 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Diffusion Generative Inverse Design
Sep 18, 2023
Inverse design refers to the problem of optimizing the input of an objective function in order to enact a target outcome. For many real-world engineering problems, the objective function takes the form of a simulator that predicts how the system state will evolve over time, and the design challenge is to optimize the initial conditions that lead to a target outcome. Recent developments in learned simulation have shown that graph neural networks (GNNs) can be used for accurate, efficient, differentiable estimation of simulator dynamics, and support high-quality design optimization with gradient- or sampling-based optimization procedures. However, optimizing designs from scratch requires many expensive model queries, and these procedures exhibit basic failures on either non-convex or high-dimensional problems. In this work, we show how denoising diffusion models (DDMs) can be used to solve inverse design problems efficiently and propose a particle sampling algorithm for further improving their efficiency. We perform experiments on a number of fluid dynamics design challenges, and find that our approach substantially reduces the number of calls to the simulator compared to standard techniques.
Sparse and Privacy-enhanced Representation for Human Pose Estimation
Sep 18, 2023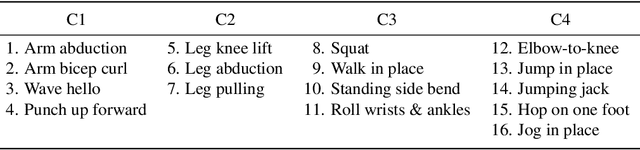
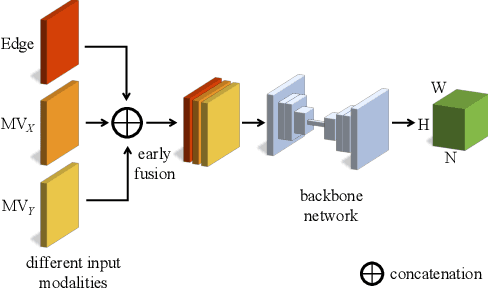
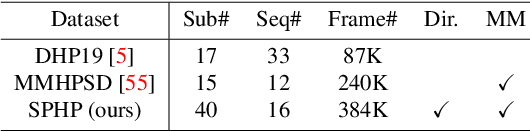
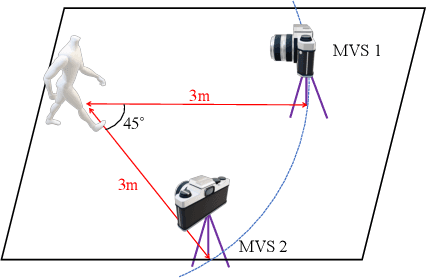
We propose a sparse and privacy-enhanced representation for Human Pose Estimation (HPE). Given a perspective camera, we use a proprietary motion vector sensor(MVS) to extract an edge image and a two-directional motion vector image at each time frame. Both edge and motion vector images are sparse and contain much less information (i.e., enhancing human privacy). We advocate that edge information is essential for HPE, and motion vectors complement edge information during fast movements. We propose a fusion network leveraging recent advances in sparse convolution used typically for 3D voxels to efficiently process our proposed sparse representation, which achieves about 13x speed-up and 96% reduction in FLOPs. We collect an in-house edge and motion vector dataset with 16 types of actions by 40 users using the proprietary MVS. Our method outperforms individual modalities using only edge or motion vector images. Finally, we validate the privacy-enhanced quality of our sparse representation through face recognition on CelebA (a large face dataset) and a user study on our in-house dataset.
A Study of Data-driven Methods for Adaptive Forecasting of COVID-19 Cases
Sep 18, 2023Severe acute respiratory disease SARS-CoV-2 has had a found impact on public health systems and healthcare emergency response especially with respect to making decisions on the most effective measures to be taken at any given time. As demonstrated throughout the last three years with COVID-19, the prediction of the number of positive cases can be an effective way to facilitate decision-making. However, the limited availability of data and the highly dynamic and uncertain nature of the virus transmissibility makes this task very challenging. Aiming at investigating these challenges and in order to address this problem, this work studies data-driven (learning, statistical) methods for incrementally training models to adapt to these nonstationary conditions. An extensive empirical study is conducted to examine various characteristics, such as, performance analysis on a per virus wave basis, feature extraction, "lookback" window size, memory size, all for next-, 7-, and 14-day forecasting tasks. We demonstrate that the incremental learning framework can successfully address the aforementioned challenges and perform well during outbreaks, providing accurate predictions.
