 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Guided Online Distillation: Promoting Safe Reinforcement Learning by Offline Demonstration
Sep 18, 2023
Safe Reinforcement Learning (RL) aims to find a policy that achieves high rewards while satisfying cost constraints. When learning from scratch, safe RL agents tend to be overly conservative, which impedes exploration and restrains the overall performance. In many realistic tasks, e.g. autonomous driving, large-scale expert demonstration data are available. We argue that extracting expert policy from offline data to guide online exploration is a promising solution to mitigate the conserveness issue. Large-capacity models, e.g. decision transformers (DT), have been proven to be competent in offline policy learning. However, data collected in real-world scenarios rarely contain dangerous cases (e.g., collisions), which makes it prohibitive for the policies to learn safety concepts. Besides, these bulk policy networks cannot meet the computation speed requirements at inference time on real-world tasks such as autonomous driving. To this end, we propose Guided Online Distillation (GOLD), an offline-to-online safe RL framework. GOLD distills an offline DT policy into a lightweight policy network through guided online safe RL training, which outperforms both the offline DT policy and online safe RL algorithms. Experiments in both benchmark safe RL tasks and real-world driving tasks based on the Waymo Open Motion Dataset (WOMD) demonstrate that GOLD can successfully distill lightweight policies and solve decision-making problems in challenging safety-critical scenarios.
Machine Learning Approaches to Predict and Detect Early-Onset of Digital Dermatitis in Dairy Cows using Sensor Data
Sep 18, 2023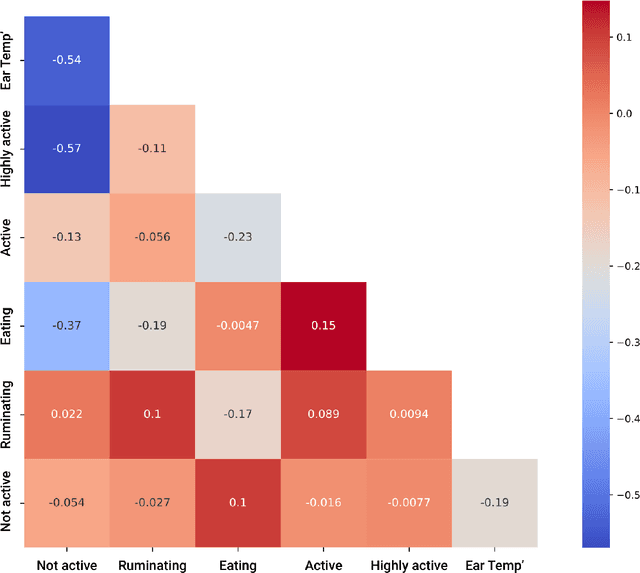
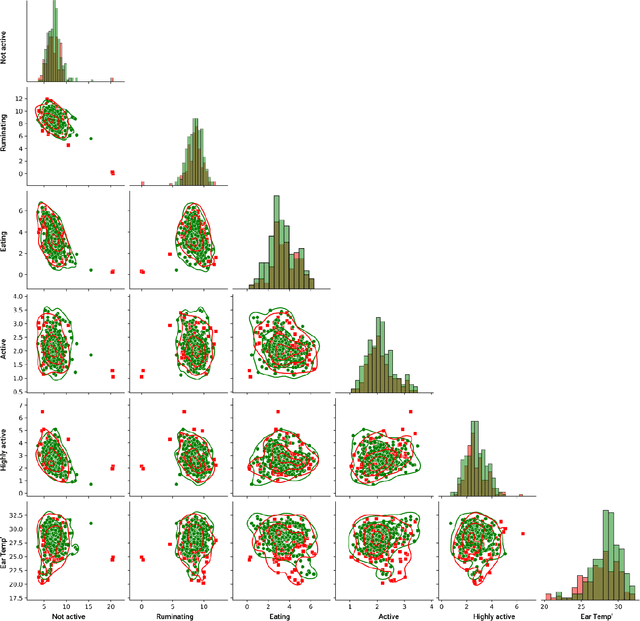
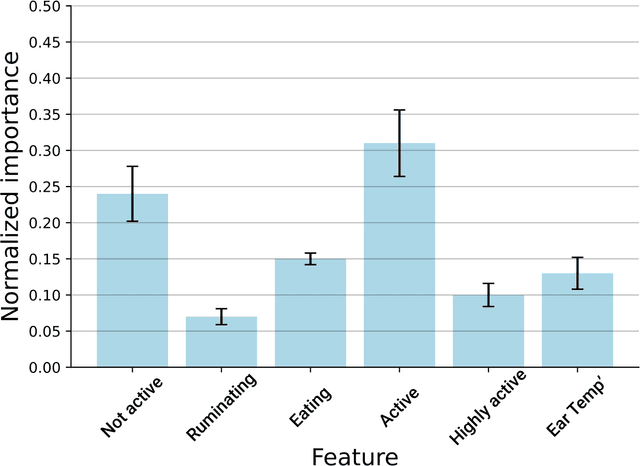
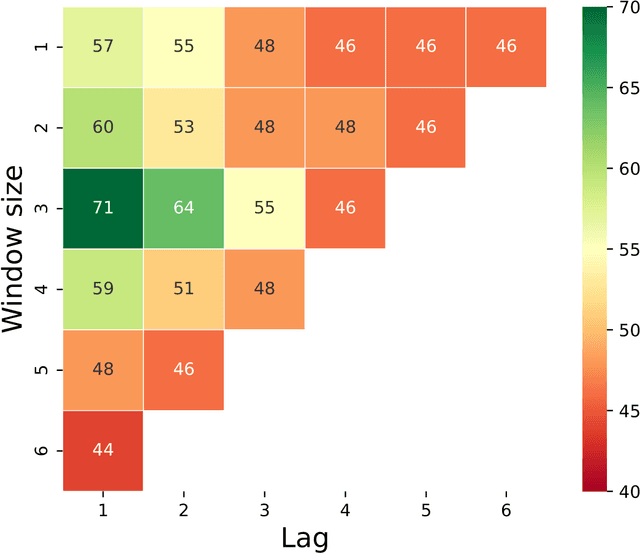
The aim of this study was to employ machine learning algorithms based on sensor behavior data for (1) early-onset detection of digital dermatitis (DD); and (2) DD prediction in dairy cows. With the ultimate goal to set-up early warning tools for DD prediction, which would than allow a better monitoring and management of DD under commercial settings, resulting in a decrease of DD prevalence and severity, while improving animal welfare. A machine learning model that is capable of predicting and detecting digital dermatitis in