 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Emu: Enhancing Image Generation Models Using Photogenic Needles in a Haystack
Sep 27, 2023
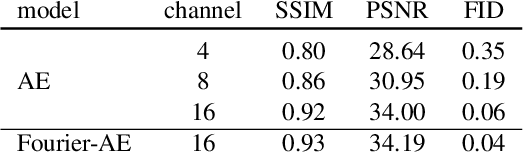

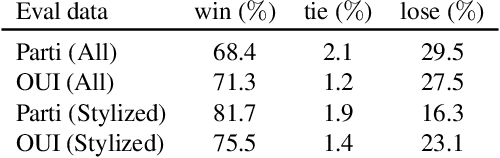

Training text-to-image models with web scale image-text pairs enables the generation of a wide range of visual concepts from text. However, these pre-trained models often face challenges when it comes to generating highly aesthetic images. This creates the need for aesthetic alignment post pre-training. In this paper, we propose quality-tuning to effectively guide a pre-trained model to exclusively generate highly visually appealing images, while maintaining generality across visual concepts. Our key insight is that supervised fine-tuning with a set of surprisingly small but extremely visually appealing images can significantly improve the generation quality. We pre-train a latent diffusion model on $1.1$ billion image-text pairs and fine-tune it with only a few thousand carefully selected high-quality images. The resulting model, Emu, achieves a win rate of $82.9\%$ compared with its pre-trained only counterpart. Compared to the state-of-the-art SDXLv1.0, Emu is preferred $68.4\%$ and $71.3\%$ of the time on visual appeal on the standard PartiPrompts and our Open User Input benchmark based on the real-world usage of text-to-image models. In addition, we show that quality-tuning is a generic approach that is also effective for other architectures, including pixel diffusion and masked generative transformer models.
Position and Orientation-Aware One-Shot Learning for Medical Action Recognition from Signal Data
Sep 27, 2023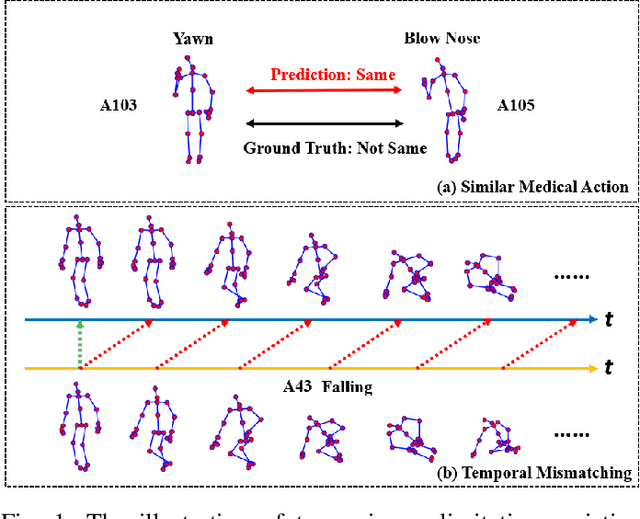
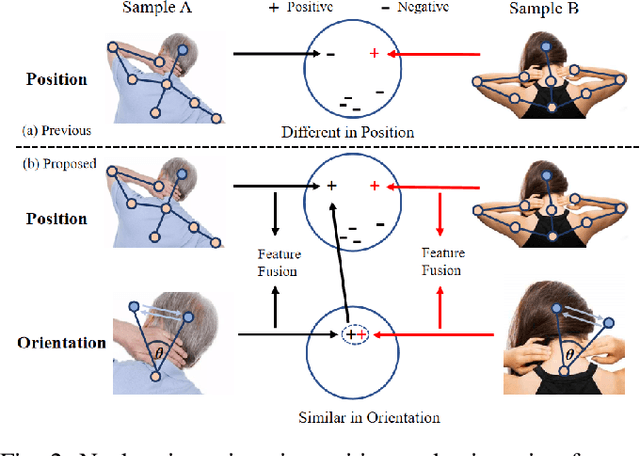
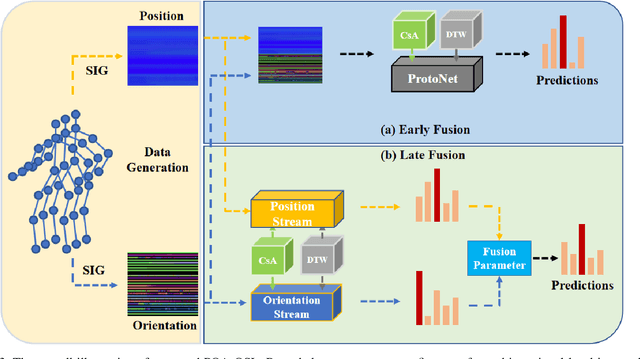
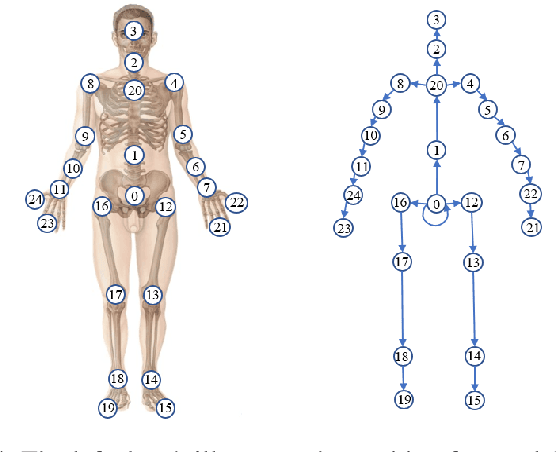
In this work, we propose a position and orientation-aware one-shot learning framework for medical action recognition from signal data. The proposed framework comprises two stages and each stage includes signal-level image generation (SIG), cross-attention (CsA), dynamic time warping (DTW) modules and the information fusion between the proposed privacy-preserved position and orientation features. The proposed SIG method aims to transform the raw skeleton data into privacy-preserved features for training. The CsA module is developed to guide the network in reducing medical action recognition bias and more focusing on important human body parts for each specific action, aimed at addressing similar medical action related issues. Moreover, the DTW module is employed to minimize temporal mismatching between instances and further improve model performance. Furthermore, the proposed privacy-preserved orientation-level features are utilized to assist the position-level features in both of the two stages for enhancing medical action recognition performance. Extensive experimental results on the widely-used and well-known NTU RGB+D 60, NTU RGB+D 120, and PKU-MMD datasets all demonstrate the effectiveness of the proposed method, which outperforms the other state-of-the-art methods with general dataset partitioning by 2.7%, 6.2% and 4.1%, respectively.
