 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
mdendro: An R package for extended agglomerative hierarchical clustering
Sep 23, 2023
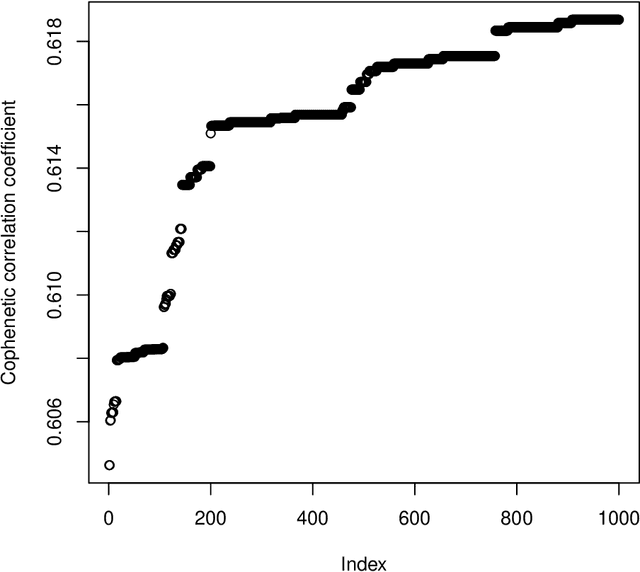

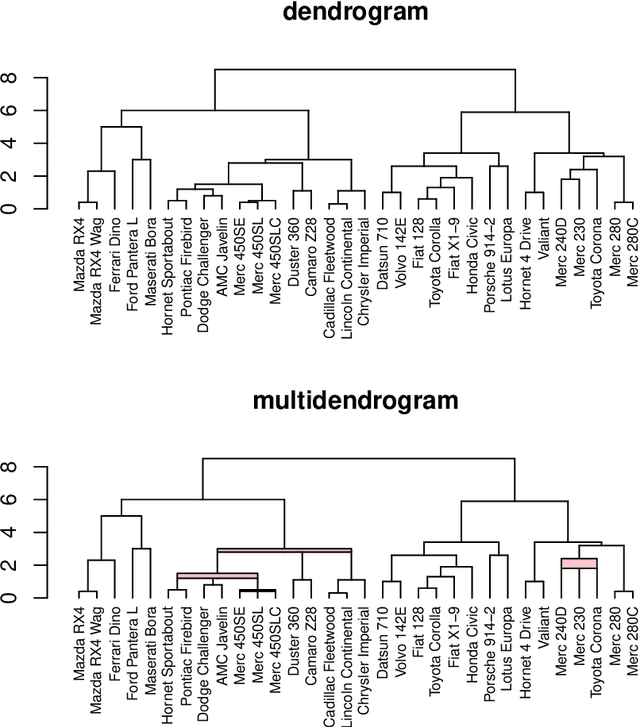

"mdendro" is an R package that provides a comprehensive collection of linkage methods for agglomerative hierarchical clustering on a matrix of proximity data (distances or similarities), returning a multifurcated dendrogram or multidendrogram. Multidendrograms can group more than two clusters at the same time, solving the nonuniqueness problem that arises when there are ties in the data. This problem causes that different binary dendrograms are possible depending both on the order of the input data and on the criterion used to break ties. Weighted and unweighted versions of the most common linkage methods are included in the package, which also implements two parametric linkage methods. In addition, package "mdendro" provides five descriptive measures to analyze the resulting dendrograms: cophenetic correlation coefficient, space distortion ratio, agglomerative coefficient, chaining coefficient and tree balance.
