 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Wi-BFI: Extracting the IEEE 802.11 Beamforming Feedback Information from Commercial Wi-Fi Devices
Sep 12, 2023
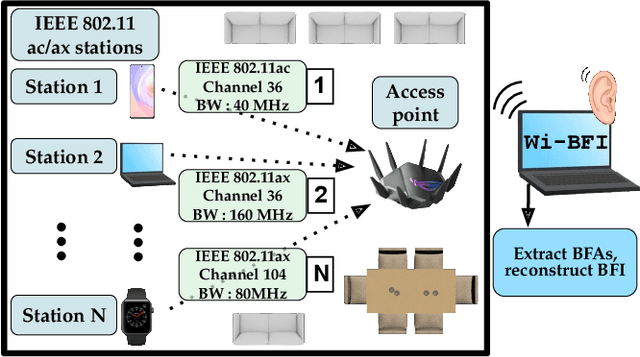
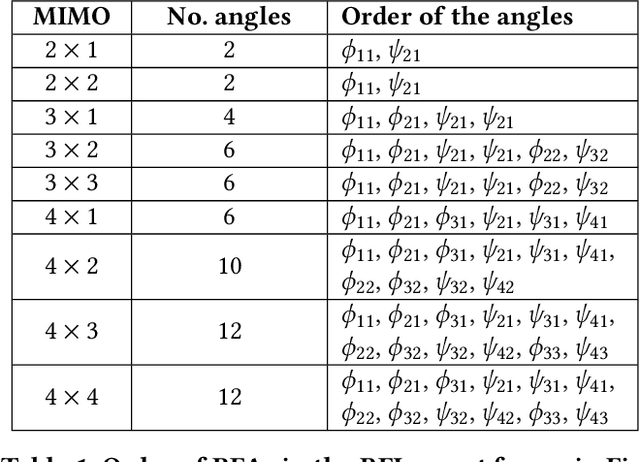
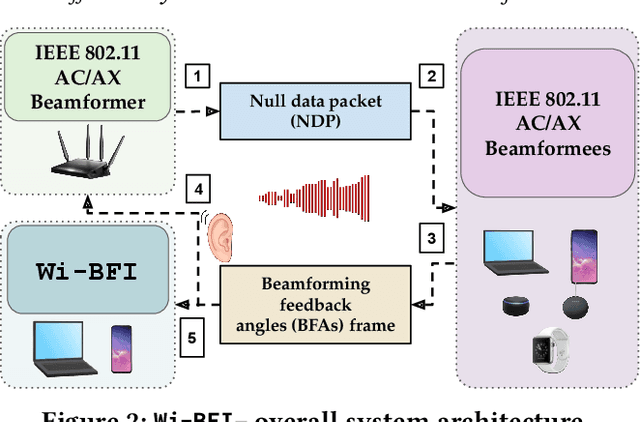
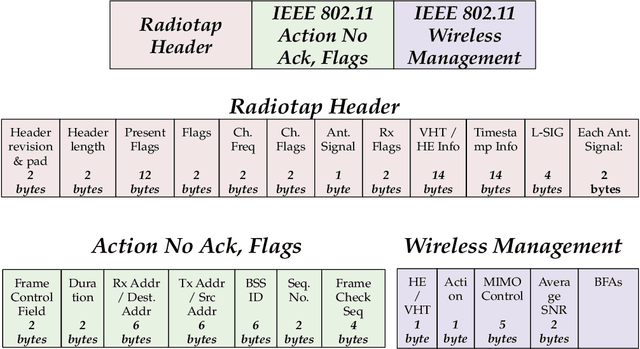
Recently, researchers have shown that the beamforming feedback angles (BFAs) used for Wi-Fi multiple-input multiple-output (MIMO) operations can be effectively leveraged as a proxy of the channel frequency response (CFR) for different purposes. Examples are passive human activity recognition and device fingerprinting. However, even though the BFAs report frames are sent in clear text, there is not yet a unified open-source tool to extract and decode the BFAs from the frames. To fill this gap, we developed Wi-BFI, the first tool that allows retrieving Wi-Fi BFAs and reconstructing the beamforming feedback information (BFI) - a compressed representation of the CFR - from the BFAs frames captured over the air. The tool supports BFAs extraction within both IEEE 802.11ac and 802.11ax networks operating on radio channels with 160/80/40/20 MHz bandwidth. Both multi-user and single-user MIMO feedback can be decoded through Wi-BFI. The tool supports real-time and offline extraction and storage of BFAs and BFI. The real-time mode also includes a visual representation of the channel state that continuously updates based on the collected data. Wi-BFI code is open source and the tool is also available as a pip package.
