 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning Quasi-Static 3D Models of Markerless Deformable Linear Objects for Bimanual Robotic Manipulation
Sep 14, 2023

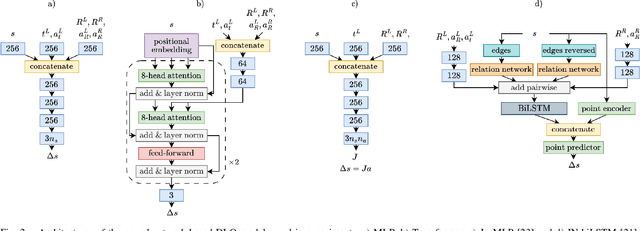
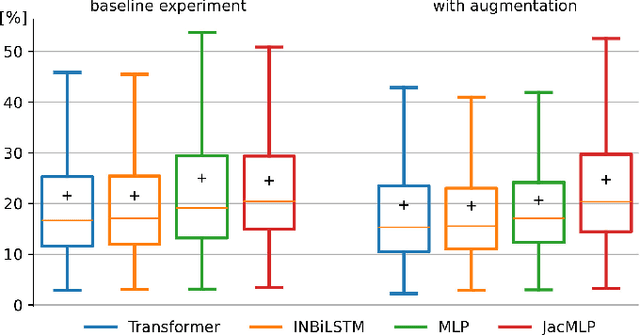
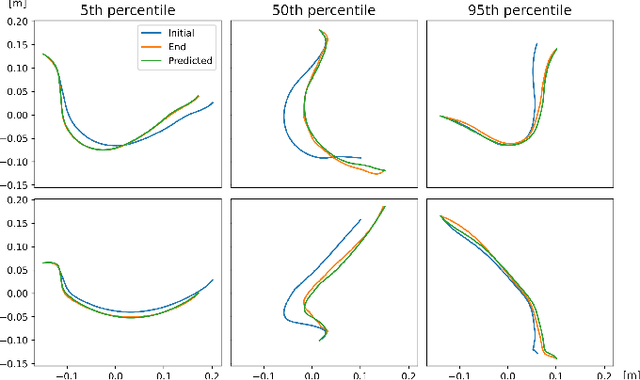
The robotic manipulation of Deformable Linear Objects (DLOs) is a vital and challenging task that is important in many practical applications. Classical model-based approaches to this problem require an accurate model to capture how robot motions affect the deformation of the DLO. Nowadays, data-driven models offer the best tradeoff between quality and computation time. This paper analyzes several learning-based 3D models of the DLO and proposes a new one based on the Transformer architecture that achieves superior accuracy, even on the DLOs of different lengths, thanks to the proposed scaling method. Moreover, we introduce a data augmentation technique, which improves the prediction performance of almost all considered DLO data-driven models. Thanks to this technique, even a simple Multilayer Perceptron (MLP) achieves close to state-of-the-art performance while being significantly faster to evaluate. In the experiments, we compare the performance of the learning-based 3D models of the DLO on several challenging datasets quantitatively and demonstrate their applicability in the task of shaping a DLO.