Unlabeled Out-Of-Domain Data Improves Generalization
Sep 29, 2023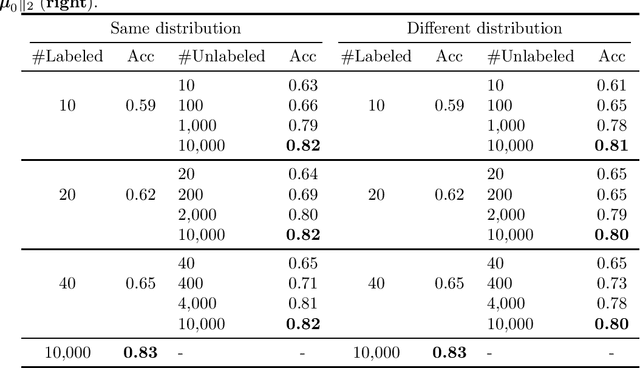
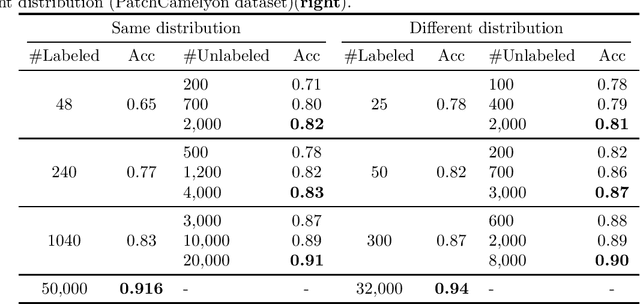

We propose a novel framework for incorporating unlabeled data into semi-supervised classification problems, where scenarios involving the minimization of either i) adversarially robust or ii) non-robust loss functions have been considered. Notably, we allow the unlabeled samples to deviate slightly (in total variation sense) from the in-domain distribution. The core idea behind our framework is to combine Distributionally Robust Optimization (DRO) with self-supervised training. As a result, we also leverage efficient polynomial-time algorithms for the training stage. From a theoretical standpoint, we apply our framework on the classification problem of a mixture of two Gaussians in $\mathbb{R}^d$, where in addition to the $m$ independent and labeled samples from the true distribution, a set of $n$ (usually with $n\gg m$) out of domain and unlabeled samples are gievn as well. Using only the labeled data, it is known that the generalization error can be bounded by $\propto\left(d/m\right)^{1/2}$. However, using our method on both isotropic and non-isotropic Gaussian mixture models, one can derive a new set of analytically explicit and non-asymptotic bounds which show substantial improvement on the generalization error compared ERM. Our results underscore two significant insights: 1) out-of-domain samples, even when unlabeled, can be harnessed to narrow the generalization gap, provided that the true data distribution adheres to a form of the "cluster assumption", and 2) the semi-supervised learning paradigm can be regarded as a special case of our framework when there are no distributional shifts. We validate our claims through experiments conducted on a variety of synthetic and real-world datasets.
Towards Flexible Time-to-event Modeling: Optimizing Neural Networks via Rank Regression
Jul 16, 2023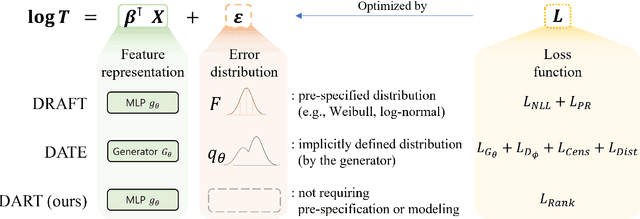


Time-to-event analysis, also known as survival analysis, aims to predict the time of occurrence of an event, given a set of features. One of the major challenges in this area is dealing with censored data, which can make learning algorithms more complex. Traditional methods such as Cox's proportional hazards model and the accelerated failure time (AFT) model have been popular in this field, but they often require assumptions such as proportional hazards and linearity. In particular, the AFT models often require pre-specified parametric distributional assumptions. To improve predictive performance and alleviate strict assumptions, there have been many deep learning approaches for hazard-based models in recent years. However, representation learning for AFT has not been widely explored in the neural network literature, despite its simplicity and interpretability in comparison to hazard-focused methods. In this work, we introduce the Deep AFT Rank-regression model for Time-to-event prediction (DART). This model uses an objective function based on Gehan's rank statistic, which is efficient and reliable for representation learning. On top of eliminating the requirement to establish a baseline event time distribution, DART retains the advantages of directly predicting event time in standard AFT models. The proposed method is a semiparametric approach to AFT modeling that does not impose any distributional assumptions on the survival time distribution. This also eliminates the need for additional hyperparameters or complex model architectures, unlike existing neural network-based AFT models. Through quantitative analysis on various benchmark datasets, we have shown that DART has significant potential for modeling high-throughput censored time-to-event data.