REM-U-net: Deep Learning Based Agile REM Prediction with Energy-Efficient Cell-Free Use Case
Sep 21, 2023Radio environment maps (REMs) hold a central role in optimizing wireless network deployment, enhancing network performance, and ensuring effective spectrum management. Conventional REM prediction methods are either excessively time-consuming, e.g., ray tracing, or inaccurate, e.g., statistical models, limiting their adoption in modern inherently dynamic wireless networks. Deep-learning-based REM prediction has recently attracted considerable attention as an appealing, accurate, and time-efficient alternative. However, existing works on REM prediction using deep learning are either confined to 2D maps or use a limited dataset. In this paper, we introduce a runtime-efficient REM prediction framework based on u-nets, trained on a large-scale 3D maps dataset. In addition, data preprocessing steps are investigated to further refine the REM prediction accuracy. The proposed u-net framework, along with preprocessing steps, are evaluated in the context of the 2023 IEEE ICASSP Signal Processing Grand Challenge, namely, the First Pathloss Radio Map Prediction Challenge. The evaluation results demonstrate that the proposed method achieves an average normalized root-mean-square error (RMSE) of 0.045 with an average of 14 milliseconds (ms) runtime. Finally, we position our achieved REM prediction accuracy in the context of a relevant cell-free massive multiple-input multiple-output (CF-mMIMO) use case. We demonstrate that one can obviate consuming energy on large-scale fading measurements and rely on predicted REM instead to decide on which sleep access points (APs) to switch on in a CF-mMIMO network that adopts a minimum propagation loss AP switch ON/OFF strategy.
ChatGPT-4 with Code Interpreter can be used to solve introductory college-level vector calculus and electromagnetism problems
Sep 16, 2023We evaluated ChatGPT 3.5, 4, and 4 with Code Interpreter on a set of college-level engineering-math and electromagnetism problems, such as those often given to sophomore electrical engineering majors. We selected a set of 13 problems, and had ChatGPT solve them multiple times, using a fresh instance (chat) each time. We found that ChatGPT-4 with Code Interpreter was able to satisfactorily solve most problems we tested most of the time -- a major improvement over the performance of ChatGPT-4 (or 3.5) without Code Interpreter. The performance of ChatGPT was observed to be somewhat stochastic, and we found that solving the same problem N times in new ChatGPT instances and taking the most-common answer was an effective strategy. Based on our findings and observations, we provide some recommendations for instructors and students of classes at this level.
