 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
PROSE: Predicting Operators and Symbolic Expressions using Multimodal Transformers
Sep 28, 2023
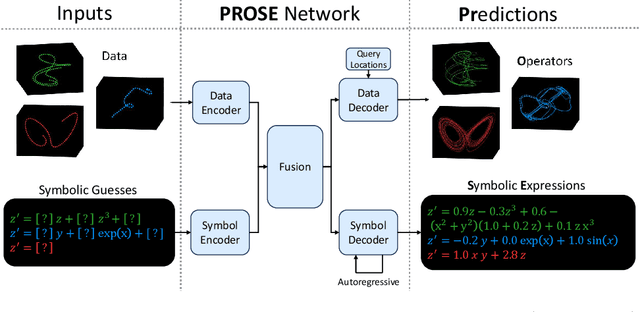
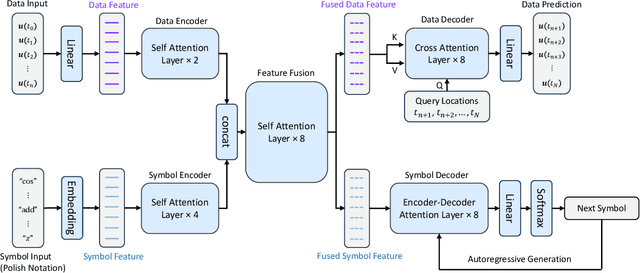

Approximating nonlinear differential equations using a neural network provides a robust and efficient tool for various scientific computing tasks, including real-time predictions, inverse problems, optimal controls, and surrogate modeling. Previous works have focused on embedding dynamical systems into networks through two approaches: learning a single solution operator (i.e., the mapping from input parametrized functions to solutions) or learning the governing system of equations (i.e., the constitutive model relative to the state variables). Both of these approaches yield different representations for the same underlying data or function. Additionally, observing that families of differential equations often share key characteristics, we seek one network representation across a wide range of equations. Our method, called Predicting Operators and Symbolic Expressions (PROSE), learns maps from multimodal inputs to multimodal outputs, capable of generating both numerical predictions and mathematical equations. By using a transformer structure and a feature fusion approach, our network can simultaneously embed sets of solution operators for various parametric differential equations using a single trained network. Detailed experiments demonstrate that the network benefits from its multimodal nature, resulting in improved prediction accuracy and better generalization. The network is shown to be able to handle noise in the data and errors in the symbolic representation, including noisy numerical values, model misspecification, and erroneous addition or deletion of terms. PROSE provides a new neural network framework for differential equations which allows for more flexibility and generality in learning operators and governing equations from data.
Diverse and Aligned Audio-to-Video Generation via Text-to-Video Model Adaptation
Sep 28, 2023We consider the task of generating diverse and realistic videos guided by natural audio samples from a wide variety of semantic classes. For this task, the videos are required to be aligned both globally and temporally with the input audio: globally, the input audio is semantically associated with the entire output video, and temporally, each segment of the input audio is associated with a corresponding segment of that video. We utilize an existing text-conditioned video generation model and a pre-trained audio encoder model. The proposed method is based on a lightweight adaptor network, which learns to map the audio-based representation to the input representation expected by the text-to-video generation model. As such, it also enables video generation conditioned on text, audio, and, for the first time as far as we can ascertain, on both text and audio. We validate our method extensively on three datasets demonstrating significant semantic diversity of audio-video samples and further propose a novel evaluation metric (AV-Align) to assess the alignment of generated videos with input audio samples. AV-Align is based on the detection and comparison of energy peaks in both modalities. In comparison to recent state-of-the-art approaches, our method generates videos that are better aligned with the input sound, both with respect to content and temporal axis. We also show that videos produced by our method present higher visual quality and are more diverse.
