 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Dynamic Domain Adaptation Deep Learning Network for EEG-based Motor Imagery Classification
Sep 21, 2023
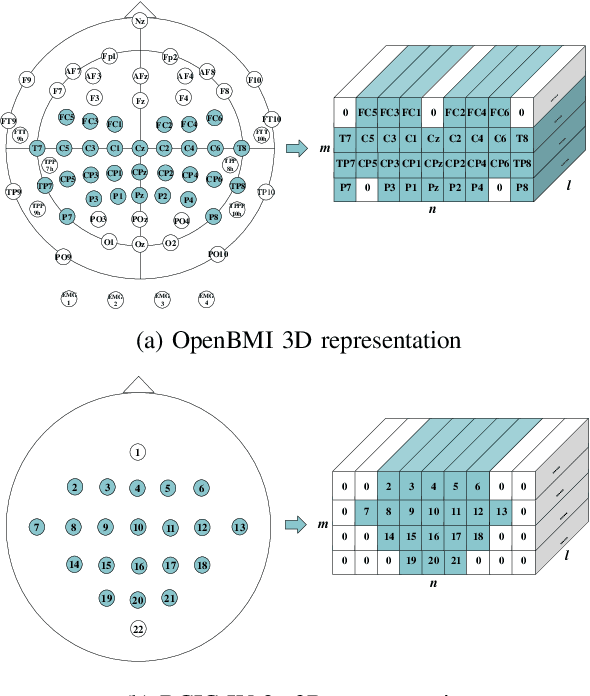
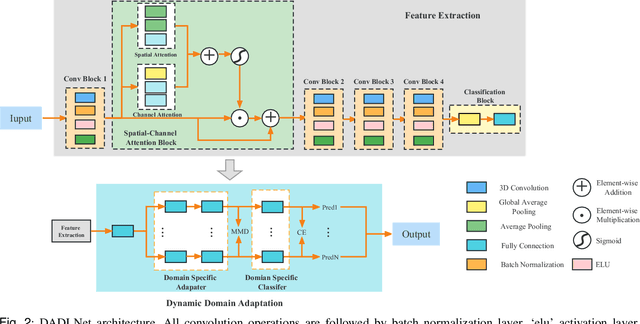
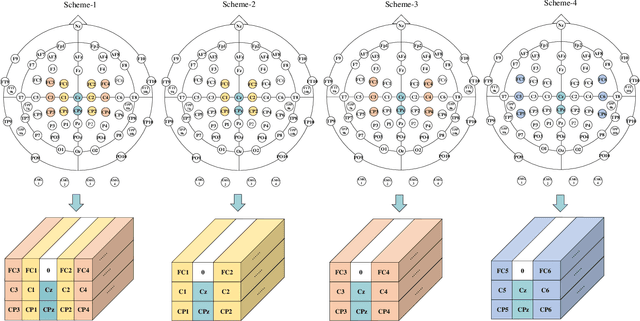
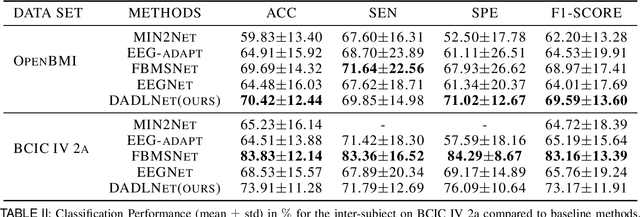
There is a correlation between adjacent channels of electroencephalogram (EEG), and how to represent this correlation is an issue that is currently being explored. In addition, due to inter-individual differences in EEG signals, this discrepancy results in new subjects need spend a amount of calibration time for EEG-based motor imagery brain-computer interface. In order to solve the above problems, we propose a Dynamic Domain Adaptation Based Deep Learning Network (DADL-Net). First, the EEG data is mapped to the three-dimensional geometric space and its temporal-spatial features are learned through the 3D convolution module, and then the spatial-channel attention mechanism is used to strengthen the features, and the final convolution module can further learn the spatial-temporal information of the features. Finally, to account for inter-subject and cross-sessions differences, we employ a dynamic domain-adaptive strategy, the distance between features is reduced by introducing a Maximum Mean Discrepancy loss function, and the classification layer is fine-tuned by using part of the target domain data. We verify the performance of the proposed method on BCI competition IV 2a and OpenBMI datasets. Under the intra-subject experiment, the accuracy rates of 70.42% and 73.91% were achieved on the OpenBMI and BCIC IV 2a datasets.
