 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Diffusion Generative Inverse Design
Sep 18, 2023
Inverse design refers to the problem of optimizing the input of an objective function in order to enact a target outcome. For many real-world engineering problems, the objective function takes the form of a simulator that predicts how the system state will evolve over time, and the design challenge is to optimize the initial conditions that lead to a target outcome. Recent developments in learned simulation have shown that graph neural networks (GNNs) can be used for accurate, efficient, differentiable estimation of simulator dynamics, and support high-quality design optimization with gradient- or sampling-based optimization procedures. However, optimizing designs from scratch requires many expensive model queries, and these procedures exhibit basic failures on either non-convex or high-dimensional problems. In this work, we show how denoising diffusion models (DDMs) can be used to solve inverse design problems efficiently and propose a particle sampling algorithm for further improving their efficiency. We perform experiments on a number of fluid dynamics design challenges, and find that our approach substantially reduces the number of calls to the simulator compared to standard techniques.
Euclidean and non-Euclidean Trajectory Optimization Approaches for Quadrotor Racing
Sep 13, 2023We present two approaches to compute raceline trajectories for quadrotors by solving an optimal control problem. The approaches involve expressing quadrotor pose in either a Euclidean or non-Euclidean frame of reference and are both based on collocation. The compute times of both approaches are over 100x faster than published methods. Additionally, both approaches compute trajectories with faster lap time and show improved numerical convergence. In the last part of the paper we devise a novel method to compute racelines in dense obstacle fields using the non-Euclidean approach.
Computing SHAP Efficiently Using Model Structure Information
Sep 05, 2023
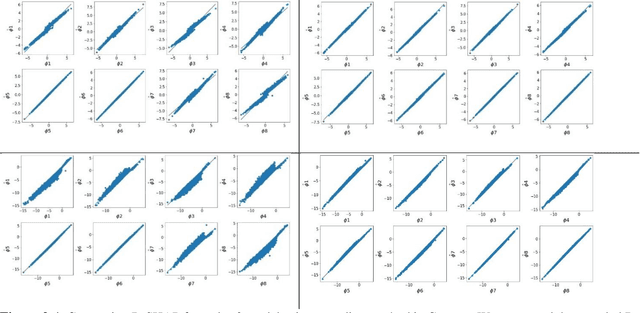
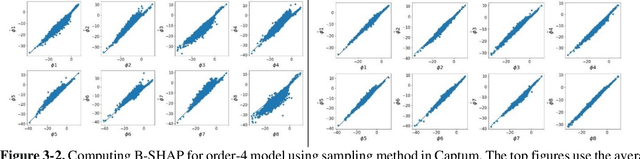
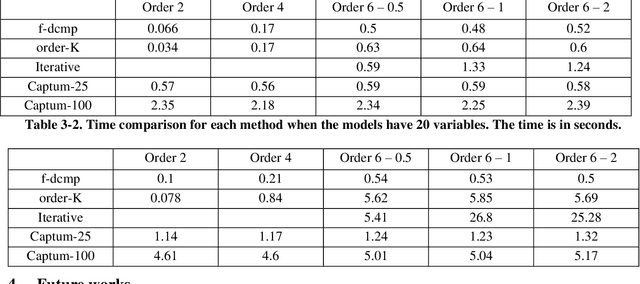
SHAP (SHapley Additive exPlanations) has become a popular method to attribute the prediction of a machine learning model on an input to its features. One main challenge of SHAP is the computation time. An exact computation of Shapley values requires exponential time complexity. Therefore, many approximation methods are proposed in the literature. In this paper, we propose methods that can compute SHAP exactly in polynomial time or even faster for SHAP definitions that satisfy our additivity and dummy assumptions (eg, kernal SHAP and baseline SHAP). We develop different strategies for models with different levels of model structure information: known functional decomposition, known order of model (defined as highest order of interaction in the model), or unknown order. For the first case, we demonstrate an additive property and a way to compute SHAP from the lower-order functional components. For the second case, we derive formulas that can compute SHAP in polynomial time. Both methods yield exact SHAP results. Finally, if even the order of model is unknown, we propose an iterative way to approximate Shapley values. The three methods we propose are computationally efficient when the order of model is not high which is typically the case in practice. We compare with sampling approach proposed in Castor & Gomez (2008) using simulation studies to demonstrate the efficacy of our proposed methods.
