 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Panoptic Vision-Language Feature Fields
Sep 11, 2023
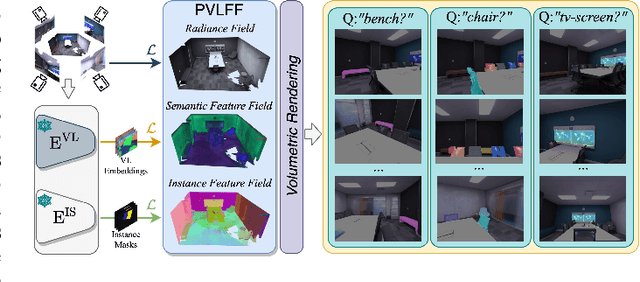
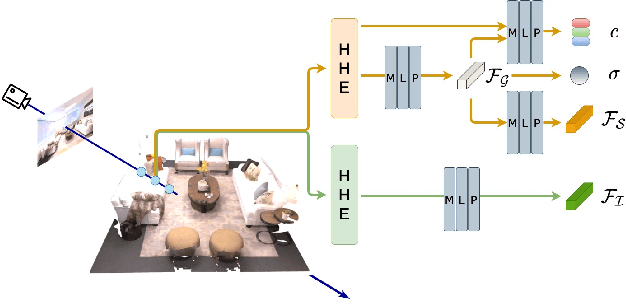
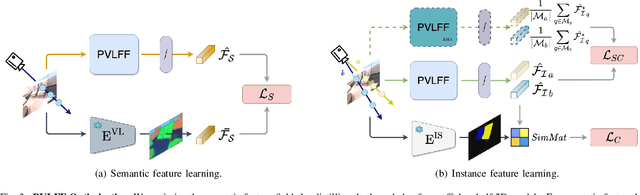

Recently, methods have been proposed for 3D open-vocabulary semantic segmentation. Such methods are able to segment scenes into arbitrary classes given at run-time using their text description. In this paper, we propose to our knowledge the first algorithm for open-vocabulary panoptic segmentation, simultaneously performing both semantic and instance segmentation. Our algorithm, Panoptic Vision-Language Feature Fields (PVLFF) learns a feature field of the scene, jointly learning vision-language features and hierarchical instance features through a contrastive loss function from 2D instance segment proposals on input frames. Our method achieves comparable performance against the state-of-the-art close-set 3D panoptic systems on the HyperSim, ScanNet and Replica dataset and outperforms current 3D open-vocabulary systems in terms of semantic segmentation. We additionally ablate our method to demonstrate the effectiveness of our model architecture. Our code will be available at https://github.com/ethz-asl/autolabel.
FlowIBR: Leveraging Pre-Training for Efficient Neural Image-Based Rendering of Dynamic Scenes
Sep 11, 2023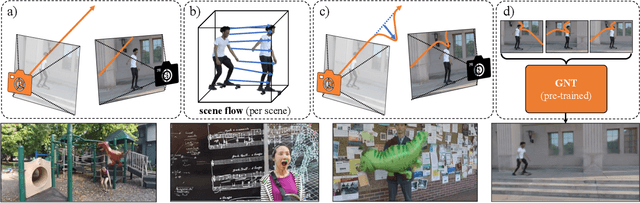
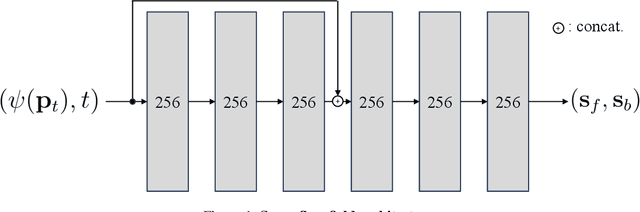
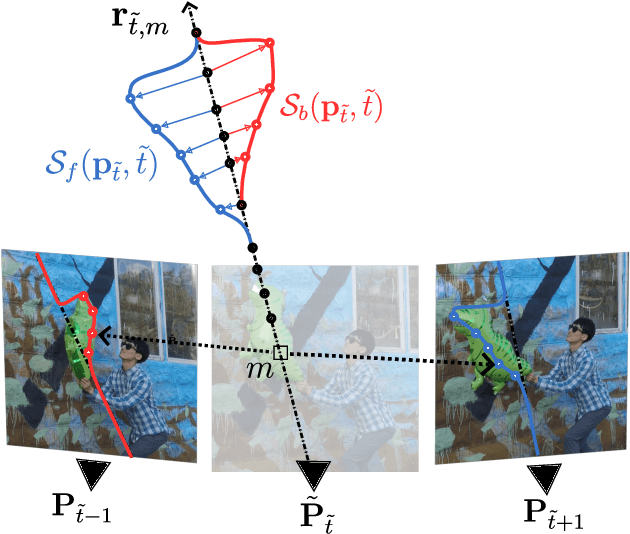