From Peptides to Nanostructures: A Euclidean Transformer for Fast and Stable Machine Learned Force Fields
Sep 21, 2023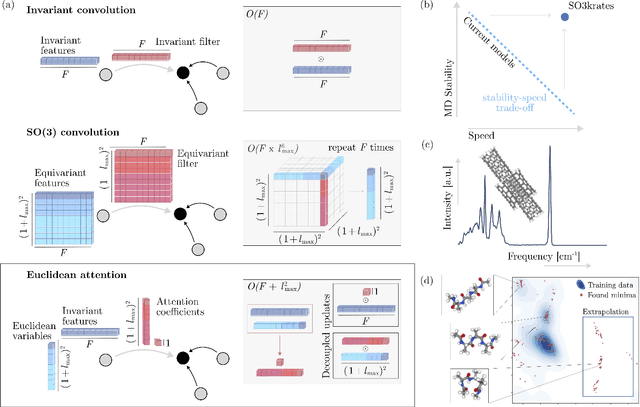
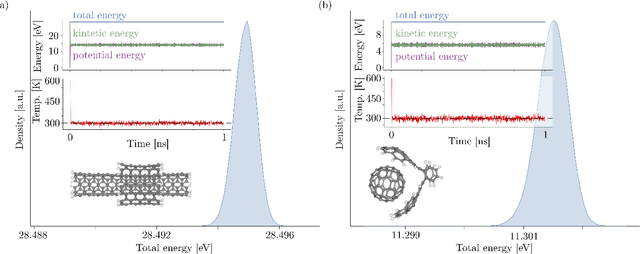
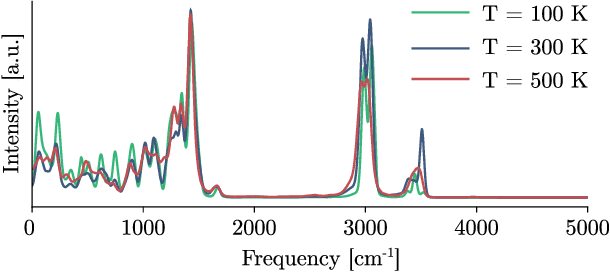

Recent years have seen vast progress in the development of machine learned force fields (MLFFs) based on ab-initio reference calculations. Despite achieving low test errors, the suitability of MLFFs in molecular dynamics (MD) simulations is being increasingly scrutinized due to concerns about instability. Our findings suggest a potential connection between MD simulation stability and the presence of equivariant representations in MLFFs, but their computational cost can limit practical advantages they would otherwise bring. To address this, we propose a transformer architecture called SO3krates that combines sparse equivariant representations (Euclidean variables) with a self-attention mechanism that can separate invariant and equivariant information, eliminating the need for expensive tensor products. SO3krates achieves a unique combination of accuracy, stability, and speed that enables insightful analysis of quantum properties of matter on unprecedented time and system size scales. To showcase this capability, we generate stable MD trajectories for flexible peptides and supra-molecular structures with hundreds of atoms. Furthermore, we investigate the PES topology for medium-sized chainlike molecules (e.g., small peptides) by exploring thousands of minima. Remarkably, SO3krates demonstrates the ability to strike a balance between the conflicting demands of stability and the emergence of new minimum-energy conformations beyond the training data, which is crucial for realistic exploration tasks in the field of biochemistry.
