 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Near Field Optimization Algorithm for Reconfigurable Intelligent Surface
Sep 21, 2023
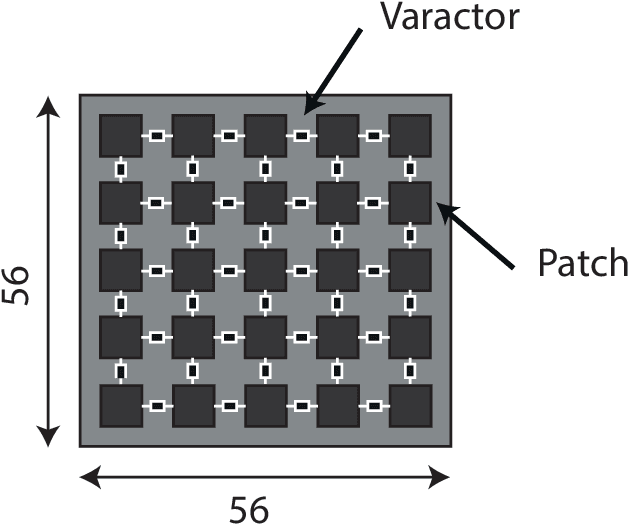
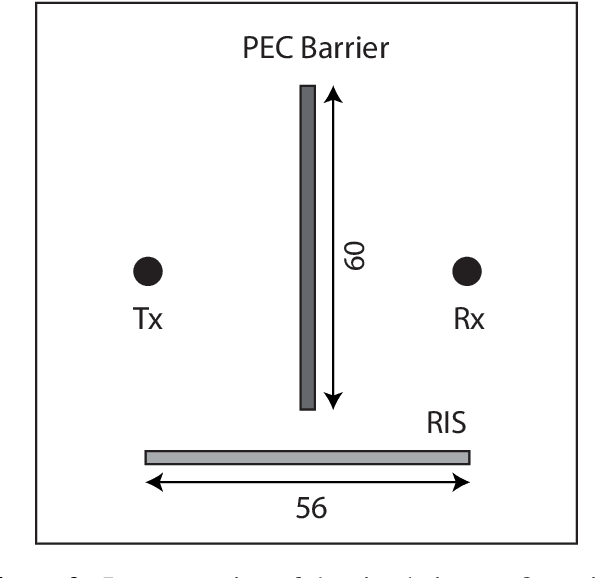
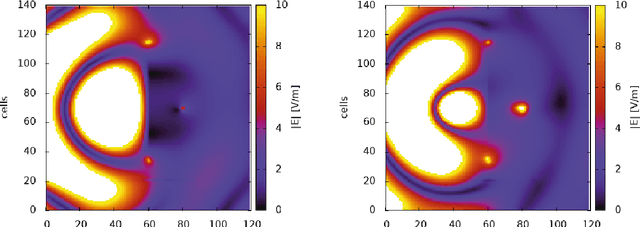
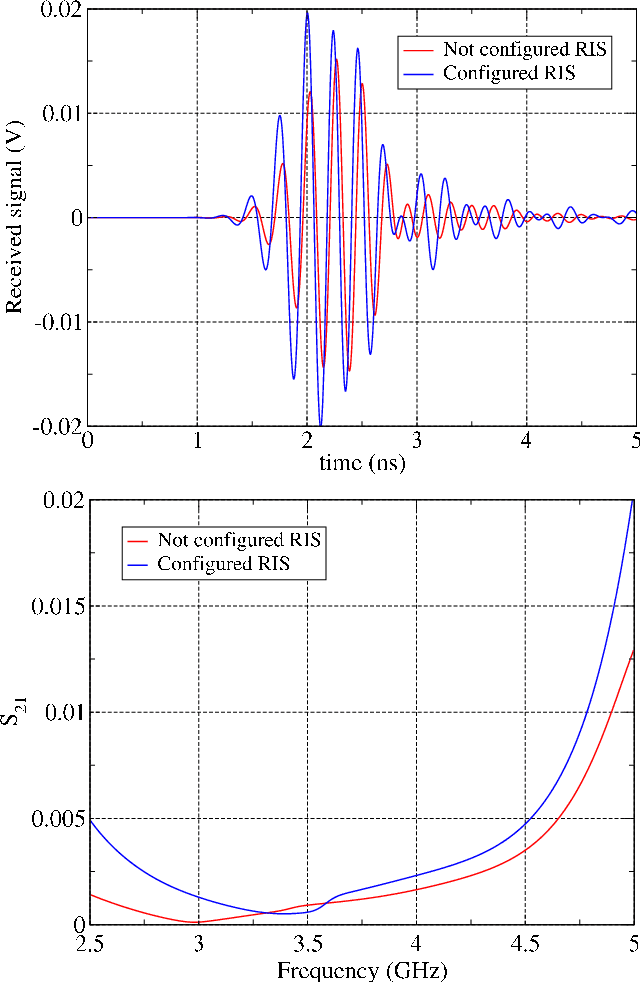
Reconfigurable intelligent surface (RIS) is a type of wireless communication technology that uses a reconfigurable surface, such as a wall or building that is able to adjust its properties by an integrated optimization algorithm in order to optimize the signal propagation for a given communication scenario. As a reconfiguration algorithm the multidimensional optimization of the GNU scientific library was analyzed to evaluate the performance of the smart surface in the quality of signal reception. This analysis took place by means of electrodynamic simulations based on the finite difference time domain method. Through these simulations it was possible to observe the efficiency of the algorithm in the reconfiguration of the RIS, managing to focus the electromagnetic waves in a remarkable way towards the point of interest.