DPA-WNO: A gray box model for a class of stochastic mechanics problem
Sep 28, 2023The well-known governing physics in science and engineering is often based on certain assumptions and approximations. Therefore, analyses and designs carried out based on these equations are also approximate. The emergence of data-driven models has, to a certain degree, addressed this challenge; however, the purely data-driven models often (a) lack interpretability, (b) are data-hungry, and (c) do not generalize beyond the training window. Operator learning has recently been proposed as a potential alternative to address the aforementioned challenges; however, the challenges are still persistent. We here argue that one of the possible solutions resides in data-physics fusion, where the data-driven model is used to correct/identify the missing physics. To that end, we propose a novel Differentiable Physics Augmented Wavelet Neural Operator (DPA-WNO). The proposed DPA-WNO blends a differentiable physics solver with the Wavelet Neural Operator (WNO), where the role of WNO is to model the missing physics. This empowers the proposed framework to exploit the capability of WNO to learn from data while retaining the interpretability and generalizability associated with physics-based solvers. We illustrate the applicability of the proposed approach in solving time-dependent uncertainty quantification problems due to randomness in the initial condition. Four benchmark uncertainty quantification and reliability analysis examples from various fields of science and engineering are solved using the proposed approach. The results presented illustrate interesting features of the proposed approach.
Stochastic Digital Twin for Copy Detection Patterns
Sep 28, 2023Copy detection patterns (CDP) present an efficient technique for product protection against counterfeiting. However, the complexity of studying CDP production variability often results in time-consuming and costly procedures, limiting CDP scalability. Recent advancements in computer modelling, notably the concept of a "digital twin" for printing-imaging channels, allow for enhanced scalability and the optimization of authentication systems. Yet, the development of an accurate digital twin is far from trivial. This paper extends previous research which modelled a printing-imaging channel using a machine learning-based digital twin for CDP. This model, built upon an information-theoretic framework known as "Turbo", demonstrated superior performance over traditional generative models such as CycleGAN and pix2pix. However, the emerging field of Denoising Diffusion