Robust Online Covariance and Sparse Precision Estimation Under Arbitrary Data Corruption
Sep 16, 2023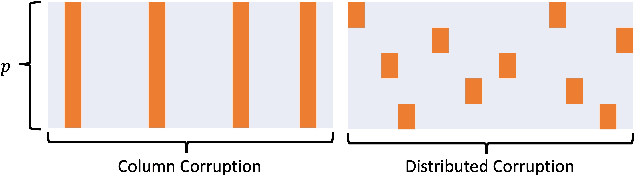
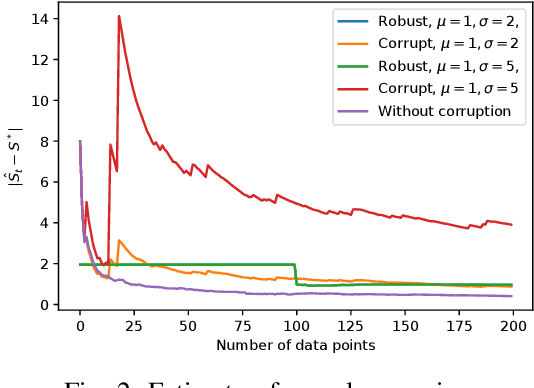
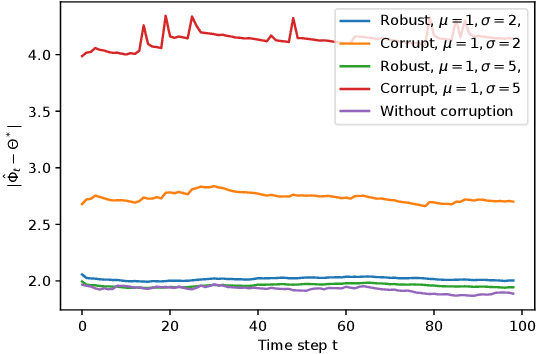
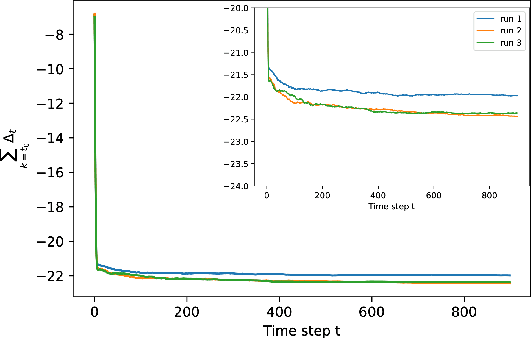
Gaussian graphical models are widely used to represent correlations among entities but remain vulnerable to data corruption. In this work, we introduce a modified trimmed-inner-product algorithm to robustly estimate the covariance in an online scenario even in the presence of arbitrary and adversarial data attacks. At each time step, data points, drawn nominally independently and identically from a multivariate Gaussian distribution, arrive. However, a certain fraction of these points may have been arbitrarily corrupted. We propose an online algorithm to estimate the sparse inverse covariance (i.e., precision) matrix despite this corruption. We provide the error-bound and convergence properties of the estimates to the true precision matrix under our algorithms.
Multivariate Time Series characterization and forecasting of VoIP traffic in real mobile networks
Jul 13, 2023Predicting the behavior of real-time traffic (e.g., VoIP) in mobility scenarios could help the operators to better plan their network infrastructures and to optimize the allocation of resources. Accordingly, in this work the authors propose a forecasting analysis of crucial QoS/QoE descriptors (some of which neglected in the technical literature) of VoIP traffic in a real mobile environment. The problem is formulated in terms of a multivariate time series analysis. Such a formalization allows to discover and model the temporal relationships among various descriptors and to forecast their behaviors for future periods. Techniques such as Vector Autoregressive models and machine learning (deep-based and tree-based) approaches are employed and compared in terms of performance and time complexity, by reframing the multivariate time series problem into a supervised learning one. Moreover, a series of auxiliary analyses (stationarity, orthogonal impulse responses, etc.) are performed to discover the analytical structure of the time series and to provide deep insights about their relationships. The whole theoretical analysis has an experimental counterpart since a set of trials across a real-world LTE-Advanced environment has been performed to collect, post-process and analyze about 600,000 voice packets, organized per flow and differentiated per codec.