A new meteor detection application robust to camera movements
Sep 12, 2023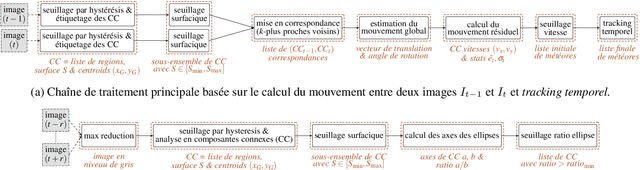
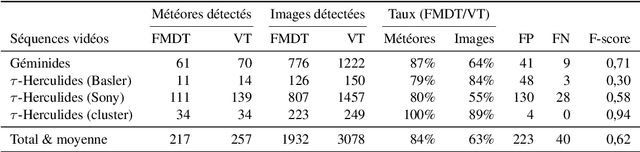


This article presents a new tool for the automatic detection of meteors. Fast Meteor Detection Toolbox (FMDT) is able to detect meteor sightings by analyzing videos acquired by cameras onboard weather balloons or within airplane with stabilization. The challenge consists in designing a processing chain composed of simple algorithms, that are robust to the high fluctuation of the videos and that satisfy the constraints on power consumption (10 W) and real-time processing (25 frames per second).
Budget-Aware Pruning: Handling Multiple Domains with Less Parameters
Sep 20, 2023Deep learning has achieved state-of-the-art performance on several computer vision tasks and domains. Nevertheless, it still has a high computational cost and demands a significant amount of parameters. Such requirements hinder the use in resource-limited environments and demand both software and hardware optimization. Another limitation is that deep models are usually specialized into a single domain or task, requiring them to learn and store new parameters for each new one. Multi-Domain Learning (MDL) attempts to solve this problem by learning a single model that is capable of performing well in multiple domains. Nevertheless, the models are usually larger than the baseline for a single domain. This work tackles both of these problems: our objective is to prune models capable of handling multiple domains according to a user-defined budget, making them more computationally affordable while keeping a similar classification performance. We achieve this by encouraging all domains to use a similar subset of filters from the baseline model, up to the amount defined by the user's budget. Then, filters that are