 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Passive Variable Impedance Control Strategy with Viscoelastic Parameters Estimation of Soft Tissues for Safe Ultrasonography
Sep 26, 2023
In the context of telehealth, robotic approaches have proven a valuable solution to in-person visits in remote areas, with decreased costs for patients and infection risks. In particular, in ultrasonography, robots have the potential to reproduce the skills required to acquire high-quality images while reducing the sonographer's physical efforts. In this paper, we address the control of the interaction of the probe with the patient's body, a critical aspect of ensuring safe and effective ultrasonography. We introduce a novel approach based on variable impedance control, allowing real-time optimisation of a compliant controller parameters during ultrasound procedures. This optimisation is formulated as a quadratic programming problem and incorporates physical constraints derived from viscoelastic parameter estimations. Safety and passivity constraints, including an energy tank, are also integrated to minimise potential risks during human-robot interaction. The proposed method's efficacy is demonstrated through experiments on a patient dummy torso, highlighting its potential for achieving safe behaviour and accurate force control during ultrasound procedures, even in cases of contact loss.
QA-LoRA: Quantization-Aware Low-Rank Adaptation of Large Language Models
Sep 26, 2023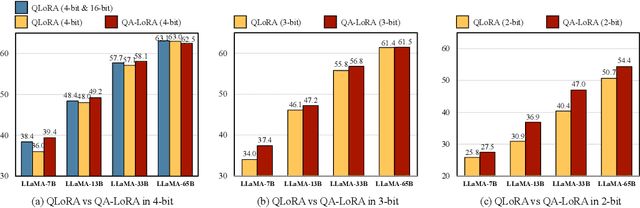
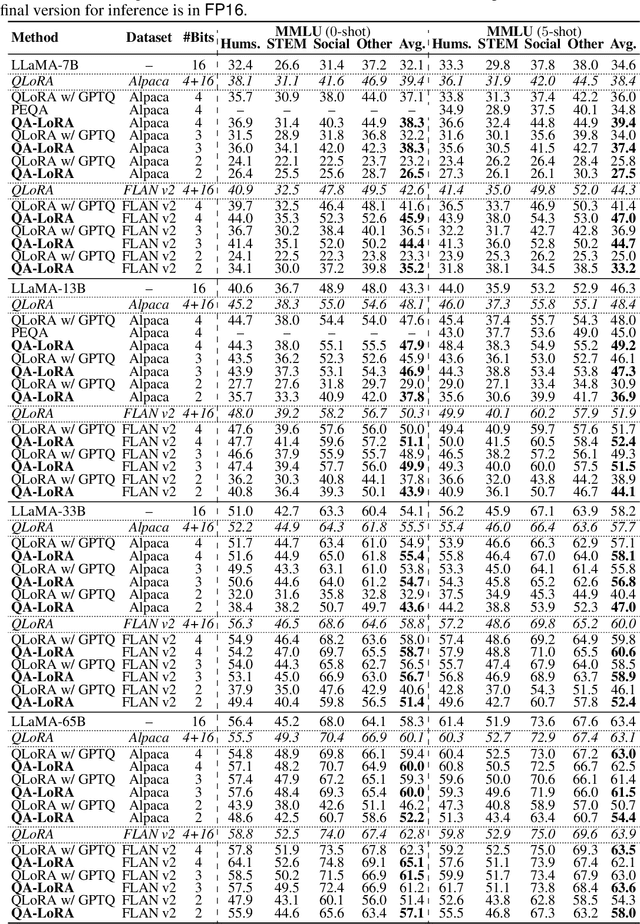
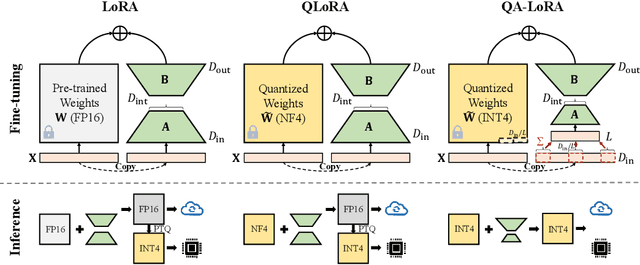

Recently years have witnessed a rapid development of large language models (LLMs). Despite the strong ability in many language-understanding tasks, the heavy computational burden largely restricts the application of LLMs especially when one needs to deploy them onto edge devices. In this paper, we propose a quantization-aware low-rank adaptation (QA-LoRA) algorithm. The motivation lies in the imbalanced degrees of freedom of quantization and adaptation, and the solution is to use group-wise operators which increase the degree of freedom of quantization meanwhile decreasing that of adaptation. QA-LoRA is easily implemented with a few lines of code, and it equips the original LoRA with two-fold abilities: (i) during fine-tuning, the LLM's weights are quantized (e.g., into INT4) to reduce time and memory usage; (ii) after fine-tuning, the LLM and auxiliary weights are naturally integrated into a quantized model without loss of accuracy. We apply QA-LoRA to the LLaMA and LLaMA2 model families and validate its effectiveness in different fine-tuning datasets and downstream scenarios. Code will be made available at https://github.com/yuhuixu1993/qa-lora.
