 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Continual Learning with Dirichlet Generative-based Rehearsal
Sep 13, 2023
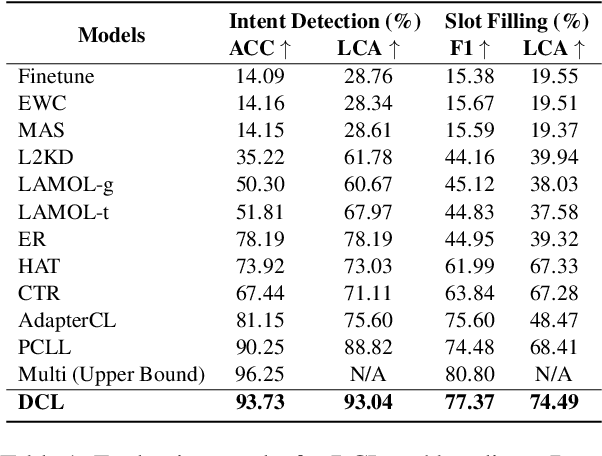
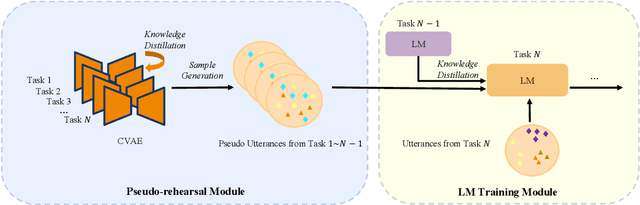
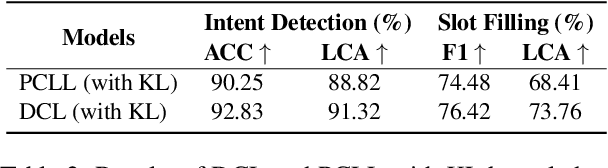
Recent advancements in data-driven task-oriented dialogue systems (ToDs) struggle with incremental learning due to computational constraints and time-consuming issues. Continual Learning (CL) attempts to solve this by avoiding intensive pre-training, but it faces the problem of catastrophic forgetting (CF). While generative-based rehearsal CL methods have made significant strides, generating pseudo samples that accurately reflect the underlying task-specific distribution is still a challenge. In this paper, we present Dirichlet Continual Learning (DCL), a novel generative-based rehearsal strategy for CL. Unlike the traditionally used Gaussian latent variable in the Conditional Variational Autoencoder (CVAE), DCL leverages the flexibility and versatility of the Dirichlet distribution to model the latent prior variable. This enables it to efficiently capture sentence-level features of previous tasks and effectively guide the generation of pseudo samples. In addition, we introduce Jensen-Shannon Knowledge Distillation (JSKD), a robust logit-based knowledge distillation method that enhances knowledge transfer during pseudo sample generation. Our experiments confirm the efficacy of our approach in both intent detection and slot-filling tasks, outperforming state-of-the-art methods.
EgoPoser: Robust Real-Time Ego-Body Pose Estimation in Large Scenes
Aug 17, 2023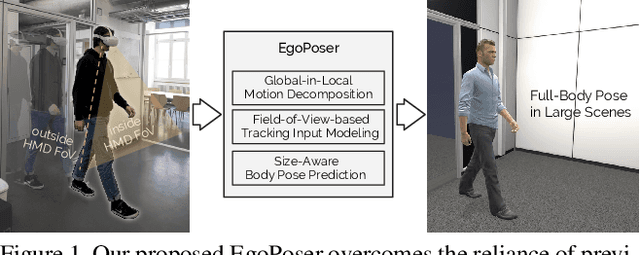

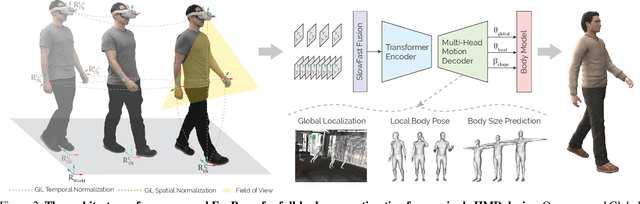

Full-body ego-pose estimation from head and hand poses alone has become an active area of research to power articulate avatar representation on headset-based platforms. However, existing methods over-rely on the confines of the motion-capture spaces in which datasets were recorded, while simultaneously assuming continuous capture of joint motions and uniform body dimensions. In this paper, we propose EgoPoser, which overcomes these limitations by 1) rethinking the input representation for headset-based ego-pose estimation and introducing a novel motion decomposition method that predicts full-body pose independent of global positions, 2) robustly modeling body pose from intermittent hand position and orientation tracking only when inside a headset's field of view, and 3) generalizing across various body sizes for different users. Our experiments show that EgoPoser outperforms state-of-the-art methods both qualitatively and quantitatively, while maintaining a high inference speed of over 600 fps. EgoPoser establishes a robust baseline for future work, where full-body pose estimation needs no longer rely on outside-in capture and can scale to large-scene environments.
