 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Global Context Aggregation Network for Lightweight Saliency Detection of Surface Defects
Sep 22, 2023
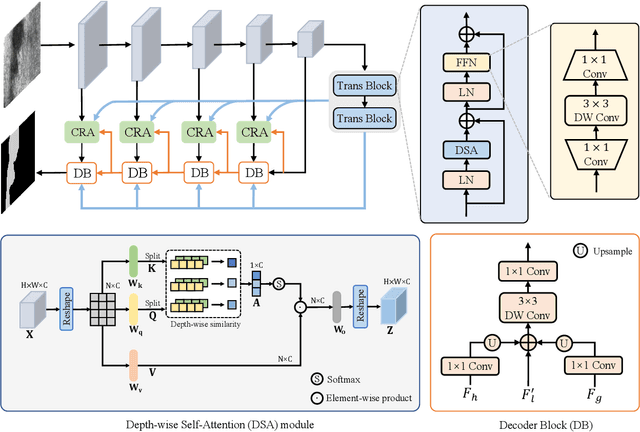
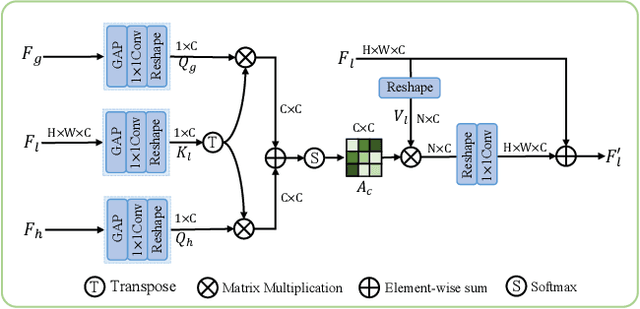
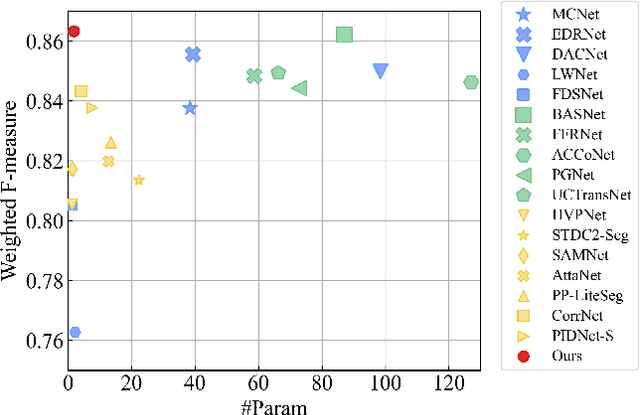
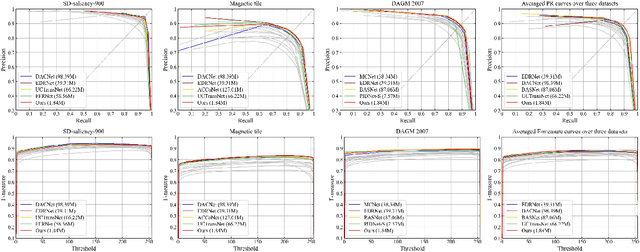
Surface defect inspection is a very challenging task in which surface defects usually show weak appearances or exist under complex backgrounds. Most high-accuracy defect detection methods require expensive computation and storage overhead, making them less practical in some resource-constrained defect detection applications. Although some lightweight methods have achieved real-time inference speed with fewer parameters, they show poor detection accuracy in complex defect scenarios. To this end, we develop a Global Context Aggregation Network (GCANet) for lightweight saliency detection of surface defects on the encoder-decoder structure. First, we introduce a novel transformer encoder on the top layer of the lightweight backbone, which captures global context information through a novel Depth-wise Self-Attention (DSA) module. The proposed DSA performs element-wise similarity in channel dimension while maintaining linear complexity. In addition, we introduce a novel Channel Reference Attention (CRA) module before each decoder block to strengthen the representation of multi-level features in the bottom-up path. The proposed CRA exploits the channel correlation between features at different layers to adaptively enhance feature representation. The experimental results on three public defect datasets demonstrate that the proposed network achieves a better trade-off between accuracy and running efficiency compared with other 17 state-of-the-art methods. Specifically, GCANet achieves competitive accuracy (91.79% $F_{\beta}^{w}$, 93.55% $S_\alpha$, and 97.35% $E_\phi$) on SD-saliency-900 while running 272fps on a single gpu.
