 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Near-Linear Time Algorithm for the Chamfer Distance
Jul 06, 2023


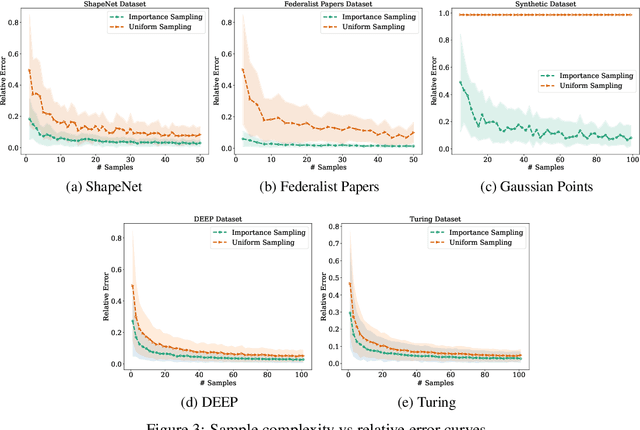
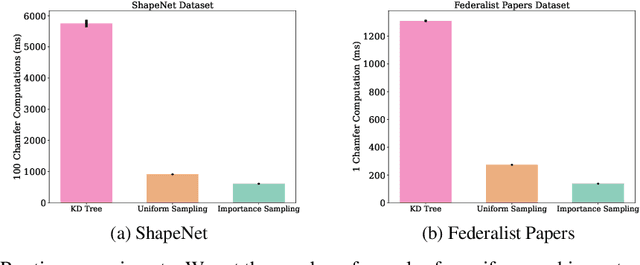
For any two point sets $A,B \subset \mathbb{R}^d$ of size up to $n$, the Chamfer distance from $A$ to $B$ is defined as $\text{CH}(A,B)=\sum_{a \in A} \min_{b \in B} d_X(a,b)$, where $d_X$ is the underlying distance measure (e.g., the Euclidean or Manhattan distance). The Chamfer distance is a popular measure of dissimilarity between point clouds, used in many machine learning, computer vision, and graphics applications, and admits a straightforward $O(d n^2)$-time brute force algorithm. Further, the Chamfer distance is often used as a proxy for the more computationally demanding Earth-Mover (Optimal Transport) Distance. However, the \emph{quadratic} dependence on $n$ in the running time makes the naive approach intractable for large datasets. We overcome this bottleneck and present the first $(1+\epsilon)$-approximate algorithm for estimating the Chamfer distance with a near-linear running time. Specifically, our algorithm runs in time $O(nd \log (n)/\varepsilon^2)$ and is implementable. Our experiments demonstrate that it is both accurate and fast on large high-dimensional datasets. We believe that our algorithm will open new avenues for analyzing large high-dimensional point clouds. We also give evidence that if the goal is to \emph{report} a $(1+\varepsilon)$-approximate mapping from $A$ to $B$ (as opposed to just its value), then any sub-quadratic time algorithm is unlikely to exist.
Discrete Denoising Diffusion Approach to Integer Factorization
Sep 11, 2023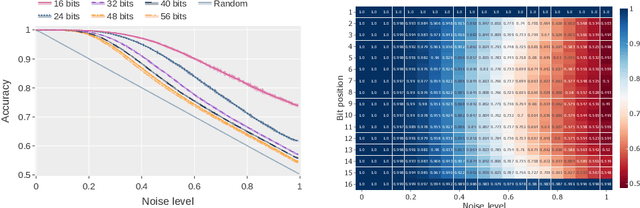
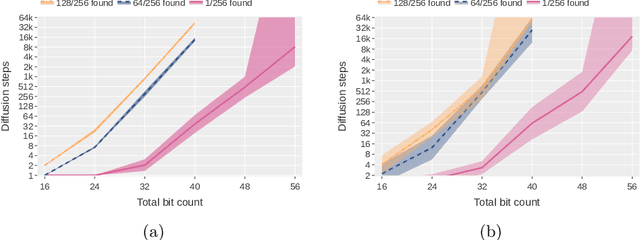
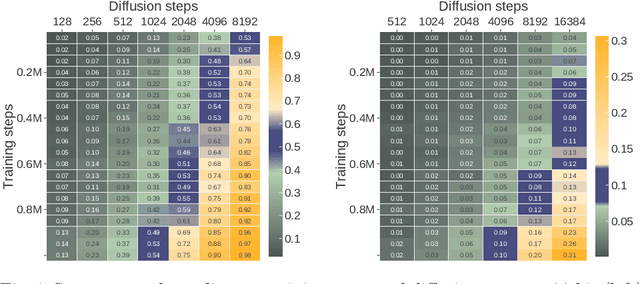
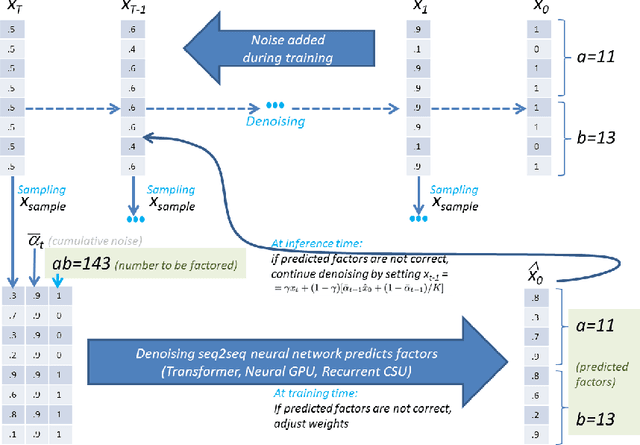
Integer factorization is a famous computational problem unknown whether being solvable in the polynomial time. With the rise of deep neural networks, it is interesting whether they can facilitate faster factorization. We present an approach to factorization utilizing deep neural networks and discrete denoising diffusion that works by iteratively correcting errors in a partially-correct solution. To this end, we develop a new seq2seq neural network architecture, employ relaxed categorical distribution and adapt the reverse diffusion process to cope better with inaccuracies in the denoising step. The approach is able to find factors for integers of up to 56 bits long. Our analysis indicates that investment in training leads to an exponential decrease of sampling steps required at inference to achieve a given success rate, thus counteracting an exponential run-time increase depending on the bit-length.
AI-Driven Patient Monitoring with Multi-Agent Deep Reinforcement Learning
Sep 24, 2023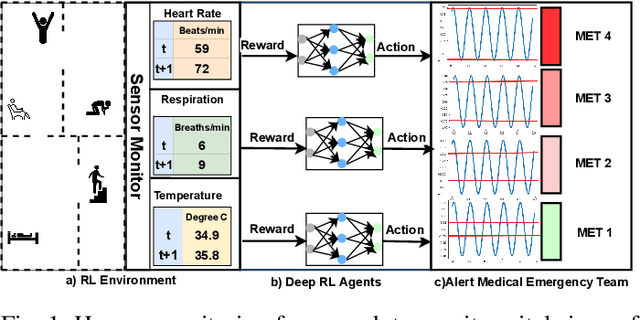
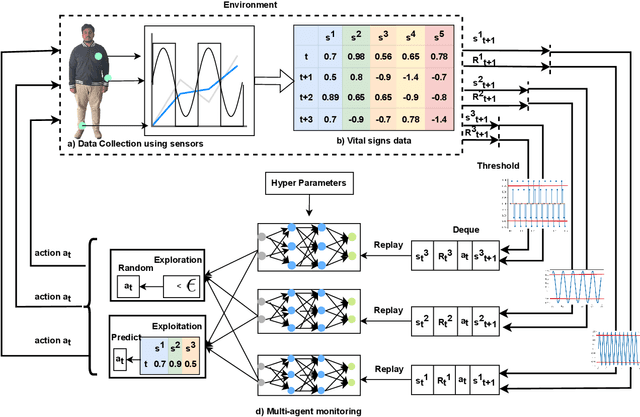
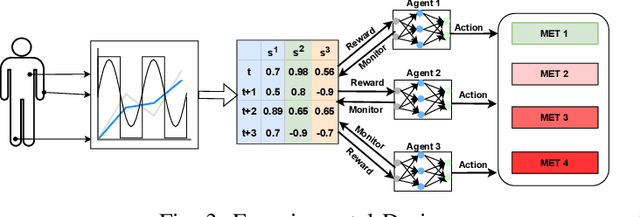
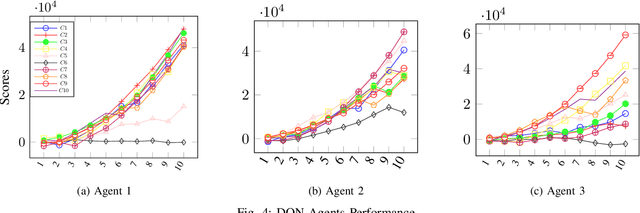
Effective patient monitoring is vital for timely interventions and improved healthcare outcomes. Traditional monitoring systems often struggle to handle complex, dynamic environments with fluctuating vital signs, leading to delays in identifying critical conditions. To address this challenge, we propose a novel AI-driven patient monitoring framework using multi-agent deep reinforcement learning (DRL). Our approach deploys multiple learning agents, each dedicated to monitoring a specific physiological feature, such as heart rate, respiration, and temperature. These agents interact with a generic healthcare monitoring environment, learn the patients' behavior patterns, and make informed decisions to alert the corresponding Medical Emergency Teams (METs) based on the level of emergency estimated. In this study, we evaluate the performance of the proposed multi-agent DRL framework using real-world physiological and motion data from two datasets: PPG-DaLiA and WESAD. We compare the results with several baseline models, including Q-Learning, PPO, Actor-Critic, Double DQN, and DDPG, as well as monitoring frameworks like WISEML and CA-MAQL. Our experiments demonstrate that the proposed DRL approach outperforms all other baseline models, achieving more accurate monitoring of patient's vital signs. Furthermore, we conduct hyperparameter optimization to fine-tune the learning process of each agent. By optimizing hyperparameters, we enhance the learning rate and discount factor, thereby improving the agents' overall performance in monitoring patient health status. Our AI-driven patient monitoring system offers several advantages over traditional methods, including the ability to handle complex and uncertain environments, adapt to varying patient conditions, and make real-time decisions without external supervision.