Test-Time Training on Video Streams
Jul 12, 2023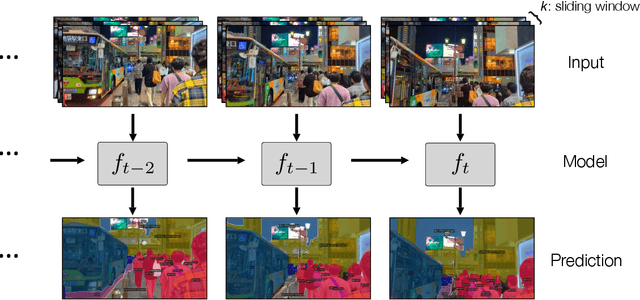
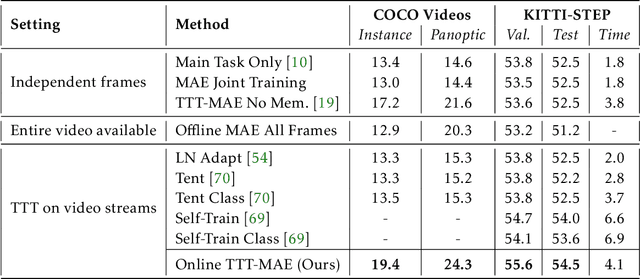
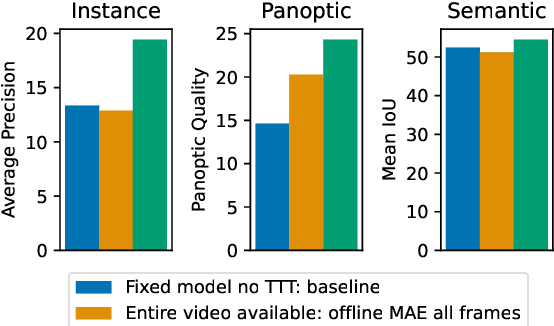
Prior work has established test-time training (TTT) as a general framework to further improve a trained model at test time. Before making a prediction on each test instance, the model is trained on the same instance using a self-supervised task, such as image reconstruction with masked autoencoders. We extend TTT to the streaming setting, where multiple test instances - video frames in our case - arrive in temporal order. Our extension is online TTT: The current model is initialized from the previous model, then trained on the current frame and a small window of frames immediately before. Online TTT significantly outperforms the fixed-model baseline for four tasks, on three real-world datasets. The relative improvement is 45% and 66% for instance and panoptic segmentation. Surprisingly, online TTT also outperforms its offline variant that accesses more information, training on all frames from the entire test video regardless of temporal order. This differs from previous findings using synthetic videos. We conceptualize locality as the advantage of online over offline TTT. We analyze the role of locality with ablations and a theory based on bias-variance trade-off.
AnyPose: Anytime 3D Human Pose Forecasting via Neural Ordinary Differential Equations
Sep 09, 2023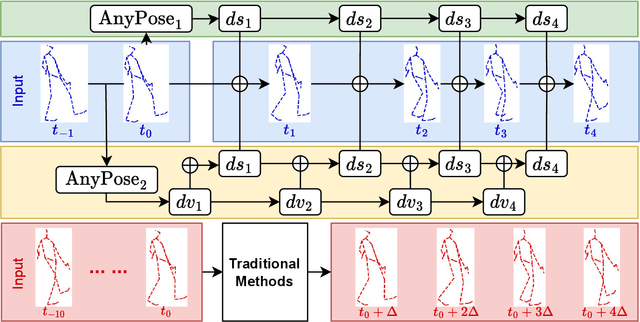
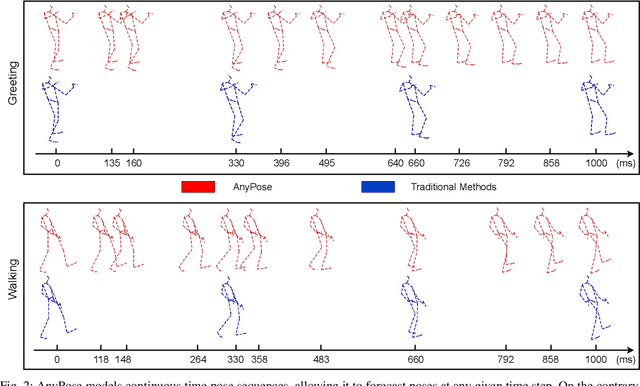
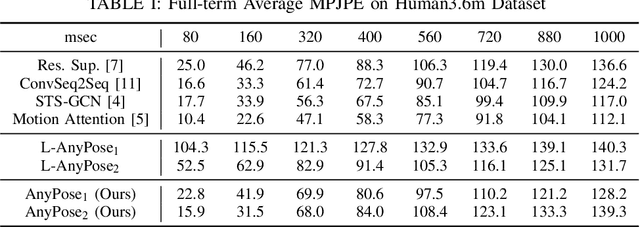
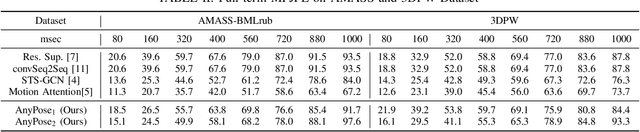
Anytime 3D human pose forecasting is crucial to synchronous real-world human-machine interaction, where the term ``anytime" corresponds to predicting human pose at any real-valued time step. However, to the best of our knowledge, all the existing methods in human pose forecasting perform predictions at