 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Desenvolvimento de modelo para predição de cotações de ação baseada em análise de sentimentos de tweets
Sep 11, 2023
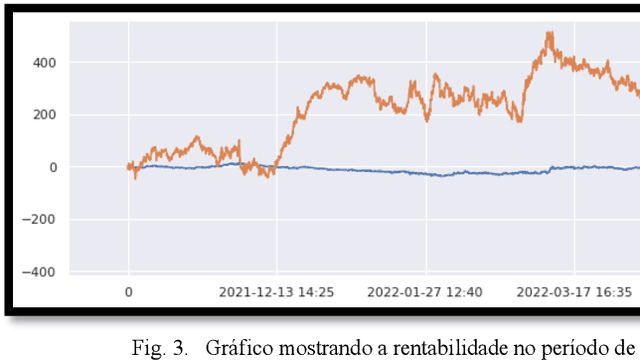
Training machine learning models for predicting stock market share prices is an active area of research since the automatization of trading such papers was available in real time. While most of the work in this field of research is done by training Neural networks based on past prices of stock shares, in this work, we use iFeel 2.0 platform to extract 19 sentiment features from posts obtained from microblog platform Twitter that mention the company Petrobras. Then, we used those features to train XBoot models to predict future stock prices for the referred company. Later, we simulated the trading of Petrobras' shares based on the model's outputs and determined the gain of R$88,82 (net) in a 250-day period when compared to a 100 random models' average performance.
* in Portuguese language, Presented at: 1o Semin\'ario de Ci\^encia de Dados do IFSP. Campinas: 2023
Energy Preservation and Stability of Random Filterbanks
Sep 11, 2023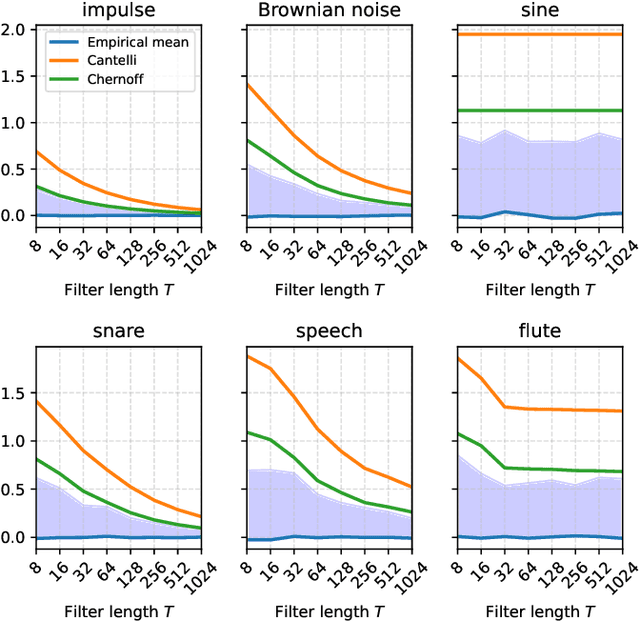
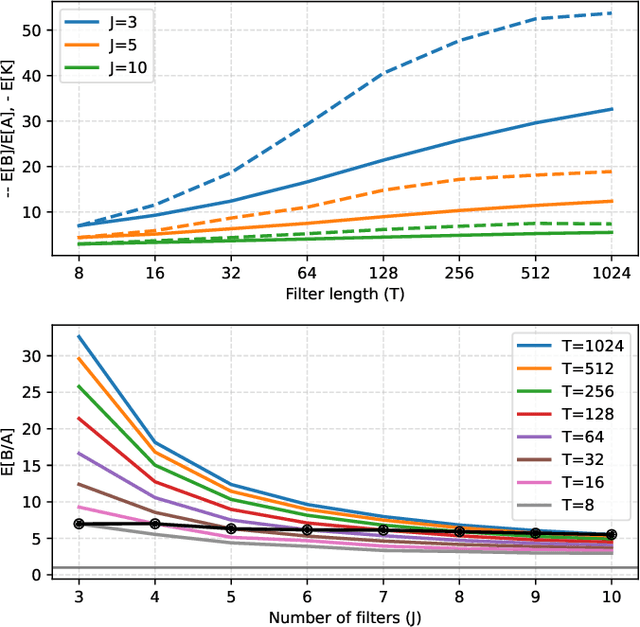
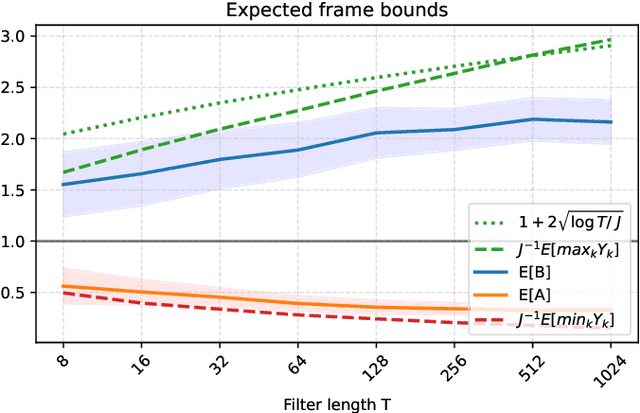
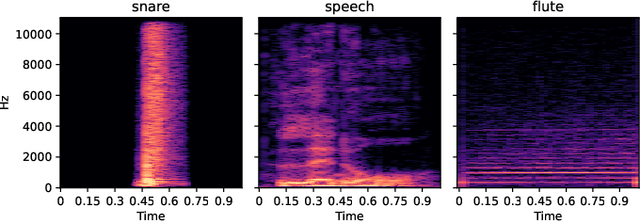
What makes waveform-based deep learning so hard? Despite numerous attempts at training convolutional neural networks (convnets) for filterbank design, they often fail to outperform hand-crafted baselines. This is all the more surprising because these baselines are linear time-invariant systems: as such, their transfer functions could be accurately represented by a convnet with a large receptive field. In this article, we elaborate on the statistical properties of simple convnets from the mathematical perspective of random convolutional operators. We find that FIR filterbanks with random Gaussian weights are ill-conditioned for large filters and locally periodic input signals, which both are typical in audio signal processing applications. Furthermore, we observe that expected energy preservation of a random filterbank is not sufficient for numerical stability and derive theoretical bounds for its expected frame bounds.
An Explicit Method for Fast Monocular Depth Recovery in Corridor Environments
