 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
SynthoGestures: A Novel Framework for Synthetic Dynamic Hand Gesture Generation for Driving Scenarios
Sep 08, 2023
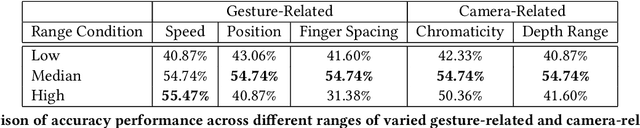
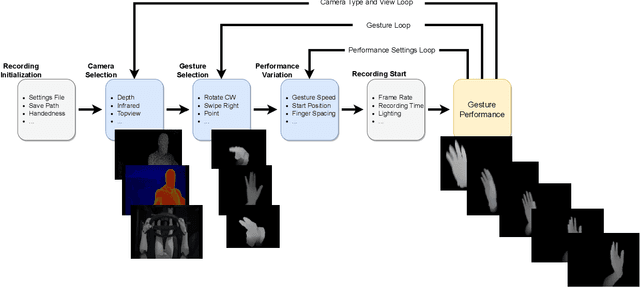

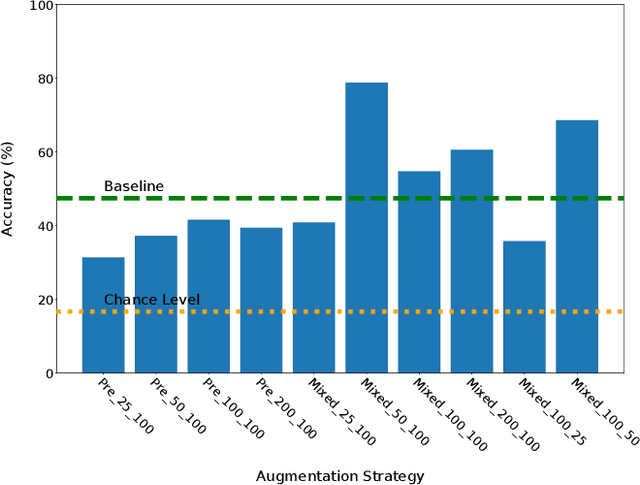
Creating a diverse and comprehensive dataset of hand gestures for dynamic human-machine interfaces in the automotive domain can be challenging and time-consuming. To overcome this challenge, we propose using synthetic gesture datasets generated by virtual 3D models. Our framework utilizes Unreal Engine to synthesize realistic hand gestures, offering customization options and reducing the risk of overfitting. Multiple variants, including gesture speed, performance, and hand shape, are generated to improve generalizability. In addition, we simulate different camera locations and types, such as RGB, infrared, and depth cameras, without incurring additional time and cost to obtain these cameras. Experimental results demonstrate that our proposed framework, SynthoGestures\footnote{\url{https://github.com/amrgomaaelhady/SynthoGestures}}, improves gesture recognition accuracy and can replace or augment real-hand datasets. By saving time and effort in the creation of the data set, our tool accelerates the development of gesture recognition systems for automotive applications.