Crowdotic: A Privacy-Preserving Hospital Waiting Room Crowd Density Estimation with Non-speech Audio
Sep 20, 2023

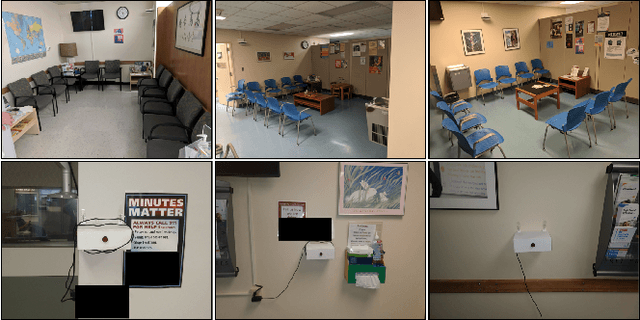
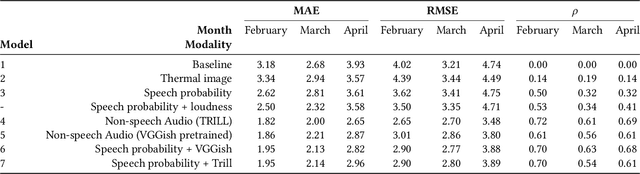
Privacy-preserving crowd density analysis finds application across a wide range of scenarios, substantially enhancing smart building operation and management while upholding privacy expectations in various spaces. We propose a non-speech audio-based approach for crowd analytics, leveraging a transformer-based model. Our results demonstrate that non-speech audio alone can be used to conduct such analysis with remarkable accuracy. To the best of our knowledge, this is the first time when non-speech audio signals are proposed for predicting occupancy. As far as we know, there has been no other similar approach of its kind prior to this. To accomplish this, we deployed our sensor-based platform in the waiting room of a large hospital with IRB approval over a period of several months to capture non-speech audio and thermal images for the training and evaluation of our models. The proposed non-speech-based approach outperformed the thermal camera-based model and all other baselines. In addition to demonstrating superior performance without utilizing speech audio, we conduct further analysis using differential privacy techniques to provide additional privacy guarantees. Overall, our work demonstrates the viability of employing non-speech audio data for accurate occupancy estimation, while also ensuring the exclusion of speech-related content and providing robust privacy protections through differential privacy guarantees.
