 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
BEA: Revisiting anchor-based object detection DNN using Budding Ensemble Architecture
Sep 19, 2023

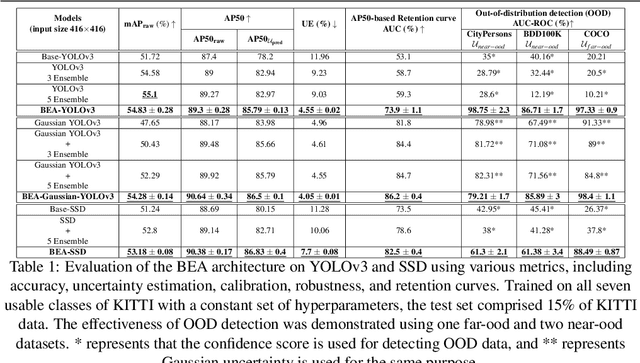
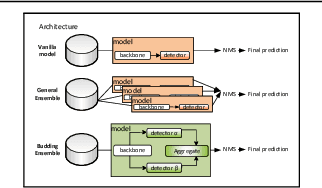
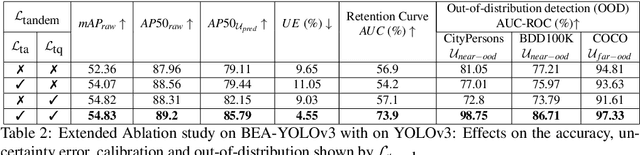
This paper introduces the Budding Ensemble Architecture (BEA), a novel reduced ensemble architecture for anchor-based object detection models. Object detection models are crucial in vision-based tasks, particularly in autonomous systems. They should provide precise bounding box detections while also calibrating their predicted confidence scores, leading to higher-quality uncertainty estimates. However, current models may make erroneous decisions due to false positives receiving high scores or true positives being discarded due to low scores. BEA aims to address these issues. The proposed loss functions in BEA improve the confidence score calibration and lower the uncertainty error, which results in a better distinction of true and false positives and, eventually, higher accuracy of the object detection models. Both Base-YOLOv3 and SSD models were enhanced using the BEA method and its proposed loss functions. The BEA on Base-YOLOv3 trained on the KITTI dataset results in a 6% and 3.7% increase in mAP and AP50, respectively. Utilizing a well-balanced uncertainty estimation threshold to discard samples in real-time even leads to a 9.6% higher AP50 than its base model. This is attributed to a 40% increase in the area under the AP50-based retention curve used to measure the quality of calibration of confidence scores. Furthermore, BEA-YOLOV3 trained on KITTI provides superior out-of-distribution detection on Citypersons, BDD100K, and COCO datasets compared to the ensembles and vanilla models of YOLOv3 and Gaussian-YOLOv3.
LineMarkNet: Line Landmark Detection for Valet Parking
Sep 19, 2023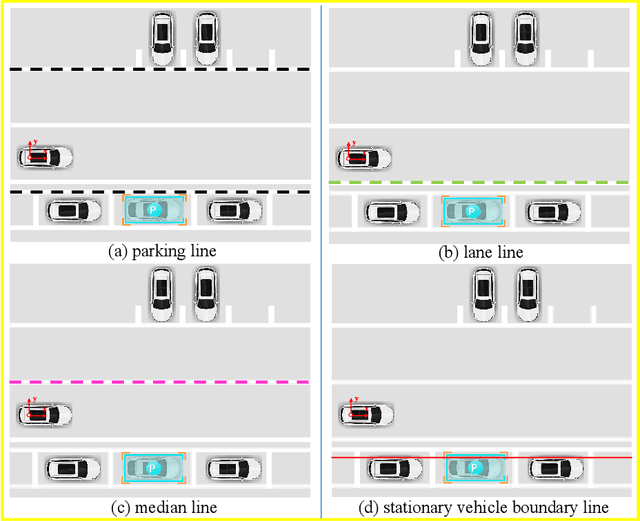
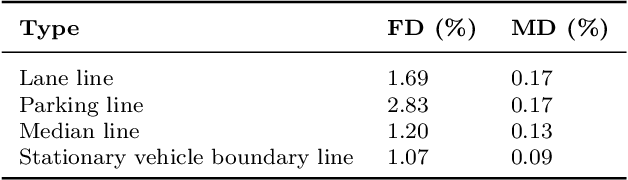
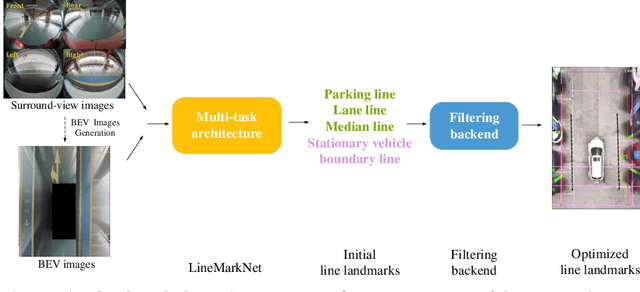