Sep 14, 2023Monocular cameras are extensively employed in indoor robotics, but their performance is limited in visual odometry, depth estimation, and related applications due to the absence of scale information.Depth estimation refers to the process of estimating a dense depth map from the corresponding input image, existing researchers mostly address this issue through deep learning-based approaches, yet their inference speed is slow, leading to poor real-time capabilities. To tackle this challenge, we propose an explicit method for rapid monocular depth recovery specifically designed for corridor environments, leveraging the principles of nonlinear optimization. We adopt the virtual camera assumption to make full use of the prior geometric features of the scene. The depth estimation problem is transformed into an optimization problem by minimizing the geometric residual. Furthermore, a novel depth plane construction technique is introduced to categorize spatial points based on their possible depths, facilitating swift depth estimation in enclosed structural scenarios, such as corridors. We also propose a new corridor dataset, named Corr\_EH\_z, which contains images as captured by the UGV camera of a variety of corridors. An exhaustive set of experiments in different corridors reveal the efficacy of the proposed algorithm.
RecycleNet: Latent Feature Recycling Leads to Iterative Decision Refinement
Sep 14, 2023Despite the remarkable success of deep learning systems over the last decade, a key difference still remains between neural network and human decision-making: As humans, we cannot only form a decision on the spot, but also ponder, revisiting an initial guess from different angles, distilling relevant information, arriving at a better decision. Here, we propose RecycleNet, a latent feature recycling method, instilling the pondering capability for neural networks to refine initial decisions over a number of recycling steps, where outputs are fed back into earlier network layers in an iterative fashion. This approach makes minimal assumptions about the neural network architecture and thus can be implemented in a wide variety of contexts. Using medical image segmentation as the evaluation environment, we show that latent feature recycling enables the network to iteratively refine initial predictions even beyond the iterations seen during training, converging towards an improved decision. We evaluate this across a variety of segmentation benchmarks and show consistent improvements even compared with top-performing segmentation methods. This allows trading increased computation time for improved performance, which can be beneficial, especially for safety-critical applications.