S3TC: Spiking Separated Spatial and Temporal Convolutions with Unsupervised STDP-based Learning for Action Recognition
Sep 22, 2023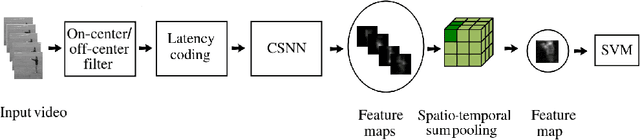
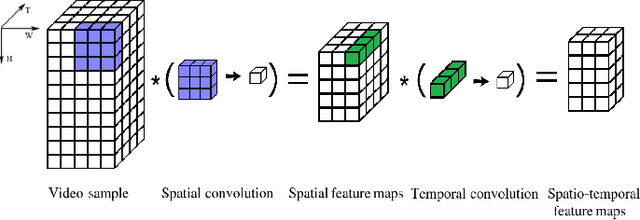
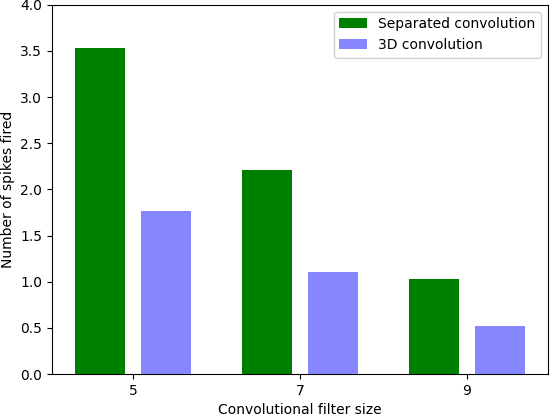
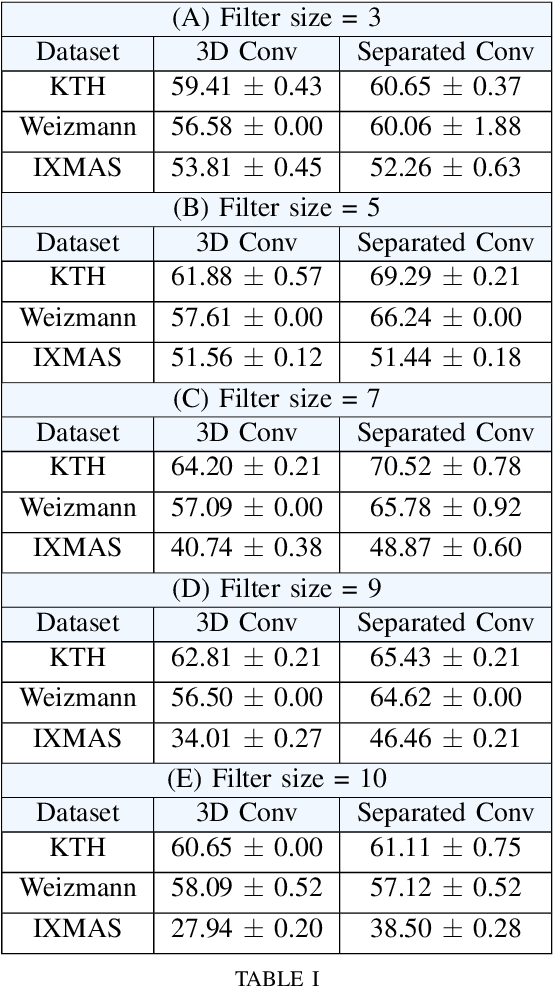
Video analysis is a major computer vision task that has received a lot of attention in recent years. The current state-of-the-art performance for video analysis is achieved with Deep Neural Networks (DNNs) that have high computational costs and need large amounts of labeled data for training. Spiking Neural Networks (SNNs) have significantly lower computational costs (thousands of times) than regular non-spiking networks when implemented on neuromorphic hardware. They have been used for video analysis with methods like 3D Convolutional Spiking Neural Networks (3D CSNNs). However, these networks have a significantly larger number of parameters compared with spiking 2D CSNN. This, not only increases the computational costs, but also makes these networks more difficult to implement with neuromorphic hardware. In this work, we use CSNNs trained in an unsupervised manner with the Spike Timing-Dependent Plasticity (STDP) rule, and we introduce, for the first time, Spiking Separated Spatial and Temporal Convolutions (S3TCs) for the sake of reducing the number of parameters required for video analysis. This unsupervised learning has the advantage of not needing large amounts of labeled data for training. Factorizing a single spatio-temporal spiking convolution into a spatial and a temporal spiking convolution decreases the number of parameters of the network. We test our network with the KTH, Weizmann, and IXMAS datasets, and we show that S3TCs successfully extract spatio-temporal information from videos, while increasing the output spiking activity, and outperforming spiking 3D convolutions.