Real-time Traffic Classification for 5G NSA Encrypted Data Flows With Physical Channel Records
Jul 15, 2023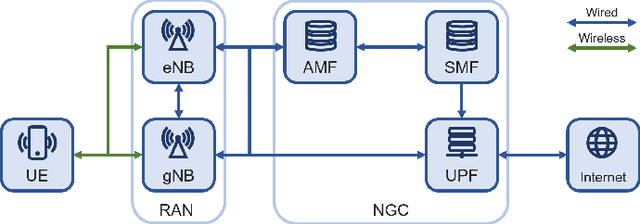
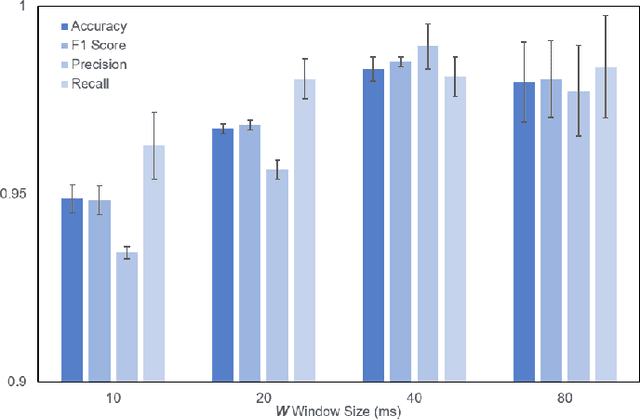
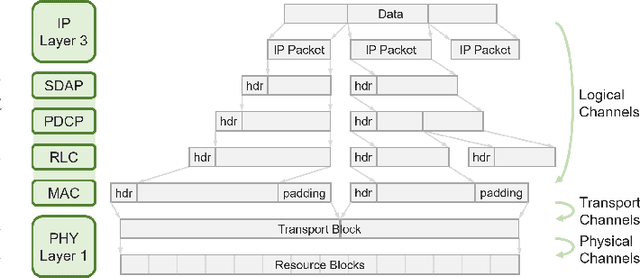
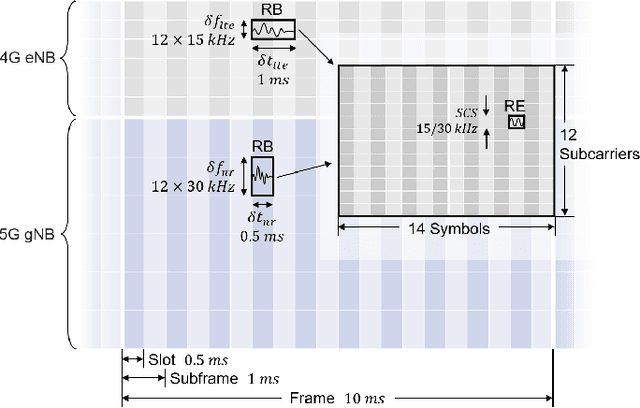
The classification of fifth-generation New-Radio (5G-NR) mobile network traffic is an emerging topic in the field of telecommunications. It can be utilized for quality of service (QoS) management and dynamic resource allocation. However, traditional approaches such as Deep Packet Inspection (DPI) can not be directly applied to encrypted data flows. Therefore, new real-time encrypted traffic classification algorithms need to be investigated to handle dynamic transmission. In this study, we examine the real-time encrypted 5G Non-Standalone (NSA) application-level traffic classification using physical channel records. Due to the vastness of their features, decision-tree-based gradient boosting algorithms are a viable approach for classification. We generate a noise-limited 5G NSA trace dataset with traffic from multiple applications. We develop a new pipeline to convert sequences of physical channel records into numerical vectors. A set of machine learning models are tested, and we propose our solution based on Light Gradient Boosting Machine (LGBM) due to its advantages in fast parallel training and low computational burden in practical scenarios. Our experiments demonstrate that our algorithm can achieve 95% accuracy on the classification task with a state-of-the-art response time as quick as 10ms.
Learning Disentangled Representation with Mutual Information Maximization for Real-Time UAV Tracking
Aug 20, 2023Efficiency has been a critical problem in UAV tracking due to limitations in computation resources, battery capacity, and unmanned aerial vehicle maximum load. Although discriminative correlation filters (DCF)-based trackers prevail in this field for their favorable efficiency, some recently proposed lightweight deep learning (DL)-based trackers using model compression demonstrated quite remarkable CPU efficiency as well as precision. Unfortunately, the model compression methods utilized by these works, though simple, are still unable to achieve satisfying tracking precision with higher compression rates. This paper aims to exploit disentangled representation learning with mutual information maximization (DR-MIM) to further improve DL-based trackers' precision and efficiency for UAV tracking. The proposed disentangled representation separates the feature into an identity-related and an identity-unrelated features. Only the latter is used, which enhances the effectiveness of the feature representation for subsequent classification and regression tasks. Extensive experiments on four UAV benchmarks, including UAV123@10fps, DTB70, UAVDT and VisDrone2018, show that our DR-MIM tracker significantly outperforms state-of-the-art UAV tracking methods.