Safe Hierarchical Reinforcement Learning for CubeSat Task Scheduling Based on Energy Consumption
Sep 21, 2023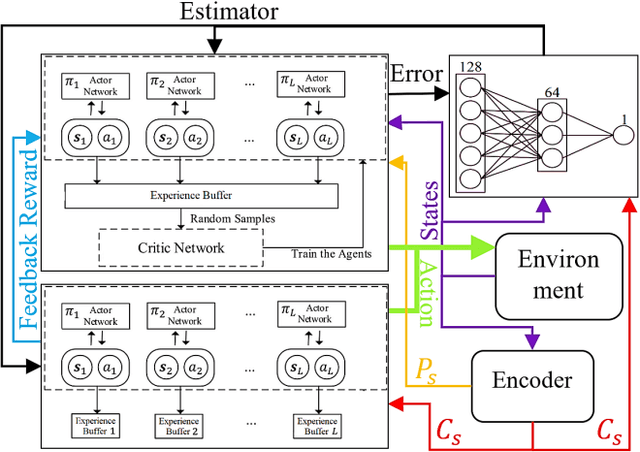
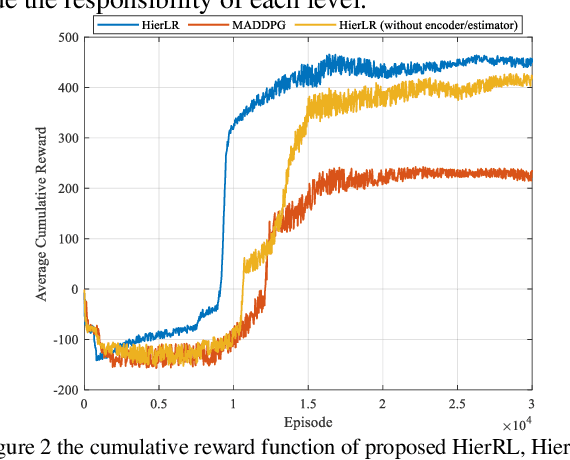
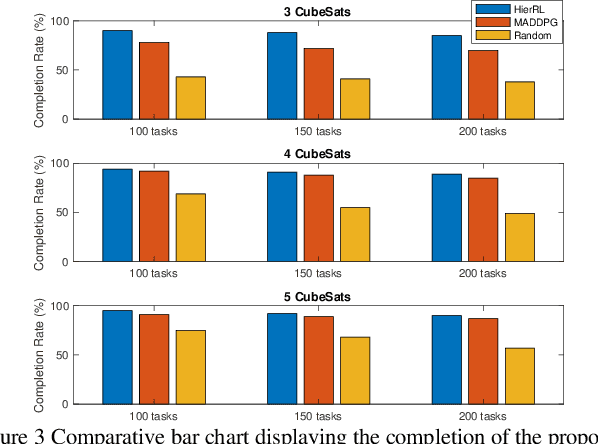
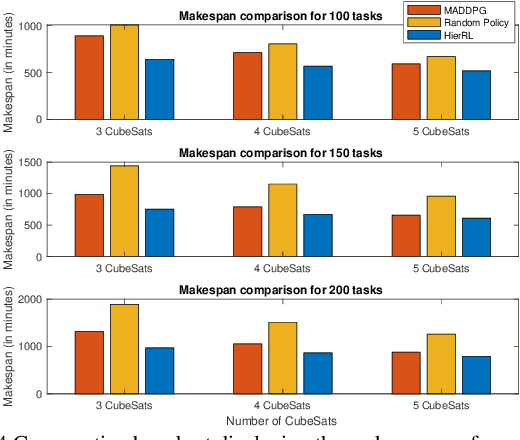
This paper presents a Hierarchical Reinforcement Learning methodology tailored for optimizing CubeSat task scheduling in Low Earth Orbits (LEO). Incorporating a high-level policy for global task distribution and a low-level policy for real-time adaptations as a safety mechanism, our approach integrates the Similarity Attention-based Encoder (SABE) for task prioritization and an MLP estimator for energy consumption forecasting. Integrating this mechanism creates a safe and fault-tolerant system for CubeSat task scheduling. Simulation results validate the Hierarchical Reinforcement Learning superior convergence and task success rate, outperforming both the MADDPG model and traditional random scheduling across multiple CubeSat configurations.
