 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Visible and NIR Image Fusion Algorithm Based on Information Complementarity
Sep 19, 2023

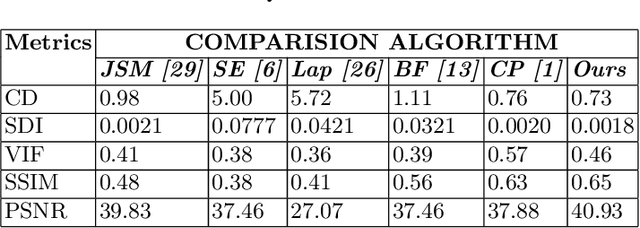
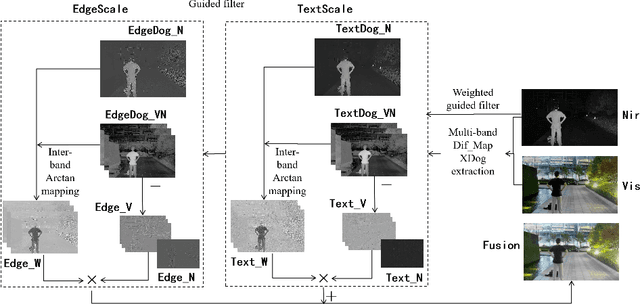

Visible and near-infrared(NIR) band sensors provide images that capture complementary spectral radiations from a scene. And the fusion of the visible and NIR image aims at utilizing their spectrum properties to enhance image quality. However, currently visible and NIR fusion algorithms cannot well take advantage of spectrum properties, as well as lack information complementarity, which results in color distortion and artifacts. Therefore, this paper designs a complementary fusion model from the level of physical signals. First, in order to distinguish between noise and useful information, we use two layers of the weight-guided filter and guided filter to obtain texture and edge layers, respectively. Second, to generate the initial visible-NIR complementarity weight map, the difference maps of visible and NIR are filtered by the extend-DoG filter. After that, the significant region of NIR night-time compensation guides the initial complementarity weight map by the arctanI function. Finally, the fusion images can be generated by the complementarity weight maps of visible and NIR images, respectively. The experimental results demonstrate that the proposed algorithm can not only well take advantage of the spectrum properties and the information complementarity, but also avoid color unnatural while maintaining naturalness, which outperforms the state-of-the-art.
Delay-Doppler Alignment Modulation for Spatially Sparse Massive MIMO Communication
Sep 02, 2023Delay alignment modulation (DAM) is an emerging technique for achieving inter-symbol interference (ISI)-free wideband communications using spatial-delay processing, without relying on channel equalization or multi-carrier transmission. However, existing works on DAM only consider multiple-input single-output (MISO) communication systems and assume time-invariant channels. In this paper, by extending DAM to time-variant frequency-selective multiple-input multiple-output (MIMO) channels, we propose a novel technique termed \emph{delay-Doppler alignment modulation} (DDAM). Specifically, by leveraging \emph{delay-Doppler compensation} and \emph{path-based beamforming}, the Doppler effect of each multi-path can be eliminated and all multi-path signal components may reach the receiver concurrently and constructively. We first show that by applying path-based zero-forcing (ZF) precoding and receive combining, DDAM can transform the original time-variant frequency-selective channels into time-invariant ISI-free channels. The necessary and/or sufficient conditions to achieve such a transformation are derived. Then an asymptotic analysis is provided by showing that when the number of base station (BS) antennas is much larger than that of channel paths, DDAM enables time-invariant ISI-free channels with the simple delay-Doppler compensation and path-based maximal-ratio transmission (MRT) beamforming. Furthermore, for the general DDAM design with some tolerable ISI, the path-based transmit precoding and receive combining matrices are optimized to maximize the spectral efficiency. Numerical results are provided to compare the proposed DDAM technique with various benchmarking schemes, including MIMO-orthogonal time frequency space (OTFS), MIMO-orthogonal frequency-division multiplexing (OFDM) without or with carrier frequency offset (CFO) compensation, and beam alignment along the dominant path.