Q-YOLO: Efficient Inference for Real-time Object Detection
Jul 01, 2023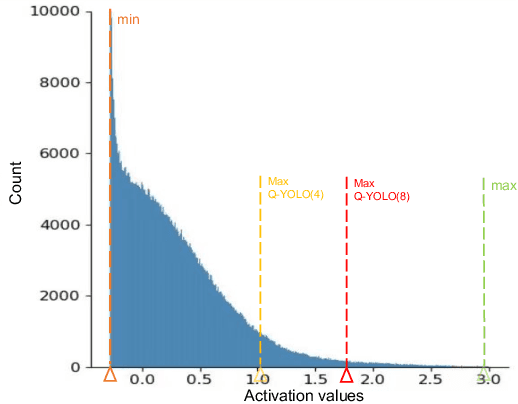
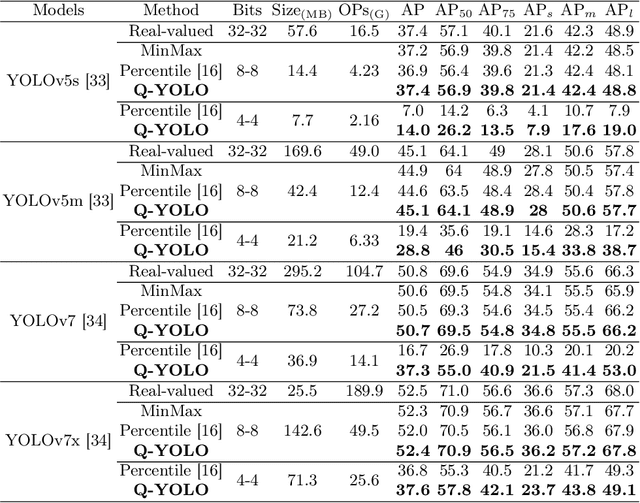
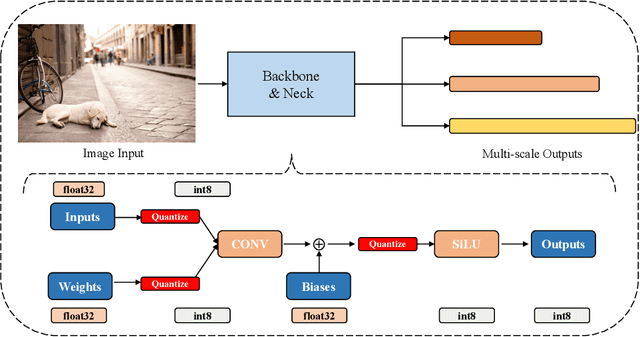
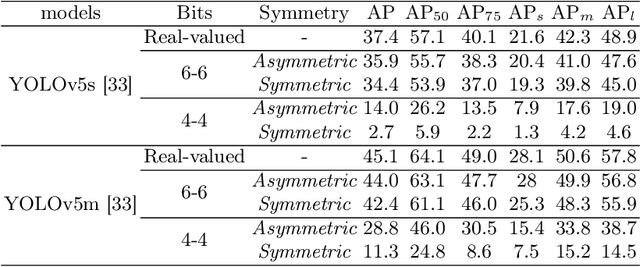
Real-time object detection plays a vital role in various computer vision applications. However, deploying real-time object detectors on resource-constrained platforms poses challenges due to high computational and memory requirements. This paper describes a low-bit quantization method to build a highly efficient one-stage detector, dubbed as Q-YOLO, which can effectively address the performance degradation problem caused by activation distribution imbalance in traditional quantized YOLO models. Q-YOLO introduces a fully end-to-end Post-Training Quantization (PTQ) pipeline with a well-designed Unilateral Histogram-based (UH) activation quantization scheme, which determines the maximum truncation values through histogram analysis by minimizing the Mean Squared Error (MSE) quantization errors. Extensive experiments on the COCO dataset demonstrate the effectiveness of Q-YOLO, outperforming other PTQ methods while achieving a more favorable balance between accuracy and computational cost. This research contributes to advancing the efficient deployment of object detection models on resource-limited edge devices, enabling real-time detection with reduced computational and memory overhead.