* Keywords: incremental learning, data streams, neural networks, time-series forecasting
SYNDICOM: Improving Conversational Commonsense with Error-Injection and Natural Language Feedback
Sep 18, 2023Commonsense reasoning is a critical aspect of human communication. Despite recent advances in conversational AI driven by large language models, commonsense reasoning remains a challenging task. In this work, we introduce SYNDICOM - a method for improving commonsense in dialogue response generation. SYNDICOM consists of two components. The first component is a dataset composed of commonsense dialogues created from a knowledge graph and synthesized into natural language. This dataset includes both valid and invalid responses to dialogue contexts, along with natural language feedback (NLF) for the invalid responses. The second contribution is a two-step procedure: training a model to predict natural language feedback (NLF) for invalid responses, and then training a response generation model conditioned on the predicted NLF, the invalid response, and the dialogue. SYNDICOM is scalable and does not require reinforcement learning. Empirical results on three tasks are evaluated using a broad range of metrics. SYNDICOM achieves a relative improvement of 53% over ChatGPT on ROUGE1, and human evaluators prefer SYNDICOM over ChatGPT 57% of the time. We will publicly release the code and the full dataset.
Designing a Hybrid Neural System to Learn Real-world Crack Segmentation from Fractal-based Simulation
Sep 18, 2023
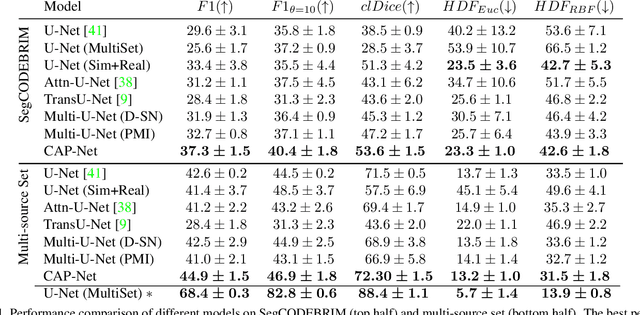
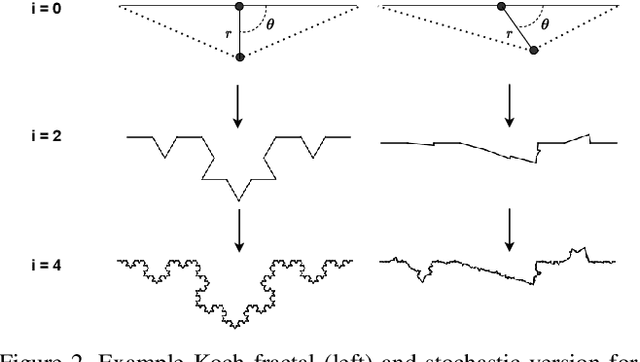
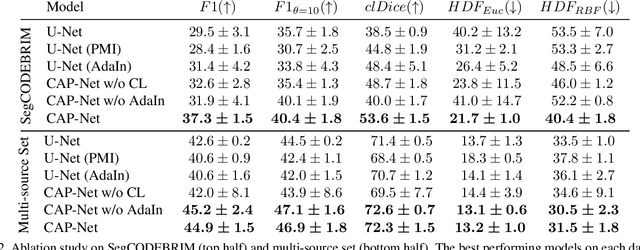
Identification of cracks is essential to assess the structural integrity of concrete infrastructure. However, robust crack segmentation remains a challenging task for computer vision systems due to the diverse appearance of concrete surfaces, variable lighting and weather conditions, and the overlapping of different defects. In particular recent data-driven methods struggle with the limited availability of data, the fine-grained and time-consuming nature of crack annotation, and face subsequent difficulty in generalizing to out-of-distribution samples. In this work, we move past these challenges in a two-fold way. We introduce a high-fidelity crack graphics simulator based on fractals and a corresponding fully-annotated crack dataset. We then complement the latter with a system that learns generalizable representations from simulation, by leveraging both a pointwise mutual information estimate along with adaptive instance normalization as inductive biases. Finally, we empirically highlight how different design choices are symbiotic in bridging the simulation to real gap, and ultimately demonstrate that our introduced system can effectively handle real-world crack segmentation.
Mutual Information-calibrated Conformal Feature Fusion for Uncertainty-Aware Multimodal 3D Object Detection at the Edge
Sep 18, 2023In the expanding landscape of AI-enabled robotics, robust quantification of predictive uncertainties is of great importance. Three-dimensional (3D) object detection, a critical robotics operation, has seen significant advancements; however, the majority of current works focus only on accuracy and ignore uncertainty quantification. Addressing this gap, our novel study integrates the principles of conformal inference (CI) with information theoretic measures to perform lightweight, Monte Carlo-free uncertainty estimation within a multimodal framework. Through a multivariate Gaussian product of the latent variables in a Variational Autoencoder (VAE), features from RGB camera and LiDAR sensor data are fused to improve the prediction accuracy. Normalized mutual information (NMI) is leveraged as a modulator for calibrating uncertainty bounds derived from CI based on a weighted loss function. Our simulation results show an inverse correlation between inherent predictive uncertainty and NMI throughout the model's training. The framework demonstrates comparable or better performance in KITTI 3D object detection benchmarks to similar methods that are not uncertainty-aware, making it suitable for real-time edge robotics.
Gradpaint: Gradient-Guided Inpainting with Diffusion Models
Sep 18, 2023Denoising Diffusion Probabilistic Models (DDPMs) have recently achieved remarkable results in conditional and unconditional image generation. The pre-trained models can be adapted without further training to different downstream tasks, by guiding their iterative denoising process at inference time to satisfy additional constraints. For the specific task of image inpainting, the current guiding mechanism relies on copying-and-pasting the known regions from the input image at each denoising step. However, diffusion models are strongly conditioned by the initial random noise, and therefore struggle to harmonize predictions inside the inpainting mask with the real parts of the input image, often producing results with unnatural artifacts. Our method, dubbed GradPaint, steers the generation towards a globally coherent image. At each step in the denoising process, we leverage the model's "denoised image estimation" by calculating a custom loss measuring its coherence with the masked input image. Our guiding mechanism uses the gradient obtained from backpropagating this loss through the diffusion model itself. GradPaint generalizes well to diffusion models trained on various datasets, improving upon current state-of-the-art supervised and unsupervised methods.
Self-supervised TransUNet for Ultrasound regional segmentation of the distal radius in children
Sep 18, 2023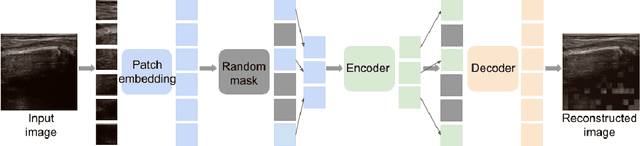


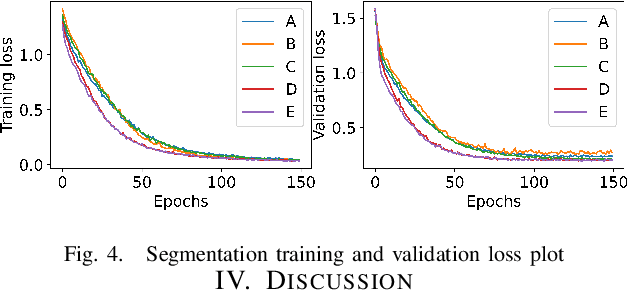
Supervised deep learning offers great promise to automate analysis of medical images from segmentation to diagnosis. However, their performance highly relies on the quality and quantity of the data annotation. Meanwhile, curating large annotated datasets for medical images requires a high level of expertise, which is time-consuming and expensive. Recently, to quench the thirst for large data sets with high-quality annotation, self-supervised learning (SSL) methods using unlabeled domain-specific data, have attracted attention. Therefore, designing an SSL method that relies on minimal quantities of labeled data has far-reaching significance in medical images. This paper investigates the feasibility of deploying the Masked Autoencoder for SSL (SSL-MAE) of TransUNet, for segmenting bony regions from children's wrist ultrasound scans. We found that changing the embedding and loss function in SSL-MAE can produce better downstream results compared to the original SSL-MAE. In addition, we determined that only pretraining TransUNet embedding and encoder with SSL-MAE does not work as well as TransUNet without SSL-MAE pretraining on downstream segmentation tasks.