not used by any domain are pruned from the network. The proposed approach innovates by better adapting to resource-limited devices while, to our knowledge, being the only work that handles multiple domains at test time with fewer parameters and lower computational complexity than the baseline model for a single domain.
AutoSynth: Learning to Generate 3D Training Data for Object Point Cloud Registration
Sep 20, 2023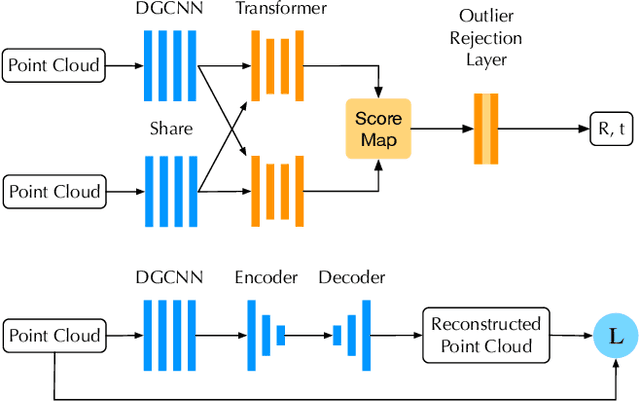

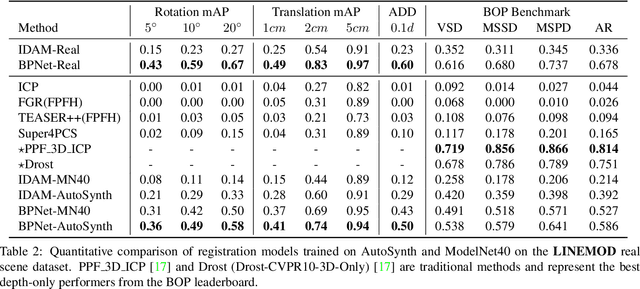
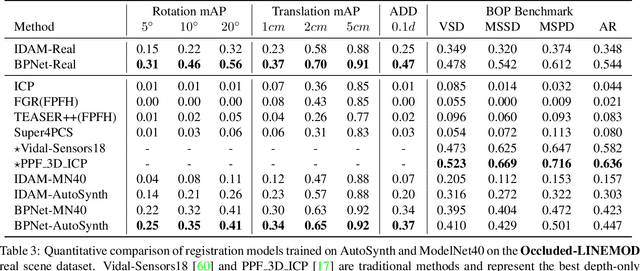
In the current deep learning paradigm, the amount and quality of training data are as critical as the network architecture and its training details. However, collecting, processing, and annotating real data at scale is difficult, expensive, and time-consuming, particularly for tasks such as 3D object registration. While synthetic datasets can be created, they require expertise to design and include a limited number of categories. In this paper, we introduce a new approach called AutoSynth, which automatically generates 3D training data for point cloud registration. Specifically, AutoSynth automatically curates an optimal dataset by exploring a search space encompassing millions of potential datasets with diverse 3D shapes at a low cost.To achieve this, we generate synthetic 3D datasets by assembling shape primitives, and develop a meta-learning strategy to search for the best training data for 3D registration on real point clouds. For this search to remain tractable, we replace the point cloud registration network with a much smaller surrogate network, leading to a $4056.43$ times speedup. We demonstrate the generality of our approach by implementing it with two different point cloud registration networks, BPNet and IDAM. Our results on TUD-L, LINEMOD and Occluded-LINEMOD evidence that a neural network trained on our searched dataset yields consistently better performance than the same one trained on the widely used ModelNet40 dataset.