Machine-assisted mixed methods: augmenting humanities and social sciences with artificial intelligence
Sep 24, 2023
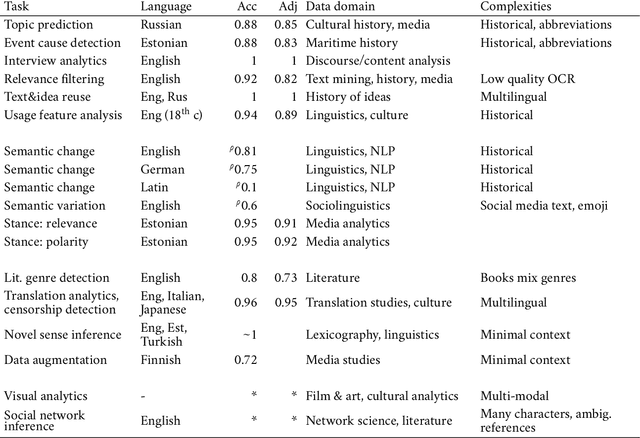

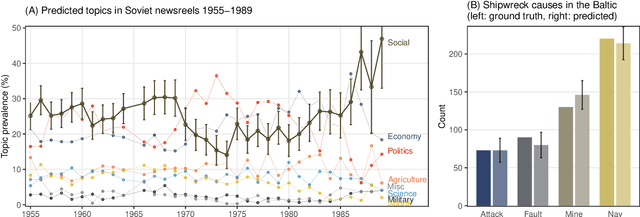
The increasing capacities of large language models (LLMs) present an unprecedented opportunity to scale up data analytics in the humanities and social sciences, augmenting and automating qualitative analytic tasks previously typically allocated to human labor. This contribution proposes a systematic mixed methods framework to harness qualitative analytic expertise, machine scalability, and rigorous quantification, with attention to transparency and replicability. 16 machine-assisted case studies are showcased as proof of concept. Tasks include linguistic and discourse analysis, lexical semantic change detection, interview analysis, historical event cause inference and text mining, detection of political stance, text and idea reuse, genre composition in literature and film; social network inference, automated lexicography, missing metadata augmentation, and multimodal visual cultural analytics. In contrast to the focus on English in the emerging LLM applicability literature, many examples here deal with scenarios involving smaller languages and historical texts prone to digitization distortions. In all but the most difficult tasks requiring expert knowledge, generative LLMs can demonstrably serve as viable research instruments. LLM (and human) annotations may contain errors and variation, but the agreement rate can and should be accounted for in subsequent statistical modeling; a bootstrapping approach is discussed. The replications among the case studies illustrate how tasks previously requiring potentially months of team effort and complex computational pipelines, can now be accomplished by an LLM-assisted scholar in a fraction of the time. Importantly, this approach is not intended to replace, but to augment researcher knowledge and skills. With these opportunities in sight, qualitative expertise and the ability to pose insightful questions have arguably never been more critical.