A Wearable Ultra-Low-Power sEMG-Triggered Ultrasound System for Long-Term Muscle Activity Monitoring
Sep 14, 2023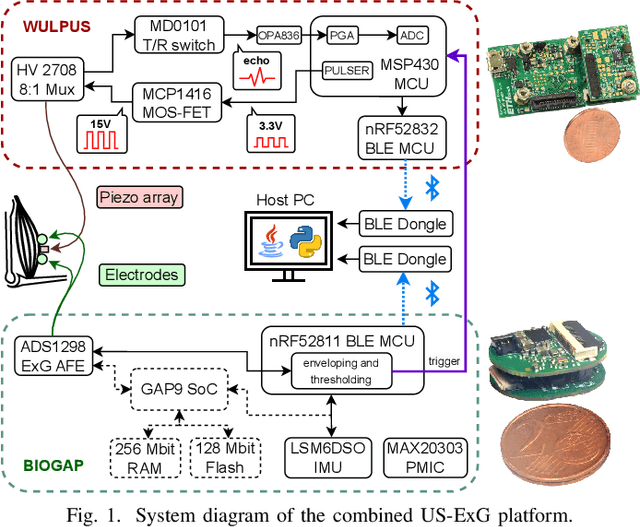
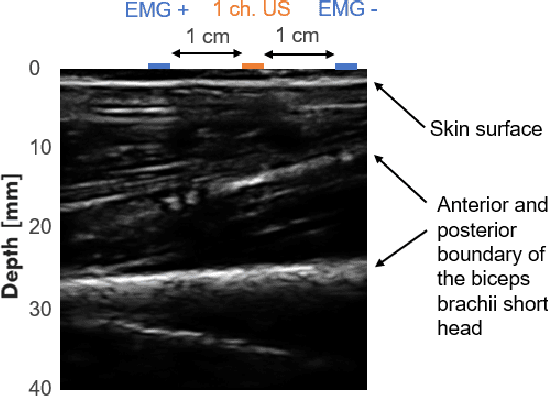
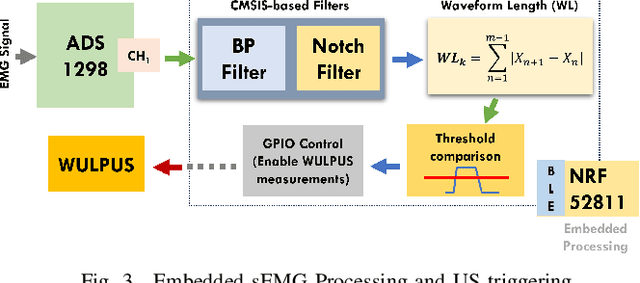
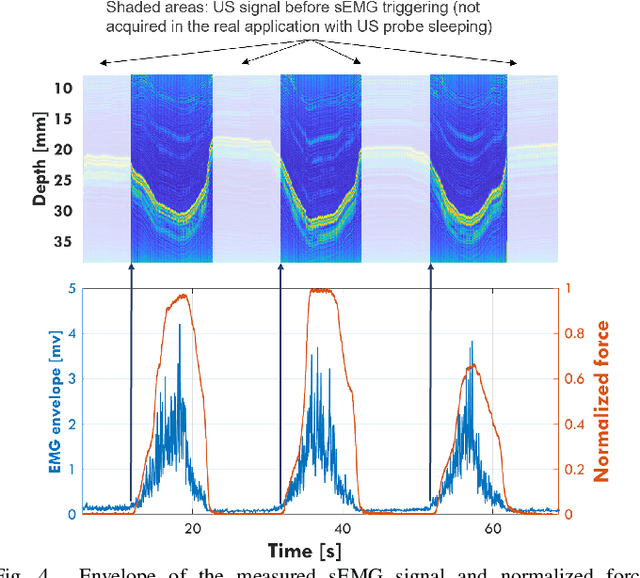
Surface electromyography (sEMG) is a well-established approach to monitor muscular activity on wearable and resource-constrained devices. However, when measuring deeper muscles, its low signal-to-noise ratio (SNR), high signal attenuation, and crosstalk degrade sensing performance. Ultrasound (US) complements sEMG effectively with its higher SNR at high penetration depths. In fact, combining US and sEMG improves the accuracy of muscle dynamic assessment, compared to using only one modality. However, the power envelope of US hardware is considerably higher than that of sEMG, thus inflating energy consumption and reducing the battery life. This work proposes a wearable solution that integrates both modalities and utilizes an EMG-driven wake-up approach to achieve ultra-low power consumption as needed for wearable long-term monitoring. We integrate two wearable state-of-the-art (SoA) US and ExG biosignal acquisition devices to acquire time-synchronized measurements of the short head of the biceps. To minimize power consumption, the US probe is kept in a sleep state when there is no muscle activity. sEMG data are processed on the probe (filtering, envelope extraction and thresholding) to identify muscle activity and generate a trigger to wake-up the US counterpart. The US acquisition starts before muscle fascicles displacement thanks to a triggering time faster than the electromechanical delay (30-100 ms) between the neuromuscular junction stimulation and the muscle contraction. Assuming a muscle contraction of 200 ms at a contraction rate of 1 Hz, the proposed approach enables more than 59% energy saving (with a full-system average power consumption of 12.2 mW) as compared to operating both sEMG and US continuously.