preset, discrete time intervals. Therefore, we introduce AnyPose, a lightweight continuous-time neural architecture that models human behavior dynamics with neural ordinary differential equations. We validate our framework on the Human3.6M, AMASS, and 3DPW dataset and conduct a series of comprehensive analyses towards comparison with existing methods and the intersection of human pose and neural ordinary differential equations. Our results demonstrate that AnyPose exhibits high-performance accuracy in predicting future poses and takes significantly lower computational time than traditional methods in solving anytime prediction tasks.
Autoencoder-based Anomaly Detection System for Online Data Quality Monitoring of the CMS Electromagnetic Calorimeter
Sep 18, 2023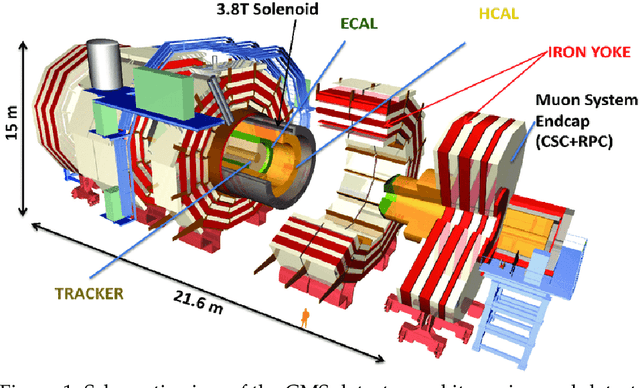
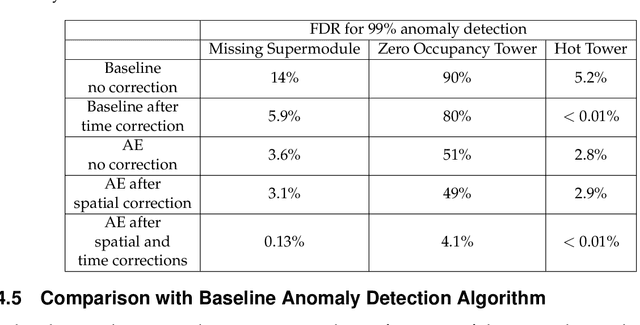
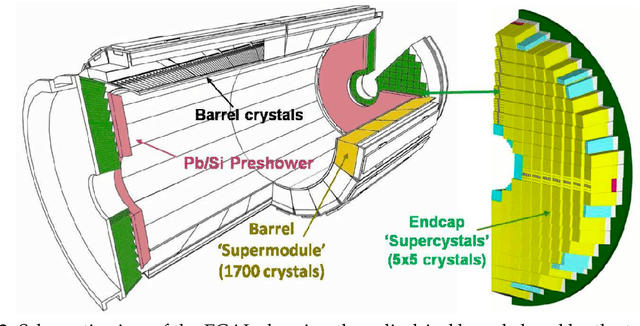
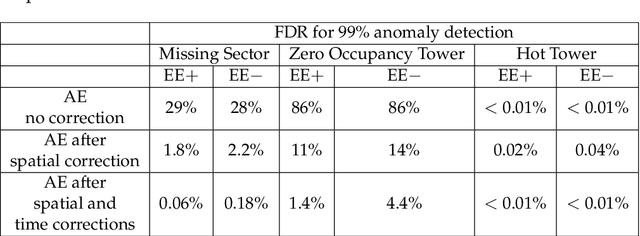
The CMS detector is a general-purpose apparatus that detects high-energy collisions produced at the LHC. Online Data Quality Monitoring of the CMS electromagnetic calorimeter is a vital operational tool that allows detector experts to quickly identify, localize, and diagnose a broad range of detector issues that could affect the quality of physics data. A real-time autoencoder-based anomaly detection system using semi-supervised machine learning is presented enabling the detection of anomalies in the CMS electromagnetic calorimeter data. A novel method is introduced which maximizes the anomaly detection performance by exploiting the time-dependent evolution of anomalies as well as spatial variations in the detector response. The autoencoder-based system is able to efficiently detect anomalies, while maintaining a very low false discovery rate. The performance of the system is validated with anomalies found in 2018 and 2022 LHC collision data. Additionally, the first results from deploying the autoencoder-based system in the CMS online Data Quality Monitoring workflow during the beginning of Run 3 of the LHC are presented, showing its ability to detect issues missed by the existing system.
