 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Data efficiency, dimensionality reduction, and the generalized symmetric information bottleneck
Sep 11, 2023
The Symmetric Information Bottleneck (SIB), an extension of the more familiar Information Bottleneck, is a dimensionality reduction technique that simultaneously compresses two random variables to preserve information between their compressed versions. We introduce the Generalized Symmetric Information Bottleneck (GSIB), which explores different functional forms of the cost of such simultaneous reduction. We then explore the dataset size requirements of such simultaneous compression. We do this by deriving bounds and root-mean-squared estimates of statistical fluctuations of the involved loss functions. We show that, in typical situations, the simultaneous GSIB compression requires qualitatively less data to achieve the same errors compared to compressing variables one at a time. We suggest that this is an example of a more general principle that simultaneous compression is more data efficient than independent compression of each of the input variables.
BodySLAM++: Fast and Tightly-Coupled Visual-Inertial Camera and Human Motion Tracking
Sep 03, 2023Robust, fast, and accurate human state - 6D pose and posture - estimation remains a challenging problem. For real-world applications, the ability to estimate the human state in real-time is highly desirable. In this paper, we present BodySLAM++, a fast, efficient, and accurate human and camera state estimation framework relying on visual-inertial data. BodySLAM++ extends an existing visual-inertial state estimation framework, OKVIS2, to solve the dual task of estimating camera and human states simultaneously. Our system improves the accuracy of both human and camera state estimation with respect to baseline methods by 26% and 12%, respectively, and achieves real-time performance at 15+ frames per second on an Intel i7-model CPU. Experiments were conducted on a custom dataset containing both ground truth human and camera poses collected with an indoor motion tracking system.
CPMR: Context-Aware Incremental Sequential Recommendation with Pseudo-Multi-Task Learning
Sep 16, 2023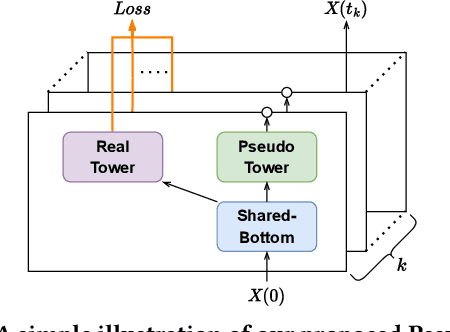


The motivations of users to make interactions can be divided into static preference and dynamic interest. To accurately model user representations over time, recent studies in sequential recommendation utilize information propagation and evolution to mine from batches of arriving interactions. However, they ignore the fact that people are easily influenced by the recent actions of other users in the contextual scenario, and applying evolution across all historical interactions dilutes the importance of recent ones, thus failing to model the evolution of dynamic interest accurately. To address this issue, we propose a Context-Aware Pseudo-Multi-Task Recommender System (CPMR) to model the evolution in both historical and contextual scenarios by creating three representations for each user and item under different dynamics: static embedding, historical temporal states, and contextual temporal states. To dually improve the performance of temporal states evolution and incremental recommendation, we design a Pseudo-Multi-Task Learning (PMTL) paradigm by stacking the incremental single-target recommendations into one multi-target task for joint optimization. Within the PMTL paradigm, CPMR employs a shared-bottom network to conduct the evolution of temporal states across historical and contextual scenarios, as well as the fusion of them at the user-item level. In addition, CPMR incorporates one real tower for incremental predictions, and two pseudo towers dedicated to updating the respective temporal states based on new batches of interactions. Experimental results on four benchmark recommendation datasets show that CPMR consistently outperforms state-of-the-art baselines and achieves significant gains on three of them. The code is available at: https://github.com/DiMarzioBian/CPMR.