PLMM: Personal Large Models on Mobile Devices
Sep 26, 2023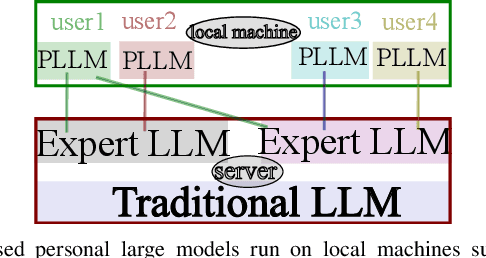

Inspired by Federated Learning, in this paper, we propose personal large models that are distilled from traditional large language models but more adaptive to local users' personal information such as education background and hobbies. We classify the large language models into three levels: the personal level, expert level and traditional level. The personal level models are adaptive to users' personal information. They encrypt the users' input and protect their privacy. The expert level models focus on merging specific knowledge such as finance, IT and art. The traditional models focus on the universal knowledge discovery and upgrading the expert models. In such classifications, the personal models directly interact with the user. For the whole system, the personal models have users' (encrypted) personal information. Moreover, such models must be small enough to be performed on personal computers or mobile devices. Finally, they also have to response in real-time for better user experience and produce high quality results. The proposed personal large models can be applied in a wide range of applications such as language and vision tasks.
Quantitative Analysis of Forecasting Models:In the Aspect of Online Political Bias
Sep 19, 2023Understanding and mitigating political bias in online social media platforms are crucial tasks to combat misinformation and echo chamber effects. However, characterizing political bias temporally using computational methods presents challenges due to the high frequency of noise in social media datasets. While existing research has explored various approaches to political bias characterization, the ability to forecast political bias and anticipate how political conversations might evolve in the near future has not been extensively studied. In this paper, we propose a heuristic approach to classify social media posts into five distinct political leaning categories. Since there is a lack of prior work on forecasting political bias, we conduct an in-depth analysis of existing baseline models to identify which model best fits to forecast political leaning time series. Our approach involves utilizing existing time series forecasting models on two social media datasets with different political ideologies, specifically Twitter and Gab. Through our experiments and analyses, we seek to shed light on the challenges and opportunities in forecasting political bias in social media platforms. Ultimately, our work aims to pave the way for developing more effective strategies to mitigate the negative impact of political bias in the digital realm.
