 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
OrCo: Towards Better Generalization via Orthogonality and Contrast for Few-Shot Class-Incremental Learning
Mar 27, 2024
Few-Shot Class-Incremental Learning (FSCIL) introduces a paradigm in which the problem space expands with limited data. FSCIL methods inherently face the challenge of catastrophic forgetting as data arrives incrementally, making models susceptible to overwriting previously acquired knowledge. Moreover, given the scarcity of labeled samples available at any given time, models may be prone to overfitting and find it challenging to strike a balance between extensive pretraining and the limited incremental data. To address these challenges, we propose the OrCo framework built on two core principles: features' orthogonality in the representation space, and contrastive learning. In particular, we improve the generalization of the embedding space by employing a combination of supervised and self-supervised contrastive losses during the pretraining phase. Additionally, we introduce OrCo loss to address challenges arising from data limitations during incremental sessions. Through feature space perturbations and orthogonality between classes, the OrCo loss maximizes margins and reserves space for the following incremental data. This, in turn, ensures the accommodation of incoming classes in the feature space without compromising previously acquired knowledge. Our experimental results showcase state-of-the-art performance across three benchmark datasets, including mini-ImageNet, CIFAR100, and CUB datasets. Code is available at https://github.com/noorahmedds/OrCo
A Situation-aware Enhancer for Personalized Recommendation
Mar 27, 2024When users interact with Recommender Systems (RecSys), current situations, such as time, location, and environment, significantly influence their preferences. Situations serve as the background for interactions, where relationships between users and items evolve with situation changes. However, existing RecSys treat situations, users, and items on the same level. They can only model the relations between situations and users/items respectively, rather than the dynamic impact of situations on user-item associations (i.e., user preferences). In this paper, we provide a new perspective that takes situations as the preconditions for users' interactions. This perspective allows us to separate situations from user/item representations, and capture situations' influences over the user-item relationship, offering a more comprehensive understanding of situations. Based on it, we propose a novel Situation-Aware Recommender Enhancer (SARE), a pluggable module to integrate situations into various existing RecSys. Since users' perception of situations and situations' impact on preferences are both personalized, SARE includes a Personalized Situation Fusion (PSF) and a User-Conditioned Preference Encoder (UCPE) to model the perception and impact of situations, respectively. We conduct experiments of applying SARE on seven backbones in various settings on two real-world datasets. Experimental results indicate that SARE improves the recommendation performances significantly compared with backbones and SOTA situation-aware baselines.
Experimental Comparison of Ensemble Methods and Time-to-Event Analysis Models Through Integrated Brier Score and Concordance Index
Mar 12, 2024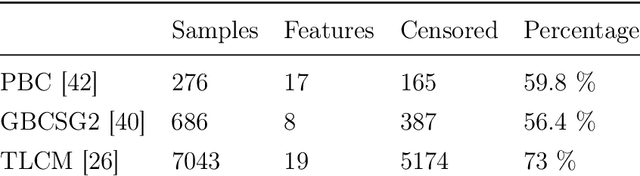
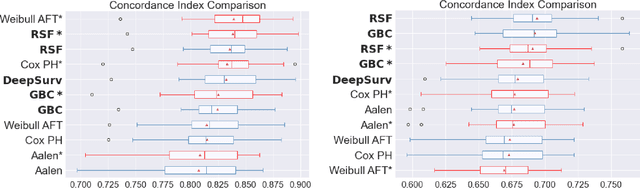
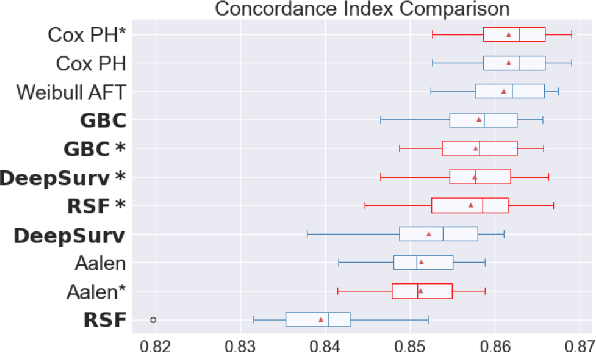
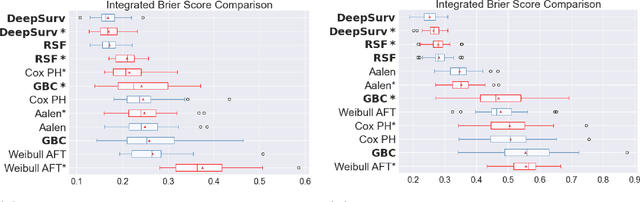
Time-to-event analysis is a branch of statistics that has increased in popularity during the last decades due to its many application fields, such as predictive maintenance, customer churn prediction and population lifetime estimation. In this paper, we review and compare the performance of several prediction models for time-to-event analysis. These consist of semi-parametric and parametric statistical models, in addition to machine learning approaches. Our study is carried out on three datasets and evaluated in two different scores (the integrated Brier score and concordance index). Moreover, we show how ensemble methods, which surprisingly have not yet been much studied in time-to-event analysis, can improve the prediction accuracy and enhance the robustness of the prediction performance. We conclude the analysis with a simulation experiment in which we evaluate the factors influencing the performance ranking of the methods using both scores.