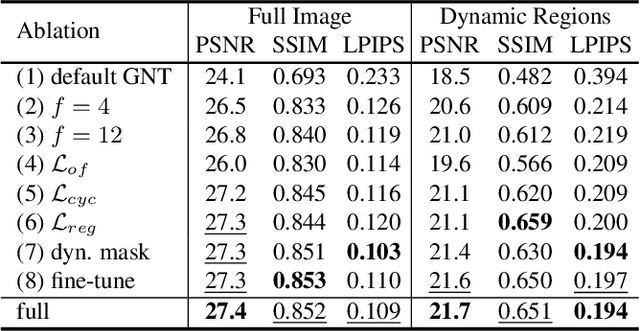
We introduce a novel approach for monocular novel view synthesis of dynamic scenes. Existing techniques already show impressive rendering quality but tend to focus on optimization within a single scene without leveraging prior knowledge. This limitation has been primarily attributed to the lack of datasets of dynamic scenes available for training and the diversity of scene dynamics. Our method FlowIBR circumvents these issues by integrating a neural image-based rendering method, pre-trained on a large corpus of widely available static scenes, with a per-scene optimized scene flow field. Utilizing this flow field, we bend the camera rays to counteract the scene dynamics, thereby presenting the dynamic scene as if it were static to the rendering network. The proposed method reduces per-scene optimization time by an order of magnitude, achieving comparable results to existing methods - all on a single consumer-grade GPU.
Extending Transductive Knowledge Graph Embedding Models for Inductive Logical Relational Inference
Sep 07, 2023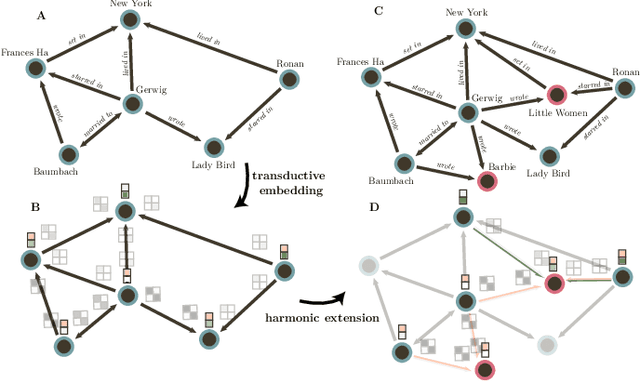
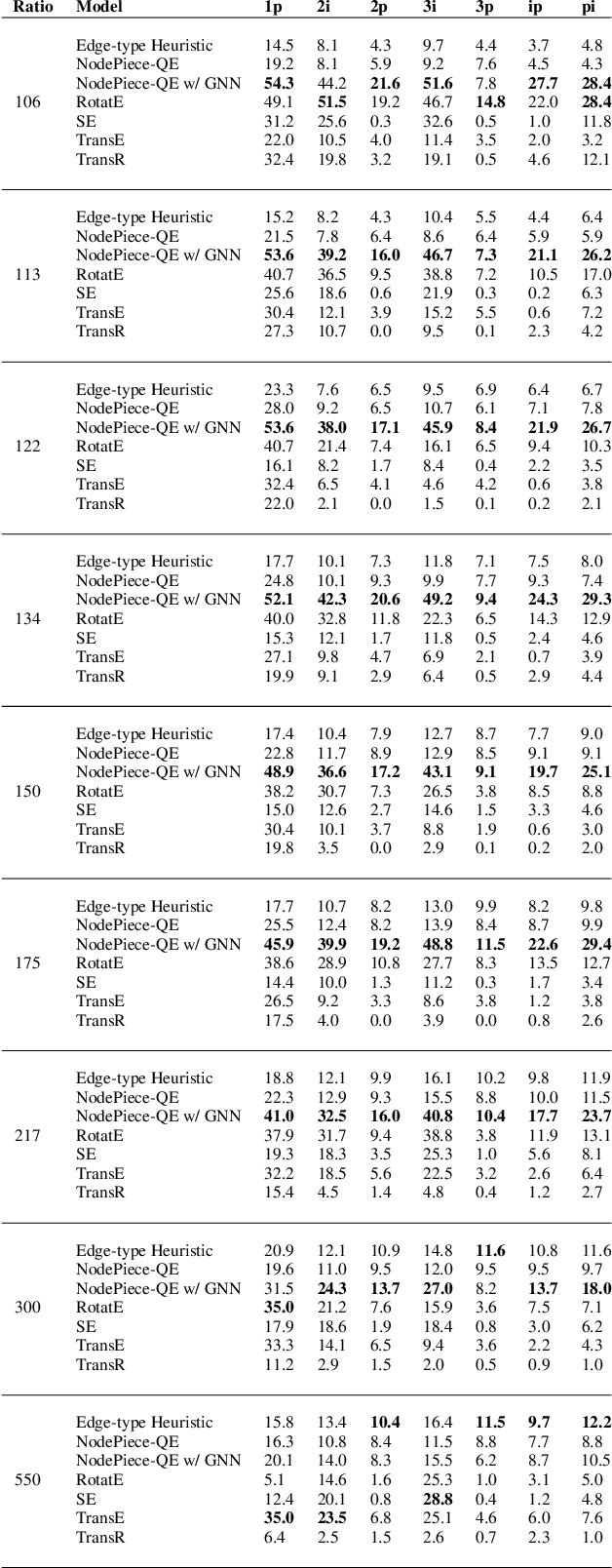
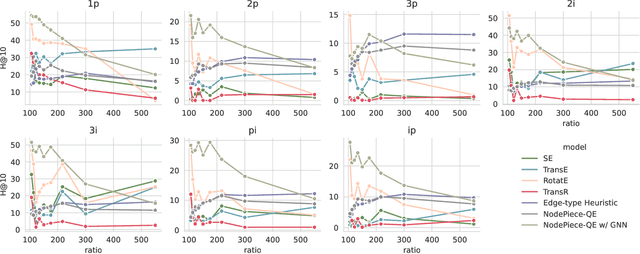
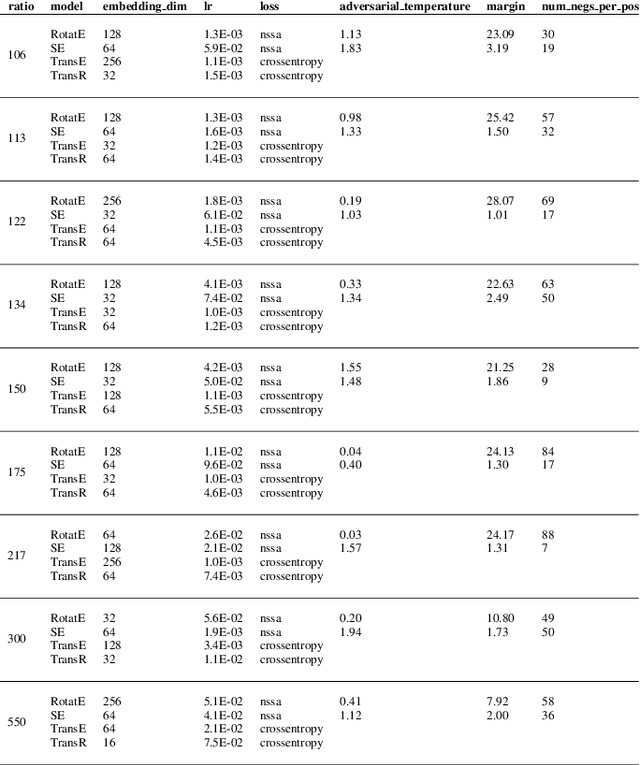
Many downstream inference tasks for knowledge graphs, such as relation prediction, have been handled successfully by knowledge graph embedding techniques in the transductive setting. To address the inductive setting wherein new