EDMP: Ensemble-of-costs-guided Diffusion for Motion Planning
Sep 20, 2023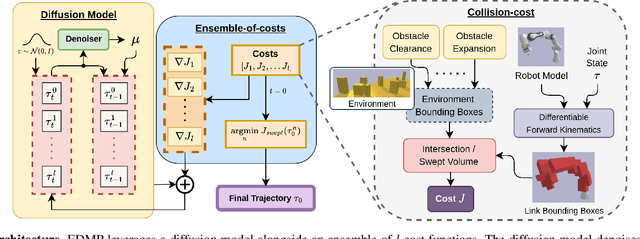
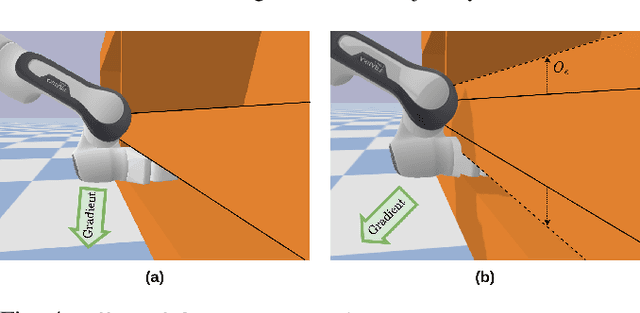
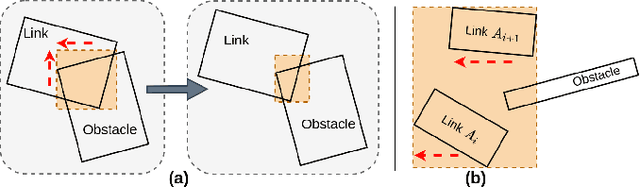
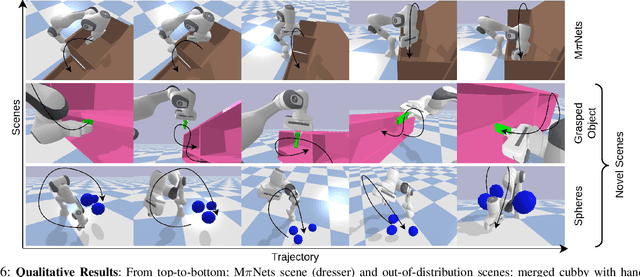
Classical motion planning for robotic manipulation includes a set of general algorithms that aim to minimize a scene-specific cost of executing a given plan. This approach offers remarkable adaptability, as they can be directly used off-the-shelf for any new scene without needing specific training datasets. However, without a prior understanding of what diverse valid trajectories are and without specially designed cost functions for a given scene, the overall solutions tend to have low success rates. While deep-learning-based algorithms tremendously improve success rates, they are much harder to adopt without specialized training datasets. We propose EDMP, an Ensemble-of-costs-guided Diffusion for Motion Planning that aims to combine the strengths of classical and deep-learning-based motion planning. Our diffusion-based network is trained on a set of diverse kinematically valid trajectories. Like classical planning, for any new scene at the time of inference, we compute scene-specific costs such as "collision cost" and guide the diffusion to generate valid trajectories that satisfy the scene-specific constraints. Further, instead of a single cost function that may be insufficient in capturing diversity across scenes, we use an ensemble of costs to guide the diffusion process, significantly improving the success rate compared to classical planners. EDMP performs comparably with SOTA deep-learning-based methods while retaining the generalization capabilities primarily associated with classical planners.