We aim for accurate and efficient line landmark detection for valet parking, which is a long-standing yet unsolved problem in autonomous driving. To this end, we present a deep line landmark detection system where we carefully design the modules to be lightweight. Specifically, we first empirically design four general line landmarks including three physical lines and one novel mental line. The four line landmarks are effective for valet parking. We then develop a deep network (LineMarkNet) to detect line landmarks from surround-view cameras where we, via the pre-calibrated homography, fuse context from four separate cameras into the unified bird-eye-view (BEV) space, specifically we fuse the surroundview features and BEV features, then employ the multi-task decoder to detect multiple line landmarks where we apply the center-based strategy for object detection task, and design our graph transformer to enhance the vision transformer with hierarchical level graph reasoning for semantic segmentation task. At last, we further parameterize the detected line landmarks (e.g., intercept-slope form) whereby a novel filtering backend incorporates temporal and multi-view consistency to achieve smooth and stable detection. Moreover, we annotate a large-scale dataset to validate our method. Experimental results show that our framework achieves the enhanced performance compared with several line detection methods and validate the multi-task network's efficiency about the real-time line landmark detection on the Qualcomm 820A platform while meantime keeps superior accuracy, with our deep line landmark detection system.
Assessing the capacity of a denoising diffusion probabilistic model to reproduce spatial context
Sep 19, 2023
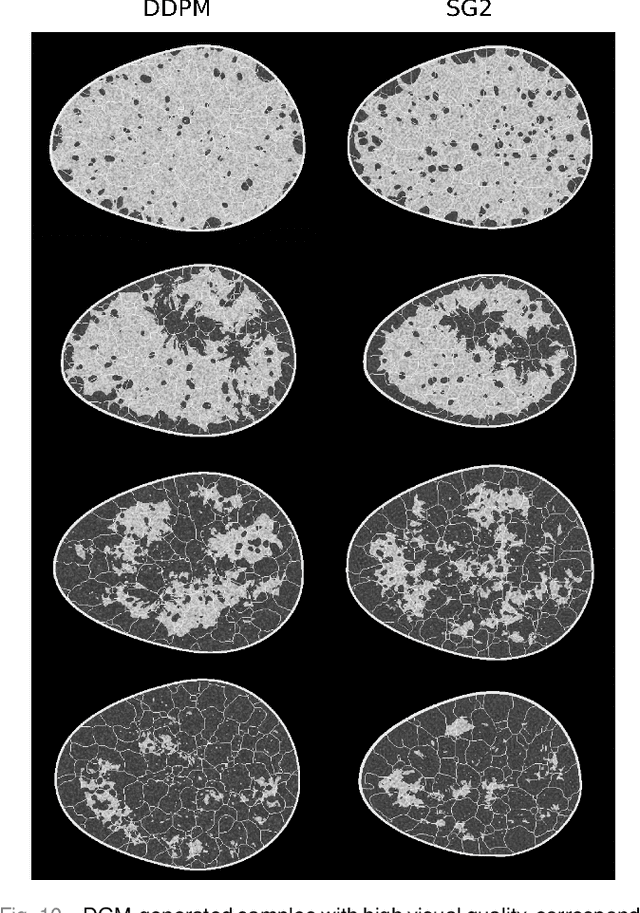
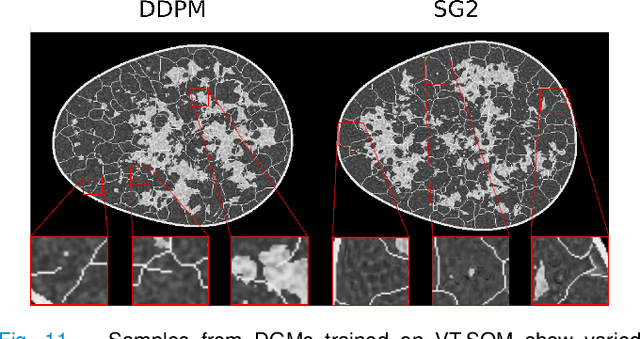

Diffusion models have emerged as a popular family of deep generative models (DGMs). In the literature, it has been claimed that one class of diffusion models -- denoising diffusion probabilistic models (DDPMs) -- demonstrate superior image synthesis performance as compared to generative adversarial networks (GANs). To date, these claims have been evaluated using either ensemble-based methods designed for natural images, or conventional measures of image quality such as structural similarity. However, there remains an important need to understand the extent to which DDPMs can reliably learn medical imaging domain-relevant information, which is referred to as `spatial context' in this work. To address this, a systematic assessment of the ability of