 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
To Adapt or Not to Adapt? Real-Time Adaptation for Semantic Segmentation
Aug 07, 2023
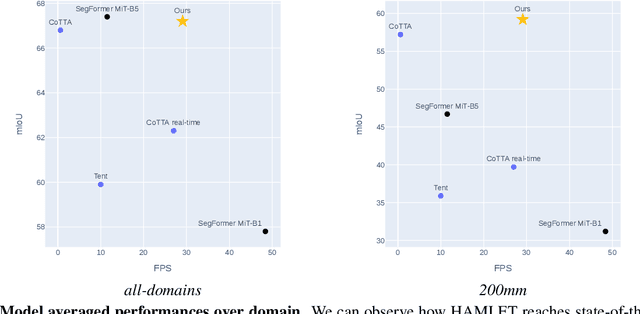
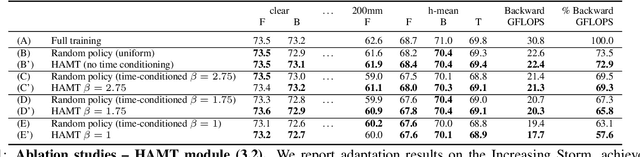
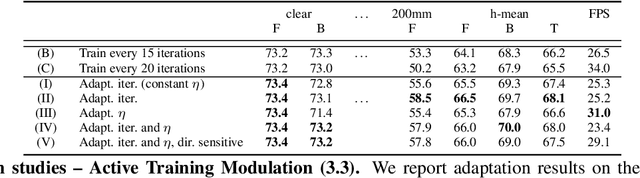
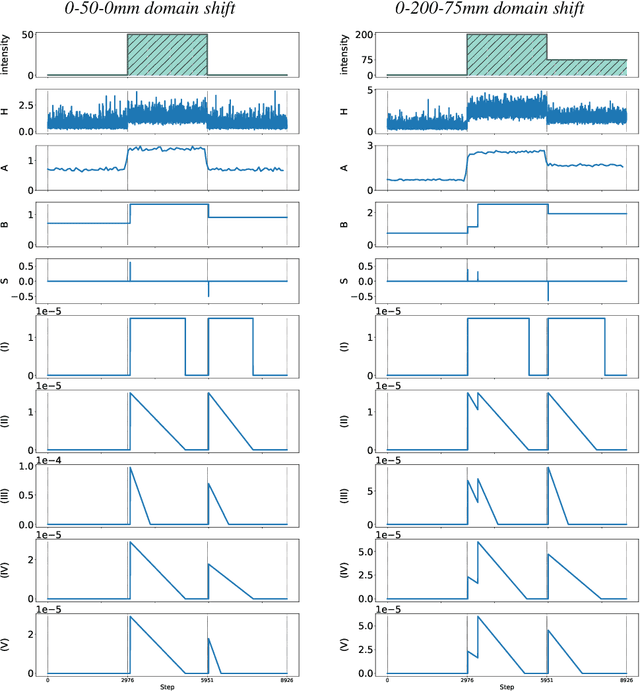
The goal of Online Domain Adaptation for semantic segmentation is to handle unforeseeable domain changes that occur during deployment, like sudden weather events. However, the high computational costs associated with brute-force adaptation make this paradigm unfeasible for real-world applications. In this paper we propose HAMLET, a Hardware-Aware Modular Least Expensive Training framework for real-time domain adaptation. Our approach includes a hardware-aware back-propagation orchestration agent (HAMT) and a dedicated domain-shift detector that enables active control over when and how the model is adapted (LT). Thanks to these advancements, our approach is capable of performing semantic segmentation while simultaneously adapting at more than 29FPS on a single consumer-grade GPU. Our framework's encouraging accuracy and speed trade-off is demonstrated on OnDA and SHIFT benchmarks through experimental results.