* Accepted by CIKM 2023. Alias: "Modeling Context-Aware Temporal Dynamics via Pseudo-Multi-Task Learning"
Split Federated Learning for 6G Enabled-Networks: Requirements, Challenges and Future Directions
Sep 16, 2023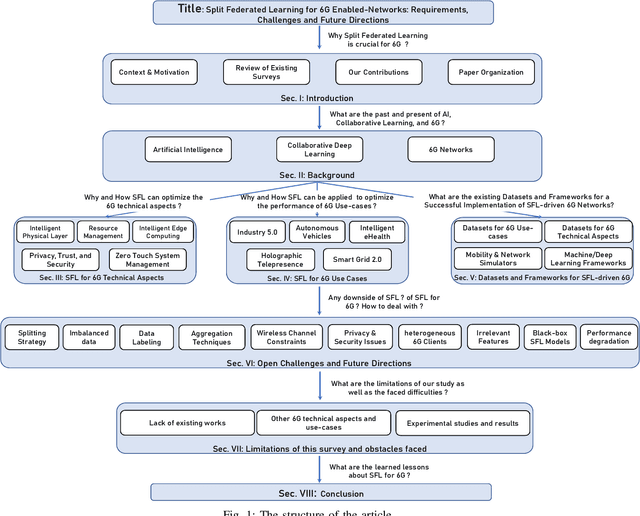
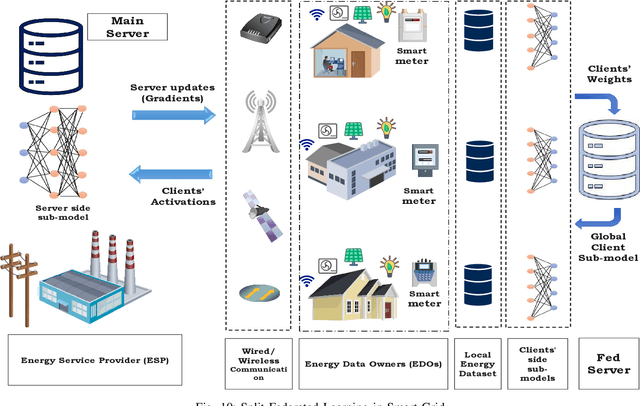
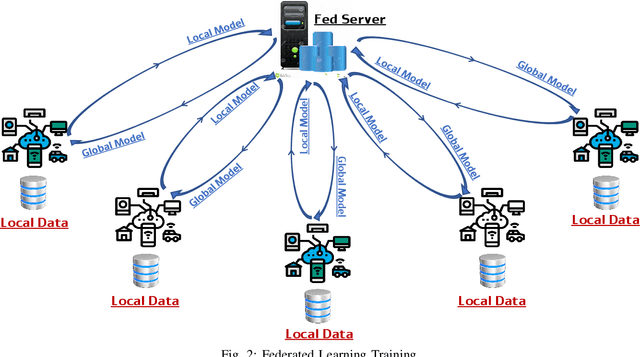
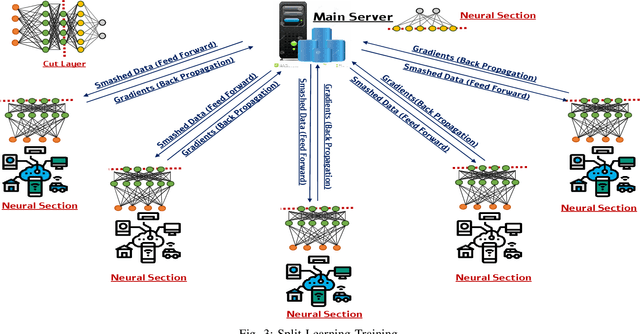
Sixth-generation (6G) networks anticipate intelligently supporting a wide range of smart services and innovative applications. Such a context urges a heavy usage of Machine Learning (ML) techniques, particularly Deep Learning (DL), to foster innovation and ease the deployment of intelligent network functions/operations, which are able to fulfill the various requirements of the envisioned 6G services. Specifically, collaborative ML/DL consists of deploying a set of distributed agents that collaboratively train learning models without sharing their data, thus improving data privacy and reducing the time/communication overhead. This work provides a comprehensive study on how collaborative learning can be effectively deployed over 6G wireless networks. In particular, our study focuses on Split Federated Learning (SFL), a technique recently emerged promising better performance compared with existing collaborative learning approaches. We first provide an overview of three emerging collaborative learning paradigms, including federated learning, split learning, and split federated learning, as well as of 6G networks along with their main vision and timeline of key developments. We then highlight the need for split federated learning towards the upcoming 6G networks in every aspect, including 6G technologies (e.g., intelligent physical layer, intelligent edge computing, zero-touch network management, intelligent resource management) and 6G use cases (e.g., smart grid 2.0, Industry 5.0, connected and autonomous systems). Furthermore, we review existing datasets along with frameworks that can help in implementing SFL for 6G networks. We finally identify key technical challenges, open issues, and future research directions related to SFL-enabled 6G networks.
