphic cochlear prototype which demonstrates that our approach can provide a systematic solution for spike-based artificial intelligence by fully exploiting its advantages with spike-based computation.
Stochastic Configuration Machines for Industrial Artificial Intelligence
Sep 11, 2023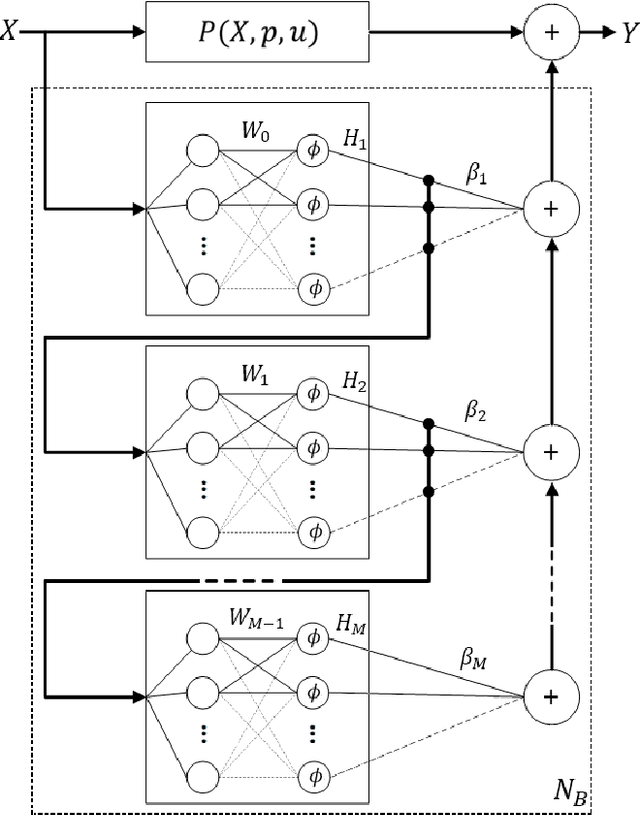
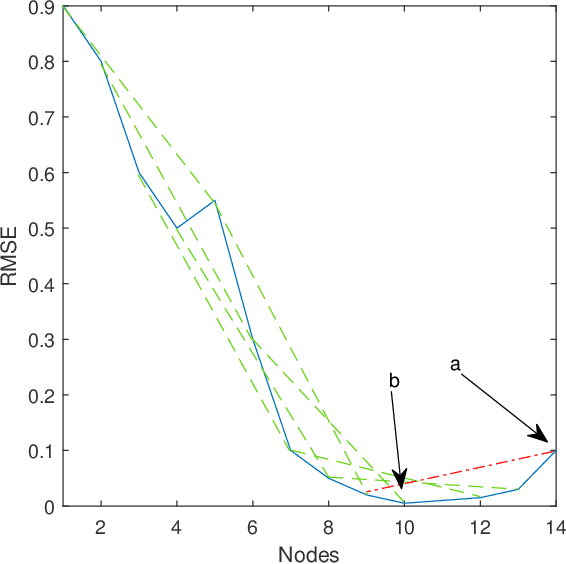
Real-time predictive modelling with desired accuracy is highly expected in industrial artificial intelligence (IAI), where neural networks play a key role. Neural networks in IAI require powerful, high-performance computing devices to operate a large number of floating point data. Based on stochastic configuration networks (SCNs), this paper proposes a new randomized learner model, termed stochastic configuration machines (SCMs), to stress effective modelling and data size saving that are useful and valuable for industrial applications. Compared to SCNs and random vector functional-link (RVFL) nets with binarized implementation, the model storage of SCMs can be significantly compressed while retaining favourable prediction performance. Besides the architecture of the SCM learner model and its learning algorithm, as an important part of this contribution, we also provide a theoretical basis on the learning capacity of SCMs by analysing the model's complexity. Experimental studies are carried out over some benchmark datasets and three industrial applications. The results demonstrate that SCM has great potential for dealing with industrial data analytics.