entities are introduced into the knowledge graph at inference time, more recent work opts for models which learn implicit representations of the knowledge graph through a complex function of a network's subgraph structure, often parametrized by graph neural network architectures. These come at the cost of increased parametrization, reduced interpretability and limited generalization to other downstream inference tasks. In this work, we bridge the gap between traditional transductive knowledge graph embedding approaches and more recent inductive relation prediction models by introducing a generalized form of harmonic extension which leverages representations learned through transductive embedding methods to infer representations of new entities introduced at inference time as in the inductive setting. This harmonic extension technique provides the best such approximation, can be implemented via an efficient iterative scheme, and can be employed to answer a family of conjunctive logical queries over the knowledge graph, further expanding the capabilities of transductive embedding methods. In experiments on a number of large-scale knowledge graph embedding benchmarks, we find that this approach for extending the functionality of transductive knowledge graph embedding models to perform knowledge graph completion and answer logical queries in the inductive setting is competitive with--and in some scenarios outperforms--several state-of-the-art models derived explicitly for such inductive tasks.
RGI-Net: 3D Room Geometry Inference from Room Impulse Responses in the Absence of First-order Echoes
Sep 04, 2023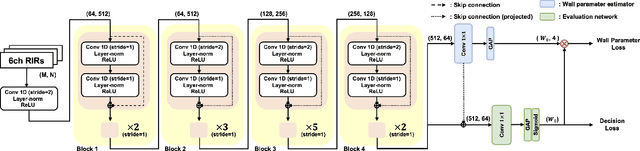

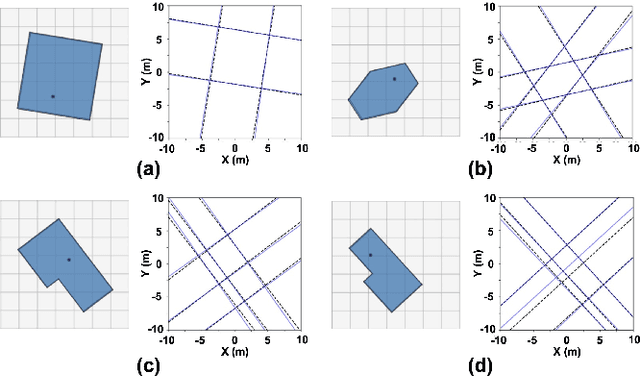
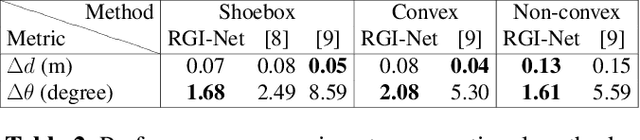
Room geometry is important prior information for implementing realistic 3D audio rendering. For this reason, various room geometry inference (RGI) methods have been developed by utilizing the time of arrival (TOA) or time difference of arrival (TDOA) information in room impulse responses. However, the conventional RGI technique poses several assumptions, such as convex room shapes, the number of walls known in priori, and the visibility of first-order reflections. In this work, we introduce the deep neural network (DNN), RGI-Net, which can estimate room geometries without the aforementioned assumptions. RGI-Net learns and exploits complex relationships between high-order reflections in room impulse responses (RIRs) and, thus, can estimate room shapes even when the shape is non-convex or first-order reflections are missing in the RIRs. The network takes RIRs measured from a compact audio device equipped with a circular microphone array and a single loudspeaker, which greatly improves its practical applicability. RGI-Net includes the evaluation network that separately evaluates the presence probability of walls, so the geometry inference is possible without prior knowledge of the number of walls.