VLSlice: Interactive Vision-and-Language Slice Discovery
Sep 13, 2023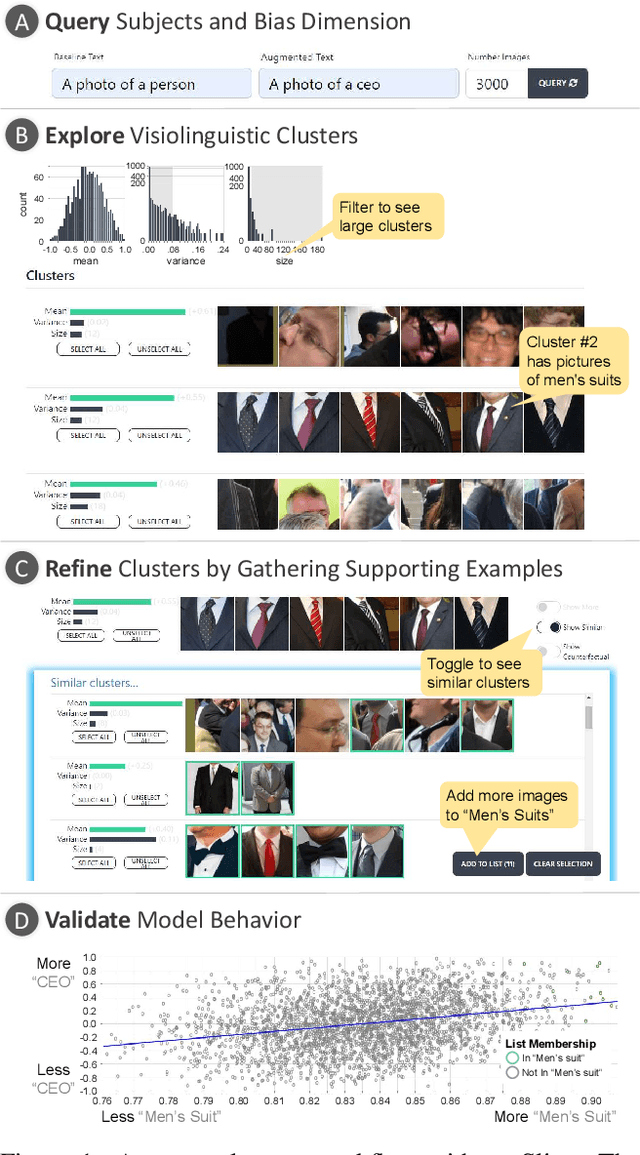
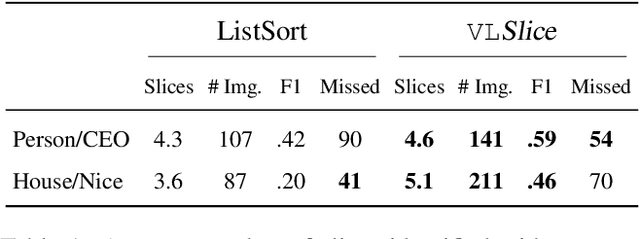

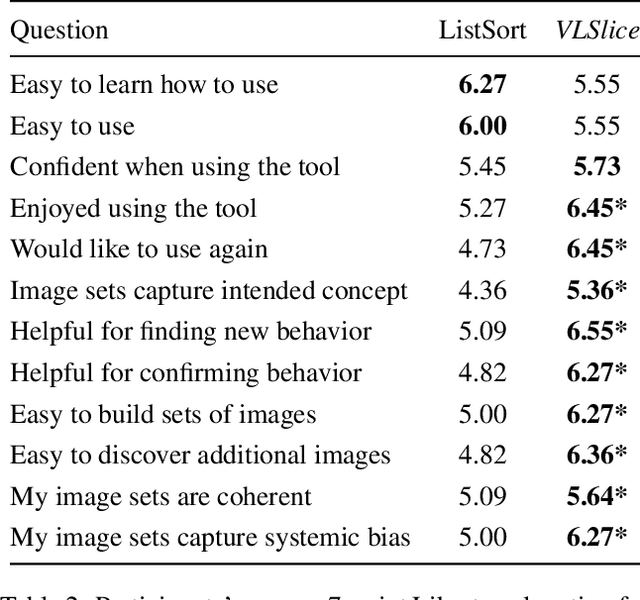
Recent work in vision-and-language demonstrates that large-scale pretraining can learn generalizable models that are efficiently transferable to downstream tasks. While this may improve dataset-scale aggregate metrics, analyzing performance around hand-crafted subgroups targeting specific bias dimensions reveals systemic undesirable behaviors. However, this subgroup analysis is frequently stalled by annotation efforts, which require extensive time and resources to collect the necessary data. Prior art attempts to automatically discover subgroups to circumvent these constraints but typically leverages model behavior on existing task-specific annotations and rapidly degrades on more complex inputs beyond "tabular" data, none of which study vision-and-language models. This paper presents VLSlice, an interactive system enabling user-guided discovery of coherent representation-level subgroups with consistent visiolinguistic behavior, denoted as vision-and-language slices, from unlabeled image sets. We show that VLSlice enables users to quickly generate diverse high-coherency slices in a user study (n=22) and release the tool publicly.
