 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Multiagent Reinforcement Learning with an Attention Mechanism for Improving Energy Efficiency in LoRa Networks
Sep 16, 2023
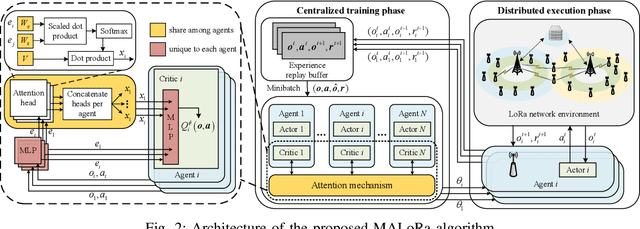
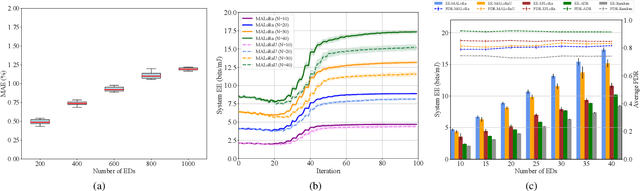
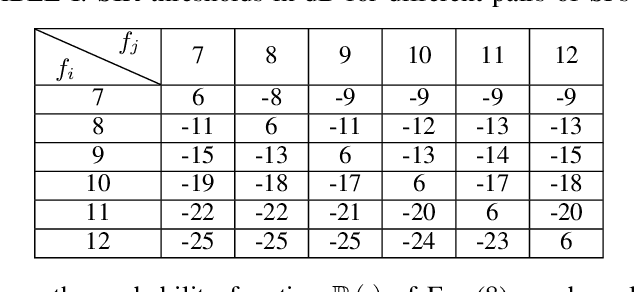
Long Range (LoRa) wireless technology, characterized by low power consumption and a long communication range, is regarded as one of the enabling technologies for the Industrial Internet of Things (IIoT). However, as the network scale increases, the energy efficiency (EE) of LoRa networks decreases sharply due to severe packet collisions. To address this issue, it is essential to appropriately assign transmission parameters such as the spreading factor and transmission power for each end device (ED). However, due to the sporadic traffic and low duty cycle of LoRa networks, evaluating the system EE performance under different parameter settings is time-consuming. Therefore, we first formulate an analytical model to calculate the system EE. On this basis, we propose a transmission parameter allocation algorithm based on multiagent reinforcement learning (MALoRa) with the aim of maximizing the system EE of LoRa networks. Notably, MALoRa employs an attention mechanism to guide each ED to better learn how much ''attention'' should be given to the parameter assignments for relevant EDs when seeking to improve the system EE. Simulation results demonstrate that MALoRa significantly improves the system EE compared with baseline algorithms with an acceptable degradation in packet delivery rate (PDR).
Reducing Memory Requirements for the IPU using Butterfly Factorizations
Sep 16, 2023High Performance Computing (HPC) benefits from different improvements during last decades, specially in terms of hardware platforms to provide more processing power while maintaining the power consumption at a reasonable level. The Intelligence Processing Unit (IPU) is a new type of massively parallel processor, designed to speedup parallel computations with huge number of processing cores and on-chip memory components connected with high-speed fabrics. IPUs mainly target machine learning applications, however, due to the architectural differences between GPUs and IPUs, especially significantly less memory capacity on an IPU, methods for reducing model size by sparsification have to be considered. Butterfly factorizations are well-known replacements for fully-connected and convolutional layers. In this paper, we examine how butterfly structures can be implemented on an IPU and study their behavior and performance compared to a GPU. Experimental results indicate that these methods can provide 98.5% compression ratio to decrease the immense need for memory, the IPU implementation can benefit from 1.3x and 1.6x performance improvement for butterfly and pixelated butterfly, respectively. We also reach to 1.62x training time speedup on a real-word dataset such as CIFAR10.