Probabilistic Models (DDPM) presents a potential advancement in generative models due to its ability to stochastically model the inherent randomness of the printing-imaging process, and its impressive performance in image-to-image translation tasks. This study aims at comparing the capabilities of the Turbo framework and DDPM on the same CDP datasets, with the goal of establishing the real-world benefits of DDPM models for digital twin applications in CDP security. Furthermore, the paper seeks to evaluate the generative potential of the studied models in the context of mobile phone data acquisition. Despite the increased complexity of DDPM methods when compared to traditional approaches, our study highlights their advantages and explores their potential for future applications.
Channel Vision Transformers: An Image Is Worth C x 16 x 16 Words
Sep 28, 2023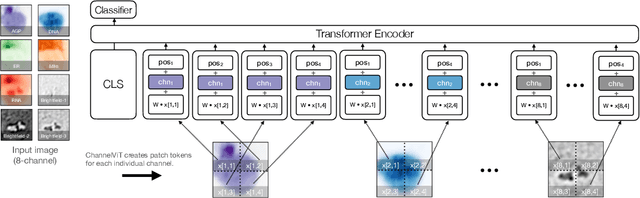
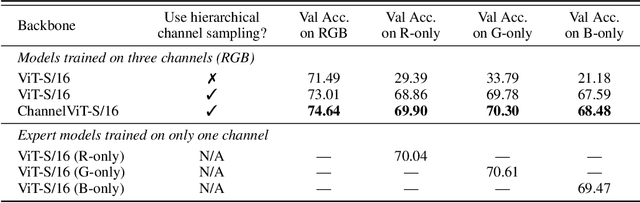
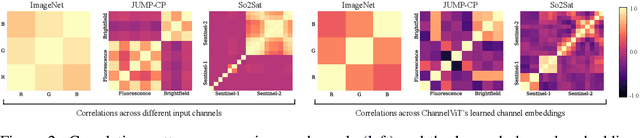
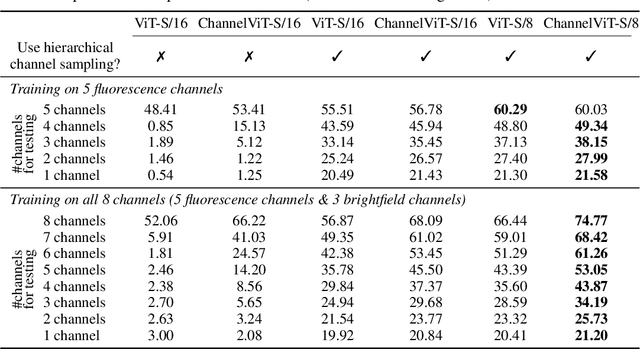
Vision Transformer (ViT) has emerged as a powerful architecture in the realm of modern computer vision. However, its application in certain imaging fields, such as microscopy and satellite imaging, presents unique challenges. In these domains, images often contain multiple channels, each carrying semantically distinct and independent information. Furthermore, the model must demonstrate robustness to sparsity in input channels, as they may not be densely available during training or testing. In this paper, we propose a modification to the ViT architecture that enhances reasoning across the input channels and introduce Hierarchical Channel Sampling (HCS) as an additional regularization technique to ensure robustness when only partial channels are presented during test time. Our proposed model, ChannelViT, constructs patch tokens independently from each input channel and utilizes a learnable channel embedding that is added to the patch tokens, similar to positional embeddings. We evaluate the performance of ChannelViT on ImageNet, JUMP-CP (microscopy cell imaging), and So2Sat (satellite imaging). Our results show that ChannelViT outperforms ViT on classification tasks and generalizes well, even when a subset of input channels is used during testing. Across our experiments, HCS proves to be a powerful regularizer, independent of the architecture employed, suggesting itself as a straightforward technique for robust ViT training. Lastly, we find that ChannelViT generalizes effectively even when there is limited access to all channels during training, highlighting its potential for multi-channel imaging under real-world conditions with sparse sensors.