MINS: Efficient and Robust Multisensor-aided Inertial Navigation System
Sep 27, 2023Robust multisensor fusion of multi-modal measurements such as IMUs, wheel encoders, cameras, LiDARs, and GPS holds great potential due to its innate ability to improve resilience to sensor failures and measurement outliers, thereby enabling robust autonomy. To the best of our knowledge, this work is among the first to develop a consistent tightly-coupled Multisensor-aided Inertial Navigation System (MINS) that is capable of fusing the most common navigation sensors in an efficient filtering framework, by addressing the particular challenges of computational complexity, sensor asynchronicity, and intra-sensor calibration. In particular, we propose a consistent high-order on-manifold interpolation scheme to enable efficient asynchronous sensor fusion and state management strategy (i.e. dynamic cloning). The proposed dynamic cloning leverages motion-induced information to adaptively select interpolation orders to control computational complexity while minimizing trajectory representation errors. We perform online intrinsic and extrinsic (spatiotemporal) calibration of all onboard sensors to compensate for poor prior calibration and/or degraded calibration varying over time. Additionally, we develop an initialization method with only proprioceptive measurements of IMU and wheel encoders, instead of exteroceptive sensors, which is shown to be less affected by the environment and more robust in highly dynamic scenarios. We extensively validate the proposed MINS in simulations and large-scale challenging real-world datasets, outperforming the existing state-of-the-art methods, in terms of localization accuracy, consistency, and computation efficiency. We have also open-sourced our algorithm, simulator, and evaluation toolbox for the benefit of the community: https://github.com/rpng/mins.
Self-Sustaining Multiple Access with Continual Deep Reinforcement Learning for Dynamic Metaverse Applications
Sep 18, 2023The Metaverse is a new paradigm that aims to create a virtual environment consisting of numerous worlds, each of which will offer a different set of services. To deal with such a dynamic and complex scenario, considering the stringent quality of service requirements aimed at the 6th generation of communication systems (6G), one potential approach is to adopt self-sustaining strategies, which can be realized by employing Adaptive Artificial Intelligence (Adaptive AI) where models are continually re-trained with new data and conditions. One aspect of self-sustainability is the management of multiple access to the frequency spectrum. Although several innovative methods have been proposed to address this challenge, mostly using Deep Reinforcement Learning (DRL), the problem of adapting agents to a non-stationary environment has not yet been precisely addressed. This paper fills in the gap in the current literature by investigating the problem of multiple access in multi-channel environments to maximize the throughput of the intelligent agent when the number of active User Equipments (UEs) may fluctuate over time. To solve the problem, a Double Deep Q-Learning (DDQL) technique empowered by Continual Learning (CL) is proposed to overcome the non-stationary situation, while the environment is unknown. Numerical simulations demonstrate that, compared to other well-known methods, the CL-DDQL algorithm achieves significantly higher throughputs with a considerably shorter convergence time in highly dynamic scenarios.