Lighter-Than-Air Autonomous Ball Capture and Scoring Robot -- Design, Development, and Deployment
Sep 12, 2023
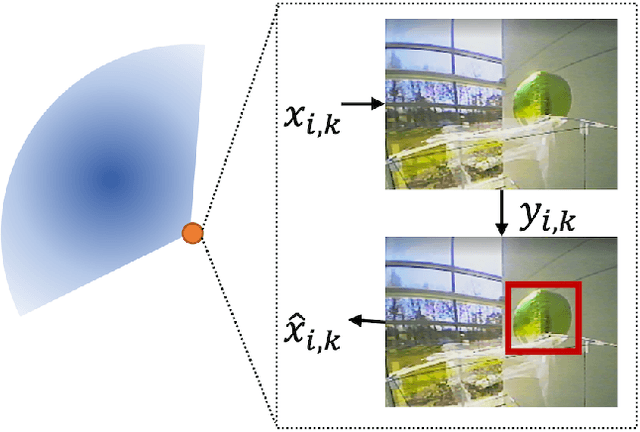
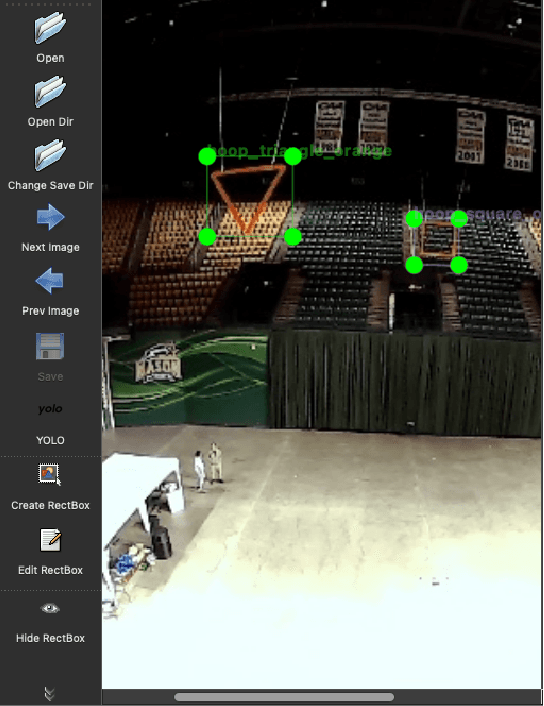

This paper describes the full end-to-end design of our primary scoring agent in an aerial autonomous robotics competition from April 2023. As open-ended robotics competitions become more popular, we wish to begin documenting successful team designs and approaches. The intended audience of this paper is not only any future or potential participant in this particular national Defend The Republic (DTR) competition, but rather anyone thinking about designing their first robot or system to be entered in a competition with clear goals. Future DTR participants can and should either build on the ideas here, or find new alternate strategies that can defeat the most successful design last time. For non-DTR participants but students interested in robotics competitions, identifying the minimum viable system needed to be competitive is still important in helping manage time and prioritizing tasks that are crucial to competition success first.
Joint Machine-Transporter Scheduling for Multistage Jobs with Adjustable Computation Time
Jul 11, 2023This paper presents a scalable solution with adjustable computation time for the joint problem of scheduling and assigning machines and transporters for missions that must be completed in a fixed order of operations across multiple stages. A battery-operated multi-robot system with a maximum travel range is employed as the transporter between stages and charging them is considered as an operation. Robots are assigned to a single job until its completion. Additionally, The operation completion time is assumed to be dependent on the machine and the type of operation, but independent of the job. This work aims to minimize a weighted multi-objective goal that includes both the required time and energy consumed by the transporters. This problem is a variation of the flexible flow shop with transports, that is proven to be NP-complete. To provide a solution, time is discretized, the solution space is divided temporally, and jobs are clustered into diverse groups. Finally, an integer linear programming solver is applied within a sliding time window to determine assignments and create a schedule that minimizes the objective. The computation time can be reduced depending on the number of jobs selected at each segment, with a trade-off on optimality. The proposed algorithm finds its application in a water sampling project, where water sampling jobs are assigned to robots, sample deliveries at laboratories are scheduled, and the robots are routed to charging stations.
A Deep Dive into Perturbations as Evaluation Technique for Time Series XAI
Jul 11, 2023
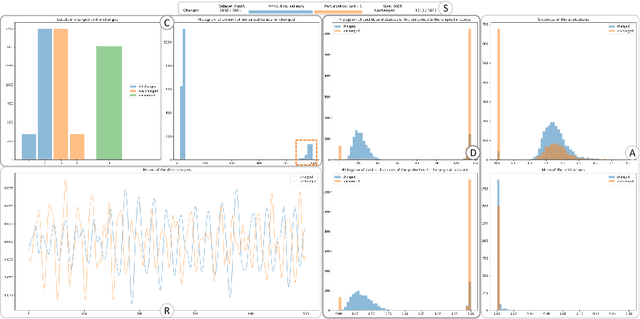
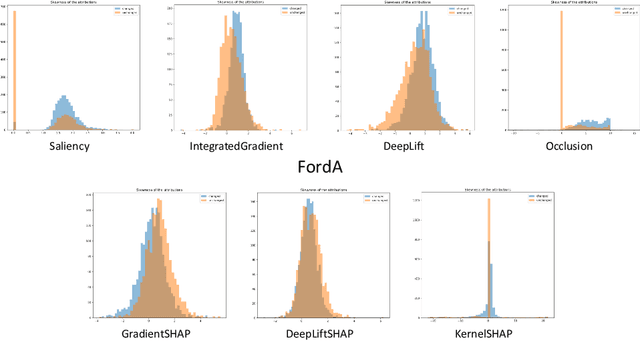
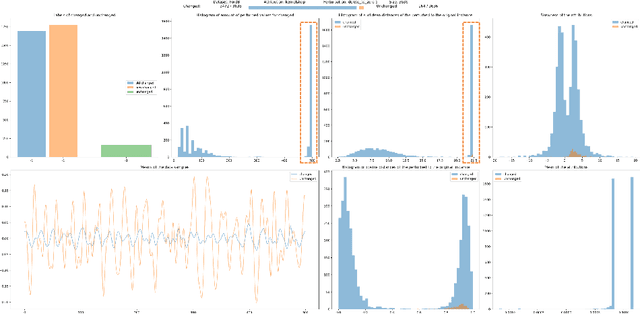