Deep Learning based Fast and Accurate Beamforming for Millimeter-Wave Systems
Sep 19, 2023The widespread proliferation of mmW devices has led to a surge of interest in antenna arrays. This interest in arrays is due to their ability to steer beams in desired directions, for the purpose of increasing signal-power and/or decreasing interference levels. To enable beamforming, array coefficients are typically stored in look-up tables (LUTs) for subsequent referencing. While LUTs enable fast sweep times, their limited memory size restricts the number of beams the array can produce. Consequently, a receiver is likely to be offset from the main beam, thus decreasing received power, and resulting in sub-optimal performance. In this letter, we present BeamShaper, a deep neural network (DNN) framework, which enables fast and accurate beamsteering in any desirable 3-D direction. Unlike traditional finite-memory LUTs which support a fixed set of beams, BeamShaper utilizes a trained NN model to generate the array coefficients for arbitrary directions in \textit{real-time}. Our simulations show that BeamShaper outperforms contemporary LUT based solutions in terms of cosine-similarity and central angle in time scales that are slightly higher than LUT based solutions. Additionally, we show that our DNN based approach has the added advantage of being more resilient to the effects of quantization noise generated while using digital phase-shifters.
Semi-Autoregressive Streaming ASR With Label Context
Sep 19, 2023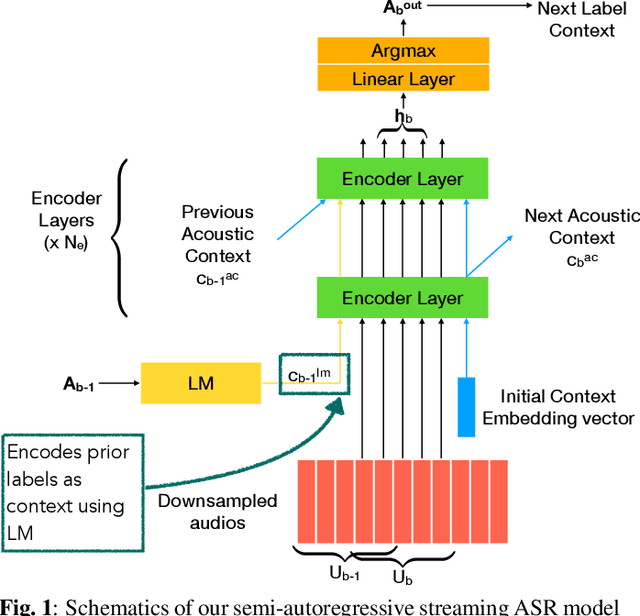
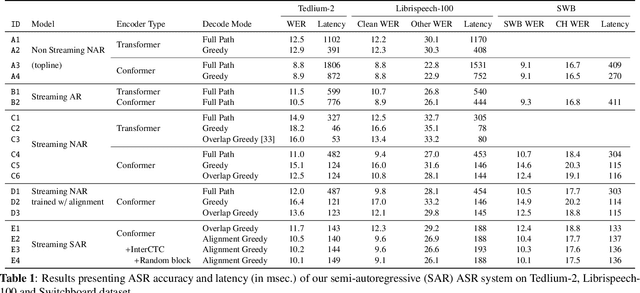

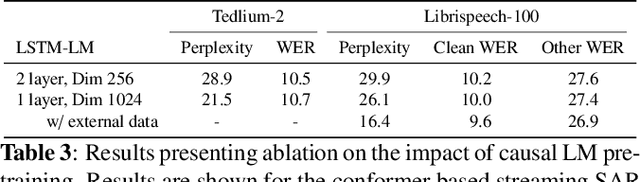
Non-autoregressive (NAR) modeling has gained significant interest in speech processing since these models achieve dramatically lower inference time than autoregressive (AR) models while also achieving good transcription accuracy. Since NAR automatic speech recognition (ASR) models must wait for the completion of the entire utterance before processing, some works explore streaming NAR models based on blockwise attention for low-latency applications. However, streaming NAR models significantly lag in accuracy compared to streaming AR and non-streaming NAR models. To address this, we propose a streaming "semi-autoregressive" ASR model that incorporates the labels emitted in previous blocks as additional context using a Language Model (LM) subnetwork. We also introduce a novel greedy decoding algorithm that addresses insertion and deletion errors near block boundaries while not significantly increasing the inference time. Experiments show that our method outperforms the existing streaming NAR model by 19% relative on Tedlium2, 16%/8% on Librispeech-100 clean/other test sets, and 19%/8% on the Switchboard(SWB) / Callhome(CH) test sets. It also reduced the accuracy gap with streaming AR and non-streaming NAR models while achieving 2.5x lower latency. We also demonstrate that our approach can effectively utilize external text data to pre-train the LM subnetwork to further improve streaming ASR accuracy.