cows housed under free-stall conditions based on behavior sensor data has been purposed and tested in this exploratory study. The model for DD detection on day 0 of the appearance of the clinical signs has reached an accuracy of 79%, while the model for prediction of DD 2 days prior to the appearance of the first clinical signs has reached an accuracy of 64%. The proposed machine learning models could help to develop a real-time automated tool for monitoring and diagnostic of DD in lactating dairy cows, based on behavior sensor data under conventional dairy environments. Results showed that alterations in behavioral patterns at individual levels can be used as inputs in an early warning system for herd management in order to detect variances in health of individual cows.
Causal Discovery and Counterfactual Explanations for Personalized Student Learning
Sep 18, 2023The paper focuses on identifying the causes of student performance to provide personalized recommendations for improving pass rates. We introduce the need to move beyond predictive models and instead identify causal relationships. We propose using causal discovery techniques to achieve this. The study's main contributions include using causal discovery to identify causal predictors of student performance and applying counterfactual analysis to provide personalized recommendations. The paper describes the application of causal discovery methods, specifically the PC algorithm, to real-life student performance data. It addresses challenges such as sample size limitations and emphasizes the role of domain knowledge in causal discovery. The results reveal the identified causal relationships, such as the influence of earlier test grades and mathematical ability on final student performance. Limitations of this study include the reliance on domain expertise for accurate causal discovery, and the necessity of larger sample sizes for reliable results. The potential for incorrect causal structure estimations is acknowledged. A major challenge remains, which is the real-time implementation and validation of counterfactual recommendations. In conclusion, the paper demonstrates the value of causal discovery for understanding student performance and providing personalized recommendations. It highlights the challenges, benefits, and limitations of using causal inference in an educational context, setting the stage for future studies to further explore and refine these methods.
