 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
After-Fatigue Condition: A Novel Analysis Based on Surface EMG Signals
Sep 09, 2023
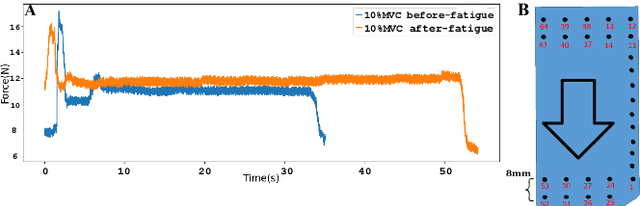
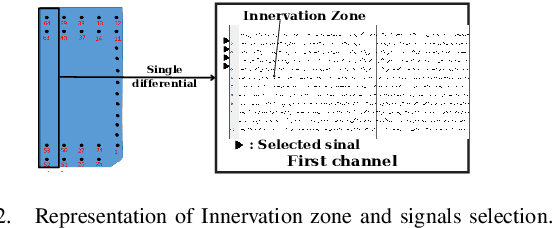
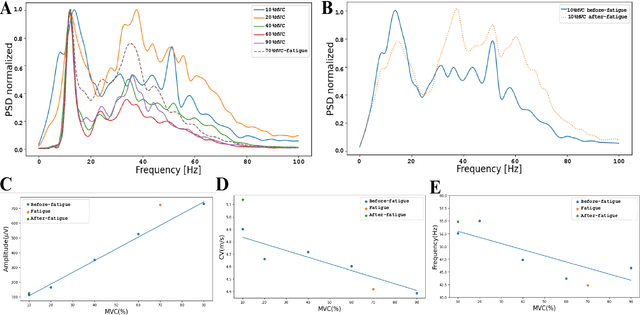
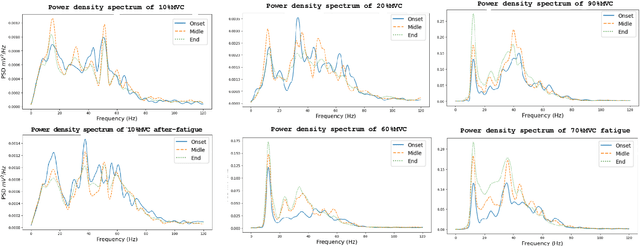
This study introduces a novel muscle activation analysis based on surface electromyography (sEMG) signals to assess the muscle's after-fatigue condition. Previous studies have mainly focused on the before-fatigue and fatigue conditions. However, a comprehensive analysis of the after-fatigue condition has been overlooked. The proposed method analyzes muscle fatigue indicators at various maximal voluntary contraction (MVC) levels to compare the before-fatigue, fatigue, and after-fatigue conditions using amplitude-based, spectral-based, and muscle fiber conduction velocity (CV) parameters. In addition, the contraction time of each MVC level is also analyzed with the same indicators. The results show that in the after-fatigue condition, the muscle activation changes significantly in the ways such as higher CV, power spectral density shifting to the right, and longer contraction time until exhaustion compared to the before-fatigue and fatigue conditions. The results can provide a comprehensive and objective evaluation of muscle fatigue and recovery, which can be helpful in clinical diagnosis, rehabilitation, and sports performance.
Combining deep learning and street view imagery to map smallholder crop types
Sep 12, 2023Accurate crop type maps are an essential source of information for monitoring yield progress at scale, projecting global crop production, and planning effective policies. To date, however, crop type maps remain challenging to create in low and middle-income countries due to a lack of ground truth labels for training machine learning models. Field surveys are the gold standard in terms of accuracy but require an often-prohibitively large amount of time, money, and statistical capacity. In recent years, street-level imagery, such as Google Street View, KartaView, and Mapillary, has become available around the world. Such imagery contains rich information about crop types grown at particular locations and times. In this work, we develop an automated system to generate crop type ground references using deep learning and Google Street View imagery. The method efficiently curates a set of street view images containing crop fields, trains a model to predict crop type by utilizing weakly-labelled images from disparate out-of-domain sources, and combines predicted labels with remote sensing time series to create a wall-to-wall crop type map. We show that, in Thailand, the resulting country-wide map of rice, cassava, maize, and sugarcane achieves an accuracy of 93%. As the availability of roadside imagery expands, our pipeline provides a way to map crop types at scale around the globe, especially in underserved smallholder regions.