ViT-MDHGR: Cross-day Reliability and Agility in Dynamic Hand Gesture Prediction via HD-sEMG Signal Decoding
Sep 22, 2023Surface electromyography (sEMG) and high-density sEMG (HD-sEMG) biosignals have been extensively investigated for myoelectric control of prosthetic devices, neurorobotics, and more recently human-computer interfaces because of their capability for hand gesture recognition/prediction in a wearable and non-invasive manner. High intraday (same-day) performance has been reported. However, the interday performance (separating training and testing days) is substantially degraded due to the poor generalizability of conventional approaches over time, hindering the application of such techniques in real-life practices. There are limited recent studies on the feasibility of multi-day hand gesture recognition. The existing studies face a major challenge: the need for long sEMG epochs makes the corresponding neural interfaces impractical due to the induced delay in myoelectric control. This paper proposes a compact ViT-based network for multi-day dynamic hand gesture prediction. We tackle the main challenge as the proposed model only relies on very short HD-sEMG signal windows (i.e., 50 ms, accounting for only one-sixth of the convention for real-time myoelectric implementation), boosting agility and responsiveness. Our proposed model can predict 11 dynamic gestures for 20 subjects with an average accuracy of over 71% on the testing day, 3-25 days after training. Moreover, when calibrated on just a small portion of data from the testing day, the proposed model can achieve over 92% accuracy by retraining less than 10% of the parameters for computational efficiency.
Frequency-Domain Detection for Molecular Communication with Cross-Reactive Receptors
Sep 17, 2023Molecular Communications (MC) is a bio-inspired communication paradigm that uses molecules as information carriers, requiring unconventional transceivers and modulation/detection techniques. Practical MC receivers (MC-Rxs) can be implemented using field-effect transistor biosensor (bioFET) architectures, where surface receptors reversibly react with ligands. The time-varying concentration of ligand-bound receptors is translated into electrical signals via field effect, which is used to decode the transmitted information. However, ligand-receptor interactions do not provide an ideal molecular selectivity, as similar ligand types, i.e., interferers, co-existing in the MC channel, can interact with the same type of receptors. Overcoming this molecular cross-talk in the time domain can be challenging, especially when Rx has no knowledge of the interferer statistics or operates near saturation. Therefore, we propose a frequency-domain detection (FDD) technique for bioFET-based MC-Rxs that exploits the difference in binding reaction rates of different ligand types reflected in the power spectrum of the ligand-receptor binding noise. We derive the bit error probability (BEP) of the FDD technique and demonstrate its effectiveness in decoding transmitted concentration signals under stochastic molecular interference compared to a widely used time-domain detection (TDD) technique. We then verified the analytical performance bounds of the FDD through a particle-based spatial stochastic simulator simulating reactions on the MC-Rx in microfluidic channels.
A 5-Point Minimal Solver for Event Camera Relative Motion Estimation
Sep 29, 2023Event-based cameras are ideal for line-based motion estimation, since they predominantly respond to edges in the scene. However, accurately determining the camera displacement based on events continues to be an open problem. This is because line feature extraction and dynamics estimation are tightly coupled when using event cameras, and no precise model is currently available for describing the complex structures generated by lines in the space-time volume of events. We solve this problem by deriving the correct non-linear parametrization of such manifolds, which we term eventails, and demonstrate its application to event-based linear motion estimation, with known rotation from an Inertial Measurement Unit. Using this parametrization, we introduce a novel minimal 5-point solver that jointly estimates line parameters and linear camera velocity projections, which can be fused into a single, averaged linear velocity when considering multiple lines. We demonstrate on both synthetic and real data that our solver generates more stable relative motion estimates than other methods while capturing more inliers than clustering based on spatio-temporal planes. In particular, our method consistently achieves a 100% success rate in estimating linear velocity where existing closed-form solvers only achieve between 23% and 70%. The proposed eventails contribute to a better understanding of spatio-temporal event-generated geometries and we thus believe it will become a core building block of future event-based motion estimation algorithms.