Non-Uniform Sampling Reconstruction for Symmetrical NMR Spectroscopy by Exploiting Inherent Symmetry
Sep 24, 2023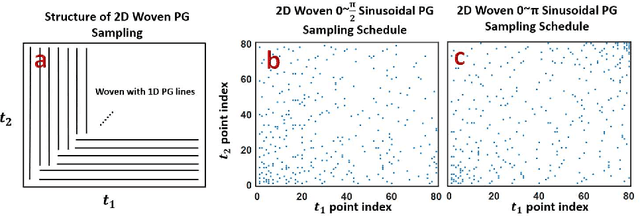
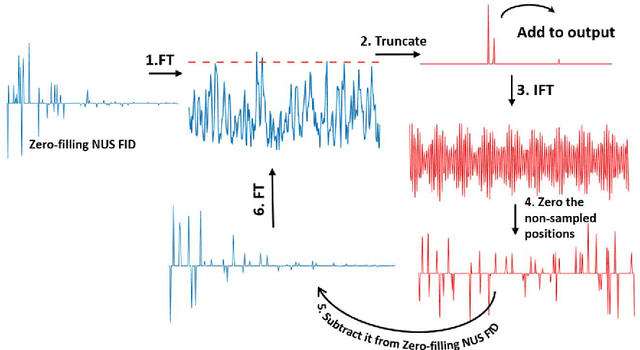
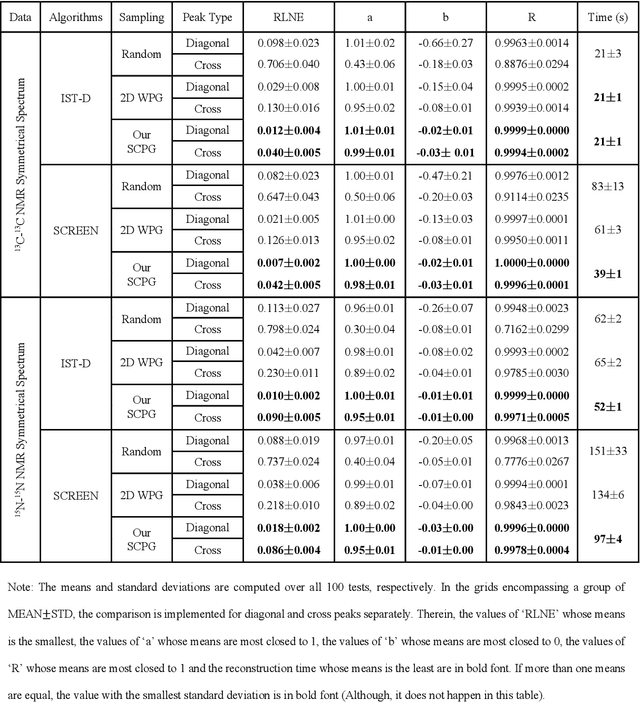
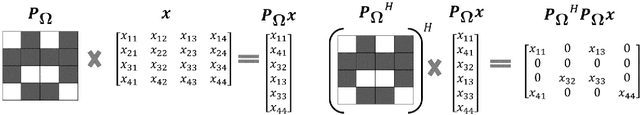
Symmetrical NMR spectroscopy constitutes a vital branch of multidimensional NMR spectroscopy, providing a powerful tool for the structural elucidation of biological macromolecules. Non-Uniform Sampling (NUS) serves as an effective strategy for averting the prohibitive acquisition time of multidimensional NMR spectroscopy by only sampling a few points according to NUS sampling schedules and reconstructing missing points via algorithms. However, current sampling schedules are unable to maintain the accurate recovery of cross peaks that are weak but important. In this work, we propose a novel sampling schedule termed as SCPG (Symmetrical Copy Poisson Gap) and employ CS (Compressed Sensing) methods for reconstruction. We theoretically prove that the symmetrical constraint, apart from sparsity, is implicitly implemented when SCPG is combined with CS methods. The simulated and experimental data substantiate the advantage of SCPG over state-of-the-art 2D Woven PG in the NUS reconstruction of symmetrical NMR spectroscopy.
OneSeg: Self-learning and One-shot Learning based Single-slice Annotation for 3D Medical Image Segmentation
Sep 24, 2023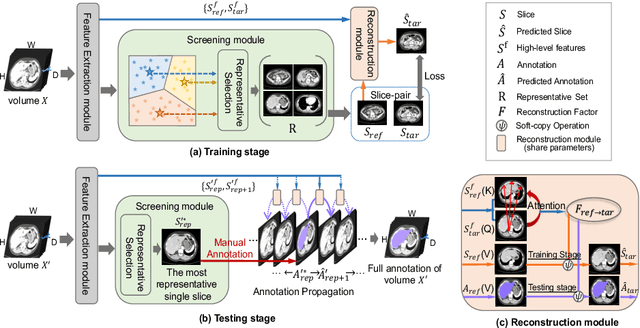
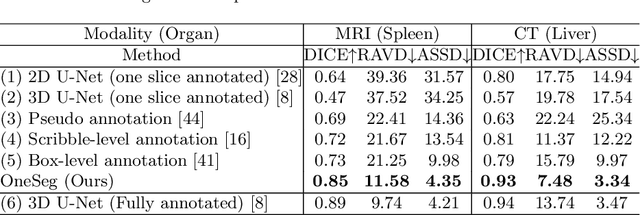

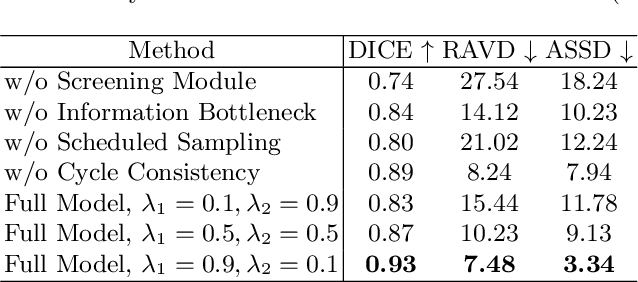
As deep learning methods continue to improve medical image segmentation performance, data annotation is still a big bottleneck due to the labor-intensive and time-consuming burden on medical experts, especially for 3D images. To significantly reduce annotation efforts while attaining competitive segmentation accuracy, we propose a self-learning and one-shot learning based framework for 3D medical image segmentation by annotating only one slice of each 3D image. Our approach takes two steps: (1) self-learning of a reconstruction network to learn semantic correspondence among 2D slices within 3D images, and (2) representative selection of single slices for one-shot manual annotation and propagating the annotated data with the well-trained reconstruction network. Extensive experiments verify that our new framework achieves comparable performance with less than 1% annotated data compared with fully supervised methods and generalizes well on several out-of-distribution testing sets.