Update Monte Carlo tree search (UMCTS) algorithm for heuristic global search of sizing optimization problems for truss structures
Sep 12, 2023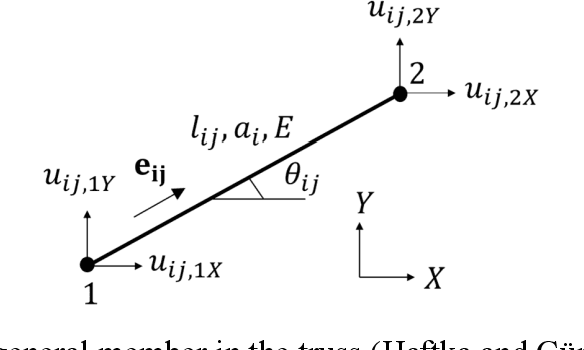


Sizing optimization of truss structures is a complex computational problem, and the reinforcement learning (RL) is suitable for dealing with multimodal problems without gradient computations. In this paper, a new efficient optimization algorithm called update Monte Carlo tree search (UMCTS) is developed to obtain the appropriate design for truss structures. UMCTS is an RL-based method that combines the novel update process and Monte Carlo tree search (MCTS) with the upper confidence bound (UCB). Update process means that in each round, the optimal cross-sectional area of each member is determined by search tree, and its initial state is the final state in the previous round. In the UMCTS algorithm, an accelerator for the number of selections for member area and iteration number is introduced to reduce the computation time. Moreover, for each state, the average reward is replaced by the best reward collected on the simulation process to determine the optimal solution. The proposed optimization method is examined on some benchmark problems of planar and spatial trusses with discrete sizing variables to demonstrate the efficiency and validity. It is shown that the computation time for the proposed approach is at least ten times faster than the branch and bound (BB) method. The numerical results indicate that the proposed method stably achieves better solution than other conventional methods.
Frequency-Aware Masked Autoencoders for Multimodal Pretraining on Biosignals
Sep 12, 2023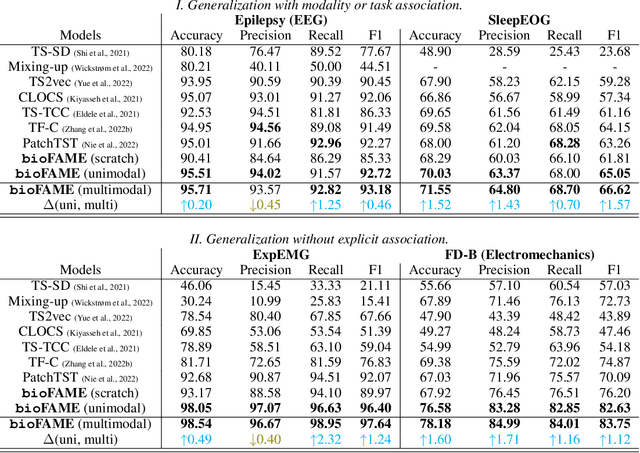
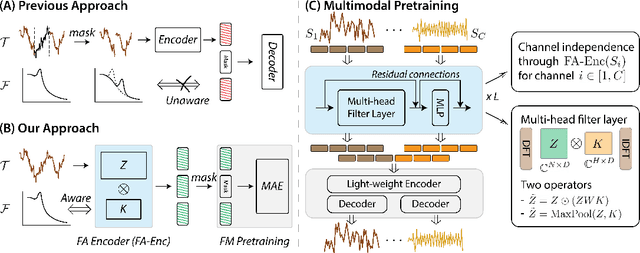
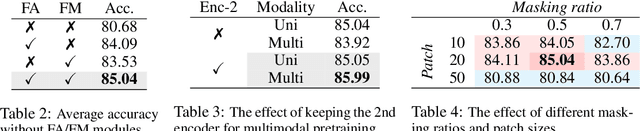
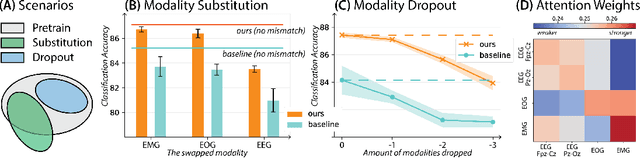