Spiking NeRF: Making Bio-inspired Neural Networks See through the Real World
Sep 20, 2023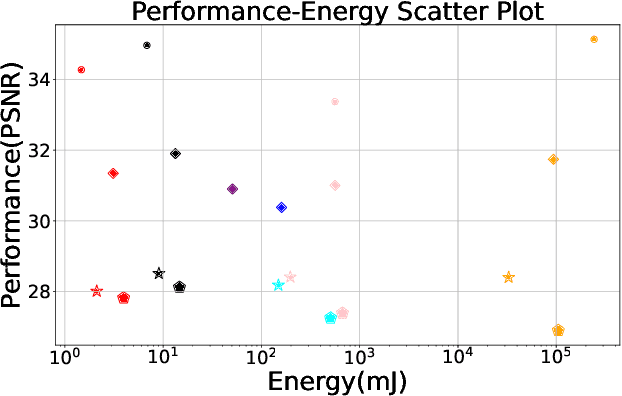
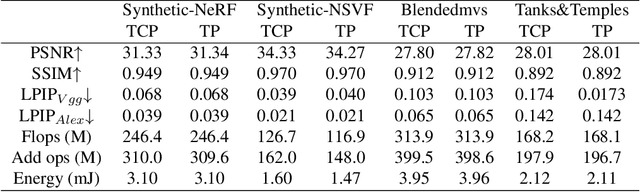
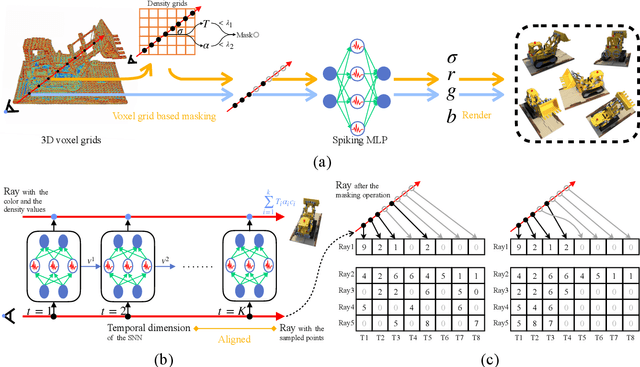
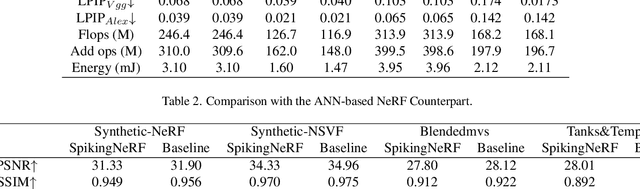
Spiking neuron networks (SNNs) have been thriving on numerous tasks to leverage their promising energy efficiency and exploit their potentialities as biologically plausible intelligence. Meanwhile, the Neural Radiance Fields (NeRF) render high-quality 3D scenes with massive energy consumption, and few works delve into the energy-saving solution with a bio-inspired approach. In this paper, we propose spiking NeRF (SpikingNeRF), which aligns the radiance ray with the temporal dimension of SNN, to naturally accommodate the SNN to the reconstruction of Radiance Fields. Thus, the computation turns into a spike-based, multiplication-free manner, reducing the energy consumption. In SpikingNeRF, each sampled point on the ray is matched onto a particular time step, and represented in a hybrid manner where the voxel grids are maintained as well. Based on the voxel grids, sampled points are determined whether to be masked for better training and inference. However, this operation also incurs irregular temporal length. We propose the temporal condensing-and-padding (TCP) strategy to tackle the masked samples to maintain regular temporal length, i.e., regular tensors, for hardware-friendly computation. Extensive experiments on a variety of datasets demonstrate that our method reduces the $76.74\%$ energy consumption on average and obtains comparable synthesis quality with the ANN baseline.
Fast and Regret Optimal Best Arm Identification: Fundamental Limits and Low-Complexity Algorithms
Sep 01, 2023This paper considers a stochastic multi-armed bandit (MAB) problem with dual objectives: (i) quick identification and commitment to the optimal arm, and (ii) reward maximization throughout a sequence of $T$ consecutive rounds. Though each objective has been individually well-studied, i.e., best arm identification for (i) and regret minimization for (ii), the simultaneous realization of both objectives remains an open problem, despite its practical importance. This paper introduces \emph{Regret Optimal Best Arm Identification} (ROBAI) which aims to achieve these dual objectives. To solve ROBAI with both pre-determined stopping time and adaptive stopping time requirements, we present the $\mathsf{EOCP}$ algorithm and its variants respectively, which not only achieve asymptotic optimal regret in both Gaussian and general bandits, but also commit to the optimal arm in $\mathcal{O}(\log T)$ rounds with pre-determined stopping time and $\mathcal{O}(\log^2 T)$ rounds with adaptive stopping time. We further characterize lower bounds on the commitment time (equivalent to sample complexity) of ROBAI, showing that $\mathsf{EOCP}$ and its variants are sample optimal with pre-determined stopping time, and almost sample optimal with adaptive stopping time. Numerical results confirm our theoretical analysis and reveal an interesting ``over-exploration'' phenomenon carried by classic $\mathsf{UCB}$ algorithms, such that $\mathsf{EOCP}$ has smaller regret even though it stops exploration much earlier than $\mathsf{UCB}$ ($\mathcal{O}(\log T)$ versus $\mathcal{O}(T)$), which suggests over-exploration is unnecessary and potentially harmful to system performance.