Multimodal Transformers for Wireless Communications: A Case Study in Beam Prediction
Sep 21, 2023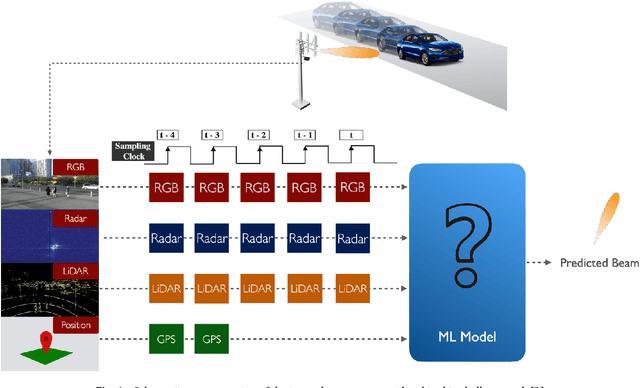
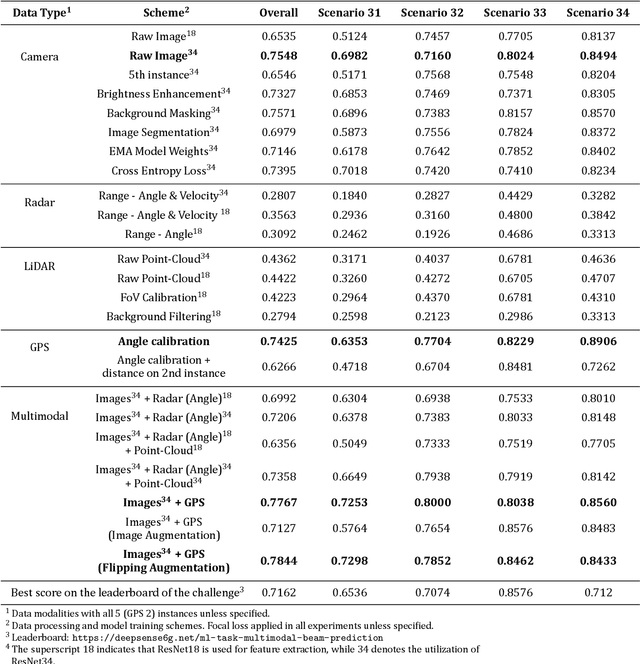
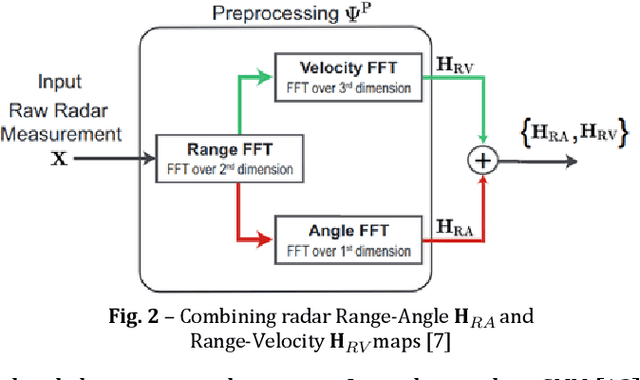
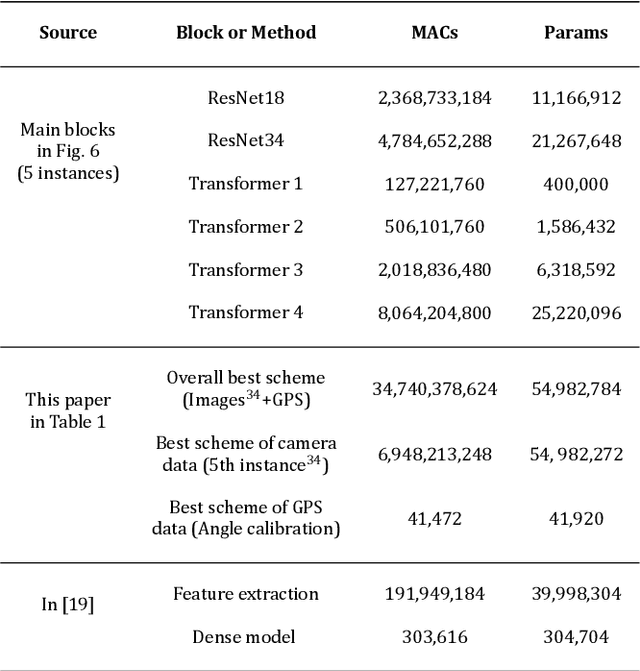
Wireless communications at high-frequency bands with large antenna arrays face challenges in beam management, which can potentially be improved by multimodality sensing information from cameras, LiDAR, radar, and GPS. In this paper, we present a multimodal transformer deep learning framework for sensing-assisted beam prediction. We employ a convolutional neural network to extract the features from a sequence of images, point clouds, and radar raw data sampled over time. At each convolutional layer, we use transformer encoders to learn the hidden relations between feature tokens from different modalities and time instances over abstraction space and produce encoded vectors for the next-level feature extraction. We train the model on a combination of different modalities with supervised learning. We try to enhance the model over imbalanced data by utilizing focal loss and exponential moving average. We also evaluate data processing and augmentation techniques such as image enhancement, segmentation, background filtering, multimodal data flipping, radar signal transformation, and GPS angle calibration. Experimental results show that our solution trained on image and GPS data produces the best distance-based accuracy of predicted beams at 78.44%, with effective generalization to unseen day scenarios near 73% and night scenarios over 84%. This outperforms using other modalities and arbitrary data processing techniques, which demonstrates the effectiveness of transformers with feature fusion in performing radio beam prediction from images and GPS. Furthermore, our solution could be pretrained from large sequences of multimodality wireless data, on fine-tuning for multiple downstream radio network tasks.