Rail Crack Propagation Forecasting Using Multi-horizons RNNs
Sep 04, 2023The prediction of rail crack length propagation plays a crucial role in the maintenance and safety assessment of materials and structures. Traditional methods rely on physical models and empirical equations such as Paris law, which often have limitations in capturing the complex nature of crack growth. In recent years, machine learning techniques, particularly Recurrent Neural Networks (RNNs), have emerged as promising methods for time series forecasting. They allow to model time series data, and to incorporate exogenous variables into the model. The proposed approach involves collecting real data on the French rail network that includes historical crack length measurements, along with relevant exogenous factors that may influence crack growth. First, a pre-processing phase was performed to prepare a consistent data set for learning. Then, a suitable Bayesian multi-horizons recurrent architecture was designed to model the crack propagation phenomenon. Obtained results show that the Multi-horizons model outperforms state-of-the-art models such as LSTM and GRU.
Sleep Stage Classification Using a Pre-trained Deep Learning Model
Sep 12, 2023One of the common human diseases is sleep disorders. The classification of sleep stages plays a fundamental role in diagnosing sleep disorders, monitoring treatment effectiveness, and understanding the relationship between sleep stages and various health conditions. A precise and efficient classification of these stages can significantly enhance our understanding of sleep-related phenomena and ultimately lead to improved health outcomes and disease treatment. Models others propose are often time-consuming and lack sufficient accuracy, especially in stage N1. The main objective of this research is to present a machine-learning model called "EEGMobile". This model utilizes pre-trained models and learns from electroencephalogram (EEG) spectrograms of brain signals. The model achieved an accuracy of 86.97% on a publicly available dataset named "Sleep-EDF20", outperforming other models proposed by different researchers. Moreover, it recorded an accuracy of 56.4% in stage N1, which is better than other models. These findings demonstrate that this model has the potential to achieve better results for the treatment of this disease.
SCP: Scene Completion Pre-training for 3D Object Detection
Sep 12, 2023
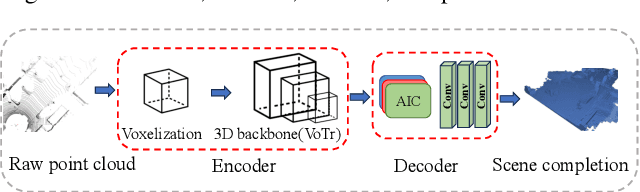
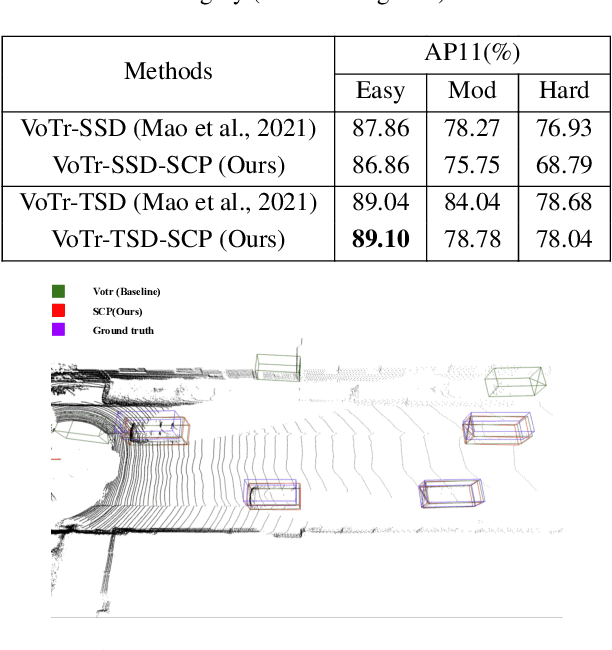
3D object detection using LiDAR point clouds is a fundamental task in the fields of computer vision, robotics, and autonomous driving. However, existing 3D detectors heavily rely on annotated datasets, which are both time-consuming and prone to errors during the process of labeling 3D bounding boxes. In this paper, we propose a Scene Completion Pre-training (SCP) method to enhance the performance of 3D object detectors with less labeled data. SCP offers three key advantages: (1) Improved initialization of the point cloud model. By completing the scene point clouds, SCP effectively captures the spatial and semantic relationships among objects within urban environments. (2) Elimination of the need for additional datasets. SCP serves as a valuable auxiliary network that does not impose any additional efforts or data requirements on the 3D detectors. (3) Reduction of the amount of labeled data for detection. With the help of SCP, the existing state-of-the-art 3D detectors can achieve comparable performance while only relying on 20% labeled data.