Automatic Endoscopic Ultrasound Station Recognition with Limited Data
Sep 22, 2023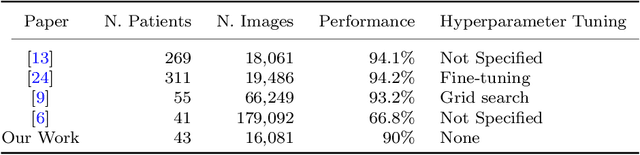
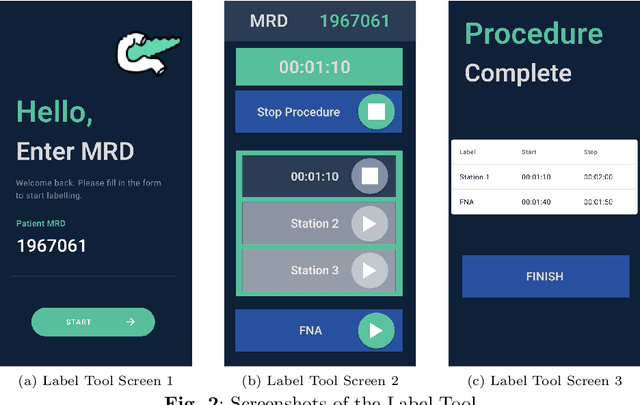
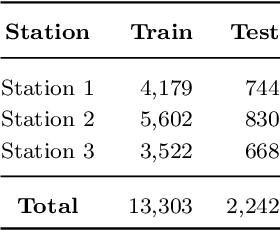
Pancreatic cancer is a lethal form of cancer that significantly contributes to cancer-related deaths worldwide. Early detection is essential to improve patient prognosis and survival rates. Despite advances in medical imaging techniques, pancreatic cancer remains a challenging disease to detect. Endoscopic ultrasound (EUS) is the most effective diagnostic tool for detecting pancreatic cancer. However, it requires expert interpretation of complex ultrasound images to complete a reliable patient scan. To obtain complete imaging of the pancreas, practitioners must learn to guide the endoscope into multiple "EUS stations" (anatomical locations), which provide different views of the pancreas. This is a difficult skill to learn, involving over 225 proctored procedures with the support of an experienced doctor. We build an AI-assisted tool that utilizes deep learning techniques to identify these stations of the stomach in real time during EUS procedures. This computer-assisted diagnostic (CAD) will help train doctors more efficiently. Historically, the challenge faced in developing such a tool has been the amount of retrospective labeling required by trained clinicians. To solve this, we developed an open-source user-friendly labeling web app that streamlines the process of annotating stations during the EUS procedure with minimal effort from the clinicians. Our research shows that employing only 43 procedures with no hyperparameter fine-tuning obtained a balanced accuracy of 90%, comparable to the current state of the art. In addition, we employ Grad-CAM, a visualization technology that provides clinicians with interpretable and explainable visualizations.