RADE: Reference-Assisted Dialogue Evaluation for Open-Domain Dialogue
Sep 15, 2023

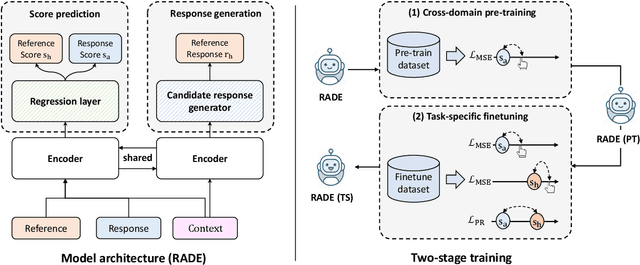
Evaluating open-domain dialogue systems is challenging for reasons such as the one-to-many problem, i.e., many appropriate responses other than just the golden response. As of now, automatic evaluation methods need better consistency with humans, while reliable human evaluation can be time- and cost-intensive. To this end, we propose the Reference-Assisted Dialogue Evaluation (RADE) approach under the multi-task learning framework, which leverages the pre-created utterance as reference other than the gold response to relief the one-to-many problem. Specifically, RADE explicitly compares reference and the candidate response to predict their overall scores. Moreover, an auxiliary response generation task enhances prediction via a shared encoder. To support RADE, we extend three datasets with additional rated responses other than just a golden response by human annotation. Experiments on our three datasets and two existing benchmarks demonstrate the effectiveness of our method, where Pearson, Spearman, and Kendall correlations with human evaluation outperform state-of-the-art baselines.
MAVIS: Multi-Camera Augmented Visual-Inertial SLAM using SE2(3) Based Exact IMU Pre-integration
Sep 15, 2023
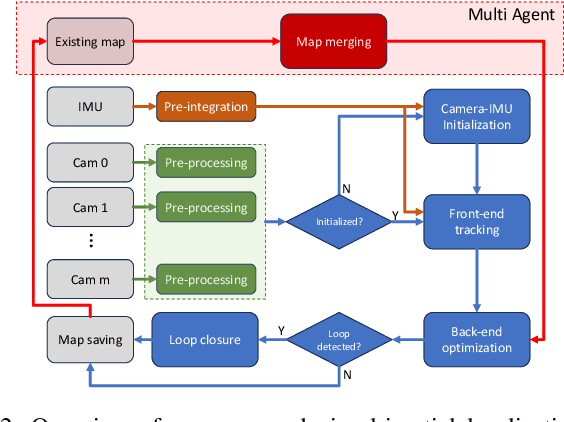
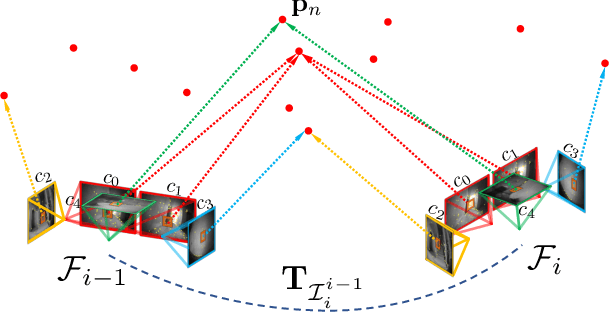
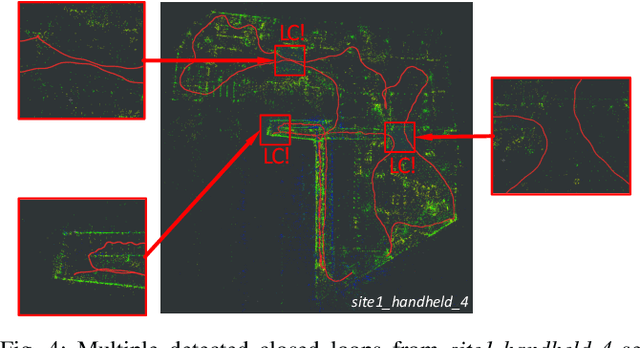
We present a novel optimization-based Visual-Inertial SLAM system designed for multiple partially overlapped camera systems, named MAVIS. Our framework fully exploits the benefits of wide field-of-view from multi-camera systems, and the metric scale measurements provided by an inertial measurement unit (IMU). We introduce an improved IMU pre-integration formulation based on the exponential function of an automorphism of SE_2(3), which can effectively enhance tracking performance under fast rotational motion and extended integration time. Furthermore, we extend conventional front-end tracking and back-end optimization module designed for monocular or stereo setup towards multi-camera systems, and introduce implementation details that contribute to the performance of our system in challenging scenarios. The practical validity of our approach is supported by our experiments on public datasets. Our MAVIS won the first place in all the vision-IMU tracks (single and multi-session SLAM) on Hilti SLAM Challenge 2023 with 1.7 times the score compared to the second place.