Can Whisper perform speech-based in-context learning
Sep 13, 2023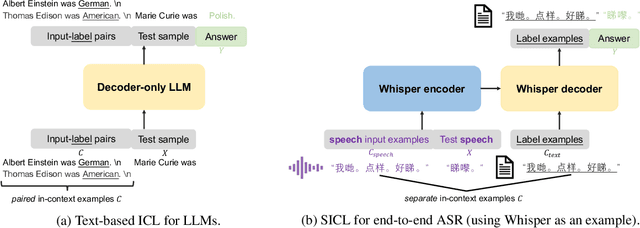
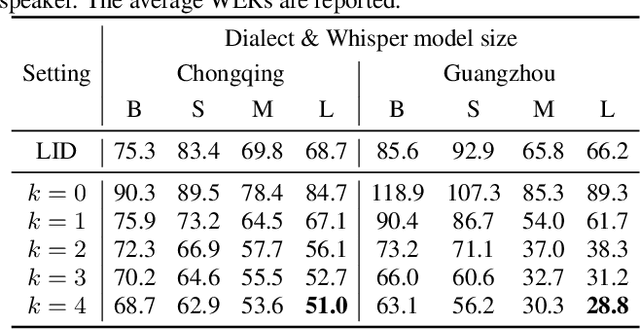
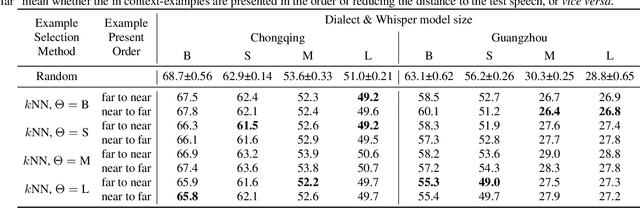
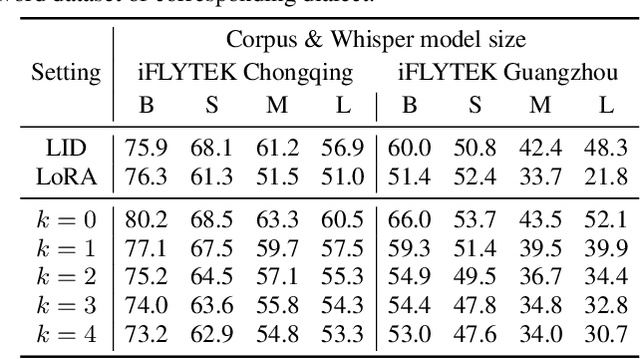
This paper investigates the in-context learning abilities of the Whisper automatic speech recognition (ASR) models released by OpenAI. A novel speech-based in-context learning (SICL) approach is proposed for test-time adaptation, which can reduce the word error rates (WERs) with only a small number of labelled speech samples without gradient descent. Language-level adaptation experiments using Chinese dialects showed that when applying SICL to isolated word ASR, consistent and considerable relative WER reductions can be achieved using Whisper models of any size on two dialects, which is on average 32.3%. A k-nearest-neighbours-based in-context example selection technique can be applied to further improve the efficiency of SICL, which can increase the average relative WER reduction to 36.4%. The findings are verified using speaker adaptation or continuous speech recognition tasks, and both achieved considerable relative WER reductions. Detailed quantitative analyses are also provided to shed light on SICL's adaptability to phonological variances and dialect-specific lexical nuances.