PRE: Vision-Language Prompt Learning with Reparameterization Encoder
Sep 14, 2023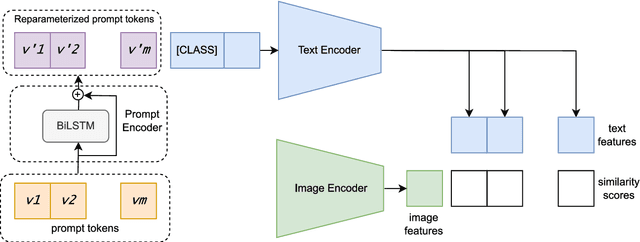
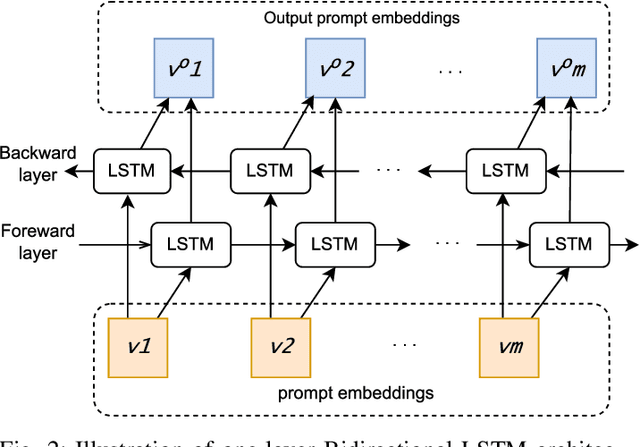
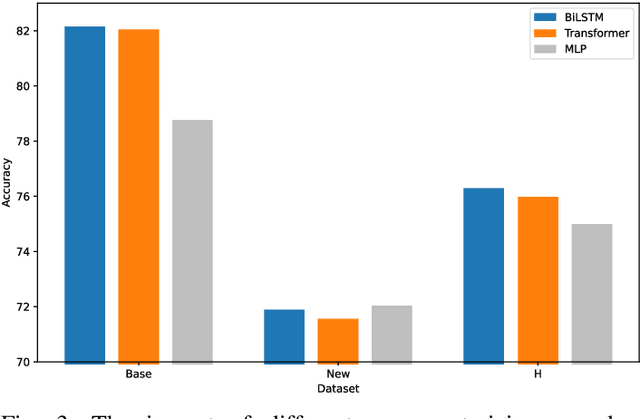
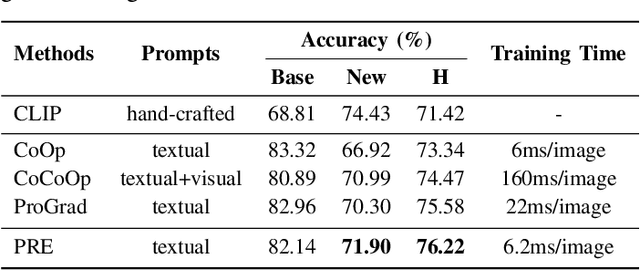
Large pre-trained vision-language models such as CLIP have demonstrated great potential in zero-shot transferability to downstream tasks. However, to attain optimal performance, the manual selection of prompts is necessary to improve alignment between the downstream image distribution and the textual class descriptions. This manual prompt engineering is the major challenge for deploying such models in practice since it requires domain expertise and is extremely time-consuming. To avoid non-trivial prompt engineering, recent work Context Optimization (CoOp) introduced the concept of prompt learning to the vision domain using learnable textual tokens. While CoOp can achieve substantial improvements over manual prompts, its learned context is worse generalizable to wider unseen classes within the same dataset. In this work, we present Prompt Learning with Reparameterization Encoder (PRE) - a simple and efficient method that enhances the generalization ability of the learnable prompt to unseen classes while maintaining the capacity to learn Base classes. Instead of directly optimizing the prompts, PRE employs a prompt encoder to reparameterize the input prompt embeddings, enhancing the exploration of task-specific knowledge from few-shot samples. Experiments and extensive ablation studies on 8 benchmarks demonstrate that our approach is an efficient method for prompt learning. Specifically, PRE achieves a notable enhancement of 5.60% in average accuracy on New classes and 3% in Harmonic mean compared to CoOp in the 16-shot setting, all achieved within a good training time.