ChatGPT-4 as a Tool for Reviewing Academic Books in Spanish
Sep 20, 2023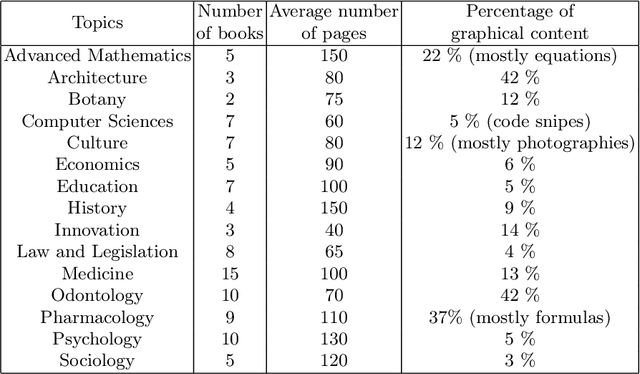
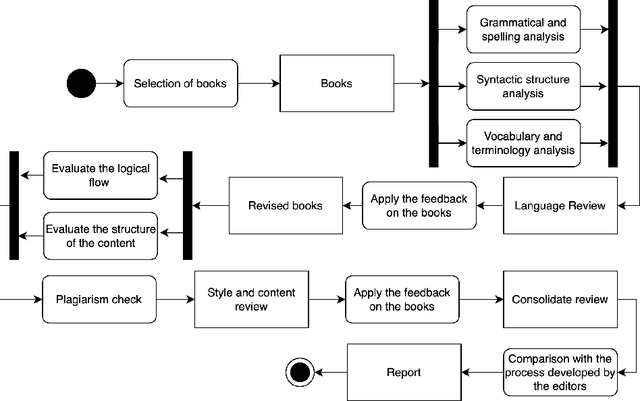
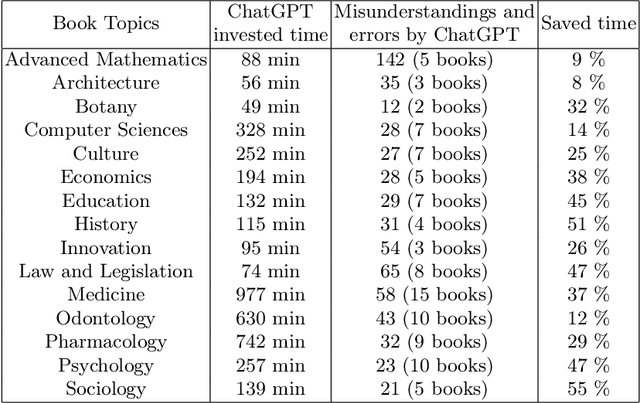
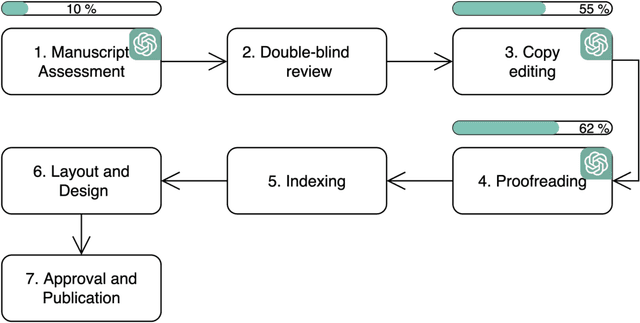
This study evaluates the potential of ChatGPT-4, an artificial intelligence language model developed by OpenAI, as an editing tool for Spanish literary and academic books. The need for efficient and accessible reviewing and editing processes in the publishing industry has driven the search for automated solutions. ChatGPT-4, being one of the most advanced language models, offers notable capabilities in text comprehension and generation. In this study, the features and capabilities of ChatGPT-4 are analyzed in terms of grammatical correction, stylistic coherence, and linguistic enrichment of texts in Spanish. Tests were conducted with 100 literary and academic texts, where the edits made by ChatGPT-4 were compared to those made by expert human reviewers and editors. The results show that while ChatGPT-4 is capable of making grammatical and orthographic corrections with high accuracy and in a very short time, it still faces challenges in areas such as context sensitivity, bibliometric analysis, deep contextual understanding, and interaction with visual content like graphs and tables. However, it is observed that collaboration between ChatGPT-4 and human reviewers and editors can be a promising strategy for improving efficiency without compromising quality. Furthermore, the authors consider that ChatGPT-4 represents a valuable tool in the editing process, but its use should be complementary to the work of human editors to ensure high-caliber editing in Spanish literary and academic books.
Large-scale Pretraining Improves Sample Efficiency of Active Learning based Molecule Virtual Screening