Unified Contrastive Fusion Transformer for Multimodal Human Action Recognition
Sep 10, 2023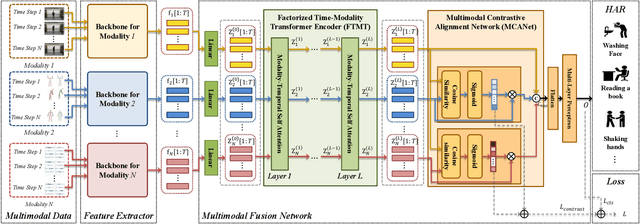
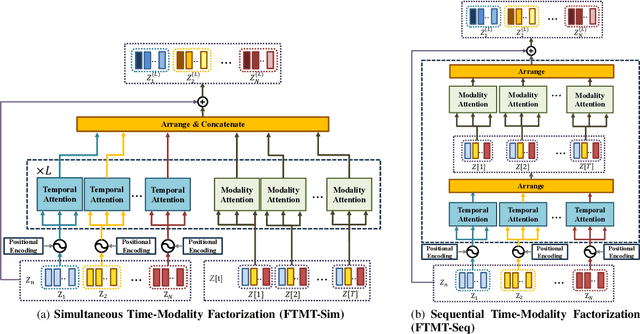

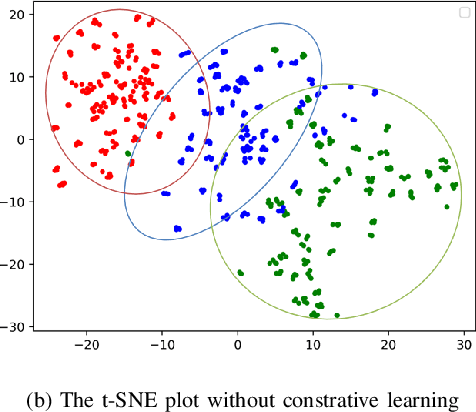
Various types of sensors have been considered to develop human action recognition (HAR) models. Robust HAR performance can be achieved by fusing multimodal data acquired by different sensors. In this paper, we introduce a new multimodal fusion architecture, referred to as Unified Contrastive Fusion Transformer (UCFFormer) designed to integrate data with diverse distributions to enhance HAR performance. Based on the embedding features extracted from each modality, UCFFormer employs the Unified Transformer to capture the inter-dependency among embeddings in both time and modality domains. We present the Factorized Time-Modality Attention to perform self-attention efficiently for the Unified Transformer. UCFFormer also incorporates contrastive learning to reduce the discrepancy in feature distributions across various modalities, thus generating semantically aligned features for information fusion. Performance evaluation conducted on two popular datasets, UTD-MHAD and NTU RGB+D, demonstrates that UCFFormer achieves state-of-the-art performance, outperforming competing methods by considerable margins.
Fully Convolutional Generative Machine Learning Method for Accelerating Non-Equilibrium Greens Function Simulations
Sep 17, 2023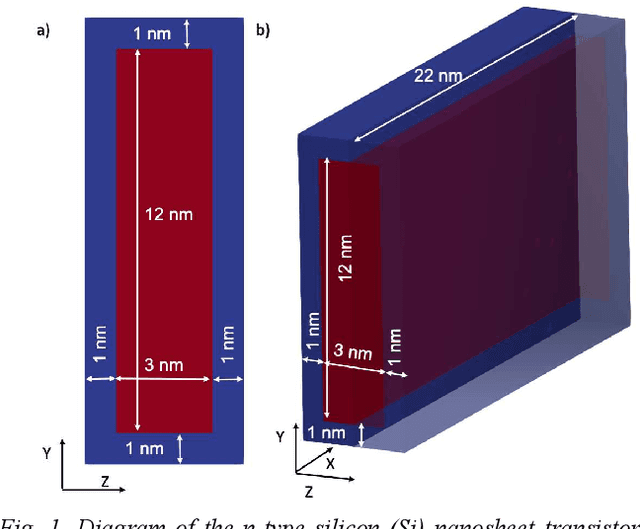
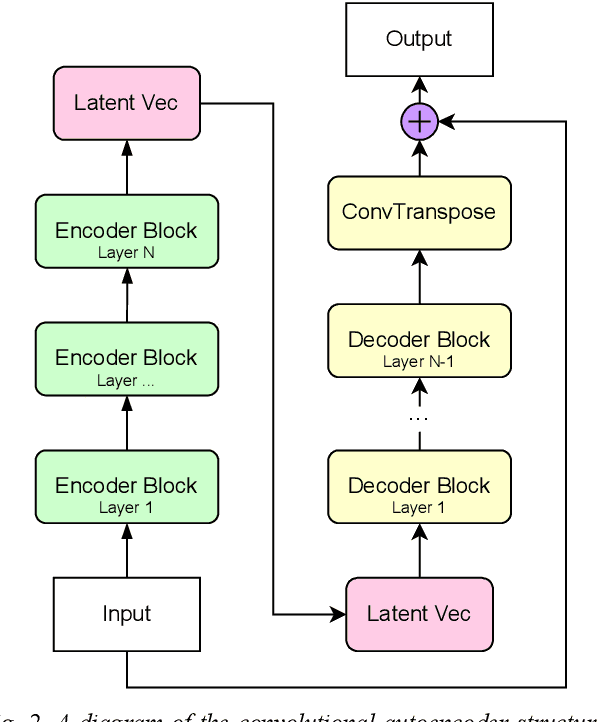
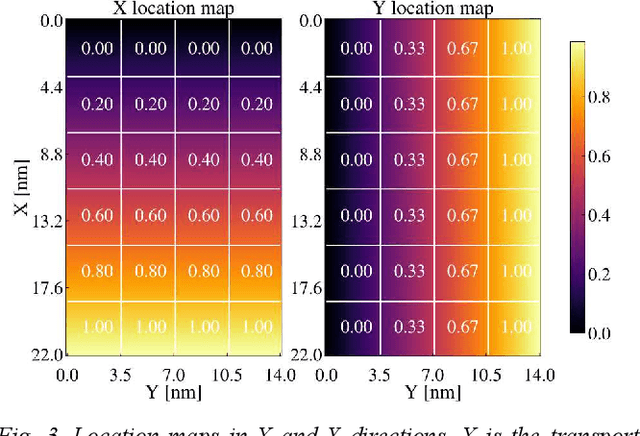
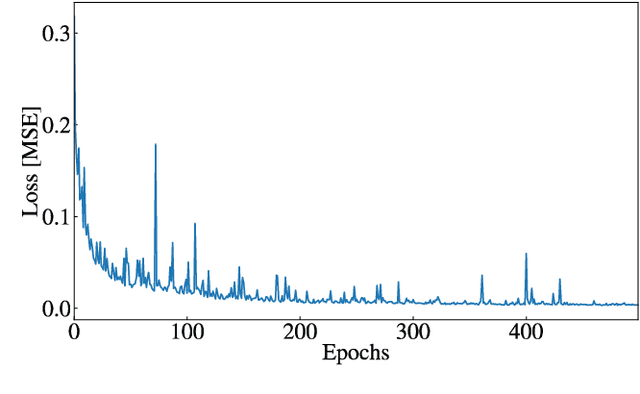
This work describes a novel simulation approach that combines machine learning and device modelling simulations. The device simulations are based on the quantum mechanical non-equilibrium Greens function (NEGF) approach and the machine learning method is an extension to a convolutional generative network. We have named our new simulation approach ML-NEGF and we have implemented it in our in-house simulator called NESS (nano-electronics simulations software). The reported results demonstrate the improved convergence speed of the ML-NEGF method in comparison to the standard NEGF approach. The trained ML model effectively learns the underlying physics of nano-sheet transistor behaviour, resulting in faster convergence of the coupled Poisson-NEGF simulations. Quantitatively, our ML- NEGF approach achieves an average convergence acceleration of 60%, substantially reducing the computational time while maintaining the same accuracy.