Temporal Inductive Path Neural Network for Temporal Knowledge Graph Reasoning
Sep 06, 2023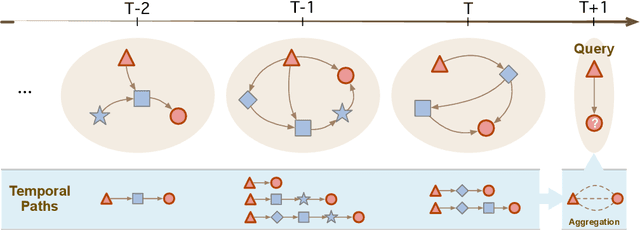

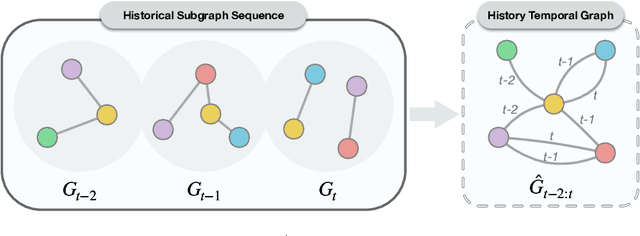
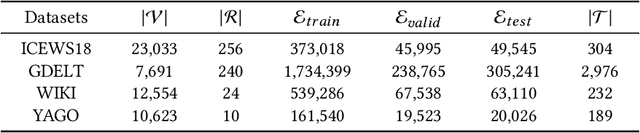
Temporal Knowledge Graph (TKG) is an extension of traditional Knowledge Graph (KG) that incorporates the dimension of time. Reasoning on TKGs is a crucial task that aims to predict future facts based on historical occurrences. The key challenge lies in uncovering structural dependencies within historical subgraphs and temporal patterns. Most existing approaches model TKGs relying on entity modeling, as nodes in the graph play a crucial role in knowledge representation. However, the real-world scenario often involves an extensive number of entities, with new entities emerging over time. This makes it challenging for entity-dependent methods to cope with extensive volumes of entities, and effectively handling newly emerging entities also becomes a significant challenge. Therefore, we propose Temporal Inductive Path Neural Network (TiPNN), which models historical information in an entity-independent perspective. Specifically, TiPNN adopts a unified graph, namely history temporal graph, to comprehensively capture and encapsulate information from history. Subsequently, we utilize the defined query-aware temporal paths to model historical path information related to queries on history temporal graph for the reasoning. Extensive experiments illustrate that the proposed model not only attains significant performance enhancements but also handles inductive settings, while additionally facilitating the provision of reasoning evidence through history temporal graphs.
RepSGG: Novel Representations of Entities and Relationships for Scene Graph Generation
Sep 06, 2023Scene Graph Generation (SGG) has achieved significant progress recently. However, most previous works rely heavily on fixed-size entity representations based on bounding box proposals, anchors, or learnable queries. As each representation's cardinality has different trade-offs between performance and computation overhead, extracting highly representative features efficiently and dynamically is both challenging and crucial for SGG. In this work, a novel architecture called RepSGG is proposed to address the aforementioned challenges, formulating a subject as queries, an object as keys, and their relationship as the maximum attention weight between pairwise queries and keys. With more fine-grained and flexible representation power for entities and relationships, RepSGG learns to sample semantically discriminative and representative points for relationship inference. Moreover, the long-tailed distribution also poses a significant challenge for generalization of SGG. A run-time performance-guided logit adjustment (PGLA) strategy is proposed such that the relationship logits are modified via affine transformations based on run-time performance during training. This strategy encourages a more balanced performance between dominant and rare classes. Experimental results show that RepSGG achieves the state-of-the-art or comparable performance on the Visual Genome and Open Images V6 datasets with fast inference speed, demonstrating the efficacy and efficiency of the proposed methods.