MPR-Net:Multi-Scale Pattern Reproduction Guided Universality Time Series Interpretable Forecasting
Jul 13, 2023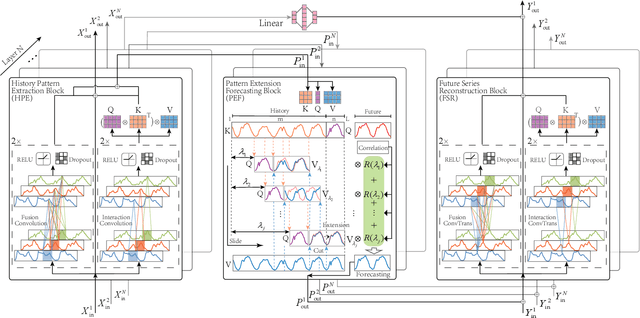
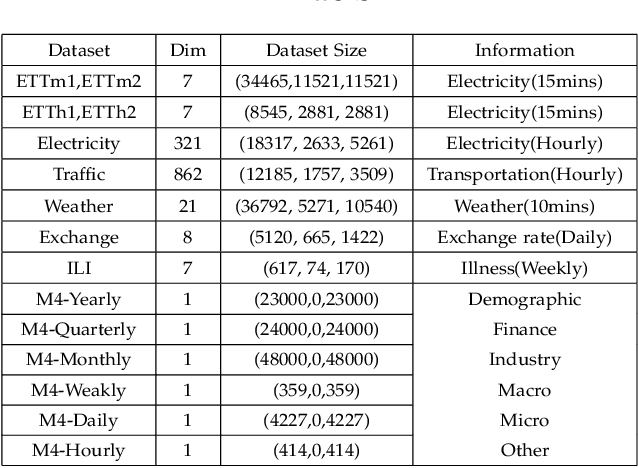
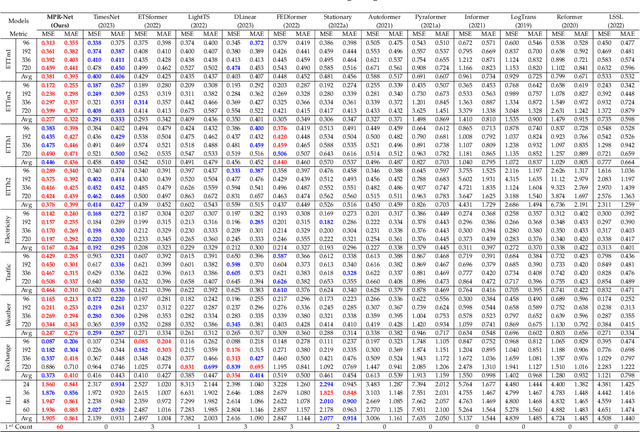
Time series forecasting has received wide interest from existing research due to its broad applications and inherent challenging. The research challenge lies in identifying effective patterns in historical series and applying them to future forecasting. Advanced models based on point-wise connected MLP and Transformer architectures have strong fitting power, but their secondary computational complexity limits practicality. Additionally, those structures inherently disrupt the temporal order, reducing the information utilization and making the forecasting process uninterpretable. To solve these problems, this paper proposes a forecasting model, MPR-Net. It first adaptively decomposes multi-scale historical series patterns using convolution operation, then constructs a pattern extension forecasting method based on the prior knowledge of pattern reproduction, and finally reconstructs future patterns into future series using deconvolution operation. By leveraging the temporal dependencies present in the time series, MPR-Net not only achieves linear time complexity, but also makes the forecasting process interpretable. By carrying out sufficient experiments on more than ten real data sets of both short and long term forecasting tasks, MPR-Net achieves the state of the art forecasting performance, as well as good generalization and robustness performance.