Leveraging Watch-time Feedback for Short-Video Recommendations: A Causal Labeling Framework
Jun 30, 2023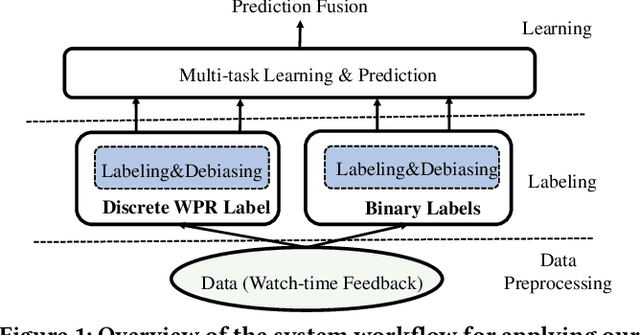

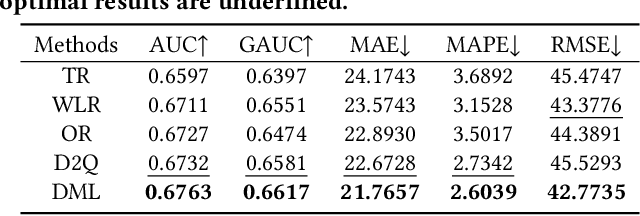
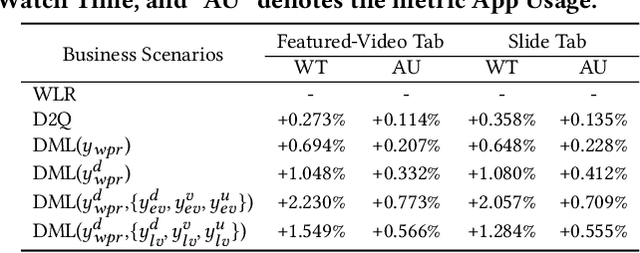
With the proliferation of short video applications, the significance of short video recommendations has vastly increased. Unlike other recommendation scenarios, short video recommendation systems heavily rely on feedback from watch time. Existing approaches simply treat watch time as a direct label, failing to effectively harness its extensive semantics and introduce bias, thereby limiting the potential for modeling user interests based on watch time. To overcome this challenge, we propose a framework named Debiasied Multiple-semantics-extracting Labeling (DML). DML constructs labels that encompass various semantics by utilizing quantiles derived from the distribution of watch time, prioritizing relative order rather than absolute label values. This approach facilitates easier model learning while aligning with the ranking objective of recommendations. Furthermore, we introduce a method inspired by causal adjustment to refine label definitions, thereby reducing the impact of bias on the label and directly mitigating bias at the label level. We substantiate the effectiveness of our DML framework through both online and offline experiments. Extensive results demonstrate that our DML could effectively leverage watch time to discover users' real interests, enhancing their engagement in our application.
Diffusion models for audio semantic communication
Sep 13, 2023Directly sending audio signals from a transmitter to a receiver across a noisy channel may absorb consistent bandwidth and be prone to errors when trying to recover the transmitted bits. On the contrary, the recent semantic communication approach proposes to send the semantics and then regenerate semantically consistent content at the receiver without exactly recovering the bitstream. In this paper, we propose a generative audio semantic communication framework that faces the communication problem as an inverse problem, therefore being robust to different corruptions. Our method transmits lower-dimensional representations of the audio signal and of the associated semantics to the receiver, which generates the corresponding signal with a particular focus on its meaning (i.e., the semantics) thanks to the conditional diffusion model at its core. During the generation process, the diffusion model restores the received information from multiple degradations at the same time including corruption noise and missing parts caused by the transmission over the noisy channel. We show that our framework outperforms competitors in a real-world scenario and with different channel conditions. Visit the project page to listen to samples and access the code: https://ispamm.github.io/diffusion-audio-semantic-communication/.