Contrastive Learning and Data Augmentation in Traffic Classification Using a Flowpic Input Representation
Sep 18, 2023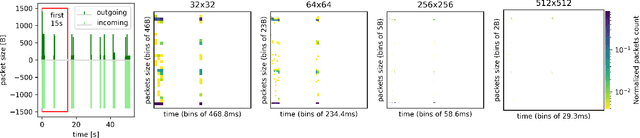

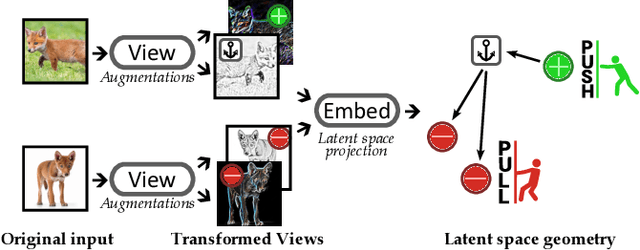
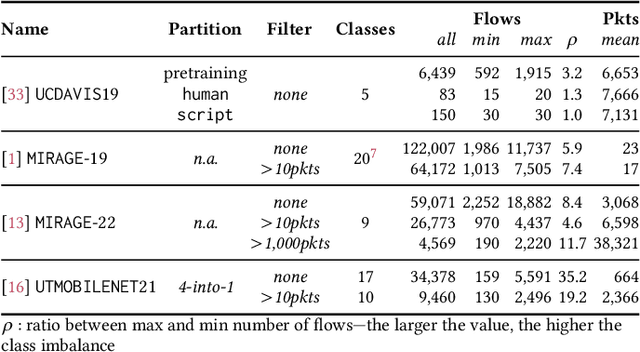
Over the last years we witnessed a renewed interest towards Traffic Classification (TC) captivated by the rise of Deep Learning (DL). Yet, the vast majority of TC literature lacks code artifacts, performance assessments across datasets and reference comparisons against Machine Learning (ML) methods. Among those works, a recent study from IMC'22 [17] is worth of attention since it adopts recent DL methodologies (namely, few-shot learning, self-supervision via contrastive learning and data augmentation) appealing for networking as they enable to learn from a few samples and transfer across datasets. The main result of [17] on the UCDAVIS19, ISCX-VPN and ISCX-Tor datasets is that, with such DL methodologies, 100 input samples are enough to achieve very high accuracy using an input representation called "flowpic" (i.e., a per-flow 2d histograms of the packets size evolution over time). In this paper (i) we reproduce [17] on the same datasets and (ii) we replicate its most salient aspect (the importance of data augmentation) on three additional public datasets, MIRAGE-19, MIRAGE-22 and UTMOBILENET21. While we confirm most of the original results, we also found a 20% accuracy drop on some of the investigated scenarios due to a data shift in the original dataset that we uncovered. Additionally, our study validates that the data augmentation strategies studied in [17] perform well on other datasets too. In the spirit of reproducibility and replicability we make all artifacts (code and data) available at [10].
Asynchronous Perception-Action-Communication with Graph Neural Networks
Sep 18, 2023Collaboration in large robot swarms to achieve a common global objective is a challenging problem in large environments due to limited sensing and communication capabilities. The robots must execute a Perception-Action-Communication (PAC) loop -- they perceive their local environment, communicate with other robots, and take actions in real time. A fundamental challenge in decentralized PAC systems is to decide what information to communicate with the neighboring robots and how to take actions while utilizing the information shared by the neighbors. Recently, this has been addressed using Graph Neural Networks (GNNs) for applications such as flocking and coverage control. Although conceptually, GNN policies are fully decentralized, the evaluation and deployment of such policies have primarily remained centralized or restrictively decentralized. Furthermore, existing frameworks assume sequential execution of perception and action inference, which is very restrictive in real-world applications. This paper proposes a framework for asynchronous PAC in robot swarms, where decentralized GNNs are used to compute navigation actions and generate messages for communication. In particular, we use aggregated GNNs, which enable the exchange of hidden layer information between robots for computational efficiency and decentralized inference of actions. Furthermore, the modules in the framework are asynchronous, allowing robots to perform sensing, extracting information, communication, action inference, and control execution at different frequencies. We demonstrate the effectiveness of GNNs executed in the proposed framework in navigating large robot swarms for collaborative coverage of large environments.