Topological fingerprints for audio identification
Sep 07, 2023
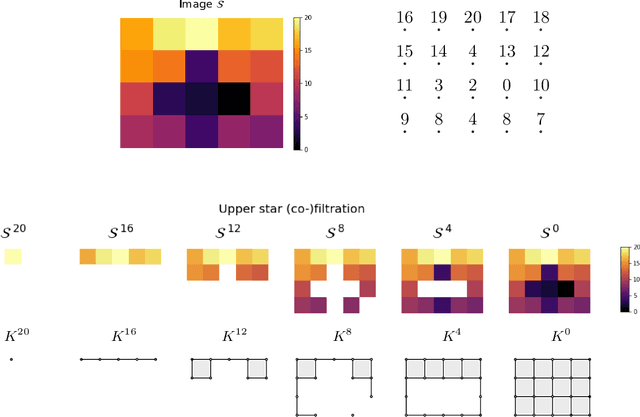
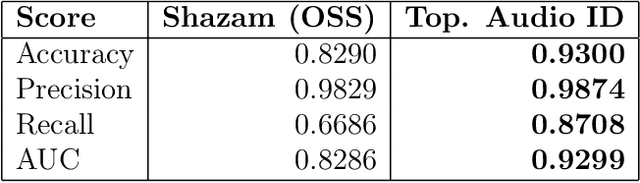
We present a topological audio fingerprinting approach for robustly identifying duplicate audio tracks. Our method applies persistent homology on local spectral decompositions of audio signals, using filtered cubical complexes computed from mel-spectrograms. By encoding the audio content in terms of local Betti curves, our topological audio fingerprints enable accurate detection of time-aligned audio matchings. Experimental results demonstrate the accuracy of our algorithm in the detection of tracks with the same audio content, even when subjected to various obfuscations. Our approach outperforms existing methods in scenarios involving topological distortions, such as time stretching and pitch shifting.
Improving physics-informed DeepONets with hard constraints
Sep 14, 2023Current physics-informed (standard or operator) neural networks still rely on accurately learning the initial conditions of the system they are solving. In contrast, standard numerical methods evolve such initial conditions without needing to learn these. In this study, we propose to improve current physics-informed deep learning strategies such that initial conditions do not need to be learned and are represented exactly in the predicted solution. Moreover, this method guarantees that when a DeepONet is applied multiple times to time step a solution, the resulting function is continuous.
Learning from Auxiliary Sources in Argumentative Revision Classification
Sep 13, 2023We develop models to classify desirable reasoning revisions in argumentative writing. We explore two approaches -- multi-task learning and transfer learning -- to take advantage of auxiliary sources of revision data for similar tasks. Results of intrinsic and extrinsic evaluations show that both approaches can indeed improve classifier performance over baselines. While multi-task learning shows that training on different sources of data at the same time may improve performance, transfer-learning better represents the relationship between the data.