Deep Multi-Agent Reinforcement Learning for Decentralized Active Hypothesis Testing
Sep 14, 2023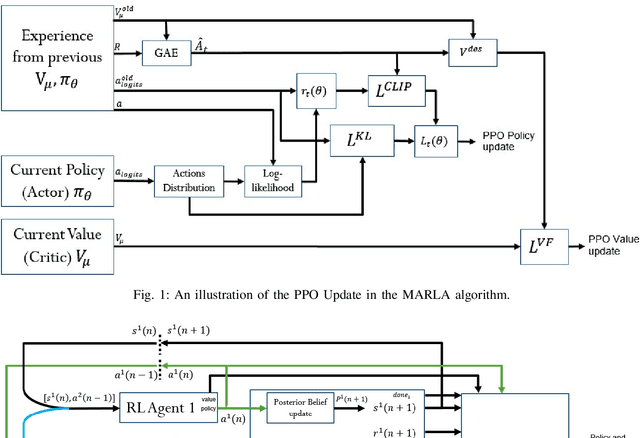
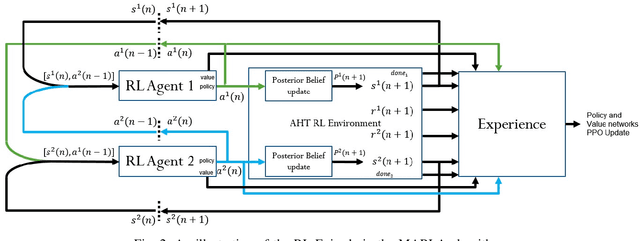

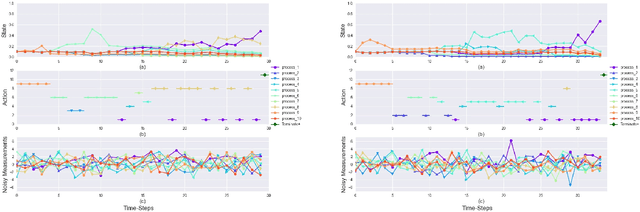
We consider a decentralized formulation of the active hypothesis testing (AHT) problem, where multiple agents gather noisy observations from the environment with the purpose of identifying the correct hypothesis. At each time step, agents have the option to select a sampling action. These different actions result in observations drawn from various distributions, each associated with a specific hypothesis. The agents collaborate to accomplish the task, where message exchanges between agents are allowed over a rate-limited communications channel. The objective is to devise a multi-agent policy that minimizes the Bayes risk. This risk comprises both the cost of sampling and the joint terminal cost incurred by the agents upon making a hypothesis declaration. Deriving optimal structured policies for AHT problems is generally mathematically intractable, even in the context of a single agent. As a result, recent efforts have turned to deep learning methodologies to address these problems, which have exhibited significant success in single-agent learning scenarios. In this paper, we tackle the multi-agent AHT formulation by introducing a novel algorithm rooted in the framework of deep multi-agent reinforcement learning. This algorithm, named Multi-Agent Reinforcement Learning for AHT (MARLA), operates at each time step by having each agent map its state to an action (sampling rule or stopping rule) using a trained deep neural network with the goal of minimizing the Bayes risk. We present a comprehensive set of experimental results that effectively showcase the agents' ability to learn collaborative strategies and enhance performance using MARLA. Furthermore, we demonstrate the superiority of MARLA over single-agent learning approaches. Finally, we provide an open-source implementation of the MARLA framework, for the benefit of researchers and developers in related domains.