Robust Asynchronous Collaborative 3D Detection via Bird's Eye View Flow
Sep 29, 2023By facilitating communication among multiple agents, collaborative perception can substantially boost each agent's perception ability. However, temporal asynchrony among agents is inevitable in real-world due to communication delays, interruptions, and clock misalignments. This issue causes information mismatch during multi-agent fusion, seriously shaking the foundation of collaboration. To address this issue, we propose CoBEVFlow, an asynchrony-robust collaborative 3D perception system based on bird's eye view (BEV) flow. The key intuition of CoBEVFlow is to compensate motions to align asynchronous collaboration messages sent by multiple agents. To model the motion in a scene, we propose BEV flow, which is a collection of the motion vector corresponding to each spatial location. Based on BEV flow, asynchronous perceptual features can be reassigned to appropriate positions, mitigating the impact of asynchrony. CoBEVFlow has two advantages: (i) CoBEVFlow can handle asynchronous collaboration messages sent at irregular, continuous time stamps without discretization; and (ii) with BEV flow, CoBEVFlow only transports the original perceptual features, instead of generating new perceptual features, avoiding additional noises. To validate CoBEVFlow's efficacy, we create IRregular V2V(IRV2V), the first synthetic collaborative perception dataset with various temporal asynchronies that simulate different real-world scenarios. Extensive experiments conducted on both IRV2V and the real-world dataset DAIR-V2X show that CoBEVFlow consistently outperforms other baselines and is robust in extremely asynchronous settings. The code will be released.
Continual Action Assessment via Task-Consistent Score-Discriminative Feature Distribution Modeling
Sep 29, 2023Action Quality Assessment (AQA) is a task that tries to answer how well an action is carried out. While remarkable progress has been achieved, existing works on AQA assume that all the training data are visible for training in one time, but do not enable continual learning on assessing new technical actions. In this work, we address such a Continual Learning problem in AQA (Continual-AQA), which urges a unified model to learn AQA tasks sequentially without forgetting. Our idea for modeling Continual-AQA is to sequentially learn a task-consistent score-discriminative feature distribution, in which the latent features express a strong correlation with the score labels regardless of the task or action types. From this perspective, we aim to mitigate the forgetting in Continual-AQA from two aspects. Firstly, to fuse the features of new and previous data into a score-discriminative distribution, a novel Feature-Score Correlation-Aware Rehearsal is proposed to store and reuse data from previous tasks with limited memory size. Secondly, an Action General-Specific Graph is developed to learn and decouple the action-general and action-specific knowledge so that the task-consistent score-discriminative features can be better extracted across various tasks. Extensive experiments are conducted to evaluate the contributions of proposed components. The comparisons with the existing continual learning methods additionally verify the effectiveness and versatility of our approach.
Towards Connecting Control to Perception: High-Performance Whole-Body Collision Avoidance Using Control-Compatible Obstacles
Sep 13, 2023One of the most important aspects of autonomous systems is safety. This includes ensuring safe human-robot and safe robot-environment interaction when autonomously performing complex tasks or in collaborative scenarios. Although several methods have been introduced to tackle this, most are unsuitable for real-time applications and require carefully hand-crafted obstacle descriptions. In this work, we propose a method combining high-frequency and real-time self and environment collision avoidance of a robotic manipulator with low-frequency, multimodal, and high-resolution environmental perceptions accumulated in a digital twin system. Our method is based on geometric primitives, so-called primitive skeletons. These, in turn, are information-compressed and real-time compatible digital representations of the robot's body and environment, automatically generated from ultra-realistic virtual replicas of the real world provided by the digital twin. Our approach is a key enabler for closing the loop between environment perception and robot control by providing the millisecond real-time control stage with a current and accurate world description, empowering it to react to environmental changes. We evaluate our whole-body collision avoidance on a 9-DOFs robot system through five experiments, demonstrating the functionality and efficiency of our framework.