Effect of roundabout design on the behavior of road users: A case study of roundabouts with application of Unsupervised Machine Learning
Sep 25, 2023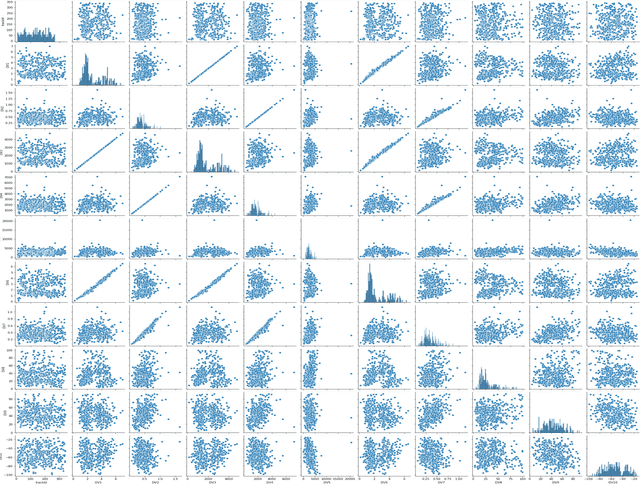
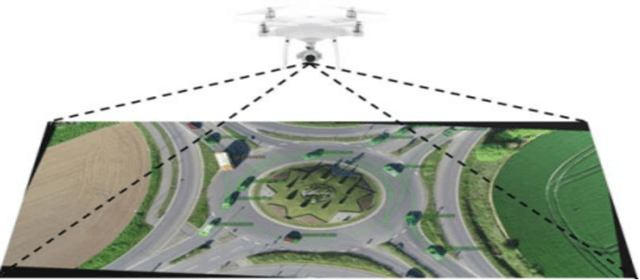
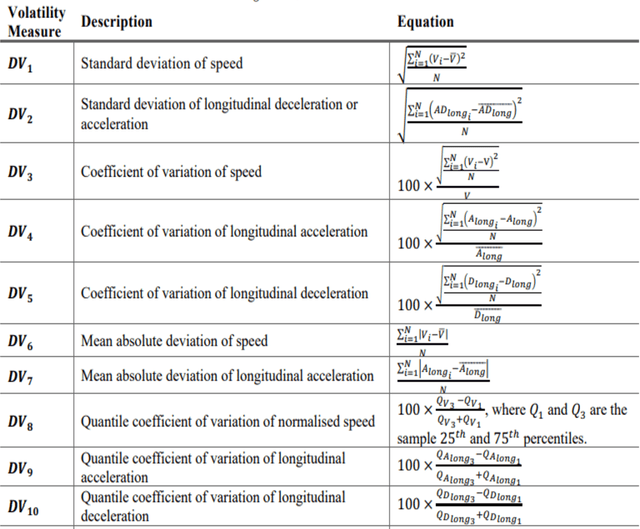
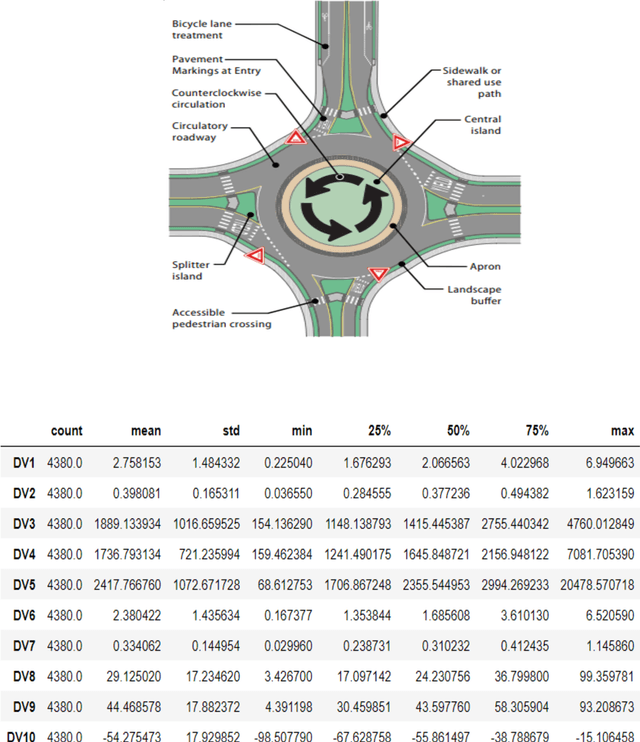
This research aims to evaluate the performance of the rotors and study the behavior of the human driver in interacting with the rotors. In recent years, rotors have been increasingly used between countries due to their safety, capacity, and environmental advantages, and because they provide safe and fluid flows of vehicles for transit and integration. It turns out that roundabouts can significantly reduce speed at twisting intersections, entry speed and the resulting effect on speed depends on the rating of road users. In our research, (bus, car, truck) drivers were given special attention and their behavior was categorized into (conservative, normal, aggressive). Anticipating and recognizing driver behavior is an important challenge. Therefore, the aim of this research is to study the effect of roundabouts on these classifiers and to develop a method for predicting the behavior of road users at roundabout intersections. Safety is primarily due to two inherent features of the rotor. First, by comparing the data collected and processed in order to classify and evaluate drivers' behavior, and comparing the speeds of the drivers (bus, car and truck), the speed of motorists at crossing the roundabout was more fit than that of buses and trucks. We looked because the car is smaller and all parts of the rotor are visible to it. So drivers coming from all directions have to slow down, giving them more time to react and mitigating the consequences in the event of an accident. Second, with fewer conflicting flows (and points of conflict), drivers only need to look to their left (in right-hand traffic) for other vehicles, making their job of crossing the roundabout easier as there is less need to split attention between different directions.