Market-GAN: Adding Control to Financial Market Data Generation with Semantic Context
Sep 14, 2023Financial simulators play an important role in enhancing forecasting accuracy, managing risks, and fostering strategic financial decision-making. Despite the development of financial market simulation methodologies, existing frameworks often struggle with adapting to specialized simulation context. We pinpoint the challenges as i) current financial datasets do not contain context labels; ii) current techniques are not designed to generate financial data with context as control, which demands greater precision compared to other modalities; iii) the inherent difficulties in generating context-aligned, high-fidelity data given the non-stationary, noisy nature of financial data. To address these challenges, our contributions are: i) we proposed the Contextual Market Dataset with market dynamics, stock ticker, and history state as context, leveraging a market dynamics modeling method that combines linear regression and Dynamic Time Warping clustering to extract market dynamics; ii) we present Market-GAN, a novel architecture incorporating a Generative Adversarial Networks (GAN) for the controllable generation with context, an autoencoder for learning low-dimension features, and supervisors for knowledge transfer; iii) we introduce a two-stage training scheme to ensure that Market-GAN captures the intrinsic market distribution with multiple objectives. In the pertaining stage, with the use of the autoencoder and supervisors, we prepare the generator with a better initialization for the adversarial training stage. We propose a set of holistic evaluation metrics that consider alignment, fidelity, data usability on downstream tasks, and market facts. We evaluate Market-GAN with the Dow Jones Industrial Average data from 2000 to 2023 and showcase superior performance in comparison to 4 state-of-the-art time-series generative models.