Selective Volume Mixup for Video Action Recognition
Sep 18, 2023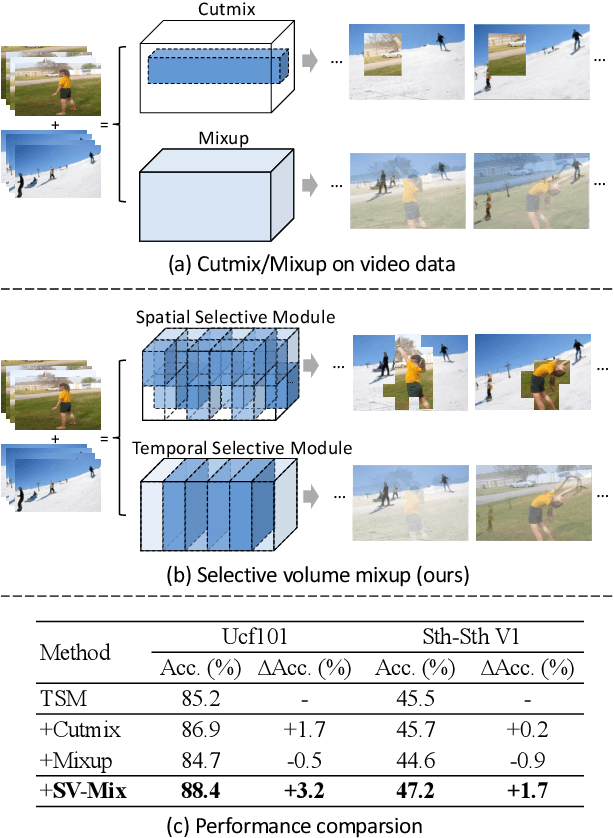
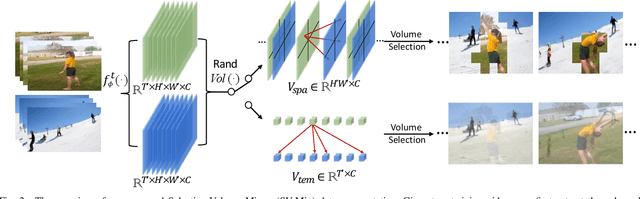
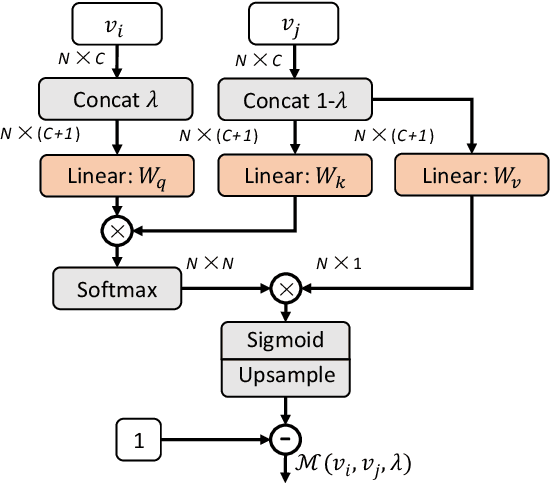
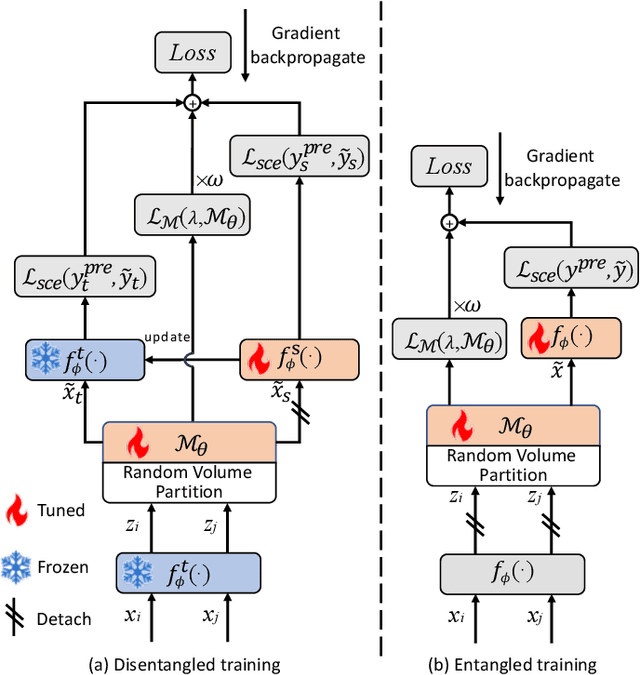
The recent advances in Convolutional Neural Networks (CNNs) and Vision Transformers have convincingly demonstrated high learning capability for video action recognition on large datasets. Nevertheless, deep models often suffer from the overfitting effect on small-scale datasets with a limited number of training videos. A common solution is to exploit the existing image augmentation strategies for each frame individually including Mixup, Cutmix, and RandAugment, which are not particularly optimized for video data. In this paper, we propose a novel video augmentation strategy named Selective Volume Mixup (SV-Mix) to improve the generalization ability of deep models with limited training videos. SV-Mix devises a learnable selective module to choose the most informative volumes from two videos and mixes the volumes up to achieve a new training video. Technically, we propose two new modules, i.e., a spatial selective module to select the local patches for each spatial position, and a temporal selective module to mix the entire frames for each timestamp and maintain the spatial pattern. At each time, we randomly choose one of the two modules to expand the diversity of training samples. The selective modules are jointly optimized with the video action recognition framework to find the optimal augmentation strategy. We empirically demonstrate the merits of the SV-Mix augmentation on a wide range of video action recognition benchmarks and consistently boot the performances of both CNN-based and transformer-based models.
Scalable Label-efficient Footpath Network Generation Using Remote Sensing Data and Self-supervised Learning