Constricting Normal Latent Space for Anomaly Detection with Normal-only Training Data
Mar 24, 2024In order to devise an anomaly detection model using only normal training data, an autoencoder (AE) is typically trained to reconstruct the data. As a result, the AE can extract normal representations in its latent space. During test time, since AE is not trained using real anomalies, it is expected to poorly reconstruct the anomalous data. However, several researchers have observed that it is not the case. In this work, we propose to limit the reconstruction capability of AE by introducing a novel latent constriction loss, which is added to the existing reconstruction loss. By using our method, no extra computational cost is added to the AE during test time. Evaluations using three video anomaly detection benchmark datasets, i.e., Ped2, Avenue, and ShanghaiTech, demonstrate the effectiveness of our method in limiting the reconstruction capability of AE, which leads to a better anomaly detection model.
Multi-Fidelity Reinforcement Learning for Time-Optimal Quadrotor Re-planning
Mar 13, 2024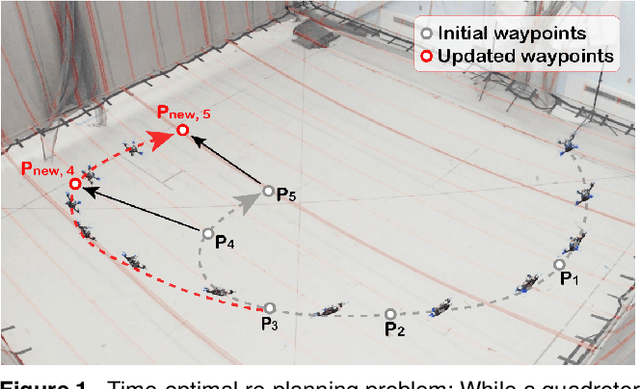
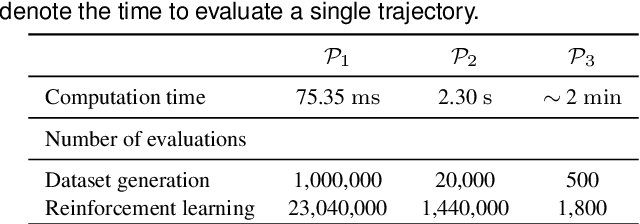
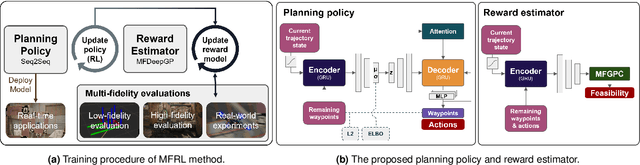
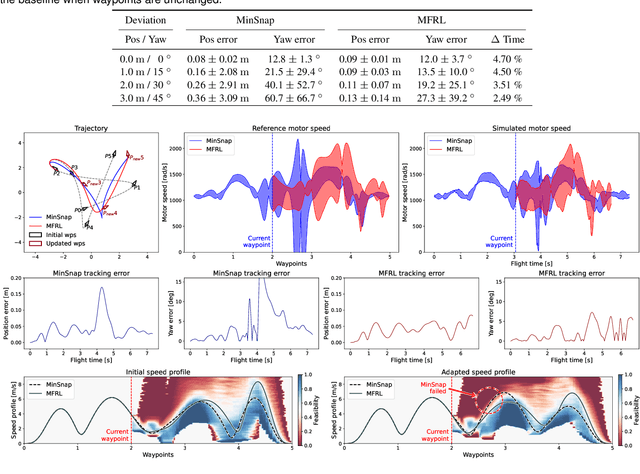
High-speed online trajectory planning for UAVs poses a significant challenge due to the need for precise modeling of complex dynamics while also being constrained by computational limitations. This paper presents a multi-fidelity reinforcement learning method (MFRL) that aims to effectively create a realistic dynamics model and simultaneously train a planning policy that can be readily deployed in real-time applications. The proposed method involves the co-training of a planning policy and a reward estimator; the latter predicts the performance of the policy's output and is trained efficiently through multi-fidelity Bayesian optimization. This optimization approach models the correlation between different fidelity levels, thereby constructing a high-fidelity model based on a low-fidelity foundation, which enables the accurate development of the reward model with limited high-fidelity experiments. The framework is further extended to include real-world flight experiments in reinforcement learning training, allowing the reward model to precisely reflect real-world constraints and broadening the policy's applicability to real-world scenarios. We present rigorous evaluations by training and testing the planning policy in both simulated and real-world environments. The resulting trained policy not only generates faster and more reliable trajectories compared to the baseline snap minimization method, but it also achieves trajectory updates in 2 ms on average, while the baseline method takes several minutes.