U-shaped Transformer: Retain High Frequency Context in Time Series Analysis
Jul 18, 2023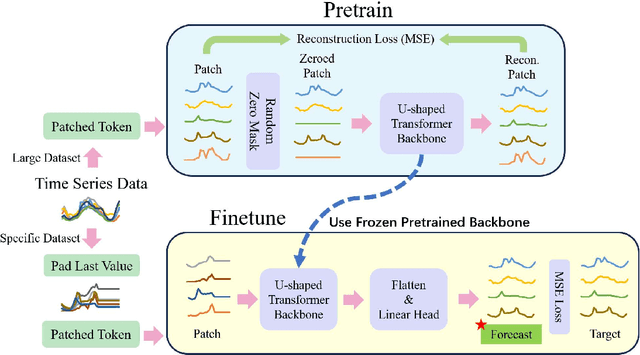
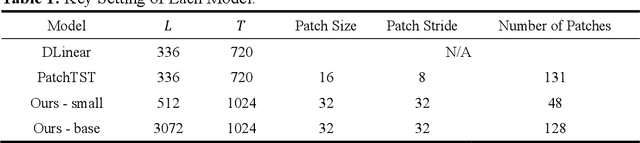

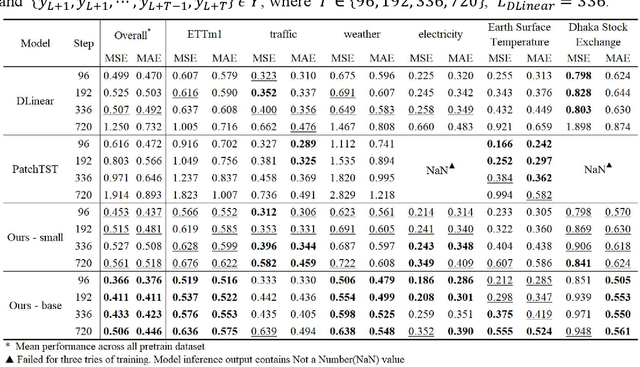
Time series prediction plays a crucial role in various industrial fields. In recent years, neural networks with a transformer backbone have achieved remarkable success in many domains, including computer vision and NLP. In time series analysis domain, some studies have suggested that even the simplest MLP networks outperform advanced transformer-based networks on time series forecast tasks. However, we believe these findings indicate there to be low-rank properties in time series sequences. In this paper, we consider the low-pass characteristics of transformers and try to incorporate the advantages of MLP. We adopt skip-layer connections inspired by Unet into traditional transformer backbone, thus preserving high-frequency context from input to output, namely U-shaped Transformer. We introduce patch merge and split operation to extract features with different scales and use larger datasets to fully make use of the transformer backbone. Our experiments demonstrate that the model performs at an advanced level across multiple datasets with relatively low cost.
Augmenting transformers with recursively composed multi-grained representations
Sep 28, 2023We present ReCAT, a recursive composition augmented Transformer that is able to explicitly model hierarchical syntactic structures of raw texts without relying on gold trees during both learning and inference. Existing research along this line restricts data to follow a hierarchical tree structure and thus lacks inter-span communications. To overcome the problem, we propose a novel contextual inside-outside (CIO) layer that learns contextualized representations of spans through bottom-up and top-down passes, where a bottom-up pass forms representations of high-level spans by composing low-level spans, while a top-down pass combines information inside and outside a span. By stacking several CIO layers between the embedding layer and the attention layers in Transformer, the ReCAT model can perform both deep intra-span and deep inter-span interactions, and thus generate multi-grained representations fully contextualized with other spans. Moreover, the CIO layers can be jointly pre-trained with Transformers, making ReCAT enjoy scaling ability, strong performance, and interpretability at the same time. We conduct experiments on various sentence-level and span-level tasks. Evaluation results indicate that ReCAT can significantly outperform vanilla Transformer models on all span-level tasks and baselines that combine recursive networks with Transformers on natural language inference tasks. More interestingly, the hierarchical structures induced by ReCAT exhibit strong consistency with human-annotated syntactic trees, indicating good interpretability brought by the CIO layers.