Sep 18, 2023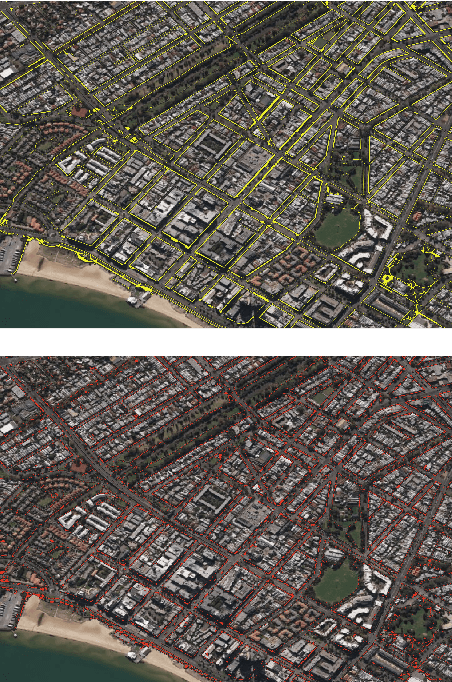
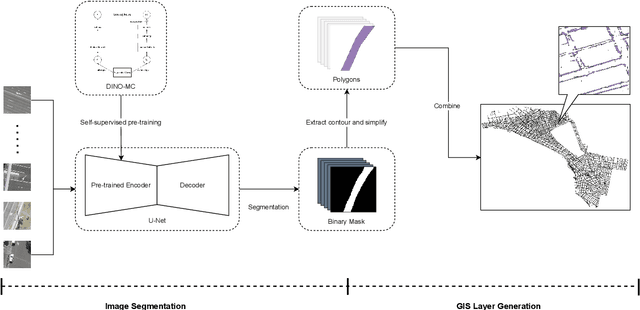
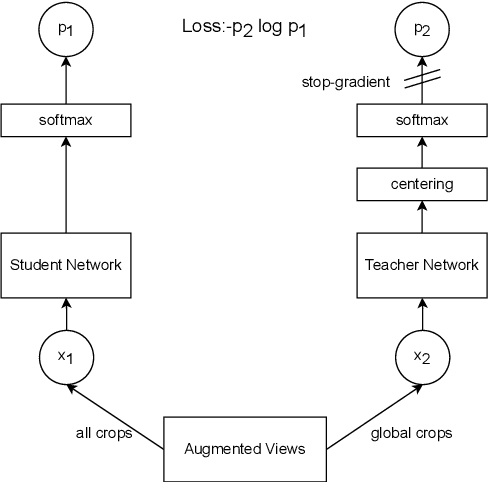
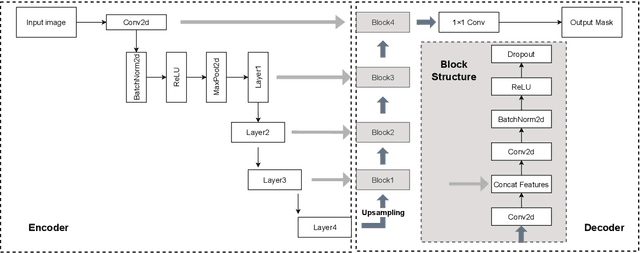
Footpath mapping, modeling, and analysis can provide important geospatial insights to many fields of study, including transport, health, environment and urban planning. The availability of robust Geographic Information System (GIS) layers can benefit the management of infrastructure inventories, especially at local government level with urban planners responsible for the deployment and maintenance of such infrastructure. However, many cities still lack real-time information on the location, connectivity, and width of footpaths, and/or employ costly and manual survey means to gather this information. This work designs and implements an automatic pipeline for generating footpath networks based on remote sensing images using machine learning models. The annotation of segmentation tasks, especially labeling remote sensing images with specialized requirements, is very expensive, so we aim to introduce a pipeline requiring less labeled data. Considering supervised methods require large amounts of training data, we use a self-supervised method for feature representation learning to reduce annotation requirements. Then the pre-trained model is used as the encoder of the U-Net for footpath segmentation. Based on the generated masks, the footpath polygons are extracted and converted to footpath networks which can be loaded and visualized by geographic information systems conveniently. Validation results indicate considerable consistency when compared to manually collected GIS layers. The footpath network generation pipeline proposed in this work is low-cost and extensible, and it can be applied where remote sensing images are available. Github: https://github.com/WennyXY/FootpathSeg.