Encoding Seasonal Climate Predictions for Demand Forecasting with Modular Neural Network
Sep 05, 2023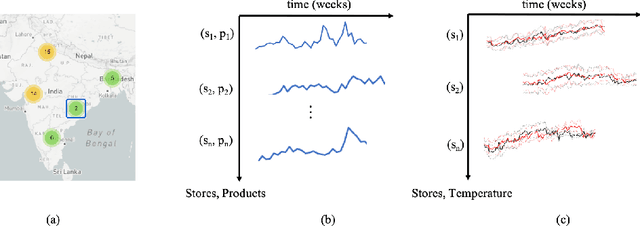
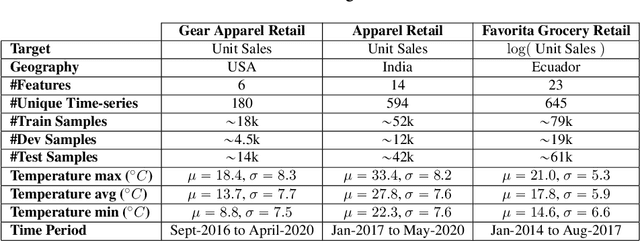
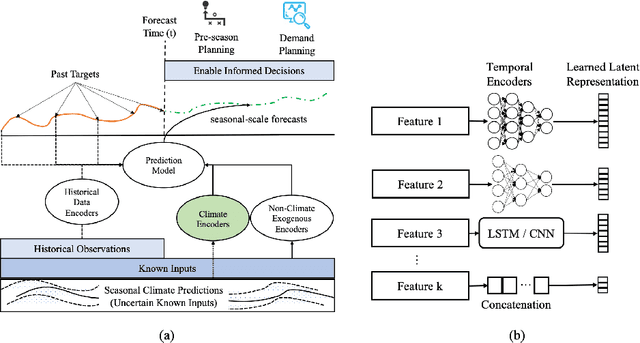
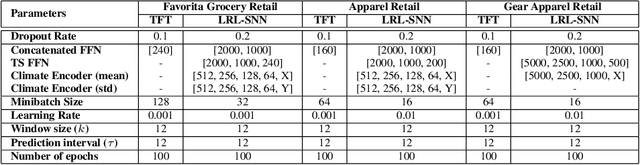
Current time-series forecasting problems use short-term weather attributes as exogenous inputs. However, in specific time-series forecasting solutions (e.g., demand prediction in the supply chain), seasonal climate predictions are crucial to improve its resilience. Representing mid to long-term seasonal climate forecasts is challenging as seasonal climate predictions are uncertain, and encoding spatio-temporal relationship of climate forecasts with demand is complex. We propose a novel modeling framework that efficiently encodes seasonal climate predictions to provide robust and reliable time-series forecasting for supply chain functions. The encoding framework enables effective learning of latent representations -- be it uncertain seasonal climate prediction or other time-series data (e.g., buyer patterns) -- via a modular neural network architecture. Our extensive experiments indicate that learning such representations to model seasonal climate forecast results in an error reduction of approximately 13\% to 17\% across multiple real-world data sets compared to existing demand forecasting methods.
Differentiable short-time Fourier transform with respect to the hop length
Jul 26, 2023In this paper, we propose a differentiable version of the short-time Fourier transform (STFT) that allows for gradient-based optimization of the hop length or the frame temporal position by making these parameters continuous. Our approach provides improved control over the temporal positioning of frames, as the continuous nature of the hop length allows for a more finely-tuned optimization. Furthermore, our contribution enables the use of optimization methods such as gradient descent, which are more computationally efficient than conventional discrete optimization methods. Our differentiable STFT can also be easily integrated into existing algorithms and neural networks. We present a simulated illustration to demonstrate the efficacy of our approach and to garner interest from the research community.