Real-Time Progressive Learning: Mutually Reinforcing Learning and Control with Neural-Network-Based Selective Memory
Aug 08, 2023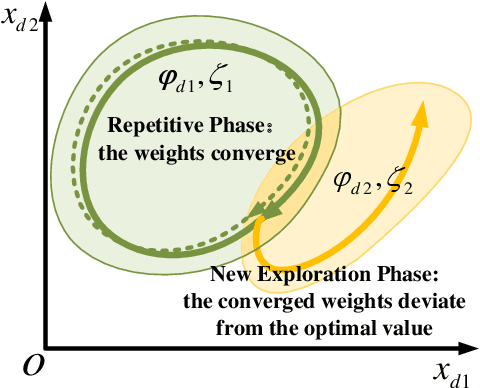
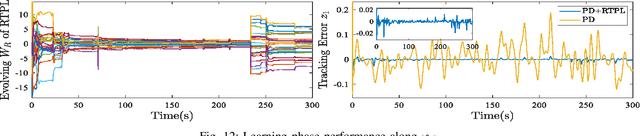
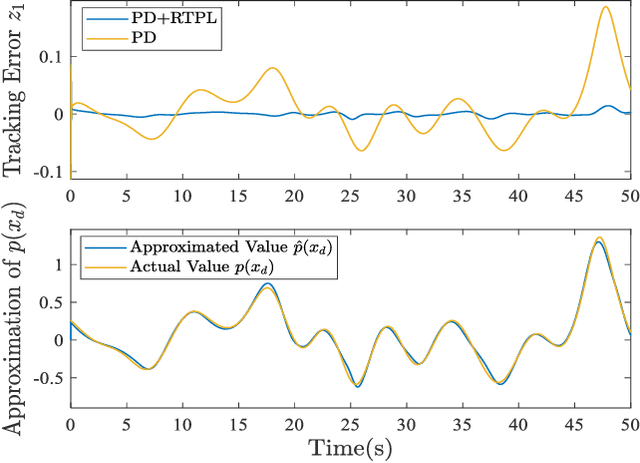
Memory, as the basis of learning, determines the storage, update and forgetting of the knowledge and further determines the efficiency of learning. Featured with a mechanism of memory, a radial basis function neural network (RBFNN) based learning control scheme named real-time progressive learning (RTPL) is proposed to learn the unknown dynamics of the system with guaranteed stability and closed-loop performance. Instead of the stochastic gradient descent (SGD) update law in adaptive neural control (ANC), RTPL adopts the selective memory recursive least squares (SMRLS) algorithm to update the weights of the RBFNN. Through SMRLS, the approximation capabilities of the RBFNN are uniformly distributed over the feature space and thus the passive knowledge forgetting phenomenon of SGD method is suppressed. Subsequently, RTPL achieves the following merits over the classical ANC: 1) guaranteed learning capability under low-level persistent excitation (PE), 2) improved learning performance (learning speed, accuracy and generalization capability), and 3) low gain requirement ensuring robustness of RTPL in practical applications. Moreover, the RTPL based learning and control will gradually reinforce each other during the task execution, making it appropriate for long-term learning control tasks. As an example, RTPL is used to address the tracking control problem of a class of nonlinear systems with RBFNN being an adaptive feedforward controller. Corresponding theoretical analysis and simulation studies demonstrate the effectiveness of RTPL.