Research on self-cross transformer model of point cloud change detecter
Sep 14, 2023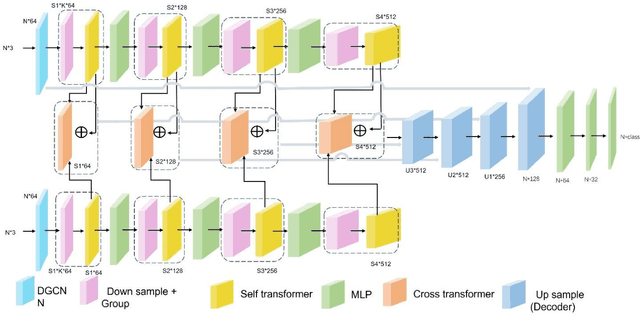

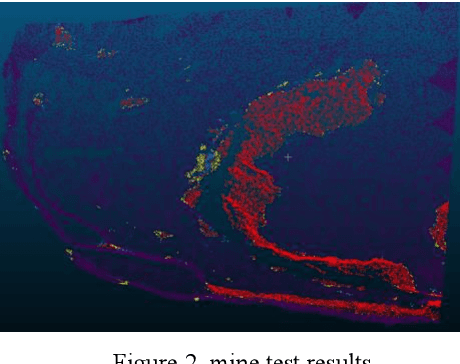
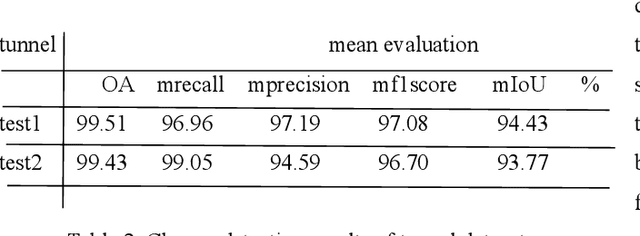
With the vigorous development of the urban construction industry, engineering deformation or changes often occur during the construction process. To combat this phenomenon, it is necessary to detect changes in order to detect construction loopholes in time, ensure the integrity of the project and reduce labor costs. Or the inconvenience and injuriousness of the road. In the study of change detection in 3D point clouds, researchers have published various research methods on 3D point clouds. Directly based on but mostly based ontraditional threshold distance methods (C2C, M3C2, M3C2-EP), and some are to convert 3D point clouds into DSM, which loses a lot of original information. Although deep learning is used in remote sensing methods, in terms of change detection of 3D point clouds, it is more converted into two-dimensional patches, and neural networks are rarely applied directly. We prefer that the network is given at the level of pixels or points. Variety. Therefore, in this article, our network builds a network for 3D point cloud change detection, and proposes a new module Cross transformer suitable for change detection. Simultaneously simulate tunneling data for change detection, and do test experiments with our network.
Tightening Classification Boundaries in Open Set Domain Adaptation through Unknown Exploitation
Sep 16, 2023Convolutional Neural Networks (CNNs) have brought revolutionary advances to many research areas due to their capacity of learning from raw data. However, when those methods are applied to non-controllable environments, many different factors can degrade the model's expected performance, such as unlabeled datasets with different levels of domain shift and category shift. Particularly, when both issues occur at the same time, we tackle this challenging setup as Open Set Domain Adaptation (OSDA) problem. In general, existing OSDA approaches focus their efforts only on aligning known classes or, if they already extract possible negative instances, use them as a new category learned with supervision during the course of training. We propose a novel way to improve OSDA approaches by extracting a high-confidence set of unknown instances and using it as a hard constraint to tighten the classification boundaries of OSDA methods. Especially, we adopt a new loss constraint evaluated in three different means, (1) directly with the pristine negative instances; (2) with randomly transformed negatives using data augmentation techniques; and (3) with synthetically generated negatives containing adversarial features. We assessed all approaches in an extensive set of experiments based on OVANet, where we could observe consistent improvements for two public benchmarks, the Office-31 and Office-Home datasets, yielding absolute gains of up to 1.3% for both Accuracy and H-Score on Office-31 and 5.8% for Accuracy and 4.7% for H-Score on Office-Home.