Minuteman: Machine and Human Joining Forces in Meeting Summarization
Sep 11, 2023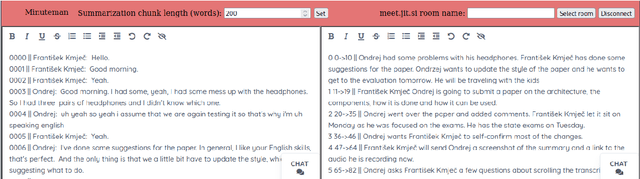


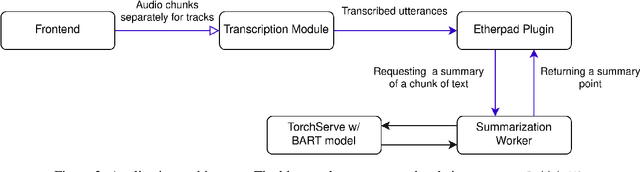
Many meetings require creating a meeting summary to keep everyone up to date. Creating minutes of sufficient quality is however very cognitively demanding. Although we currently possess capable models for both audio speech recognition (ASR) and summarization, their fully automatic use is still problematic. ASR models frequently commit errors when transcribing named entities while the summarization models tend to hallucinate and misinterpret the transcript. We propose a novel tool -- Minuteman -- to enable efficient semi-automatic meeting minuting. The tool provides a live transcript and a live meeting summary to the users, who can edit them in a collaborative manner, enabling correction of ASR errors and imperfect summary points in real time. The resulting application eases the cognitive load of the notetakers and allows them to easily catch up if they missed a part of the meeting due to absence or a lack of focus. We conduct several tests of the application in varied settings, exploring the worthiness of the concept and the possible user strategies.
A DRL-based Reflection Enhancement Method for RIS-assisted Multi-receiver Communications
Sep 11, 2023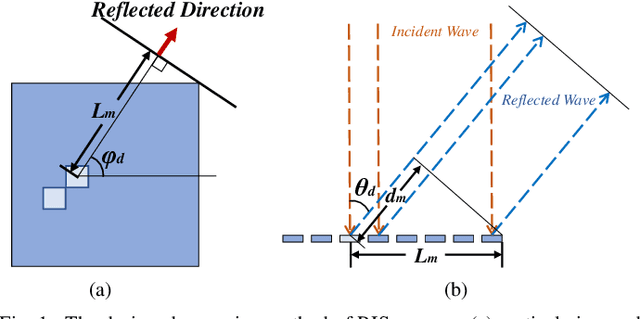

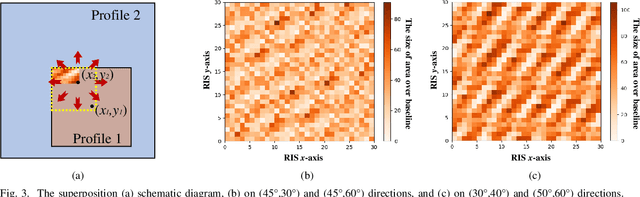
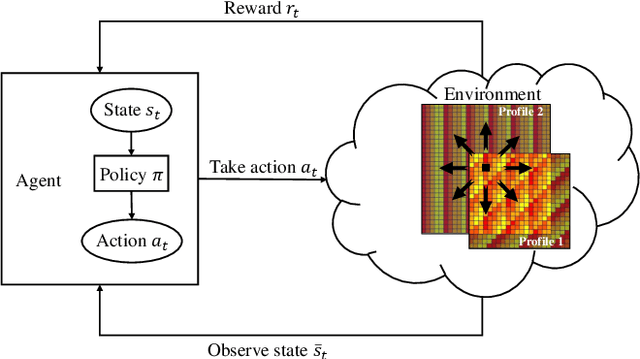
In reconfigurable intelligent surface (RIS)-assisted wireless communication systems, the pointing accuracy and intensity of reflections depend crucially on the 'profile,' representing the amplitude/phase state information of all elements in a RIS array. The superposition of multiple single-reflection profiles enables multi-reflection for distributed users. However, the optimization challenges from periodic element arrangements in single-reflection and multi-reflection profiles are understudied. The combination of periodical single-reflection profiles leads to amplitude/phase counteractions, affecting the performance of each reflection beam. This paper focuses on a dual-reflection optimization scenario and investigates the far-field performance deterioration caused by the misalignment of overlapped profiles. To address this issue, we introduce a novel deep reinforcement learning (DRL)-based optimization method. Comparative experiments against random and exhaustive searches demonstrate that our proposed DRL method outperforms both alternatives, achieving the shortest optimization time. Remarkably, our approach achieves a 1.2 dB gain in the reflection peak gain and a broader beam without any hardware modifications.