ZiCo-BC: A Bias Corrected Zero-Shot NAS for Vision Tasks
Sep 26, 2023Zero-Shot Neural Architecture Search (NAS) approaches propose novel training-free metrics called zero-shot proxies to substantially reduce the search time compared to the traditional training-based NAS. Despite the success on image classification, the effectiveness of zero-shot proxies is rarely evaluated on complex vision tasks such as semantic segmentation and object detection. Moreover, existing zero-shot proxies are shown to be biased towards certain model characteristics which restricts their broad applicability. In this paper, we empirically study the bias of state-of-the-art (SOTA) zero-shot proxy ZiCo across multiple vision tasks and observe that ZiCo is biased towards thinner and deeper networks, leading to sub-optimal architectures. To solve the problem, we propose a novel bias correction on ZiCo, called ZiCo-BC. Our extensive experiments across various vision tasks (image classification, object detection and semantic segmentation) show that our approach can successfully search for architectures with higher accuracy and significantly lower latency on Samsung Galaxy S10 devices.
Policy Optimization in a Noisy Neighborhood: On Return Landscapes in Continuous Control
Sep 26, 2023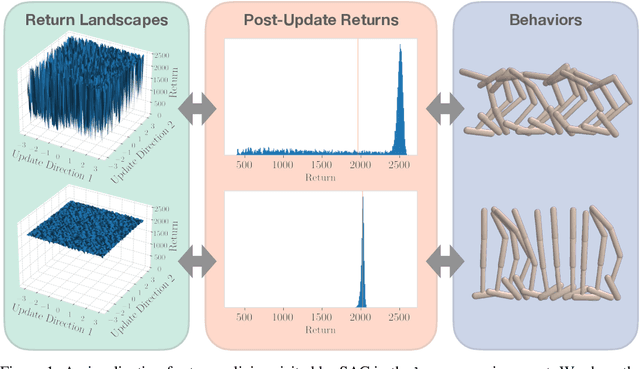
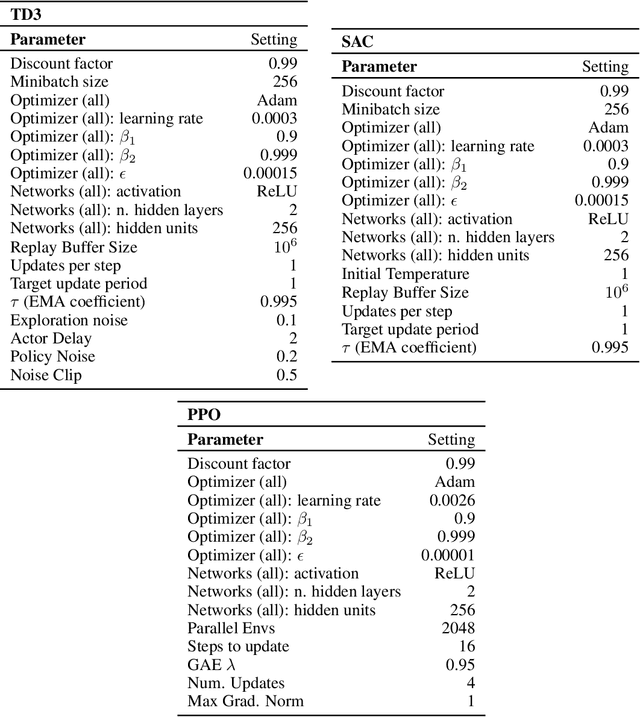
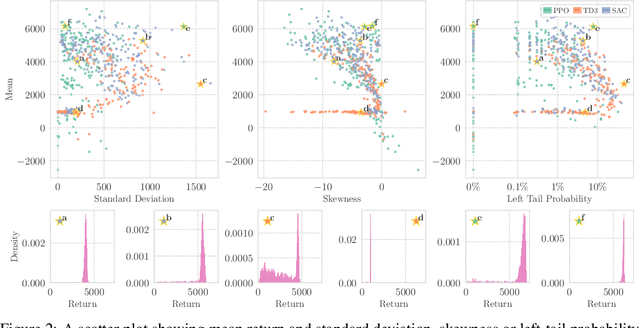
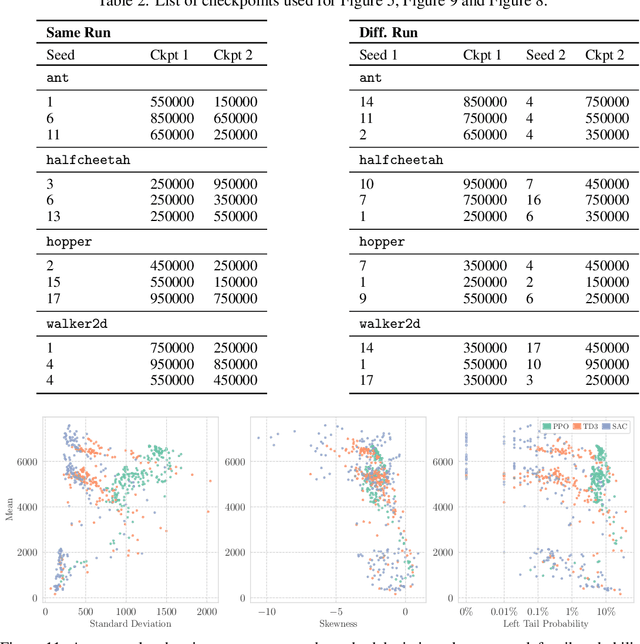
Deep reinforcement learning agents for continuous control are known to exhibit significant instability in their performance over time. In this work, we provide a fresh perspective on these behaviors by studying the return landscape: the mapping between a policy and a return. We find that popular algorithms traverse noisy neighborhoods of this landscape, in which a single update to the policy parameters leads to a wide range of returns. By taking a distributional view of these returns, we map the landscape, characterizing failure-prone regions of policy space and revealing a hidden dimension of policy quality. We show that the landscape exhibits surprising structure by finding simple paths in parameter space which improve the stability of a policy. To conclude, we develop a distribution-aware procedure which finds such paths, navigating away from noisy neighborhoods in order to improve the robustness of a policy. Taken together, our results provide new insight into the optimization, evaluation, and design of agents.