A Schedule of Duties in the Cloud Space Using a Modified Salp Swarm Algorithm
Sep 18, 2023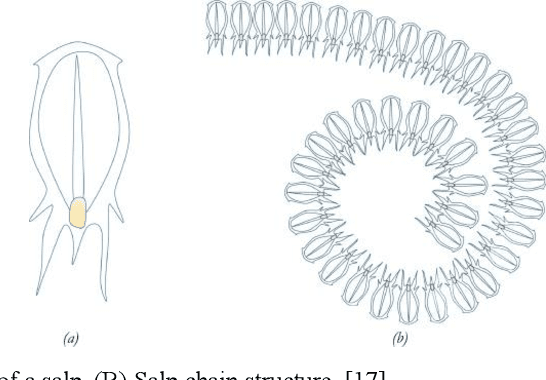



Cloud computing is a concept introduced in the information technology era, with the main components being the grid, distributed, and valuable computing. The cloud is being developed continuously and, naturally, comes up with many challenges, one of which is scheduling. A schedule or timeline is a mechanism used to optimize the time for performing a duty or set of duties. A scheduling process is accountable for choosing the best resources for performing a duty. The main goal of a scheduling algorithm is to improve the efficiency and quality of the service while at the same time ensuring the acceptability and effectiveness of the targets. The task scheduling problem is one of the most important NP-hard issues in the cloud domain and, so far, many techniques have been proposed as solutions, including using genetic algorithms (GAs), particle swarm optimization, (PSO), and ant colony optimization (ACO). To address this problem, in this paper, one of the collective intelligence algorithms, called the Salp Swarm Algorithm (SSA), has been expanded, improved, and applied. The performance of the proposed algorithm has been compared with that of GAs, PSO, continuous ACO, and the basic SSA. The results show that our algorithm has generally higher performance than the other algorithms. For example, compared to the basic SSA, the proposed method has an average reduction of approximately 21% in makespan.
Source-Free Domain Adaptation with Temporal Imputation for Time Series Data
Jul 14, 2023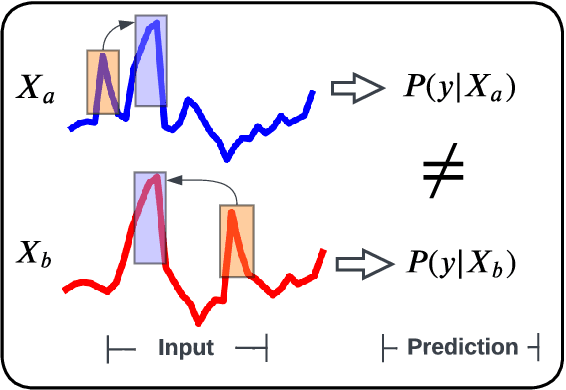
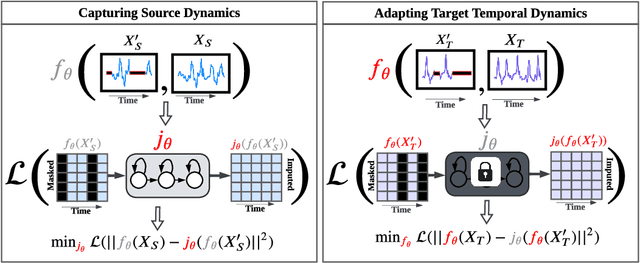
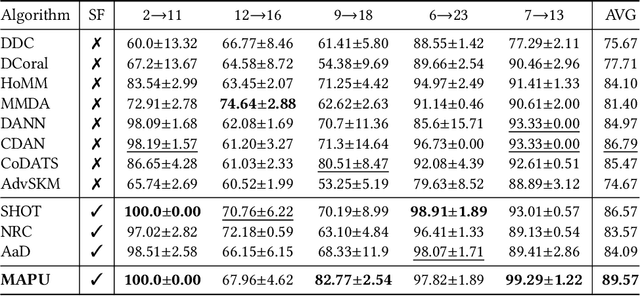
Source-free domain adaptation (SFDA) aims to adapt a pretrained model from a labeled source domain to an unlabeled target domain without access to the source domain data, preserving source domain privacy. Despite its prevalence in visual applications, SFDA is largely unexplored in time series applications. The existing SFDA methods that are mainly designed for visual applications may fail to handle the temporal dynamics in time series, leading to impaired adaptation performance. To address this challenge, this paper presents a simple yet effective approach for source-free domain adaptation on time series data, namely MAsk and imPUte (MAPU). First, to capture temporal information of the source domain, our method performs random masking on the time series signals while leveraging a novel temporal imputer to recover the original signal from a masked version in the embedding space. Second, in the adaptation step, the imputer network is leveraged to guide the target model to produce target features that are temporally consistent with the source features. To this end, our MAPU can explicitly account for temporal dependency during the adaptation while avoiding the imputation in the noisy input space. Our method is the first to handle temporal consistency in SFDA for time series data and can be seamlessly equipped with other existing SFDA methods. Extensive experiments conducted on three real-world time series datasets demonstrate that our MAPU achieves significant performance gain over existing methods. Our code is available at \url{https://github.com/mohamedr002/MAPU_SFDA_TS}.