Non-Ideal Program-Time Conservation in Charge Trap Flash for Deep Learning
Jul 12, 2023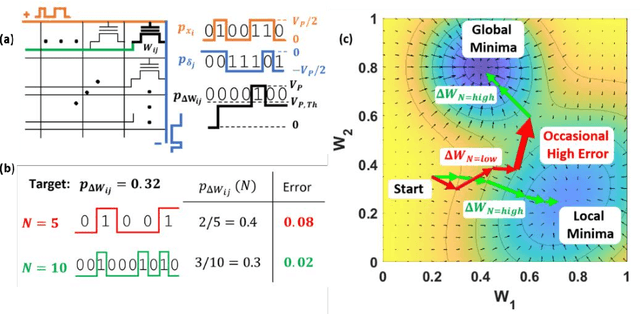
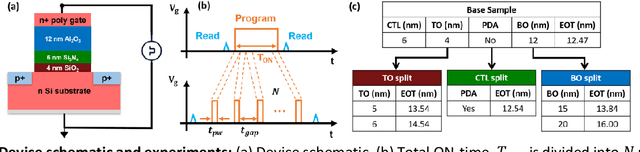
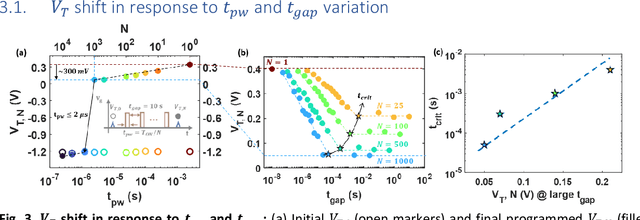
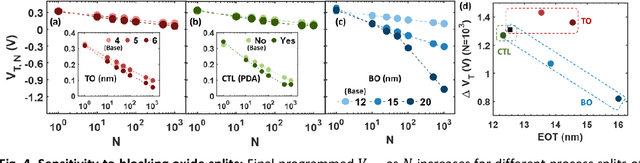
Training deep neural networks (DNNs) is computationally intensive but arrays of non-volatile memories like Charge Trap Flash (CTF) can accelerate DNN operations using in-memory computing. Specifically, the Resistive Processing Unit (RPU) architecture uses the voltage-threshold program by stochastic encoded pulse trains and analog memory features to accelerate vector-vector outer product and weight update for the gradient descent algorithms. Although CTF, offering high precision, has been regarded as an excellent choice for implementing RPU, the accumulation of charge due to the applied stochastic pulse trains is ultimately of critical significance in determining the final weight update. In this paper, we report the non-ideal program-time conservation in CTF through pulsing input measurements. We experimentally measure the effect of pulse width and pulse gap, keeping the total ON-time of the input pulse train constant, and report three non-idealities: (1) Cumulative V_T shift reduces when total ON-time is fragmented into a larger number of shorter pulses, (2) Cumulative V_T shift drops abruptly for pulse widths < 2 {\mu}s, (3) Cumulative V_T shift depends on the gap between consecutive pulses and the V_T shift reduction gets recovered for smaller gaps. We present an explanation based on a transient tunneling field enhancement due to blocking oxide trap-charge dynamics to explain these non-idealities. Identifying and modeling the responsible mechanisms and predicting their system-level effects during learning is critical. This non-ideal accumulation is expected to affect algorithms and architectures relying on devices for implementing mathematically equivalent functions for in-memory computing-based acceleration.