DDPMs to learn spatial context relevant to medical imaging applications is reported for the first time. A key aspect of the studies is the use of stochastic context models (SCMs) to produce training data. In this way, the ability of the DDPMs to reliably reproduce spatial context can be quantitatively assessed by use of post-hoc image analyses. Error-rates in DDPM-generated ensembles are reported, and compared to those corresponding to a modern GAN. The studies reveal new and important insights regarding the capacity of DDPMs to learn spatial context. Notably, the results demonstrate that DDPMs hold significant capacity for generating contextually correct images that are `interpolated' between training samples, which may benefit data-augmentation tasks in ways that GANs cannot.
GPT4AIGChip: Towards Next-Generation AI Accelerator Design Automation via Large Language Models
Sep 19, 2023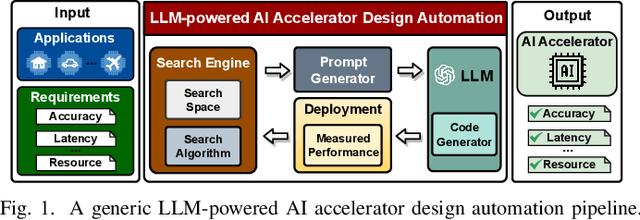
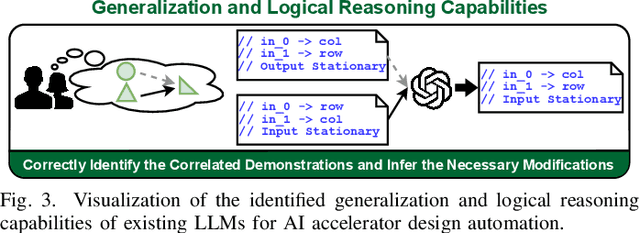
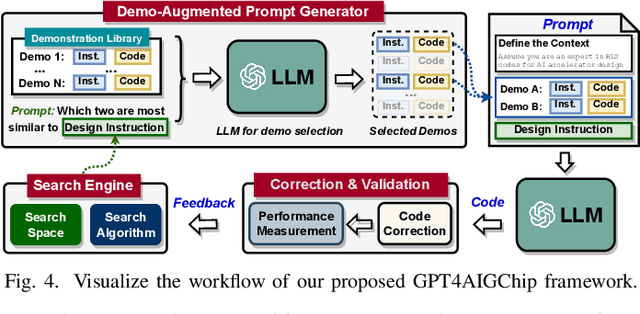
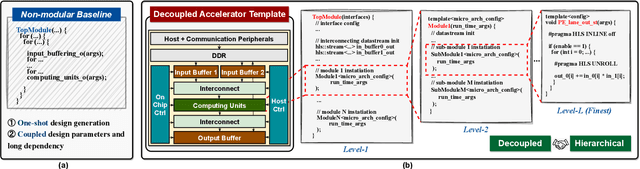
The remarkable capabilities and intricate nature of Artificial Intelligence (AI) have dramatically escalated the imperative for specialized AI accelerators. Nonetheless, designing these accelerators for various AI workloads remains both labor- and time-intensive. While existing design exploration and automation tools can partially alleviate the need for extensive human involvement, they still demand substantial hardware expertise, posing a barrier to non-experts and stifling AI accelerator development. Motivated by the astonishing potential of large language models (LLMs) for generating high-quality content in response to human language instructions, we embark on this work to examine the possibility of harnessing LLMs to automate AI accelerator design. Through this endeavor, we develop GPT4AIGChip, a framework intended to democratize AI accelerator design by leveraging human natural languages instead of domain-specific languages. Specifically, we first perform an in-depth investigation into LLMs' limitations and capabilities for AI accelerator design, thus aiding our understanding of our current position and garnering insights into LLM-powered automated AI accelerator design. Furthermore, drawing inspiration from the