Trajectory Tracking Control of Skid-Steering Mobile Robots with Slip and Skid Compensation using Sliding-Mode Control and Deep Learning
Sep 16, 2023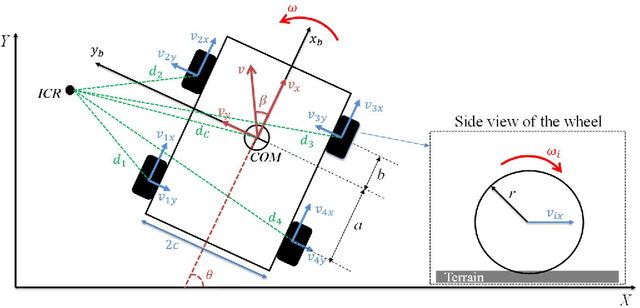
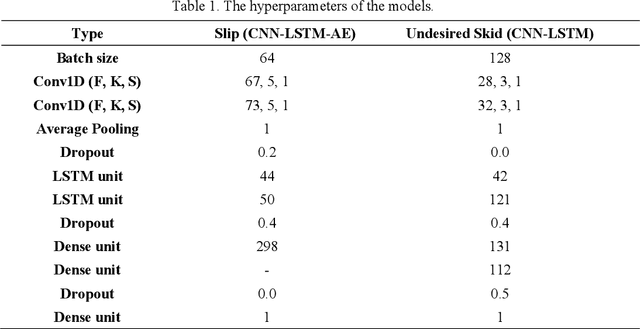
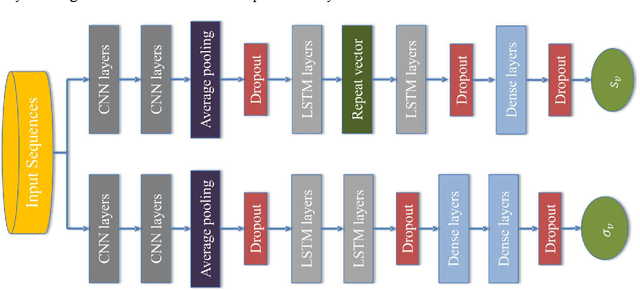
Slip and skid compensation is crucial for mobile robots' navigation in outdoor environments and uneven terrains. In addition to the general slipping and skidding hazards for mobile robots in outdoor environments, slip and skid cause uncertainty for the trajectory tracking system and put the validity of stability analysis at risk. Despite research in this field, having a real-world feasible online slip and skid compensation is still challenging due to the complexity of wheel-terrain interaction in outdoor environments. This paper presents a novel trajectory tracking technique with real-world feasible online slip and skid compensation at the vehicle-level for skid-steering mobile robots in outdoor environments. The sliding mode control technique is utilized to design a robust trajectory tracking system to be able to consider the parameter uncertainty of this type of robot. Two previously developed deep learning models [1], [2] are integrated into the control feedback loop to estimate the robot's slipping and undesired skidding and feed the compensator in a real-time manner. The main advantages of the proposed technique are (1) considering two slip-related parameters rather than the conventional three slip parameters at the wheel-level, and (2) having an online real-world feasible slip and skid compensator to be able to reduce the tracking errors in unforeseen environments. The experimental results show that the proposed controller with the slip and skid compensator improves the performance of the trajectory tracking system by more than 27%.