Neurosymbolic Meta-Reinforcement Lookahead Learning Achieves Safe Self-Driving in Non-Stationary Environments
Sep 05, 2023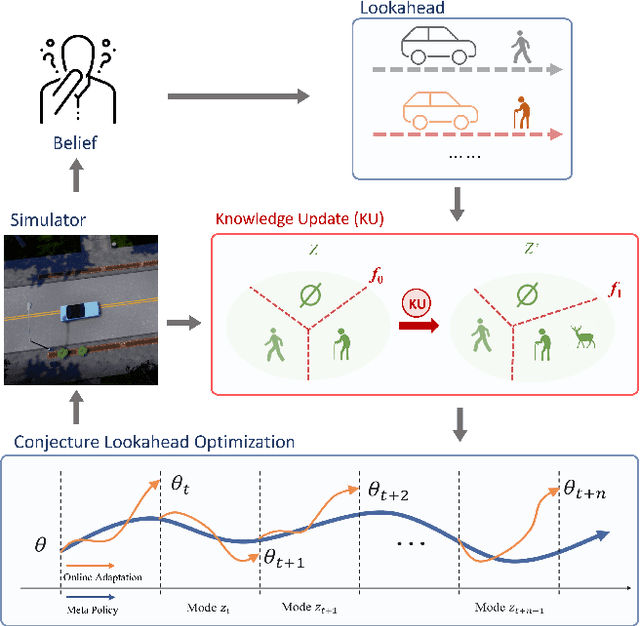
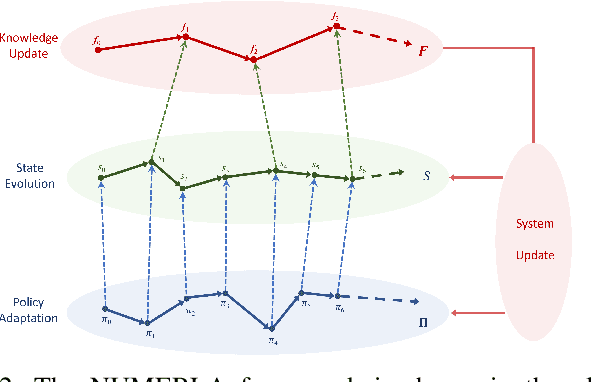
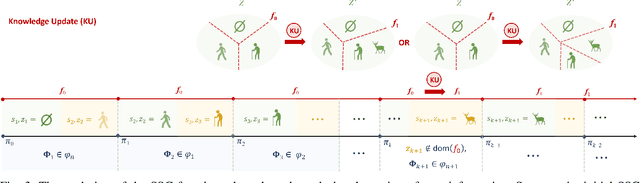
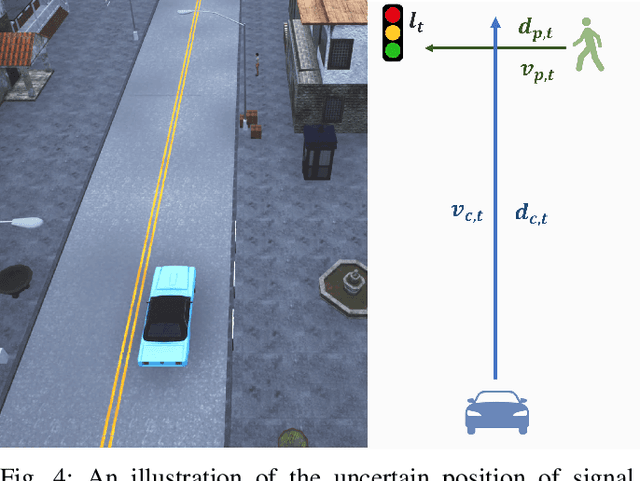
In the area of learning-driven artificial intelligence advancement, the integration of machine learning (ML) into self-driving (SD) technology stands as an impressive engineering feat. Yet, in real-world applications outside the confines of controlled laboratory scenarios, the deployment of self-driving technology assumes a life-critical role, necessitating heightened attention from researchers towards both safety and efficiency. To illustrate, when a self-driving model encounters an unfamiliar environment in real-time execution, the focus must not solely revolve around enhancing its anticipated performance; equal consideration must be given to ensuring its execution or real-time adaptation maintains a requisite level of safety. This study introduces an algorithm for online meta-reinforcement learning, employing lookahead symbolic constraints based on \emph{Neurosymbolic Meta-Reinforcement Lookahead Learning} (NUMERLA). NUMERLA proposes a lookahead updating mechanism that harmonizes the efficiency of online adaptations with the overarching goal of ensuring long-term safety. Experimental results demonstrate NUMERLA confers the self-driving agent with the capacity for real-time adaptability, leading to safe and self-adaptive driving under non-stationary urban human-vehicle interaction scenarios.
Efficient Face Detection with Audio-Based Region Proposals
Sep 14, 2023Robot vision often involves a large computational load due to large images to process in a short amount of time. Existing solutions often involve reducing image quality which can negatively impact processing. Another approach is to generate regions of interest with expensive vision algorithms. In this paper, we evaluate how audio can be used to generate regions of interest in optical images. To achieve this, we propose a unique attention mechanism to localize speech sources and evaluate its impact on a face detection algorithm. Our results show that the attention mechanism reduces the computational load. The proposed pipeline is flexible and can be easily adapted for human-robot interactions, robot surveillance, video-conferences or smart glasses.