above insights, we develop a framework called GPT4AIGChip, which features an automated demo-augmented prompt-generation pipeline utilizing in-context learning to guide LLMs towards creating high-quality AI accelerator design. To our knowledge, this work is the first to demonstrate an effective pipeline for LLM-powered automated AI accelerator generation. Accordingly, we anticipate that our insights and framework can serve as a catalyst for innovations in next-generation LLM-powered design automation tools.
VPRTempo: A Fast Temporally Encoded Spiking Neural Network for Visual Place Recognition
Sep 19, 2023
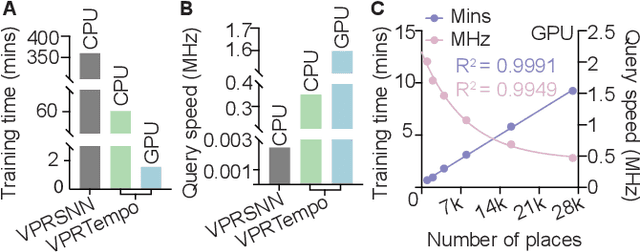
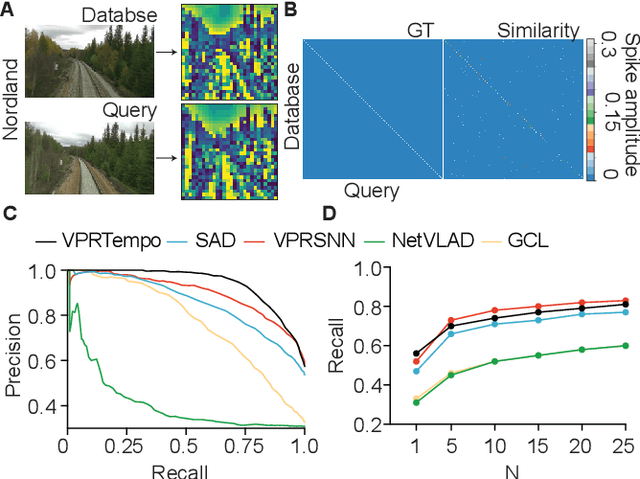
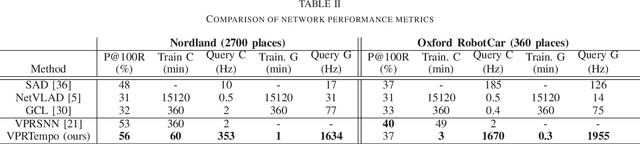
Spiking Neural Networks (SNNs) are at the forefront of neuromorphic computing thanks to their potential energy-efficiency, low latencies, and capacity for continual learning. While these capabilities are well suited for robotics tasks, SNNs have seen limited adaptation in this field thus far. This work introduces a SNN for Visual Place Recognition (VPR) that is both trainable within minutes and queryable in milliseconds, making it well suited for deployment on compute-constrained robotic systems. Our proposed system, VPRTempo, overcomes slow training and inference times using an abstracted SNN that trades biological realism for efficiency. VPRTempo employs a temporal code that determines the timing of a single spike based on a pixel's intensity, as opposed to prior SNNs relying on rate coding that determined the number of spikes; improving spike efficiency by over 100%. VPRTempo is trained using Spike-Timing Dependent Plasticity and a supervised delta learning rule enforcing that each output spiking neuron responds to just a single place. We evaluate our system on the Nordland and Oxford RobotCar benchmark localization datasets, which include up to 27k places. We found that VPRTempo's accuracy is comparable to prior SNNs and the popular NetVLAD place recognition algorithm, while being several orders of magnitude faster and suitable for real-time deployment -- with inference speeds over 50 Hz on CPU. VPRTempo could be integrated as a loop closure component for online SLAM on resource-constrained systems such as space and underwater robots.