Weakly-Supervised Multi-Task Learning for Audio-Visual Speaker Verification
Sep 13, 2023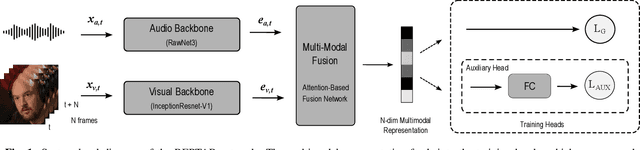

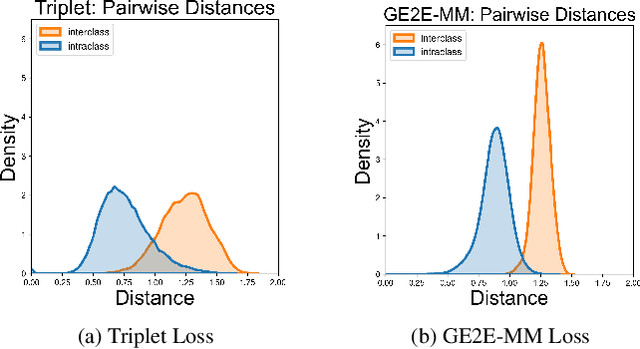
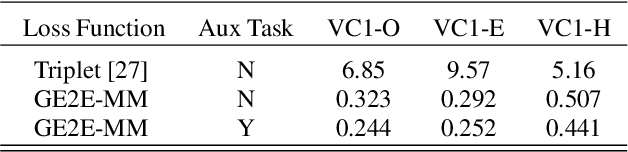
In this paper, we present a methodology for achieving robust multimodal person representations optimized for open-set audio-visual speaker verification. Distance Metric Learning (DML) approaches have typically dominated this problem space, owing to strong performance on new and unseen classes. In our work, we explored multitask learning techniques to further boost performance of the DML approach and show that an auxiliary task with weak labels can increase the compactness of the learned speaker representation. We also extend the Generalized end-to-end loss (GE2E) to multimodal inputs and demonstrate that it can achieve competitive performance in an audio-visual space. Finally, we introduce a non-synchronous audio-visual sampling random strategy during training time that has shown to improve generalization. Our network achieves state of the art performance for speaker verification, reporting 0.244%, 0.252%, 0.441% Equal Error Rate (EER) on the three official trial lists of VoxCeleb1-O/E/H, which is to our knowledge, the best published results on VoxCeleb1-E and VoxCeleb1-H.