On the Terminal Location Uncertainty in Elliptical Footprints: Application in Air-to-Ground Links
Sep 13, 2023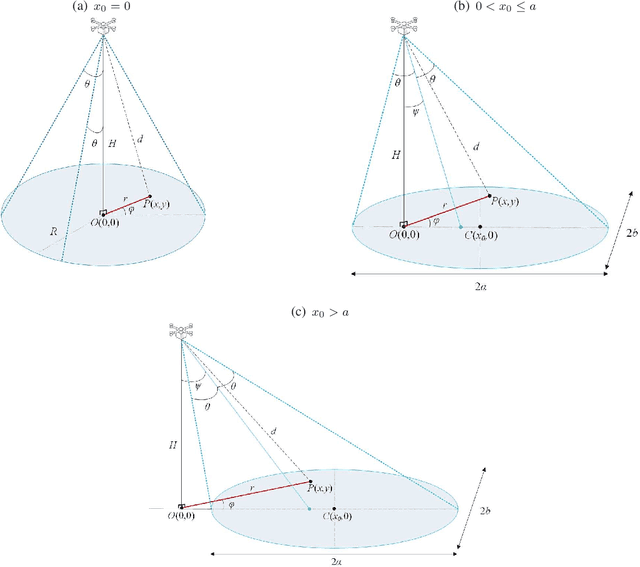
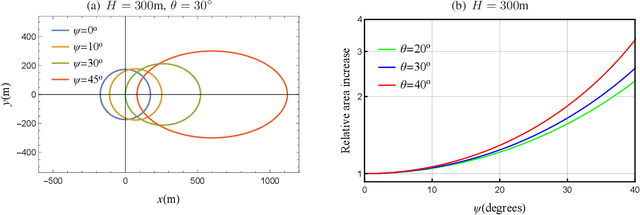
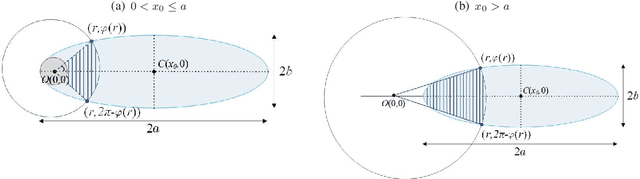
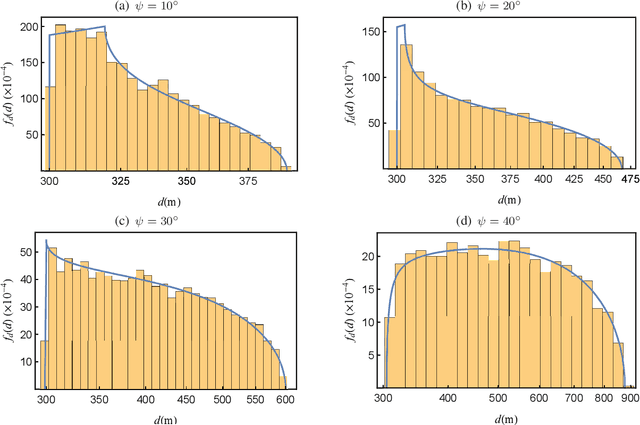
Wireless transmitters (Txs) radiating directionally downwards often generate circular footprints on the ground. In certain scenarios, using elliptical cells can offer increased flexibility for providing user coverage, owing to the unique network characteristics. For instance, an elliptical footprint can be produced when a practical directional antenna with unequal azimuth and elevation half-power beamwidths is used in high-speed railway networks. Another common scenario involves the production of an elliptical footprint when an airborne Tx radiates at an angle by tilting its directional antenna by a few degrees. This paper aims to investigate, for the first time, the association between the random user location within an elliptical coverage area and the performance of a wireless communication link by considering these scenarios. We assume an unmanned aerial vehicle (UAV) as a Tx, although a tall cellular base station tower could also be employed without losing generality. To better understand the impact of random location, we derive relevant distance metrics and investigate the outage probability of the link for the two scenarios, taking both random terminal location and fading impairments into account. The findings may provide valuable insights into the performance of similar wireless systems.
MTD: Multi-Timestep Detector for Delayed Streaming Perception
Sep 13, 2023Autonomous driving systems require real-time environmental perception to ensure user safety and experience. Streaming perception is a task of reporting the current state of the world, which is used to evaluate the delay and accuracy of autonomous driving systems. In real-world applications, factors such as hardware limitations and high temperatures inevitably cause delays in autonomous driving systems, resulting in the offset between the model output and the world state. In order to solve this problem, this paper propose the Multi- Timestep Detector (MTD), an end-to-end detector which uses dynamic routing for multi-branch future prediction, giving model the ability to resist delay fluctuations. A Delay Analysis Module (DAM) is proposed to optimize the existing delay sensing method, continuously monitoring the model inference stack and calculating the delay trend. Moreover, a novel Timestep Branch Module (TBM) is constructed, which includes static flow and adaptive flow to adaptively predict specific timesteps according to the delay trend. The proposed method has been evaluated on the Argoverse-HD dataset, and the experimental results show that it has achieved state-of-the-art performance across various delay settings.