Diversity-based core-set selection for text-to-speech with linguistic and acoustic features
Sep 15, 2023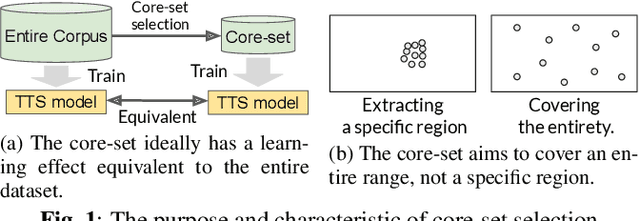
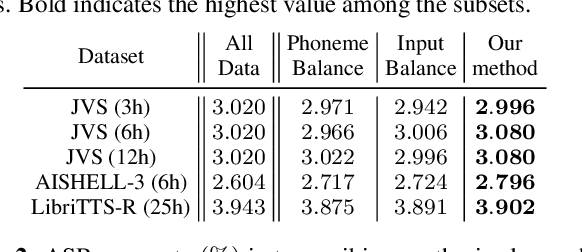
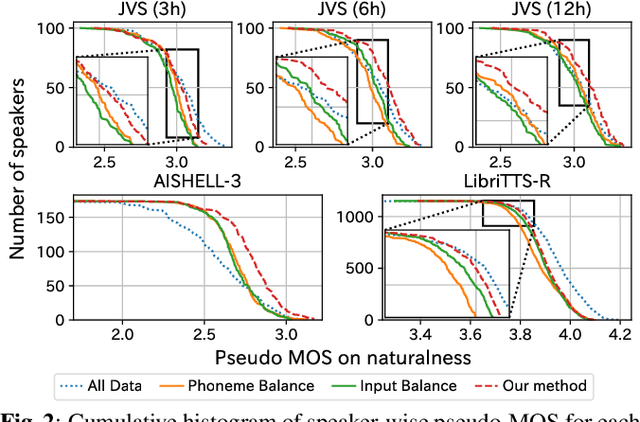
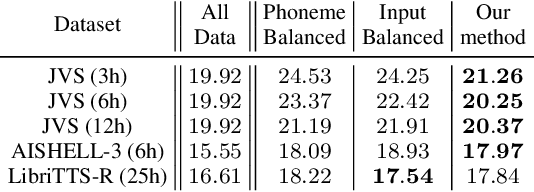
This paper proposes a method for extracting a lightweight subset from a text-to-speech (TTS) corpus ensuring synthetic speech quality. In recent years, methods have been proposed for constructing large-scale TTS corpora by collecting diverse data from massive sources such as audiobooks and YouTube. Although these methods have gained significant attention for enhancing the expressive capabilities of TTS systems, they often prioritize collecting vast amounts of data without considering practical constraints like storage capacity and computation time in training, which limits the available data quantity. Consequently, the need arises to efficiently collect data within these volume constraints. To address this, we propose a method for selecting the core subset~(known as \textit{core-set}) from a TTS corpus on the basis of a \textit{diversity metric}, which measures the degree to which a subset encompasses a wide range. Experimental results demonstrate that our proposed method performs significantly better than the baseline phoneme-balanced data selection across language and corpus size.