Temporal compressive edge imaging enabled by a lensless diffuser camera
Sep 13, 2023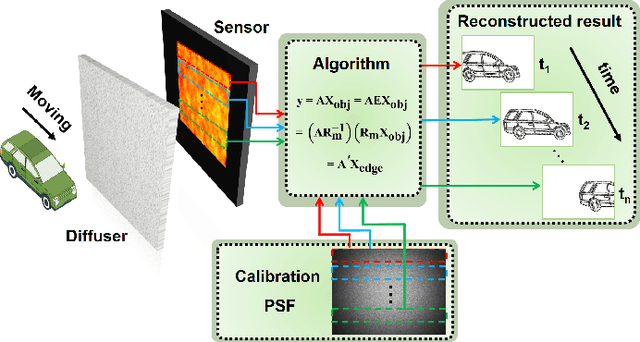

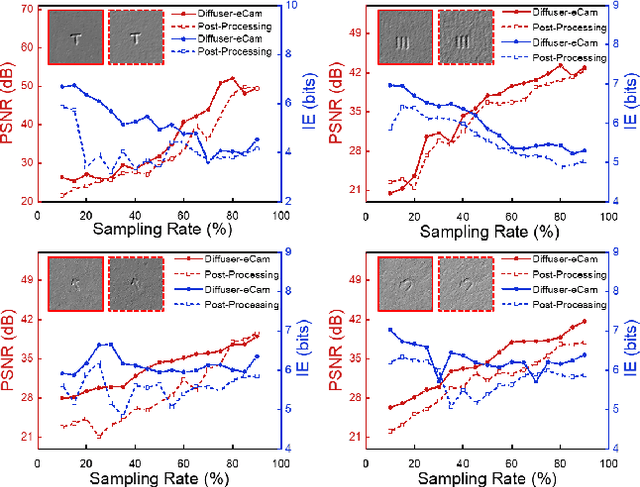

Lensless imagers based on diffusers or encoding masks enable high-dimensional imaging from a single shot measurement and have been applied in various applications. However, to further extract image information such as edge detection, conventional post-processing filtering operations are needed after the reconstruction of the original object images in the diffuser imaging systems. Here, we present the concept of a temporal compressive edge detection method based on a lensless diffuser camera, which can directly recover a time sequence of edge images of a moving object from a single-shot measurement, without further post-processing steps. Our approach provides higher image quality during edge detection, compared with the conventional post-processing method. We demonstrate the effectiveness of this approach by both numerical simulation and experiments. The proof-of-concept approach can be further developed with other image post-process operations or versatile computer vision assignments toward task-oriented intelligent lensless imaging systems.
Anisotropic Diffusion Stencils: From Simple Derivations over Stability Estimates to ResNet Implementations
Sep 13, 2023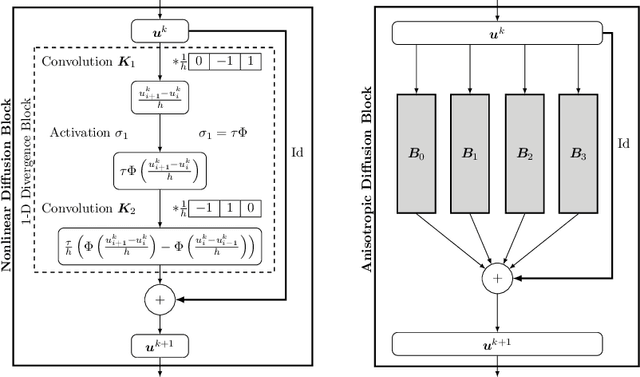
Anisotropic diffusion processes with a diffusion tensor are important in image analysis, physics, and engineering. However, their numerical approximation has a strong impact on dissipative artefacts and deviations from rotation invariance. In this work, we study a large family of finite difference discretisations on a 3 x 3 stencil. We derive it by splitting 2-D anisotropic diffusion into four 1-D diffusions. The resulting stencil class involves one free parameter and covers a wide range of existing discretisations. It comprises the full stencil family of Weickert et al. (2013) and shows that their two parameters contain redundancy. Furthermore, we establish a bound on the spectral norm of the matrix corresponding to the stencil. This gives time step size limits that guarantee stability of an explicit scheme in the Euclidean norm. Our directional splitting also allows a very natural translation of the explicit scheme into ResNet blocks. Employing neural network libraries enables simple and highly efficient parallel implementations on GPUs.