Stabilizing Training with Soft Dynamic Time Warping: A Case Study for Pitch Class Estimation with Weakly Aligned Targets
Aug 10, 2023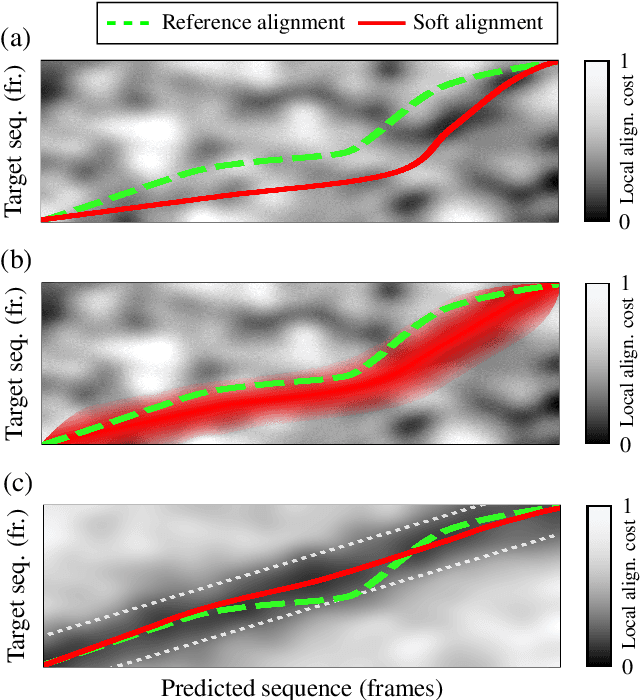
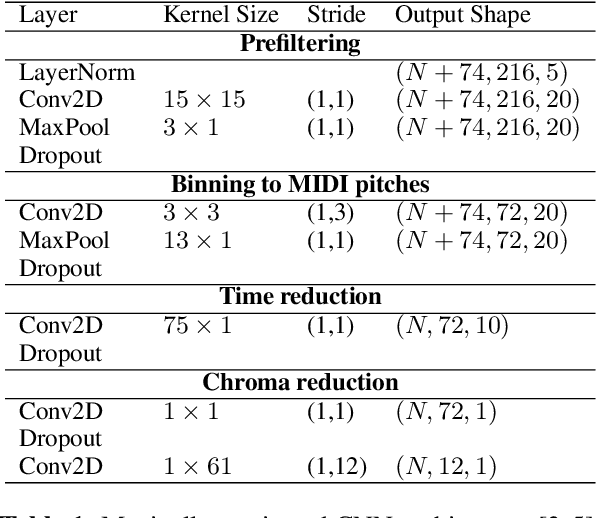
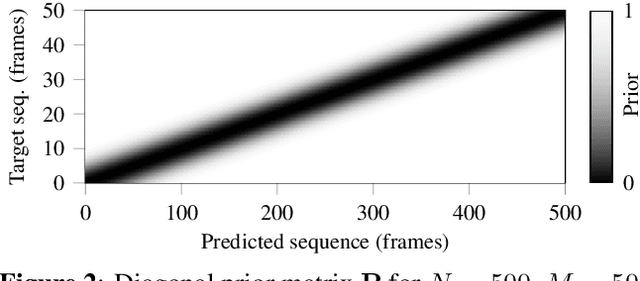
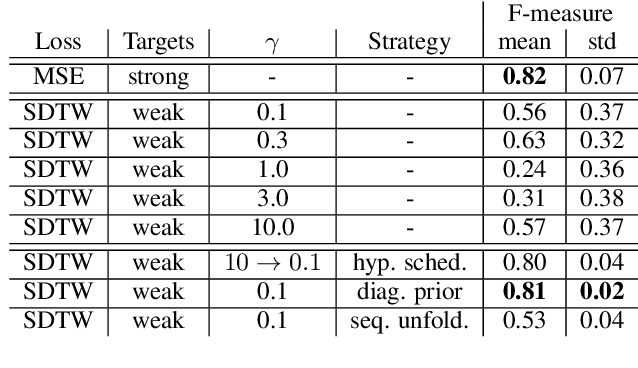
Soft dynamic time warping (SDTW) is a differentiable loss function that allows for training neural networks from weakly aligned data. Typically, SDTW is used to iteratively compute and refine soft alignments that compensate for temporal deviations between the training data and its weakly annotated targets. One major problem is that a mismatch between the estimated soft alignments and the reference alignments in the early training stage leads to incorrect parameter updates, making the overall training procedure unstable. In this paper, we investigate such stability issues by considering the task of pitch class estimation from music recordings as an illustrative case study. In particular, we introduce and discuss three conceptually different strategies (a hyperparameter scheduling, a diagonal prior, and a sequence unfolding strategy) with the objective of stabilizing intermediate soft alignment results. Finally, we report on experiments that demonstrate the effectiveness of the strategies and discuss efficiency and implementation issues.