Sep 20, 2023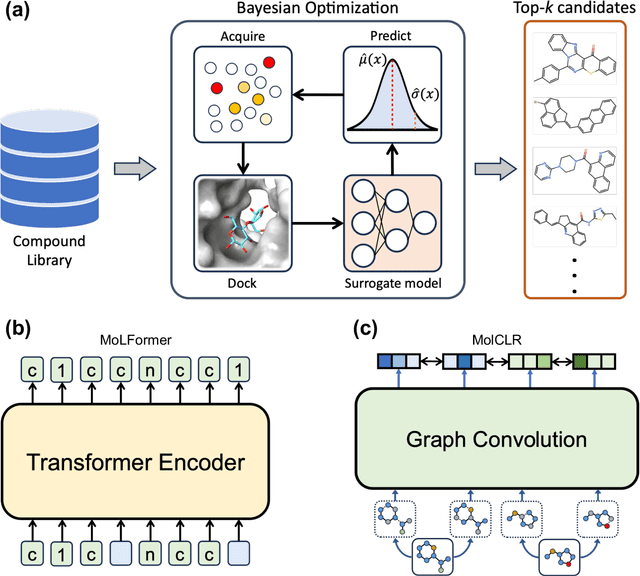
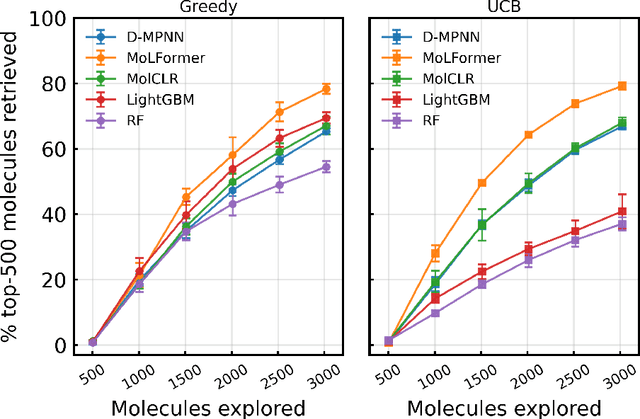
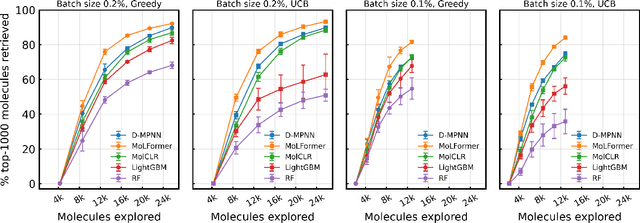
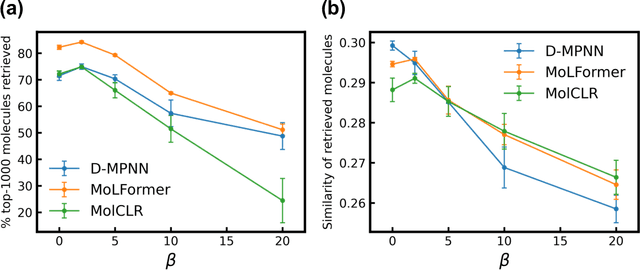
Virtual screening of large compound libraries to identify potential hit candidates is one of the earliest steps in drug discovery. As the size of commercially available compound collections grows exponentially to the scale of billions, brute-force virtual screening using traditional tools such as docking becomes infeasible in terms of time and computational resources. Active learning and Bayesian optimization has recently been proven as effective methods of narrowing down the search space. An essential component in those methods is a surrogate machine learning model that is trained with a small subset of the library to predict the desired properties of compounds. Accurate model can achieve high sample efficiency by finding the most promising compounds with only a fraction of the whole library being virtually screened. In this study, we examined the performance of pretrained transformer-based language model and graph neural network in Bayesian optimization active learning framework. The best pretrained models identifies 58.97% of the top-50000 by docking score after screening only 0.6% of an ultra-large library containing 99.5 million compounds, improving 8% over previous state-of-the-art baseline. Through extensive benchmarks, we show that the superior performance of pretrained models persists in both structure-based and ligand-based drug discovery. Such model can serve as a boost to the accuracy and sample efficiency of active learning based molecule virtual screening.
A Wearable Ultra-Low-Power sEMG-Triggered Ultrasound System for Long-Term Muscle Activity Monitoring
Sep 14, 2023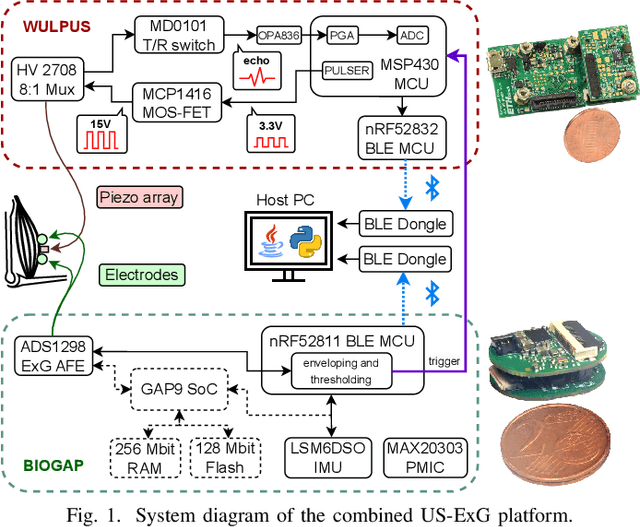