Collaborative Watermarking for Adversarial Speech Synthesis
Sep 26, 2023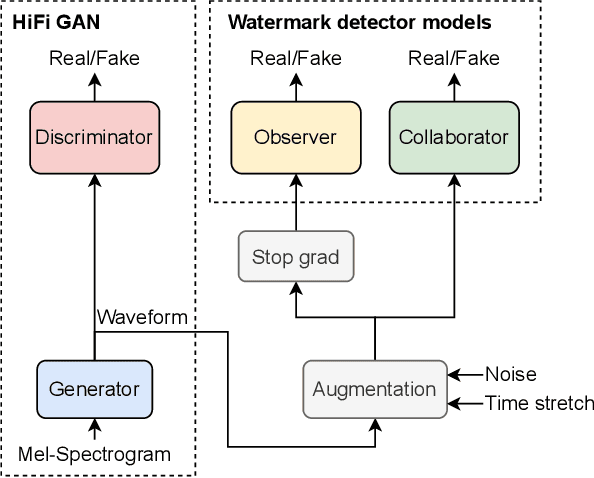
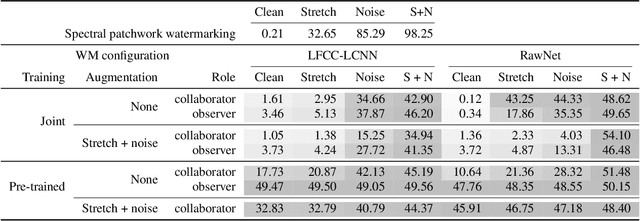

Advances in neural speech synthesis have brought us technology that is not only close to human naturalness, but is also capable of instant voice cloning with little data, and is highly accessible with pre-trained models available. Naturally, the potential flood of generated content raises the need for synthetic speech detection and watermarking. Recently, considerable research effort in synthetic speech detection has been related to the Automatic Speaker Verification and Spoofing Countermeasure Challenge (ASVspoof), which focuses on passive countermeasures. This paper takes a complementary view to generated speech detection: a synthesis system should make an active effort to watermark the generated speech in a way that aids detection by another machine, but remains transparent to a human listener. We propose a collaborative training scheme for synthetic speech watermarking and show that a HiFi-GAN neural vocoder collaborating with the ASVspoof 2021 baseline countermeasure models consistently improves detection performance over conventional classifier training. Furthermore, we demonstrate how collaborative training can be paired with augmentation strategies for added robustness against noise and time-stretching. Finally, listening tests demonstrate that collaborative training has little adverse effect on perceptual quality of vocoded speech.