Fast and Resource-Efficient Object Tracking on Edge Devices: A Measurement Study
Sep 06, 2023

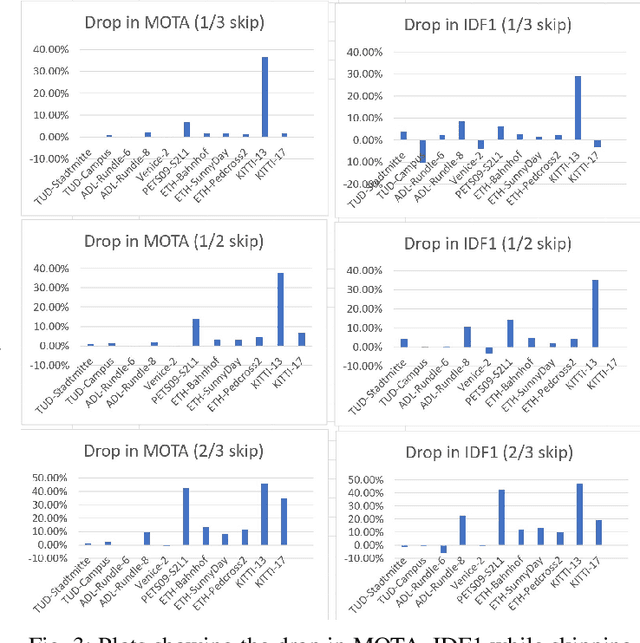
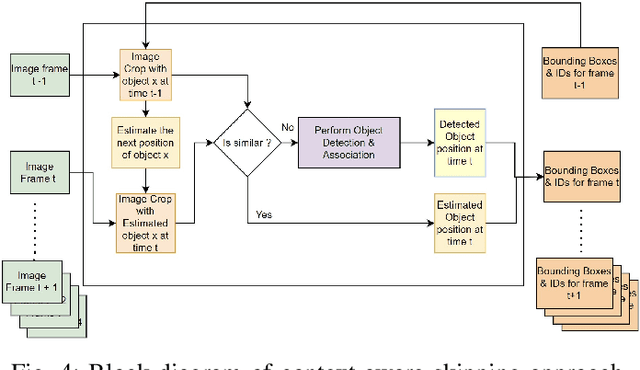
Object tracking is an important functionality of edge video analytic systems and services. Multi-object tracking (MOT) detects the moving objects and tracks their locations frame by frame as real scenes are being captured into a video. However, it is well known that real time object tracking on the edge poses critical technical challenges, especially with edge devices of heterogeneous computing resources. This paper examines the performance issues and edge-specific optimization opportunities for object tracking. We will show that even the well trained and optimized MOT model may still suffer from random frame dropping problems when edge devices have insufficient computation resources. We present several edge specific performance optimization strategies, collectively coined as EMO, to speed up the real time object tracking, ranging from window-based optimization to similarity based optimization. Extensive experiments on popular MOT benchmarks demonstrate that our EMO approach is competitive with respect to the representative methods for on-device object tracking techniques in terms of run-time performance and tracking accuracy. EMO is released on Github at https://github.com/git-disl/EMO.
Generative AI-Driven Storytelling: A New Era for Marketing
Sep 16, 2023This paper delves into the transformative power of Generative AI-driven storytelling in the realm of marketing. Generative AI, distinct from traditional machine learning, offers the capability to craft narratives that resonate with consumers on a deeply personal level. Through real-world examples from industry leaders like Google, Netflix and Stitch Fix, we elucidate how this technology shapes marketing strategies, personalizes consumer experiences, and navigates the challenges it presents. The paper also explores future directions and recommendations for generative AI-driven storytelling, including prospective applications such as real-time personalized storytelling, immersive storytelling experiences, and social media storytelling. By shedding light on the potential and impact of generative AI-driven storytelling in marketing, this paper contributes to the understanding of this cutting-edge approach and its transformative power in the field of marketing.