Towards Practical Capture of High-Fidelity Relightable Avatars
Sep 08, 2023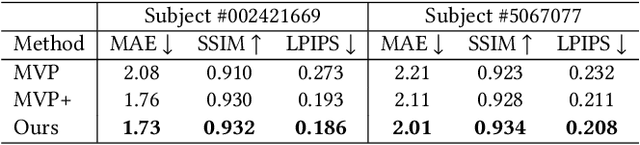
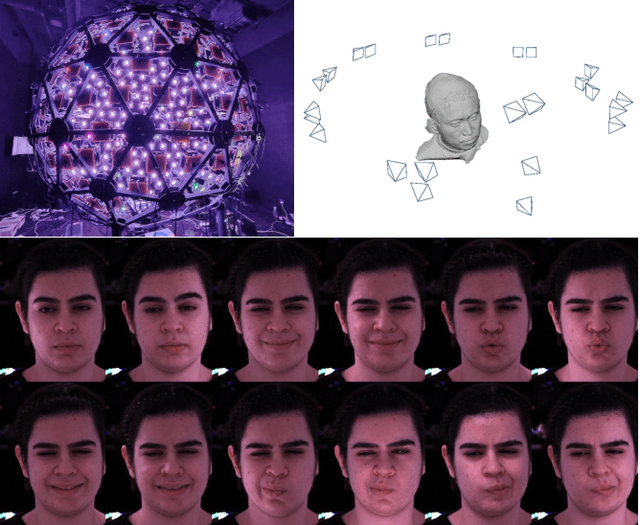
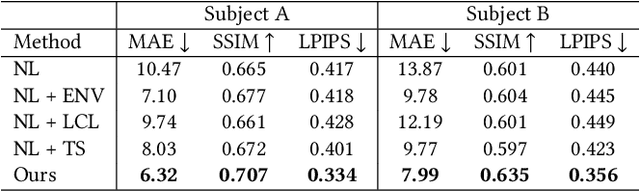
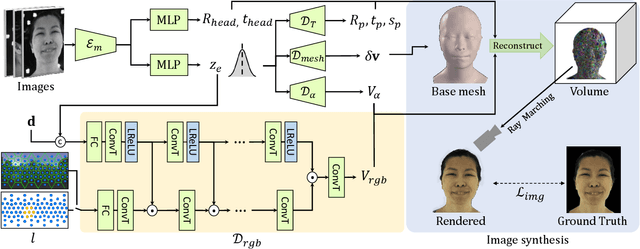
In this paper, we propose a novel framework, Tracking-free Relightable Avatar (TRAvatar), for capturing and reconstructing high-fidelity 3D avatars. Compared to previous methods, TRAvatar works in a more practical and efficient setting. Specifically, TRAvatar is trained with dynamic image sequences captured in a Light Stage under varying lighting conditions, enabling realistic relighting and real-time animation for avatars in diverse scenes. Additionally, TRAvatar allows for tracking-free avatar capture and obviates the need for accurate surface tracking under varying illumination conditions. Our contributions are two-fold: First, we propose a novel network architecture that explicitly builds on and ensures the satisfaction of the linear nature of lighting. Trained on simple group light captures, TRAvatar can predict the appearance in real-time with a single forward pass, achieving high-quality relighting effects under illuminations of arbitrary environment maps. Second, we jointly optimize the facial geometry and relightable appearance from scratch based on image sequences, where the tracking is implicitly learned. This tracking-free approach brings robustness for establishing temporal correspondences between frames under different lighting conditions. Extensive qualitative and quantitative experiments demonstrate that our framework achieves superior performance for photorealistic avatar animation and relighting.
Multi-fidelity reduced-order surrogate modeling
Sep 01, 2023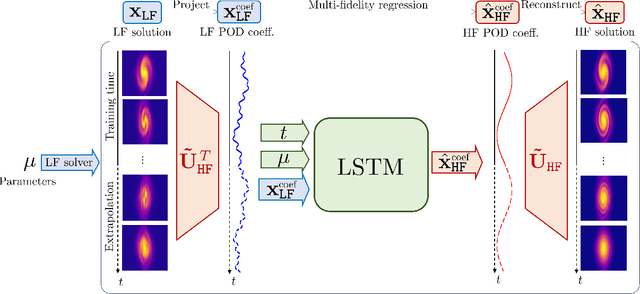