Differentiable Modelling of Percussive Audio with Transient and Spectral Synthesis
Sep 13, 2023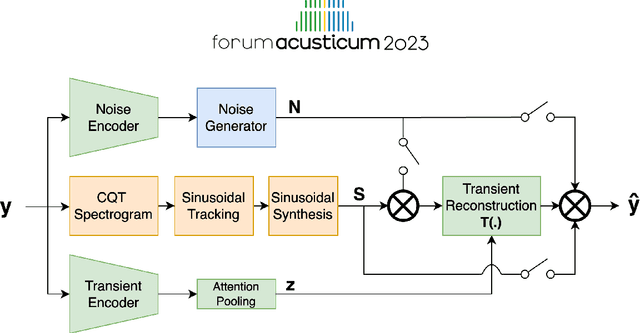
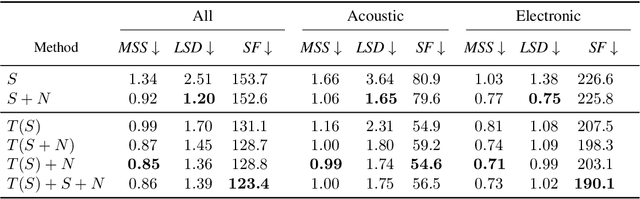
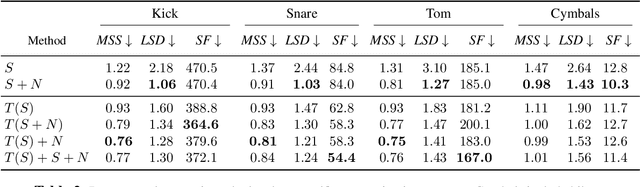
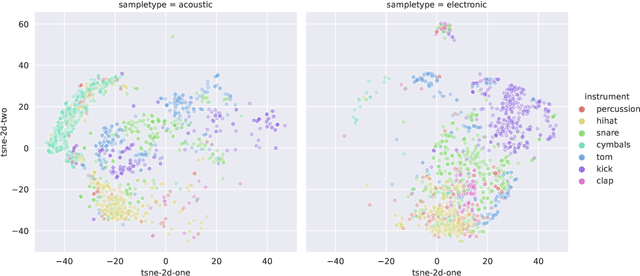
Differentiable digital signal processing (DDSP) techniques, including methods for audio synthesis, have gained attention in recent years and lend themselves to interpretability in the parameter space. However, current differentiable synthesis methods have not explicitly sought to model the transient portion of signals, which is important for percussive sounds. In this work, we present a unified synthesis framework aiming to address transient generation and percussive synthesis within a DDSP framework. To this end, we propose a model for percussive synthesis that builds on sinusoidal modeling synthesis and incorporates a modulated temporal convolutional network for transient generation. We use a modified sinusoidal peak picking algorithm to generate time-varying non-harmonic sinusoids and pair it with differentiable noise and transient encoders that are jointly trained to reconstruct drumset sounds. We compute a set of reconstruction metrics using a large dataset of acoustic and electronic percussion samples that show that our method leads to improved onset signal reconstruction for membranophone percussion instruments.