Des-q: a quantum algorithm to construct and efficiently retrain decision trees for regression and binary classification
Sep 19, 2023Decision trees are widely used in machine learning due to their simplicity in construction and interpretability. However, as data sizes grow, traditional methods for constructing and retraining decision trees become increasingly slow, scaling polynomially with the number of training examples. In this work, we introduce a novel quantum algorithm, named Des-q, for constructing and retraining decision trees in regression and binary classification tasks. Assuming the data stream produces small increments of new training examples, we demonstrate that our Des-q algorithm significantly reduces the time required for tree retraining, achieving a poly-logarithmic time complexity in the number of training examples, even accounting for the time needed to load the new examples into quantum-accessible memory. Our approach involves building a decision tree algorithm to perform k-piecewise linear tree splits at each internal node. These splits simultaneously generate multiple hyperplanes, dividing the feature space into k distinct regions. To determine the k suitable anchor points for these splits, we develop an efficient quantum-supervised clustering method, building upon the q-means algorithm of Kerenidis et al. Des-q first efficiently estimates each feature weight using a novel quantum technique to estimate the Pearson correlation. Subsequently, we employ weighted distance estimation to cluster the training examples in k disjoint regions and then proceed to expand the tree using the same procedure. We benchmark the performance of the simulated version of our algorithm against the state-of-the-art classical decision tree for regression and binary classification on multiple data sets with numerical features. Further, we showcase that the proposed algorithm exhibits similar performance to the state-of-the-art decision tree while significantly speeding up the periodic tree retraining.