CPU frequency scheduling of real-time applications on embedded devices with temporal encoding-based deep reinforcement learning
Sep 07, 2023Small devices are frequently used in IoT and smart-city applications to perform periodic dedicated tasks with soft deadlines. This work focuses on developing methods to derive efficient power-management methods for periodic tasks on small devices. We first study the limitations of the existing Linux built-in methods used in small devices. We illustrate three typical workload/system patterns that are challenging to manage with Linux's built-in solutions. We develop a reinforcement-learning-based technique with temporal encoding to derive an effective DVFS governor even with the presence of the three system patterns. The derived governor uses only one performance counter, the same as the built-in Linux mechanism, and does not require an explicit task model for the workload. We implemented a prototype system on the Nvidia Jetson Nano Board and experimented with it with six applications, including two self-designed and four benchmark applications. Under different deadline constraints, our approach can quickly derive a DVFS governor that can adapt to performance requirements and outperform the built-in Linux approach in energy saving. On Mibench workloads, with performance slack ranging from 0.04 s to 0.4 s, the proposed method can save 3% - 11% more energy compared to Ondemand. AudioReg and FaceReg applications tested have 5%- 14% energy-saving improvement. We have open-sourced the implementation of our in-kernel quantized neural network engine. The codebase can be found at: https://github.com/coladog/tinyagent.
* Accepted to Journal of Systems Architecture
Correlation-aware Spatial-Temporal Graph Learning for Multivariate Time-series Anomaly Detection
Jul 17, 2023
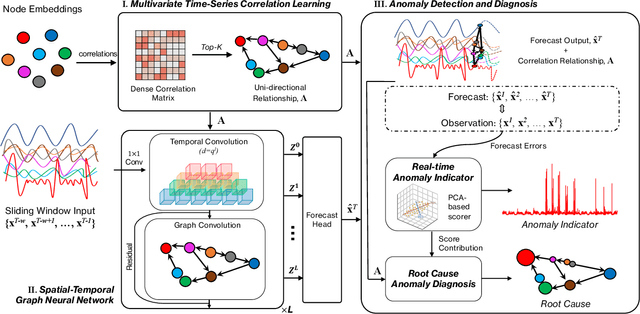

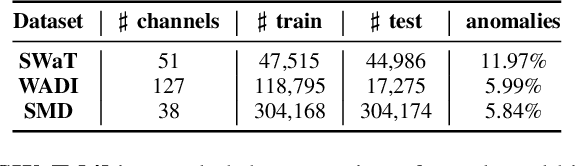
Multivariate time-series anomaly detection is critically important in many applications, including retail, transportation, power grid, and water treatment plants. Existing approaches for this problem mostly employ either statistical models which cannot capture the non-linear relations well or conventional deep learning models (e.g., CNN and LSTM) that do not explicitly learn the pairwise correlations among variables. To overcome these limitations, we propose a novel method, correlation-aware spatial-temporal graph learning (termed CST-GL), for time series anomaly detection. CST-GL explicitly captures the pairwise correlations via a multivariate time series correlation learning module based on which a spatial-temporal graph neural network (STGNN) can be developed. Then, by employing a graph convolution network that exploits one- and multi-hop neighbor information, our STGNN component can encode rich spatial information from complex pairwise dependencies between variables. With a temporal module that consists of dilated convolutional functions, the STGNN can further capture long-range dependence over time. A novel anomaly scoring component is further integrated into CST-GL to estimate the degree of an anomaly in a purely unsupervised manner. Experimental results demonstrate that CST-GL can detect anomalies effectively in general settings as well as enable early detection across different time delays.
Simultaneous Measurement of Multiple Acoustic Attributes Using Structured Periodic Test Signals Including Music and Other Sound Materials
Sep 06, 2023We introduce a general framework for measuring acoustic properties such as liner time-invariant (LTI) response, signal-dependent time-invariant (SDTI) component, and random and time-varying (RTV) component simultaneously using structured periodic test signals. The framework also enables music pieces and other sound materials as test signals by "safeguarding" them by adding slight deterministic "noise." Measurement using swept-sin, MLS (Maxim Length Sequence), and their variants are special cases of the proposed framework. We implemented interactive and real-time measuring tools based on this framework and made them open-source. Furthermore, we applied this framework to assess pitch extractors objectively.