Unidirectional brain-computer interface: Artificial neural network encoding natural images to fMRI response in the visual cortex
Sep 26, 2023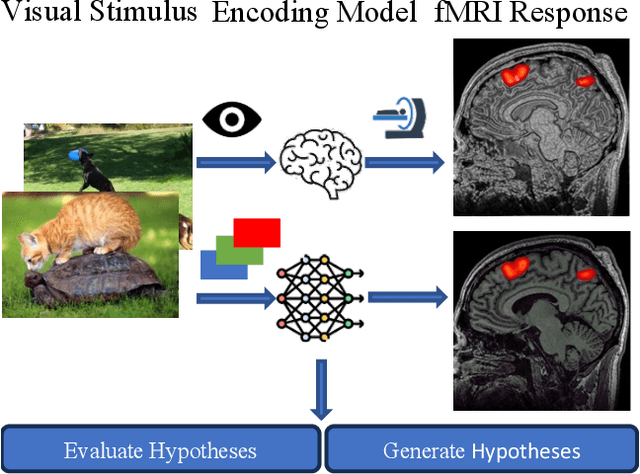
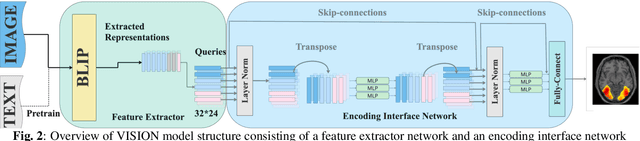
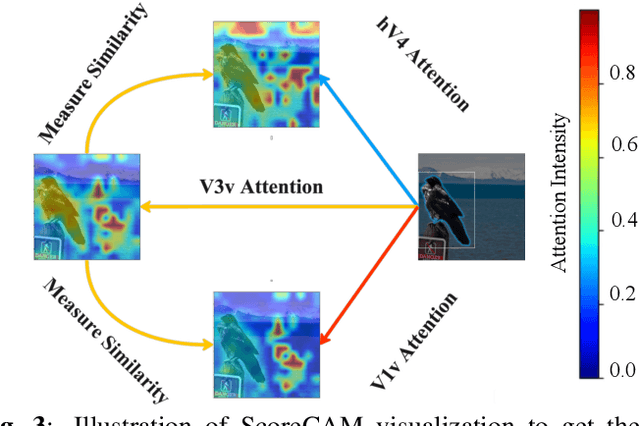
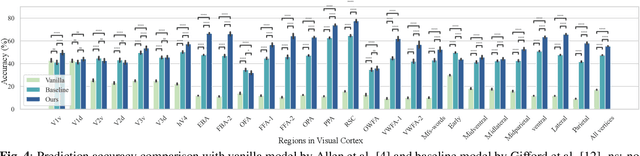
While significant advancements in artificial intelligence (AI) have catalyzed progress across various domains, its full potential in understanding visual perception remains underexplored. We propose an artificial neural network dubbed VISION, an acronym for "Visual Interface System for Imaging Output of Neural activity," to mimic the human brain and show how it can foster neuroscientific inquiries. Using visual and contextual inputs, this multimodal model predicts the brain's functional magnetic resonance imaging (fMRI) scan response to natural images. VISION successfully predicts human hemodynamic responses as fMRI voxel values to visual inputs with an accuracy exceeding state-of-the-art performance by 45%. We further probe the trained networks to reveal representational biases in different visual areas, generate experimentally testable hypotheses, and formulate an interpretable metric to associate these hypotheses with cortical functions. With both a model and evaluation metric, the cost and time burdens associated with designing and implementing functional analysis on the visual cortex could be reduced. Our work suggests that the evolution of computational models may shed light on our fundamental understanding of the visual cortex and provide a viable approach toward reliable brain-machine interfaces.
Advanced Volleyball Stats for All Levels: Automatic Setting Tactic Detection and Classification with a Single Camera
Sep 26, 2023This paper presents PathFinder and PathFinderPlus, two novel end-to-end computer vision frameworks designed specifically for advanced setting strategy classification in volleyball matches from a single camera view. Our frameworks combine setting ball trajectory recognition with a novel set trajectory classifier to generate comprehensive and advanced statistical data. This approach offers a fresh perspective for in-game analysis and surpasses the current level of granularity in volleyball statistics. In comparison to existing methods used in our baseline PathFinder framework, our proposed ball trajectory detection methodology in PathFinderPlus exhibits superior performance for classifying setting tactics under various game conditions. This robustness is particularly advantageous in handling complex game situations and accommodating different camera angles. Additionally, our study introduces an innovative algorithm for automatic identification of the opposing team's right-side (opposite) hitter's current row (front or back) during gameplay, providing critical insights for tactical analysis. The successful demonstration of our single-camera system's feasibility and benefits makes high-level technical analysis accessible to volleyball enthusiasts of all skill levels and resource availability. Furthermore, the computational efficiency of our system allows for real-time deployment, enabling in-game strategy analysis and on-the-spot gameplan adjustments.