Spatio-Temporal Analysis of Patient-Derived Organoid Videos Using Deep Learning for the Prediction of Drug Efficacy
Aug 28, 2023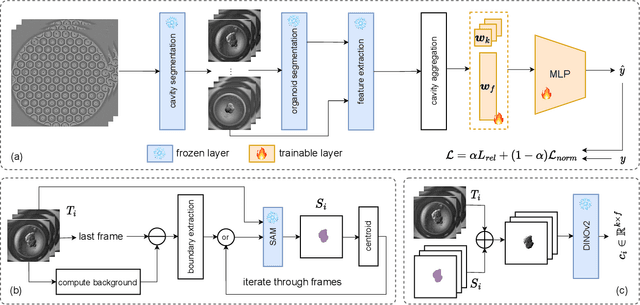

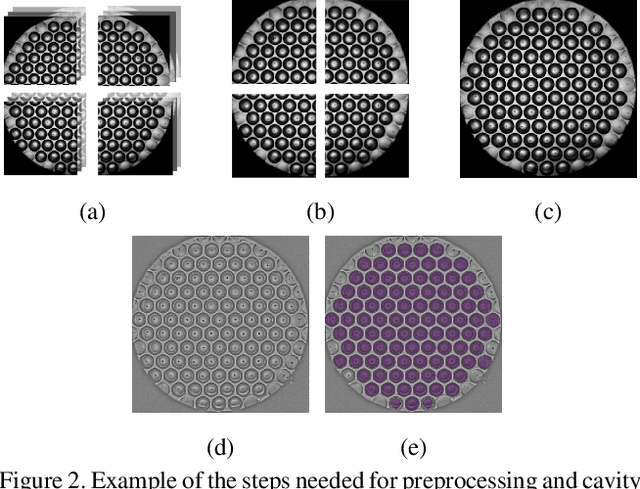

Over the last ten years, Patient-Derived Organoids (PDOs) emerged as the most reliable technology to generate ex-vivo tumor avatars. PDOs retain the main characteristics of their original tumor, making them a system of choice for pre-clinical and clinical studies. In particular, PDOs are attracting interest in the field of Functional Precision Medicine (FPM), which is based upon an ex-vivo drug test in which living tumor cells (such as PDOs) from a specific patient are exposed to a panel of anti-cancer drugs. Currently, the Adenosine Triphosphate (ATP) based cell viability assay is the gold standard test to assess the sensitivity of PDOs to drugs. The readout is measured at the end of the assay from a global PDO population and therefore does not capture single PDO responses and does not provide time resolution of drug effect. To this end, in this study, we explore for the first time the use of powerful large foundation models for the automatic processing of PDO data. In particular, we propose a novel imaging-based high-throughput screening method to assess real-time drug efficacy from a time-lapse microscopy video of PDOs. The recently proposed SAM algorithm for segmentation and DINOv2 model are adapted in a comprehensive pipeline for processing PDO microscopy frames. Moreover, an attention mechanism is proposed for fusing temporal and spatial features in a multiple instance learning setting to predict ATP. We report better results than other non-time-resolved methods, indicating that the temporality of data is an important factor for the prediction of ATP. Extensive ablations shed light on optimizing the experimental setting and automating the prediction both in real-time and for forecasting.
Enhancing Continuous Time Series Modelling with a Latent ODE-LSTM Approach
Jul 11, 2023
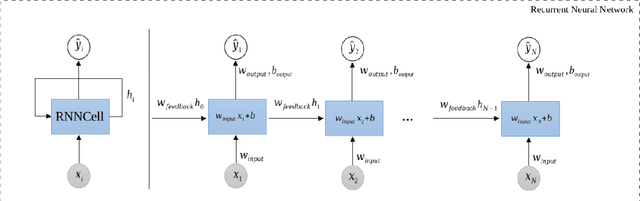
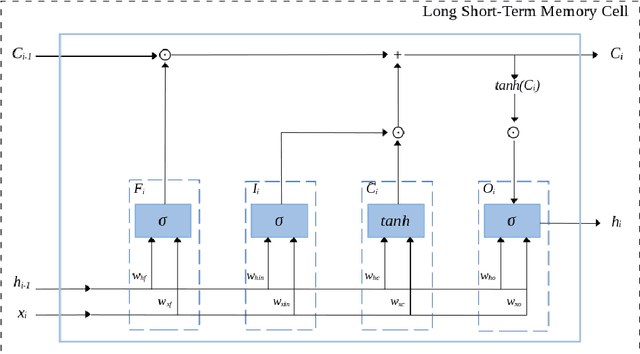

Due to their dynamic properties such as irregular sampling rate and high-frequency sampling, Continuous Time Series (CTS) are found in many applications. Since CTS with irregular sampling rate are difficult to model with standard Recurrent Neural Networks (RNNs), RNNs have been generalised to have continuous-time hidden dynamics defined by a Neural Ordinary Differential Equation (Neural ODE), leading to the ODE-RNN model. Another approach that provides a better modelling is that of the Latent ODE model, which constructs a continuous-time model where a latent state is defined at all times. The Latent ODE model uses a standard RNN as the encoder and a Neural ODE