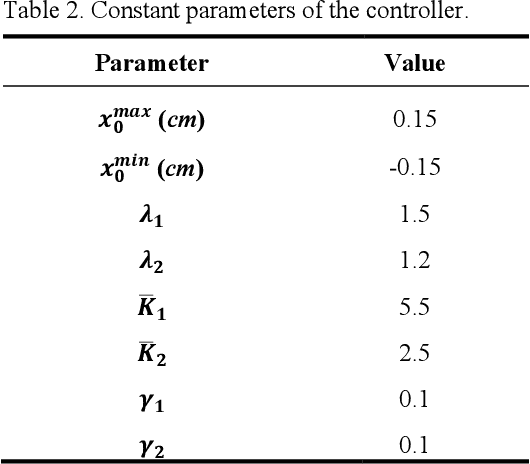
Combining Thermodynamics-based Model of the Centrifugal Compressors and Active Machine Learning for Enhanced Industrial Design Optimization
Sep 06, 2023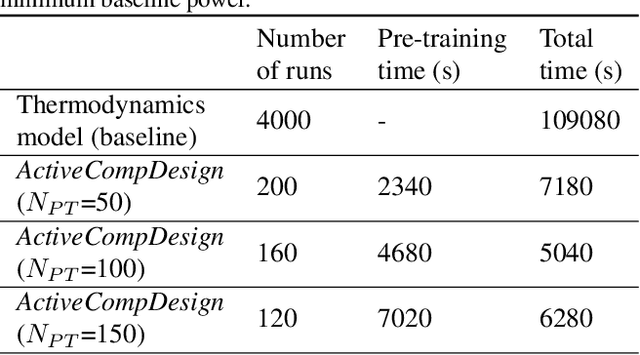
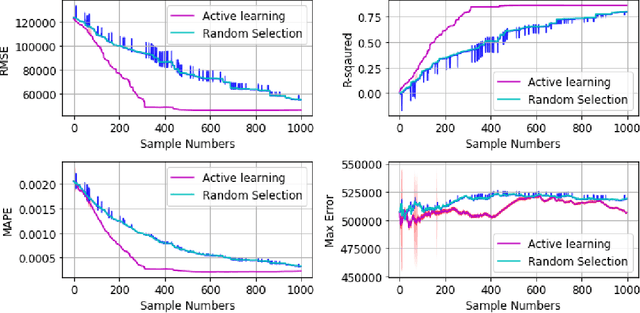
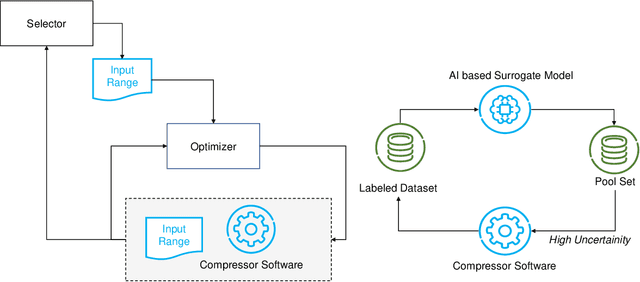
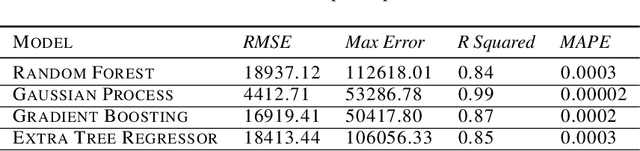
The design process of centrifugal compressors requires applying an optimization process which is computationally expensive due to complex analytical equations underlying the compressor's dynamical equations. Although the regression surrogate models could drastically reduce the computational cost of such a process, the major challenge is the scarcity of data for training the surrogate model. Aiming to strategically exploit the labeled samples, we propose the Active-CompDesign framework in which we combine a thermodynamics-based compressor model (i.e., our internal software for compressor design) and Gaussian Process-based surrogate model within a deployable Active Learning (AL) setting. We first conduct experiments in an offline setting and further, extend it to an online AL framework where a real-time interaction with the thermodynamics-based compressor's model allows the deployment in production. ActiveCompDesign shows a significant performance improvement in surrogate modeling by leveraging on uncertainty-based query function of samples within the AL framework with respect to the random selection of data points. Moreover, our framework in production has reduced the total computational time of compressor's design optimization to around 46% faster than relying on the internal thermodynamics-based simulator, achieving the same performance.