Explainable Artificial Intelligence (XAI) has gained significant attention recently as the demand for transparency and interpretability of machine learning models has increased. In particular, XAI for time series data has become increasingly important in finance, healthcare, and climate science. However, evaluating the quality of explanations, such as attributions provided by XAI techniques, remains challenging. This paper provides an in-depth analysis of using perturbations to evaluate attributions extracted from time series models. A perturbation analysis involves systematically modifying the input data and evaluating the impact on the attributions generated by the XAI method. We apply this approach to several state-of-the-art XAI techniques and evaluate their performance on three time series classification datasets. Our results demonstrate that the perturbation analysis approach can effectively evaluate the quality of attributions and provide insights into the strengths and limitations of XAI techniques. Such an approach can guide the selection of XAI methods for time series data, e.g., focusing on return time rather than precision, and facilitate the development of more reliable and interpretable machine learning models for time series analysis.
fakenewsbr: A Fake News Detection Platform for Brazilian Portuguese
Sep 21, 2023The proliferation of fake news has become a significant concern in recent times due to its potential to spread misinformation and manipulate public opinion. This paper presents a comprehensive study on detecting fake news in Brazilian Portuguese, focusing on journalistic-type news. We propose a machine learning-based approach that leverages natural language processing techniques, including TF-IDF and Word2Vec, to extract features from textual data. We evaluate the performance of various classification algorithms, such as logistic regression, support vector machine, random forest, AdaBoost, and LightGBM, on a dataset containing both true and fake news articles. The proposed approach achieves high accuracy and F1-Score, demonstrating its effectiveness in identifying fake news. Additionally, we developed a user-friendly web platform, fakenewsbr.com, to facilitate the verification of news articles' veracity. Our platform provides real-time analysis, allowing users to assess the likelihood of fake news articles. Through empirical analysis and comparative studies, we demonstrate the potential of our approach to contribute to the fight against the spread of fake news and promote more informed media consumption.
CaveSeg: Deep Semantic Segmentation and Scene Parsing for Autonomous Underwater Cave Exploration
Sep 21, 2023
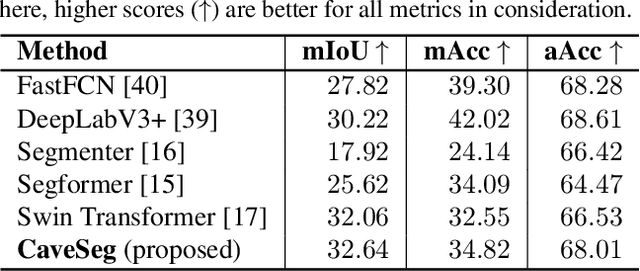

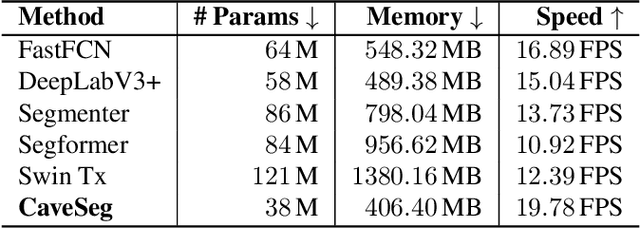
In this paper, we present CaveSeg - the first visual learning pipeline for semantic segmentation and scene parsing for AUV navigation inside underwater caves. We address the problem of scarce annotated training data by preparing a comprehensive dataset for semantic segmentation of underwater cave scenes. It contains pixel annotations for important navigation markers (e.g. caveline, arrows), obstacles (e.g. ground plain and overhead layers), scuba divers, and open areas for servoing. Through comprehensive benchmark analyses on cave systems in USA, Mexico, and Spain locations, we demonstrate that robust deep visual models can be developed based on CaveSeg for fast semantic scene parsing of underwater cave environments. In particular, we formulate a novel transformer-based model that is computationally light and offers near real-time execution in addition to achieving state-of-the-art performance. Finally, we explore the design choices and implications of semantic segmentation for visual servoing by AUVs inside underwater caves. The proposed model and benchmark dataset open up promising opportunities for future research in autonomous underwater cave exploration and mapping.