Large Language Models for Failure Mode Classification: An Investigation
Sep 15, 2023In this paper we present the first investigation into the effectiveness of Large Language Models (LLMs) for Failure Mode Classification (FMC). FMC, the task of automatically labelling an observation with a corresponding failure mode code, is a critical task in the maintenance domain as it reduces the need for reliability engineers to spend their time manually analysing work orders. We detail our approach to prompt engineering to enable an LLM to predict the failure mode of a given observation using a restricted code list. We demonstrate that the performance of a GPT-3.5 model (F1=0.80) fine-tuned on annotated data is a significant improvement over a currently available text classification model (F1=0.60) trained on the same annotated data set. The fine-tuned model also outperforms the out-of-the box GPT-3.5 (F1=0.46). This investigation reinforces the need for high quality fine-tuning data sets for domain-specific tasks using LLMs.
Optimizing Modular Robot Composition: A Lexicographic Genetic Algorithm Approach
Sep 15, 2023Industrial robots are designed as general-purpose hardware, which limits their ability to adapt to changing task requirements or environments. Modular robots, on the other hand, offer flexibility and can be easily customized to suit diverse needs. The morphology, i.e., the form and structure of a robot, significantly impacts the primary performance metrics acquisition cost, cycle time, and energy efficiency. However, identifying an optimal module composition for a specific task remains an open problem, presenting a substantial hurdle in developing task-tailored modular robots. Previous approaches either lack adequate exploration of the design space or the possibility to adapt to complex tasks. We propose combining a genetic algorithm with a lexicographic evaluation of solution candidates to overcome this problem and navigate search spaces exceeding those in prior work by magnitudes in the number of possible compositions. We demonstrate that our approach outperforms a state-of-the-art baseline and is able to synthesize modular robots for industrial tasks in cluttered environments.
VoicePAT: An Efficient Open-source Evaluation Toolkit for Voice Privacy Research
Sep 14, 2023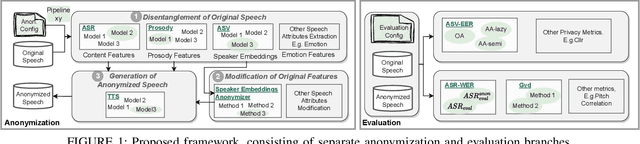
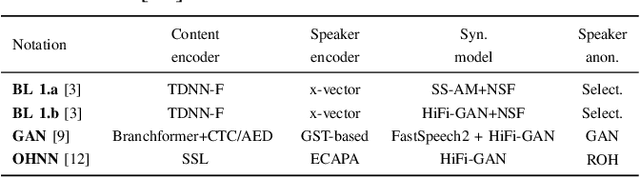

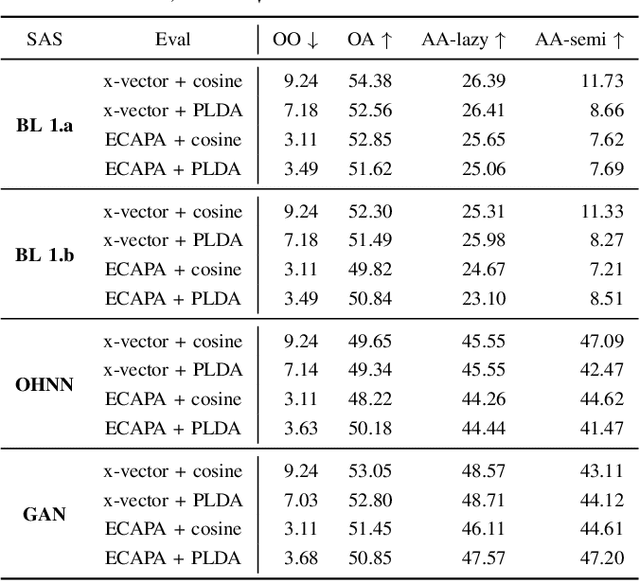
Speaker anonymization is the task of modifying a speech recording such that the original speaker cannot be identified anymore. Since the first Voice Privacy Challenge in 2020, along with the release of a framework, the popularity of this research topic is continually increasing. However, the comparison and combination of different anonymization approaches remains challenging due to the complexity of evaluation and the absence of user-friendly research frameworks. We therefore propose an efficient speaker anonymization and evaluation framework based on a modular and easily extendable structure, almost fully in Python. The framework facilitates the orchestration of several anonymization approaches in parallel and allows for interfacing between different techniques. Furthermore, we propose modifications to common evaluation methods which make the evaluation more powerful and reduces their computation time by 65 to 95\%, depending on the metric. Our code is fully open source.