Leveraging multimodal information from biosignals is vital for building a comprehensive representation of people's physical and mental states. However, multimodal biosignals often exhibit substantial distributional shifts between pretraining and inference datasets, stemming from changes in task specification or variations in modality compositions. To achieve effective pretraining in the presence of potential distributional shifts, we propose a frequency-aware masked autoencoder ($\texttt{bio}$FAME) that learns to parameterize the representation of biosignals in the frequency space. $\texttt{bio}$FAME incorporates a frequency-aware transformer, which leverages a fixed-size Fourier-based operator for global token mixing, independent of the length and sampling rate of inputs. To maintain the frequency components within each input channel, we further employ a frequency-maintain pretraining strategy that performs masked autoencoding in the latent space. The resulting architecture effectively utilizes multimodal information during pretraining, and can be seamlessly adapted to diverse tasks and modalities at test time, regardless of input size and order. We evaluated our approach on a diverse set of transfer experiments on unimodal time series, achieving an average of $\uparrow$5.5% improvement in classification accuracy over the previous state-of-the-art. Furthermore, we demonstrated that our architecture is robust in modality mismatch scenarios, including unpredicted modality dropout or substitution, proving its practical utility in real-world applications. Code will be available soon.
SALC: Skeleton-Assisted Learning-Based Clustering for Time-Varying Indoor Localization
Jul 14, 2023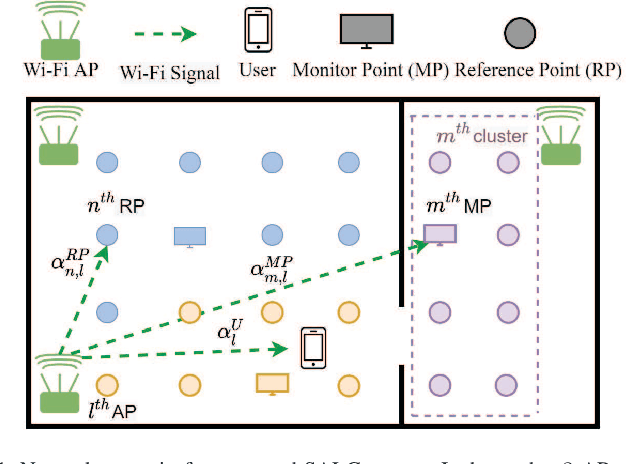
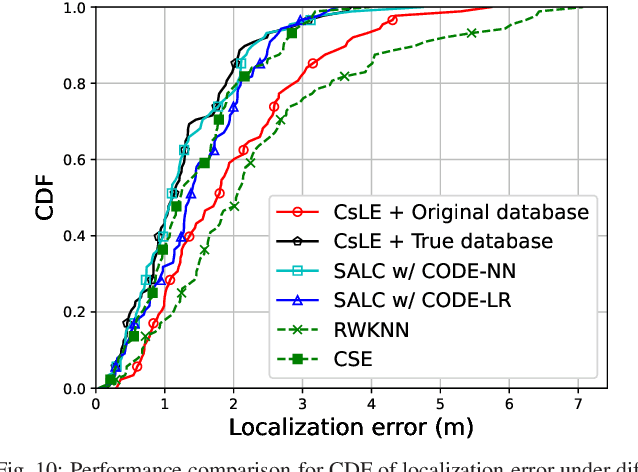

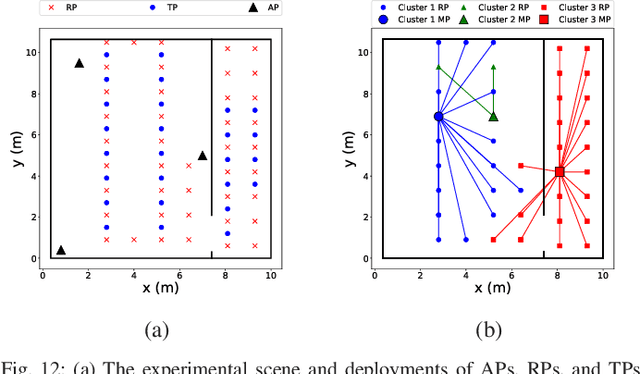
Wireless indoor localization has attracted significant amount of attention in recent years. Using received signal strength (RSS) obtained from WiFi access points (APs) for establishing fingerprinting database is a widely utilized method in indoor localization. However, the time-variant problem for indoor positioning systems is not well-investigated in existing literature. Compared to conventional static fingerprinting, the dynamicallyreconstructed database can adapt