Spiral Complete Coverage Path Planning Based on Conformal Slit Mapping in Multi-connected Domains
Sep 19, 2023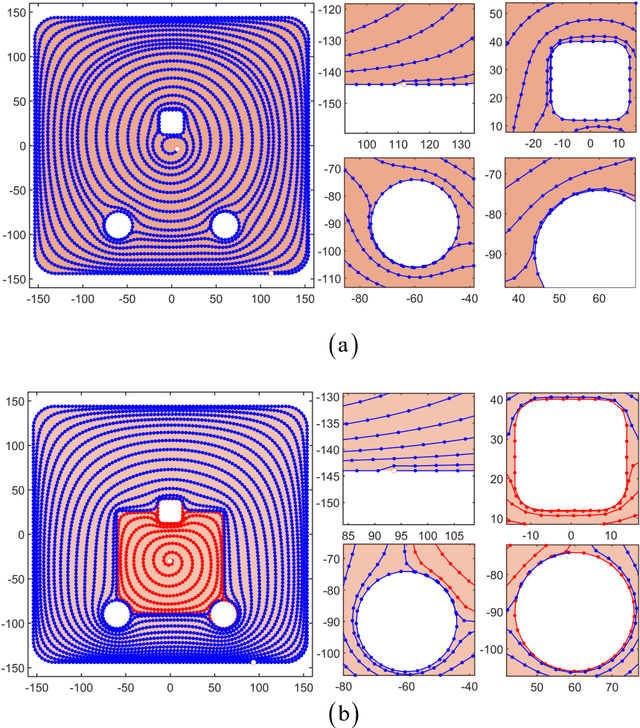
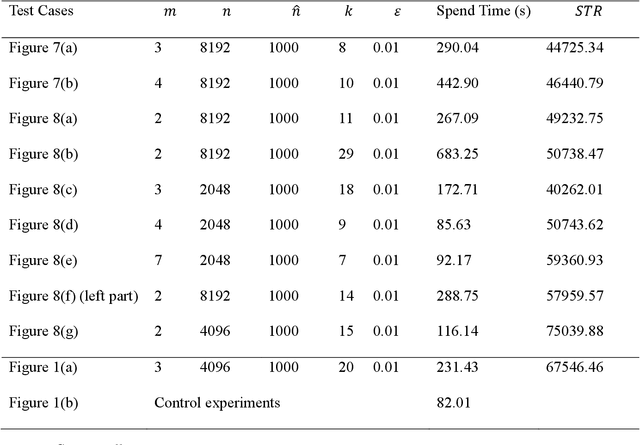
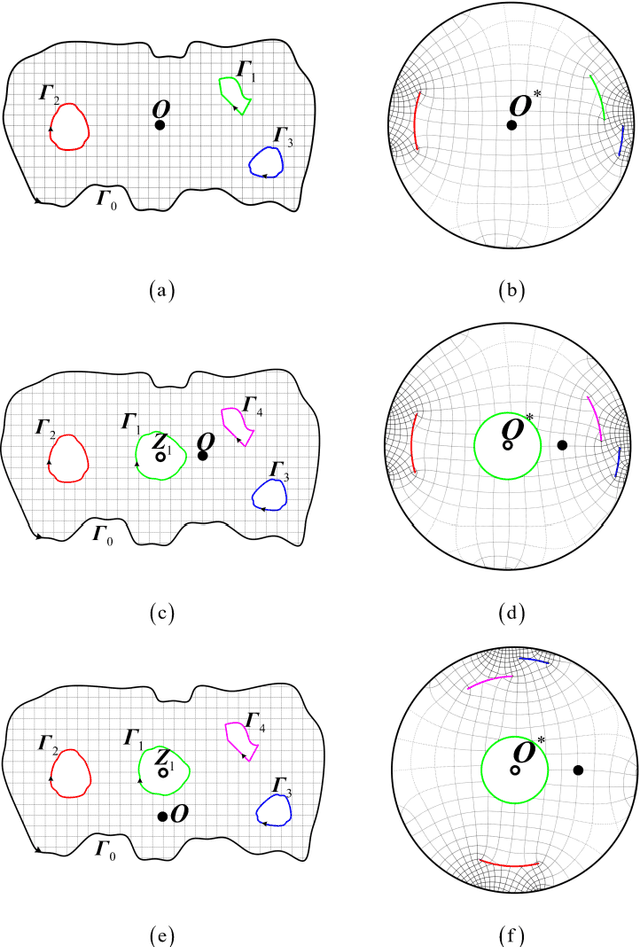
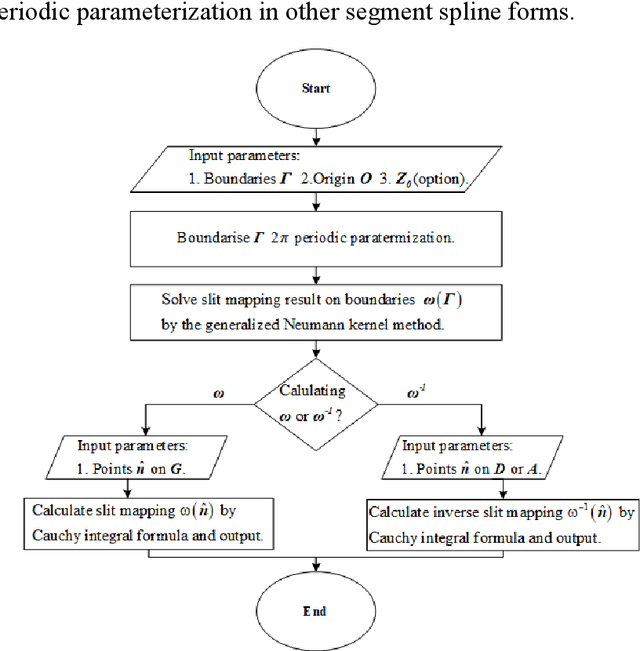
Generating a smooth and shorter spiral complete coverage path in a multi-connected domain is an important research area in robotic cavity machining. Traditional spiral path planning methods in multi-connected domains involve a subregion division procedure; a deformed spiral path is incorporated within each subregion, and these paths within the subregions are interconnected with bridges. In intricate domains with abundant voids and irregular boundaries, the added subregion boundaries increase the path avoidance requirements. This results in excessive bridging and necessitates longer uneven-density spirals to achieve complete subregion coverage. Considering that conformal slit mapping can transform multi-connected regions into regular disks or annuluses without subregion division, this paper presents a novel spiral complete coverage path planning method by conformal slit mapping. Firstly, a slit mapping calculation technique is proposed for segmented cubic spline boundaries with corners. Then, a spiral path spacing control method is developed based on the maximum inscribed circle radius between adjacent conformal slit mapping iso-parameters. Lastly, the spiral path is derived by offsetting iso-parameters. The complexity and applicability of the proposed method are comprehensively analyzed across various boundary scenarios. Meanwhile, two cavities milling experiments are conducted to compare the new method with conventional spiral complete coverage path methods. The comparation indicate that the new path meets the requirement for complete coverage in cavity machining while reducing path length and machining time by 12.70% and 12.34%, respectively.