Learning Semantic Segmentation with Query Points Supervision on Aerial Images
Sep 11, 2023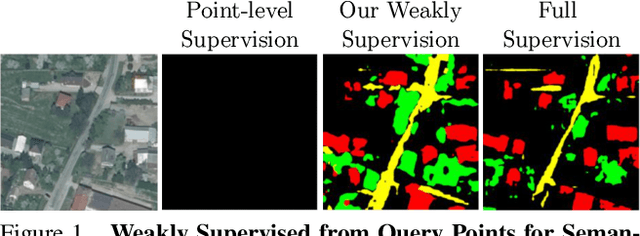
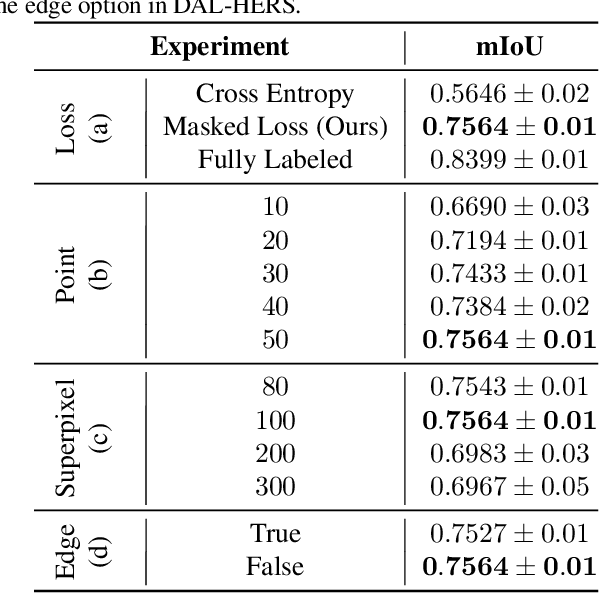
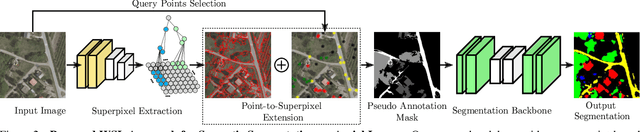
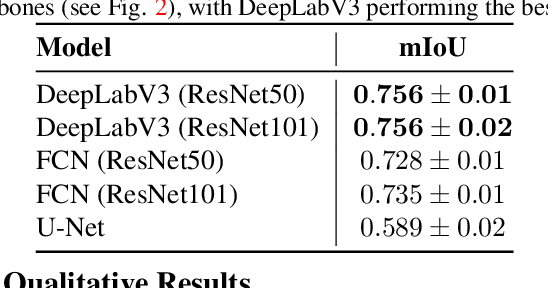
Semantic segmentation is crucial in remote sensing, where high-resolution satellite images are segmented into meaningful regions. Recent advancements in deep learning have significantly improved satellite image segmentation. However, most of these methods are typically trained in fully supervised settings that require high-quality pixel-level annotations, which are expensive and time-consuming to obtain. In this work, we present a weakly supervised learning algorithm to train semantic segmentation algorithms that only rely on query point annotations instead of full mask labels. Our proposed approach performs accurate semantic segmentation and improves efficiency by significantly reducing the cost and time required for manual annotation. Specifically, we generate superpixels and extend the query point labels into those superpixels that group similar meaningful semantics. Then, we train semantic segmentation models, supervised with images partially labeled with the superpixels pseudo-labels. We benchmark our weakly supervised training approach on an aerial image dataset and different semantic segmentation architectures, showing that we can reach competitive performance compared to fully supervised training while reducing the annotation effort.
Subgroup detection in linear growth curve models with generalized linear mixed model (GLMM) trees
Sep 11, 2023Growth curve models are popular tools for studying the development of a response variable within subjects over time. Heterogeneity between subjects is common in such models, and researchers are typically interested in explaining or predicting this heterogeneity. We show how generalized linear mixed effects model (GLMM) trees can be used to identify subgroups with differently shaped trajectories in linear growth curve models. Originally developed for clustered cross-sectional data, GLMM trees are extended here to longitudinal data. The resulting extended GLMM trees are directly applicable to growth curve models as an important special case. In simulated and real-world data, we assess the performance of the extensions and compare against other partitioning methods for growth curve models. Extended GLMM trees perform more accurately than the original algorithm and LongCART, and similarly accurate as structural equation model (SEM) trees. In addition, GLMM trees allow for modeling both discrete and continuous time series, are less sensitive to (mis-)specification of the random-effects structure and are much faster to compute.