ExBluRF: Efficient Radiance Fields for Extreme Motion Blurred Images
Sep 21, 2023

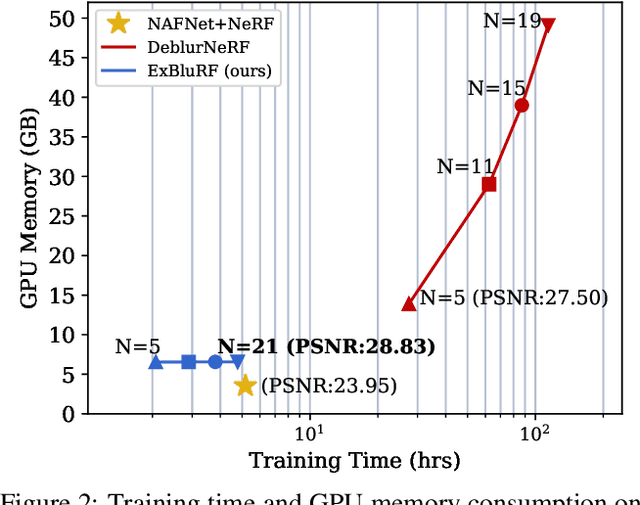
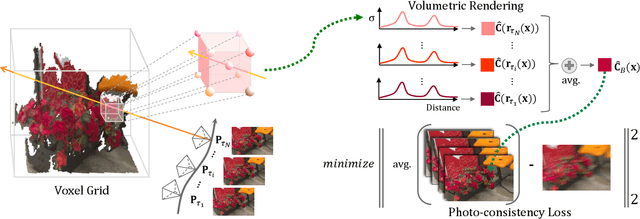
We present ExBluRF, a novel view synthesis method for extreme motion blurred images based on efficient radiance fields optimization. Our approach consists of two main components: 6-DOF camera trajectory-based motion blur formulation and voxel-based radiance fields. From extremely blurred images, we optimize the sharp radiance fields by jointly estimating the camera trajectories that generate the blurry images. In training, multiple rays along the camera trajectory are accumulated to reconstruct single blurry color, which is equivalent to the physical motion blur operation. We minimize the photo-consistency loss on blurred image space and obtain the sharp radiance fields with camera trajectories that explain the blur of all images. The joint optimization on the blurred image space demands painfully increasing computation and resources proportional to the blur size. Our method solves this problem by replacing the MLP-based framework to low-dimensional 6-DOF camera poses and voxel-based radiance fields. Compared with the existing works, our approach restores much sharper 3D scenes from challenging motion blurred views with the order of 10 times less training time and GPU memory consumption.