A Machine Vision Method for Correction of Eccentric Error: Based on Adaptive Enhancement Algorithm
Sep 01, 2023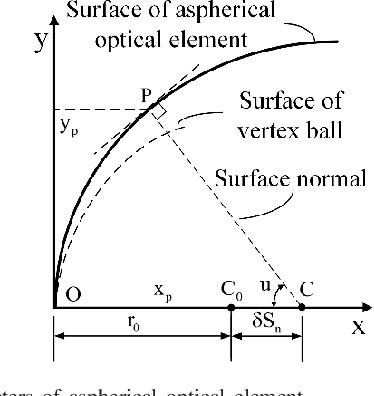

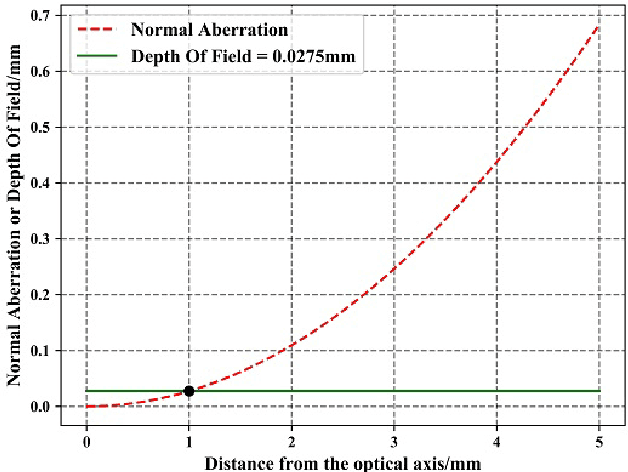

In the procedure of surface defects detection for large-aperture aspherical optical elements, it is of vital significance to adjust the optical axis of the element to be coaxial with the mechanical spin axis accurately. Therefore, a machine vision method for eccentric error correction is proposed in this paper. Focusing on the severe defocus blur of reference crosshair image caused by the imaging characteristic of the aspherical optical element, which may lead to the failure of correction, an Adaptive Enhancement Algorithm (AEA) is proposed to strengthen the crosshair image. AEA is consisted of existed Guided Filter Dark Channel Dehazing Algorithm (GFA) and proposed lightweight Multi-scale Densely Connected Network (MDC-Net). The enhancement effect of GFA is excellent but time-consuming, and the enhancement effect of MDC-Net is slightly inferior but strongly real-time. As AEA will be executed dozens of times during each correction procedure, its real-time performance is very important. Therefore, by setting the empirical threshold of definition evaluation function SMD2, GFA and MDC-Net are respectively applied to highly and slightly blurred crosshair images so as to ensure the enhancement effect while saving as much time as possible. AEA has certain robustness in time-consuming performance, which takes an average time of 0.2721s and 0.0963s to execute GFA and MDC-Net separately on ten 200pixels 200pixels Region of Interest (ROI) images with different degrees of blur. And the eccentricity error can be reduced to within 10um by our method.