Heuristic Search for Path Finding with Refuelling
Sep 19, 2023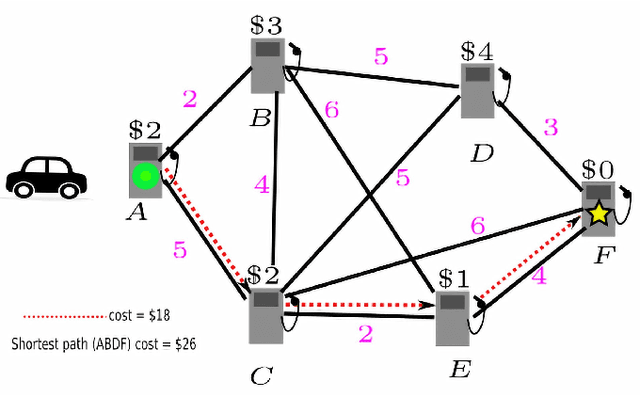
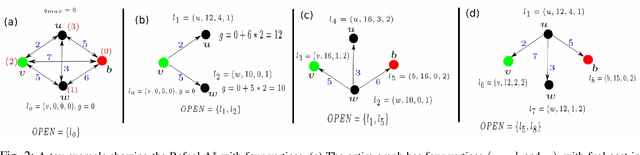
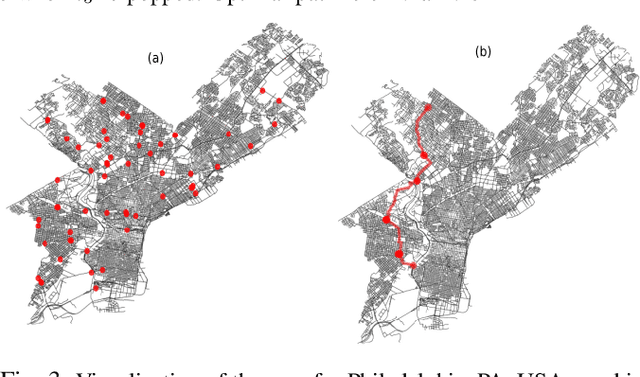
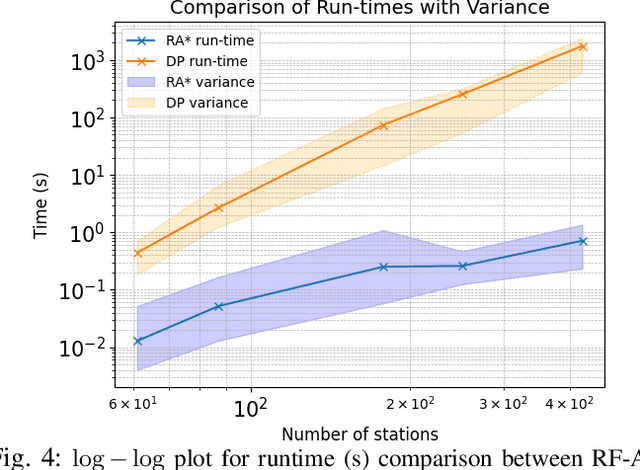
This paper considers a generalization of the Path Finding (PF) with refueling constraints referred to as the Refuelling Path Finding (RF-PF) problem. Just like PF, the RF-PF problem is defined over a graph, where vertices are gas stations with known fuel prices, and edge costs depend on the gas consumption between the corresponding vertices. RF-PF seeks a minimum-cost path from the start to the goal vertex for a robot with a limited gas tank and a limited number of refuelling stops. While RF-PF is polynomial-time solvable, it remains a challenge to quickly compute an optimal solution in practice since the robot needs to simultaneously determine the path, where to make the stops, and the amount to refuel at each stop. This paper develops a heuristic search algorithm called Refuel A* (RF-A* ) that iteratively constructs partial solution paths from the start to the goal guided by a heuristic function while leveraging dominance rules for state pruning during planning. RF-A* is guaranteed to find an optimal solution and runs more than an order of magnitude faster than the existing state of the art (a polynomial time algorithm) when tested in large city maps with hundreds of gas stations.