A Comprehensive Study of PAPR Reduction Techniques for Deep Joint Source Channel Coding in OFDM Systems
Sep 21, 2023
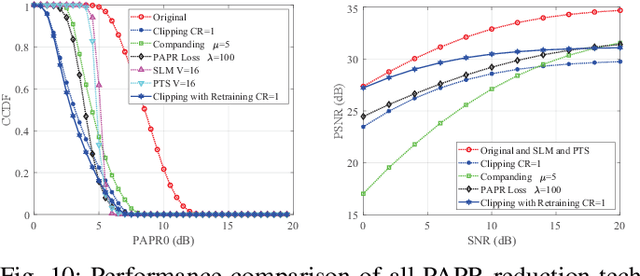
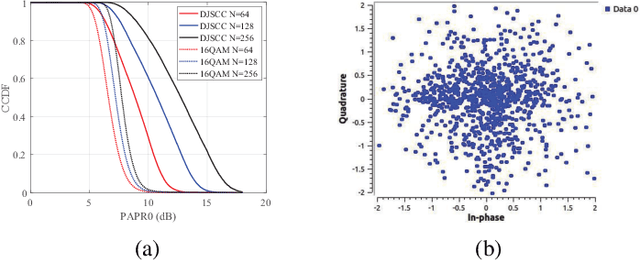
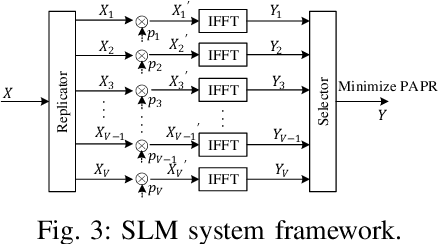
Recently, deep joint source channel coding (DJSCC) techniques have been extensively studied and have shown significant performance with limited bandwidth and low signal to noise ratio. Most DJSCC work considers discrete-time analog transmission, while combining it with orthogonal frequency division multiplexing (OFDM) creates serious high peak-to-average power ratio (PAPR) problem. This paper conducts a comprehensive analysis on the use of various OFDM PAPR reduction techniques in the DJSCC system, including both conventional techniques such as clipping, companding, SLM and PTS, and deep learning-based PAPR reduction techniques such as PAPR loss and clipping with retraining. Our investigation shows that although conventional PAPR reduction techniques can be applied to DJSCC, their performance in DJSCC is different from the conventional split source channel coding. Moreover, we observe that for signal distortion PAPR reduction techniques, clipping with retraining achieves the best performance in terms of both PAPR reduction and recovery accuracy. It is also noticed that signal non-distortion PAPR reduction techniques can successfully reduce the PAPR in DJSCC without compromise to signal reconstruction.
On the Relationship between Skill Neurons and Robustness in Prompt Tuning
Sep 21, 2023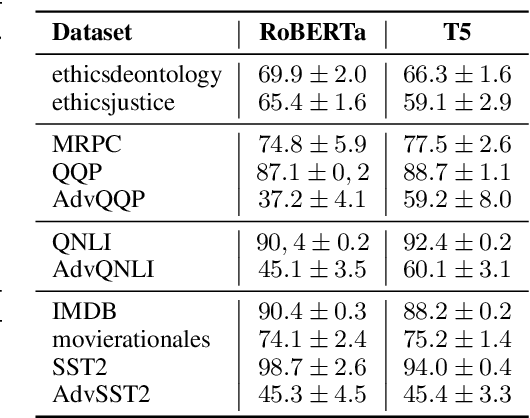
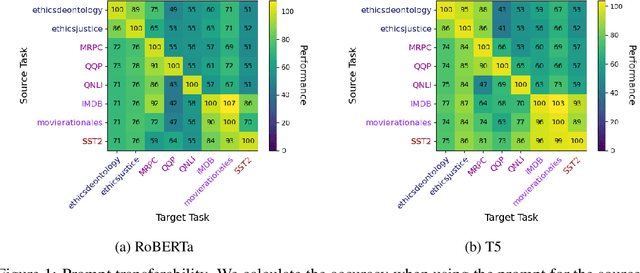
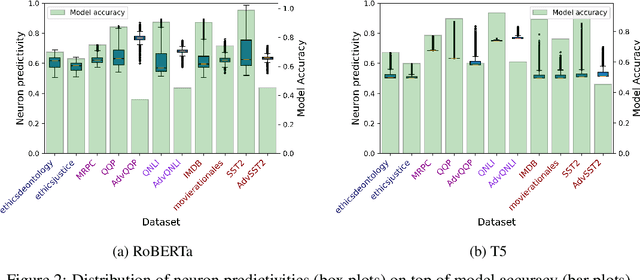
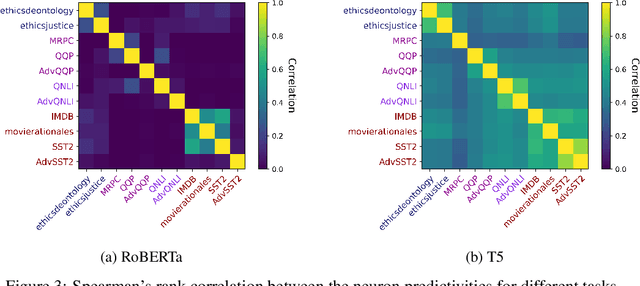
Prompt Tuning is a popular parameter-efficient finetuning method for pre-trained large language models (PLMs). Recently, based on experiments with RoBERTa, it has been suggested that Prompt Tuning activates specific neurons in the transformer's feed-forward networks, that are highly predictive and selective for the given task. In this paper, we study the robustness of Prompt Tuning in relation to these "skill neurons", using RoBERTa and T5. We show that prompts tuned for a specific task are transferable to tasks of the same type but are not very robust to adversarial data, with higher robustness for T5 than RoBERTa. At the same time, we replicate the existence of skill neurons in RoBERTa and further show that skill neurons also seem to exist in T5. Interestingly, the skill neurons of T5 determined on non-adversarial data are also among the most predictive neurons on the adversarial data, which is not the case for RoBERTa. We conclude that higher adversarial robustness may be related to a model's ability to activate the relevant skill neurons on adversarial data.