Outlier Robust Adversarial Training
Sep 10, 2023
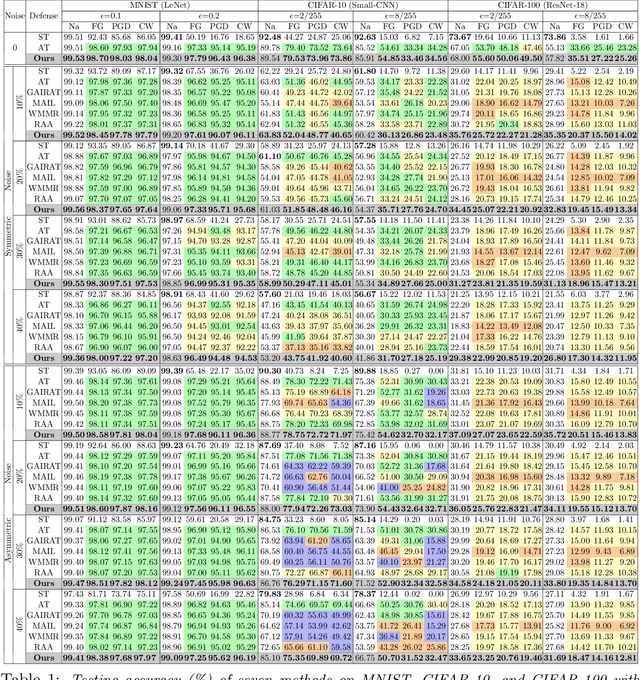
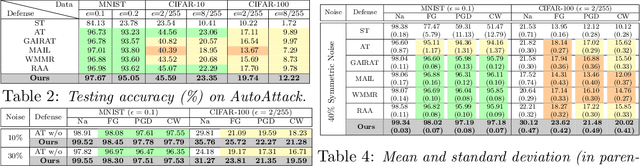
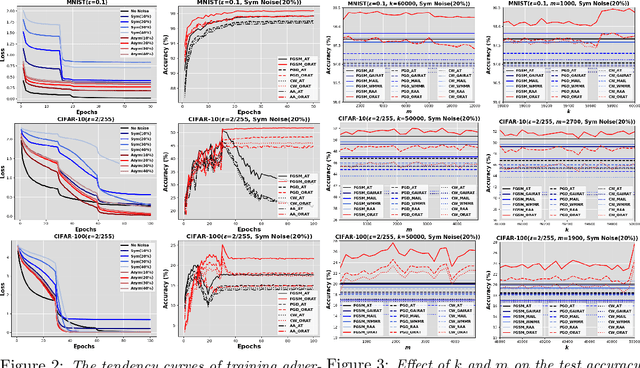
Supervised learning models are challenged by the intrinsic complexities of training data such as outliers and minority subpopulations and intentional attacks at inference time with adversarial samples. While traditional robust learning methods and the recent adversarial training approaches are designed to handle each of the two challenges, to date, no work has been done to develop models that are robust with regard to the low-quality training data and the potential adversarial attack at inference time simultaneously. It is for this reason that we introduce Outlier Robust Adversarial Training (ORAT) in this work. ORAT is based on a bi-level optimization formulation of adversarial training with a robust rank-based loss function. Theoretically, we show that the learning objective of ORAT satisfies the $\mathcal{H}$-consistency in binary classification, which establishes it as a proper surrogate to adversarial 0/1 loss. Furthermore, we analyze its generalization ability and provide uniform convergence rates in high probability. ORAT can be optimized with a simple algorithm. Experimental evaluations on three benchmark datasets demonstrate the effectiveness and robustness of ORAT in handling outliers and adversarial attacks. Our code is available at https://github.com/discovershu/ORAT.
Automated Real Time Delineation of Supraclavicular Brachial Plexus in Neck Ultrasonography Videos: A Deep Learning Approach
Aug 07, 2023Peripheral nerve blocks are crucial to treatment of post-surgical pain and are associated with reduction in perioperative opioid use and hospital stay. Accurate interpretation of sono-anatomy is critical for the success of ultrasound (US) guided peripheral nerve blocks and can be challenging to the new operators. This prospective study enrolled 227 subjects who were systematically scanned for supraclavicular and interscalene brachial plexus in various settings using three different US machines to create a dataset of 227 unique videos. In total, 41,000 video frames were annotated by experienced anaesthesiologists using partial automation with object tracking and active contour algorithms. Four baseline neural network models were trained on the dataset and their performance was evaluated for object detection and segmentation tasks. Generalizability of the best suited model was then tested on the datasets constructed from separate US scanners with and without fine-tuning. The results demonstrate that deep learning models can be leveraged for real time segmentation of supraclavicular brachial plexus in neck ultrasonography videos with high accuracy and reliability. Model was also tested for its ability to differentiate between supraclavicular and adjoining interscalene brachial plexus. The entire dataset has been released publicly for further study by the research community.