RAI4IoE: Responsible AI for Enabling the Internet of Energy
Sep 20, 2023This paper plans to develop an Equitable and Responsible AI framework with enabling techniques and algorithms for the Internet of Energy (IoE), in short, RAI4IoE. The energy sector is going through substantial changes fueled by two key drivers: building a zero-carbon energy sector and the digital transformation of the energy infrastructure. We expect to see the convergence of these two drivers resulting in the IoE, where renewable distributed energy resources (DERs), such as electric cars, storage batteries, wind turbines and photovoltaics (PV), can be connected and integrated for reliable energy distribution by leveraging advanced 5G-6G networks and AI technology. This allows DER owners as prosumers to participate in the energy market and derive economic incentives. DERs are inherently asset-driven and face equitable challenges (i.e., fair, diverse and inclusive). Without equitable access, privileged individuals, groups and organizations can participate and benefit at the cost of disadvantaged groups. The real-time management of DER resources not only brings out the equity problem to the IoE, it also collects highly sensitive location, time, activity dependent data, which requires to be handled responsibly (e.g., privacy, security and safety), for AI-enhanced predictions, optimization and prioritization services, and automated management of flexible resources. The vision of our project is to ensure equitable participation of the community members and responsible use of their data in IoE so that it could reap the benefits of advances in AI to provide safe, reliable and sustainable energy services.