Characterizing Speed Performance of Multi-Agent Reinforcement Learning
Sep 13, 2023
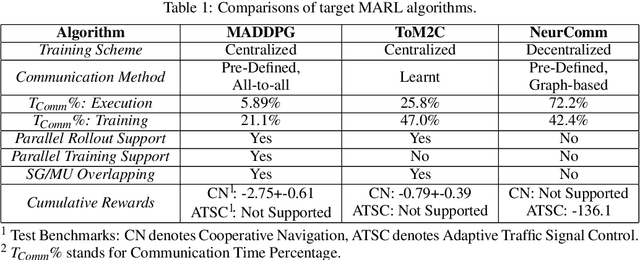
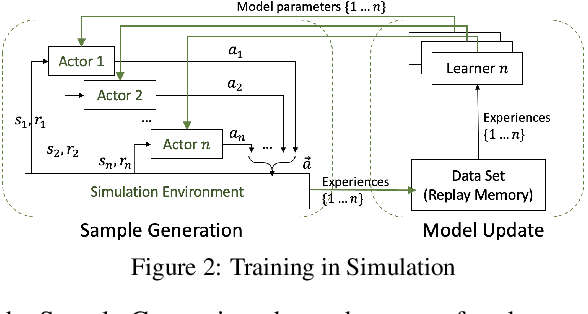
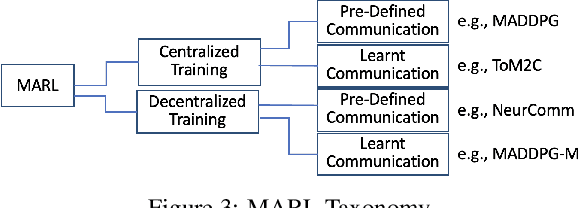
Multi-Agent Reinforcement Learning (MARL) has achieved significant success in large-scale AI systems and big-data applications such as smart grids, surveillance, etc. Existing advancements in MARL algorithms focus on improving the rewards obtained by introducing various mechanisms for inter-agent cooperation. However, these optimizations are usually compute- and memory-intensive, thus leading to suboptimal speed performance in end-to-end training time. In this work, we analyze the speed performance (i.e., latency-bounded throughput) as the key metric in MARL implementations. Specifically, we first introduce a taxonomy of MARL algorithms from an acceleration perspective categorized by (1) training scheme and (2) communication method. Using our taxonomy, we identify three state-of-the-art MARL algorithms - Multi-Agent Deep Deterministic Policy Gradient (MADDPG), Target-oriented Multi-agent Communication and Cooperation (ToM2C), and Networked Multi-Agent RL (NeurComm) - as target benchmark algorithms, and provide a systematic analysis of their performance bottlenecks on a homogeneous multi-core CPU platform. We justify the need for MARL latency-bounded throughput to be a key performance metric in future literature while also addressing opportunities for parallelization and acceleration.
Implicit regularization of deep residual networks towards neural ODEs
Sep 03, 2023Residual neural networks are state-of-the-art deep learning models. Their continuous-depth analog, neural ordinary differential equations (ODEs), are also widely used. Despite their success, the link between the discrete and continuous models still lacks a solid mathematical foundation. In this article, we take a step in this direction by establishing an implicit regularization of deep residual networks towards neural ODEs, for nonlinear networks trained with gradient flow. We prove that if the network is initialized as a discretization of a neural ODE, then such a discretization holds throughout training. Our results are valid for a finite training time, and also as the training time tends to infinity provided that the network satisfies a Polyak-Lojasiewicz condition. Importantly, this condition holds for a family of residual networks where the residuals are two-layer perceptrons with an overparameterization in width that is only linear, and implies the convergence of gradient flow to a global minimum. Numerical experiments illustrate our results.