as the decoder. However, since the RNN encoder leads to difficulties with missing data and ill-defined latent variables, a Latent ODE-RNN model has recently been proposed that uses a ODE-RNN model as the encoder instead. Both the Latent ODE and Latent ODE-RNN models are difficult to train due to the vanishing and exploding gradients problem. To overcome this problem, the main contribution of this paper is to propose and illustrate a new model based on a new Latent ODE using an ODE-LSTM (Long Short-Term Memory) network as an encoder -- the Latent ODE-LSTM model. To limit the growth of the gradients the Norm Gradient Clipping strategy was embedded on the Latent ODE-LSTM model. The performance evaluation of the new Latent ODE-LSTM (with and without Norm Gradient Clipping) for modelling CTS with regular and irregular sampling rates is then demonstrated. Numerical experiments show that the new Latent ODE-LSTM performs better than Latent ODE-RNNs and can avoid the vanishing and exploding gradients during training.
Clinical Text Summarization: Adapting Large Language Models Can Outperform Human Experts
Sep 14, 2023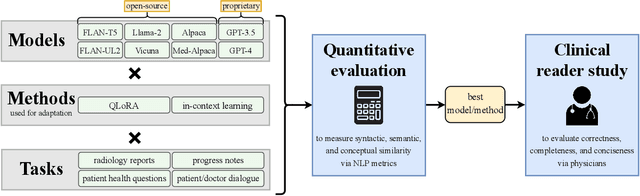
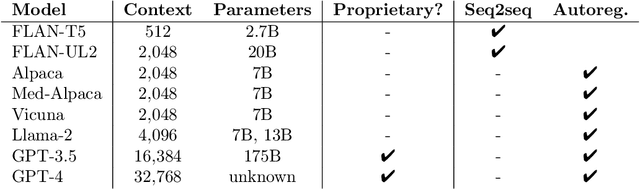
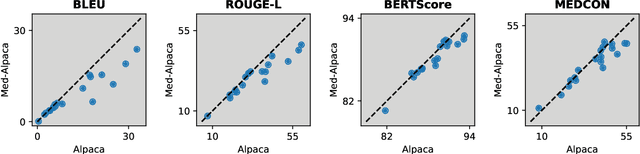

Sifting through vast textual data and summarizing key information imposes a substantial burden on how clinicians allocate their time. Although large language models (LLMs) have shown immense promise in natural language processing (NLP) tasks, their efficacy across diverse clinical summarization tasks has not yet been rigorously examined. In this work, we employ domain adaptation methods on eight LLMs, spanning six datasets and four distinct summarization tasks: radiology reports, patient questions, progress notes, and doctor-patient dialogue. Our thorough quantitative assessment reveals trade-offs between models and adaptation methods in addition to instances where recent advances in LLMs may not lead to improved results. Further, in a clinical reader study with six physicians, we depict that summaries from the best adapted LLM are preferable to human summaries in terms of completeness and correctness. Our ensuing qualitative analysis delineates mutual challenges faced by both LLMs and human experts. Lastly, we correlate traditional quantitative NLP metrics with reader study scores to enhance our understanding of how these metrics align with physician preferences. Our research marks the first evidence of LLMs outperforming human experts in clinical text summarization across multiple tasks. This implies that integrating LLMs into clinical workflows could alleviate documentation burden, empowering clinicians to focus more on personalized patient care and other irreplaceable human aspects of medicine.