Active Inference for Sum Rate Maximization in UAV-Assisted Cognitive NOMA Networks
Sep 20, 2023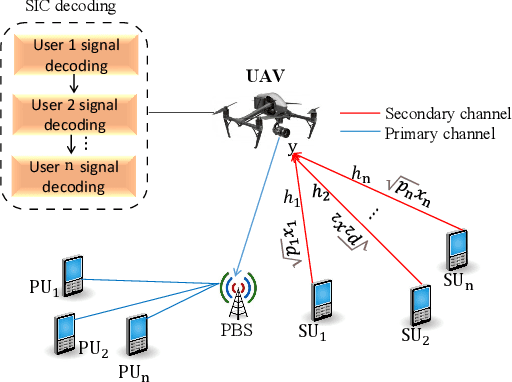
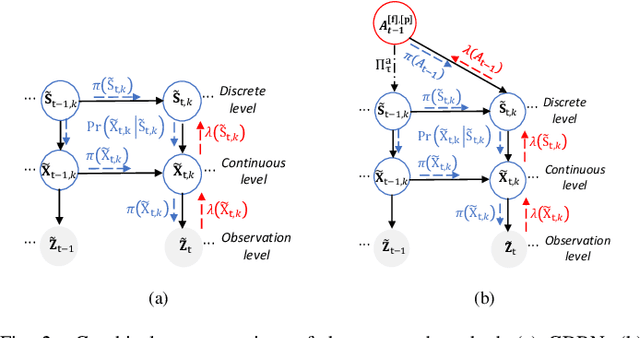
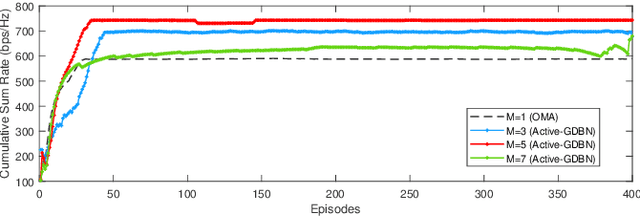
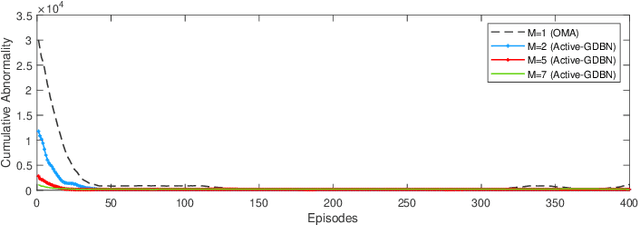
Given the surge in wireless data traffic driven by the emerging Internet of Things (IoT), unmanned aerial vehicles (UAVs), cognitive radio (CR), and non-orthogonal multiple access (NOMA) have been recognized as promising techniques to overcome massive connectivity issues. As a result, there is an increasing need to intelligently improve the channel capacity of future wireless networks. Motivated by active inference from cognitive neuroscience, this paper investigates joint subchannel and power allocation for an uplink UAV-assisted cognitive NOMA network. Maximizing the sum rate is often a highly challenging optimization problem due to dynamic network conditions and power constraints. To address this challenge, we propose an active inference-based algorithm. We transform the sum rate maximization problem into abnormality minimization by utilizing a generalized state-space model to characterize the time-changing network environment. The problem is then solved using an Active Generalized Dynamic Bayesian Network (Active-GDBN). The proposed framework consists of an offline perception stage, in which a UAV employs a hierarchical GDBN structure to learn an optimal generative model of discrete subchannels and continuous power allocation. In the online active inference stage, the UAV dynamically selects discrete subchannels and continuous power to maximize the sum rate of secondary users. By leveraging the errors in each episode, the UAV can adapt its resource allocation policies and belief updating to improve its performance over time. Simulation results demonstrate the effectiveness of our proposed algorithm in terms of cumulative sum rate compared to benchmark schemes.