Heart rate measurement using the built-in triaxial accelerometer from a commercial digital writing device
Sep 25, 2023Wearable devices are on the rise. Smart watches and phones, fitness trackers or smart textiles now provide unprecedented access to our own personal data. As such, wearable devices can enable health monitoring without disrupting our daily routines. In clinical settings, electrocardiograms (ECGs) and photoplethysmographies (PPGs) are used to monitor the heart's and respiratory behaviors. In more practical settings, accelerometers can be used to estimate the heartrate when they are attached to the chest. They can also help filter out some noise in ECG signal from movement. In this work, we compare the heart rate data extracted from the built-in accelerometer of a commercial smart pen equipped with sensors (STABILO's DigiPen), with a standard ECG monitor readouts. We demonstrate that it is possible to accurately predict the heart rate from the smart pencil. The data collection is done with eight volunteers, writing the alphabet continuously for five minutes. The signal is processed with a Butterworth filter to cut off noise. We achieve a mean-squared error (MSE) better than 6.685x10$^{-3}$ comparing the DigiPen's computed ${\Delta}$t (time between pulses) with the reference ECG data. The peaks' timestamps for both signals all maintain a correlation higher than 0.99. All computed heart rates from the pen accurately correlate with the reference ECG signals.
Hierarchical Reinforcement Learning based on Planning Operators
Sep 25, 2023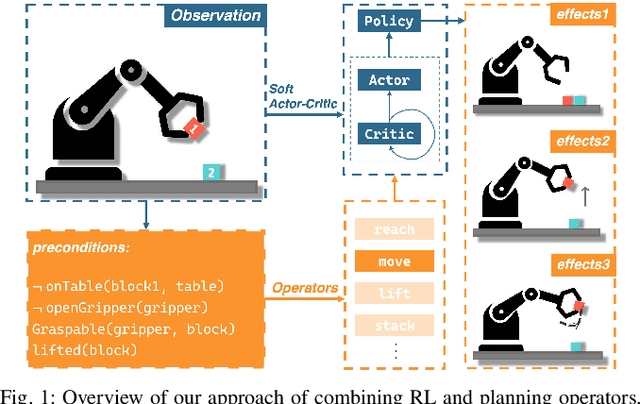

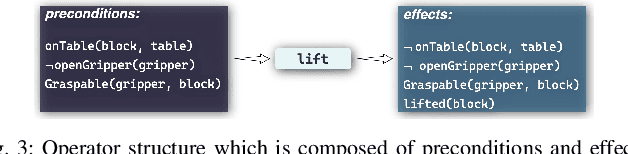
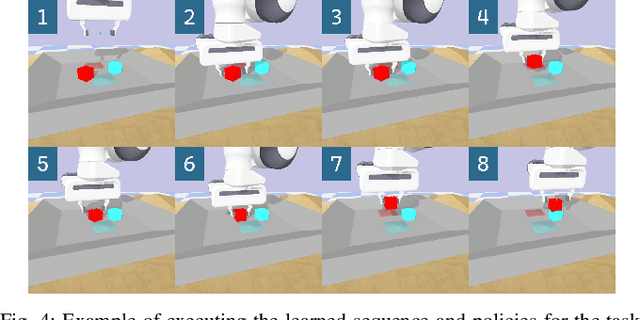
Long-horizon manipulation tasks such as stacking represent a longstanding challenge in the field of robotic manipulation, particularly when using reinforcement learning (RL) methods which often struggle to learn the correct sequence of actions for achieving these complex goals. To learn this sequence, symbolic planning methods offer a good solution based on high-level reasoning, however, planners often fall short in addressing the low-level control specificity needed for precise execution. This paper introduces a novel framework that integrates symbolic planning with hierarchical RL through the cooperation of high-level operators and low-level policies. Our contribution integrates planning operators (e.g. preconditions and effects) as part of the hierarchical RL algorithm based on the Scheduled Auxiliary Control (SAC-X) method. We developed a dual-purpose high-level operator, which can be used both in holistic planning and as independent, reusable policies. Our approach offers a flexible solution for long-horizon tasks, e.g., stacking a cube. The experimental results show that our proposed method obtained an average of 97.2% success rate for learning and executing the whole stack sequence, and the success rate for learning independent policies, e.g. reach (98.9%), lift (99.7%), stack (85%), etc. The training time is also reduced by 68% when using our proposed approach.