Folding Attention: Memory and Power Optimization for On-Device Transformer-based Streaming Speech Recognition
Sep 14, 2023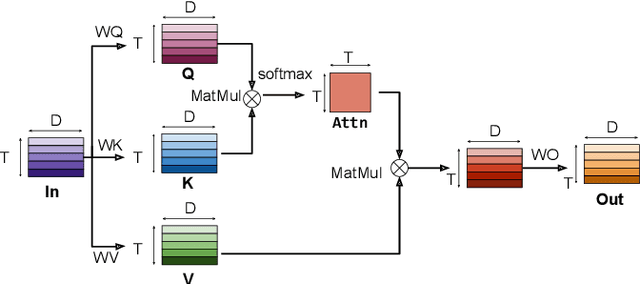
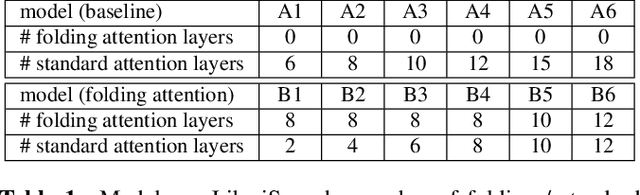
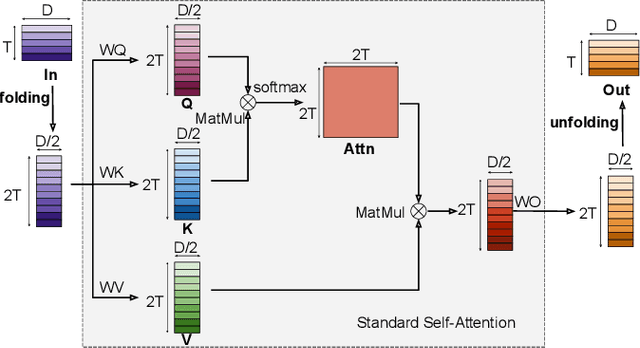
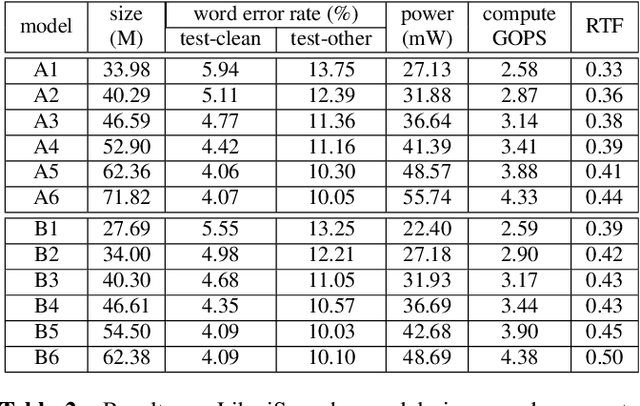
Transformer-based models excel in speech recognition. Existing efforts to optimize Transformer inference, typically for long-context applications, center on simplifying attention score calculations. However, streaming speech recognition models usually process a limited number of tokens each time, making attention score calculation less of a bottleneck. Instead, the bottleneck lies in the linear projection layers of multi-head attention and feedforward networks, constituting a substantial portion of the model size and contributing significantly to computation, memory, and power usage. To address this bottleneck, we propose folding attention, a technique targeting these linear layers, significantly reducing model size and improving memory and power efficiency. Experiments on on-device Transformer-based streaming speech recognition models show that folding attention reduces model size (and corresponding memory consumption) by up to 24% and power consumption by up to 23%, all without compromising model accuracy or computation overhead.