PDRL: Multi-Agent based Reinforcement Learning for Predictive Monitoring
Sep 20, 2023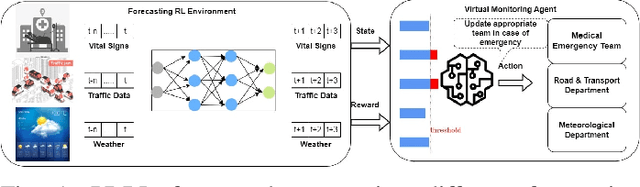
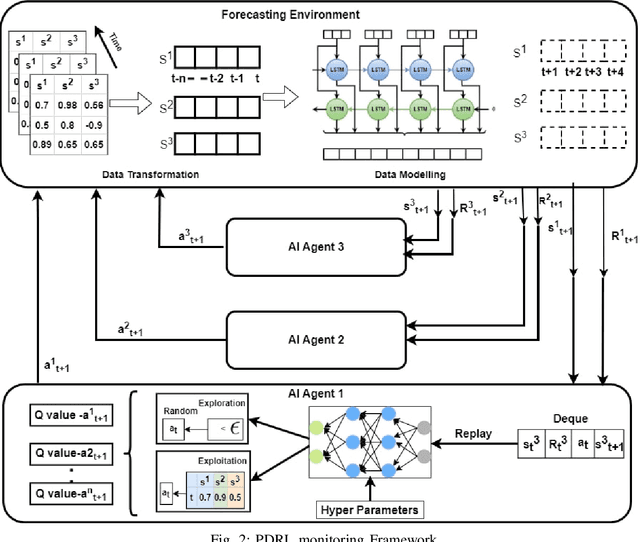
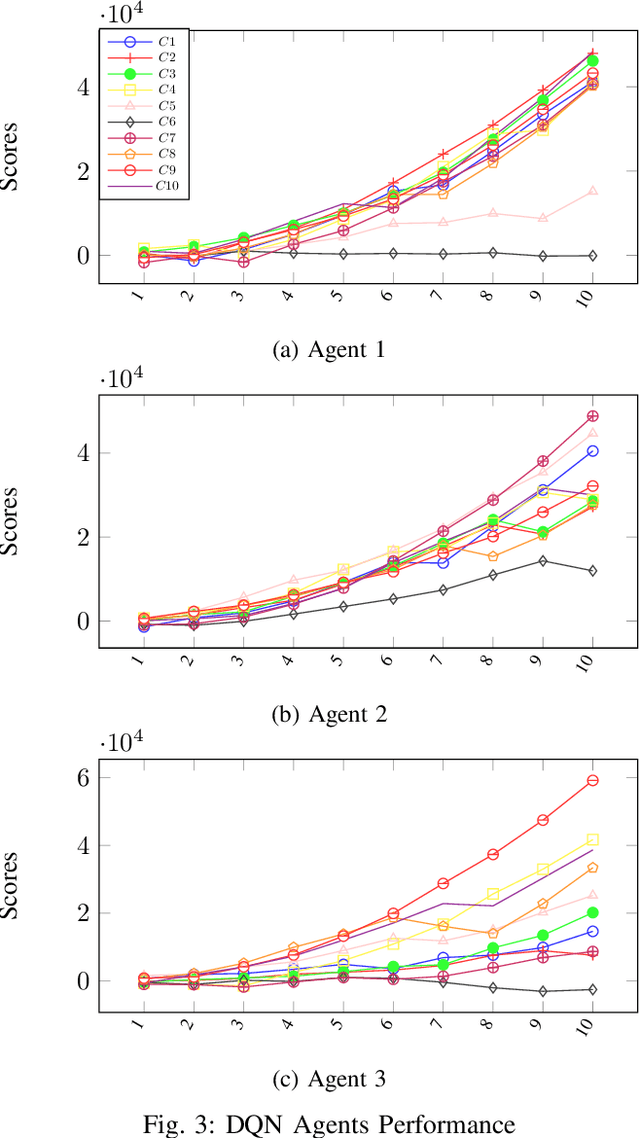
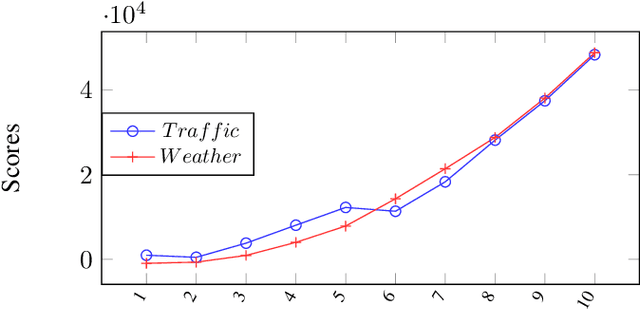
Reinforcement learning has been increasingly applied in monitoring applications because of its ability to learn from previous experiences and can make adaptive decisions. However, existing machine learning-based health monitoring applications are mostly supervised learning algorithms, trained on labels and they cannot make adaptive decisions in an uncertain complex environment. This study proposes a novel and generic system, predictive deep reinforcement learning (PDRL) with multiple RL agents in a time series forecasting environment. The proposed generic framework accommodates virtual Deep Q Network (DQN) agents to monitor predicted future states of a complex environment with a well-defined reward policy so that the agent learns existing knowledge while maximizing their rewards. In the evaluation process of the proposed framework, three DRL agents were deployed to monitor a subject's future heart rate, respiration, and temperature predicted using a BiLSTM model. With each iteration, the three agents were able to learn the associated patterns and their cumulative rewards gradually increased. It outperformed the baseline models for all three monitoring agents. The proposed PDRL framework is able to achieve state-of-the-art performance in the time series forecasting process. The proposed DRL agents and deep learning model in the PDRL framework are customized to implement the transfer learning in other forecasting applications like traffic and weather and monitor their states. The PDRL framework is able to learn the future states of the traffic and weather forecasting and the cumulative rewards are gradually increasing over each episode.