Efficiently Robustify Pre-trained Models
Sep 14, 2023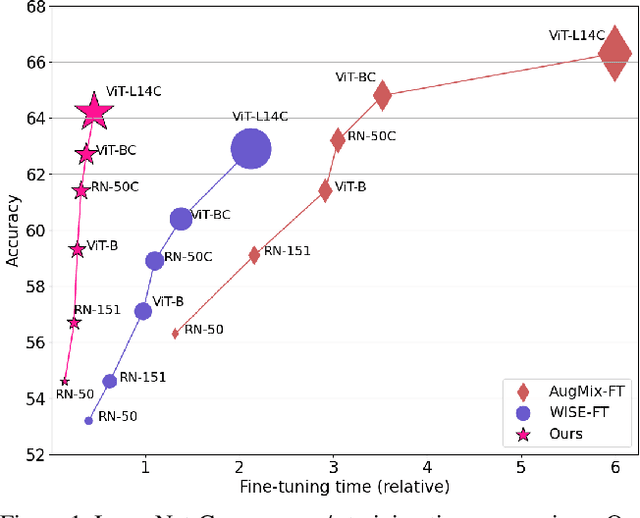
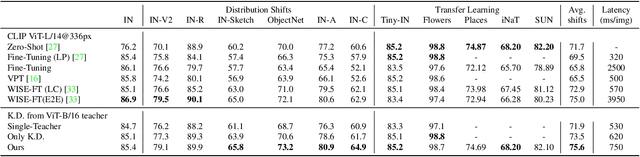
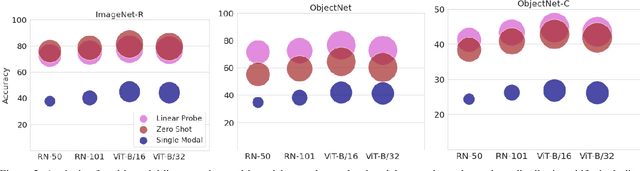

A recent trend in deep learning algorithms has been towards training large scale models, having high parameter count and trained on big dataset. However, robustness of such large scale models towards real-world settings is still a less-explored topic. In this work, we first benchmark the performance of these models under different perturbations and datasets thereby representing real-world shifts, and highlight their degrading performance under these shifts. We then discuss on how complete model fine-tuning based existing robustification schemes might not be a scalable option given very large scale networks and can also lead them to forget some of the desired characterstics. Finally, we propose a simple and cost-effective method to solve this problem, inspired by knowledge transfer literature. It involves robustifying smaller models, at a lower computation cost, and then use them as teachers to tune a fraction of these large scale networks, reducing the overall computational overhead. We evaluate our proposed method under various vision perturbations including ImageNet-C,R,S,A datasets and also for transfer learning, zero-shot evaluation setups on different datasets. Benchmark results show that our method is able to induce robustness to these large scale models efficiently, requiring significantly lower time and also preserves the transfer learning, zero-shot properties of the original model which none of the existing methods are able to achieve.