Sparse-firing regularization methods for spiking neural networks with time-to-first spike coding
Jul 24, 2023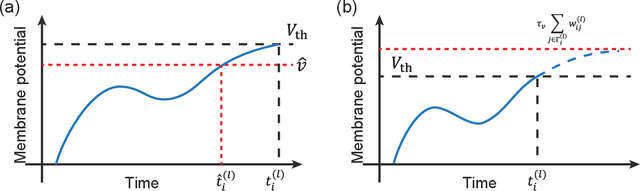
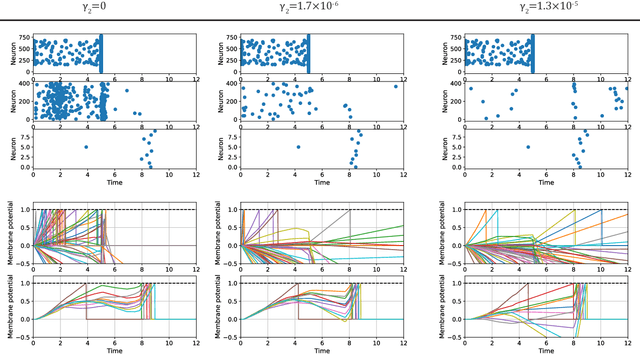
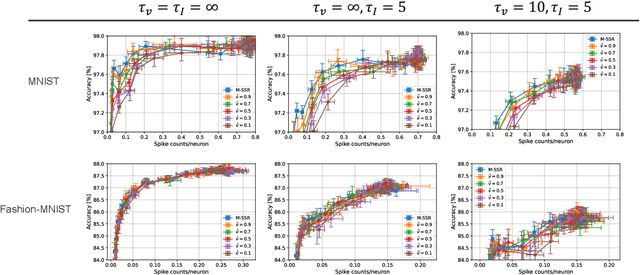
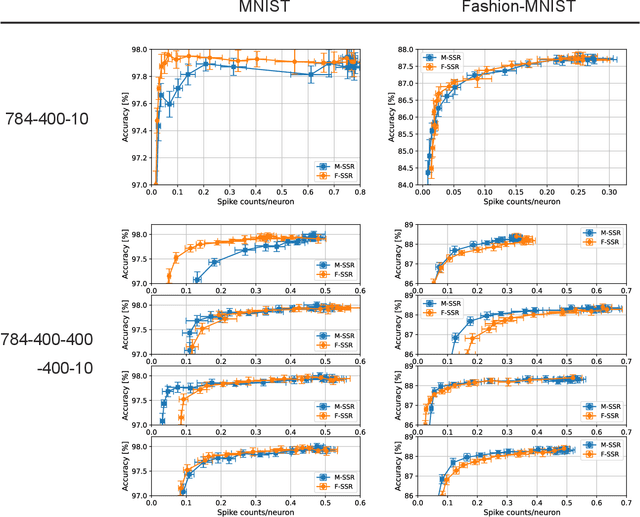
The training of multilayer spiking neural networks (SNNs) using the error backpropagation algorithm has made significant progress in recent years. Among the various training schemes, the error backpropagation method that directly uses the firing time of neurons has attracted considerable attention because it can realize ideal temporal coding. This method uses time-to-first spike (TTFS) coding, in which each neuron fires at most once, and this restriction on the number of firings enables information to be processed at a very low firing frequency. This low firing frequency increases the energy efficiency of information processing in SNNs, which is important not only because of its similarity with information processing in the brain, but also from an engineering point of view. However, only an upper limit has been provided for TTFS-coded SNNs, and the information-processing capability of SNNs at lower firing frequencies has not been fully investigated. In this paper, we propose two spike timing-based sparse-firing (SSR) regularization methods to further reduce the firing frequency of TTFS-coded SNNs. The first is the membrane potential-aware SSR (M-SSR) method, which has been derived as an extreme form of the loss function of the membrane potential value. The second is the firing condition-aware SSR (F-SSR) method, which is a regularization function obtained from the firing conditions. Both methods are characterized by the fact that they only require information about the firing timing and associated weights. The effects of these regularization methods were investigated on the MNIST, Fashion-MNIST, and CIFAR-10 datasets using multilayer perceptron networks and convolutional neural network structures.