GenDOM: Generalizable One-shot Deformable Object Manipulation with Parameter-Aware Policy
Sep 19, 2023
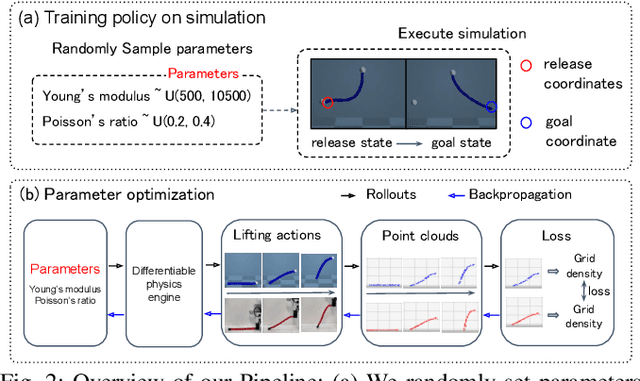


Due to the inherent uncertainty in their deformability during motion, previous methods in deformable object manipulation, such as rope and cloth, often required hundreds of real-world demonstrations to train a manipulation policy for each object, which hinders their applications in our ever-changing world. To address this issue, we introduce GenDOM, a framework that allows the manipulation policy to handle different deformable objects with only a single real-world demonstration. To achieve this, we augment the policy by conditioning it on deformable object parameters and training it with a diverse range of simulated deformable objects so that the policy can adjust actions based on different object parameters. At the time of inference, given a new object, GenDOM can estimate the deformable object parameters with only a single real-world demonstration by minimizing the disparity between the grid density of point clouds of real-world demonstrations and simulations in a differentiable physics simulator. Empirical validations on both simulated and real-world object manipulation setups clearly show that our method can manipulate different objects with a single demonstration and significantly outperforms the baseline in both environments (a 62% improvement for in-domain ropes and a 15% improvement for out-of-distribution ropes in simulation, as well as a 26% improvement for ropes and a 50% improvement for cloths in the real world), demonstrating the effectiveness of our approach in one-shot deformable object manipulation.
Deep projection networks for learning time-homogeneous dynamical systems
Jul 19, 2023We consider the general class of time-homogeneous dynamical systems, both discrete and continuous, and study the problem of learning a meaningful representation of the state from observed data. This is instrumental for the task of learning a forward transfer operator of the system, that in turn can be used for forecasting future states or observables. The representation, typically parametrized via a neural network, is associated with a projection operator and is learned by optimizing an objective function akin to that of canonical correlation analysis (CCA). However, unlike CCA, our objective avoids matrix inversions and therefore is generally more stable and applicable to challenging scenarios. Our objective is a tight relaxation of CCA and we further enhance it by proposing two regularization schemes, one encouraging the orthogonality of the components of the representation while the other exploiting Chapman-Kolmogorov's equation. We apply our method to challenging discrete dynamical systems, discussing improvements over previous methods, as well as to continuous dynamical systems.