SG-Bot: Object Rearrangement via Coarse-to-Fine Robotic Imagination on Scene Graphs
Sep 21, 2023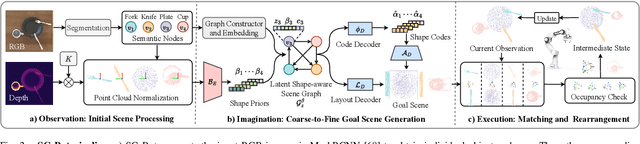
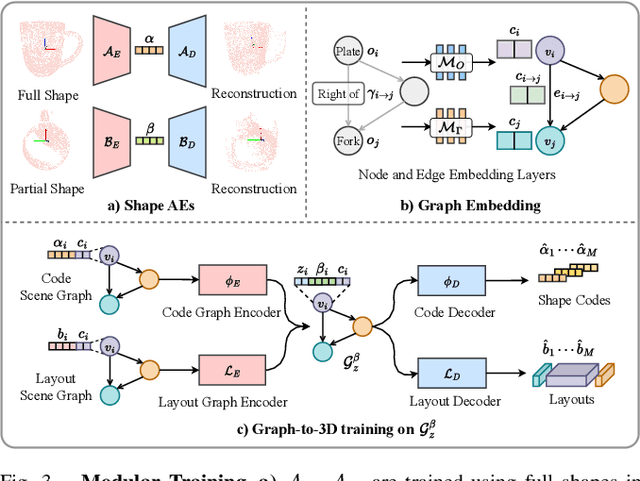
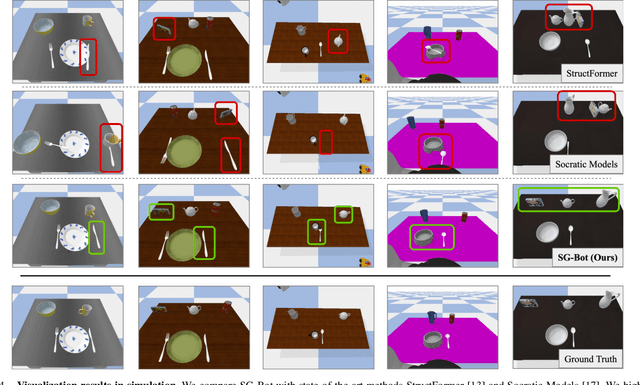

Object rearrangement is pivotal in robotic-environment interactions, representing a significant capability in embodied AI. In this paper, we present SG-Bot, a novel rearrangement framework that utilizes a coarse-to-fine scheme with a scene graph as the scene representation. Unlike previous methods that rely on either known goal priors or zero-shot large models, SG-Bot exemplifies lightweight, real-time, and user-controllable characteristics, seamlessly blending the consideration of commonsense knowledge with automatic generation capabilities. SG-Bot employs a three-fold procedure--observation, imagination, and execution--to adeptly address the task. Initially, objects are discerned and extracted from a cluttered scene during the observation. These objects are first coarsely organized and depicted within a scene graph, guided by either commonsense or user-defined criteria. Then, this scene graph subsequently informs a generative model, which forms a fine-grained goal scene considering the shape information from the initial scene and object semantics. Finally, for execution, the initial and envisioned goal scenes are matched to formulate robotic action policies. Experimental results demonstrate that SG-Bot outperforms competitors by a large margin.