GVD-Exploration: An Efficient Autonomous Robot Exploration Framework Based on Fast Generalized Voronoi Diagram Extraction
Sep 12, 2023Rapidly-exploring Random Trees (RRTs) are a popular technique for autonomous exploration of mobile robots. However, the random sampling used by RRTs can result in inefficient and inaccurate frontiers extraction, which affects the exploration performance. To address the issues of slow path planning and high path cost, we propose a framework that uses a generalized Voronoi diagram (GVD) based multi-choice strategy for robot exploration. Our framework consists of three components: a novel mapping model that uses an end-to-end neural network to construct GVDs of the environments in real time; a GVD-based heuristic scheme that accelerates frontiers extraction and reduces frontiers redundancy; and a multi-choice frontiers assignment scheme that considers different types of frontiers and enables the robot to make rational decisions during the exploration process. We evaluate our method on simulation and real-world experiments and show that it outperforms RRT-based exploration methods in terms of efficiency and robustness.
MultiWay-Adapater: Adapting large-scale multi-modal models for scalable image-text retrieval
Sep 12, 2023As the size of Large Multi-Modal Models (LMMs) increases consistently, the adaptation of these pre-trained models to specialized tasks has become a computationally and memory-intensive challenge. Traditional fine-tuning methods require isolated, exhaustive retuning for each new task, limiting the models' versatility. Moreover, current efficient adaptation techniques often overlook modality alignment, focusing only on the knowledge extraction of new tasks. To tackle these issues, we introduce Multiway-Adapter, an innovative framework incorporating an 'Alignment Enhancer' to deepen modality alignment, enabling high transferability without tuning pre-trained parameters. Our method adds fewer than 1.25\% of additional parameters to LMMs, exemplified by the BEiT-3 model in our study. This leads to superior zero-shot image-text retrieval performance compared to fully fine-tuned models, while achieving up to a 57\% reduction in fine-tuning time. Our approach offers a resource-efficient and effective adaptation pathway for LMMs, broadening their applicability. The source code is publicly available at: \url{https://github.com/longkukuhi/MultiWay-Adapter}.