Optical Fiber-Based Needle Shape Sensing in Real Tissue: Single Core vs. Multicore Approaches
Sep 08, 2023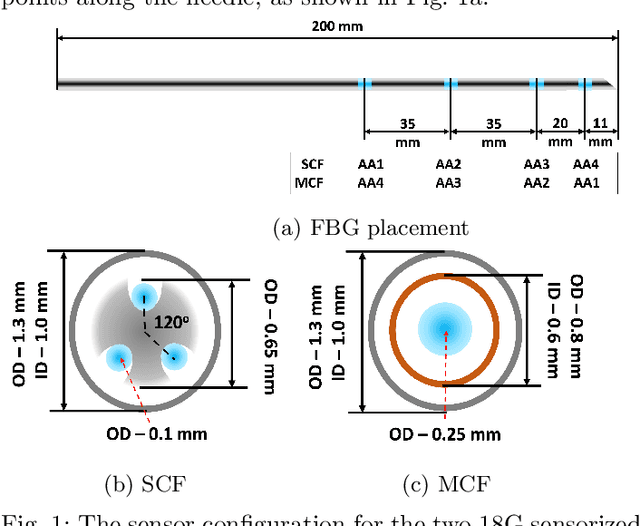
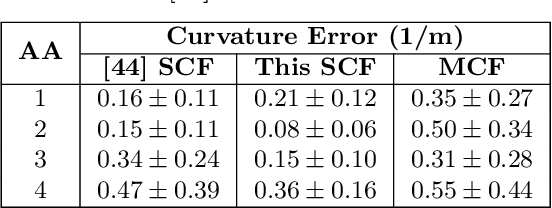
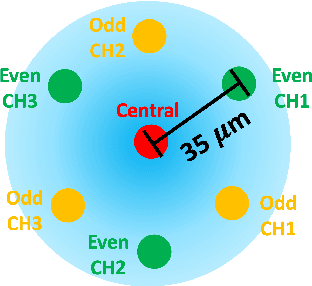
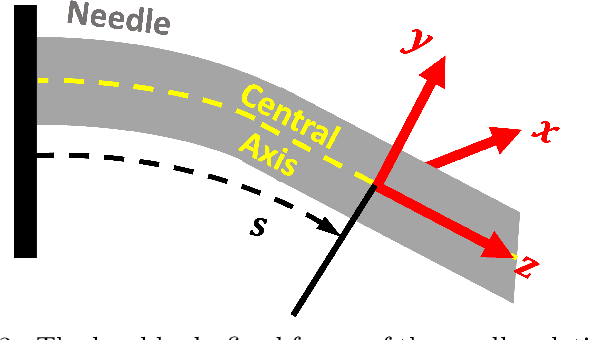
Flexible needle insertion procedures are common for minimally-invasive surgeries for diagnosing and treating prostate cancer. Bevel-tip needles provide physicians the capability to steer the needle during long insertions to avoid vital anatomical structures in the patient and reduce post-operative patient discomfort. To provide needle placement feedback to the physician, sensors are embedded into needles for determining the real-time 3D shape of the needle during operation without needing to visualize the needle intra-operatively. Through expansive research in fiber optics, a plethora of bio-compatible, MRI-compatible, optical shape-sensors have been developed to provide real-time shape feedback, such as single-core and multicore fiber Bragg gratings. In this paper, we directly compare single-core fiber-based and multicore fiber-based needle shape-sensing through identically constructed, four-active area sensorized bevel-tip needles inserted into phantom and \exvivo tissue on the same experimental platform. In this work, we found that for shape-sensing in phantom tissue, the two needles performed identically with a $p$-value of $0.164 > 0.05$, but in \exvivo real tissue, the single-core fiber sensorized needle significantly outperformed the multicore fiber configuration with a $p$-value of $0.0005 < 0.05$. This paper also presents the experimental platform and method for directly comparing these optical shape sensors for the needle shape-sensing task, as well as provides direction, insight and required considerations for future work in constructively optimizing sensorized needles.