Towards Self-Adaptive Pseudo-Label Filtering for Semi-Supervised Learning
Sep 18, 2023Recent semi-supervised learning (SSL) methods typically include a filtering strategy to improve the quality of pseudo labels. However, these filtering strategies are usually hand-crafted and do not change as the model is updated, resulting in a lot of correct pseudo labels being discarded and incorrect pseudo labels being selected during the training process. In this work, we observe that the distribution gap between the confidence values of correct and incorrect pseudo labels emerges at the very beginning of the training, which can be utilized to filter pseudo labels. Based on this observation, we propose a Self-Adaptive Pseudo-Label Filter (SPF), which automatically filters noise in pseudo labels in accordance with model evolvement by modeling the confidence distribution throughout the training process. Specifically, with an online mixture model, we weight each pseudo-labeled sample by the posterior of it being correct, which takes into consideration the confidence distribution at that time. Unlike previous handcrafted filters, our SPF evolves together with the deep neural network without manual tuning. Extensive experiments demonstrate that incorporating SPF into the existing SSL methods can help improve the performance of SSL, especially when the labeled data is extremely scarce.
FedLALR: Client-Specific Adaptive Learning Rates Achieve Linear Speedup for Non-IID Data
Sep 18, 2023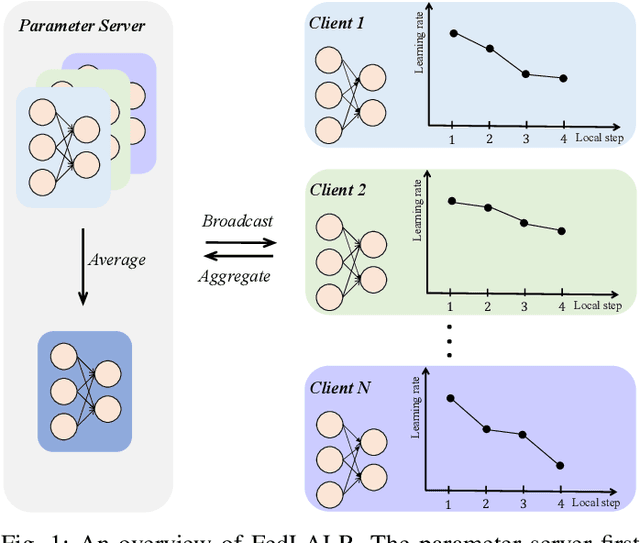
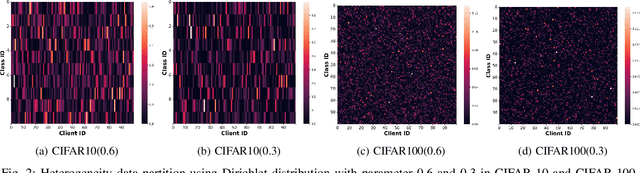
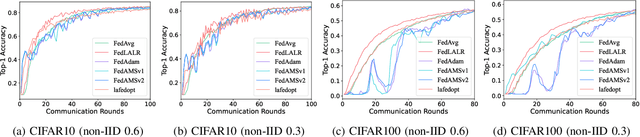
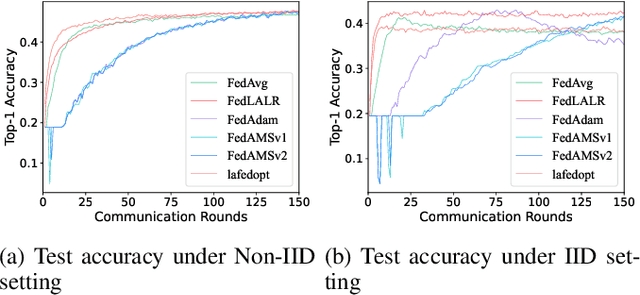
Federated learning is an emerging distributed machine learning method, enables a large number of clients to train a model without exchanging their local data. The time cost of communication is an essential bottleneck in federated learning, especially for training large-scale deep neural networks. Some communication-efficient federated learning methods, such as FedAvg and FedAdam, share the same learning rate across different clients. But they are not efficient when data is heterogeneous. To maximize the performance of optimization methods, the main challenge is how to adjust the learning rate without hurting the convergence. In this paper, we propose a heterogeneous local variant of AMSGrad, named FedLALR, in which each client adjusts its learning rate based on local historical gradient squares and synchronized learning rates. Theoretical analysis shows that our client-specified auto-tuned learning rate scheduling can converge and achieve linear speedup with respect to the number of clients, which enables promising scalability in federated optimization. We also empirically compare our method with several communication-efficient federated optimization methods. Extensive experimental results on Computer Vision (CV) tasks and Natural Language Processing (NLP) task show the efficacy of our proposed FedLALR method and also coincides with our theoretical findings.