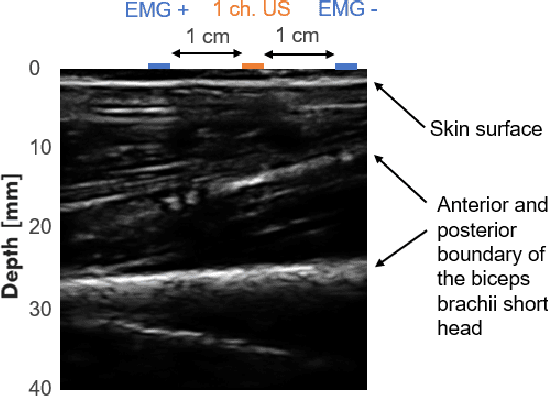
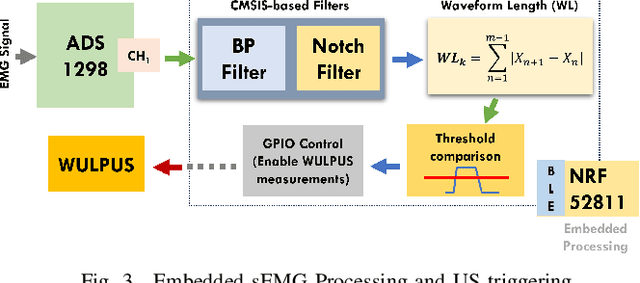
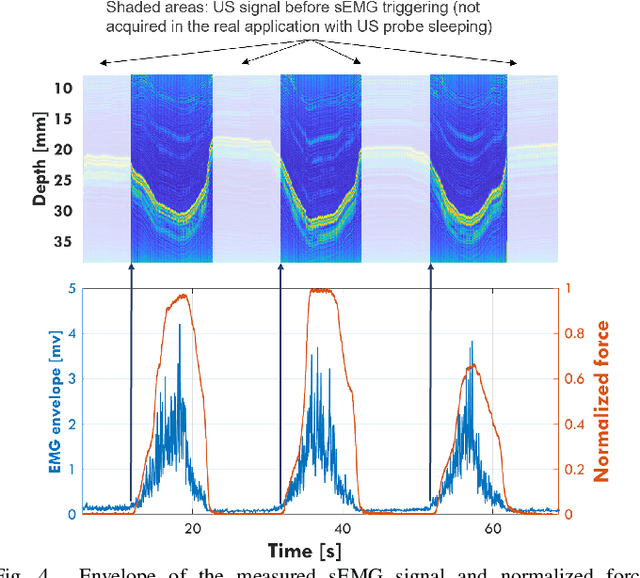
Surface electromyography (sEMG) is a well-established approach to monitor muscular activity on wearable and resource-constrained devices. However, when measuring deeper muscles, its low signal-to-noise ratio (SNR), high signal attenuation, and crosstalk degrade sensing performance. Ultrasound (US) complements sEMG effectively with its higher SNR at high penetration depths. In fact, combining US and sEMG improves the accuracy of muscle dynamic assessment, compared to using only one modality. However, the power envelope of US hardware is considerably higher than that of sEMG, thus inflating energy consumption and reducing the battery life. This work proposes a wearable solution that integrates both modalities and utilizes an EMG-driven wake-up approach to achieve ultra-low power consumption as needed for wearable long-term monitoring. We integrate two wearable state-of-the-art (SoA) US and ExG biosignal acquisition devices to acquire time-synchronized measurements of the short head of the biceps. To minimize power consumption, the US probe is kept in a sleep state when there is no muscle activity. sEMG data are processed on the probe (filtering, envelope extraction and thresholding) to identify muscle activity and generate a trigger to wake-up the US counterpart. The US acquisition starts before muscle fascicles displacement thanks to a triggering time faster than the electromechanical delay (30-100 ms) between the neuromuscular junction stimulation and the muscle contraction. Assuming a muscle contraction of 200 ms at a contraction rate of 1 Hz, the proposed approach enables more than 59% energy saving (with a full-system average power consumption of 12.2 mW) as compared to operating both sEMG and US continuously.