A framework for paired-sample hypothesis testing for high-dimensional data
Sep 28, 2023The standard paired-sample testing approach in the multidimensional setting applies multiple univariate tests on the individual features, followed by p-value adjustments. Such an approach suffers when the data carry numerous features. A number of studies have shown that classification accuracy can be seen as a proxy for two-sample testing. However, neither theoretical foundations nor practical recipes have been proposed so far on how this strategy could be extended to multidimensional paired-sample testing. In this work, we put forward the idea that scoring functions can be produced by the decision rules defined by the perpendicular bisecting hyperplanes of the line segments connecting each pair of instances. Then, the optimal scoring function can be obtained by the pseudomedian of those rules, which we estimate by extending naturally the Hodges-Lehmann estimator. We accordingly propose a framework of a two-step testing procedure. First, we estimate the bisecting hyperplanes for each pair of instances and an aggregated rule derived through the Hodges-Lehmann estimator. The paired samples are scored by this aggregated rule to produce a unidimensional representation. Second, we perform a Wilcoxon signed-rank test on the obtained representation. Our experiments indicate that our approach has substantial performance gains in testing accuracy compared to the traditional multivariate and multiple testing, while at the same time estimates each feature's contribution to the final result.
Class Activation Map-based Weakly supervised Hemorrhage Segmentation using Resnet-LSTM in Non-Contrast Computed Tomography images
Sep 28, 2023In clinical settings, intracranial hemorrhages (ICH) are routinely diagnosed using non-contrast CT (NCCT) for severity assessment. Accurate automated segmentation of ICH lesions is the initial and essential step, immensely useful for such assessment. However, compared to other structural imaging modalities such as MRI, in NCCT images ICH appears with very low contrast and poor SNR. Over recent years, deep learning (DL)-based methods have shown great potential, however, training them requires a huge amount of manually annotated lesion-level labels, with sufficient diversity to capture the characteristics of ICH. In this work, we propose a novel weakly supervised DL method for ICH segmentation on NCCT scans, using image-level binary classification labels, which are less time-consuming and labor-efficient when compared to the manual labeling of individual ICH lesions. Our method initially determines the approximate location of ICH using class activation maps from a classification network, which is trained to learn dependencies across contiguous slices. We further refine the ICH segmentation using pseudo-ICH masks obtained in an unsupervised manner. The method is flexible and uses a computationally light architecture during testing. On evaluating our method on the validation data of the MICCAI 2022 INSTANCE challenge, our method achieves a Dice value of 0.55, comparable with those of existing weakly supervised method (Dice value of 0.47), despite training on a much smaller training data.
Automatic Identification of Stone-Handling Behaviour in Japanese Macaques Using LabGym Artificial Intelligence
Sep 28, 2023
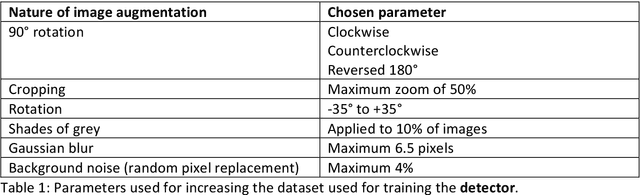


The latest advancements in artificial intelligence technology have opened doors to the analysis of intricate behaviours. In light of this, ethologists are actively exploring the potential of these innovations to streamline the time-intensive process of behavioural analysis using video data. In the realm of primatology, several tools have been developed for this purpose. Nonetheless, each of these tools grapples with technical constraints that we aim to surmount. To address these limitations, we have established a comprehensive protocol designed to harness the capabilities of a cutting-edge tool, LabGym. Our primary objective was to evaluate LabGym's suitability for the analysis of primate behaviour, with a focus on Japanese macaques as our model subjects. We have successfully developed a model that demonstrates a high degree of accuracy in detecting Japanese macaques stone-handling behaviour. Our behavioural analysis model was completed as per our initial expectations and LabGym succeed to recognise stone-handling behaviour on videos. However, it is important to note that our study's ability to draw definitive conclusions regarding the quality of the behavioural analysis is hampered by the absence of quantitative data within the specified timeframe. Nevertheless, our model represents the pioneering endeavour, as far as our knowledge extends, in leveraging LabGym for the analysis of primate behaviours. It lays the groundwork for potential future research in this promising field.