DRG-LLaMA : Tuning LLaMA Model to Predict Diagnosis-related Group for Hospitalized Patients
Sep 22, 2023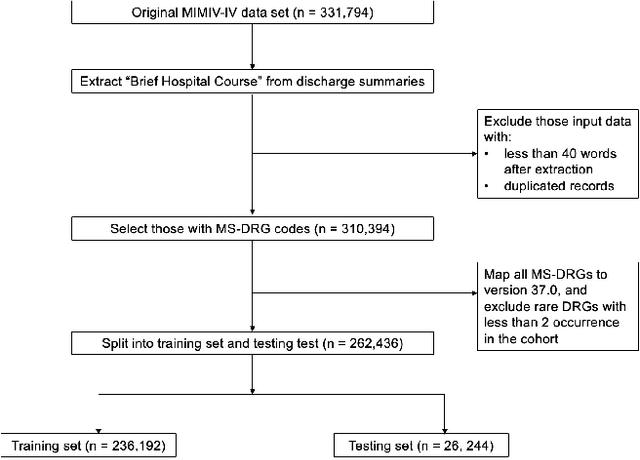
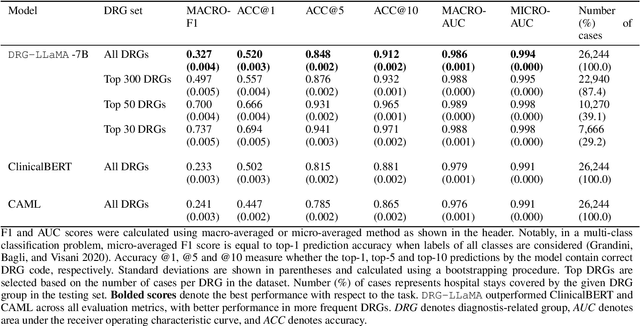
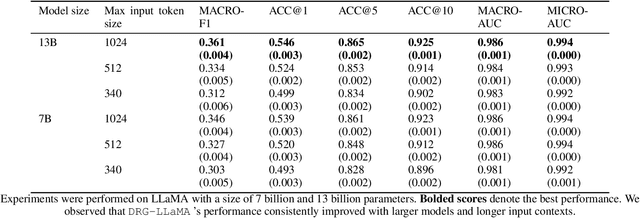
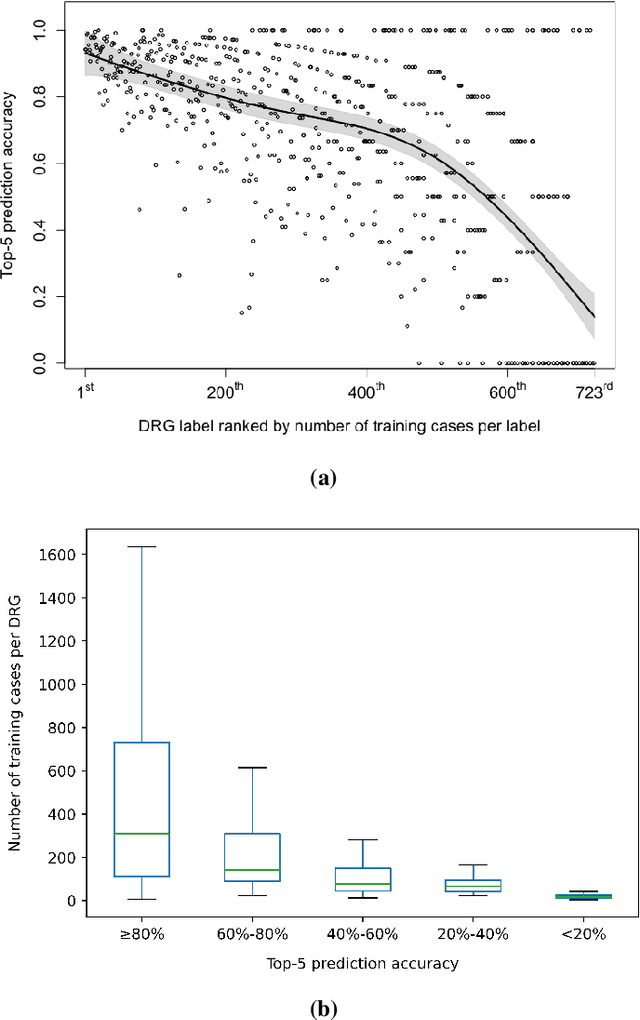
In the U.S. inpatient payment system, the Diagnosis-Related Group (DRG) plays a key role but its current assignment process is time-consuming. We introduce DRG-LLaMA, a large language model (LLM) fine-tuned on clinical notes for improved DRG prediction. Using Meta's LLaMA as the base model, we optimized it with Low-Rank Adaptation (LoRA) on 236,192 MIMIC-IV discharge summaries. With an input token length of 512, DRG-LLaMA-7B achieved a macro-averaged F1 score of 0.327, a top-1 prediction accuracy of 52.0% and a macro-averaged Area Under the Curve (AUC) of 0.986. Impressively, DRG-LLaMA-7B surpassed previously reported leading models on this task, demonstrating a relative improvement in macro-averaged F1 score of 40.3% compared to ClinicalBERT and 35.7% compared to CAML. When DRG-LLaMA is applied to predict base DRGs and complication or comorbidity (CC) / major complication or comorbidity (MCC), the top-1 prediction accuracy reached 67.8% for base DRGs and 67.5% for CC/MCC status. DRG-LLaMA performance exhibits improvements in correlation with larger model parameters and longer input context lengths. Furthermore, usage of LoRA enables training even on smaller GPUs with 48 GB of VRAM, highlighting the viability of adapting LLMs for DRGs prediction.