Vehicle-to-Grid and ancillary services:a profitability analysis under uncertainty
Sep 20, 2023The rapid and massive diffusion of electric vehicles poses new challenges to the electric system, which must be able to supply these new loads, but at the same time opens up new opportunities thanks to the possible provision of ancillary services. Indeed, in the so-called Vehicle-to-Grid (V2G) set-up, the charging power can be modulated throughout the day so that a fleet of vehicles can absorb an excess of power from the grid or provide extra power during a shortage.To this end, many works in the literature focus on the optimization of each vehicle daily charging profiles to offer the requested ancillary services while guaranteeing a charged battery for each vehicle at the end of the day. However, the size of the economic benefits related to the provision of ancillary services varies significantly with the modeling approaches, different assumptions, and considered scenarios. In this paper we propose a profitability analysis with reference to a recently proposed framework for V2G optimal operation in presence of uncertainty. We provide necessary and sufficient conditions for profitability in a simplified case and we show via simulation that they also hold for the general case.
Delays in Reinforcement Learning
Sep 20, 2023Delays are inherent to most dynamical systems. Besides shifting the process in time, they can significantly affect their performance. For this reason, it is usually valuable to study the delay and account for it. Because they are dynamical systems, it is of no surprise that sequential decision-making problems such as Markov decision processes (MDP) can also be affected by delays. These processes are the foundational framework of reinforcement learning (RL), a paradigm whose goal is to create artificial agents capable of learning to maximise their utility by interacting with their environment. RL has achieved strong, sometimes astonishing, empirical results, but delays are seldom explicitly accounted for. The understanding of the impact of delay on the MDP is limited. In this dissertation, we propose to study the delay in the agent's observation of the state of the environment or in the execution of the agent's actions. We will repeatedly change our point of view on the problem to reveal some of its structure and peculiarities. A wide spectrum of delays will be considered, and potential solutions will be presented. This dissertation also aims to draw links between celebrated frameworks of the RL literature and the one of delays.