to a highly-changing environment, which achieves sustainability of localization accuracy. To deal with the time-varying issue, we propose a skeleton-assisted learning-based clustering localization (SALC) system, including RSS-oriented map-assisted clustering (ROMAC), cluster-based online database establishment (CODE), and cluster-scaled location estimation (CsLE). The SALC scheme jointly considers similarities from the skeleton-based shortest path (SSP) and the time-varying RSS measurements across the reference points (RPs). ROMAC clusters RPs into different feature sets and therefore selects suitable monitor points (MPs) for enhancing location estimation. Moreover, the CODE algorithm aims for establishing adaptive fingerprint database to alleviate the timevarying problem. Finally, CsLE is adopted to acquire the target position by leveraging the benefits of clustering information and estimated signal variations in order to rescale the weights fromweighted k-nearest neighbors (WkNN) method. Both simulation and experimental results demonstrate that the proposed SALC system can effectively reconstruct the fingerprint database with an enhanced location estimation accuracy, which outperforms the other existing schemes in the open literature.
Generative Algorithms for Fusion of Physics-Based Wildfire Spread Models with Satellite Data for Initializing Wildfire Forecasts
Sep 05, 2023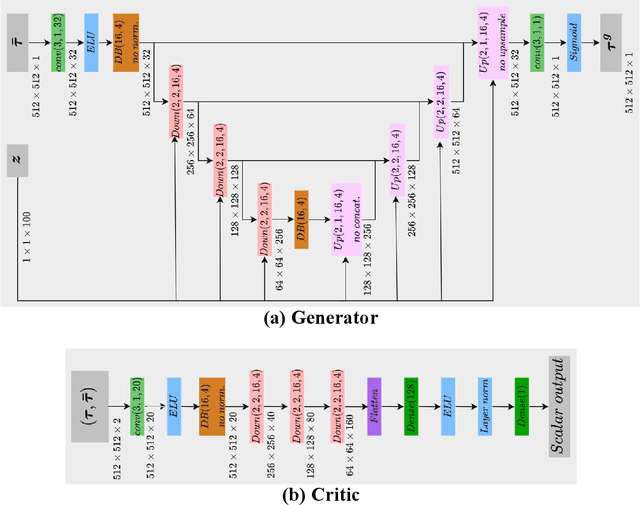

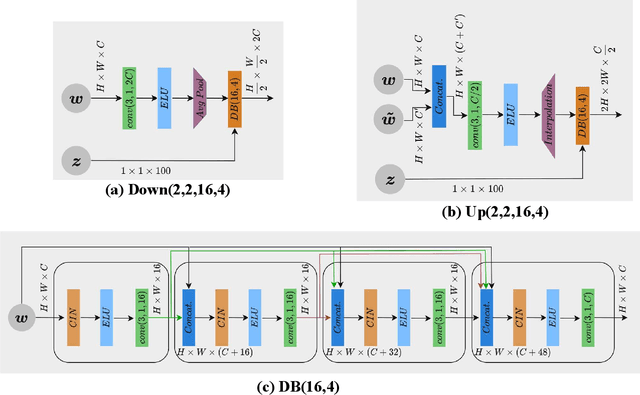
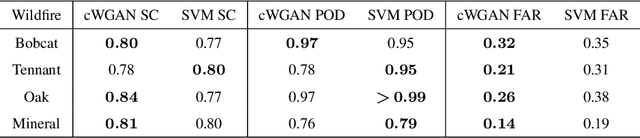
Increases in wildfire activity and the resulting impacts have prompted the development of high-resolution wildfire behavior models for forecasting fire spread. Recent progress in using satellites to detect fire locations further provides the opportunity to use measurements to improve fire spread forecasts from numerical models through data assimilation. This work develops a method for inferring the history of a wildfire from satellite measurements, providing the necessary information to initialize coupled atmosphere-wildfire models from a measured