FastCAR: Fast Classification And Regression Multi-Task Learning via Task Consolidation for Modelling a Continuous Property Variable of Object Classes
Mar 26, 2024FastCAR is a novel task consolidation approach in Multi-Task Learning (MTL) for a classification and a regression task, despite task heterogeneity with only subtle correlation. It addresses object classification and continuous property variable regression, a crucial use case in science and engineering. FastCAR involves a labeling transformation approach that can be used with a single-task regression network architecture. FastCAR outperforms traditional MTL model families, parametrized in the landscape of architecture and loss weighting schemes, when learning of both tasks are collectively considered (classification accuracy of 99.54%, regression mean absolute percentage error of 2.3%). The experiments performed used an Advanced Steel Property dataset contributed by us. The dataset comprises 4536 images of 224x224 pixels, annotated with object classes and hardness properties that take continuous values. With the labeling transformation and single-task regression network architecture, FastCAR achieves reduced latency and time efficiency.
Adaptive Line-Of-Sight guidance law based on vector fields path following for underactuated unmanned surface vehicle
Mar 26, 2024The focus of this paper is to develop a methodology that enables an unmanned surface vehicle (USV) to efficiently track a planned path. The introduction of a vector field-based adaptive line-of-sight guidance law (VFALOS) for accurate trajectory tracking and minimizing the overshoot response time during USV tracking of curved paths improves the overall line-of-sight (LOS) guidance method. These improvements contribute to faster convergence to the desired path, reduce oscillations, and can mitigate the effects of persistent external disturbances. It is shown that the proposed guidance law exhibits k-exponential stability when converging to the desired path consisting of straight and curved lines. The results in the paper show that the proposed method effectively improves the accuracy of the USV tracking the desired path while ensuring the safety of the USV work.
Latent Attention for Linear Time Transformers
Mar 04, 2024The time complexity of the standard attention mechanism in a transformer scales quadratically with the length of the sequence. We introduce a method to reduce this to linear scaling with time, based on defining attention via latent vectors. The method is readily usable as a drop-in replacement for the standard attention mechanism. Our "Latte Transformer" model can be implemented for both bidirectional and unidirectional tasks, with the causal version allowing a recurrent implementation which is memory and time-efficient during inference of language generation tasks. Whilst next token prediction scales linearly with the sequence length for a standard transformer, a Latte Transformer requires constant time to compute the next token. The empirical performance of our method is comparable to standard attention, yet allows scaling to context windows much larger than practical in standard attention.
Addressing Data Annotation Challenges in Multiple Sensors: A Solution for Scania Collected Datasets
Mar 27, 2024Data annotation in autonomous vehicles is a critical step in the development of Deep Neural Network (DNN) based models or the performance evaluation of the perception system. This often takes the form of adding 3D bounding boxes on time-sequential and registered series of point-sets captured from active sensors like Light Detection and Ranging (LiDAR) and Radio Detection and Ranging (RADAR). When annotating multiple active sensors, there is a need to motion compensate and translate the points to a consistent coordinate frame and timestamp respectively. However, highly dynamic objects pose a unique challenge, as they can appear at different timestamps in each sensor's data. Without knowing the speed of the objects, their position appears to be different in different sensor outputs. Thus, even after motion compensation, highly dynamic objects are not matched from multiple sensors in the same frame, and human annotators struggle to add unique bounding boxes that capture all objects. This article focuses on addressing this challenge, primarily within the context of Scania collected datasets. The proposed solution takes a track of an annotated object as input and uses the Moving Horizon Estimation (MHE) to robustly estimate its speed. The estimated speed profile is utilized to correct the position of the annotated box and add boxes to object clusters missed by the original annotation.
Few-shot Online Anomaly Detection and Segmentation
Mar 27, 2024Detecting anomaly patterns from images is a crucial artificial intelligence technique in industrial applications. Recent research in this domain has emphasized the necessity of a large volume of training data, overlooking the practical scenario where, post-deployment of the model, unlabeled data containing both normal and abnormal samples can be utilized to enhance the model's performance. Consequently, this paper focuses on addressing the challenging yet practical few-shot online anomaly detection and segmentation (FOADS) task. Under the FOADS framework, models are trained on a few-shot normal dataset, followed by inspection and improvement of their capabilities by leveraging unlabeled streaming data containing both normal and abnormal samples simultaneously. To tackle this issue, we propose modeling the feature distribution of normal images using a Neural Gas network, which offers the flexibility to adapt the topology structure to identify outliers in the data flow. In order to achieve improved performance with limited training samples, we employ multi-scale feature embedding extracted from a CNN pre-trained on ImageNet to obtain a robust representation. Furthermore, we introduce an algorithm that can incrementally update parameters without the need to store previous samples. Comprehensive experimental results demonstrate that our method can achieve substantial performance under the FOADS setting, while ensuring that the time complexity remains within an acceptable range on MVTec AD and BTAD datasets.