TensorCodec: Compact Lossy Compression of Tensors without Strong Data Assumptions
Sep 20, 2023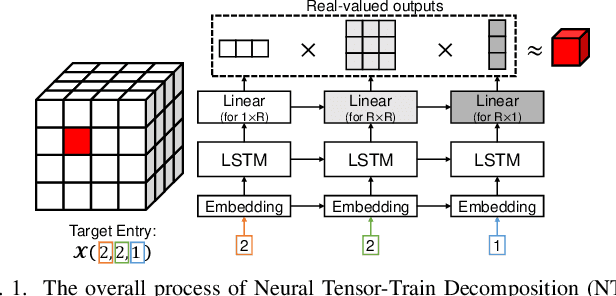
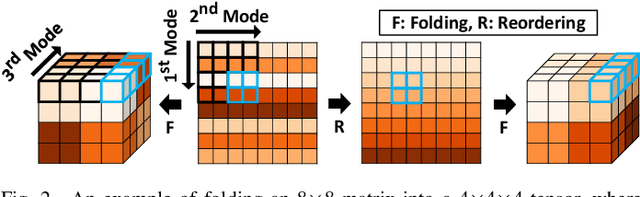
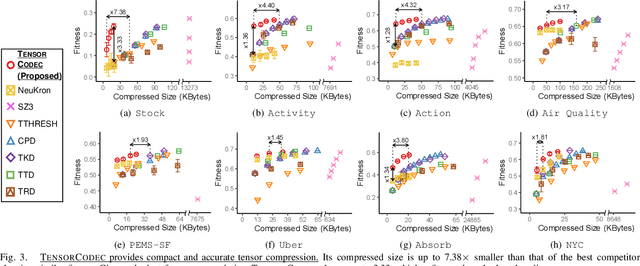
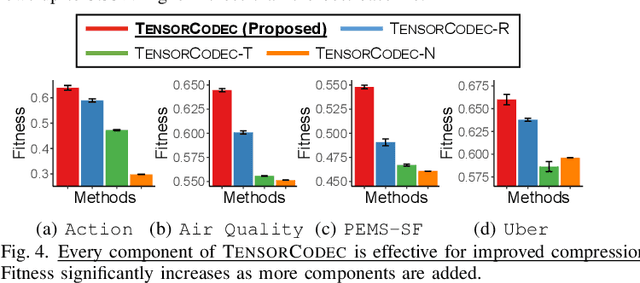
Many real-world datasets are represented as tensors, i.e., multi-dimensional arrays of numerical values. Storing them without compression often requires substantial space, which grows exponentially with the order. While many tensor compression algorithms are available, many of them rely on strong data assumptions regarding its order, sparsity, rank, and smoothness. In this work, we propose TENSORCODEC, a lossy compression algorithm for general tensors that do not necessarily adhere to strong input data assumptions. TENSORCODEC incorporates three key ideas. The first idea is Neural Tensor-Train Decomposition (NTTD) where we integrate a recurrent neural network into Tensor-Train Decomposition to enhance its expressive power and alleviate the limitations imposed by the low-rank assumption. Another idea is to fold the input tensor into a higher-order tensor to reduce the space required by NTTD. Finally, the mode indices of the input tensor are reordered to reveal patterns that can be exploited by NTTD for improved approximation. Our analysis and experiments on 8 real-world datasets demonstrate that TENSORCODEC is (a) Concise: it gives up to 7.38x more compact compression than the best competitor with similar reconstruction error, (b) Accurate: given the same budget for compressed size, it yields up to 3.33x more accurate reconstruction than the best competitor, (c) Scalable: its empirical compression time is linear in the number of tensor entries, and it reconstructs each entry in logarithmic time. Our code and datasets are available at https://github.com/kbrother/TensorCodec.