SPFQ: A Stochastic Algorithm and Its Error Analysis for Neural Network Quantization
Sep 20, 2023Quantization is a widely used compression method that effectively reduces redundancies in over-parameterized neural networks. However, existing quantization techniques for deep neural networks often lack a comprehensive error analysis due to the presence of non-convex loss functions and nonlinear activations. In this paper, we propose a fast stochastic algorithm for quantizing the weights of fully trained neural networks. Our approach leverages a greedy path-following mechanism in combination with a stochastic quantizer. Its computational complexity scales only linearly with the number of weights in the network, thereby enabling the efficient quantization of large networks. Importantly, we establish, for the first time, full-network error bounds, under an infinite alphabet condition and minimal assumptions on the weights and input data. As an application of this result, we prove that when quantizing a multi-layer network having Gaussian weights, the relative square quantization error exhibits a linear decay as the degree of over-parametrization increases. Furthermore, we demonstrate that it is possible to achieve error bounds equivalent to those obtained in the infinite alphabet case, using on the order of a mere $\log\log N$ bits per weight, where $N$ represents the largest number of neurons in a layer.
Talk2Care: Facilitating Asynchronous Patient-Provider Communication with Large-Language-Model
Sep 22, 2023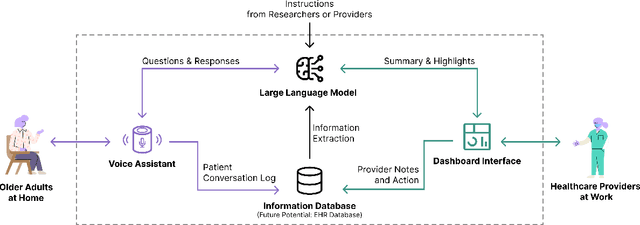
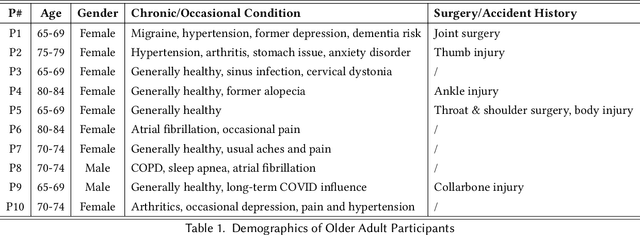
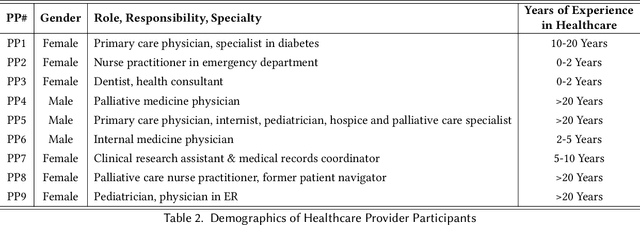
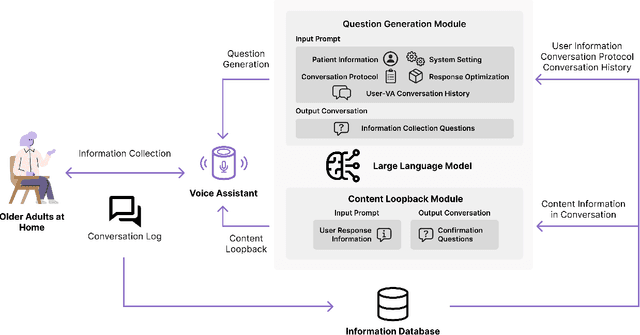
Despite the plethora of telehealth applications to assist home-based older adults and healthcare providers, basic messaging and phone calls are still the most common communication methods, which suffer from limited availability, information loss, and process inefficiencies. One promising solution to facilitate patient-provider communication is to leverage large language models (LLMs) with their powerful natural conversation and summarization capability. However, there is a limited understanding of LLMs' role during the communication. We first conducted two interview studies with both older adults (N=10) and healthcare providers (N=9) to understand their needs and opportunities for LLMs in patient-provider asynchronous communication. Based on the insights, we built an LLM-powered communication system, Talk2Care, and designed interactive components for both groups: (1) For older adults, we leveraged the convenience and accessibility of voice assistants (VAs) and built an LLM-powered VA interface for effective information collection. (2) For health providers, we built an LLM-based dashboard to summarize and present important health information based on older adults' conversations with the VA. We further conducted two user studies with older adults and providers to evaluate the usability of the system. The results showed that Talk2Care could facilitate the communication process, enrich the health information collected from older adults, and considerably save providers' efforts and time. We envision our work as an initial exploration of LLMs' capability in the intersection of healthcare and interpersonal communication.