SlideSpeech: A Large-Scale Slide-Enriched Audio-Visual Corpus
Sep 12, 2023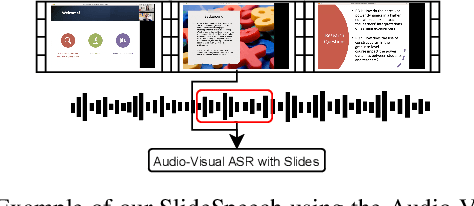
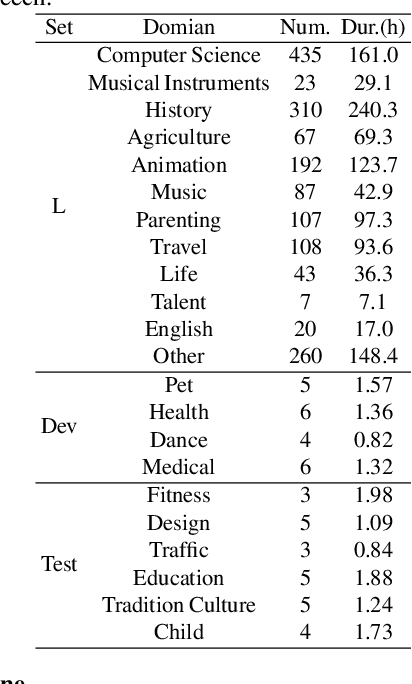
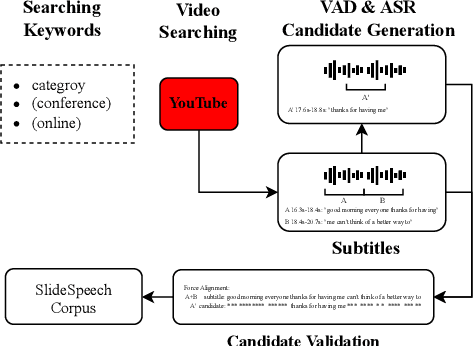

Multi-Modal automatic speech recognition (ASR) techniques aim to leverage additional modalities to improve the performance of speech recognition systems. While existing approaches primarily focus on video or contextual information, the utilization of extra supplementary textual information has been overlooked. Recognizing the abundance of online conference videos with slides, which provide rich domain-specific information in the form of text and images, we release SlideSpeech, a large-scale audio-visual corpus enriched with slides. The corpus contains 1,705 videos, 1,000+ hours, with 473 hours of high-quality transcribed speech. Moreover, the corpus contains a significant amount of real-time synchronized slides. In this work, we present the pipeline for constructing the corpus and propose baseline methods for utilizing text information in the visual slide context. Through the application of keyword extraction and contextual ASR methods in the benchmark system, we demonstrate the potential of improving speech recognition performance by incorporating textual information from supplementary video slides.
A New Deep State-Space Analysis Framework for Patient Latent State Estimation and Classification from EHR Time Series Data
Jul 21, 2023Many diseases, including cancer and chronic conditions, require extended treatment periods and long-term strategies. Machine learning and AI research focusing on electronic health records (EHRs) have emerged to address this need. Effective treatment strategies involve more than capturing sequential changes in patient test values. It requires an explainable and clinically interpretable model by capturing the patient's internal state over time. In this study, we propose the "deep state-space analysis framework," using time-series unsupervised learning of EHRs with a deep state-space model. This framework enables learning, visualizing, and clustering of temporal changes in patient latent states related to disease progression. We evaluated our framework using time-series laboratory data from 12,695 cancer patients. By estimating latent states, we successfully discover latent states related to prognosis. By visualization and cluster analysis, the temporal transition of patient status and test items during state transitions characteristic of each anticancer drug were identified. Our framework surpasses existing methods in capturing interpretable latent space. It can be expected to enhance our comprehension of disease progression from EHRs, aiding treatment adjustments and prognostic determinations.