wildfire state in a physics-informed approach. The fire arrival time, which is the time the fire reaches a given spatial location, acts as a succinct representation of the history of a wildfire. In this work, a conditional Wasserstein Generative Adversarial Network (cWGAN), trained with WRF-SFIRE simulations, is used to infer the fire arrival time from satellite active fire data. The cWGAN is used to produce samples of likely fire arrival times from the conditional distribution of arrival times given satellite active fire detections. Samples produced by the cWGAN are further used to assess the uncertainty of predictions. The cWGAN is tested on four California wildfires occurring between 2020 and 2022, and predictions for fire extent are compared against high resolution airborne infrared measurements. Further, the predicted ignition times are compared with reported ignition times. An average Sorensen's coefficient of 0.81 for the fire perimeters and an average ignition time error of 32 minutes suggest that the method is highly accurate.
Multivariate Time Series Classification: A Deep Learning Approach
Jul 05, 2023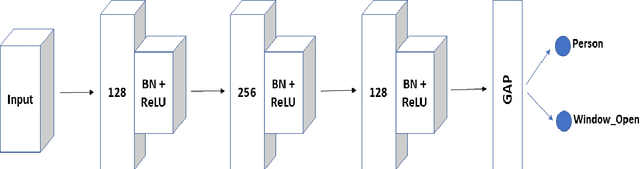
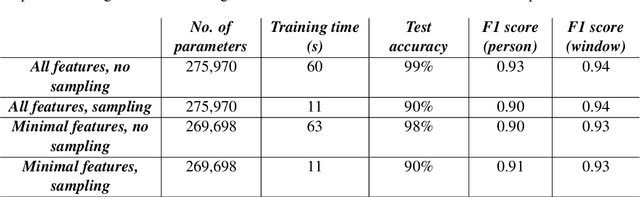
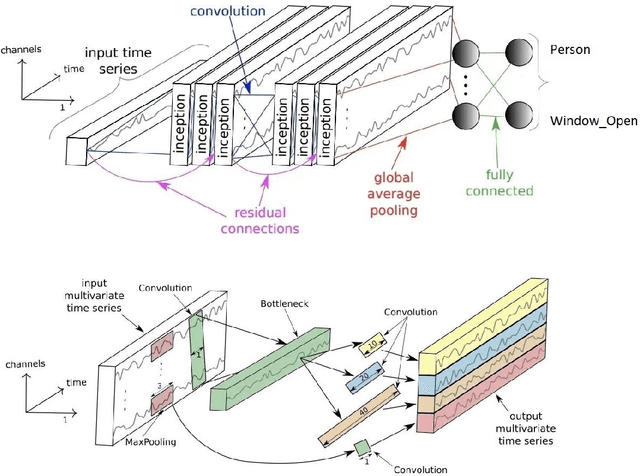

This paper investigates different methods and various neural network architectures applicable in the time series classification domain. The data is obtained from a fleet of gas sensors that measure and track quantities such as oxygen and sound. With the help of this data, we can detect events such as occupancy in a specific environment. At first, we analyze the time series data to understand the effect of different parameters, such as the sequence length, when training our models. These models employ Fully Convolutional Networks (FCN) and Long Short-Term Memory (LSTM) for supervised learning and Recurrent Autoencoders for semisupervised learning. Throughout this study, we spot the differences between these methods based on metrics such as precision and recall identifying which technique best suits this problem.