PROSE: Predicting Operators and Symbolic Expressions using Multimodal Transformers
Sep 28, 2023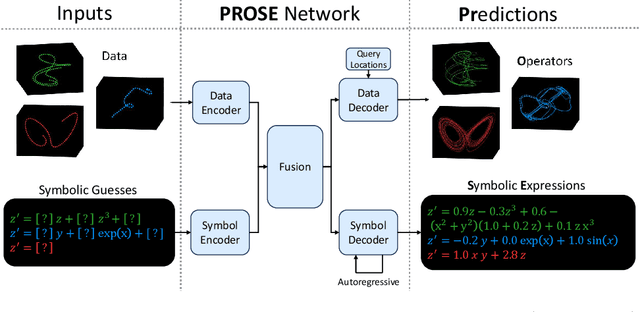
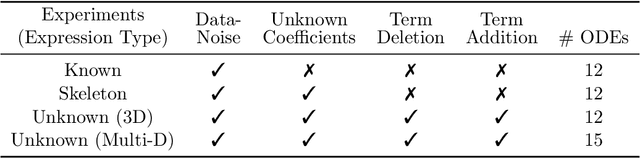
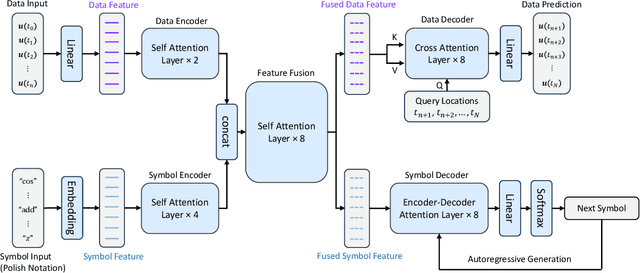

Approximating nonlinear differential equations using a neural network provides a robust and efficient tool for various scientific computing tasks, including real-time predictions, inverse problems, optimal controls, and surrogate modeling. Previous works have focused on embedding dynamical systems into networks through two approaches: learning a single solution operator (i.e., the mapping from input parametrized functions to solutions) or learning the governing system of equations (i.e., the constitutive model relative to the state variables). Both of these approaches yield different representations for the same underlying data or function. Additionally, observing that families of differential equations often share key characteristics, we seek one network representation across a wide range of equations. Our method, called Predicting Operators and Symbolic Expressions (PROSE), learns maps from multimodal inputs to multimodal outputs, capable of generating both numerical predictions and mathematical equations. By using a transformer structure and a feature fusion approach, our network can simultaneously embed sets of solution operators for various parametric differential equations using a single trained network. Detailed experiments demonstrate that the network benefits from its multimodal nature, resulting in improved prediction accuracy and better generalization. The network is shown to be able to handle noise in the data and errors in the symbolic representation, including noisy numerical values, model misspecification, and erroneous addition or deletion of terms. PROSE provides a new neural network framework for differential equations which allows for more flexibility and generality in learning operators and governing equations from data.
Diverse and Aligned Audio-to-Video Generation via Text-to-Video Model Adaptation
Sep 28, 2023We consider the task of generating diverse and realistic videos guided by natural audio samples from a wide variety of semantic classes. For this task, the videos are required to be aligned both globally and temporally with the input audio: globally, the input audio is semantically associated with the entire output video, and temporally, each segment of the input audio is associated with a corresponding segment of that video. We utilize an existing text-conditioned video generation model and a pre-trained audio encoder model. The proposed method is based on a lightweight adaptor network, which learns to map the audio-based representation to the input representation expected by the text-to-video generation model. As such, it also enables video generation conditioned on text, audio, and, for the first time as far as we can ascertain, on both text and audio. We validate our method extensively on three datasets demonstrating significant semantic diversity of audio-video samples and further propose a novel evaluation metric (AV-Align) to assess the alignment of generated videos with input audio samples. AV-Align is based on the detection and comparison of energy peaks in both modalities. In comparison to recent state-of-the-art approaches, our method generates videos that are better aligned with the input sound, both with respect to content and temporal axis. We also show that videos produced by our method present higher visual quality and are more diverse.