A Natural Gas Consumption Forecasting System for Continual Learning Scenarios based on Hoeffding Trees with Change Point Detection Mechanism
Sep 07, 2023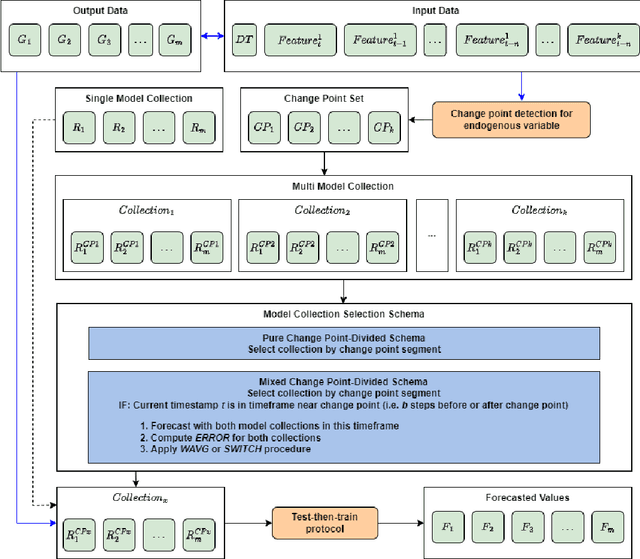
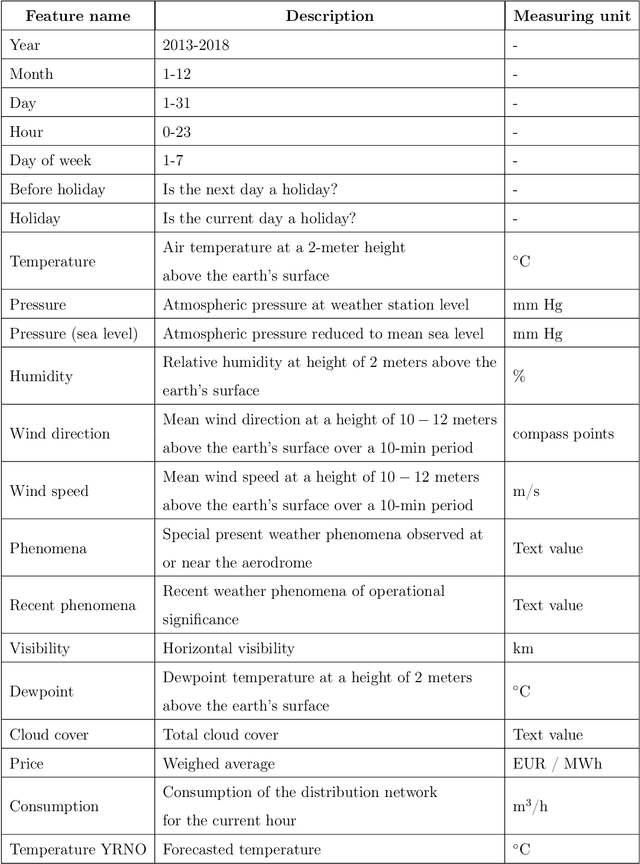
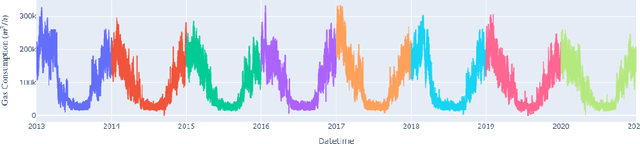
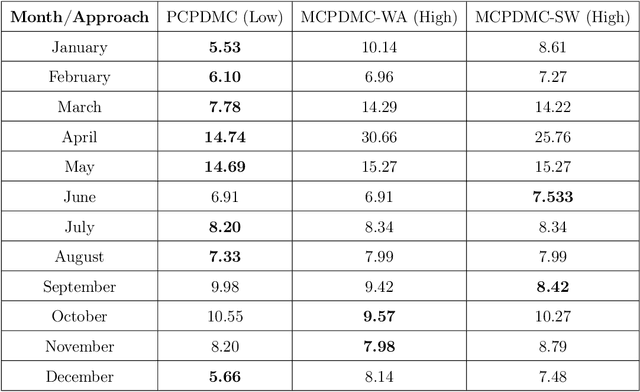
Forecasting natural gas consumption, considering seasonality and trends, is crucial in planning its supply and consumption and optimizing the cost of obtaining it, mainly by industrial entities. However, in times of threats to its supply, it is also a critical element that guarantees the supply of this raw material to meet individual consumers' needs, ensuring society's energy security. This article introduces a novel multistep ahead forecasting of natural gas consumption with change point detection integration for model collection selection with continual learning capabilities using data stream processing. The performance of the forecasting models based on the proposed approach is evaluated in a complex real-world use case of natural gas consumption forecasting. We employed Hoeffding tree predictors as forecasting models and the Pruned Exact Linear Time (PELT) algorithm for the change point detection procedure. The change point detection integration enables selecting a different model collection for successive time frames. Thus, three model collection selection procedures (with and without an error feedback loop) are defined and evaluated for forecasting scenarios with various densities of detected change points. These models were compared with change point agnostic baseline approaches. Our experiments show that fewer change points result in a lower forecasting error regardless of the model collection selection procedure employed. Also, simpler model collection selection procedures omitting forecasting error feedback leads to more robust forecasting models suitable for continual learning tasks.