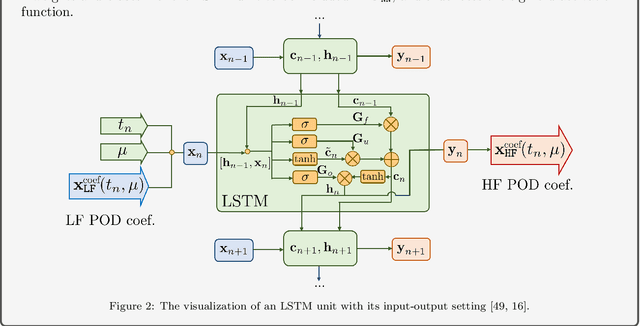

High-fidelity numerical simulations of partial differential equations (PDEs) given a restricted computational budget can significantly limit the number of parameter configurations considered and/or time window evaluated for modeling a given system. Multi-fidelity surrogate modeling aims to leverage less accurate, lower-fidelity models that are computationally inexpensive in order to enhance predictive accuracy when high-fidelity data are limited or scarce. However, low-fidelity models, while often displaying important qualitative spatio-temporal features, fail to accurately capture the onset of instability and critical transients observed in the high-fidelity models, making them impractical as surrogate models. To address this shortcoming, we present a new data-driven strategy that combines dimensionality reduction with multi-fidelity neural network surrogates. The key idea is to generate a spatial basis by applying the classical proper orthogonal decomposition (POD) to high-fidelity solution snapshots, and approximate the dynamics of the reduced states - time-parameter-dependent expansion coefficients of the POD basis - using a multi-fidelity long-short term memory (LSTM) network. By mapping low-fidelity reduced states to their high-fidelity counterpart, the proposed reduced-order surrogate model enables the efficient recovery of full solution fields over time and parameter variations in a non-intrusive manner. The generality and robustness of this method is demonstrated by a collection of parametrized, time-dependent PDE problems where the low-fidelity model can be defined by coarser meshes and/or time stepping, as well as by misspecified physical features. Importantly, the onset of instabilities and transients are well captured by this surrogate modeling technique.