Beta Diffusion
Sep 14, 2023

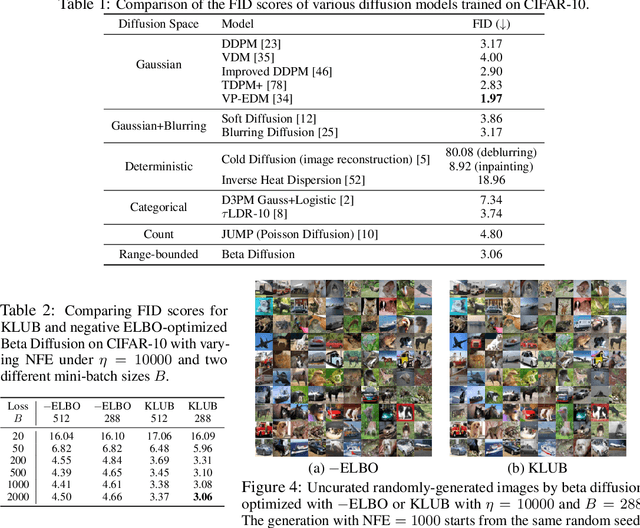
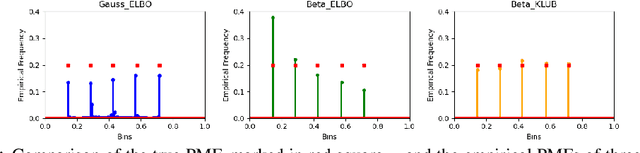
We introduce beta diffusion, a novel generative modeling method that integrates demasking and denoising to generate data within bounded ranges. Using scaled and shifted beta distributions, beta diffusion utilizes multiplicative transitions over time to create both forward and reverse diffusion processes, maintaining beta distributions in both the forward marginals and the reverse conditionals, given the data at any point in time. Unlike traditional diffusion-based generative models relying on additive Gaussian noise and reweighted evidence lower bounds (ELBOs), beta diffusion is multiplicative and optimized with KL-divergence upper bounds (KLUBs) derived from the convexity of the KL divergence. We demonstrate that the proposed KLUBs are more effective for optimizing beta diffusion compared to negative ELBOs, which can also be derived as the KLUBs of the same KL divergence with its two arguments swapped. The loss function of beta diffusion, expressed in terms of Bregman divergence, further supports the efficacy of KLUBs for optimization. Experimental results on both synthetic data and natural images demonstrate the unique capabilities of beta diffusion in generative modeling of range-bounded data and validate the effectiveness of KLUBs in optimizing diffusion models, thereby making them valuable additions to the family of diffusion-based generative models and the optimization techniques used to train them.