Secure Degree of Freedom of Wireless Networks Using Collaborative Pilots
Sep 21, 2023A wireless network of full-duplex nodes/users, using anti-eavesdropping channel estimation (ANECE) based on collaborative pilots, can yield a positive secure degree-of-freedom (SDoF) regardless of the number of antennas an eavesdropper may have. This paper presents novel results on SDoF of ANECE by analyzing secret-key capacity (SKC) of each pair of nodes in a network of multiple collaborative nodes per channel coherence period. Each transmission session of ANECE has two phases: phase 1 is used for pilots, and phase 2 is used for random symbols. This results in two parts of SDoF of ANECE. Both lower and upper bounds on the SDoF of ANECE for any number of users are shown, and the conditions for the two bounds to meet are given. This leads to important discoveries, including: a) The phase-1 SDoF is the same for both multi-user ANECE and pair-wise ANECE while the former may require only a fraction of the number of time slots needed by the latter; b) For a three-user network, the phase-2 SDoF of all-user ANECE is generally larger than that of pair-wise ANECE; c) For a two-user network, a modified ANECE deploying square-shaped nonsingular pilot matrices yields a higher total SDoF than the original ANECE. The multi-user ANECE and the modified two-user ANECE shown in this paper appear to be the best full-duplex schemes known today in terms of SDoF subject to each node using a given number of antennas for both transmitting and receiving.
Stock Market Sentiment Classification and Backtesting via Fine-tuned BERT
Sep 21, 2023With the rapid development of big data and computing devices, low-latency automatic trading platforms based on real-time information acquisition have become the main components of the stock trading market, so the topic of quantitative trading has received widespread attention. And for non-strongly efficient trading markets, human emotions and expectations always dominate market trends and trading decisions. Therefore, this paper starts from the theory of emotion, taking East Money as an example, crawling user comment titles data from its corresponding stock bar and performing data cleaning. Subsequently, a natural language processing model BERT was constructed, and the BERT model was fine-tuned using existing annotated data sets. The experimental results show that the fine-tuned model has different degrees of performance improvement compared to the original model and the baseline model. Subsequently, based on the above model, the user comment data crawled is labeled with emotional polarity, and the obtained label information is combined with the Alpha191 model to participate in regression, and significant regression results are obtained. Subsequently, the regression model is used to predict the average price change for the next five days, and use it as a signal to guide automatic trading. The experimental results show that the incorporation of emotional factors increased the return rate by 73.8\% compared to the baseline during the trading period, and by 32.41\% compared to the original alpha191 model. Finally, we discuss the advantages and disadvantages of incorporating emotional factors into quantitative trading, and give possible directions for further research in the future.
Deep learning probability flows and entropy production rates in active matter
Sep 22, 2023Active matter systems, from self-propelled colloids to motile bacteria, are characterized by the conversion of free energy into useful work at the microscopic scale. These systems generically involve physics beyond the reach of equilibrium statistical mechanics, and a persistent challenge has been to understand the nature of their nonequilibrium states. The entropy production rate and the magnitude of the steady-state probability current provide quantitative ways to do so by measuring the breakdown of time-reversal symmetry and the strength of nonequilibrium transport of measure. Yet, their efficient computation has remained elusive, as they depend on the system's unknown and high-dimensional probability density. Here, building upon recent advances in generative modeling, we develop a deep learning framework that estimates the score of this density. We show that the score, together with the microscopic equations of motion, gives direct access to the entropy production rate, the probability current, and their decomposition into local contributions from individual particles, spatial regions, and degrees of freedom. To represent the score, we introduce a novel, spatially-local transformer-based network architecture that learns high-order interactions between particles while respecting their underlying permutation symmetry. We demonstrate the broad utility and scalability of the method by applying it to several high-dimensional systems of interacting active particles undergoing motility-induced phase separation (MIPS). We show that a single instance of our network trained on a system of 4096 particles at one packing fraction can generalize to other regions of the phase diagram, including systems with as many as 32768 particles. We use this observation to quantify the spatial structure of the departure from equilibrium in MIPS as a function of the number of particles and the packing fraction.