Drift Analysis with Fitness Levels for Elitist Evolutionary Algorithms
Sep 02, 2023
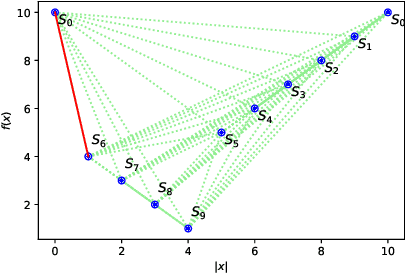
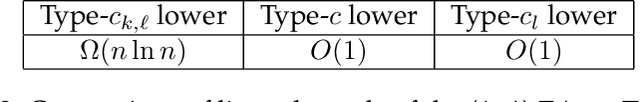

The fitness level method is a popular tool for analyzing the computation time of elitist evolutionary algorithms. Its idea is to divide the search space into multiple fitness levels and estimate lower and upper bounds on the computation time using transition probabilities between fitness levels. However, the lower bound generated from this method is often not tight. To improve the lower bound, this paper rigorously studies an open question about the fitness level method: what are the tightest lower and upper time bounds that can be constructed based on fitness levels? To answer this question, drift analysis with fitness levels is developed, and the tightest bound problem is formulated as a constrained multi-objective optimization problem subject to fitness level constraints. The tightest metric bounds from fitness levels are constructed and proven for the first time. Then the metric bounds are converted into linear bounds, where existing linear bounds are special cases. This paper establishes a general framework that can cover various linear bounds from trivial to best coefficients. It is generic and promising, as it can be used not only to draw the same bounds as existing ones, but also to draw tighter bounds, especially on fitness landscapes where shortcuts exist. This is demonstrated in the case study of the (1+1) EA maximizing the TwoPath function.
How Transferable are Attribute Controllers on Pretrained Multilingual Translation Models?
Sep 15, 2023Customizing machine translation models to comply with fine-grained attributes such as formality has seen tremendous progress recently. However, current approaches mostly rely on at least some supervised data with attribute annotation. Data scarcity therefore remains a bottleneck to democratizing such customization possibilities to a wider range of languages, lower-resource ones in particular. Given recent progress in pretrained massively multilingual translation models, we use them as a foundation to transfer the attribute controlling capabilities to languages without supervised data. In this work, we present a comprehensive analysis of transferring attribute controllers based on a pretrained NLLB-200 model. We investigate both training- and inference-time control techniques under various data scenarios, and uncover their relative strengths and weaknesses in zero-shot performance and domain robustness. We show that both paradigms are complementary, as shown by consistent improvements on 5 zero-shot directions. Moreover, a human evaluation on a real low-resource language, Bengali, confirms our findings on zero-shot transfer to new target languages. The code is $\href{https://github.com/dannigt/attribute-controller-transfer}{\text{here}}$.