Improving Adversarial Robustness of Masked Autoencoders via Test-time Frequency-domain Prompting
Aug 22, 2023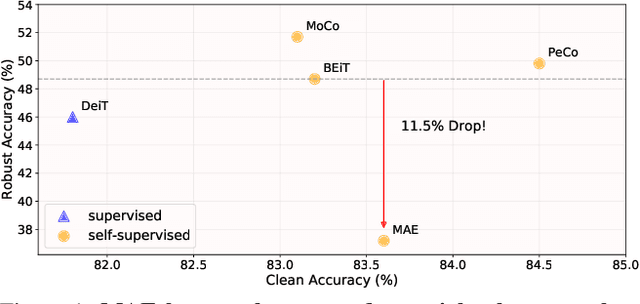
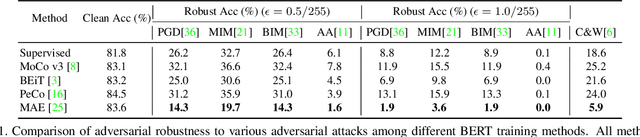
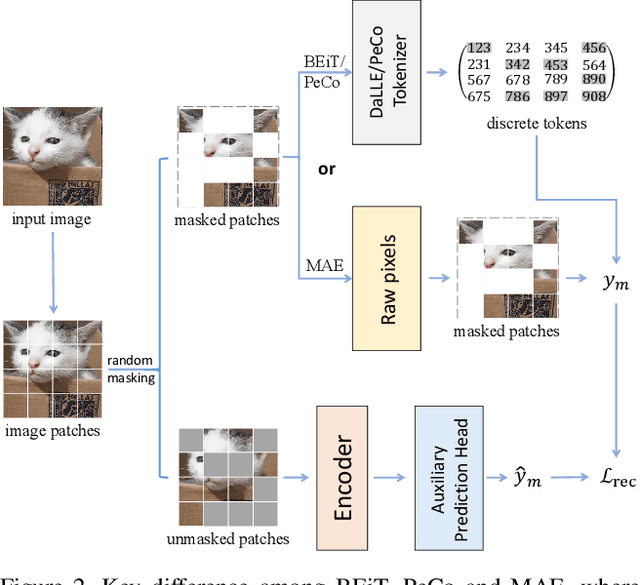

In this paper, we investigate the adversarial robustness of vision transformers that are equipped with BERT pretraining (e.g., BEiT, MAE). A surprising observation is that MAE has significantly worse adversarial robustness than other BERT pretraining methods. This observation drives us to rethink the basic differences between these BERT pretraining methods and how these differences affect the robustness against adversarial perturbations. Our empirical analysis reveals that the adversarial robustness of BERT pretraining is highly related to the reconstruction target, i.e., predicting the raw pixels of masked image patches will degrade more adversarial robustness of the model than predicting the semantic context, since it guides the model to concentrate more on medium-/high-frequency components of images. Based on our analysis, we provide a simple yet effective way to boost the adversarial robustness of MAE. The basic idea is using the dataset-extracted domain knowledge to occupy the medium-/high-frequency of images, thus narrowing the optimization space of adversarial perturbations. Specifically, we group the distribution of pretraining data and optimize a set of cluster-specific visual prompts on frequency domain. These prompts are incorporated with input images through prototype-based prompt selection during test period. Extensive evaluation shows that our method clearly boost MAE's adversarial robustness while maintaining its clean performance on ImageNet-1k classification. Our code is available at: https://github.com/shikiw/RobustMAE.
GenLayNeRF: Generalizable Layered Representations with 3D Model Alignment for Multi-Human View Synthesis
Sep 20, 2023Novel view synthesis (NVS) of multi-human scenes imposes challenges due to the complex inter-human occlusions. Layered representations handle the complexities by dividing the scene into multi-layered radiance fields, however, they are mainly constrained to per-scene optimization making them inefficient. Generalizable human view synthesis methods combine the pre-fitted 3D human meshes with image features to reach generalization, yet they are mainly designed to operate on single-human scenes. Another drawback is the reliance on multi-step optimization techniques for parametric pre-fitting of the 3D body models that suffer from misalignment with the images in sparse view settings causing hallucinations in synthesized views. In this work, we propose, GenLayNeRF, a generalizable layered scene representation for free-viewpoint rendering of multiple human subjects which requires no per-scene optimization and very sparse views as input. We divide the scene into multi-human layers anchored by the 3D body meshes. We then ensure pixel-level alignment of the body models with the input views through a novel end-to-end trainable module that carries out iterative parametric correction coupled with multi-view feature fusion to produce aligned 3D models. For NVS, we extract point-wise image-aligned and human-anchored features which are correlated and fused using self-attention and cross-attention modules. We augment low-level RGB values into the features with an attention-based RGB fusion module. To evaluate our approach, we construct two multi-human view synthesis datasets; DeepMultiSyn and ZJU-MultiHuman. The results indicate that our proposed approach outperforms generalizable and non-human per-scene NeRF methods while performing at par with layered per-scene methods without test time optimization.