RMP: A Random Mask Pretrain Framework for Motion Prediction
Sep 16, 2023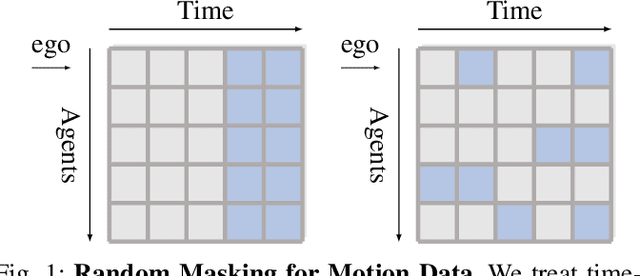
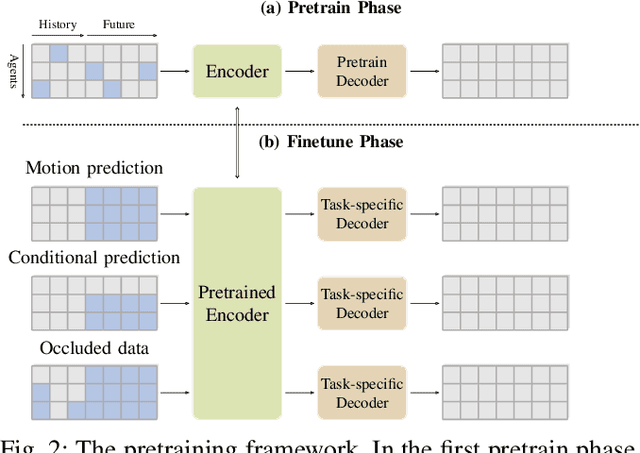
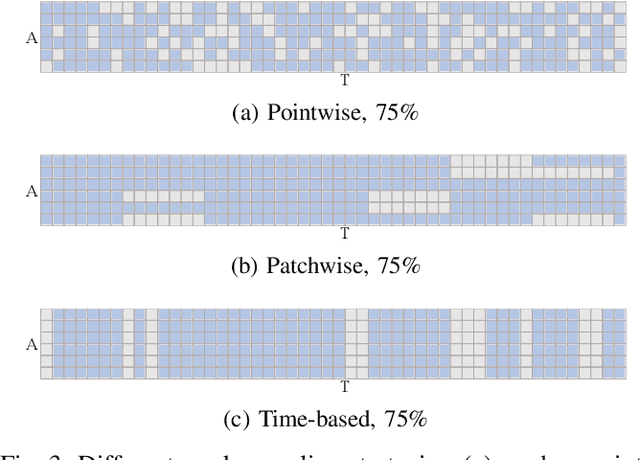
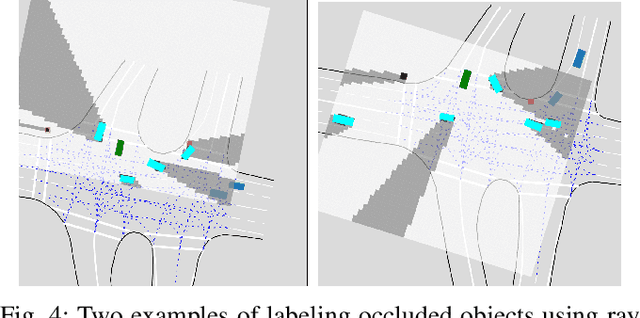
As the pretraining technique is growing in popularity, little work has been done on pretrained learning-based motion prediction methods in autonomous driving. In this paper, we propose a framework to formalize the pretraining task for trajectory prediction of traffic participants. Within our framework, inspired by the random masked model in natural language processing (NLP) and computer vision (CV), objects' positions at random timesteps are masked and then filled in by the learned neural network (NN). By changing the mask profile, our framework can easily switch among a range of motion-related tasks. We show that our proposed pretraining framework is able to deal with noisy inputs and improves the motion prediction accuracy and miss rate, especially for objects occluded over time by evaluating it on Argoverse and NuScenes datasets.
Quantitative Analysis of Forecasting Models:In the Aspect of Online Political Bias
Sep 11, 2023Understanding and mitigating political bias in online social media platforms are crucial tasks to combat misinformation and echo chamber effects. However, characterizing political bias temporally using computational methods presents challenges due to the high frequency of noise in social media datasets. While existing research has explored various approaches to political bias characterization, the ability to forecast political bias and anticipate how political conversations might evolve in the near future has not been extensively studied. In this paper, we propose a heuristic approach to classify social media posts into five distinct political leaning categories. Since there is a lack of prior work on forecasting political bias, we conduct an in-depth analysis of existing baseline models to identify which model best fits to forecast political leaning time series. Our approach involves utilizing existing time series forecasting models on two social media datasets with different political ideologies, specifically Twitter and Gab. Through our experiments and analyses, we seek to shed light on the challenges and opportunities in forecasting political bias in social media platforms. Ultimately, our work aims to pave the way for developing more effective strategies to mitigate the negative impact of political bias in the digital realm.
Computing SHAP Efficiently Using Model Structure Information
Sep 05, 2023
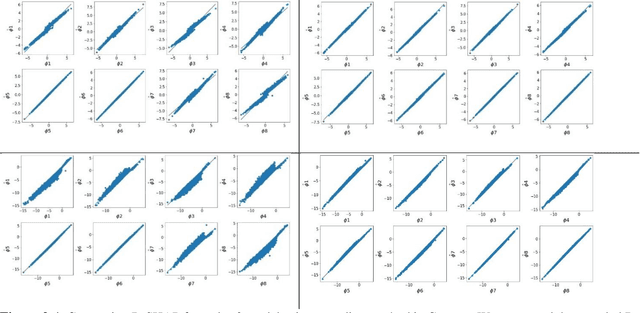
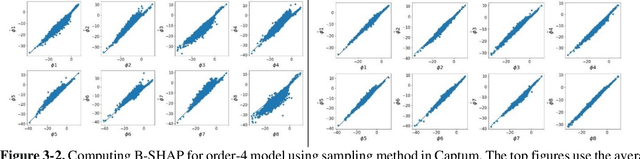
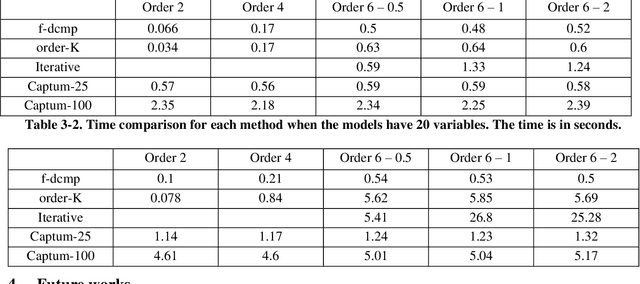
SHAP (SHapley Additive exPlanations) has become a popular method to attribute the prediction of a machine learning model on an input to its features. One main challenge of SHAP is the computation time. An exact computation of Shapley values requires exponential time complexity. Therefore, many approximation methods are proposed in the literature. In this paper, we propose methods that can compute SHAP exactly in polynomial time or even faster for SHAP definitions that satisfy our additivity and dummy assumptions (eg, kernal SHAP and baseline SHAP). We develop different strategies for models with different levels of model structure information: known functional decomposition, known order of model (defined as highest order of interaction in the model), or unknown order. For the first case, we demonstrate an additive property and a way to compute SHAP from the lower-order functional components. For the second case, we derive formulas that can compute SHAP in polynomial time. Both methods yield exact SHAP results. Finally, if even the order of model is unknown, we propose an iterative way to approximate Shapley values. The three methods we propose are computationally efficient when the order of model is not high which is typically the case in practice. We compare with sampling approach proposed in Castor & Gomez (2008) using simulation studies to demonstrate the efficacy of our proposed methods.